时间序列分解结果

在随机时间序列分析中,为简便起见,我们假定时间序列主要由趋势项(T)、季节项 (S)和随机项(R)构成。
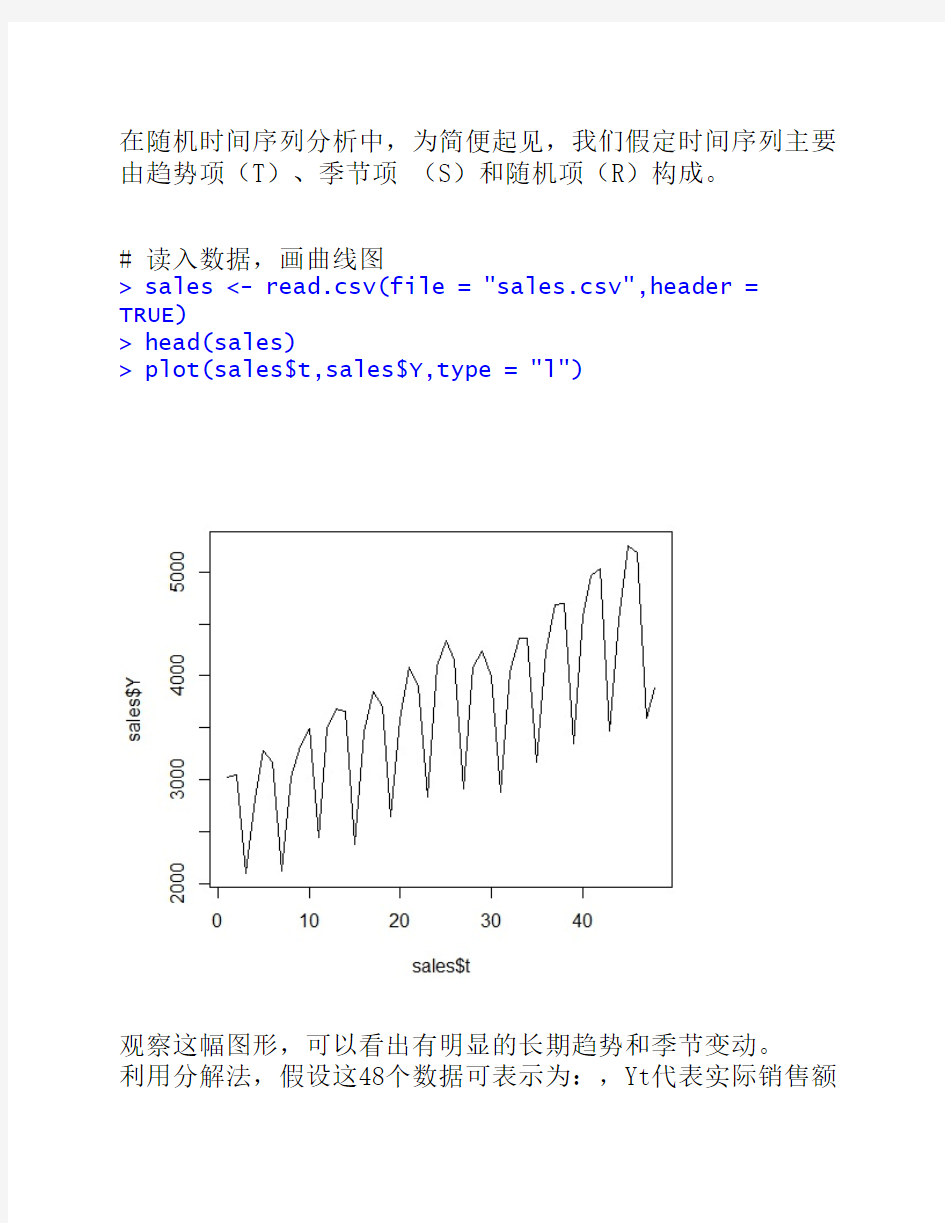
# 读入数据,画曲线图
> sales <- read.csv(file = "sales.csv",header = TRUE)
> head(sales)
> plot(sales$t,sales$Y,type = "l")
观察这幅图形,可以看出有明显的长期趋势和季节变动。
利用分解法,假设这48个数据可表示为:,Yt代表实际销售额
度。
长期趋势的分解
用时间回归法,在同一图中画出趋势项目、季节项和随机项的数据图,如下:
decompose()函数主要用来做季节指数分解,figure项即指季节指数。同时也返回原始数据,以及MA算法的结果;trend趋势项使用光滑移动平均法求得,它包含了长期趋势T 和周期变动因素C,之前用回归法求得长期趋势T,利用此函数的返回值Trend即可求得周期变动因素C;Random即为不规则变动。
此函数的基本结构:
Additive: xt = Trend + Seasonal + Random
Multiplicative: xt = Trend * Seasonal * Random
> sales1 <- ts(sales[,2],start = 1,frequency = 4)
# 季节变动趋势分解
> m <- decompose(sales1,type = "multiplicative")
> plot(m)
> m$x
Qtr1 Qtr2 Qtr3 Qtr4
2003 3017.60 3043.54 2094.35 2809.84
2004 3274.80 3163.28 2114.31 3024.57
2005 3327.48 3493.48 2439.93 3490.79
2006 3685.08 3661.23 2378.43 3459.55
2007 3849.63 3701.18 2642.38 3585.52
2008 4078.66 3907.06 2828.46 4089.50
2009 4339.61 4148.60 2916.45 4084.64
2010 4242.42 3997.58 2881.01 4036.23
2011 4360.33 4360.53 3172.18 4223.76
2012 4690.48 4694.48 3342.35 4577.63
2013 4965.46 5026.05 3470.14 4525.94
2014 5258.71 5189.58 3596.76 3881.60
$seasonal
Qtr1 Qtr2 Qtr3 Qtr4 2003 1.1213967 1.0938549 0.7535947 1.0311537 2004 1.1213967 1.0938549 0.7535947 1.0311537 2005 1.1213967 1.0938549 0.7535947 1.0311537 2006 1.1213967 1.0938549 0.7535947 1.0311537 2007 1.1213967 1.0938549 0.7535947 1.0311537 2008 1.1213967 1.0938549 0.7535947 1.0311537 2009 1.1213967 1.0938549 0.7535947 1.0311537 2010 1.1213967 1.0938549 0.7535947 1.0311537 2011 1.1213967 1.0938549 0.7535947 1.0311537 2012 1.1213967 1.0938549 0.7535947 1.0311537 2013 1.1213967 1.0938549 0.7535947 1.0311537 2014 1.1213967 1.0938549 0.7535947 1.0311537 $trend(居中平均TC)
Qtr1 Qtr2 Qtr3 Qtr4 2003 NA NA 2773.483 2820.600 2004 2838.062 2867.399 2900.825 2948.685 2005 3030.662 3129.642 3232.620 3298.289 2006 3311.570 3299.977 3316.641 3342.204 2007 3380.191 3428.931 3473.306 3527.670 2008 3576.665 3662.923 3758.539 3821.350 2009 3862.541 3872.932 3860.176 3829.150 **** ****.843 3795.361 3804.049 3864.156 **** ****.921 4005.759 4070.469 4153.481 2012 4216.496 4282.001 4360.608 4436.426 2013 4493.846 4503.359 4533.554 4590.651 2014 4626.920 4562.205 NA NA $random(不规则变动)
Qtr1 Qtr2 Qtr3 Qtr4 2003 NA NA 1.0020422 0.9660880 2004 1.0289720 1.0085324 0.9671844 0.9947452 2005 0.9790810 1.0204784 1.0015782 1.0263881 2006 0.9923245 1.0142764 0.9515991 1.0038372
2007 1.0155901 0.9867832 1.0095187 0.9856910 2008 1.0169040 0.9751303 0.9986037 1.0378390 2009 1.0018860 0.9792688 1.0025581 1.0344940 2010 0.9940394 0.9629070 1.0049880 1.0129728 2011 0.9853980 0.9951643 1.0341310 0.9861967 2012 0.9919877 1.0022614 1.0171081 1.0006541 2013 0.9853307 1.0203063 1.0157116 0.9561171 2014 1.0135098 1.0399147 NA NA $figure (季节变动指数)
[1] 1.1213967 1.0938549 0.7535947 1.0311537 $type
[1] "multiplicative"
attr(,"class")
[1] "decomposed.ts"
观察趋势图,可以发现明显的呈现直线上升的趋势,所有采用线性回归拟合。
> lm.fit <- lm(Y ~ t,data = sales)
> summary(lm.fit)
Call:
lm(formula = Y ~ t, data = sales)
Residuals:
Min 1Q Median 3Q Max
-1062.7 -724.4 241.7 384.8 769.7 Coefficients:
Estimate Std. Error t value Pr(>|t|) (Intercept) 2736.101 168.642 16.224 < 2e-16
***
t 38.954 5.992 6.501 5.11e-08
***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 575.1 on 46 degrees of freedom
Multiple R-squared: 0.4789, Adjusted R-squared: 0.4675
F-statistic: 42.27 on 1 and 46 DF, p-value:
5.115e-08
由此,长期趋势方程为:T=2736.10+38.95t,利用此方程即可求得每个季度的趋势值。
# 长期趋势预测
> lm.predict <- predict(lm.fit,
newdata = data.frame(t =
seq(1:48)))
> lm.predict
> pre15 <- predict(lm.fit,newdata = data.frame(t = 49))
> pre15
1
4644.865
周期变动因素C:
采取百分比率,其值大于100的表明该季度经济活动水平高于所有季度的平均值,而小于100的循环指数所表明的情况则
刚好相反。
#周期变动C
> c <- m$trend/lm.predict
> write.csv(round(c,4),file = "sales2.csv") decompose()函数主要用来做季节指数分解,figure项即指季节指数。同时也返回原始数据,以及MA算法的结果;trend趋势项使用光滑移动平均法求得,它包含了长期趋势T 和周期变动因素C,之前用回归法求得长期趋势T,利用此函数的返回值Trend即可求得周期变动因素C;Random即为不规则变动。
此函数的基本结构:
Additive: xt = Trend + Seasonal + Random Multiplicative: xt = Trend * Seasonal * Random
> sales1 <- ts(sales[,2],start = 1,frequency = 4) # 季节变动趋势分解
> m <- decompose(sales1,type = "multiplicative")
> plot(m)
> m$x
Qtr1 Qtr2 Qtr3 Qtr4
2003 3017.60 3043.54 2094.35 2809.84
2004 3274.80 3163.28 2114.31 3024.57
2005 3327.48 3493.48 2439.93 3490.79
2006 3685.08 3661.23 2378.43 3459.55
2007 3849.63 3701.18 2642.38 3585.52
2008 4078.66 3907.06 2828.46 4089.50
2009 4339.61 4148.60 2916.45 4084.64
2010 4242.42 3997.58 2881.01 4036.23
2011 4360.33 4360.53 3172.18 4223.76
2012 4690.48 4694.48 3342.35 4577.63
2013 4965.46 5026.05 3470.14 4525.94
2014 5258.71 5189.58 3596.76 3881.60
$seasonal
Qtr1 Qtr2 Qtr3 Qtr4
2003 1.1213967 1.0938549 0.7535947 1.0311537
2004 1.1213967 1.0938549 0.7535947 1.0311537 2005 1.1213967 1.0938549 0.7535947 1.0311537 2006 1.1213967 1.0938549 0.7535947 1.0311537 2007 1.1213967 1.0938549 0.7535947 1.0311537 2008 1.1213967 1.0938549 0.7535947 1.0311537 2009 1.1213967 1.0938549 0.7535947 1.0311537 2010 1.1213967 1.0938549 0.7535947 1.0311537 2011 1.1213967 1.0938549 0.7535947 1.0311537 2012 1.1213967 1.0938549 0.7535947 1.0311537 2013 1.1213967 1.0938549 0.7535947 1.0311537 2014 1.1213967 1.0938549 0.7535947 1.0311537 $trend(居中平均TC)
Qtr1 Qtr2 Qtr3 Qtr4 2003 NA NA 2773.483 2820.600 2004 2838.062 2867.399 2900.825 2948.685 2005 3030.662 3129.642 3232.620 3298.289 2006 3311.570 3299.977 3316.641 3342.204 2007 3380.191 3428.931 3473.306 3527.670 2008 3576.665 3662.923 3758.539 3821.350 2009 3862.541 3872.932 3860.176 3829.150 **** ****.843 3795.361 3804.049 3864.156 **** ****.921 4005.759 4070.469 4153.481 2012 4216.496 4282.001 4360.608 4436.426 2013 4493.846 4503.359 4533.554 4590.651 2014 4626.920 4562.205 NA NA $random(不规则变动)
Qtr1 Qtr2 Qtr3 Qtr4 2003 NA NA 1.0020422 0.9660880 2004 1.0289720 1.0085324 0.9671844 0.9947452 2005 0.9790810 1.0204784 1.0015782 1.0263881 2006 0.9923245 1.0142764 0.9515991 1.0038372 2007 1.0155901 0.9867832 1.0095187 0.9856910 2008 1.0169040 0.9751303 0.9986037 1.0378390 2009 1.0018860 0.9792688 1.0025581 1.0344940 2010 0.9940394 0.9629070 1.0049880 1.0129728
2011 0.9853980 0.9951643 1.0341310 0.9861967 2012 0.9919877 1.0022614 1.0171081 1.0006541 2013 0.9853307 1.0203063 1.0157116 0.9561171 2014 1.0135098 1.0399147 NA NA $figure (季节变动指数)
[1] 1.1213967 1.0938549 0.7535947 1.0311537 $type
[1] "multiplicative"
attr(,"class")
[1] "decomposed.ts"
【SPSS看统计学】之时间序列预测Word版
时间序列预测技术 下面看看如何采用SPSS软件进行时间序列的预测 我们通过案例来说明: 假设我们拿到一个时间序列数据集:某男装生产线销售额。一个产品分类销售公司会根据过去 10 年的销售数据来预测其男装生产线的月销售情况。 现在我们得到了10年120个历史销售数据,理论上讲,历史数据越多预测越稳定,一般也要24个历史数据才行! 大家看到,原则上讲数据中没有时间变量,实际上也不需要时间变量,但你必须知道时间的起点和时间间隔。
当我们现在预测方法创建模型时,记住:一定要先定义数据的时间序列和标记! 这时候你要决定你的时间序列数据的开始时间,时间间隔,周期!在我们这个案例中,你要决定季度是否是你考虑周期性或季节性的影响因素,软件能够侦测到你的数据的季节性变化因子。
定义了时间序列的时间标记后,数据集自动生成四个新的变量:YEAR、QUARTER、MONTH和DATE(时间标签)。 接下来:为了帮我们找到适当的模型,最好先绘制时间序列。时间序列的可视化检查通常可以很好地指导并帮助我们进行选择。另外,我们需要弄清以下几点: ?此序列是否存在整体趋势?如果是,趋势是显示持续存在还是显示将随时间而消逝? ?此序列是否显示季节变化?如果是,那么这种季节的波动是随时间而加剧还是持续稳定存在?
这时候我们就可以看到时间序列图了! 我们看到:此序列显示整体上升趋势,即序列值随时间而增加。上升趋势似乎将持续,即为线性趋势。此序列还有一个明显的季节特征,即年度高点在十二月。季节变化显示随上升序列而增长的趋势,表明是乘法季节模型而不是加法季节模型。 此时,我们对时间序列的特征有了大致的了解,便可以开始尝试构建预测模型。时间序列预测模型的建立是一个不断尝试和选择的过程。 了三大类预测方法:1-专家建模器,2-指数平滑法,3-ARIMA
基于奇异值分解的人脸识别
人机交互大作业 ——人脸识别
“人脸识别”系统设计文档 人脸识别的意义及应用 人脸识别是指对视频或图像中的人脸进行发现,追踪,进而识别出是特定个体的一种生物特征技术,也是生物特征识别中最主要的研究方向之一。人脸识别在日常生活中有着非常广泛的应用市场。下面列举了一些人脸识别的主要应用:1.监控系统 监控系统在日常生活中非常常用,是防盗系统的主要组成部分之一。人工智能的监控系统的一大优势就是可以将人类从每天对着监视器的枯燥工作中解脱出来。将监视的工作交给计算机来做,有几个优势。一是可以365天,24小时不间断的工作。二是可以不知疲倦,不会因为时间长而分散注意力。但是人工智能的监控系统仍面临着很多问题,比如漏识别,识别误差等等。2.身份验证 身份验证系统可以应用的范围也很广。比如现有的银行存取款系统,当人的银行卡和密码同时丢失时,卡中的钱就可能被转走。但是如果在取款机上安装一个人脸识别系统,在提供银行卡和密码时,同时需要进行面部认证,这样就会大大降低个人财产损失的风险。 3.考勤系统 考勤系统通常用在公司里。传统的考勤系统需要给每个员工分配一张考勤卡,每天上下班需要去打卡。这样会给员工带来一定的不便。如果员工忘记带卡,或者卡有损坏,就会耽误打卡。而且专门设立打卡地点,不仅上下班打卡不方便,而且还会出现替打卡的情况。使用人脸识别系统,可以在不被觉察的情况下,自然地实现员工的考勤。减少了很多不必要的麻烦。 4.视频、图像检索 随着人们对图像,视频等需求的不断扩展,网络上的图像和视频信息量也在以极快的速度增长。在如此庞大的信息库中快速查找到用户需要的信息成了现在研究的一个重要方向。而现在最主流的方式是在视频和图像上附带描述信息。这种描述信息可以被发布人随意更改,很多时候会对用户产生误导,浪费了时间。而用人脸识别进行图像和视频的检索,在检索某些特定人相关的资源时,会大大提高搜索结果的质量。再配合上描述关键词,能使人更快速寻找到所需信息。 人脸识别的优势和困难 人脸识别相对于传统的身份验证技术,和现有的虹膜识别,指纹识别等技术有一个显著的优势,就是可以自然地获取识别对象的身份信息,而不需要识别对象刻意的配合。虹膜识别和指纹识别都需要识别对象的配合。在这种情况下,识别对象可以有意识的进行伪装和欺骗。而人脸识别是在人们不经意的时候对人们图像的采集和识别,不会引起识别对象的注意。因此从某种意义上更容易获得真实的信息。 虽然人脸识别有着不可比拟的优势,但是在实现方面还有着很大的困难。
时间序列分析报告word版
第2章 时间序列的预处理 拿到一个观察值序列之后,首先要对它的平稳性和纯随机性进行检验,这两个重要的检验称为序列的预处理。根据检验的结果可以将序列分为不同的类型,对不同类型的序列我们会采用不同的分析方法。 2.1 平稳性检验 2.1.1 特征统计量 平稳性是某些时间序列具有的一种统计特征。要描述清楚这个特征,我们必须借助如下统计工具。 一、概率分布 数理统计的基础知识告诉我们分布函数或密度函数能够完整地描述一个随 机变量的统计特征。同样,一个随机 变量族的统计特性也完全由它们的联 合分布函数或联合密度函数决定。 对于时间序列{t X ,t ∈T },这样来定义它的概率分布: 任取正整数m ,任取m t t t ,, ,?21∈T ,则m 维随机向量(m t t t X X X ,,,?21)’的联合概率分布记为),,,(m t t t x x x F m ??21,,,21,由这些有限维分布函数构成的全体。 {),,,(m t t t x x x F m ??21,,,21,?m ∈正整数,?m t t t ,,,?21∈T } 就称为序列{t X }的概率分布族。 概率分布族是极其重要的统计特征描述工具,因为序列的所有统计性质理论上都可以通过 概率分布推测出来,但是概率分布族的重要 性也就停留在这样的理论意义上。在实际应 用中,要得到序列的联合概率分布几乎是不 可能的,而且联合概率分布通常涉及非常复 杂的数学运算,这些原因使我们很少直接使 用联合概率分布进行时间序列分析。 二、特征统计量 一个更简单、更实用的描述时间序列统计特征的方法是研究该序列的低阶矩,特别是均值、方差、自协方差和自相关系数,它们也被称为特征统计量。 尽管这些特征统计量不能描述随机序列全部的统计性质,但由于它们概率意义明显,易于计算,而且往往能代表随机 序列的主要概率特征,所以我们对时间序列进行分析,主要就是通过分析这些统计量的统计特性,推断出随机序列的性质。 1.均值 对时间序列{t X ,t ∈T }而言,任意时刻的序列值t X 都是一个随机变量,都有它自己的概率分布,不妨记为)(x F t 。只要满足条件 ∞
基于奇异值分解的图像压缩及实现
基于奇异值分解的图像压缩及实现 本文利用奇异值分解方法,来对图片进行压缩,过程中我们 利用Matlab 编程来达到这个目的。 一:实验方法及原理 奇异值:矩阵A 的奇异值定义如下:设n *m r C A ?(r>0),且A A T 的特征值分别为 0n 1r r 21==??=≥≥??≥+λλλλλ (1) 则称i i λσ= (i=1,2,…,n )为A 的奇异值。 奇异值分解定理:设Σ=diag(r 21...σσσ,, ,),由式(1)可知,i σ(i=1,2,…,r )为A 的非零奇异值。U 为m 阶酉矩阵(n 阶复 方阵U 的n 个列向量是U 空间的一个标准正交基,则U 是酉矩阵),V 为n 阶酉矩阵,若满足矩阵等式 (2) 则称式(2)为A 的奇异值分解。若U 写成U =[m 21u ......u u ,, ,]的形式,V 写成V=[n 21v ......v v ,, ,]的形式,则式(2)可写成如下形式: (3) 由于大的奇异值对图像的贡献大,小的奇异值对图像的贡献小,所以可以从r 个奇异值生成矩阵中选取前k 个(k (4) 近似表示图像A。 存储图像A需要mn个数值,存储图像k A需(m+n+1)k个数值,若取 (5) 则可达到压缩图像的目的,比率 (6) 称为压缩率 二:实验过程 1.实验数据来源: 本实验所需要的实验原图片是lena.bmp,处理后的图片设置为lena2.bmp。并获取图片的描述矩阵,为512*512阶8位的方阵。 设为A,同时也是原始矩阵,本实验主要是对A进行奇异值分解,用一个更小阶的矩阵来描述A,从而达到实验目的。 2.实验过程: 提取图像lena.bmp数据,将图片读入Matlab中,存储的是数据矩阵并且设置为512*512的矩阵A,将矩阵A中的数据转换为double型,以适应svd函数的要求,运用函数[U,S,V]=svd(A)进行图像的奇异值分解,分别得到对角奇异值矩阵S为512*1阶,以 1 页(共 4 页) 考核课程 时间序列分析(B 卷) 考核方式 闭卷 考核时间 120 分钟 注:B 为延迟算子,使得1-=t t Y BY ;?为差分算子,1--=?t t t Y Y Y 。 一、单项选择题(每小题3 分,共24 分。) 1. 若零均值平稳序列{}t X ,其样本ACF 和样本PACF 都呈现拖尾性,则对{}t X 可能建立( B )模型。 A. MA(2) B.ARMA(1,1) C.AR(2) D.MA(1) 2.下图是某时间序列的样本偏自相关函数图,则恰当的模型是( B )。 A. )1(MA B.)1(AR C.)1,1(ARMA D.)2(MA 3. 考虑MA(2)模型212.09.0--+-=t t t t e e e Y ,则其MA 特征方程的根是( C )。 (A )5.0,4.021==λλ (B )5.0,4.021-=-=λλ (C )5.2221==λλ, (D ) 5.2221=-=λλ, 4. 设有模型112111)1(----=++-t t t t t e e X X X θφφ,其中11<φ,则该模型属于( B )。 A.ARMA(2,1) B.ARIMA(1,1,1) C.ARIMA(0,1,1) D.ARIMA(1,2,1) 5. AR(2)模型t t t t e Y Y Y +-=--215.04.0,其中64.0)(=t e Var ,则=)(t t e Y E ( B )。 A.0 B.64.0 C. 1 6.0 D. 2.0 6.对于一阶滑动平均模型MA(1): 15.0--=t t t e e Y ,则其一阶自相关函数为( C )。 A.5.0- B. 25.0 C. 4.0- D. 8.0 7. 若零均值平稳序列{}t X ?,其样本ACF 呈现二阶截尾性,其样本PACF 呈现拖尾性,则可初步认为对{}t X 应该建立( B )模型。 A. MA(2) B.)2,1(IMA C.)1,2(ARI D.ARIMA(2,1,2) 8. 记?为差分算子,则下列不正确的是( C )。 A. 12-?-?=?t t t Y Y Y B. 212 2--+-=?t t t t Y Y Y Y C. k t t t k Y Y Y --=? D. t t t t Y X Y X ?+?=+?) ( 二、填空题(每题3分,共24分); 1. 若{}t Y 满足: 1312112---Θ-Θ--=??t t t t t e e e e Y θθ, 则该模型为一个季节周期为=s __12____的乘法季节s ARIMA )1,1_,0(_)1_,1_,0(?模型。 现代信号处理 学号: 小组组长: 小组成员及分工: 任课教师: 教师所在学院:信息工程学院 2015年11月 论文题目 基于奇异值分解的MVDR方法及其在信号频率估计领域的 应用 摘要:本文主要是介绍和验证MVDR的算法,此算法应用于信号频率估计的领域中。我们通过使用经典的MVDR算法验证算法的可行性,再通过引用了奇异值分解的思想对MVDR方法进行了改进,在验证这种改进思想的方法可行性时,我们发现基于这种奇异值分解的MVDR方法在信号频率估计上具有提高检测精度的特性,这也说明了这种思想在应用信号频率估计时是可行的。 关键词:MVDR算法奇异值分解信号频率估计 论文题目(English) MVDR method based on singular value decomposition and its application in signal frequency estimation Abstract:In this paper, the algorithm of MVDR is introduced, and the algorithm is applied to the field of signal frequency estimation. By using the classical MVDR algorithm to verify the feasibility of the algorithm, and then through the use of the idea of singular value decomposition to improve the MVDR method, in the verification of the feasibility of the method, we found that the MVDR method based on the singular value decomposition has the characteristics of improving the detection accuracy in signal frequency estimation. It also shows that this idea is feasible in the application of signal frequency estimation. Key words: MVDR method Singular value decomposition Signal frequency estimation 应用时间序列分析实验报告 实验过程记录(含程序、数据记录及分析和实验结果等):时序图如下: 单位根检验输出结果如下: 序列x的单位根检验结果: 序列y的单位根检验结果: 序列y和序列x之间的相关图如下: 残差序列自相关图: 自相关图显示。延迟6阶之后自相关系数都在2倍标准差范围之内,可以认为残差序列平稳。 对残差序列进行2阶自相关单位根检验,检验结果显示残差序列显著平稳,如下图:残差序列单位根检验结果: 残差序列平稳,说明序列Y与序列X之间具有协整关系,我可以大胆的在这两个 序列之间建立回归模型而不必担心虚假回归问题。 考察残差序列白噪声检验结果,如下图: 残差序列白噪声检验结果: 输出结果显示,延迟各阶LB 统计量的P 值都大于显著水平0.05,可以认为残差序列为白噪声检验结果,结束分析。 出口序列拟合的模型为:lnx t ~ARIMA(1,1,0),具体口径为: 1 ln 0.1468910.38845t t x B ε?=+- 进口序列拟合的模型为 lny t ~ARIMA(1,1,0) ,具体口径为: 1 ln 0.1467210.36364 t t y ε?=+- lny t 和lnx t 具有协整关系。 协整模型为: 1ln 0.99179ln 0.69938t t t t y x εε-=+- 误差修正模型为: 1ln 0.9786ln 0.22395t t t y x ECM -?=?- SAS 程序如下: data example6_4; input x y@@; t=_n_; cards ; 1950 20.0 21.3 1951 24.2 35.3 1952 27.1 37.5 1953 34.8 46.1 1954 40.0 44.7 1955 48.7 61.1 1956 55.7 53.0 1957 54.5 50.0 1958 67.0 61.7 1959 78.1 71.2 1960 63.3 65.1 1961 47.7 43.0 1962 47.1 33.8 1963 50.0 35.7 1964 55.4 42.1 1965 63.1 55.3 1966 66.0 61.1 考核课程 时间序列分析(B 卷) 考核方式 闭卷 考核时间 120 分钟 注:B 为延迟算子,使得1-=t t Y BY ;?为差分算子,。 一、单项选择题(每小题3 分,共24 分。) 1. 若零均值平稳序列{}t X ,其样本ACF 和样本PACF 都呈现拖尾性,则对{}t X 可能建立( B )模型。 A. MA(2) B.ARMA(1,1) C.AR(2) D.MA(1) 2.下图是某时间序列的样本偏自相关函数图,则恰当的模型是( B )。 A. )1(MA B.)1(AR C.)1,1(ARMA D.)2(MA 3. 考虑MA(2)模型212.09.0--+-=t t t t e e e Y ,则其MA 特征方程的根是( C )。 (A )5.0,4.021==λλ (B )5.0,4.021-=-=λλ (C )5.2221==λλ, (D ) 5.2221=-=λλ, 4. 设有模型112111)1(----=++-t t t t t e e X X X θφφ,其中11<φ,则该模型属于( B )。 A.ARMA(2,1) B.ARIMA(1,1,1) C.ARIMA(0,1,1) D.ARIMA(1,2,1) 5. AR(2)模型t t t t e Y Y Y +-=--215.04.0,其中64.0)(=t e Var ,则=)(t t e Y E ( B )。 A.0 B.64.0 C. 1 6.0 D. 2.0 6.对于一阶滑动平均模型MA(1): 15.0--=t t t e e Y ,则其一阶自相关函数为( C )。 A.5.0- B. 25.0 C. 4.0- D. 8.0 7. 若零均值平稳序列{}t X ?,其样本ACF 呈现二阶截尾性,其样本PACF 呈现拖尾性,则可初步认为对{}t X 应该建立( B )模型。 A. MA(2) B.)2,1(IMA C.)1,2(ARI D.ARIMA(2,1,2) 8. 记?为差分算子,则下列不正确的是( C )。 A. 12-?-?=?t t t Y Y Y B. 212 2--+-=?t t t t Y Y Y Y C. k t t t k Y Y Y --=? D. t t t t Y X Y X ?+?=+?) ( 二、填空题(每题3分,共24分); 【时间简“识”】 说明:本文摘自于经管之家(原人大经济论坛) 作者:胖胖小龟宝。原版请到经管之家(原人大经济论坛) 查看。 1.带你看看时间序列的简史 现在前面的话—— 时间序列作为一门统计学,经济学相结合的学科,在我们论坛,特别是五区计量经济学中是热门讨论话题。本月楼主推出新的系列专题——时间简“识”,旨在对时间序列方面进行知识扫盲(扫盲,仅仅扫盲而已……),同时也想借此吸引一些专业人士能够协助讨论和帮助大家解疑答惑。 在统计学的必修课里,时间序列估计是遭吐槽的重点科目了,其理论性强,虽然应用领域十分广泛,但往往在实际操作中会遇到很多“令人发指”的问题。所以本帖就从基础开始,为大家絮叨絮叨那些关于“时间”的故事! Long long ago,有多long?估计大概7000年前吧,古埃及人把尼罗河涨落的情况逐天记录下来,这一记录也就被我们称作所谓的时间序列。记录这个河流涨落有什么意义?当时的人们并不是随手一记,而是对这个时间序列进行了长期的观察。结果,他们发现尼罗河的涨落非常有规律。掌握了尼罗河泛滥的规律,这帮助了古埃及对农耕和居所有了规划,使农业迅速发展,从而创建了埃及灿烂的史前文明。 好~~从上面那个故事我们看到了 1、时间序列的定义——按照时间的顺序把随机事件变化发展的过程记录下来就构成了一个时间序列。 2、时间序列分析的定义——对时间序列进行观察、研究,找寻它变化发展的规律,预测它将来的走势就是时间序列分析。 既然有了序列,那怎么拿来分析呢? 时间序列分析方法分为描述性时序分析和统计时序分析。 1、描述性时序分析——通过直观的数据比较或绘图观测,寻找序列中蕴含的发展规律,这种分析方法就称为描述性时序分析 描述性时序分析方法具有操作简单、直观有效的特点,它通常是人们进行统计时序分析的第一步。 现代信号处理学号: 小组组长: 小组成员及分工: 任课教师: 教师所在学院:信息工程学院2015年11月 论文题目 基于奇异值分解的MVDR方法及其在信号频率估计领域的 应用 摘要:本文主要是介绍和验证MVDR的算法,此算法应用于信号频率估计的领域中。我们通过使用经典的MVDR算法验证算法的可行性,再通过引用了奇异值分解的思想对MVDR方法进行了改进,在验证这种改进思想的方法可行性时,我们发现基于这种奇异值分解的MVDR方法在信号频率估计上具有提高检测精度的特性,这也说明了这种思想在应用信号频率估计时是可行的。 关键词:MVDR算法奇异值分解信号频率估计 论文题目(English) MVDR method based on singular value decomposition and its application in signal frequency estimation Abstract:In this paper, the algorithm of MVDR is introduced, and the algorithm is applied to the field of signal frequency estimation. By using the classical MVDR algorithm to verify the feasibility of the algorithm, and then through the use of the idea of singular value decomposition to improve the MVDR method, in the verification of the feasibility of the method, we found that the MVDR method based on the singular value decomposition has the characteristics of improving the detection accuracy in signal frequency estimation. It also shows that this idea is feasible in the application of signal frequency estimation. Key words: MVDR method Singular value decomposition Signal frequency estimation 《时间序列分析》 课程设计报告 学院 专业 姓名 学号 评语: 分数 二○一二年十一月 目录 1.平稳序列分析(选用数据:国内工业同比增长率)-------------------------3 1.1 序列分析--------------------------------------------------------------3 1.2 附录(程序代码)------------------------------------------------------7 2.非平稳序列分析I(选用数据:国家财政预算支出)-------------------------8 2.1 使用ARIMA进行拟合-------------------------------------------------8 2.2 使用残差自回归进行拟合---------------------------------------------11 2.3 附录(程序代码)-----------------------------------------------------12 3.非平稳序列分析II(选用数据:美国月度进出口额)------------------------13 3.1序列分析--------------------------------------------------------------13 3.2附录(程序代码)------------------------------------------------------18 一、平稳序列分析(选用数据:国内工业同比增长率,2005年01月-2012年5月)绘制时序图 rate 22 21 20 19 18 17 16 15 14 13 12 11 10 9 8 7 6 5 01JAN0501JUL0501JAN0601JUL0601JAN0701JUL0701JAN0801JUL0801JAN0901JUL0901JAN1001JUL1001JAN1101JUL1101JAN1201JUL12 time 图1-1 国内工业月度同比增长率序列时序图 的趋势以及周期性,波动稳定,可以初步判定为平稳序列。下面进一步考察序列的自相关图。 图1-2 国内工业月度同比增长率序列的样本自相关图 认为该序列平稳。下面对序列进行白噪声检验。 时间序列分析作业 1、数据收集 通过长江证券金长江网上交易软件收集中信证券(600030)股价数据(2010-7-1~2011-5-9,共200组),保存文件,命名为“股价数据”。 2、工作表建立 打开eviews,点击file下拉菜单中的new项选择workfile项,弹出窗口如下: (1)、在datespecification中选择integer date。 (2)、在start和end中分别输入“1”“200” (3)、在wf项后面的框中输入工作表名称hr,点击ok。 窗口如下: 3、数据导入 在hr工作文件的菜单选项中选择pro,在弹出的下拉菜单中选择import,然后再下拉二级菜单中选择read text-lotus-excell,找到数据,双击弹出如下对话框: 默认date order,选择右边upper-left data cell下面的空格填写,输入excel中第一个有效数据单元格地址B6,在names for series or number if named in file 中输入序列名称,不妨设为s,点击ok,导入数据。 4、平稳性检验 点击s序列,选择菜单view/correlogram,弹出correlogram specification对话框,如下图,在对话框中默认level,lags to include 改为20(200/10),可得下图: 序列的自相关系数没有很快的趋近0,说明原序列是非平稳的序列。 5、对原序列做对数差分处理 A、在主窗口输入smpl 2 200,对样本数据进行选取, B、在主命令窗口输入series is=log(s)-log(s(-1)) 可以得到新的序列is 对is序列做同上的平稳性检验可以得到如下图: 时间序列分析法原理及步骤 ----目标变量随决策变量随时间序列变化系统 一、认识时间序列变动特征 认识时间序列所具有的变动特征, 以便在系统预测时选择采用不同的方法 1》随机性:均匀分布、无规则分布,可能符合某统计分布(用因变量的散点图和直方图及其包含的正态分布检验随机性, 大多服从正态分布 2》平稳性:样本序列的自相关函数在某一固定水平线附近摆动, 即方差和数学期望稳定为常数 识别序列特征可利用函数 ACF :其中是的 k 阶自 协方差,且 平稳过程的自相关系数和偏自相关系数都会以某种方式衰减趋于 0, 前者测度当前序列与先前序列之间简单和常规的相关程度, 后者是在控制其它先前序列的影响后,测度当前序列与某一先前序列之间的相关程度。实际上, 预测模型大都难以满足这些条件, 现实的经济、金融、商业等序列都是非稳定的,但通过数据处理可以变换为平稳的。 二、选择模型形式和参数检验 1》自回归 AR(p模型 模型意义仅通过时间序列变量的自身历史观测值来反映有关因素对预测目标的影响和作用,不受模型变量互相独立的假设条件约束,所构成的模型可以消除普通回归预测方法中由于自变量选择、多重共线性的比你更造成的困难用 PACF 函数判别 (从 p 阶开始的所有偏自相关系数均为 0 2》移动平均 MA(q模型 识别条件 平稳时间序列的偏相关系数和自相关系数均不截尾,但较快收敛到 0, 则该时间序列可能是 ARMA(p,q模型。实际问题中,多数要用此模型。因此建模解模的主要工作时求解 p,q 和φ、θ的值,检验和的值。 模型阶数 实际应用中 p,q 一般不超过 2. 3》自回归综合移动平均 ARIMA(p,d,q模型 模型含义 模型形式类似 ARMA(p,q模型, 但数据必须经过特殊处理。特别当线性时间序列非平稳时,不能直接利用 ARMA(p,q模型,但可以利用有限阶差分使非平稳时间序列平稳化,实际应用中 d (差分次数一般不超过 2. 模型识别 平稳时间序列的偏相关系数和自相关系数均不截尾,且缓慢衰减收敛,则该时间序列可能是 ARIMA(p,d,q模型。若时间序列存在周期性波动, 则可按时间周期进 现代佶号处理学号: 小组组长: 小组成员及分工: 任课教师: 教师所疫学院:信息工程学院 2015年11月 基于奇畀值分鮮的MVDR方法及其在信号频率估计领城的 应用 摘要:本丈主要是介绍和验证MVDR的算出,此算岀应用于信号频率估计的领城中。我们通过使用经典的MVDR算去验证算比的可行性,再通过引用了奇异值分解的思想对MVDR方法进行了孜进,准.脸证这种改进思想的方法可行性肘,我们发现基于这种奇异值分鮮的MVDR 方岀在信号频率估计上具有提壽检测赫度的特性,这色说朗了这种思想>4应用信号频率估计肘是可行的。 论丈题tl (English丿 MVDR method based on singular value decomposition and its application in signal frequency estimation Abstract:In this paper, the algorithm of MVDR is introduced, and the algorithm is applied to the field of signal frequency estimation. By using the classical MVDR algorithm to verify the feasibility of the algorithm, and then through the use of the idea of singular value decomposition to improve the MVDR method, in the verification of the feasibility of the method, we found that the MVDR method based on the singular value decomposition has the characteristics of improving the detection accuracy in signal frequency estimation. It also shows that this idea is feasible in the application of signal frequency estimation. Key words:MVDR method Singular value decomposition Signal frequency estimatio n 实验一ARMA模型建模 一、实验目的 学会检验序列平稳性、随机性。学会分析时序图与自相关图。学会利用最小二乘法等方法对ARMA模型进行估计,以及掌握利用ARMA模型进行预测的方法。学会运用Eviews软件进行ARMA模型的识别、诊断、估计和预测和相关具体操作。 二、基本概念 1平稳时间序列: 定义:时间序列{zt}是平稳的。如果{zt}有有穷的二阶中心矩,而且满足: (a) ut= Ezt =c; (b) r (t, s) = E[(zt~c) (zs-c)] = r (t~s, 0) 则称{zt}是平稳的。 2AR模型: AR模型也称为自回归模型。它的预测方式是通过过去的观测值和现在的F扰值的线性组合预测。具有如下结构的模型称为P阶自回归模型,简记为AR(P)。 氓=% +忖“ + @耳-2 +…+忙耳“ + S t 忙工0 = 0, Var{s t) =(7;, E{s z£s) = 0, s H 上 Ex s s t = 0, Vs < t 3MA模型: MA模型也称为滑动平均模型。它的预测方式是通过过去的干扰值和现在的干扰值的线性组合预测。具有如下结构的模型称为Q阶移动平均回归模型,简记为MA (q) o 兀二“ +吕—叽-&耳2_???-恥r 七H0 E(£)= 0, Var(£t) =(j~,= 0,sH7 4ARMA模型: ARMA模型:自回归模型和滑动平均模型的组合,便构成了用于描述平稳随机过程的自回归滑动平均模型ARMA。具有如下结构的模型称为自回归移动平均回归模型,简记为ARMA(p,q)° x< = 00 + 欣-1 + …++ 6 —一…一臥 7 0, H 0, Q H 0 E(s t) = 0, Var{s t) = crj, E(8t£s) = 0, s H r E XS T = 0, Vs < t ?O' 三、实验内容及要求 1实验内容: (1)根据时序图判断序列的平稳性; (2)观察相关图,初步确定移动平均阶数q和自回归阶数P: 2实验要求: (1)深刻理解平稳性的要求以及ARMA模型的建模思想; (2)如何通过观察自相关,偏自相关系数及苴图形,利用最小二乘法,以及信息准则建立合适的ARMA模型;如何利用ARMA模型进行预测: (3)熟练掌握相关Eviews操作,读懂模型参数估il?结果。 四、实验指导 1数据录入 首先用命令series x = nrnd生成一个500个白噪声序列。然后利用excel生成一个平稳序 列如图1所示,其中设定方程为X(t) = -0?5*X(t-l)+0? 4*X(t-2)+£ (t)o Series: Y Workfile: RAN::Untitled\ View Proc Object Properties Print Name Freeze Defeult v Sort Edi Last updated: 12/21/12-21:52 1 3.871776 2 2.721548 3 ?0.394538 4 1.771239 5 -0.557231 6 1.037903 7 0.139982 80.723313 9 1.959045 10 -0.098984 11 2.150510 1 2绘制序列时序图 双击打开series y ?选择View—Graph—Line & Symbol。得到的时序图如下所示: 《时间序列分析》试卷 注意:请将答案直接写在试卷上 一、填空题(1分*20空=20分) 1. 德国药剂师、业余天文学家施瓦尔发现太阳黑子的活动具有 11年周期依靠的是 时序分析方法。 2. 时间序列预处理包括 和 。 3. 平稳时间序列有两种定义,根据限制条件的严格程度,分为 和 。使用序列的特征统计量来定义的平稳性属于 。 4. 统计时序分析方法分为 和 。 5. 为了判断一个平稳的序列中是否含有信息,即是否可以继续分析,需对该序 列进行 检验,该检验用到的统计量服从 分布;原假设和备择假设分别是 和 。 6. 图1为2000年1月——2007年12月中国社会消费品零售总额时间序列图, 据此判断,该序列{}t X 是否平稳(填“是”或 者“否”) ;要使其平稳化,应该对原序列进行 和 差分处理。用Eviews 软件对该序列做差分运算的表达式是 。 7. ARIMA 模型的实质 是和 的结合。 8. 差分运算的实质是使用的 方式提取确定性信息。 9. 用延迟算子表示中心化的AR(P)模型是 。 二、不定项选择题(下列每小题至少有一个答案是正确的,请将正确答 班级 姓名 学号 500 1000150020002500300035004000 93 94 95 96 97 98 99 00 图1 案代码填入相应括号内,2分*5题=10分) 1.下列属于白噪声序列{}t ε所满足的条件的是( ) A. 任取T t ∈,有με=)(t E (μ为常数) B. 任取T t ∈,有0)(=t E ε C.)(0),(s t Cov s t ≠?=εε D. 2 )(εσε=t Var (2 εσ为常数) 2.使用n 期中心移动平均法对序列{}t x 进行平滑时,下列表达式正确的是( ) A.n x x x x x n x n t n t t n t n t t ),(1 ~ 211211212 1-+--++----++++++=ΛΛ为奇数; B. n x x x x x n x n t n t t n t n t t ),(1 ~ 2 12122 +-++--++++++=ΛΛ为偶数; C. )(1 ~11+--+++= n t t t t x x x n x Λ; D. n x x x x x n x n t n t t n t n t t ),21 21(1~ 212 122+-++--++++++=ΛΛ为偶数。 3.关于延迟算子的性质,下列表示中正确的有 ( ) A.10=B B.n t t n x x B -= C.∑=-= -n i n i n n n B C B 0 ) 1()1( D.对任意两个序列{}t x 和{}t y ,有11)(--+=+t t t t y x y x B 4.下列选项不属于平稳时间序列的统计性质的是 ( ) A.均值为常数 B 均值为零 C.方差为常数 D.自协方差函数和自相关系数只依赖于时间的平移长度,而与时间的起止点无关。 5.ARMA 模型平稳性条件是() A.0=Φt x B )(的特征根都在单位圆内; B. 0=Φt x B )(的根都在单位圆内; C.0=Θt B ε)(的特征根都在单位圆内; D. 0=Φ)(B 的根都在单位圆外。 三、判断并说明理由(10分) 1.模型的有效性检验是指检验模型能否能够有效地提取序列中的信息,即对残差进行平稳性检验。 2.ARIMA (p,d,q )模型具有方差齐次性。 四、简答题:(第1小题15分,第2小题5分,本题共20分) 时间序列分析预测法有两个特点: ①时间序列分析预测法是根据市场过去的变化趋势预测未来的发展,它的前提是假定事物的过去会同样延续到未来。事物的现实是历史发展的结果,而事物的未来又是现实的延伸,事物的过去和未来是有联系的。市场预测的时间序列分析法,正是根据客观事物发展的这种连续规律性,运用过去的历史数据,通过统计分析,进一步推测市场未来的发展趋势。市场预测中,事物的过去会同样延续到未来,其意思是说,市场未来不会发生突然跳跃式变化,而是渐进变化的。 时间序列分析预测法的哲学依据,是唯物辩证法中的基本观点,即认为一切事物都是发展变化的,事物的发展变化在时间上具有连续性,市场现象也是这样。市场现象过去和现在的发展变化规律和发展水平,会影响到市场现象未来的发展变化规律和规模水平;市场现象未来的变化规律和水平,是市场现象过去和现在变化规律和发展水平的结果。 需要指出,由于事物的发展不仅有连续性的特点,而且又是复杂多样的。因此,在应用时间序列分析法进行市场预测时应注意市场现象未来发展变化规律和发展水平,不一定与其历史和现在的发展变化规律完全一致。随着市场现象的发展,它还会出现一些新的特点。因此,在时间序列分析预测中,决不能机械地按市场现象过去和现在的规律向外延伸。必须要研究分析市场现象变化的新特点,新表现,并且将这些新特点和新表现充分考虑在预测值内。这样才能对市场现象做出既延续其历史变化规律,又符合其现实表现的可靠的预测结果。 ②时间序列分析预测法突出了时间因素在预测中的作用,暂不考虑外界具体因素的影响。时间序列在时间序列分析预测法处于核心位置,没有时间序列,就没有这一方法的存在。虽然,预测对象的发展变化是受很多因素影响的。但是,运用时间序列分析进行量的预测,实际上将所有的影响因素归结到时间这一因素上,只承认所有影响因素的综合作用,并在未来对预测对象仍然起作用,并未去分析探讨预测对象和影响因素之间的因果关系。因此,为了求得能反映市场未来发展变化的精确预测值,在运用时间序列分析法进行预测时,必须将量的分析方法和质的分析方法结合起来,从质的方面充分研究各种因素与市场的关系,在充分分析研究影响市场变化的各种因素的基础上确定预测值。 需要指出的是,时间序列预测法因突出时间序列暂不考虑外界因素影响,因而存在着预测误差的缺陷,当遇到外界发生较大变化,往往会有较大偏差,时间序列预测法对于中短期预测的效果要比长期预测的效果好。因为客观事物,尤其是经济现象,在一个较长时间内发生外界因素变化的可能性加大,它们对市场经济现象必定要产生重大影响。如果出现这种情况,进行预测时,只考虑时间因素不考虑外界因素对预测对象的影响,其预测结果就会与实际状况严重不符。 时间序列分解算法和d ecompose函数实现 李思亮 55531469@https://www.360docs.net/doc/759896607.html, 目录 时间序列分解算法和decompose函数实现 (1) 1 数据读入并生成时间序列 (2) 2 数据可视化 (4) 3 时间序列分解 (7) 在时间序列分析的过程中,往往需要对时间序列作出初步分析,本文主要采用R语言作为分析平台,从数据的读入,可视化图,分解(decompose)为趋势项,季节项,随机波动等角度对数据开展分析的几个案例。最后对分解算法作出初步描述并探讨其预测预报中的潜在应用。本文的数据和部分内容主要采用https://www.360docs.net/doc/759896607.html,/en/latest/中的内容,感兴趣的读者可以参考。 1 数据读入并生成时间序列 对于数据分析来讲,数据读入是一个比较关键的步骤。常用的数据读入函数有scan,read.table 等。下面列举了几种常见的数据。 首先是https://www.360docs.net/doc/759896607.html,/tsdldata/misc/kings.dat,中包含了英国国王的寿命从William开始,数据来源(Hipel and Mcleod, 1994)。 > kings <- scan("https://www.360docs.net/doc/759896607.html,/tsdldata/misc/kings.dat",skip=3) Read 42 items > kings [1] 60 43 67 50 56 42 50 65 68 43 65 34 47 34 49 41 13 35 53 56 16 43 69 59 48 59 86 55 68 51 33 49 67 77 81 67 71 81 68 70 77 56 上述例子中,读入了连续42个公国国王的寿命并将其赋给变量‘kings’ 如果我们希望对读入数据开展分析,下一步就是将其转化为时间序列对象(时间序列类),R提供了很多函数用于分析时间序列类数据。可以使用ts函数将变量转化为时间序列类。 > kingsts <- ts(kings) > kingsts Time Series: Start = 1 End = 42 Frequency = 1 [1] 60 43 67 50 56 42 50 65 68 43 65 34 47 34 49 41 13 35 53 56 16 43 69 59 48 59 86 55 68 51 33 49 67 77 81 67 71 81 68 70 77 56 对于上述数据操作的好处是将数据转化为特定的“时间序列类”便于我们使用R中的函数分析数据。 有时候我们会按照一定的时间周期来收集数据,这个周期可能是季度,月,日,小时,分。在大数据时代,有些情况下的数据是按照秒来采集收集。这种情况下,我们需要对数据的周期或频率进行设置。这里采用ts函数中的frequency参数可以实现这种功能。比方说,若按1年为一个周期,我们的月度时间(完整word版)时间序列分析考试卷及答案
基于奇异值分解的MVDR谱估计
多元时间序列建模分析(DOC)
(完整word版)时间序列分析考试卷及答案 (2)
时间序列分析——最经典的
基于奇异值分解的MVDR谱估计
时间序列分析课程设计(最终版)
时间序列分析作业.doc
时间序列分析法原理及步骤
基于奇异值分解的MVDR谱估计
eviews时间序列分析实验Word版
(完整word版)《时间序列》试卷
时间序列分析法缺点
时间序列分解Decompose