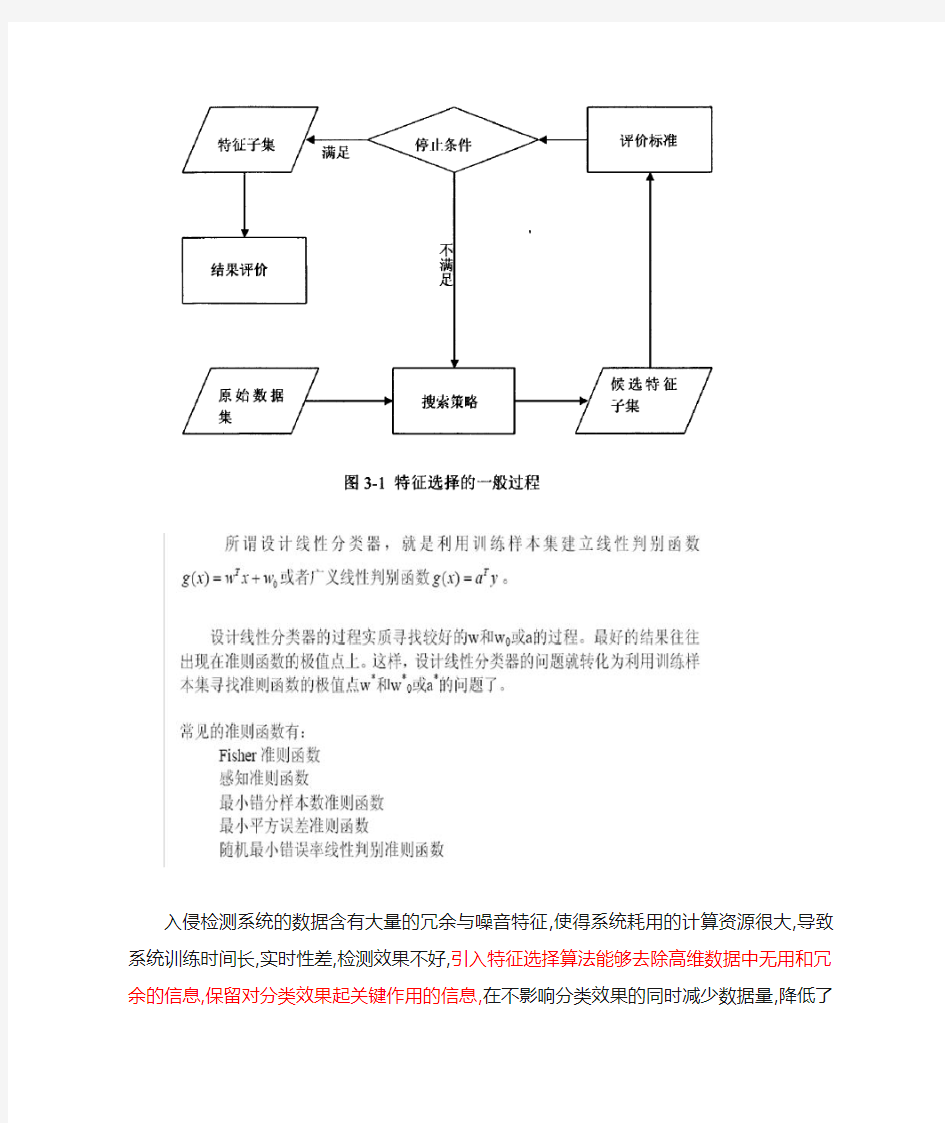
有关特征选择内容

特征选择和集成学习是当前机器学习中的两大研究热点,其研究成果己被广泛地应用于提高单个学习器的泛化能力。
特征选择是指从原始特征集中选择使某种评估标准最优的特征子集。其目的是根据一些准则选出最小的特征子集,使得任务如分类、回归等达到和特征选择前近似甚至更好的效果。通过特征选择,一些和任务无关或者冗余的特征被删除,简化的数据集常常会得到更精确的模型,也更容易理解。
滤波式(filter)方法的特征评估标准直接由数据集求得,而无需学习算法进行反馈,其优点是运行效率高,因此非常适用于集成学习.假设用于集成的特征选择算法有k种,,抽取产生m 个子训练集,在每个训练集上利用其中一种特征选择算法选出满足条件的属性作为个体svm训练的输入空间,并训练得到m个svm个体,然后对其他的特征选择算法重复执行上述过程,最后将得到的k*m 个子svm的预测结果集成.
特征选择是从一组数量为D 的原始特征中选出数量为d(D>d)的一组最优特征采用遗传退火算法进行特征选择.随机生成长度为
D 的二进制串个体其中1 的个数为d 。连续产生这样的个体M 个M 为种群规模其大小影响着遗传算法的最终结果及其执行效率M。
特征选择的目的是找出分类能力最强的特征组合需要一个定量准则来度量特征组合的分类能力。度量特征选择算法优劣的判据很多各样本之所以能分开是因为它们位于特征空间的不同区域如果类间
距离越大类内各样本间的距离越小则分类效果越好。
各种新搜索算法和评估标准都应用到特征选择算法中。如粗糙集算法,神经网络剪枝法,支持向量机的评估标准,特征集的模糊嫡评价,马尔可夫算法等
入侵检测系统的数据含有大量的冗余与噪音特征,使得系统耗用的计算资源很大,导致系统训练时间长,实时性差,检测效果不好,引入特征选择算法能够去除高维数据中无用和冗余的信息,保留对分类效果起关键作用的信息,在不影响分类效果的同时减少数据量,降低了数据存储复杂度,减轻系统负荷,提高入侵检测系统的检测速度,增强入侵检测系统的健壮性。
入侵检测问题从机器学习的角度看实际上是一个分类问题,分类器的性能不仅与分类器设计算法有关,而且与选择的特征子集有关。一个高度相关的特征子集可有效改进分类器的性能,因而特征选择(属性约简)具有重要的理论意义和应用价值。
集成学习(Ensemble Learning)是通过将一组学习器以某种方式组合在一起可以显著提高学习系统的泛化能力(有监督的分类器集成和半监督的分类器集成)。
神经网络集成可以显著地提高神经网络系统的泛化能力,被视为
一种非常有效的工程化神经计算方法。然而,实际应用中集成系统的个体弱学习器成员可以是任何学习算法,如最近邻法、贝叶斯方法、神经网络及支持向量机等。从这点上讲,可以说集成学习只是提供了一个广义的框架,针对具体的机器学习问题需要设计具体的集成学习模型。
基于遗传算法的特征选择算法中一般选择适配值最高的个体作为特征选择的结果,而抛弃了其他个体。我们设想,是否其他个体也会提供有用的信息,如果在不同的个体(即特征子集)上训练得到不同的个体分类器,然后将这些分类器组合起来,是否会得到很好的集成分类结果。
机器学习中的特征选择可定义为:己知一个特征集,从中选择一个子集可以使得评价标准最优。
从特征选择的定义可见,在给定学习算法、数据集及特征集的前提下,各种评价准则的定义和优化技术的应用将构成特征选择的重要内容。
特征选择作为应用于数据挖掘中消除数据噪声的一种技术,也作为根据某一准则从原有的特征中选择出最优的特征组合实现对数据进行预处理的一种常用手段。选出与结果最相关的特征,排除不相关或者冗余的特征,从而提高判断的准确率。
本文运用以具有良好泛化能力的支持向量机的特征选择和集成分类器新技术,在支持向量机分类的基础上,以特征选择和基于特征选择的集成学习方法为主要研究内容,以影响支持向量机性能的主要因素为研究对象,对正则化参数C和核函数参数的选择进行了较深入的研究,并通过对多个成员分类器结果的集成,以进一步提高对数据挖掘的学习泛化能力。
在遗传算法优化特征子集的同时,把支持向量机参数混编入遗传算法的遗传假设中,从而实现同步优化特征子集和支持向量机参数。
集成学习就是利用有限个学习器对同一个问题进行学习,某样本的输入的输出值是由构成集成的各学习器共同决定的。
集成学习方法是通过训练大量的基学习器,然后按照一定的标准
选择一部分基分类器进行集成,最终能获得较好的分类效果。
使用特征选择对数据进行预处理。采用主成分分析法先对数据进行预处理。
由于特征子集大小变化幅度很大,我们可以根据特征子集大小使用不同的搜索策略来搜索特征空间。目前,搜索策略大致分为3种:完全搜索,启发性搜索和随机搜索。完全搜索就是在事先知道特征子集大小的情况下,能够找到相对较好的特征子集。启发性搜索在搜索特征空间的时候根据启发性信息沿着一条特殊的路径处理数据,最后能够得到近似最优解。随机搜索:该方法首先随机产生一个待评价的子集,然后要求新产生的子集要在维度、准确性方面都要比当前的子集有所提高
Relief算法借用了最近邻学习算法的思想,其是根据特征对近距离样本的区分能力来评估特征,其核心思想为:一个好的特征应该使同类的样本接近,而使不同类的样本之间远离。可以对每个特征进行排序,好的特征赋予较大的权值,表示该特征的分类能力较强,反之,表示分类能力较弱。
Relief特征选择支持向量机Bagging集成学习和基于预报风险的特征选择支持向量机Bagging集成学习。它们均采用同时对输入特征空间和支持向量机的模型参数进行扰动的方式来产生个体分类器,并利用多数投票方法对它们进行组合。基于多个数据集的数值实验结果表明,这两种算法均能够显著提升SVM的泛化性能,均显著地优于Bagging、Boostin只等集成学习算法。
因Relief仅局限于解决两类的分类问题。ReliefF则可以解决多类问题以及回归问题,并补充了对缺失数据的处理办法。当有数据缺失时,如果缺失的属性为连续型夕则用该特征的平均值代替。如果缺失的属性为离散型,则用该特征中出现频率最高的值代替。
Relief法是一种特征权重算法(Feature weighting algorithms),根据各个特征和类别相关性赋给每个特征不同的权重,权重小于某个闭值的特征将被删去。Relief算法特征和类别的相关性是基于特征对近距
离样本的区分能力。
根据样本是否含有类别信息,特征选择可分为非监督的特征选择和有监督的特征选择。非监督的特征选择:指在数据集中,通过数据集中特征自身之间的关系进行特征选择的方式。有监督的特征选择:指在给定类别的前提下,利用特征之间和特征与类别之间的关系对特征集进行选择的过程。
当使用支持向量机作为分类器时,就必须考虑支持向量机的参数问题。核函数间接的描述了支持向量机的高维特征空间,参数C用来平衡模型复杂度和经验风险值。
本章通过把支持向量机参数引入到遗传算法中,构造出了基于遗传算法的模型参数自适应优化算法。
本文把参数的选择和特征选择同时进行,即在选择特征的同时找出与其对应的参数最优点。
如在支持向量分类机中,可以通过改变核函数或者核函数参数建立不同的成员分类器。提出了一种对样本先进行优化特征子集预处理,再加入支持向量机参数进行优化分类。
数据挖掘中的特征选择不仅可以去除特征集合中冗余的无关的特征信息,提高原始数据的质量,使得数据挖掘可以从数据中得到更有价值的信息,同时大大降低了数据挖掘的计算成本和获取冗余信息所耗费的成本。SVM作为基学习器。利用主成份分析法减少冗余特
征,并在此基础上结合集成方法进行学习。
支持向量机是在统计学习理论基础上提出的,利用结构风险最小化的原则建立目标函数,通过二次凸规划来解决,得到最优解,具有良好的泛化能力。它本质上是求解一个凸优化问题
其中bagging 和boosting 是目前比较流行的两种集成学习方法。
提高个体分类器的精度,增加个体分类器间的差异,可以有效的提高集成学习的泛化性能。特征选择可以提高分类器精度并增加个体分类器差异,扰动支持向量机的模型参数,也可以增加个体分类器的差异性。Relief过滤式特征选择算法和基于预报风险的嵌入式特征选择算法两种特征选择方法参与集成学习的研究,并在支持向量机的低偏差区域内随机的选取支持向量机的模型参数,提出了两种基于特征选择的低偏差的支持向量机Bagging集成学习算法。
机器学习的目的是设计某种方法,通过对己知数据的学习,找到数据内在的相互依赖关系,从而对未知数据预测和对其性能进行判断.
机器学习的目的是根据给定的训练样本来估计某系统的输入和输出之间的依赖关系,使它能够对未知输入尽可能准确的预测。
统计学习理论(STL)。
集成后的学习器比任何一个个体学习器有更高的精度的充要条件是:个体学习器有较高的精度并且个体学习器是互不相同的。其中,个体学习器有较高精度是指对一个新的数据进行函数逼近或分类,它的误差比随机猜测要好。两个个体学习器互不相同是指对于新的样本点进行预测或分类时,它们的错误是不相关。
Bagging方法中,各学习器的训练集由从原始训练集中随机选取若干样本组成,训练集的规模通常与原始训练集相当,训练样本允许重复选取。Bagging方法通过重新选取训练集增加了集成学习的差异度,从而提高了系统的泛化能力。
Boosting方法特别是其中的Adaboost(ad叩tiveboosting)算法,通过迭代生成多个训练集,每次迭代都增加一个新的分类器到集成中,该分类器使用的训练样本根据一个分布或权值有放回地原数据集中选择,然后修改样本的分布或权值,使得前一次分类器错分的样本获得更大的权值,这样后来的基分类器可更关注难于分类的样本。对基分类器的输出通常采用加权投票组合。Adaboost算法随着迭代增进训练误差下降。Adaboost算法后来有很多变种,如Adaboosting.MI、Adaboosting.MZ和Adaboosting.R。Boosting方法能够增强集成学习的泛化能力,但是同时也有可能使算法过分偏向于某几个特别困
难的示例,该算法对噪声比较敏感。
交叉验证法将训练集分成若干个不相交的子集,每次去掉一个子集,而将其余子集组合成为一个新的训练集。这样,新的训练集之间是部分重叠的。
纠错输出编码(error correcting output coding , Ecoc)
并指出了两个方向:利用支持向量机的偏差特性,采用低偏差支持向量机作为基分类器;或者,利用偏差与方差对核参数的依赖性,通过偏差与方差分析构建低偏差异类分类器集成.
支持向量机的模型参数一般有两个:核参数和惩罚参数C.
Relief特征选择是指从原始特征集中选择按照一定评估标准最优的特征子集,一方面它可以去除无关特征、冗余特征、甚至噪声特征,得到一个较小的特征子集,提高学习算法的性能和运行效率,提高个体学习器的泛化能力,另一方面可以增强个体学习器的差异度,从而提高集成学习的效果。在低偏差区域内随机选择支持向量机的核参数和惩罚参数从另一方面增加了个体学习器的差异度,从而也可以提高集成学习的性能。
集成学习一般包含两个阶段,即个体分类器的生成阶段和个体分类器的结合阶段。本文方法在个体分类器的生成阶段采用的策略是:先在训练集上产生多个分类器,再在验证集上测试,并从中选择部分分类器。
集成学习通过训练多个个体学习器并将其结果进行合成,显著地提高了学习系统的泛化能力。选择性集成方法从集成系统中选择出部
分个体参与集成。
集成学习的根本目的是为了提升学习算法的性能。它是将多个不同的基模型组合成一个模型的学习方法,利用多个基模型间的差异来提高模型的泛化性能。
支持向量机作为一种相对“稳定”和“高精度”的学习机,对集成学习技术提出了新的挑战。
1.个体生成方法
如何产生有差异的个体是集成学习的关键问题,现有的支持向量机集成中的个体生成方法主要通过扰动训练样本集、扰动特征空间、扰动模型参数以及多重扰动机制的结合来实现的。
研究类别数目不均的支持向量机集成,其训练样本的扰动是将大样本的负类样本分成K等分,与小样本的正类样本合成一个训练样本集,在其上训练生成一个个体支持向量机分类器,一共得到K个个体支持向量机,最后用多数投票法进行集成。
为克服不均匀样本数据对支持向量机性能的影响,提出在样本数目远大于正类样本的负类上进行样本重取样工作,取得与正类样本数目相当的负类样本,并与正类样本一起组成训练样本集合。
2. 结论合成方法
结论合成方法主要研究如何对集成中个体分类器所给出的结论进行合成。在对支持向量机的结论进行合成时,目前主要采用的方法有以下几种:
第一,全部生成的个体支持向量机都参与集成的投票法,主要包括
多数投票法和加权投票法:
(l)多数投票法(Majority voting),每个个体支持向量机分类器对于待测样本x有一个类别的判断,并给所判断的待测样本二的归属拳别投一票。
(2)加权投票法,是给每一个个体支持向量机分类器赋予一个权值,权值的获取通常是通过在训练样本集上的分类器的精度获得,精度越高,权值越大,反之,精度越小,权值越小。
第二,从集成中选择出部分个体支持向量机的选择性集成学习算法。
第三,利用支持向量机后验概率输出信息的度量层支持向量机集成学习算法。
针对个体生成方法的研究主要考虑如何提高支持向量机集成中个体的精度和集成差异度。针对结论合成方法的研究主要考虑如何对集成系统中各个体支持向量机给出的结论进行合成。
支持向量机分类器。学习的目标就是构造一个决策函数,将测试数据尽可能正确地分类。分类的目的就是找到一个超平面将这两类样本完全分开。针对训练样本为线性或者非线性两种情况。如果训练样本可以被无误差地分开,并且每一类数据与超平面距离最近的向量与超平面之间的距离最大,则称这个超平面为最优超平面。
目前影响支持向量机性能的因素主要有:(l)支持向量机的求解方法;(2)核函数类型选取、核函数参数及惩罚参数值的选取;(3)支持向量机从二类分类到多类分类的推广。核函数参数、误差惩罚参数统称为
支持向量机的超参数。核函数类别选择、超参数选择统称为支持向量机的模型选择问题。目前核函数参数及惩罚参数的选择主要有参数空间穷举法(又称枚举法、网格搜索法)、梯度下降法和核校准方法。
可能近似正确学习模型PAC(Probably Approximately Correct)。
神经网络集成是用有限个神经网络对同一个问题进行学习,集成在某输入示例下的输出由构成集成的各神经网络在该示例下的输出共同决定。
集成学习(Ensemble Learning)是用有限个学习器对同一个问题进行学习,集成在某输入示例下的输出由构成集成的各学习器在该示例下的输出共同决定。个体学习器可以是任意回归模型或分类器。
1)个体生成方法的研究,主要研究如何生成集成中的个体分类器;2)结论合成方法的研究,主要研究怎样将多个个体分类器的结论进行合成。
1.个体生成方法
为生成具有一定差异性的个体,如何构造集成中的个体分类器对集成的性能有重大影响,目前的方法主要有:
(l)扰动训练样本分布
通过划分训练样本集合产生多个训练样本子集,学习算法分别在这些训练样本子集上进行训练,生成多个个体分类器。
(2)扰动特征空间
该类方法把输入特征空间划分为多个特征子集,在不同特征子集上投影得到的训练样本用于训练生成多个个体分类器。如何有效地生
成特征子集是基于特征划分方法需要解决的核心问题。
(3)扰动分类器的输出类别
即对分类器的输出类标进行处理,每个个体分类器将一类与其它类分开。
(4)扰动分类器的模型参数
一般的分类器都有自己特定的模型参数。通过扰动这些参数可以产生具有一定差异的个体分类器。
(5)随机设置初始权值
对同一训练样本赋予不同初始权值,使构成集成中的个体学习器的分类结果不同。
(6)多重扰动机制的合成
即通过将上述某两种或几种扰动方式合成的方式来产生有差异的个体。
2.结论合成方法
(l)从集成中个体的输出形式来看,结论合成方法可以分为三类:
l)决策层合成,即个体分类器的输出为某个确定的类标号。其中多数投票法是最简单和应用最广泛的合成方法,它只利用个体分类器对给定测试样本的输出类别,将该测试样本划分到多数分类器具有相同决策的一类,不需要任何训练;而Bayes规则和BKS方法都需要进行合成训练,通常把训练数据集划分为三个部分:个体分类器的训练集u1、结论合成方法训练集u2、合成方法测试集u3。结论合成方法训练集u2用来统计在运用合成规则时需要的一些参量。其中,Bayes规则要
统计的是混淆矩阵;BKS方法要统计每一类样本落在行为知识空间各单元的个数。决策层合成是目前应用最广泛、研究较早和较充分的一类结论合成方法。
2)排序层合成,即个体分类器的输出为给定测试样本属于各类的可能性的一个排序列表.
3) 度量层合成,即个体分类器输出为待测样本属于各类的后验概率.
(2)从参与集成的个体与集成系统的关系来看,集成可以分为全体集
成和选择性集成。
1)全体集成指的是集成系统中生成的所有个体都参与结论的合成:
2)选择性集成指的是从集成系统中选择出部分个体参与集成.
(3)从集成中个体在集成决策系统中所起的作用来分,可以分为静态集成和动态集成,所谓的静态集成和动态集成主要体现在集成中个体在进行结论合成时的权值上。
1)静态集成指的是在进行加权合成时,各个体的权值对所有的测试样本都相同,其权值体现的是个体在训练样本上的全局性能;
2)动态集成指的是在进行加权合成时,各个体的权值是根据该个体分类器对待测样本的局部分类性能动态确定的,体现的是个体分类器相对于待测样本的局部性能。
(4)从集成中个体分类器是否同质来分,可分为同构集成和异构集成。
l)同构集成指的是集成系统中个体分类器的生成都是来自同一类
型的分类器,比如都是神经网络、决策树、支持向量机等.
2)异构集成指的是集成系统组合了不同类型的分类器如神经网络、支持向量机、决策树、KNN等.
基于参数扰动的支持向量机集成学习算法,目的在于通过选取不同的参数以提高个体支持向量机分类器之间的差异,经典的基于参数扰动的支持向量机集成算法根据支持向量机核参数、惩罚参数对支持向量机性能的影响,通过扰动支持向量机的核函数参数值和惩罚参数值达到提高集成差异度的目的。
惩罚参数C表示对错误分类的惩罚,实现在错分样本的比例和算法的复杂度之间的折中。即在确定的特征子空间中调节学习机器置信范围和经验风险的比例,以使学习机器的推广能力最好.
基于特征扰动的集成(又被称为集成特征选择),通过构建训练样本集的不同特征子集,达到提高集成差异度的目的,其关键问题是如何有效地生成各特征子集.
特征变换方法主要有主成分分析法(Principle Component Analysis, pCA)和独立成分分析法(ICA)。PCA方法是进行特征变换常用的一种线性变换方法,又称之为K-L变换。目的是寻找一组最优的单位正交向量,即所谓的主成分,作为子空间的基。ICA方法的目的是将观测到的数据进行某种线性分解,使其分解成统计独立的成分。
特征选择方法在建模中的应用
特征选择方法在建模中的应用 ——以CHAID树模型为例 华东师范大学邝春伟
特征选择是指从高维特征集合中根据某种评估标准选择输出性能最优的特征子集,其目的是寻求保持数据集感兴趣特性的低维数据集合,通过低维数据的分析来获得相应的高维数据特性,从而达到简化分析、获取数据有效特征以及可视化数据的目标。 目前,许多机构的数据均已超载,因此简化和加快建模过程是特征选择的根本优势。通过将注意力迅速集中到最重要的字段(变量)上,可以降低所需的计算量,并且可以方便地找到因某种原因被忽略的小而重要的关系,最终获得更简单、精确和易于解释的模型。通过减少模型中的字段数量,可以减少评分时间以及未来迭代中所收集的数据量。 减少字段数量特别有利于Logistic 回归这样的模型。
SPSS Modeler是一个非常优秀的数据挖掘软件。它的前身是SPSS Clementine及PASW Modeler。该软件 的特征选择节点有助于识别用于预测特定结果的最重要的字段。特征选择节点可对成百乃至上千个预测变量进行筛选、排序,并选择出可能是最重要的预测变量。最后,会生成一个执行地更快且更加有效的模型—此模型使用较少的预测变量,执行地更快且更易于理解。 案例中使用的数据为“上海高中生家庭教育的调查”,包含有关该CY二中的304名学生参与环保活动的信息。 该数据包含几十个的字段(变量),其中有学生年龄、性别、家庭收入、身体状况情况等统计量。其中有一个“目标”字段,显示学生是否参加过环保活动。我们想利用这些数据来预测哪些学生最可能在将来参加环保活动。
案例关注的是学生参与环保活动的情况,并将其作为目标。案例使用CHAID树构建节点来开发模型,用以说明最有可能参与环保活动的学生。其中对以下两种方法作了对比: ?不使用特征选择。数据集中的所有预测变量字段 均可用作CHAID 树的输入。 ?使用特征选择。使用特征选择节点选择最佳的4 个预测变量。然后将其输入到CHAID 树中。 通过比较两个生成的树模型,可以看到特征选择如何产生有效的结果。
文献综述-蛋白质多级结构的表征方式及测定方法
文献综述 蛋白多级结构的表征及测定方式 摘要研究蛋白质的结构对生命科学有重要意义,因为明确了蛋白质的结构,有助于了解蛋白质的作用,了解蛋白质如何行使其生物功能,认识蛋白质与蛋白质(或其它分子)之间的相互作用,这无论是对于生物学还是对于生物医学和生物药学,都是非常重要的。蛋白质分子的多级结构可划分为四级,以描述其不同的方面,包括蛋白二级结构、超二级结构和结构域、三级结构、四级结构。 关键词:二级结构超二级结构和结构域三级结构四级结构表征和测定方式 1 蛋白多级结构概述 蛋白质分子是由氨基酸首尾相连缩合而成的共价多肽链,每一种天然蛋白质都有自己特有的空间结构或称三维结构,这种三维结构通常被称为蛋白质的构象,即蛋白质的结构。 1.1 蛋白质的二级结构 蛋白质的二级结构(secondary structure)是指多肽链中主链原子的局部空间排布即构象,不涉及侧链部分的构象。 蛋白质主链构象的结构单元包括:α-螺旋(α-helix)、β-片层结构(β-pleated sheet)或称β-折迭、β-转角(β-turn或β-bend)、无规卷曲(random coil)。 α-螺旋有以下几个特点:①多个肽键平面通过α-碳原子旋转,相互之间紧密盘曲成稳固的右手螺旋。②主链呈螺旋上升,每3.6个氨基酸残基上升一圈,相当于0.54nm。③每一个氨基酸残基中的NH和前面相隔三个残基的C=O之间形成氢键。④肽链中氨基酸侧链R,分布在螺旋外侧,其形状、大小及电荷影响α-螺旋的形成。 β-片层结构有以下几个特点:①是肽链相当伸展的结构,肽链平面之间折叠成锯齿状,相邻肽键平面间呈110°角。氨基酸残基的R侧链伸出在锯齿的上方或下方。②依靠两条肽链或一条肽链内的两段肽链间的C=O与H形成氢键,使构象稳定。③两段肽链可以是平行的,也可以是反平行的。即前者两条链从“N
《大数据时代下的数据挖掘》试题及答案要点
《海量数据挖掘技术及工程实践》题目 一、单选题(共80题) 1)( D )的目的缩小数据的取值范围,使其更适合于数据挖掘算法的需要,并且能够得到 和原始数据相同的分析结果。 A.数据清洗 B.数据集成 C.数据变换 D.数据归约 2)某超市研究销售纪录数据后发现,买啤酒的人很大概率也会购买尿布,这种属于数据挖 掘的哪类问题?(A) A. 关联规则发现 B. 聚类 C. 分类 D. 自然语言处理 3)以下两种描述分别对应哪两种对分类算法的评价标准? (A) (a)警察抓小偷,描述警察抓的人中有多少个是小偷的标准。 (b)描述有多少比例的小偷给警察抓了的标准。 A. Precision,Recall B. Recall,Precision A. Precision,ROC D. Recall,ROC 4)将原始数据进行集成、变换、维度规约、数值规约是在以下哪个步骤的任务?(C) A. 频繁模式挖掘 B. 分类和预测 C. 数据预处理 D. 数据流挖掘 5)当不知道数据所带标签时,可以使用哪种技术促使带同类标签的数据与带其他标签的数 据相分离?(B) A. 分类 B. 聚类 C. 关联分析 D. 隐马尔可夫链 6)建立一个模型,通过这个模型根据已知的变量值来预测其他某个变量值属于数据挖掘的 哪一类任务?(C) A. 根据内容检索 B. 建模描述 C. 预测建模 D. 寻找模式和规则 7)下面哪种不属于数据预处理的方法? (D) A.变量代换 B.离散化
C.聚集 D.估计遗漏值 8)假设12个销售价格记录组已经排序如下:5, 10, 11, 13, 15, 35, 50, 55, 72, 92, 204, 215 使用如下每种方法将它们划分成四个箱。等频(等深)划分时,15在第几个箱子内? (B) A.第一个 B.第二个 C.第三个 D.第四个 9)下面哪个不属于数据的属性类型:(D) A.标称 B.序数 C.区间 D.相异 10)只有非零值才重要的二元属性被称作:( C ) A.计数属性 B.离散属性 C.非对称的二元属性 D.对称属性 11)以下哪种方法不属于特征选择的标准方法: (D) A.嵌入 B.过滤 C.包装 D.抽样 12)下面不属于创建新属性的相关方法的是: (B) A.特征提取 B.特征修改 C.映射数据到新的空间 D.特征构造 13)下面哪个属于映射数据到新的空间的方法? (A) A.傅立叶变换 B.特征加权 C.渐进抽样 D.维归约 14)假设属性income的最大最小值分别是12000元和98000元。利用最大最小规范化的方 法将属性的值映射到0至1的范围内。对属性income的73600元将被转化为:(D) A.0.821 B.1.224 C.1.458 D.0.716 15)一所大学内的各年纪人数分别为:一年级200人,二年级160人,三年级130人,四年 级110人。则年级属性的众数是: (A) A.一年级 B.二年级 C.三年级 D.四年级
常见的特征选择或特征降维方法
URL:https://www.360docs.net/doc/a413473326.html,/14072.html 特征选择(排序)对于数据科学家、机器学习从业者来说非常重要。好的特征选择能够提升模型的性能,更能帮助我们理解数据的特点、底层结构,这对进一步改善模型、算法都有着重要作用。 特征选择主要有两个功能: 1.减少特征数量、降维,使模型泛化能力更强,减少过拟合 2.增强对特征和特征值之间的理解 拿到数据集,一个特征选择方法,往往很难同时完成这两个目的。通常情况下,选择一种自己最熟悉或者最方便的特征选择方法(往往目的是降维,而忽略了对特征和数据理解的目的)。 在许多机器学习的书里,很难找到关于特征选择的容,因为特征选择要解决的问题往往被视为机器学习的一种副作用,一般不会单独拿出来讨论。本文将介绍几种常用的特征选择方法,它们各自的优缺点和问题。 1 去掉取值变化小的特征Removing features with low variance 这应该是最简单的特征选择方法了:假设某种特征的特征值只有0和1,并且在所有输入样本中,95%的实例的该特征取值都是1,那就可以认为这个特征作用不大。如果100%都是1,那这个特征就没意义了。当特征值都是离散型变量的时候这种方法才能用,如果是连续型变量,就需要将连续变量离散化之后才能用,而且实际当中,一般不太会有95%以上都取某个值的特征存在,所以这种方法虽然简单但是不太好用。可以把它作为特征选择的预处理,先去掉那些取值变化小的特征,然后再从接下来提到的特征选择方法中选择合适的进行进一步的特征选择。
2 单变量特征选择Univariate feature selection 单变量特征选择能够对每一个特征进行测试,衡量该特征和响应变量之间的关系,根据得分扔掉不好的特征。对于回归和分类问题可以采用卡方检验等方式对特征进行测试。 这种方法比较简单,易于运行,易于理解,通常对于理解数据有较好的效果(但对特征优化、提高泛化能力来说不一定有效);这种方法有许多改进的版本、变种。 2.1 Pearson相关系数Pearson Correlation 皮尔森相关系数是一种最简单的,能帮助理解特征和响应变量之间关系的方法,该方法衡量的是变量之间的线性相关性,结果的取值区间为[-1,1],-1表示完全的负相关(这个变量下降,那个就会上升),+1表示完全的正相关,0表示没有线性相关。 Pearson Correlation速度快、易于计算,经常在拿到数据(经过清洗和特征提取之后的)之后第一时间就执行。 Pearson相关系数的一个明显缺陷是,作为特征排序机制,他只对线性关系敏感。如果关系是非线性的,即便两个变量具有一一对应的关系, Pearson相关性也可能会接近0。 2.2 互信息和最大信息系数Mutual information and maximal information coefficient (MIC)
数据挖掘试题(单选)
单选题 1. 某超市研究销售纪录数据后发现,买啤酒的人很大概率也会购买尿布,这种属于数据挖掘的哪类问题?(A) A. 关联规则发现 B. 聚类 C. 分类 D. 自然语言处理 2. 以下两种描述分别对应哪两种对分类算法的评价标准? (A) (a)警察抓小偷,描述警察抓的人中有多少个是小偷的标准。 (b)描述有多少比例的小偷给警察抓了的标准。 A. Precision, Recall B. Recall, Precision A. Precision, ROC D. Recall, ROC 3. 将原始数据进行集成、变换、维度规约、数值规约是在以下哪个步骤的任务?(C) A. 频繁模式挖掘 B. 分类和预测 C. 数据预处理 D. 数据流挖掘 4. 当不知道数据所带标签时,可以使用哪种技术促使带同类标签的数据与带其他标签的数据相分离?(B) A. 分类 B. 聚类 C. 关联分析 D. 隐马尔可夫链 5. 什么是KDD? (A) A. 数据挖掘与知识发现 B. 领域知识发现 C. 文档知识发现 D. 动态知识发现 6. 使用交互式的和可视化的技术,对数据进行探索属于数据挖掘的哪一类任务?(A) A. 探索性数据分析 B. 建模描述 C. 预测建模 D. 寻找模式和规则 7. 为数据的总体分布建模;把多维空间划分成组等问题属于数据挖掘的哪一类任务?(B) A. 探索性数据分析 B. 建模描述 C. 预测建模 D. 寻找模式和规则 8. 建立一个模型,通过这个模型根据已知的变量值来预测其他某个变量值属于数据挖掘的哪一类任务?(C) A. 根据内容检索 B. 建模描述 C. 预测建模 D. 寻找模式和规则 9. 用户有一种感兴趣的模式并且希望在数据集中找到相似的模式,属于数据挖掘哪一类任务?(A) A. 根据内容检索 B. 建模描述 C. 预测建模 D. 寻找模式和规则 11.下面哪种不属于数据预处理的方法? (D) A变量代换 B离散化 C 聚集 D 估计遗漏值 12. 假设12个销售价格记录组已经排序如下:5, 10, 11, 13, 15, 35, 50, 55, 72, 92, 204, 215 使用如下每种方法将它们划分成四个箱。等频(等深)划分时,15在第几个箱子内? (B) A 第一个 B 第二个 C 第三个 D 第四个 13.上题中,等宽划分时(宽度为50),15又在哪个箱子里? (A) A 第一个 B 第二个 C 第三个 D 第四个 14.下面哪个不属于数据的属性类型:(D) A 标称 B 序数 C 区间 D相异 15. 在上题中,属于定量的属性类型是:(C) A 标称 B 序数 C区间 D 相异 16. 只有非零值才重要的二元属性被称作:( C )
自然语言处理的单词嵌入及表征方法
自然语言处理的单词嵌入及表征方法 简介 过去几年,深度神经网络在模式识别中占绝对主流。它们在许多计算机视觉任务中完爆之前的顶尖算法。在语音识别上也有这个趋势了。 虽然结果好,我们也必须思考……它们为什么这么好使? 在这篇文章里,我综述一下在自然语言处理(NLP)上应用深度神经网络得到的一些效果极其显著的成果。我希望能提供一个能解释为何深度神经网络好用的理由。我认为这是个非常简练而优美的视角。 单隐层神经网络 单隐层神经网络有一个普适性(universality):给予足够的隐结点,它可以估算任何函数。这是一个经常被引用的理论,它被误解和应用的次数就更多了。 本质上这个理论是正确的,因为隐层可以用来做查询表。 简单点,我们来看一个感知器网络(perceptron network)。感知器(perceptron)是非常简单的神经元,如果超过一个阈值它就会被启动,如果没超过改阈值它就没反应。感知器网络的输入和输出都是是二进制的(0和1)。 注意可能的输入个数是有限的。对每个可能的输入,我们可以在隐层里面构建一个只对这个输入有反应的神经元(见注解1)。然后我们可以利用这个神经元和输出神经元之间的连接来控制这个输入下得到的结果(见注解2)。
这样可以说明单隐层神经网络的确是有普适性的。但是这也没啥了不起的呀。你的模型能干和查询表一样的事并不能说明你的模型有任何优点。这只能说明用你的模型来完成任务并不是不可能的罢了。 普适性的真正意义是:一个网络能适应任何你给它的训练数据。这并不代表插入新的数据点的时候它能表现地很理想。 所以普适性并不能解释为什么神经网络如此好用。真正的原因比这微妙得多…为了理解它,我们需要先理解一些具体的成果。 单词嵌入(Word Embeddings) 我想从深度学习研究的一个非常有意思的部分讲起,它就是:单词嵌入(word embeddings)。在我看来,单词嵌入是目前深度学习最让人兴奋的领域之一,尽
文本分类中的特征提取和分类算法综述
文本分类中的特征提取和分类算法综述 摘要:文本分类是信息检索和过滤过程中的一项关键技术,其任务是对未知类别的文档进行自动处理,判别它们所属于的预定义类别集合中的类别。本文主要对文本分类中所涉及的特征选择和分类算法进行了论述,并通过实验的方法进行了深入的研究。 采用kNN和Naive Bayes分类算法对已有的经典征选择方法的性能作了测试,并将分类结果进行对比,使用查全率、查准率、F1值等多项评估指标对实验结果进行综合性评价分析.最终,揭示特征选择方法的选择对分类速度及分类精度的影响。 关键字:文本分类特征选择分类算法 A Review For Feature Selection And Classification Algorithm In Text Categorization Abstract:Text categorization is a key technology in the process of information retrieval and filtering,whose task is to process automatically the unknown categories of documents and distinguish the labels they belong to in the set of predefined categories. This paper mainly discuss the feature selection and classification algorithm in text categorization, and make deep research via experiment. kNN and Native Bayes classification algorithm have been applied to test the performance of classical feature detection methods, and the classification results based on classical feature detection methods have been made a comparison. The results have been made a comprehensive evaluation analysis by assessment indicators, such as precision, recall, F1. In the end, the influence feature selection methods have made on classification speed and accuracy have been revealed. Keywords:Text categorization Feature selection Classification algorithm
数据分析的特征选择实例分析
数据分析的特征选择实例分析 1.数据挖掘与聚类分析概述 数据挖掘一般由以下几个步骤: (l)分析问题:源数据数据库必须经过评估确认其是否符合数据挖掘标准。以决定预期结果,也就选择了这项工作的最优算法。 (2)提取、清洗和校验数据:提取的数据放在一个结构上与数据模型兼容的数据库中。以统一的格式清洗那些不一致、不兼容的数据。一旦提取和清理数据后,浏览所创建的模型,以确保所有的数据都已经存在并且完整。 (3)创建和调试模型:将算法应用于模型后产生一个结构。浏览所产生的结构中数据,确认它对于源数据中“事实”的准确代表性,这是很重要的一点。虽然可能无法对每一个细节做到这一点,但是通过查看生成的模型,就可能发现重要的特征。 (4)查询数据挖掘模型的数据:一旦建立模型,该数据就可用于决策支持了。 (5)维护数据挖掘模型:数据模型建立好后,初始数据的特征,如有效性,可能发生改变。一些信息的改变会对精度产生很大的影响,因为它的变化影响作为基础的原始模型的性质。因而,维护数据挖掘模型是非常重要的环节。 聚类分析是数据挖掘采用的核心技术,成为该研究领域中一个非常活跃的研究课题。聚类分析基于”物以类聚”的朴素思想,根据事物的特征,对其进行聚类或分类。作为数据挖掘的一个重要研究方向,聚类分析越来越得到人们的关注。聚类的输入是一组没有类别标注的数据,事先可以知道这些数据聚成几簇爪也可以不知道聚成几簇。通过分析这些数据,根据一定的聚类准则,合理划分记录集合,从而使相似的记录被划分到同一个簇中,不相似的数据划分到不同的簇中。 2.特征选择与聚类分析算法 Relief为一系列算法,它包括最早提出的Relief以及后来拓展的Relief和ReliefF,其中ReliefF算法是针对目标属性为连续值的回归问题提出的,下面仅介绍一下针对分类问题的Relief和ReliefF算法。 2.1 Relief算法 Relief算法最早由Kira提出,最初局限于两类数据的分类问题。Relief算法是一种特征权重算法(Feature weighting algorithms),根据各个特征和类别的相关性赋予特征不同的权重,权重小于某个阈值的特征将被移除。Relief算法中特征和类别的相关性是基于特征对近距离样本的区分能力。算法从训练集D中随机选择一个样本R,然后从和R同类的样本中寻找最近邻样本H,称为Near Hit,从和R不同类的样本中寻找最近邻样本M,称为NearMiss,然后根据以下规则更新每个特征的权重:如果R和Near Hit在某个特征上的距离小于R和Near Miss 上的距离,则说明该特征对区分同类和不同类的最近邻是有益的,则增加该特征的权重;反之,如果R和Near Hit 在某个特征的距离大于R和Near Miss上的距离,说明该特征对区分同类和不同类的最近邻起负面作用,则降低该特征的权重。以上过程重复m次,最后得到各特征的平均权重。特征的权重越大,表示该特征的分类能力越强,反之,表示该特征分类能力越弱。Relief算法的运行时间随着样本的抽样次数m和原始特征个数N的增加线性增加,因而运行效率非常高。具体算法如下所示:
高分子聚合物的主要表征方法
摘要 本文主要综述了高分子聚合物及其表征方法和检测手段。首先,从不同角度对高分子聚合物进行分类,并对高分子聚合物的结构,生产,性能做了一个简单的介绍。其次,阐述了表征和检测高分子聚合物的常用方法,例如:凝胶渗透色谱、核磁共振(NMR)、红外吸收光谱(IR)、激光拉曼光谱(LR)等。最后,介绍了检测高分子聚合物的常用设备,例如:偏光显微镜、金相显微镜、体视显微镜、X射线衍射、扫描电镜、透射电镜、原子力显微镜等。 关键词:聚合物;表征方法;检测手段;常用设备
ABSTRACT This paper mainly summarizes the polymer and its detection means.First of all, this paper made a simple introduction of the polymer structure, production performance. Secondly, it describes the detection methods of polymers, such as: gel permeation chromatography, nuclear magnetic resonance (NMR), infrared absorption spectroscopy (IR), laser Raman spectroscopy (LR).Finally, it describes the common equipment used to characterize and detection of polymers, such as: polarizing microscope, metallographic microscope, microscope, X ray diffraction, scanning electron microscopy, transmission electron microscopy, atomic force microscopy. Key words:Polymer; Characterization; Testing means; common equipment
最新有机化合物的结构表征方法关系与区别教程文件
一、 在研究有机化合物的过程中,往往要对未知物的结构加以测定,或要对所合成的目的物进行验证结构。其经典的方法有降解法和综合法。降解法是在确定未知物的分子式以后,将待测物降解为分子较小的有机物,这些较小的有机物的结构式都是已知的。根据较小有机物的结构及其他有关知识可以判断被测物的结构式。综合法是将已知结构的小分子有机物,通过合成途径预计某待测的有机物,将合成的有机物和被研究的有机物进行比较,可以确定其结构。经典的化学方法是研究有机物结构的基础,今天在有机物研究中,仍占重要地位。但是经典的研究方法花费时间长,消耗样品多,操作手续繁。特别是一些复杂的天然有机物结构的研究,要花费几十年甚至几代人的精力。 近代发展起来的测定有机物结构的物理方法,可以在比较短的时间内,用很少量的样品,经过简单的操作就可以获得满意的结果。近代物理方法有多种,有机化学中应用最广泛的波谱方法是紫外和可见光谱,红外光谱,以及核磁共振谱(氢谱、碳谱),一般简称“四谱”。 二、经典化学方法 1、特点:以化学反应为手段一种分析方法 2、分析步骤 (1)测定元素组成:将样品进行燃烧,观察燃烧时火焰颜色、有无黑烟、残余,再通过化学反应,检测C、H、O等元素含量,得到化学式 (2)测定分子摩尔质量:熔点降低法、沸点升高法 (3)溶解度实验:通过将样品加入不同试剂,观察溶解与否,来进行结构猜测 (4)官能团实验:通过与不同特殊试剂反应,判断对应的官能团结构(例:D-A反应形成具有固定熔点的晶体——存在共轭双烯) (5)反应生成衍生物,并与已知结构的衍生物进行比较。
三、现代检测技术 (一)紫外光谱(Ultraviolet Spectra,UV)(电子光谱) 1、基本概念 (1)定义:紫外光谱法是研究物质分子对紫外的吸收情况来进行定性、定量和结构分析的一种方法。 (2)特点:UV主要产生于分子价电子在电子能级间的跃迁,并伴随着振动转动能级跃迁,是研究物质电子光谱的定量和定性的分析方法。属于电子光谱(分子光谱),为连续带状。 (3)光吸收定律:朗伯—比尔定律 当用一波长为λ强度为I0的光通过宽度为b(cm)的透明溶液时,其透过光的强度为I,则物质的吸光度A与溶液中物质的浓度c成正比。 A=-㏒T=㏒I0/I=εbc 上式为紫外—可见吸收光谱的定量依据。 2、有机化合物电子跃迁类型 紫外-可见吸收光谱是由分子中价电子在电子能级间跃迁而产生的。按分子轨道理论,在有机化合物分子中,存在下列几种不同性质的价电子: ①形成单键的电子:σ键电子 ②形成双键的电子:π键电子 ③O、S、N、X等含有未成键的孤对电子:n电子或p电子。 常温下这些价电子都在成键轨道上,当分子吸收一定能量后,上述价电子将跃迁到较高能级,此时电子占据的轨道称反键轨道。而这种特定的跃迁是同分子内部结构有密切关系。因此,有机化合物的电子跃迁类型主要有下列几种: 1. σ→σ* 2. n→σ* 3. π→π* 4. n→π*
数据挖掘试题
For personal use only in study and research; not for commercial use 单选题 1. 某超市研究销售纪录数据后发现,买啤酒的人很大概率也会购买尿布,这种属于数据挖掘的哪类问题?(A) A. 关联规则发现 B. 聚类 C. 分类 D. 自然语言处理 3. 将原始数据进行集成、变换、维度规约、数值规约是在以下哪个步骤的任务?(C) A. 频繁模式挖掘 B. 分类和预测 C. 数据预处理 D. 数据流挖掘 4. 当不知道数据所带标签时,可以使用哪种技术促使带同类标签的数据与带其他标签的数据相分离?(B) A. 分类 B. 聚类 C. 关联分析 D. 隐马尔可夫链 6. 使用交互式的和可视化的技术,对数据进行探索属于数据挖掘的哪一类任务?(A) A. 探索性数据分析 B. 建模描述 C. 预测建模 D. 寻找模式和规则 11.下面哪种不属于数据预处理的方法?(D) A变量代换B离散化 C 聚集 D 估计遗漏值 12. 假设12个销售价格记录组已经排序如下:5, 10, 11, 13, 15, 35, 50, 55, 72, 92, 204, 215 使用如下每种方法将它们划分成四个箱。等频(等深)划分时,15在第几个箱子内?(B) A 第一个 B 第二个 C 第三个 D 第四个 13.上题中,等宽划分时(宽度为50),15又在哪个箱子里?(A) A 第一个 B 第二个 C 第三个 D 第四个 16. 只有非零值才重要的二元属性被称作:( C ) A 计数属性 B 离散属性C非对称的二元属性 D 对称属性 17. 以下哪种方法不属于特征选择的标准方法:(D) A嵌入 B 过滤 C 包装 D 抽样 18.下面不属于创建新属性的相关方法的是:(B) A特征提取B特征修改C映射数据到新的空间D特征构造 22. 假设属性income的最大最小值分别是12000元和98000元。利用最大最小规范化的方法将属性的值映射到0至1的范围内。对属性income的73600元将被转化为:(D) A 0.821 B 1.224 C 1.458 D 0.716 23.假定用于分析的数据包含属性age。数据元组中age的值如下(按递增序):13,15,16,16,19,20,20,21,22,22,25,25,25,30,33,33,35,35,36,40,45,46,52,70, 问题:使用按箱平均值平滑方法对上述数据进行平滑,箱的深度为3。第二个箱子值为:(A) A 18.3 B 22.6 C 26.8 D 27.9 28. 数据仓库是随着时间变化的,下面的描述不正确的是(C) A. 数据仓库随时间的变化不断增加新的数据内容; B. 捕捉到的新数据会覆盖原来的快照; C. 数据仓库随事件变化不断删去旧的数据内容; D. 数据仓库中包含大量的综合数据,这些综合数据会随着时间的变化不断地进行重新综合. 29. 关于基本数据的元数据是指: (D) A. 基本元数据与数据源,数据仓库,数据集市和应用程序等结构相关的信息; B. 基本元数据包括与企业相关的管理方面的数据和信息;
特征选择算法综述20160702
特征选择方法综述 控制与决策2012.2 问题的提出 特征选择框架基于搜索策略划分特征选择方法基于评价准则划分特征选择方法结论 一、问题的提出特征选择是从一组特征中挑选出一些最有效的特征以降低特征空间维数的过程,是模式识别的关键问题之一。对于模式识别系统,一个好的学习样本是训练分类器的关键,样本中是否含有不相关或冗余信息直接影响着分类器的性能。因此研究有效的特征选择方法至关重要。 特征选择算法的目的在于选择全体特征的一个较少特征集合,用以对原始数据进行有效表达按照特征关系度量划分,可分为依赖基尼指数、欧氏距离、信息熵。 、特征选择框架 由于子集搜索是一个比较费时的步骤,一些学者基于相关和冗余分析,给出了下面一种特征选择框架,避免了子集搜索,可以高效快速地寻找最优子集。 从特征选择的基本框架看出,特征选择方法中有4 个基本步骤:候选特征子集的生成(搜索策略)、评价准则、停止准则和验证方法。目前对特征选择方法的研究主要集中于搜索策略和评价准则。因而,本文从搜索策略和评价准则两个角度对特征选择方法进行分类。 三、基于搜索策略划分特征选择方法 基本的搜索策略按照特征子集的形成过程,形成的特征选择方法如下:
图3 基于搜索策略划分特征选择方法 其中,全局搜索如分支定界法,存在问题: 1)很难确定优化特征子集的数目; 2)满足单调性的可分性判据难以设计; 3)处理高维多类问题时,算法的时间复杂度较高。 随机搜索法如模拟退火、遗传算法、禁忌搜索算法等,存在问题: 1)具有较高的不确定性,只有当总循环次数较大时,才可能找到较好的结果。 2)在随机搜索策略中,可能需对一些参数进行设置,参数选择的合适与否对最终结果的好坏起着很大的作用。 启发式搜索如SFS、SBS、SFFS、SFBS等,存在问题: 1)虽然效率高,但是它以牺牲全局最优为代价。 每种搜索策略都有各自的优缺点,在实际应用过程中,根据具体环境和准则函数来寻找一个最佳的平衡点。例如,特征数较少,可采用全局最优搜索策略;若不要求全局最优,但要求计算速度快,可采用启发式策略;若需要高性能的子集,而不介意计算时间,则可采用随机搜索策略。 四、基于评价准则划分特征选择方法
热分析技术的表征应用
目录 摘要 (2) 关键词 (2) 前言 (2) 1 热分析技术综述 (2) 1.1 差示扫描量热法(DSC) (3) 1.2 差示热分析法(DTA) (3) 1.3 热重法(TGA) (3) 1.4 热机械法(DMA) (3) 2热分析技术的表征应用综述 (4) 2.1热分析技术在化合物表征中的应用 (4) 2.2 热分析技术在食品分析研究中的应用 (4) 2.2.1 食品的水含量及玻璃态转变温度Tg的测定 (4) 2.2.2 蛋白质、淀粉、脂类的研究 (5) 2.3 热分析技术在药品检验中的应用 (5) 2.3.1 药品的纯度、熔点测定 (6) 2.3.2 药品溶剂化物及水成分的确定 (6) 2.3.3 药品的相容性和稳定性测定 (6) 2.3.4 药物多晶型及差向异构体的分析 (7) 2.3.5 制剂辅料相容性考察 (7) 2.4 热分析技术在催化研究中的应用 (7) 2.4.1 金属和金属氧化物催化剂中的应用 (7) 2.4.1.1 催化剂失活研究 (7) 2.4.1.2 非晶态合金催化剂热稳定性研究 (7) 2.4.2 沸石分子筛与多孔材料研究中的应用 (8) 2.4.2.1 沸石分子筛催化剂的积炭行为研究 (8) 2.4.2.2 沸石分子筛吸附性能的研究 (8) 2.5 热分析技术高分子材料研究中的应用 (8) 2.5.1 TG在高分子材料方面的应用 (8) 2.5.1.1 高分子材料的组分测定 (8) 2.5.1.2 高分子材料中挥发性物质的测定 (9) 2.5.1.3 高分子材料的热稳定性研究 (9) 2.5.2 DTA在高分子材料方面的应用 (9) 2.5.3 DSC在高分子材料方面的应用 (9) 2.5.4 DMA在高分子材料方面的应用 (9) 2.5.4.1 高分子共混材料相容性的表征 (9) 2.5.4.2 表征高聚物材料阻尼特性 (10) 3 结语 (10) 参考文献: (10)
特征选择综述
特征选择常用算法综述 一.什么是特征选择(Featureselection ) 特征选择也叫特征子集选择 ( FSS , Feature SubsetSelection ) 。是指从已有的M个特征(Feature)中选择N个特征使得系统的特定指标最优化。 需要区分特征选择与特征提取。特征提取 ( Feature extraction )是指利用已有的特征计算出一个抽象程度更高的特征集,也指计算得到某个特征的算法。 特征提取与特征选择都能降低特征集的维度。 评价函数 ( Objective Function ),用于评价一个特征子集的好坏的指标。这里用符号J ( Y )来表示评价函数,其中Y是一个特征集,J( Y )越大表示特征集Y 越好。 评价函数根据其实现原理又分为2类,所谓的Filter和Wrapper 。 Filter(筛选器):通过分析特征子集内部的信息来衡量特征子集的好坏,比如特征间相互依赖的程度等。Filter实质上属于一种无导师学习算法。 Wrapper(封装器):这类评价函数是一个分类器,采用特定特征子集对样本集进行分类,根据分类的结果来衡量该特征子集的好坏。Wrapper实质上是一种有导师学习算法。 二.为什么要进行特征选择? 获取某些特征所需的计算量可能很大,因此倾向于选择较小的特征集特征间的相关性,比如特征A完全依赖于特征B,如果我们已经将特征B选入特征集,那么特征A 是否还有必要选入特征集?我认为是不必的。特征集越大,分类器就越复杂,其后果就是推广能力(generalization capability)下降。选择较小的特征集会降低复杂度,可能会提高系统的推广能力。Less is More ! 三.特征选择算法分类 精确的解决特征子集选择问题是一个指数级的问题。常见特征选择算法可以归为下面3类: 第一类:指数算法 ( Exponential algorithms ) 这类算法对特征空间进行穷举搜索(当然也会采用剪枝等优化),搜索出来的特征集对于样本集是最优的。这类算法的时间复杂度是指数级的。
常见的特征选择或特征降维方法
URL:https://www.360docs.net/doc/a413473326.html,/14072.html 特征选择(排序)对于数据科学家、机器学习从业者来说非常重要。好的特征选择能够提升模型的性能,更能帮助我们理解数据的特点、底层结构,这对进一步改善模型、算法都有着重要作用。 特征选择主要有两个功能: 1.减少特征数量、降维,使模型泛化能力更强,减少过拟合 2.增强对特征和特征值之间的理解 拿到数据集,一个特征选择方法,往往很难同时完成这两个目的。通常情况下,选择一种自己最熟悉或者最方便的特征选择方法(往往目的是降维,而忽略了对特征和数据理解的目的)。 在许多机器学习的书里,很难找到关于特征选择的内容,因为特征选择要解决的问题往往被视为机器学习的一种副作用,一般不会单独拿出来讨论。本文将介绍几种常用的特征选择方法,它们各自的优缺点和问题。 1 去掉取值变化小的特征 Removing features with low variance 这应该是最简单的特征选择方法了:假设某种特征的特征值只有0和1,并且在所有输入样本中,95%的实例的该特征取值都是1,那就可以认为这个特征作用不大。如果100%都是1,那这个特征就没意义了。当特征值都是离散型变量的时候这种方法才能用,如果是连续型变量,就需要将连续变量离散化之后才能用,而且实际当中,一般不太会有95%以上都取某个值的特征存在,所以这种方法虽然简单但是不太好用。可以把它作为特征选择的预处理,先去掉那些取值变化小的特征,然后再从接下来提到的特征选择方法中选择合适的进行进一步的特征选择。 2 单变量特征选择 Univariate feature selection
(整理)聚合物的表征概述
精品文档 目录1 前言 0 2 表征方法 (1) 2.1 红外光谱法(IR) (1) 2.2 核磁共振法(NMR) (3) 2.3 热分析法 (3) 2.4 扫描电镜法 (5) 2.5 X-射线衍射法 (5) 2.6 原子力显微镜法 (6) 2.7 透射电镜法 (7) 3 聚合物表征的相关研究 (8) 4 结论 (8) 参考文献 (9)
精品文档 聚合物表征方法概述 摘要:介绍了常规的聚合物的表征方法,具体叙述了红外光谱(IR)、X射线衍射(XRD)、透射电镜(TEM)、核磁共振(NMR)等的原理、方法、特点、局限性及改进方法并展望了聚合物表征方法的发展趋势。 关键词: 聚合物表征方法 Summary of polymer characterization methods Abstrac t:The conventional polymer characterization methods were introduced in this paper. The principle, method, characteristics infrared spectra (IR), X-ray diffraction (XRD), transmission electron microscopy (TEM) and the nuclear magnetic resonance (NMR) have been described, the limitations, the improved method and the predicts the development trend of those polymer characterization methods have been summarized. Keyword:polymer characterization method 1 前言 功能高分子是指具有某些特定功能的高分子材料[1]。它们之所以具有特定的功能,是由于在其大分子链中结合了特定的功能基团,或大分子与具有特定功能的其他材料进行了复合,或者二者兼而有之。功能高分子材料从20世纪50年代才初露端倪,到70年代方成为高分子学科的一个分支,目前正处于成长时期。它是在合成或天然高分子原有力学性能的基础上,再赋予传统使用性能以外的各种特定功能而制得的一类高分子[2]。一般在功能高分子的主链或侧链上具有显示某种功能的基团,其功能性的显示往往十分复杂,不仅决定于高分子链的化学结构、结构单元的序列分布、分子量及其分布、支化、立体结构等一级结构,还决定于高分子链的构象、高分子链在聚集时的高级结构等,后者对生物活性功能的显示更为重要[3]。
刻板印象的理论与研究方法综述
杨亚平1,王沛2 1宁波大学教师教育学院,浙江宁波 (315211) 2上海师范大学教育学院,上海(200234) E-mail:yaping.yang@https://www.360docs.net/doc/a413473326.html, 摘要:刻板印象是指按照性别、种族、年龄或职业等进行社会分类,形成的关于某类人的固定印象,普遍认为它与某些特征和行为相联系。自刻板印象这一概念提出以来,就引起了社会心理学界广泛而持久的研究兴趣,作为用以解释社会知觉与印象形成过程的重要操作性构念,刻板印象一直以来都是社会认知领域的核心研究课题。本文对刻板印象研究的理论进展以及研究方法进行了系统的回顾和总结,以期为以后的研究提供理论和方法的依据。 关键词:刻板印象,理论模型,研究方法 1.引言 刻板印象这一术语是1922年Lippman在其著作《公众舆论》中提出的,它是指按照性别、种族、年龄或职业等进行社会分类,形成的关于某类人的固定印象,普遍认为它与某些特征和行为相联系;从认知理论的角度出发,刻板印象可以定义为“一种涉及知觉者的关于某个人类群体的知识、观念与预期的认知结构”[1]。自刻板印象这一概念提出以来,就引起了社会心理学界广泛而持久的研究兴趣。作为用以解释社会知觉与印象形成过程的重要的操作性构念,刻板印象一直是社会认知领域的研究热点。早期的刻板印象研究主要集中于对刻板印象概念的界定,以及对不同群体刻板印象内容的评估。然而从20世纪70年代初开始,受认知心理学的影响,刻板印象的研究开始从内容向加工转移,这时的研究主要集中在作为一种认知结构的刻板印象是如何发生的,它又是如何影响后继的信息加工以及群体成员之间的知觉和行为的;研究视角也开始逐渐从意识代码的角度演变到认知神经科学的角度。2.刻板印象的主要理论模型 从不同的角度出发,刻板印象的理论模型主要体现在三个方面:刻板印象的理论解释,刻板印象的表征模型以及刻板印象的功效模型,下面从各模型理论进展的做一概述。 2.1 刻板印象的理论解释 刻板印象的理论解释,其研究进展的趋势是由社会认同理论、社会认知理论到社会环境影响理论。关于刻板印象产生的原因,不同的心理学家有不同的解释,较具代表性的有社会认同理论和社会认知理论,近年来又有人对以上两种理论加以整合,提出了社会环境影响理论。 2.1.1 社会认同理论 这一理论是由Tajfel和Turner(1979年)提出的,它包括三个中心观点:分类(categorization)、认同(identity)和比较(comparison)(因此又被称为CIC理论)。 首先是分类,分类不仅帮助我们将众多的人简单化,而且也界定了某类人是怎样的。如果知道了某人属于某个类别,然后就可以推论出许多关于他的信息。同样,通过了解自己所属类别可以更好地发现与自己有关的信息。可见刻板印象是社会分类的直接结果。
分支界定算法及其在特征选择中的应用研究
分支界定算法及其在特征选择中的应用研究作者:王思臣于潞刘水唐金元 来源:《现代电子技术》2008年第10期 摘要:分支界定算法是目前为止惟一既能保证全局最优,又能避免穷尽搜索的算法。他自上而下进行搜索,同时具有回溯功能,可使所有可能的特征组合都被考虑到。对分支界定算法进行研究,并对其做了一些改进;最后对改进前后的算法在特征选择领域进行比较,选择效率有了明显的提高。 关键词:分支界定算法;特征选择;特征集;最小决策树;局部预测 中图分类号:TP31 文献标识码:A 文章编号:1004-373X(2008)10-142- (Qingdao Branch,Naval Aeronautical Engineering Institute,Qingdao, Abstract:Branch&Bound Algorithm is the only method which can ensure best of all the vectors,and it can avoid endless searching.It searches from top to bottom and has the function that from bottom to top,so it can include all of the feature vectors.The Branch&Bound Algorithm is studied in the paper,and it is improved,the two algorithms are compared by the feature seclection,the Keywords:branch&bound algorithm;feature selection;feature vector;minimum solution 随着科学技术的发展,信息获取技术的不断提高和生存能力的提升,对于目标特征能够获得的数据量越来越大,维数越来越高,一方面可以使信息更充分,但在另一方面数据中的冗余和无关部分也会相应的增多。特征选择[1,2]就是为了筛选出那些对于分类来说最相关的特征,而去掉冗余和无关的特征。 分支界定算法[1,3,4]是一种行之有效的特征选择方法,由于合理地组织搜索过程,使其有可能避免计算某些特征组合,同时又能保证选择的特征子集是全局最优的。但是如果原始特征集的维数与要选择出来的特征子集的维数接近或者高很多,其效率就不够理想。基于此,本文对分支界定算法做了一定的改进,经过实验验证,与改进前相比其效率有明显的提高。 1 分支界定算法的基本原理