非线性时间序列 第五章

127
第五章 非参数密度估计
5.1 引论
在非参数函数估计中,平滑是最基本的方法之一,通常被称为一维散点图平滑和密度估计. 在多维框架下,平滑是建立非参数估计的有用的构建模块. 平滑首先从时间序列中的谱密度估计中产生. 在对Bartlett (1946)的富有创新的文章的讨论中,Henry E. Daniels 指出,谱密度估计的一个可能的修正可以通过平滑周期图来实现. 然后,这一问题的理论和方法由Bartlett (1948,1950)系统地发展起来. 这样,早在半个世纪以前,平滑方法便已是时间序列分析的一个重要部分.
平滑问题在时间序列分析的各个方面经常出现. 平滑方法为概述一个给定的时间序列的边缘分布提供了有用的图解工具. 它们还可用于估计和消除慢变时间趋势. 这就产生了时域平滑. 研究一个时间序列和它的延迟序列联系的需要产生了状态域平滑. 这些方法能够容易地推广到估计一个时间序列的条件方差(波动性). 为了检验周期形式和别的特征,比如时间序列的功率谱,平滑方法常常用来估计谱密度. 在拟合一个时间序列数据时,一个重要的问题是拟合模型的残差的行为是否像白噪声. 对这类非参数拟合优度检验,非参数函数估计提供了有用的工具. 这个内容将本章和下一章中讨论.
最简单的非参数函数估计问题可能是密度估计. 这种简单结构对理解非参数建模和推断中更复杂的问题提供了有用的工具. 这就是我们在本章中讨论非参数密度估计的目的.
5.2 核密度估计
国库券收益的分布是什么?直方图是回答这类问题的经典的方法. 核密度估计是对直方图方法的改善. 它用来验证数据集合的所有分布特征. 这些包括密度峰和谷的数目和位置以及密度的对称性. 它是揭示非参数函数估计基本特性的最简单的工具. 对密度估计和它的应用的全面的讨论在Devroye 和Gy ?rfi (1985),Silverman (1986)以及Scott (1992)给出.
给定T 个数据点1,,T X X ,通过对每一个观测点乘以量1/T 可得到这些数据点的
经验分布函数:
1
1()()T
t t F x I X x T ==≤∑.
这个累积分布函数是非降的,对验证给定分布的全面的结构不是太有用的. 当人们论及分布时,其脑海里常常有密度函数. 然而,经验分布函数的密度是不存在的. 对经验分布函
128
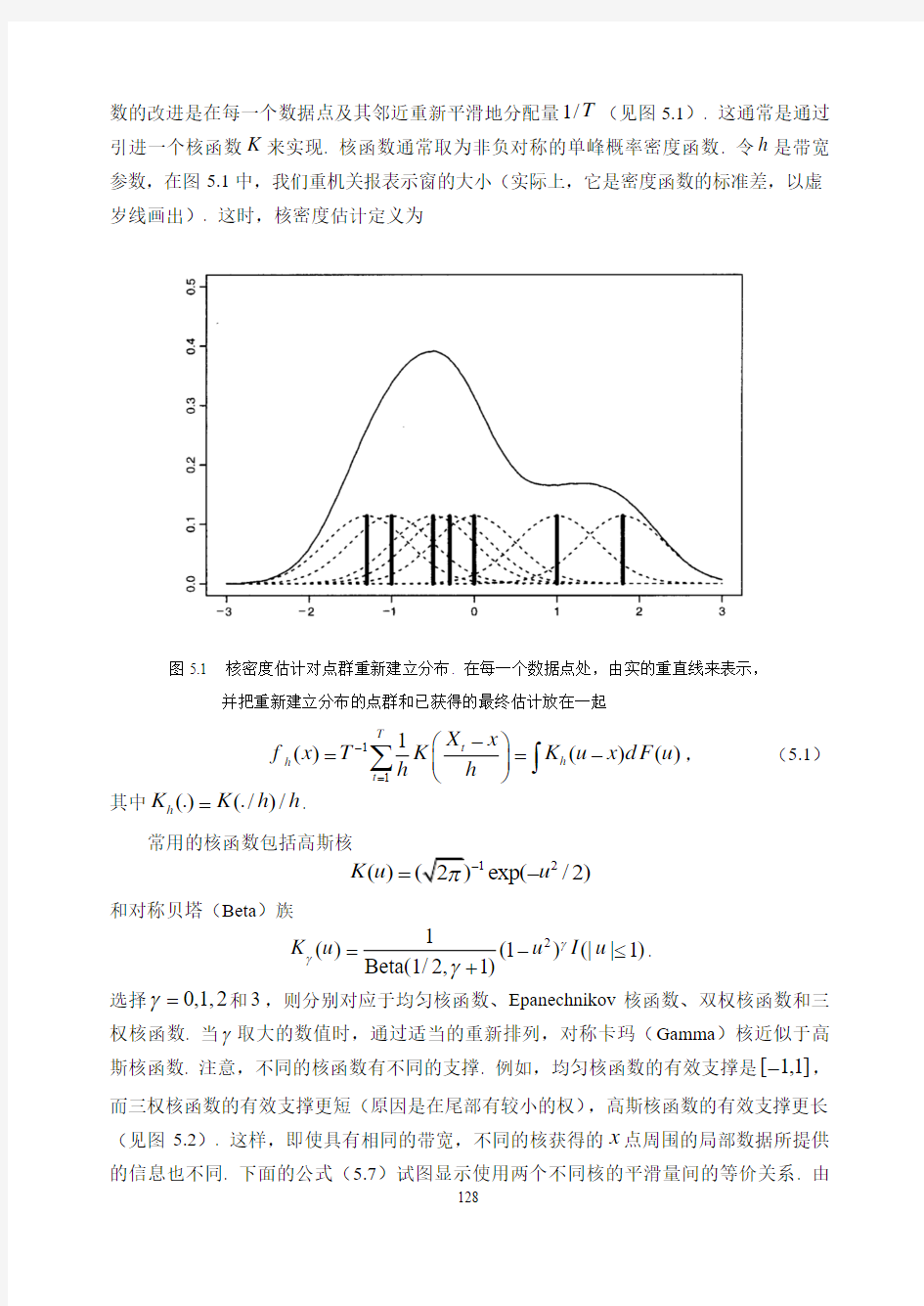
数的改进是在每一个数据点及其邻近重新平滑地分配量1/T (见图5.1). 这通常是通过引进一个核函数K 来实现. 核函数通常取为非负对称的单峰概率密度函数. 令h 是带宽参数,在图5.1中,我们重机关报表示窗的大小(实际上,它是密度函数的标准差,以虚岁线画出). 这时,核密度估计定义为
图5.1 核密度估计对点群重新建立分布. 在每一个数据点处,由实的重直线来表示,
并把重新建立分布的点群和已获得的最终估计放在一起
1
1
1()()()T
t h h t X x f x T
K K u x d F u h h -=-??==- ???∑?, (5.1) 其中()(/)/h K K h h ?=?.
常用的核函数包括高斯核
12()exp(/2)K u u -=-
和对称贝塔(Beta )族
21
()(1)(||1)Beta(1/2,1)
K u u I u γγγ=
-≤+.
选择0,1,2γ=和3,则分别对应于均匀核函数、Epanechnikov 核函数、双权核函数和三权核函数. 当γ取大的数值时,通过适当的重新排列,对称卡玛(Gamma )核近似于高斯核函数. 注意,不同的核函数有不同的支撑. 例如,均匀核函数的有效支撑是[1,1]-,而三权核函数的有效支撑更短(原因是在尾部有较小的权),高斯核函数的有效支撑更长(见图5.2). 这样,即使具有相同的带宽,不同的核获得的x 点周围的局部数据所提供的信息也不同. 下面的公式(5.7)试图显示使用两个不同核的平滑量间的等价关系.
由
129
Marron 和Nolan (1988)引入的经典核的概念减弱了这个问题.
图5.2 常用的核函数. 它们被标准化使得最大高度为1,以便于表示. 粗曲线是高斯核, 它比别的核有更长的有效支撑
为了使用核密度估计,人们需要选择核函数和带宽. 众所周知,对核密度估计,无论是从经验的角度,还是从理论的角度,核函数的选择都不是太重要的. 只要它们是对称和单峰的,当带宽h 是最优选择时,所得核密度估计的表现几乎都相同. 见§5.4中的表5.1. 这样,正如图5.3所示,在一个大的带宽h 下,得到一个过度平滑的估计,遗漏一些可能的细节,比如多峰情形和所得的估计密度低于峰值. 换句话说,使用大的带宽可能导致估计产生大的偏差. 当使用较小的带宽时,没有太多的局部数据点被使用,从而减少了估计的方差,其结果可能产生一条摆动的曲线. 为了得到满意的结果,我们需要反复试验. 带宽的数据驱动选择可以帮助我们确定最优的平滑量(更多的细节参阅§5.4).
如图5.3所示,描绘了用带宽分别为0.61/3,0.61h =和30.61?的高斯核所得的3个月期国库券收益的分布估计. S-Plus 函数“density ”被用来计算核密度估计. 带宽
0.61h =通过下面(5.9)所述的标准参考的带宽来选择,显然,小的带宽导致平滑不足
的估计,产生一个具有不自然摆动样式的密度函数,而大的带宽则给出一条过度平滑的曲线,使得原来分布好的结构变得模糊. 虽然所得的曲线稍微出现过度平滑,但简单的供参考带宽0.61h =通常被认为是对h 的一个初步选择.
正如在图5.3中所看到的那样,利率的分布有长的右尾. 分布的中位数和众数大约是5.34%,而均值是5.97%. 在1980年代初,利率高达
15%.
130
图5.3 用带宽分别为0.61/3h =(短划线),0.61(实线)和30.61?(长划线)的高斯核所得的3个 月期国库券收益(按百分率)密度估计. 因子3是有意用来解释平滑不足和平滑过度的影响
5.3 加窗和白化
如果数据1{}T t t X -是来自具有边缘密度f 的平稳过程的实现,则通过变量变换,我们有
()()
()()
h t h E f x EK X x K u f u hx du +∞-∞
=-=+?
. (5.2) 这样,估计的偏度()()h E f x f x -不依赖于数据的相依结构,就如同于独立样本那样. 然而,估计的方差却受数据相依结构的影响.
为了获得得进一步的认识,我们考虑K 有有界支撑[1,1]-的情形. 这时,核密度估计(5.1)仅用了在局部窗x h ±内的局部数据点:
1
()
1
()()J
h t j h j f x T
K X
x -==-∑,
其中()t j 是落在x h ±中的第j 个数据点,J 是局部数据点的总数. 当原始序列中的数据高相关时,在x 周围的局部窗内,新序列(){,1,,}j t j Y X j J ==的相依性可能相对很弱.
这归因于这样的事实,即时间序列{(),1,
,}t j j J =相对于小的带宽h 来说不得相隔很
远. 作为一个图例,参见5.4. 加拿大山猫数据的一步延迟自相关比局部窗2.70.2±内的那些数据相对很强. 实际上,局部数据看起来就像是来自一个独立样本的数据. 因此,当某种混合条件被使用时,人们将期望核密度估计的渐近方差如同独立观测情形那样. 这种直觉知识由Hart (1996)给予阐明. 由于在状态域中通过局部加窗所得的白化性质,使得混合过程的核密度估计所表现的行为非常像独立样本的情形. 因此,
对独立样本的所有方
131
法都可推广到混合平稳过程. 在§5.6中,我们将给出一些基本理论. 相依结构对核密度估计的影响最近由Claeskens 和Hall (2002)作了详尽的研究.
图 5.4 (a )加拿大山猫数据的延迟为1的散点图;(b )落在局部领域2.70.2±中那些数据
{,1,,}j Y j J =的延迟为1的散点图,它是点()t j X 相对于(1)t j X -画出的,用数()t j 表示点
(1)()(,)t j t j X X -;(c )用带宽0.14h =(实线)和0.23(虚线)所得的加拿大山猫数据的密度估计
5.4 带宽选择
当数据{}t X 是来自平稳过程的实现时,由下面的定理5.1,对f 支撑的内点x ,核密度估计的均方误差(MSE )能够表示为
2MSE(){()()}h x E f x f x ≡-
{}
2
2
2
421
()
(){()}()4
f x u K u du
f x h K u du Th
+∞+∞-∞
-∞
''≈
+?
?
(5.3)
这里及以后,“≈”意味着两边有相同的主项. 这是一个逐点度量.
通过使用平均平方积
132
分误差(MISE ),可获得全局度量如下:
2MISE {()()}h E f x f x dx +∞-∞
≡-?
{}
22242
11(){()}()4u K u du f x dxh K u du Th
+∞+∞+∞-∞-∞-∞''≈+???. (5.4) 调整带宽参数h 来极小公渐近MISE ,得到一个带宽,称为渐近最优带宽,或简单地,最
优带宽,它由下式给出
2/51/
o p t 2()||||h K f
T α--
''=,
(5.5) 其中222||||()g g u du +∞-∞
=
?
是2L 范数,22()()K u K u du μ+∞-∞
=?
是K 的方差,
2/52/522()()||||K K K αμ-=
是已知常数. 相对于这个渐近最优带宽,最优的MISE 是
2/54/5
25()||()||4
K f x T β-'', (5.6) 其中
2/58/522()()||||K K K βμ=.
由(5.5)得到,对两个不同的核函数1K 和2K ,最优带宽满足
1opt 1opt 22()
()()()
K h K h K K αα=
,
其中opt 1()h K 和opt 2()h K 分别是与核函数1K 和2K 相对应的最优带宽. 下面的表5.1对几个常用的核函数列出了这些有用的函数的值. 从该表可见,对使用最优带宽核函数的不同选择,它们执行的结果几乎完全相同(见表中()K β所在的行). 因此,核2K 用带宽2h 的执行的结果几乎和核1K 用如下带宽执行的结果相同
1122()
()
K h h K αα=
. (5.7)
这就是经典核概念的思想(Marron 和Nolan 1988). 它允许两个研究者比较平滑的量,即使他们用的是两个不同的核.
表5.1 一些与核函数相关的有用的常数
泛函
高斯 均匀 Epanechnikov 双权 三权 2()K μ
1 0.3333 0.2000 0.1429 0.1111 22||||K
0.2821 0.5000 0.0600 0.7143 0.8159 ()K α 0.7764 1.3501 1.7188 2.0362 2.3122 ()K β
0.3633
0.3701
0.3491
0.3508
0.3529
最优带宽(5.5)不是直接可用的,这是因为它依赖于未知的参数2||||f ''. 当f 是具
133
有标准差σ的高斯密度时,人们能够容易地由(5.5)推导出
1/51/5
o p t ,(/3)()T h K T
ασ-=. (5.8) 正态参考带宽选择(例如见Bickel 和Doksum, 1977及Silverman (1986))是通过在(5.8)中用样本标准差s 代替未知参数σ来获得得的. 特别地,在数值地计算了常数()K α后,我们有下列正态参考带宽选择
1/5o p t ,1/5
1.06,
2.34,E p a n e c h n i k o v n sT
h sT
--??=???对高斯核,对核. (5.9) 通过在高斯密度周围对f 作Edgeworth 展开可获得得一个改良的带宽选择. 这个带
宽选择由Hjort 和Jones (1996b )提供,由下式给出
1/5
*22opt,opt,43435
35385148321024T
T h
h γγγ-??=+++ ?
??
,
其中3γ和4γ分别是样本斜度和峰度,其定义为
1
3331(1)
()/T
t
t T X
X s γ-==--∑,
14441
(1)()/3T
t t T X X x γ-==---∑.
正态参考宽选择只是一个简单的经验方法. 当数据接近高斯分布时,它是一个好的选择,而且在许多应用中,常常是适当的. 然而,当真实分布是非对称或多峰时,它可能导致过度平滑. 在此情形,人们或者主观地调整带宽,或者用更精细的带宽选择方法来选择所要的带宽. 人们带可以先对数据做变换,使其分布接近于正态,然后,用正态参考带宽选择估计密度,再应用逆变换获得原始数据的密度估计. 这个方法被称为变换法. 见下面(5.12). 对由图5.3说明的非对称分布,正态参考带宽选择给出径微的过度平滑估计. 对图5.4(c )中的双峰数据,正态参考带宽选择是0.23h =,这导致一个过度平滑估计. 因此,址到获得一个适当的估计(图5.4中的实线)时,我们才减少平滑量.
有为数不多的几个重要的带宽选择方法,诸如cross-validation (CV )和plug-in 带宽选择. 理论上合理、经验上执行良好的概念上简单的方法是plug-in 方法. 该方法依赖于
在(5.5)中寻找泛函2
2||||f ''的一个估计. 这个方法的一个好的补充由Sheather 和Jones
(1991)提出. 带宽选择进展的一个总结可在Jones, Marron 和Sheather (1996)中找到. 还可参阅§6.3.5.
5.5 边界修正
在许多情况中,已知密度f 有一个有界的支撑. 例如,利率不能小于零. 一个自然的假定是利率有支撑[0,)∞. 事实上,过去的四十多年中,最低短期利率是2.11%,而最高利率是16.76%. 因此,假定短期利率有支撑区间[2%,17%]不是没有道理的. 然而,因为
134
核密度估计在观测数据点的周围平滑地散布点团,所以靠近支撑边界的一些点会分布在密度支撑之外(见图5.3). 故而核密度估计是在边界范围里估计密度. 如在图5.3所见,对大的带宽和对密度有高峰的左边界,问题更严重. 因此,做一些矫正是必需的. 为了获得一些进一步的知识,不失一般性,我们假定密度函数f 有有界的支撑[0,1],并在左边界处理密度估计. 为简单起见,假设K 有支撑[1,1]-. 则点(01)x ch c =≤<是左边界点. 易见,当0h →时,
()()()(0)()h c
c
E f ch f ch hu K u du f
K u du o ∞∞
--=
+=+?
?
. (5.10)
特别地,对对称核,(0)(0)/2(1)h E f f o =+. 另一方面,在左边界点,所得密度估计仅估计了真实密度的一半. 为了通过图例说明此点,我们从标准指数分布()e x p ()(0f x x I x =-≥抽取容量为200的随机样本,从(5.9)获得带宽0.344,用具有该带宽的高斯构成核密度估计,对密度进行估计. 明显地,在点0x =处的估计仅是真实值的一半.
有几个方法可以用来处理边界点的密度估计. 可能的方法包括边界核、反射、变换和局部多项式拟合. 这里我们介绍两个简单的方法:反射和变换方法. 反射方法是基于反射数据{,1,,}t X t T -=和原始数据{,1,,}t X t T =来构造核密
度估计. 所得的估计为
*
111()()(),0T T
h t h t h t t f x K X x K X x x T ==??
=-+--≥????
∑∑. (5.11)
注意,当x 偏离边界时,(5.11)中的第二项实际上是可被忽略的. 因此,仅需要修正边界附近的估计. 见Schuster (1985)及Hall 和Wehrly (1991). 这个估计是基于合成数据
{,1,,}t X t T ±=的两次核密度估计,一般地,如果左边界点是0x (代替0),则合成数据是
0{(),,1,
,}t t X x X t T --=,
所得的估计为
*
00111()()(),T T
h t h t h t t f x K X x K x X x x x T ==??
=-+--≥????
∑∑.
图5.5给出模拟数据,图5.6(a )描绘了基于这个方法给出的估计. 所用的核为高斯核,带宽为0.344.
另一个简单的方法是先对数据做如下变换
(),1,
,i t Y g X i n ==,
其中g 是从-∞到∞的单调增函数. 现在,应用核密度估计(5.1)到这个变换数据集,获得估计()Y f y ,再应用逆变换得到所要的X 的密度. 这就导致如下结果
1
1()()(())()(()())T
h t
X Y t f x g x f g x g x T K g x g X -=''==-∑
, (5.12)
135
图5.5 来自标准指数分布的容量为200n
=随机样本的核密度估计. 实线——真实曲线;
虚线——估计的曲线. 边界影响可被容易地看到
这里()g '?是()g ?的导函数. 图5.6(b )用对图5.5中的数据使用对数变换来说明这一想法. 我们首先应用核密度估计变换后的数据{log(),1,
,200}t X t -=,以获得()Y f y .
对变换数据使用高斯核,由高斯参考带宽选择得到0.344h =. 因此,所得密度估计是()(log )/X Y f x f x x =,
或(exp())exp()()X Y f x x f x =-. 这样,相对于exp()()Y x f x -画exp()x ,可得所要的密度估计. 在点0x =处的密度对应变换数据密度的尾部,注意到
log(0)=-∞,由于在尾部缺乏数据的原因,通常密度不能被很好地估计. 除了在这一点
处,变换方法有很好的表现.
图5.6 (a )用反射方法所得的核密度估计;(b )用变换方法所得的核密度估计. 实线——真实曲线; 虚线——估计的曲线
136
5.6 渐近结果*
我们现在给出当样本容量T →∞时,核密度估计的渐近偏度和方差. 必然地,带宽h 要依赖于T ,而且趋于零. 用在这里的想法能够推广到更复杂的结构,比如非参数回归. 我们从一个简单的引理开始,它对导出渐近偏度是有用的.
引理 5.1 令f 在其支撑的内点x 有连续的有界p 阶导数. 假定函数K 满足
|()|p u K u du +∞-∞
<∞?
. 则当0h →,我们有
()0
()()()()/!()p
i i p i i f x hu K u du K f x h i o h μ+∞-∞
=+=+∑?
,
其中()()i i K u K u du μ+∞-∞
=
?
.
证明 令()0()()()()/!p i i i i D f x hu K u du K f x h i μ+∞=-∞
=
+-∑?
,则
()0
{()()()/!}()p
i i i D f x hu f x hu i K u du +∞-∞
==+-∑?
.
由泰勒展开可得,
()(){()()}()!
p p p p
h D f x T f x u K u du p ξ+∞-∞=+-?, 其中T ξ介于0和hu 之间. 勒贝格控制收敛定理的简单应用可得
/0,0p D h h →→.
这就完成了证明.
注意,当核函数K 有有界支撑时,以上积分取值范围仅是x 的一个邻域. 因此,只需假定密度f 在点x 处有连续的p 阶导数. 鉴于这个原因,为简单的缘故,常假定K 有有界支撑. 去掉这个假定将以冗长的论证作为代价. 特别地,高斯核被允许作为核函数. 使用以上引理和(5.2),对满足下式的核函数
()1,
()0K u du uK u du +∞+∞-∞
-∞
==?
?
,
在f 有连续的二阶导数的条件下,我们即得核密度估计的偏倚为
222()
()()2
K f x h o h μ''+.
如果f 有更高阶的导数,通过要求以下条件,可得偏倚的阶为()p O h
0()1,()
0,1,,1j K K j p μμ===-, (5.13)
但是,所得结论通常对实际的样本大小不是本质的. 满足(5.13)的核称为p 阶核. 当
2p >时,由于2()0K μ=,K 不能再是非负的.
现在,我们返回到计算方差分量. 为此,我们假定过程{}t X 是有α混合系数()k α的
137
平稳过程. 进一步,令(,)g x y l 是1X 和1X +l 的联合密度.
定理 5.1 令{}t X 是一个具有混合系数|()|C βα-≤l l 的α混合过程,其中
0,2C β>>. 进一步假定(,)||||sup (,)x y g g x y ∞=l l 是有界的. 假设K 是具有有界支撑
的有界核函数,满足1()0,0K h μ=→,进而Th →∞. 如果f 在其支撑的内点x 处有连续的二阶导数,则有
222()
()()()()2
h K E f x f x f x h o h μ''=+
+
和
22
()1
Var{()}||||()h f x f x K o Th Th
=
+. 证明 由引理5.1直接得到偏度的表达式. 这样,仅需导出方差项的渐近表达式. 令
()t h t Z K X x =-. 则由{}t X 的平稳性,我们有
1
1111
12Var(())Var()(1/)Cov(,).T l h f x Z T Z Z T T -+==+-∑l l
注意,1()(1)h EZ E f x O ==. 由变量变换和引理5.1. 可得
2211()()()h t Var Z EK X x EZ =--
1
221()()()h K u f x hu dx EZ +∞--∞
=+-?
1
2
1
2()||||()h f x K o h --=+. 于是,我们仅需证明
1
11
1
1
|Cov(,)|()T Z Z o h --+==∑l l
. (5.14)
由Billingsley 不等式[命题2.5之(ii )],我们有
2
21111|Cov(,)|4()||||||||4()||||/Z Z Z Z K h αα+∞+∞∞≤≤l l l l . (5.15)
另一方面,
211111|Cov(,)||()|Z Z EZ Z EZ ++=-l l
21()()(,)()h h K u x K v x g u v dudv EZ +∞+∞-∞
-∞
≤
--+??
l
2
1||||()g EZ ∞≤+l . (5.16)
因此,协方差有常数C 为界.
我们现在验证(5.14). 令T d →∞是一个整数序列. 则由(5.16)得
11
1
1
|Cov(,)|T d T Z Z Cd -+=≤∑l l
.
由(5.15)和混合系数的假定,对某个常数D ,我们有
138
1
21
21
1
|Cov(,)|/(/)T
T
T T d d Z Z D h O d h ββ-∞
--++==≤=∑∑l l
l l ,
取2/T d h β-=,对2β>,我们有
1
2/11
1
|Cov(,)|()(1/)T Z Z O h o h β
--+===∑l l . 因此,获得得(5.14). 这就完成了证明.
逐点均方误差可分解成如下的偏度和方差表示:
2MSE(){()()}h x E f x f x =-
2{()()}Var{()}h h E f x f x f x =-+.
由定理5.1,MSE 的逼近由(5.3)给出. 相对于h ,极小化(5.3)的右边,在()0f x ''≠的条件下,得到渐近逐点最优带宽
2/51/51/5()(){()}()opt h x K f x f x T α--''=.
最小(理想)风险,即MSE ()x 的主阶逼近的最小值,由下式给出
2/54/54/5
5()()()4
K f x f x T β-'', (5.17) 其中()K β在(5.6)中给出. 类似地,极小化(5.4)的右边得到最优带宽(5.5)和(5.6)中最小的(理想)MISE. 因此,通过开方,核密度估计的收敛速度可达到2/5
T
-. 对某个
0c >,只要1/5h cT -=,就可达到这个速度. 按照Farrell (1972),Hasminskii (1978)
和Stone (1980),在具有二阶有界导数的函数类中,这是估计密度函数可能达到的最快速度.
核密度估计的渐近正态性仍然成立. 我们不加证明地叙述这个定理,它非常类似于定理6.3的证明. 我们将它留给读者作为练习. 如果混合条件()||,2c β
αβ-≤>l l ,被加
强,则条件5/3
Th
→∞能够被放松.
定理5.2 在定理5.1的条件下,如果5/3
Th →∞,则我们有
222
22()
()()()()}N(0,()||||)2
D h K f x f x f x h o h f x K μ''--
+??→.
核密度估计具有许多好的性质. 可参阅Bosq (1988)的第二章. 我们证明一个类似于Bosq (1988)定理2.2的结果,但显著地放松了对几何混合条件的要求.
定理5.3 假定过程{}t X 的混合系数满足(),5/2c β
αβ-≤>l l . 设t X 的密度f 在
区间[,]a b 上是有界的,K 满足Lipschitz 条件. 则
1/2
[,]log sup |()()|P h h x a b T f x E f x O Th -∈????
??-=?? ???????
,
其中h 以下列方式0→,
139
2525(21)/4(log )T h T βββ-+-+→∞.
作为定理 5.3的一个推论,当过程是几何混合时,即()c αρ c ρ>∈,对任意的(0,1)γ∈和0, d h dT γ->=,定理5.3成立. 定理5.3 一致地控制着核密度估计的随机误差. 偏度项()()h E f x f x -是确定性的,且由引理5.1,容易得到它的一致有界性. 它有阶2()O h . 通过选择1/5((log /))h O T T =,当()c βα-≤l l ,其中15/4β>,得到 [,] [,] [,] sup |()()|sup |()()|sup |()()|h h h h x a b x a b x a b f x f x E f x f x f x E f x ∈∈∈-≤-+- 2/5{(log /)}P O T T =. 按照Hasminskii (1978),这个速度是最优的. 一致收敛更精确的描述由Bickel 和Rosenblatt (1973)给出. 他们对独立样本导出了如下标准化统计量的渐近分布 21/2201 sup[()||||/()] (()())T h h x M f x K Th f x E f x -≤≤=-. 我们期望在一定的混合条件下,结论对平稳过程还成立. 这里使用区间[0,1]是为了方便. f 的支撑可以被任意区间所代替. 我们要求密度f 在[0,1]上是连续的和正的,而且 1/2()/()f x f x '和()f x ''在[0,1]上是有界的. 假定K 是有界的,且关于0点对称. 此外,K 或者在区间[,]A A -外为零,且在[,]A A -上绝对连续,并有导数K ',或者在(,) -∞∞绝对连续使得22(), ()K K μμ'和2||||K '是有限的. 定理 5.4 在以上条件下,如果1, ,T X X 是独立同分布的,h cT δ-=,其中 01/2δ<<,0c >,如果22 2()()/||||0c K K A K =>,则令 1/21/21/2(2log )(2log ){log ()/0.5loglog }T d h h c K h π-=-+--, 否则,令 21/2 1/2 2 22 ||||(2log ) (2log ) log 4||||T K d h h K π-'=-+-. 我们有 {}1/2(2log )()exp(2exp())T T P h M d x x --<→--. 定理5.4的一个推论是1/2 {(log )}T p M O h =-. 由此得到 1/201 sup{()()}[{(log )/()}]P h h x f x E f x O h Th ≤≤-=-, 即与定理5.3给出的阶相同. 定理5.4的一个应用是对一切的{(),[0,1]}f x x ∈,构造联合置信区间. 实际上,由定理5.4,相对于逼近概率1α-, 1/21 (2log )log{log(1)}(,)2 T T M d h c h αα-≤----≡. 以上表达式等价于 140 21/2 2 ()()(,)[()]||||/(),[0,1]h h E f x f x c h f x K Th x α∈±?∈. 用定理5.1得到,2()()()h E f x f x O h =+. 把它代入上面最后表达式,并用估计来代替 ()f x ,如果1/5{(log )}h o T T -=,则我们得到一个逼近水平为(1)α-的置信区间: 21/22()()(,)[(||||/())],[0,1]h h f x f x c h f x K Th x α∈±?∈. 最后,我们将对最优核作一些注释. 关于核函数选择的最优理论能够在Gasser, Müller 和Mammitzsch (1985)及Müller (1991,1993)中找到. 理想的逐点MSE (5.17)和理想的MISE (5.6)通过(5.6)中给出的()K β而依赖于K . 定理 5.5表明,最优核是Epanechnikov 核. 对核密度估计来说,这个结果归功于Epanechnikov (1969). 但是,这个结果早已出现在稳健回归估计的文献中(见Lehmann1983第384页和那里的文献). 这个核已被Bochener (1936)在傅里叶变换和Parzen (1961)在谱密度估计中用作收敛因子. 对这个已知的最优核,它能够容易地被计算. 对其他常用的核,其()K β的值接近于最优核的值. 见表5.1中()K β所在行. 定理5.5 使()K β达到极小的非负概率密度函数K 是Epanechnikov 核的一个尺度改变: 22opt 3 ()(1/)4K u u a a += -,对任意的0.a > 证明 首先,我们注意到,对任意的0h >,()()h K K ββ=. 令0K 是Epanechnikov 核. 对任意别的非负K ,如果必要,通过变换尺度,我们假定220()()K K μμ=. 这样,我们仅需证明0||||||||K K ≤. 令0K K δ=-. 则 2()0, ()0u du u u du δδ+∞+∞-∞ -∞ ==? ? . 并蕴涵了 2(1)()0u u du δ+∞-∞ -=?. 由此式和0K 有支撑[1,1]-的事实,我们有 20||1()()()(1)u u K u du u u du δδ+∞≤-∞ =-? ? 2||1 ()(1)u u u du δ>=--? 2||1 ()(1)u K u u du >= -? . 由于K 是非负的,故上面最后一项也是非负的. 因此, 22200()()2()()()K u du K u du K u u du u du δδ+∞+∞+∞+∞-∞ -∞ -∞ -∞ =++??? ? 20()K u du +∞-∞ ≥? , 这就证明了0K 是最优核. 141 5.7 补充——定理5.3的证明 在这一节中,我们都用C 表示一般常数,在同一表达中是可变的. 我们首先把在区间[,]a b 上的上确界问题转变为在区间上的点格的极大化问题. 为此目的,我们把区间[,]a b 分割成N 个长度相等的子区间{}j I . 令{}j x 是j I 的中心. 由于 K 满足Lipschitz 条件,我们概率为1地有 1 1 1 |()()||()()|||T h t h t h h t f x f x T K x X K x X Ch x x --='''-≤---≤-∑. 由此得到 1|()()||()()|||h h h h E f x E f x E f x f x Ch x x -'''-≤-≤-. 由上述不等式,我们有 1sup |()()||()()|()j j j h h h h x I f x E f x f x E f x C Nh -∈-≤-+. 于是, 11[,] sup |()()|max |()()|()j j h h h h j N x a b f x E f x f x E f x C Nh -≤≤∈-≤-+. 取1/2(/)N T h =,我们得到 1/2 1[,] s u p |()()| m a x |()()|()j j h h h h j N x a b f x E f x f x E f x C Th -≤≤∈-≤-+. (5.18) 现在,我们来估()()h h f x E f x -的尾部概率的界. 令()()t h t h t Y K x X EK x X =---,则1||||t Y Ch -∞<. 由指数不等式(定理2.18)对任意的0ε>和每一个整数[1,/2]q T ∈,我们有 22{|()()|}4exp 8()h h q P f x E f x v q εε?? ->≤- ??? 1/2 42212C T q h q αε?????? ++?? ????????? , (5.19) 其中 222()2()//(2)v q q p C h σε=+ 这里[/(2)]p T q =和 21(1)1021 ()max Var{}jp j p j q q Y Y σ+++≤≤-=+ +. 由定理5.1,21 ()q Cph σ-≤. 这样,取q T ε=, 2111()()v q C ph C h C h εε---≤+≤. 上式和(5.19)蕴涵了 21/20. {|()()|} 4e x p ()h h P f x E f x CTh CTh βεεε -+->≤-+. (5.20) 142 我们现在来证明定理. 对充分大的a ,取2log /()a T CTh ε=,(5.20)的右边被下式所界 /20.75/20.75/20.254(log )a T CT h T βββ--+--++. 因此, 1(max |()()|)j j h h j N P f x E f x ε≤≤-> /20.75/20.75/20.25{4(log )}a N T T h T βββ--+--+≤+ (25)/45/2(21)/4(1){()(log )}o O Th h T ββ---+=+ 它是趋于零的. 由此可得 1/2 1log max |()()|j j p h h j N T f x E f X O Th ≤≤???? ??-=?? ??????? , 联合(5.18)便证明了定理. 5.8 文献注释 非参数平滑的文献量是很大的,其遍布的范围包括核密度估计、非参数回归、时域平滑、谱密度估计和在别的统计估计中的应用. 实际上,大多数参数问题都有它们的非参数配对物. 大多数非参数的结果都能由独立数据推广到相依数据. 在过去的三十年中,非参数函数估计是最活跃的领域之一. 许多新的方法已经被发明,许多新的现象被公诸于众. 不可能对这个庞大领域给出一个全面的评述. 更确切地,我们仅从这个活跃的领域中抽取一小部分参考文献. 它们甚至也不能代表这个领域的许多重要贡献. 在这个文献注释中,列在§1.7的有关非参数函数估计的著作对独立数据给出了大量详细的讨论. 相关的文献能够在第6章和第7章中找到. 对相依数据非参数函数估计的广泛而详尽的处理方法能够在Gy ?rfi, H?rdle, Sarda 和Vieu (1990),Rosenblatt (1991)和Bosq (1998)等专著中找到. 它们把重点主要放在单变量非参数平滑的理论发展上. 对独立数据的密度估计 关于核密度估计有大量的文献. 大多数研究工作的重点是在独立随机样本方面. 核密度估计的基本思想出现在Fix 和Hodges (1951)的技术报告中. 渐近均方误差和渐近平均平方积分误差被Rosenblatt (1956),Parzen (1962)及Watson 和Leadbetter (1963)所研究. 关于核密度估计有许多著作,包括Devroye 和Gy ?rfi (1985),Silverman (1986),Scott (1992),Wand 和Jones (1995)等. 核密度估计的各种性质能够在Prakasa Rao (1983)和Nadaraya (1989)的著作中发现. 核密度估计的性质已被广泛的研究. 为减小偏度而使用高阶核的思想可追溯到Parzen (1962)和Bartlett (1963). Davis (1975)对超平滑密度用正弦核获得了一个接近 1/2 n相合估计. 最优核理论由Gasser, Müller和Mammitzsch(1985),Granovsky和Müller (1991),Müller(1993)等做了广泛的发展. 密度估计的最优收敛速度由Farrell(1972)研究. Hasminskii(1979)和Stone(1980,1982)做了进一步的研究. Ibragimov和Hasminskii(1984),Donoho和Liu(1991a,b),Fan(1993b),Low(1993)等推广到极小极大研究的范围. Sobolov空间上更深刻的渐近极小极大风险由Pinsker(1980),Efromovich和Pinsker(1982),Nussbaum(1985)等建立. 这些最优收敛速度依赖于未知函数的平滑程度. 自适应方法已被构造使其对每一个给定的函数类都几乎是最优的. 例如,见Efromovich(1985),Lepski(1991),Donoho 和Johnstone(1995,96,98),Donoho,Johnstone,Kerkyacharian和Picard(1995),Brown 和Low(1996)及Tsybakov(1998)等. 基于罚最小二乘的自适应估计能够在Barron,Birgé和Massart(1999)及Antoniadis和Fan(2001)中找到. 非线性泛函的极小极大的结果可以Bickel和Ritov(1988),Fan(1991),Birgé和Massart(1995)等中找到. 有许多核密度估计的变种和修正. 密度的局部似然估计可以在Loader(1996)及Hjort 和Jones(1996)中找到. 参数控制的非参数密度和回归估计由Hjort和Glad(1995),Efron 和Tibshirani(1996),Glad(1998)等提出. 核密度估计的变换方法被Wand,Marron和Ruppert(1991),Yang和Marron(1999)等研究. 使用可变带宽的思想能够在Breiman,Meisel和Purcell(1977),Abramson(1982),Hall和Marron(1988),Hall(1990)以及其中所列的别的文献中找到. 文献中许多文章对减小边界偏度提供了可能的入门知识. 边界核方法由Gasser和Müller(1979),Gasser,Müller和Mammitzsch(1985)引进并进行研究. Schucany和Sommers(1977),Rice(1984)建议使用具有不同带宽的两个核估计的线性组合来减小偏度. 对平滑样条的边界修正方法被Rice和Rosenblatt(1981),Eubank和Speckman(1991)及其文中所列文献研究. 对相依数据的密度估计 相依数据核密度估计的早期文献是Roussas(1967,1969)和Rosenblatt(1970),他们建立了局部渐近正态性. 估计转移概率密度的强相合性由Yakowitz(1979)建立. Ahmad (1979,1982)使用正交理论方法研究了 混合过程密度估计的相合性质. Masry(1983)对连续时过程离散时估计的偏度和协方差导出了渐近表达式. 还可见Robinson(1983). 对时间序列残差的密度估计由Robinson(1987)给出. Cheng和Robinson(1991)对强相依数据的密度估计建立了各种性质. 一致强相合速度由Pham和Tran(1991),Cai和Roussas(1992)等建立. Gy?rfi和Masry(1990)证明了相依数据递推密度估计的强相合性. Kim和Cox(1995)对混合随机变量给出了关于矩的有用的界. 随机场的密度估计由Roussas(1995),Carbon,Hallin和Tran(1996),Bradley和Tran(1999)等及其所列文献给予研究. Gy?rfi和Lugosi(1992)给出了一个核密度估计不相合的有趣的例子. Adams 和Nobel(1998)研究了遍历过程的密度估计. 在核密度估计的MISE,ISE和最优带宽方面相依性的影响被Claeskens和Hall(2002)彻底研究. 143 第五章时间序列分析 一、单项选择题 1.构成时间数列的两个基本要素是( C )(2012年1月) A.主词和宾词 B.变量和次数 C.现象所属的时间及其统计指标数值 D.时间和次数 2.某地区历年出生人口数是一个( B )(2011年10月) A.时期数列 B.时点数列 C.分配数列 D.平均数数列 3.某商场销售洗衣机,2008年共销售6000台,年底库存50台,这两个指标是( C ) (2010年10) A.时期指标 B.时点指标 C.前者是时期指标,后者是时点指标 D.前者是时点指标,后者是时期指标 4.累计增长量( A ) (2010年10) A.等于逐期增长量之和 B.等于逐期增长量之积 C.等于逐期增长量之差 D.与逐期增长量没有关系 5.某企业银行存款余额4月初为80万元,5月初为150万元,6月初为210万元,7月初为160万元,则该企业第二季度的平均存款余额为( C )(2009年10) 万元万元万元万元 6.下列指标中属于时点指标的是( A ) (2009年10) A.商品库存量 B.商品销售量 C.平均每人销售额 D.商品销售额 7.时间数列中,各项指标数值可以相加的是( A ) (2009年10) A.时期数列 B.相对数时间数列 C.平均数时间数列 D.时点数列 8.时期数列中各项指标数值( A )(2009年1月) A.可以相加 B.不可以相加 C.绝大部分可以相加 D.绝大部分不可以相加 10.某校学生人数2005年比2004年增长了8%,2006年比2005年增长了15%,2007年比2006年增长了18%,则2004-2007年学生人数共增长了( D )(2008年10月) %+15%+18%%×15%×18% C.(108%+115%+118%)-1 %×115%×118%-1 二、多项选择题 1.将不同时期的发展水平加以平均而得到的平均数称为( ABD )(2012年1月) A.序时平均数 B.动态平均数 C.静态平均数 D.平均发展水平 E.一般平均数2.定基发展速度和环比发展速度的关系是( BD )(2011年10月) A.相邻两个环比发展速度之商等于相应的定基发展速度 B.环比发展速度的连乘积等于定基发展速度 近代时间序列分析选讲: 一. 非线性时间序列 二. GARCH模型 三. 多元时间序列 四. 协整模型 非线性时间序列 第一章.非线性时间序列浅释 1.从线性到非线性自回归模型 2.线性时间序列定义的多样性第二章. 非线性时间序列模型 1. 概述 2. 非线性自回归模型 3.带条件异方差的自回归模型 4.两种可逆性 5.时间序列与伪随机数 第三章.马尔可夫链与AR模型 1. 马尔可夫链 2. AR模型所确定的马尔可夫链 3. 若干例子 第四章. 统计建模方法 1. 概论 2. 线性性检验 3.AR模型参数估计 4.AR模型阶数估计 第五章. 实例和展望 1. 实例 2.展望 第一章.非线性时间序列浅释 1. 从线性到非线性自回归模型 时间序列{x t}是一串随机变量序列, 它有广泛的实际背景, 特别是在经济与金融领域中尤其显著. 关于它们的从线性与非线性概念, 可从以下的例子入手作一浅释的说明. 考查一阶线性自回归模型---LAR(1): x t=αx t-1+e t, t=1,2,…(1.1) 其中{e t}为i.i.d.序列,且Ee t=0, Ee t=σ2<∞, 而且e t与{x t-1,x t-1,…}独立. 反复使用(1.1)式的递推关系, 就可得到 x t=αx t-1+e t = e t + αx t-1 = e t + α{ e t-1 + αx t-2} = e t + αe t-1 + α2 x t-2 =… = e t + αe t-1 + α2e t-2 +…+ αn-1e t-n+1 +αn x t-n. (1.2) 如果当n→∞时, αn x t-n→0, (1.3) {e t+αe t-1+α2e t-2+…+αn-1e t-n+1} →∑j=0∞αj e t-j . (1.4) 虽然保证以上的收敛是有条件的, 而且要涉及到具体收敛的含义, 但是, 对以上的简单模型, 不难相信, 当|α|<1时, (1.3)(1.4)式成立. 于是, 当|α|<1时, 模型LAR(1)有平稳解, 且可表达为 x t=∑j=0∞αj e t-j . (1.5) 通过上面叙述可见求LAR(1)模型的解有简便之优点, 此其一. 还有第二点, 容易推广到LAR(p)模型. 为此考查如下的p阶线性自回归模型LAR(p): 第25卷 增1 岩石力学与工程学报 V ol.25 Supp.1 2006年2月 Chinese Journal of Rock Mechanics and Engineering Feb.,2006 收稿日期:2005–11–05;修回日期:2005–12–02 基金项目:国家重点基础研究发展规划(973)项目(2002CB412707);国家自然科学基金重点项目(50539110) 作者简介:周家文(1982–),男,2003年毕业于华东交通大学建筑工程系,现为博士研究生,主要从事岩石力学方面的研究工作。E-mail :hhzjw@https://www.360docs.net/doc/cf4698976.html, 高边坡开挖变形的非线性时间序列预测分析 周家文,徐卫亚,石安池 (河海大学 岩土工程研究所,江苏 南京 210098) 摘要:在岩体高边坡开挖过程中,可以得到现场的位移监测数据,如何利用现场监测数据来预测高边坡的开挖变形是一件很有实用价值的工作。根据高边坡开挖变形时间序列的非线性特征,应用局域法对三峡高边坡的位移进行了预测分析。把局域法的思想引入到神经网络中去,按照寻找邻近点的原理构造出训练样本,通过神经网络得到的预测值与局域法得到的预测值很接近,并且可以大大地节约计算时间。计算结果表明,对于岩土体工程中的一维监测数据,通过非线性时间序列分析方法可以对其进行预测分析,该方法具有较高的实用价值。 关键词:岩石力学;开挖变形;非线性时间序列;局域法;混沌;神经网络 中图分类号:TU 457 文献标识码:A 文章编号:1000–6915(2006)增1–2795–06 APPLICATION OF NONLINEAR TIME SERIES ANALYSIS TO EXCAVATION DEFORMATION PREDICATION OF HIGH SLOPE ZHOU Jiawen ,XU Weiya ,SHI Anchi (Institute of Geotechnical Engineering ,Hohai University ,Nanjing ,Jiangsu 210098,China ) Abstract :In the course of high rock slope excavation ,the deformation data in the locale can be monitored ,and it ′s useful to predicate the excavation deformation of high slope with the monitor data. According to the nonlinear characteristics of the excavation deformation of high slope ,the displacements of the high slope of the Three Gorges are predicted by local-region method. The idea of the local-region method is introduced to the neural network ,and the training samples are formed according to the theory of finding near points. The predicated displacements by the trained neural network are very close to those by the local-region method ,and computational time is saving. The result shows that ,based on the one-dimensional monitoring data ,the displacement can be predicted by the method of nonlinear time series ,and the method has practical value. Key words :rock mechanics ;excavation deformation ;nonlinear time series ;local-region method ;chaos ;neural network 1 引 言 在岩体开挖过程中,通过对高边坡的长期监测,可以得到现场的位移监测数据,如何利用现场监测来预测高边坡的开挖变形是一件很有实用价值的工作[1]。岩石的开挖位移是一个受到多种因素影响的 复杂的非线性动力系统,如果直接通过建立开挖过程中的非线性动力学方程来进行相关分析或者是预测分析是一件很困难的事情,寻找一种可以避开上述难题来解决开挖过程中的反分析问题成了很有实际意义的研究工作。近年来,鉴于边坡变形的非线性特征和影响因素的模糊不确定性,黄志全等[2]提出了基于神经网络的边坡位移预测方法;李邵军 第五章时间序列的模型识别 前面四章我们讨论了时间序列的平稳性问题、可逆性问题,关于线性平稳时间序列模型,引入了自相关系数和偏自相关系数,由此得到ARMA(p, q)统计特性。从本章开始,我们将运用数据开始进行时间序列的建模工作,其工作流程如下: 图5.1 建立时间序列模型流程图 在ARMA(p,q)的建模过程中,对于阶数(p,q)的确定,是建模中比较重要的步骤,也是比较困难的。需要说明的是,模型的识别和估计过程必然会交叉,所以,我们可以先估计一个比我们希望找到的阶数更高的模型,然后决定哪些方面可能被简化。在这里我们使用估计过程去完成一部分模型识别,但是这样得到的模型识别必然是不精确的,而且在模型识别阶段对于有关问题没有精确的公式可以利用,初步识别可以我们提供有关模型类型的试探性的考虑。 对于线性平稳时间序列模型来说,模型的识别问题就是确定ARMA(p,q)过程的阶数,从而判定模型的具体类别,为我们下一步进行模型的参数估计做准备。所采用的基本方法主要是依据样本的自相关系数(ACF)和偏自相关系数(PACF)初步判定其阶数,如果利用这种方法无法明确判定模型的类别,就需要借助诸如AIC、BIC 等信息准则。我们分别给出几种定阶方法,它们分别是(1)利用时间序列的相关特性,这是识别模型的基本理论依据。如果样本的自相关系数(ACF)在滞后q+1阶时突然截断,即在q处截尾,那么我们可以判定该序列为MA(q)序列。同样的道理,如果样本的偏自相关系数(PACF)在p处截尾,那么我们可以判定该序列为AR(p)序列。如果ACF和PACF 都不截尾,只是按指数衰减为零,则应判定该序列为ARMA(p,q)序列,此时阶次尚需作进一步的判断;(2)利用数理统计方法检验高阶模型新增加的参数是否近似为零,根据模型参数的置信区间是否含零来确定模型阶次,检验模型残差的相关特性等;(3)利用信息准则,确定一个与模型阶数有关 非线性时间序列模型的波动性建模 Song-Yon Kim and Mun-Chol Kim 朝鲜平壤金日成综合大学数学学院 本文出自于2011年5日朝鲜平壤举行的第一届PUST国际会议 本版修订于2013年11月3日 摘要:在本文中的非线性时间序列模型被用来描述金融时间序列数据的波动。描述两种由波动的非线性时间序列组合成TAR(阈值自回归模型)与AARCH(非对称自回归条件异方差 模型)的误差项和参数估计的研究。 关键词:非线性时间序列模型;波动;ARCH(自回归条件异方差模型);AARCH;TAR;QMLE(拟极大似然估计) 一介绍 在金融市场中,资产价格的波动是一个极其重要的变量,其建模在投资,货币政策,金融风险管理等方面中有重要意义 在投资持有期的资产价格波动的一个很好的预测是评价投资风险的一个很好的起点。资产价格波动是金融衍生证券定价的最重要的变量。对于定价我们需要知道的波动性范围是从现在相关资产,直至期权到期。事实上,市场惯例是根据波动单位列出价格期权。如今,波动性的定义和测量可能在衍生工具合约明确规定。在这些新的合同,波动成为潜在的“资产”。波动率模型已成为一个在金融时间序列模型分析的主要对象并且使许多科学家沉浸其中。 其中σ称为波动,在上面的公式中所示,σ准确估计成为期权定价和估计的一个非常重要的问题。此外,如对关联时间t 的波动σt 的估计等问题开始提出。 1982,罗伯特恩格尔提出了一个新的模型来用一个更准确的方法[ 7 ]对波动作出估计。他重视ARCH 模型中的误差项,这是大多线性时间序列模型如AR 、ARMA 、ARIMA 等所忽略的。同时他提出一种新的非线性模型,通过相加取代简单的白噪声,误差项的条件异方差性偏差的变化自动回归。误差项的条件异方差性偏差的 自动回归 1986年,Bollerslev 将Engle 的 ARCH (q)模型修改变为GARCH (p, q) model [8]. ???? ???++==∑∑==--q i p i i t i i t i t t t t t h h d i i z h z 112021..:,βεααε 在他的论文中,他提出了GARCH (1,1)过程中的存在,静止状态和MLE (最大似然估计)。 此后,大量ARCH 模型相继被开发出来,例如ARCH-M ,IGARCH 和LogGARCH 等。 在整个研究中,波动性已被证明是更受“坏消息”,而不是“好消息”的影响,也就是说,是不对称的,这导致对非对称模型的研究。 1991年,Nelson 提出了指数GARCH 模型(EGARCH )描述了不对称冲击。[ 6 ] () ()()x E x x x g g h t t t -+=-+-+=λωεγγ11h 10 但在许多研究论文,有效的参数估计和固定的条件是没有明确解释的,而且这种困难难以克服[ 9 ]。 但在1993,Glosten 开始使用阈值自回归条件异方差(TARCH )模型和其后提出的许多非对称模型[ 2 ],试图对不对称的波动进行建模。 特别是在2003年,Wai Mi Bei 开发了非对称ARCH (q )模型[ 10 ]。 ()∑∑==---+++=q i p j j t j i t i i t i t h 1120H γεβεαα 直到现在,持续的研究正在努力拟出更好的波动模型以显示各种ARCH 模型的影响。 在本文中,利用非线性时间序列模型的波动性建模是基于对前人研究成果分析的观察而得出。 第5章 单变量非线性时间序列模型 §1 随机波动率模型 一. 乘积过程 t t t x U m s =+ 其中t U 一个标准化过程,即()()0,1t t E U V U ==。t s 是一个正随机变量的序列。这种类型的过程称之为乘积过程。 因为()2t t t V x s s =,因此t s 是随机过程t x 的标准差。 现在看偏微分方程 ()()log dP d P dt dW P m s ==+ 其中()log t t x P =D ,()W t 为标准布朗运动。它是通常的金融资产定价的扩散过程。离散情况1dt =,所以它是一个乘积过程。 假设()t t t U x m s =-服从正态分布,且独立于t s ,则 ()()()()()2 2 2 2 2 2 t t t t t t E x E U E E U E m s s s -=== ()()()()()0 t t k t t k t t k t t k t t k E x x E U U E U E U m m s s s s -------== = 但平方误差()2 t t S x m =-却自相关: ()()()()()cov ,t t k t t t k t S S E S E S S E S --=-- ()()() ()()()()()()() 2 2 222222 22t t k t t t k t t k t t t k t E S S E S E E U U E E E s s s s s s ----=-=-=- 此时 ()()() ()()() 2 22,42 t t k t k S t t E E E E s s s r s s --= - 非线性时间序列的高阶奇异谱分析 袁 坚 肖先赐 (电子科技大学电子工程系,成都 610054) (1997年8月28日收到) 基于反映线性相关结构的协方差矩阵的奇异谱分析,本质上是一种线性的方法.奇异谱 分析用于吸引子重构的可靠性问题引发了一些争议.本文基于具有盲高斯噪声及体现非线性相关等性质的高阶累积量,提出了一种高阶的奇异谱分析方法.通过对H énon 映射、Logistic 映射和Lorenz 模型的分析说明了该方法的有效性,并在不同的延时、嵌入维数、抽样时间及有噪声的情况下表现出较好的鲁棒性. PACC :0545 1 引言 对于不同系统产生的不规则动态行为解释为确定性的混沌过程,这一认识在几乎所有学科中得到广泛的应用.而用动力系统方法分析非线性时间序列,状态空间的重构是必不可少的一个步骤.从标量时间序列重构多维状态矢量的延迟坐标法,是在无法观测系统各个变量情况下的一种折衷方法.延迟坐标间不可避免地存在着线性依赖及人为的对称性.Takens 的嵌入定理[1]隐含着无噪声影响,且假设数据长度为无限长.这样对任意的延时都不会导致重构的退化.而实际得到的时间序列是有限长度的,并且不可避免地受到噪声的影响.延时选择过大或过小,都会导致噪声增强[2].另外,当对分析的系统无任何先验认识,无从得知其拓扑维数时,对嵌入维数的选择也成问题. 基于多通道时间序列主元分析的奇异谱分析(singular 2spectrum analysis ,SSA ),最先由Broomhead 和K ing [1]引入非线性动力学领域.该方法一方面将延迟矢量变换到一正交空间里,以消除坐标间的线性依赖及人为的对称性;另一方面在奇异谱上区分出信号成分及噪声平台,在确定出最小嵌入维数的基础上,一个维数等于最小嵌入维数的子空间内的轨迹代表了信噪比增强的重构. 但是,SSA 作为一种线性方法,其所用的协方差矩阵反映出的是线性相关的结构,而无法反映内在的非线性关系.另外,一些实际的分析结果更加深了对这一方法的质疑[3—5].文献[2,6,7]对奇异谱方法作了详尽的分析和确认工作.并且针对Palu 等[5]用SSA 研究H énon 和Lorenz 模型所提出的质疑,文献[8,9]中分别指出了这是由于重构窗口(包括延时和嵌入维数)选择不当而导致的错误理解.我们在工作中也发现,在选择合适的重构窗口前提下,Lorenz 模型的奇异谱分析是成功的[10].然而对H énon 模型无论选择怎样的重构窗口,分析出的奇异谱都无法得到满意的结果[3,5]. 奇异谱分析所用的属于二阶统计的协方差矩阵,体现的是线性相关.高阶统计作为一 第47卷第6期1998年6月 100023290/98/47(6)/0897209物 理 学 报ACTA PHYSICA SIN ICA Vol.47,No.6,J une ,1998ν1998Chin.Phys.S oc. -------------精选文档 ----------------- 近代时间序列分析选讲: 一. 非线性时间序列 二. GARCH 模型 三. 多元时间序列 四. 协整模型 -------------精选文档 ----------------- 非线性时间序列 第一章 .非线性时间序列浅释 1.从线性到非线性自回归模型 2.线性时间序列定义的多样性第二章 . 非线性时间序列模型 1.概述 2.非线性自回归模型 3.带条件异方差的自回归模型 4.两种可逆性 5.时间序列与伪随机数 第三章 . 马尔可夫链与 AR 模型 1.马尔可夫链 2.AR 模型所确定的马尔可夫链 -------------精选文档 ----------------- 3.若干例子 第四章 . 统计建模方法 1.概论 2.线性性检验 3.AR 模型参数估计 4.AR 模型阶数估计 第五章 . 实例和展望 1.实例 2.展望 第一章 .非线性时间序列浅释 1.从线性到非线性自回归模型 时间序列 {x t } 是一串随机变量序列 , 它有广泛的实际背景 , 特别是在经济与金融 -------------精选文档 ----------------- 领域中尤其显著. 关于它们的从线性与非线 性概念 , 可从以下的例子入手作一浅释的说 明. 考查一阶线性自回归模型---LAR(1): x t = x t-1 +e t ,t=1,2, (1.1) 其中 {e t } 为i.i.d.序列,且Ee t =0, Ee t = 2 <, 而且e t与 {x t-1 ,x t-1 ,} 独立 . 反复使用 (1.1) 式的递推关系 , 就可得到 x t =x t-1 +e t =e =e =e t t t +x t-1 +{ e t-1 +x t-2 } +e t-1 + 2 x t-2 佛山科学技术学院 应用时间序列分析实验报告 实验名称第五章非平稳序列的随机分析 一、上机练习 通过第4章我们学习了非平稳序列的确定性因素分解方法,但随着研究方法的深入和研究领域的拓宽,我们发现确定性因素分解方法不能很充分的提取确定性信息以及无法提供明确有效的方法判断各因素之间确切的作用关系。第5章所介绍的随机性分析方法弥补了确定性因素分解方法的不足,为我们提供了更加丰富、更加精确的时序分析工具。 5.8.1 拟合ARIMA模型 【程序】 data example5_1; input x@@; difx=dif(x); t=_n_; cards; 1.05 -0.84 -1.42 0.20 2.81 6.72 5.40 4.38 5.52 4.46 2.89 -0.43 -4.86 -8.54 -11.54 -1 6.22 -19.41 -21.61 -22.51 -23.51 -24.49 -25.54 -24.06 -23.44 -23.41 -24.17 -21.58 -19.00 -14.14 -12.69 -9.48 -10.29 -9.88 -8.33 -4.67 -2.97 -2.91 -1.86 -1.91 -0.80 ; proc gplot; plot x*t difx*t; symbol v=star c=black i=join; proc arima; identify var=x(1); estimate p=1; estimate p=1 noint; forecast lead=5id=t out=out; proc gplot data=out; plot x*t=1 forecast*t=2 l95*t=3 u95*t=3/overlay; symbol1c=black i=none v=star; symbol2c=red i=join v=none; symbol3c=green I=join v=none; 第六章 时间序列的平滑 引论 上一章我们引进非参数函数估计的基本概念,现在将它应用到时间序列别的重要平滑问题上. 对估计慢变化时间趋势,平滑技术是有用的图示工具,它产生了时域平滑(§). 对将来事件和与之相联系的现在与过去变量之间的关系的非参数统计推断导致了§的状态域平滑. § 引入的样条方法是对§引入的局部多项式方法的有用替代. 这此方法能够容易地推广到时间序列的条件方差(波动性)的估计,甚至整个条件分布的估计,参阅§. 时域平滑 6.2.1 趋势和季节分量 分析时间序列的第一步是画数据图. 这种方法使得人们可以从视觉上检查一个时间序列是否像一个平稳随机过程. 如果观察到趋势或季节分量,在分析时间序列之前通常要将它们分离开来. 假定时间序列{}t Y 能够分解成 t t t t Y f s X =++, () 其中t f 表示慢变函数,称为“趋势分量”,t s 是周期函数,称为“季节分量”,t X 是随机分量,它被假定是零均值的平稳序列. 在使用这种分解之前,可以先用方差稳定变换或Box-Cox 变换. 这类幂变换有如下以参数λ为指标的形式 ,0,()log(),0, u g x u λλλ?≠=?=? () 或具有在0λ=点处连续的变换形式 ()(1)/g u u λλ=-. 这类变换由Box 和Cox (1964)给出. 注意,由在幂变换中数据必须是非负的,因此,在使用幂变换之前,可能必须先实施平移变换. 我们的目的是估计和提取确定性分量t f 和t s . 我们希望残差分量t X 是平稳的, 且能够用线性和非线性技术做进一步的分析. 通过推广Box 和Jenkins (1970)而发展的一个替代方法是对时间序列{}t Y 重复应用差分算子,直到被差分的序列表现为平稳为止. 这时,被差分的序列可以进一步平衡时间序列技术来处理. 作为说明Box 和Jenkins 方法的一个例子,我们先取S&P500指数的对数变换,然后计算一阶差分. 图给出了这个预处理序列. 所得序列基本上是该指数中变化的每日价格的百分比. 除了几个异常值(即1987年10月19日%的市场崩盘,金融市场称之为“黑色星期一”)外,这个序列显示出平稳性. 这个变换与金融工程中常用资产定价的几何布朗运动模型的离散化有关. 图 1972年1月3日至1999年12月31日(上图)和1999年1月4日至 1999年12月31日(下图)S&P500指数对数变换的差分 统计基础5第五章时间序列分析测试卷8K 精品文档 收集于网络,如有侵权请联系管理员删除 统计基础知识测试题 第 五 章 时间序列分析 一、判断题:本大题共20小题,每小题1分,共20分。下列命题你认为正确的在题后括号内打“√”,错误的打“×”。 1.动态序列中的发展水平可以是绝对数,也可以是相对数或平均数。 √ 2.时期序列中的各项指标数值是可以相加的。√ 3.时点序列的每一项指标值反映现象在某一段时期达到的水平。× 4.时点序列的每一项指标数值的大小和它在时间间隔上的长短没有直接关系。√ 5.用各年人口出生率编制的时间数列是平均数时间序列。× 6.通过时间序列前后各时间上指标值的对比,可以反映现象的发展变化过程及其规律。√ 7.时期序列中每个指标数值的大小和它所对应时期的长短有直接关系。√ 8.编制时间序列时,各指标的经济内容可不一致。× 9.相邻两项的累积增长量之差等于相应的逐期增长量。√ 10.间隔相等的间断时点序列序时平均数的计算采用“首尾折半简单算术平均法”。 √ 11.相对数时间序列求序时平均数时,根据所给数列简单平均即可。× 12.定基发展速度等于相应时期内各个环比发展速度的连乘积。√ 13.两个相邻的定基发展速度相除可得最初水平。 √ 14.平均发展速度是将各期环比发展速度简单平均而得的。× 15.发展水平是计算其他动态分析标志的基础,它只能用总量指标来表示。× 16.保证时间序列中各个指标数列具有可比性是编制时间数列应遵守的基本原则。 √ 17.间隔相等间断时点序列序时平均数的计算方法采用简单序时平均法。√ 18.平均增长速度等于平均发展速度减1。√ 19.若将某市社会商品库存额按时间先后顺序排列,此种时间序列属于时期数列。× 20.平均增长速度不能根据各个环比增长速度直接求得。√ 二、单项选择题:本大题共20小题,每小题1分,共20分。从每小题的备选答案中,选择一个正确选项并填在对应的括号内。 21. 在时点序列中(A )。 A 各指标数值之间的距离称作“间隔” B 各指标数值所属的时期长短称作“间隔” C 最初水平与最末水平之差称作“间隔” D 最初水平和最末水平之间的距离称作“间隔” 22. 下列数列中哪一个属于动态序列(C )。 A 学生按成绩分组形成的数列 B 工业企业按地区分组形成的数列 C 职工人数按时间顺序先后排列形成的数列 D 职工按工资水平高低顺序排列形成的数列 23. 10年内每年年末国家黄金储备是( D)。 A 发展速度 B 增长速度 C 时期数列 D 时点数列 24. 对时间序列进行动态分析的基础数据是(A )。 A 发展水平 B 平均发展水平C 发展速度D 平均发展速度 25. 由时期序列计算平均数应按(A )计算。 A 算术平均法 B 调和平均法 C 几何平均法 D “首末折半法” 26. 由日期间隔相等的间断时点序列计算平均数应按( D )计算。 A 算术平均法 B 调和平均法 C 几何平均法 D “首末折半法” 27. 时间序列中的平均发展速度是(D )。 A 各时期环比发展速度的调和平均数 B 各时期定基发展速度的序时平均数 C 各时期定基发展速度的序时平均数 D 各时期环比发展速度的几何平均数 28. 应用几何平均法计算平均发展速度主要是因为(B )。 A 几何平均计算简便 B 各期环比发展速度之积等于总速度 C 各期环比发展速度之和等于总速度 D 是因为它和社会现象平均速度形成的客观过程一致 29.平均增长速度是( D)。 A 环比增长速度的算术平均数 B 总增长速度的算术平均数 C 环比发展速度的算术平均数 D 平均发展速度减100% 30.累积增长量是( A)。 A 本期水平减固定基期水平 B 本期水平减前期水平 C 本期逐期增长量减前期增长量 D 本期逐期增长量加前期逐期增长量 31.说明现象在较长时期内发展的总速度的数值是( D)。 A 环比发展速度 B 平均发展速度 C 定基增长速度 D 定基发展速度 32. 某地区2003-2007年年底生猪存栏头数在2002的基础上分别增加20、30、40、30和50万头,则5年间平均生猪增长量(B )。 A 10万头 B 34万头 C 6万头 D 13万头 33. 已知环比增长速度为8.12%、3.42%、2.91%、5.13%,则定基增长速度为(D )。 A 8.12%×3.42%×2.91%×5.13% B (8.12%×3.42%×2.91%×5.13%)-100% C 108.12%×103.42%×102.91%×105.13% D(108.12%×103.42%×102.91%×105.13%)-100% 34. 某种产品单位成本2007年比2006年下降7%,2006年比2005年下降5%,则2007年比2005年下降(B )。 A 7%×5% B 100%-(93%×95%) C (93%+95%)-100% D (107%+105%)-100% 35. 某企业生产某种产品,其产量年年增加5万吨,则该产量的环比增长速度( B)。 A 年年下降 B 年年增长 C 年年保持不变 D 无法确定 36. 某地区工业总产值2002年为20亿元,2007年为30亿元,其年平均增长速度为(D )。 A 7% B 10% C 8.3% D 8.4% 37. 在时间数列中,作为计算其他动态分析指标基础的是(A )。 A 发展水平 B 平均发展水平 C 发展速度 D 平均发展速度 38. 已知最初水平与最末水平时,要计算平均发展速度,应采用( A )。 A 水平法 B 累计法 C 两种方法都采用 D 两种方法都不能采用 39. 环比发展速度与定基发展速度之间的关系是( D )。 A 环比发展速度等于定基发展速度减1 B 定基发展速度等于环比发展速度之和 C 环比发展速度等于定基发展速度的平方根 D 环比发展速度的连乘积等于定基发展速度 40. 某企业的职工人数比上年增长5%,职工工资水平提高2%,则该企业职工工资总额比上年增长(B )。 A 7% B 7.1% C 10% D 11% 三、多项选择题:本大题共20小题,每小题2分,共40分。下列各题,均有两个或两个以上正确答案。将选项并填在下表对应的括号内。多选、少选、错选均 不得分。 41. 时间序列按统计指标的表现形式可分为(BCD)。 A 时期序列 B 相对数时间序列 C 绝对数时间序列 D 平均数时间序列 42. 编制时间序列的基本原则是(ABCD )。 A 指标数值时间长短应该一致 时间序列分析第五章作业 班级:09数学与应用数学 学号: 姓名: 习题5.7 1、 根据数据,做出它的时序图及一阶差分后图形,再用ARIMA 模型模拟该序列的发展,得出 预测。根据输出的结果,我们知道此为白噪声,为非平稳序列,同时可以得出序列t x 模型 应该用随机游走模型(0,1,0)模型来模拟,模型为:,并可以预测到下一天 的收盘价为296.0898。 各代码: data example5_1; input x@@; difx=dif(x); t=_n_; cards ; 304 303 307 299 296 293 301 293 301 295 284 286 286 287 284 282 278 281 278 277 279 278 270 268 272 273 279 279 280 275 271 277 278 279 283 284 282 283 279 280 280 279 278 283 278 270 275 273 273 272 275 273 273 272 273 272 273 271 272 271 273 277 274 274 272 280 282 292 295 295 294 290 291 288 288 290 293 288 289 291 293 293 290 288 287 289 292 288 288 285 282 286 286 287 284 283 286 282 287 286 287 292 292 294 291 288 289 ; proc gplot ; plot x*t difx*t; symbol v =star c =black i =join; proc arima data =example5_1; identify Var =x(1) nlag =8 minic p = (0:5) q = (0:5); estimate p =0 q =0 noint; forecast lead =1 id =t out =results; run ; proc gplot data =results; plot x*t=1 forecast*t=2 l95*t=3 u95*t=3/overlay ; symbol1 c =black i =none v =star; symbol2 c =red i =join v =none; symbol3 c =green i =join v =none l =32; run ; 时序图: 127 第五章 非参数密度估计 5.1 引论 在非参数函数估计中,平滑是最基本的方法之一,通常被称为一维散点图平滑和密度估计. 在多维框架下,平滑是建立非参数估计的有用的构建模块. 平滑首先从时间序列中的谱密度估计中产生. 在对Bartlett (1946)的富有创新的文章的讨论中,Henry E. Daniels 指出,谱密度估计的一个可能的修正可以通过平滑周期图来实现. 然后,这一问题的理论和方法由Bartlett (1948,1950)系统地发展起来. 这样,早在半个世纪以前,平滑方法便已是时间序列分析的一个重要部分. 平滑问题在时间序列分析的各个方面经常出现. 平滑方法为概述一个给定的时间序列的边缘分布提供了有用的图解工具. 它们还可用于估计和消除慢变时间趋势. 这就产生了时域平滑. 研究一个时间序列和它的延迟序列联系的需要产生了状态域平滑. 这些方法能够容易地推广到估计一个时间序列的条件方差(波动性). 为了检验周期形式和别的特征,比如时间序列的功率谱,平滑方法常常用来估计谱密度. 在拟合一个时间序列数据时,一个重要的问题是拟合模型的残差的行为是否像白噪声. 对这类非参数拟合优度检验,非参数函数估计提供了有用的工具. 这个内容将本章和下一章中讨论. 最简单的非参数函数估计问题可能是密度估计. 这种简单结构对理解非参数建模和推断中更复杂的问题提供了有用的工具. 这就是我们在本章中讨论非参数密度估计的目的. 5.2 核密度估计 国库券收益的分布是什么?直方图是回答这类问题的经典的方法. 核密度估计是对直方图方法的改善. 它用来验证数据集合的所有分布特征. 这些包括密度峰和谷的数目和位置以及密度的对称性. 它是揭示非参数函数估计基本特性的最简单的工具. 对密度估计和它的应用的全面的讨论在Devroye 和Gy ?rfi (1985),Silverman (1986)以及Scott (1992)给出. 给定T 个数据点1,,T X X ,通过对每一个观测点乘以量1/T 可得到这些数据点的 经验分布函数: 1 1()()T t t F x I X x T ==≤∑. 这个累积分布函数是非降的,对验证给定分布的全面的结构不是太有用的. 当人们论及分布时,其脑海里常常有密度函数. 然而,经验分布函数的密度是不存在的. 对经验分布函 基于TAR 模型的太阳黑子非线性时间序列预测 摘要:太阳黑子数目的变化对地球的气候、农业、通信、导航等方面影响巨大因此对太阳黑子数目进行预测具有十分重要的意义。本文对1945-2005年的太阳黑子数据建立基于不同时间段的门限自回归模型(TAR),分析太阳黑子时间序列的变动特征并对未来10年的太阳黑子数进行预测。从模型诊断结果可以得出:TAR(2;3,5)模型能很好地拟合该太阳黑子的非线性时间序列,相应的预测值也比较精确。 关键词:太阳黑子 非线性时间序列 TAR 模型 预测 0 引言 太阳黑子的太阳活动中最基本的现象,它是在太阳的光球层桑发生的一种太阳活动,太阳黑子是表示太阳活动强弱的一项重要指标,它是典型的复杂时间序列,地磁变化、大气运动、气候异常、海洋活动、等都和太阳黑子数的变化有着不同程度的关系。对太阳黑子活动进行有效的预测以此来分析地球环境的变化有着十分重要的价值。因此,历来世界各国都十分重视对太阳黑子活动的预测工作,以便能够采取防范措施,避免意外的灾难性事故发生。任晶等(2014)建立了基于相空间重构的神经网络和神经网络的太阳黑子时间序列预测模,并在MATLAB 环境下进行预测仿真,仿真结果表明,建立的模型预测精度较好。向昌盛等(2011)提出了一种相空间重构和最小二乘支持向量机(LSSVM )参数的联合优化方法,实验结果表明联合优化方法预测精度比较好,而且优化速度更快。对于太阳黑子的预测文献中,运用向量自回归(TAR )模型进行预测的还比较少。 本文对1945-2005年的太阳黑子数据建立基于不同时间段的门限自回归模型(TAR),分析太阳黑子时间序列的变动特征并对未来10年的太阳黑子数进行预测。 1 TAR 模型 门限自回归模型作为一类非线性模型,能够解释金融数据中的非线性性质。它首先是由Tong(1980)提出的。门限自回归模型设定某一特定的时点,时间序列的运动方式从一种机制跳跃到了另一种机制,同时这种跳跃是离散的。门限自回归模型在拟合实际数据时具有较好的性质,但是由于建立门限自回归模型的步骤比较复杂,直到Ruey S.Tsay (1989)提出了相对来说比较简易的建模及检验方法后,这类模型才被人们广泛地应用。 一般地,对于时间序列{} ,2,1,=t Y t 称为满足一个k 阶门限自回归模型(TAR),其门限变量为d t Z -,假设初始值),,,(110--j p t y y y 是已知的,如果其满足下式: 非线性时间序列分析在气候中的 应用研究进展 彭跃华1,2 于江龙3 (1.解放军理工大学气象学院,南京211101; 2.中国科学院大气物理研究所; 3.总参气象水文空间天气总站) 提 要:非线性时间序列分析方法在气候领域中的应用主要包括如下三个方面:观 测数据处理、气候突变和气候预测。综述众多文献的结果表明,有许多学者为非线性时间序列分析方法在气候领域中的应用做了大量的工作,大部分文章用到了非线性时间序列分析方面较新的方法,几乎每种方法都能在某个方面取得一定的成功。但这些大多是个例的研究,得出的结论有待更多的验证和理论上更系统的阐述;可用于业务预测且可提高预报技巧的方法仍需探求。非线性时间序列分析在气候中的应用还是任重而道远。关键词:非线性 时间序列分析 气候 Research Advances of Nonlinear Time Series Analysis Applying in Climatology Peng Yuehua 1,2 Yu Jianglong 3 (1.Institute of Meteorology ,PLA University of Science and Technology ,Nanjing 211101; 2.Institute of Atmospheric Physics ,Chinese Academy of Sciences ; 3.Meteorology ,Hydrology and Space Weather Terminal Center of G eneral Staff ) Abstract :The application of nonlinear time series analysis in climatology mainly includes three as 2pects as follows :observation data processing ,abrupt change of climate and climatological predic 2tion.The results of summarizing many papers show that ,a great deal of scholars contribute a lot to the application of nonlinear time series analysis in climatology.Most of the papers have used new methods in nonlinear time series analysis and almost every method can come to the top in some fields.However ,they are just results with case study on the whole ,the inclusions need more validation and more systemic illustration ;it is necessary to hunt methods used in operational prediction and enhancing forecast skill.There is still a long way to go.K ey Words :nonlinear time series analysis climate 收稿日期:2009年4月23日; 修定稿日期:2009年7月1日 第35卷,第10期2009年10月 气 象 M ETEOROLO GICAL MON THL Y Vol.35No.10 October ,2009统计基础知识第五章时间序列分析习题及答案
非线性时间序列
高边坡开挖变形的非线性时间序列预测分析
第五章 时间序列的模型识别
非线性时间序列模型的波动性建模(中)
单变量非线性时间序列模型
非线性时间序列的高阶奇异谱分析
非线性时间序列.doc
应用时间序列分析 第5章
非线性时间序列
统计基础5第五章时间序列分析测试卷8K资料
时间序列分析第五章作业
非线性时间序列 第五章
基于TAR模型的太阳黑子非线性时间序列预测
非线性时间序列分析在气候中的应用研究进展