残差自相关的修正

应用回归分析·上机作业二
学号:200930980106 姓名:何斌年级专业: 10级统计1班指导老师:丁仕虹
个人收集整理勿做商业用途
思考与练习 4.9
1.用普通最小二乘法建立回归方程,并画出残差散点图。
1.1首先录入数据,sas程序如下:
proc import out=aa /*使用import过程导入数据,并输出到数据集aa*/
datafile="d:\xt4.09.xls"
dbms=excel2000 replace;
getnames=yes; /*首行为变量名*/
run;
proc print data=aa noobs;
run;
1.2建立回归方程,画残差散点图,sas程序如下:
proc reg data=aa;
model y=x;
output out=out r=residual;/*把回归的结果输出在文件out里,残差给变量名residual */ run;
proc gplot data=out;
plot residual*x;/*做残差图,检验是否存在异方差*/
symbol v=star i=none;
run;
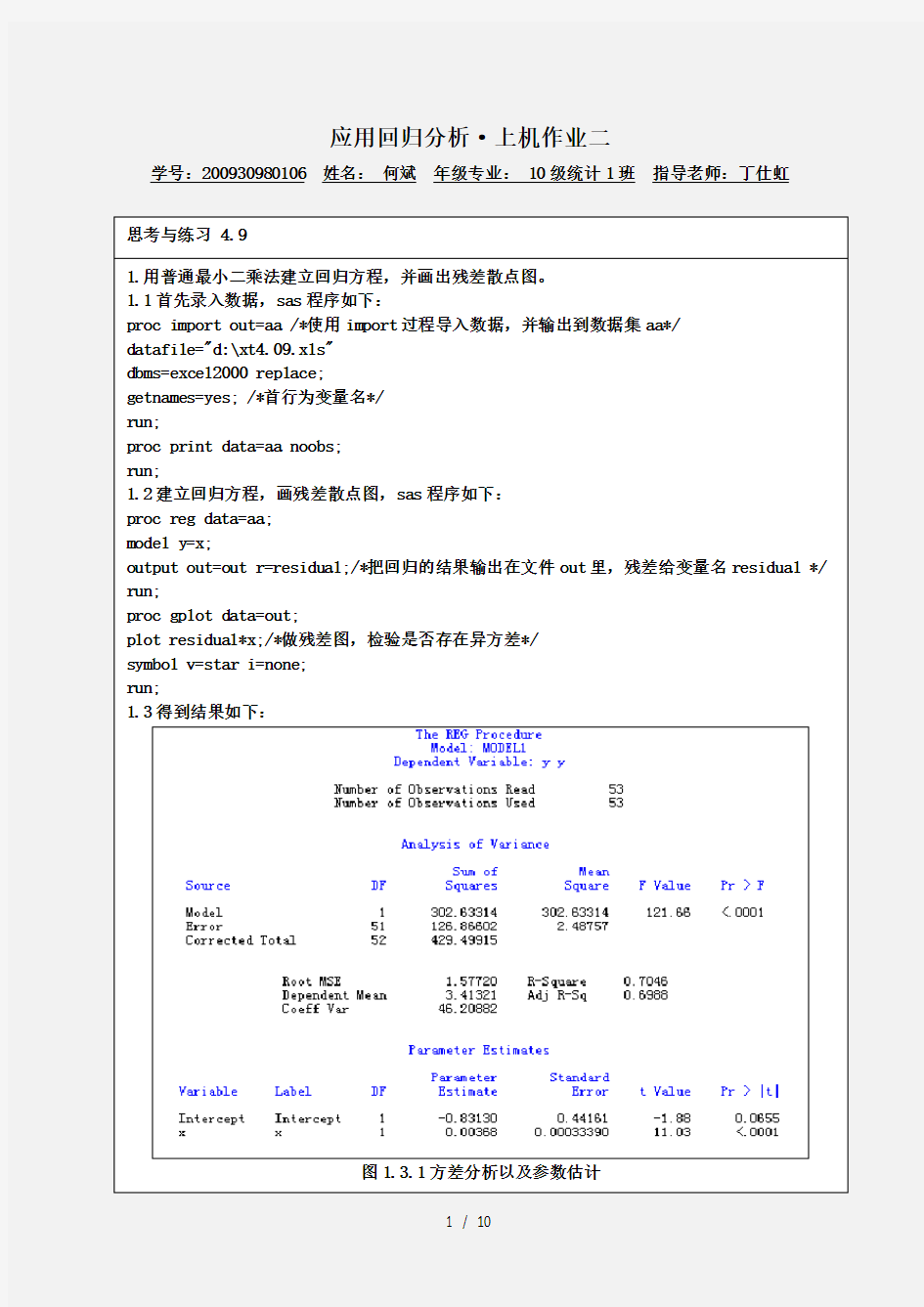
1.3得到结果如下:
图1.3.1方差分析以及参数估计
个人收集整理 勿做商业用途
1.4结果分析: 1.4.1由方差分析可知:p 值小于0.05,所以该回归方程显著有效。 1.4.2 R-Square=0.7046,Adj R-Sq=0.6988,可见回归方程的拟合度较高。 1.4.3由参数估计可得,常数项的检验P 值为0.0655大于0.05,故常数项不显著。 1.5除去常数项,重新拟合方程。 1.5.1 sas 程序如下: proc reg data=aa; model y=x/noint; run; 1.5.2得到结果如下: 图1.5.1方差分析以及参数估计 1.5.3结果分析: (1)由方差分析可知:P 值小于0.05,所以该回归方程显著有效,且F 值较有常数项时明显变大,故拟合方程较有常数项时更好。 (2) R-Square=0.8704,Adj R-Sq=0.8679,可见回归方程的拟合度有较大幅度提高。 (3)由参数估计可得,所有参数的检验P 值均小于0.05,参数显著有效。 (4)拟合的回归方程为:x y 0.00314=∧ (1.5.3.4) 1.6得到残差散点图如下:
图1.6.1残差散点图
个人收集整理勿做商业用途
2.判断是否存在异方差。
2.1残差图分析:
由图1.6.1残差散点图可以直观地看到,残差散点图上的点的分布是有一定规律的,即误差随着x的增加而波动幅度增加,呈大喇叭的形状,因此可以认为误差项存在异方差。
2.2利用等级相关系数法判断,sas程序如下:
proc reg data=aa;
model y=x/r noint;/*r是残差,noint无常数项*/
output out=out r=residual;/*把回归的结果输出在文件out里,残差给变量名residual */ run;
/*下面利用残差的绝对值和X间的 spearman的相关系数检验异方差*/
data out1 ;
set out; /*调用数据集out*/
z=abs(residual); /*求残差的绝对值*/
run;
proc corr data=out1 outs=out2;
/*corr指做相关分析 outs=out2表示将等级相关检验的结果输出到out2*/
var x z;
run;
2.2.1得到结果如下:
图2.2.1等级相关系数
个人收集整理 勿做商业用途
个人收集整理 勿做商业用途
2.2.2结果分析: 由2.2.1的输出结果可知,残差绝对值||i e 与i x 的等级相关系数0.21271 s r ,对应的P 值=0.1262,故认为残差绝对值||i e 与自变量i x 显著相关,存在异方差。
3.用幂指数型的权函数建立加权最小二乘回归方程。 3.1 sas 程序如下: title"wls method"; data w1;/*建立新的数据集w1,以便计算权重*/ set out1; keep y x; run; data w2;/*建立新的数据集w ,以保留权重*/ set w1; array row{10} w1-w10;/* w1-w10为不同m 时的权数值*/ array p{10}(-2,-1.5,-1,-0.5,0,0.5,1,1.5,2,2.5); do i=1 to 10; row(i)=1/x**p{i}; end; run; proc print data=w2; run; proc reg data=w2; model y=x/r; weight w1; output out=test r=residual; run; proc gplot data=test; plot residual*x; symbol v=dot i=none color=red; run; 3.2结果如下图所示:
图3.2.1方差分析
图3.2.1拟合优度以及参数估计 3.3结果分析:
(1)由方差分析可知:P 值小于0.05,所以该回归方程显著有效。
(2) R-Square=0.8175,Adj R-Sq=0.8139,可见回归方程的拟合度较高。
(3)由参数估计可得,所有参数的检验P 值均小于0.05,参数显著有效。
(4)加权最小二乘的回归方程为:x y 0.0046-2.40038+=∧ (3.3.4) 3.4.1残差散点图:
3.4.2残差散点图分析:
由3.4.1残差散点图可以直观地看到,残差图上的点仍是有规律的,即误差随着x 的增加而波动幅度增加,呈大喇叭的形状,因此可以认为误差项仍存在异方差。 4. 作变换:y=sqrt(y) 。
4.1得到结果如下:
个人收集整理勿做商业用途图4.1.1方差分析以及参数估计
4.2结果分析:
由图4.1.1可知,回归方程通过了显著性检验,调整2
R为0.6520,回归方程的系数都通过
了显著性检验,方差稳定变换'y y
=
后,回归方程为:
'0.582230.00095286*
y x
=+(4.2.1)
思考与练习 4.13
1.用普通最小二乘法建立y关于x的回归方程。
1.1首先录入数据,sas程序如下:
proc import out=aa2 /*使用import过程导入数据,并输出到数据集aa2*/
datafile="d:\xt_4.13.xls"
dbms=excel2000 replace;
getnames=yes; /*首行为变量名*/
run;
1.2建立回归方程,sas程序如下:
proc reg data=aa2;
model y=x/clb p r spec DW ;/*其中p是预测值,r是残差,clb是给出回归系数的区间估计,spec 可以给出怀特检验(检验异方差)的结果,DW给出一阶线性自相关检验*/
output out=out r=residual;/*把回归的结果输出在文件out里,残差给变量名residual */ run;
个人收集整理 勿做商业用途
个人收集整理 勿做商业用途
1.3得到结果如下: 图1.3.1方差分析以及参数估计 1.4结果分析: (1)由方差分析可知:p 值小于0.05,所以该回归方程显著有效。 (2)R-Square=0.9982,Adj R-Sq=0.9981,可见回归方程的拟合度较高。 (3)由参数估计可得,所有参数的检验P 值均小于0.05,参数显著有效。 (4)拟合的回归方程为:x y 17565.035145.1+-=∧ (1.4.1)
2.残差图以及DW 检验诊断序列的相关性。 2.1残差图如下:
残差图分析:该图存在一定的锯齿形,故可判断残差项存在相关。
2.2DW检验:
查DW分布表可得临界值d L和d U分别为1.20和1.41,由于DW值=0.771 个人收集整理勿做商业用途 3.迭代法处理序列相关,建立回归方程。 3.1 sas程序如下: /*迭代法处理序列相关*/ data bb; set out; ro=1-(1/2)*0.771;/*求自相关系数的估计值ro,DW值=0.771*/ y_t_1=y-ro*lag1(y); x_t_1=x-ro*lag1(x);/*lagn(n自定)函数可把一变量的各观测值移后n位;*/ proc reg data=bb; model y_t_1=x_t_1/clb p r spec DW ; run; 3.2结果如下所示: 图3.2.1方差分析以及参数估计 个人收集整理 勿做商业用途 图3.2.2 DW 检验 3.3结果分析: 由图3.2.1可知,迭代法所得的回归模型通过了显著性检验,调整2R 为0.9922,回归方程 为: 't 't 37x 17.040801.0y +-= (3.3.1) 其中,''11,t t t t t t y y py x x px --=-=- 由图3.2.2可知,DW=1.60。查DW 表,n=19,k=2,显著水平a=0.05,得d L =1.18,d U =1.40。由于1.40<1.60<4-1.40,所以迭代法得到的回归方程的误差项间无自相关。 4. 用一阶差分法处理数据,建立回归方程。 4.1 sas 程序如下: /*一阶差分法处理序列相关*/ data bb2; set aa2; difx=x-lag1(x);/*lagn (n 自定)函数可把一变量的各观测值移后n 位;对x 各观测值作一阶差分*/ dify=y-lag1(y);/*lagn (n 自定)函数可把一变量的各观测值移后n 位;对y 各观测值作一阶差分*/ run; proc reg data=bb2;/*对bb2运行回归分析过程*/ model dify=difx/p r dw; run; 4.2结果如下所示: 图4.2.1方差分析以及参数估计 个人收集整理 勿做商业用途 图4.2.2 DW 检验 4.3结果分析: 由图 4.2.1可见,一阶差分法处理数据后建立的回归模型通过了显著性检验,调整2R 为 0.9346,回归方程为: t x ?+=?16248.002827.0y t (4.3.1) 其中,1t t t y y y -?=-,1t t t x x x -?=- 由图4.2.2可知,DW=1.828。查DW 表,n=19,k=2,显著水平a=0.05,得dL=1.18,dU=1.40。由于1.40<1.828<4-1.40,所以迭代法得到的回归方程的误差项间无自相关。 5. 三种方法的优良性比较。 在回归模型不存在序列相关时,普通最小二乘法比迭代法和一阶差分法操作起来更简便,但是,当一个回归模型存在序列相关性时,普通最小二乘法所建立的回归方程就不适用了,这时需要使用迭代法或一阶差分法。 由于一阶差分法的应用条件是自相关系数P=1,当P 接近1时,一阶差分法比迭代法好,当原模型存在较高程度的一阶自相关的情况时,一般使用一阶差分法而不用迭代法,因为一阶差分法比迭代法简单而且迭代法需要用样本估计自相关系数P ,对P 的估计误差会影响迭代法的使用效率,同时迭代法的算法时间复杂度比一阶差分的高,在效率上不如一阶差分好。 应用回归分析·上机作业二 学号:200930980106 姓名:何斌年级专业: 10级统计1班指导老师:丁仕虹 思考与练习 4.9 1.用普通最小二乘法建立回归方程,并画出残差散点图。 1.1首先录入数据,sas程序如下: proc import out=aa /*使用import过程导入数据,并输出到数据集aa*/ datafile="d:\xt4.09.xls" dbms=excel2000 replace; getnames=yes; /*首行为变量名*/ run; proc print data=aa noobs; run; 1.2建立回归方程,画残差散点图,sas程序如下: proc reg data=aa; model y=x; output out=out r=residual;/*把回归的结果输出在文件out里,残差给变量名residual */ run; proc gplot data=out; plot residual*x;/*做残差图,检验是否存在异方差*/ symbol v=star i=none; run; 1.3得到结果如下: 图1.3.1方差分析以及参数估计 1.4结果分析: 1.4.1由方差分析可知:p 值小于0.05,所以该回归方程显著有效。 1.4.2 R-Square=0.7046,Adj R-Sq=0.6988,可见回归方程的拟合度较高。 1.4.3由参数估计可得,常数项的检验P 值为0.0655大于0.05,故常数项不显著。 1.5除去常数项,重新拟合方程。 1.5.1 sas 程序如下: proc reg data=aa; model y=x/noint; run; 1.5.2得到结果如下: 图1.5.1方差分析以及参数估计 1.5.3结果分析: (1)由方差分析可知:P 值小于0.05,所以该回归方程显著有效,且F 值较有常数项时明显变大,故拟合方程较有常数项时更好。 (2) R-Square=0.8704,Adj R-Sq=0.8679,可见回归方程的拟合度有较大幅度提高。 (3)由参数估计可得,所有参数的检验P 值均小于0.05,参数显著有效。 (4)拟合的回归方程为:x y 0.00314 =∧ (1.5.3.4) 1.6得到残差散点图如下: 一、误差修正模型的构造 对于yt的(1,1阶自回归分布滞后模型: 在模型两端同时减yt-1,在模型右端,得: 其中,,,。 记(5-5) 则(5-6) 称模型(5-6)为“误差修正模型”,简称ECM。 二、误差修正模型的含义 如果yt ~ I(1,x t ~ I(1,则模型(5-6)左端,右端,所以只有当yt和x t协整、即yt和x t之间存在长期均衡关系时,式(5-5)中的ecm~I(0,模型(5-6)两端的平稳性才会相同。 当yt和x t协整时,设协整回归方程为: 它反映了yt与x t的长期均衡关系,所以称式(5-5)中的ecm t-1是前一期的“非均衡误差”,称误差修正模型(5-6) 中的是误差修正项,是 修正系数,由于通常 ,这样;当ecm t-1 >0时(即出现正误差),误差修正项< 0,而ecm t-1 < 0时(即出现负误差), > 0,两者的方向恰好相反,所以,误差修正是一个反向 调整过程(负反馈机制)。 误差修正模型有以下几个明确的含义: 1.均衡的偏差调整机制 2.协整与长期均衡的关系 3.经济变量的长期与短期变化模型 长期趋势模型: 短期波动模型: 三、误差修正模型的估计 建立ECM的具体步骤为: 1.检验被解释变量y与解释变量x(可以是多个变量)之间的协整性; 2.如果y与x存在协整关系,估计协整回归方程,计算残差序列e t: 3.将e t-1作为一个解释变量,估计误差修正模型: 说明: (1)第1步协整检验中,如果残差是确定趋势过程,可以在第2步的协整回归方程中加入趋势变量; (2)第2步可以估计动态自回归分布滞后模型: 此时,长期参数为: 协整回归方程和残差也相应取成: , (3)第2步估计出ECM之后,可以检验模型的残差是否存在长期趋势和自相关性。如果存在长期趋势,则在ECM中加入趋势变量。如果存在自相关性,则在ECM的右端加入 误差修正项的滞后期一般也要作相应 调整。 如取成以下形式: 经典线性回归模型的诊断与修正下表为最近20年我国全社会固定资产投资与GDP的统计数据:1 年份国内生产总值(亿元)GDP 全社会固定资产投资(亿元)PI 1996 71813.6 22913.5 1997 79715 24941.1 1998 85195.5 28406.2 1999 90564.4 29854.7 2000 100280.1 32917.7 2001 110863.1 37213.49 2002 121717.4 43499.91 2003 137422 55566.61 2004 161840.2 70477.43 2005 187318.9 88773.61 2006 219438.5 109998.16 2007 270232.3 137323.94 2008 319515.5 172828.4 2009 349081.4 224598.77 2010 413030.3 251683.77 2011 489300.6 311485.13 2012 540367.4 374694.74 2013 595244.4 446294.09 1数据来源于国家统计局网站年度数据 1、普通最小二乘法回归结果如下: 方程初步估计为: GDP=75906.54+1.1754PI (32.351) R2=0.9822F=1046.599 DW=0.3653 2、异方差的检验与修正 首先,用图示检验法,生成残差平方和与解释变量PI的散点图如下: 从上图可以看出,残差平方和与解释变量的散点图主要分布在图形的下半部分,有随PI的变动增大的趋势,因此,模型可能存在异方差。但是否确定存在异方差,还需作进一步的验证。 G-Q检验如下: 去除序列中间约1/4的部分后,1996-2003年的OLS估计结果如下所示: 回归模型的残差分析 山东胡大波 判断回归模型的拟合效果是回归分析的重要内容,在回归分析中,通常用残差分析来判断回归模型的拟合效果。下面具体分析残差分析的途径及具体例子。 一、残差分析的两种方法 1、差分析的基本方法是由回归方程作出残差图,通过观测残差图,以分析和发现观测数据中可能出现的错误以及所选用的回归模型是否恰当;在残差图中,残差点比较均匀地落在水平区域中,说明选用的模型比较合适,这样的带状区域的宽度越窄,说明模型的拟合精度越高,回归方程的预报精度越高。 2、可以进一步通过相关指数 ∑ ∑ = = - - - = n i i n i i i y y y y R 1 2 1 2 ^ 2 ) ( ) ( 1来衡量回归模型的拟合效果,一般规律是2 R越大,残差平方和就越小,从而回归模型的拟合效果越好。 二、典例分析: 例1、某运动员训练次数与运动成绩之间的数据关系如下: 次数/x 30 33 35 37 39 44 46 50 成绩/y 30 34 37 39 42 46 48 51 试预测该运动员训练47次以及55次的成绩。 解答:(1)作出该运动员训练次数x与成绩y之间的散点图,如图1所示,由散点图可知,它们之间具有线性相关关系。 次数 i x 成绩 i y2 i x2 i y i x i y 30 30 900 900 900 33 34 1089 1156 1122 35 37 1225 1369 1295 37 39 1369 1521 1443 39 42 1521 1764 1638 44 46 1936 2116 2024 46 48 2116 2304 2208 一.GM(1,1)预测模型应用举例 灰色预测是基于GM(1,1)预测模型的预测,按其应用的对象可有四种类型: (1) 数列预测。这类预测是针对系统行为特征值的发展变化所进行的预测。 (2) 灾变预测。这类预测是针对系统行为的特征值超过某个阙值的异常值将在何时出现的预测。 (3) 季节灾变预测。若系统行为的特征有异常值出现或某种事件的发生是在一年中的某个特定的时区,则该预测为季节性灾变预测。 (4) 拓扑预测。这类预测是对一段时间内系统行为特征数据波形的预测。 例1(数列预测):设原始序列 )679.3,390.3,337.3,278.3,874.2())5(),4(),3(),2(),1(()0()0()0()0()0()0(==x x x x x X 试用GM(1,1)模型对)0(X 进行模拟和预测,并计算模拟精度。 解:第一步:对)0(X 进行一次累加,得 )558.16,897.12,489.9,152.6,874.2()1(=X 第二步:对)0(X 作准光滑性检验。由 ) 1()()()1()0(-=k x k x k ρ 得5.029.0)5(,5.036.0)4(,54.0)3(<≈<≈≈ρρρ。 当k>3时准光滑条件满足。 第三步:检验)1(X 是否具有准指数规律。由 )(1) 1() ()()1()1() 1(k k x k x k ρσ+=-= 得29.1)5(,36.1)4(,54.1)3()1()1()1(≈≈≈σσσ 当k>3时,5.0],5.1,1[)()1(<=∈δσk ,准指数规律满足,故可对)1(X 建立GM(1,1)模型。 第四步:对)1(X 作紧邻均值生成,得 )718.14,184.11,820.7,513.4()1(=Z 于是 残差分析的相关概念辨析及应用 在研究两个变量间的关系时,首先要根据散点图来粗略判断它们是否线性相关,是否可以用线性回归模型来拟合数据.然后,可以通过残差^ ^2^1,,,n e e e 来判断模型拟合的效果,判断原始数据中是否存在可疑数据.这方面的分析工作称为残差分析.残差分析一般有两种方法:(1)作残差图;(2)利用相关指数R 2来刻画回归效果. .,,2,1,^^^^n i a x b y y y e i i i i i ^ i e 称为相应于点(x i ,y i )的残差.类比 样本方差估计总体方差的思想,可以用)2)(,(2121^^ 1 ^2^2 n b a Q n e n n i i 作 为σ2 的估计量,其中^a 和^b 由公式x b y a ^^ , n i i n i i i x x y y x x b 1 2 1 ^ )() )((给出,Q(^ a , ^ b )称为残差平方和.可以用^ 2 衡量回归方程的预报精度.通常,^ 2 越小,预报 精度越高. 例1.设变量x,y 具有线性相关关系,试验采集了5组数据,下列几个点对应数据的采集可能有错误的是( ) A 点A B.点 B C.点 C D.点E 思路与技巧 由散点图判断出,点A,B,C,D,F 呈线性分布,E 点远离这个区域,说明点E 数据有问题. 解答D 评析 可以用Excel 画散点图,样本的散点图可以形象的展示两个变量的关系,画散点图的目的是用来确定回归模型的形式,若散点图呈条状分布,则x 与y 有较好的线性相关关系,散点图除了条状分布,还有其他形状的分布. 例2.为研究重量x(单位:克)对弹簧长度y(单位:厘米)的影响,对不同重量的6根弹簧进行测量,得如下数据: (1)画出散点图. (2)如果散点图中的各点大致分布在一条直线的附近,求y与x之间的回归直线方程. (3)求出残差,进行残差分析. 思路与技巧可以用Excel画散点图,由散点图发现x与y是否呈线性分布,由此判断x与y之间是否有较好的线性相关关系,若有,求出线性回归方程,再画出残差图,进行残差分析. 解答 (1)由Excel表格画散点图如图 (2)设y?=bx+a是线性回归直线方程, 两种灰色GM(1,1)残差修正方法在工程造价中的对比 李丹莹 金华正达工程造价咨询有限公司,浙江省金华市,321000 摘要:为了更准确地预测工程材料价格走势,本文介绍并比较了两种灰色GM(1,1)残差修正方法,并应用在了圆钢综合、螺纹钢综合及水泥价格的模拟和预测上,结果证明圆钢综合价格模拟仅能采取残差方法一,而残差方法二可以大大提升螺纹钢综合和水泥价格模拟精度。 关键词:工程造价;灰色预测;GM(1,1)模型;残差修正 一、概述 灰色系统理论是由我国著名学者邓聚龙教授在1982年率先提出的。近年来,不少学者已经将主要的灰色系统预测模型应用在了工程造价领域[1-3],并取得了一定的成果,但是灰色残差修正模型在工程造价方面的研究还不多。灰色残差修正模型是在灰色GM(1,1)模型的基础上,对其模拟值的残差再进行GM(1,1)建模,并将其叠加到原模型上,从而形成一个新的、精度更高的模型。尤其对于摆动或震荡的数据序列,残差修正模型的模拟精度明显优于GM(1,1)模型。 在工程造价预测领域,材料价格走势的预测是一大研究方向。由于某些工程材料价格的波动较大,而影响工程材料价格波动的因素又较复杂,经典灰色GM(1,1)模型的模拟精度常常无法达到要求,故本文引入并介绍了两种常用的灰色残差修正模型。在给出这两种计算方法的基础上,利用取得的工程材料历史价格数据,具体比较、分析了这两种方法建模的优劣和适用性。 二、灰色模型的建立 (一)灰色GM(1,1)模型的建立 设有变量X (0)={X (0)(k), k=1,2,…,n}={X (0)(1), X (0)(2), …, X (0)(n)}为某一预测对象的非负单调原始数据序列。 为建立灰色预测模型,首先对X (0)进行一次累加(1-AGO, Acumulated Generating Operator)生成一次累加序列: X (1)={X (1)(k ), k =1,2,…,n}={X (1)(1), X (1)(2), …, X (1)(n)} 其中 X (1)(k +1)=X (1)(k )+ X (0)(k +1) (1) 对X (1)可建立下述白化形式的微分方程: dt dX ) 1(十)1(aX =u (2) 即GM(1,1)模型。 上述白化微分方程的解为 X ?(1)(k +1)=(X (0)(1)-a u )ak e +a u (3) 式中:k 为时间序列。 记参数序列为a ?,a ?=[a,u]T , a ?可用下式求解: 回归模型的残差分析 山东 胡大波 判断回归模型的拟合效果是回归分析的重要内容,在回归分析中,通常用残差分析来判断回归模型的拟合效果。下面具体分析残差分析的途径及具体例子。 一、 残差分析的两种方法 1、差分析的基本方法是由回归方程作出残差图,通过观测残差图,以分析和发现观测数据中可能出现的错误以及所选用的回归模型是否恰当;在残差图中,残差点比较均匀地落在水平区域中,说明选用的模型比较合适,这样的带状区域的宽度越窄,说明模型的拟合精度越高,回归方程的预报精度越高。 2、可以进一步通过相关指数∑∑==--- =n i i n i i i y y y y R 1 2 1 2 ^ 2 )()(1来衡量回归模型的拟合效果,一般 规律是2 R 越大,残差平方和就越小,从而回归模型的拟合效果越好。 二、 典例分析: 例1、某运动员训练次数与运动成绩之间的数据关系如下: 试预测该运动员训练47次以及55次的成绩。 解答:(1)作出该运动员训练次数x 与成绩y 之间的散点图,如图1所示,由散点图可 知,它们之间具有线性相关关系。 (2)列表计算: 由上表可求得875.40,25.39==y x , 126568 1 2 =∑=i i x ,137318 1 2=∑=i i y , 131808 1 =∑=i i i y x ,所以∑∑==---= 8 1 2 8 1 )() )((i i i i i x x y y x x β.0415.188 1 2 28 1≈--= ∑∑==i i i i i x x y x y x 00302.0-≈-=x y βα,所以回归直线方程为.00302.00415.1^ -=x y (3)计算相关系数 将上述数据代入∑∑∑===---= 8 1 8 1 2 22 2 8 1 ) 8)(8(8i i i i i i i y y x x y x y x r 得992704.0=r ,查表可知 707.005.0=r ,而05.0r r >,故y 与x 之间存在显着的相关关系。 (4)残差分析: 作残差图如图2,由图可知,残差点比较均匀地分布在水平带状区域中,说明选用的模型比较合适。 计算残差的方差得884113.02 =σ ,说明预报的精度较高。 (5)计算相关指数2 R 计算相关指数2 R =0.9855.说明该运动员的成绩的差异有98.55%是由训练次数引起的。 (6)做出预报 由上述分析可知,我们可用回归方程 .00302.00415.1^ -=x y 作为该运动员成绩的预报值。 将x =47和x =55分别代入该方程可得y =49和y =57, 故预测运动员训练47次和55次的成绩分别为49和57. 点评:一般地,建立回归模型的基本步骤为: (1)确定研究对象,明确哪个变量是解释变量,哪个变量是预报变量; (2)画出确定好的解释变量和预报变量的散点图,观察它们之间的关系(如是否存在线性关系等); (3)由经验确定回归方程的类型(如我们观察到数据呈线性关系,则选用线性回归方程y =bx +a ); (4)按一定规则估计回归方程中的参数(如最小二乘法); (5)得出结果后分析残差图是否有异常(个别数据对应残差过大,或残差呈现不随机的规律性等等),若存在异常,则检查数据是否有误,或模型是否合适等。 例2、某城区为研究城镇居民月家庭人均生活费支出和月人均收入的相关关系,随机抽取 应用回归分析例库封面 一、案例背景 文章通过分阶段建立多元线性回归模型,分析了改革开放32年来民航客运量与相关因素之间的关系。结果表明:在不同历史阶段影响民航客运量的因素有所不同,并且从经济学角度对所建立的模型给出了合理的解释。 二、数据介绍 数据来自《新中国五十五年统计资料汇编》和《中国统计年鉴2010》。 三、分析过程 根据以上的分析,自改革开放以来,将中国民航客运量的增长趋势分为三个阶段,这里还有一个问题,就是年段的划分选在何处会更合理呢?对于这个问题,我们主要依据表2中分段回归拟合的残差平方和的大小,同时结合自变量选择时考虑的诸多因素做适当调整。 下面分阶段建立因变量y 关于自变量的各种组合的回归方程,这种组合方程共有 12552131555 C C C +++=-=个,根据自变量的选择准则,从中选择最优回归方程。 3.1 第一阶段:1978~1988年最优回归模型 经过比较,在通过回归方程和回归系数的显著性检验的方程中(取显著性水平0.05α=),发现表3中的两个模型最优。 由表3可见,模型一的各项指标都优于模型二,但是模型一中2x 的系数-0.290602β=<, 与实际意义不符,最终消费与民航客运量应该正相关。模型二中3x 的系数-0.008703β=<,与实际意义相符合,铁路客运量与民航客运量应该负相关,出现与实际意义不符的情况可能是由变量间的多重共线性造成的,为此考察其它几项指标,见表4. 表3 两个最优回归模型比较 模型 1978~1988年拟合回归方程 标准残差 复相关系数 PRESS AIC 模型一 721.0010-0.29060.690225 y x x =+ 41.91 0.9920 26372.68 111.0539 模型二 837.1212-0.00870.517435 y x x =+ 46.03 0.9904 52010.33 113.1177 表4 多重共线性、异常值诊断 模型 方差扩大因子 绝对值最大的删除学生化残差SRE 最大库克距离 最大杠杆值 模型一 27.9371025VIF VIF ==> 2.60473< 0.57970.5> 0.45162ch > 模型二 4.9581035VIF VIF ==< 2.6833< 0.42700.5< 0.33642ch < 从表4可见,模型一的自变量间存在严重的多重共线性,而且存在异常值点,模型二的自变量间不存在多重共线性,而且没有异常值点。为了进一步考察模型二的拟合效果,做残 3.1 第二课时 残差分析及回归模型的选择 一、课前准备 1.课时目标 (1) 了解残差分析回归效果; (2) 了解相关指数2R 分析回归效果; (3) 了解常见的非线性回归转化为线性回归的方法. 2.基础预探 1.在线性回归模型y bx a e =++中,a b 和为模型的未知参数,e y 是与y bx a =+之间的误差,通常e为随机变量,称为_______.它的均值E(e)=0,方差2 ()0D e σ=>. 线性回归模型的完整表达形式为2 ()0,()y bx a e E e D e σ=++??==? .在此模型中,随机误差r的方差2 σ越小,通过回归直线y bx a =+预报真实值y的精度越高. 2.对于样本点1122(,),(,), ,(,)n n x y x y x y 而言,相应于它们的随机误差为 (1,2,,)i i i i e y y y bx a i n =-=--=,其估计值为(1,2, ,)i i i i i e y y y bx a i n =-=--=, i e 称为相应于点(,)i i x y 的______.类比样本方差估计总体方差的思想,可以用 2 1 (,)2 Q a b n σ= -(n>2)作为2σ的估计量,其中a b 和由公式给出,()Q a b ,称为残差平方和.可以用2 σ衡量回归直线方程的预报精度.通常2 σ越小,预报精度越高. 3.在研究两个变量间的关系时,首先要根据散点图来粗略判断它们是否线性相关,是否可以用线性回归模型来拟合数据.然后,可以通过残差12,, n e e e 来判断模型拟合的效果,判断 原始数据中是否存在可疑数据.这方面的分析工作称为_______. 4.用相关指数2 R 来刻画回归的效果,其计算公式是:2 2 12 1 () 1() n i i n i i y y R y y ==-=- -∑∑.显然2 R 取值 越大,意味着残差平方和_______,也就是说模型的拟合效果________. 二、学习引领 1. 进行回归分析的步骤是什么? (1)确定研究对象,明确是哪两个变量之间的相关关系. (2)画出散点图,观察它们之间的关系是否存在线性关系,也可计算变量间的线性相关系数的值来精确判断它们之间是否存在相关关系.如果不存在线性相关关系,判断散点图是否存在非线性相关关系. 第二节误差修正模型(Error Correction Model,ECM) 一、误差修正模型的构造 对于yt的(1,1阶自回归分布滞后模型: 在模型两端同时减yt-1,在模型右端,得: 其中,,,。 记(5-5) 则(5-6) 称模型(5-6)为“误差修正模型”,简称ECM。 二、误差修正模型的含义 如果yt ~ I(1,xt ~ I(1,则模型(5-6)左端 ,右端,所以只有当yt和xt协整、即yt 和xt之间存在长期均衡关系时,式(5-5)中的 ecm~I(0,模型(5-6)两端的平稳性才会相同。 当yt和xt协整时,设协整回归方程为: 它反映了yt与xt的长期均衡关系,所以称式(5-5)中的ecmt-1是前一期的“非均衡误差”,称误差修正模型(5-6)中的是误差修正项,是修正系数,由于通常 ,这样;当ecmt-1 >0时(即出现正误差),误差 修正项< 0,而ecmt-1 < 0时(即出现负误差), > 0,两者的方向恰好相反,所以,误差修正是一个反向 调整过程(负反馈机制)。 误差修正模型有以下几个明确的含义: 1.均衡的偏差调整机制 2.协整与长期均衡的关系 3.经济变量的长期与短期变化模型 长期趋势模型: 短期波动模型: 三、误差修正模型的估计 建立ECM的具体步骤为: 1.检验被解释变量y与解释变量x(可以是多个变量)之间的协整性; 2.如果y与x存在协整关系,估计协整回归方程,计算残差序列e t: 3.将e t-1作为一个解释变量,估计误差修正模型: 说明: (1)第1步协整检验中,如果残差是确定趋势过程,可以在第2步的协整回归方程中加入趋势变量; (2)第2步可以估计动态自回归分布滞后模型: 此时,长期参数为: 协整回归方程和残差也相应取成: , (3)第2步估计出ECM之后,可以检验模型的残差是否存在长期趋势和自相关性。如果存在长期趋势,则在ECM中加入趋势变量。如果存在自相关性,则在ECM的右端加入的滞后项来消除自相关性,误差修正项的滞后期一般也要作相应调整。如取成以下形式: 由于模型中的各项都是平稳变量,所以可以用t检验判断各项的显著性,逐个剔除其中不显著的变量,当然误差修正项要尽可能保留。 第二节 误差修正模型(Error Correction Model ,ECM ) 一、误差修正模型的构造 对于y t 的(1,1)阶自回归分布滞后模型: t t t t t y x x y εβββα++++=--12110 在模型两端同时减y t-1,在模型右端10-±t x β,得: t t t t t t t t t t t t t x y x x y x y x x y εααγβεββββαββεββββα+--+?=+---+--+?=+-+++?+=?------)(]) 1()1()[1()1()(1101012120120121100 其中,12-=βγ,)1/()(200ββαα-+=,)1/(211ββα-=。 记 11011-----=t t t x y ecm αα (5-5) 则 t t t t ecm x y εγβ++?=?-10 (5-6) 称模型(5-6)为“误差修正模型”,简称ECM 。 二、误差修正模型的含义 如果y t ~ I(1),x t ~ I(1),则模型(5-6)左端)0(~I y t ?, 右端)0(~I x t ?,所以只有当y t 和x t 协整、即y t 和x t 之间存在长期均衡关系时,式(5-5)中的ecm~I(0),模型(5-6) 两端的平稳性才会相同。 当y t 和x t 协整时,设协整回归方程为: t t t x y εαα++=10 它反映了y t 与x t 的长期均衡关系,所以称式(5-5)中的ecm t -1是前一期的“非均衡误差”,称误差修正模型(5-6)中的1-t ecm γ是误差修正项,12-=βγ 是修正系数,由于通常1||2<β,这样0<γ;当ecm t -1 >0时(即出现正误差),误差 修正项1-t ecm γ< 0,而ecm t -1 < 0时(即出现负误差), 1-t ecm γ> 0,两者的方向恰好相反,所以,误差修正是一个反向调整过程(负反馈机制)。 误差修正模型有以下几个明确的含义: 1.均衡的偏差调整机制 2.协整与长期均衡的关系 3.经济变量的长期与短期变化模型 长期趋势模型: t t t x y εαα++=10 短期波动模型: t t t t ecm x y εγβ++?=?-10 实验12 向量自回归模型 【实验目的】通过本实验,使学生掌握向量自回归模型(V AR)的分析方法;能够较熟练利用Eviews,以及实际数据,针对现实问题进行向量自回归模型(V AR)分析。 【实验内容】根据中国GDP、宏观消费与基本建设投资等实际数据,建立向量自回归模型,并根据建立的模型进行分析。具体内容为: (1) V AR模型估计。 (2) V AR模型最佳滞后期的选择。 (3) V AR模型的稳定性检验。 (4) V AR模型残差检验。 (5) Granger因果性检验。 (6) 脉冲响应分析。 (7) 协整性检验。 (8) 建立VEC(向量误差修正)模型。 【实验步骤】 步骤一、数据处理 1.原始数据为国内生产总值GDP、消费总量CONS、基本建设投资INVES。 2. 为消除通货膨胀的影响,用价格指数进行调节,选择了定基价格指数(1997=1),并用三个时间序列分别除以价格指数,调整之后的序列分别命名为GDPP,CONSP,INVESP。3.三个数据变动幅度较大,为了减少可能存在的异方差性和自相关性影响,对三个序列取对数,取对数的数据序列分别命名为LNGP,LNCP和LNIP。数据如图1 图1 LNGP,LNCP和LNIP数据图 步骤二、建立V AR模型 1.在work file文档界面下,点击快捷键quick,会出现quick菜单,在quick菜单中选择估计V AR(estimate V AR)项,选择方法如图2。 图2 估计V AR选择方法 2.V AR模型设置。在V AR模型设置选项中(basics),有五个基本选项,(1)V AR类型(V AR Type)。包含无约束无约束V AR(Unrestricted V AR)和向量误差修正模型(Vector Erroe Correc)两个选项。本实验选择在V AR类型(V AR Type)选择无约束V AR(Unrestricted V AR)。 (2)样本时间范围。设定样本数据的时间范围。本实验选择1953年到1997年。 (3)模型中包含的内生变量(Endogenous Variables)。V AR模型包含的内生变量。本例在内生变量中(Endogenous Variables)输入Lngp,lncp,lnip)。 (4)内生变量滞后期区间(lag intervals for Endogenous )。设置V AR模型中各变量的滞后区间。本案例在变量滞后期框中输入“1 3”,表明建立的模型最大滞后期是3期。 (5)外生变量(Exogenous Variables)。V AR模型中包含的外生变量。在外生变量框中(Exogenous Variables)输入常数项C。 设置结果如图3 第八章 回归分析方法 当人们对研究对象的内在特性和各因素间的关系有比较充分的认识时,一般用机理分析方法建立数学模型。如果由于客观事物内部规律的复杂性及人们认识程度的限制,无法分析实际对象内在的因果关系,建立合乎机理规律的数学模型,那么通常的办法是搜集大量数据,基于对数据的统计分析去建立模型。本章讨论其中用途非常广泛的一类模型——统计回归模型。回归模型常用来解决预测、控制、生产工艺优化等问题。 变量之间的关系可以分为两类:一类叫确定性关系,也叫函数关系,其特征是:一个变量随着其它变量的确定而确定。另一类关系叫相关关系,变量之间的关系很难用一种精确的方法表示出来。例如,通常人的年龄越大血压越高,但人的年龄和血压之间没有确定的数量关系,人的年龄和血压之间的关系就是相关关系。回归分析就是处理变量之间的相关关系的一种数学方法。其解决问题的大致方法、步骤如下: (1)收集一组包含因变量和自变量的数据; (2)选定因变量和自变量之间的模型,即一个数学式子,利用数据按照最小二乘准则计算模型中的系数; (3)利用统计分析方法对不同的模型进行比较,找出与数据拟合得最好的模型; (4)判断得到的模型是否适合于这组数据; (5)利用模型对因变量作出预测或解释。 应用统计分析特别是多元统计分析方法一般都要处理大量数据,工作量非常大,所以在计算机普及以前,这些方法大都是停留在理论研究上。运用一般计算语言编程也要占用大量时间,而对于经济管理及社会学等对高级编程语言了解不深的人来说要应用这些统计方法更是不可能。MA TLAB 等软件的开发和普及大大减少了对计算机编程的要求,使数据分析方法的广泛应用成为可能。MATLAB 统计工具箱几乎包括了数理统计方面主要的概念、理论、方法和算法。运用MA TLAB 统计工具箱,我们可以十分方便地在计算机上进行计算,从而进一步加深理解,同时,其强大的图形功能使得概念、过程和结果可以直观地展现在我们面前。本章内容通常先介绍有关回归分析的数学原理,主要说明建模过程中要做的工作及理由,如模型的假设检验、参数估计等,为了把主要精力集中在应用上,我们略去详细而繁杂的理论。在此基础上再介绍在建模过程中如何有效地使用MA TLAB 软件。没有学过这部分数学知识的读者可以不深究其数学原理,只要知道回归分析的目的,按照相应方法通过软件显示的图形或计算所得结果表示什么意思,那么,仍然可以学到用回归模型解决实际问题的基本方法。包括:一元线性回归、多元线性回归、非线性回归、逐步回归等方法以及如何利用MATLAB 软件建立初步的数学模型,如何透过输出结果对模型进行分析和改进,回归模型的应用等。 8.1 一元线性回归分析 回归模型可分为线性回归模型和非线性回归模型。非线性回归模型是回归函数关于未知参数具有非线性结构的回归模型。某些非线性回归模型可以化为线性回归模型处理;如果知道函数形式只是要确定其中的参数则是拟合问题,可以使用MATLAB 软件的curvefit 命令或nlinfit 命令拟合得到参数的估计并进行统计分析。本节主要考察线性回归模型。 8.1.1 一元线性回归模型的建立及其MATLAB 实现 01y x ββε=++ 2~(0,)N εσ 其中01ββ,是待定系数,对于不同的,x y 是相互独立的随机变量。 回归模型的残差分析 判断回归模型的拟合效果是回归分析的重要内容,在回归分析中,通常用残差分析来判断回归模型的拟合效果。下面具体分析残差分析的途径及具体例子。 一、残差分析的两种方法 1、差分析的基本方法是由回归方程作出残差图,通过观测残差图, 以分析和发现观测数据中可能出现的错误以及所选用的回归模型是否恰当;在残差图中,残差点比较均匀地落在水平区域中,说明选用的模型比较合适,这样的带状区域的宽度越窄,说明模型的拟合精度越高,回归方程的预报精度越高。 2、可以进一步通过相关指数 ∑ ∑ = = - - - = n i i n i i i y y y y R 1 2 1 2 ^ 2 ) ( ) ( 1来衡量回归模型的拟合效果,一般规律是2 R越大,残差平方和就越小,从而回归模型的拟合效果越好。 二、典例分析: 例1、某运动员训练次数与运动成绩之间的数据关系如下: 试预测该运动员训练47次以及55次的成绩。 解答:(1)作出该运动员训练次数x与成绩y之间的散点图,如图1所示,由散点图可知,它们之间具有线性相关关系。 (2)列表计算: 由上表可求得875.40,25.39==y x , 126568 1 2=∑=i i x ,137318 1 2=∑=i i y , 131808 1 =∑=i i i y x ,所以∑∑==---= 8 1 2 8 1 )() )((i i i i i x x y y x x β.0415.188 1 2 28 1≈--= ∑∑==i i i i i x x y x y x 00302.0-≈-=x y βα,所以回归直线方程为.00302.00415.1^ -=x y (3)计算相关系数 将上述数据代入∑∑∑===---= 8 1 8 1 2 22 2 8 1 ) 8)(8(8i i i i i i i y y x x y x y x r 得992704.0=r ,查表可知 707.005.0=r ,而05.0r r >,故y 与x 之间存在显著的相关关系。 (4)残差分析: 作残差图如图2,由图可知,残差点比较均匀地分布在水平带状区域中,说明选用的模型比较合适。 §10.3 残差GM (1,1)模型 1.() X 0为原始序列 2. () X 1为一次累加序列 3.按GM(1,1)模型求解 4.得到() X ?1,即 () X 1的预测值 5.计算 () X 1的残差序列() ()() ()() ()k k k x x ?110- = ε 6.判断可建模残差尾段: (1)存在k 0 (2)k k ≥?,() ()k ε 0的符号一致,4 ≥-k n (3)称() ()()()()()??? ? ? ?+n k k εεε 0, ,1, 为可建模残差尾段 7.计算可建模残差尾段的一次累加序列 8.按GM(1,1)模型计算可建模残差尾段的时间响应式 9.计算残差尾段() ε0的模拟序列: () () ()()()()()?? ? ? ?+=n k k εεεε0 00, ,1, ??? ,这里,()()10 +k ε为导数还原值 即: () ()()() ()()[]k a a b k a k k 0 000exp 1?--?? ? ???? ?--=+εεεεεε, k k 0≥ 10.用() ε? 0修正 () X ?1(用一次累加序列的残差修正一次累加序列预测值),称修正后的时间 响应式: ()()() ()() ()() ()() ???? ? ??? ?≥ ?? ? ???? ?-±+? ? ????-< + ?? ? ??? - =+-- --k e a b k a e x k e x x k a b a b k a b a b k k a k ab ab 000 010111?εεεεε 其中残差修正值()()1?0+k ε的符号应与残差尾段() ε0的符号保持一致。 11.用() ε? 0修正() x ? 0(用原始序列的残差修正原始序列预测值),根据由() x ?1到() x ? 0的不同 还原方式,得到不同的残差修正时间响应式。 11.1 若() ()() ()() ()() ()() e x e x x x k a a a b k k k 10110111???--?? ?? ? ? - ??? ? ?-=-- = 则相应的残差修正时间响应式为: 第八章回归分析方法 当人们对研究对象的内在特性和各因素间的关系有比较充分的认识时,一般用机理分析方法建立数学模型。如果由于客观事物内部规律的复杂性及人们认识程度的限制,无法分析实际对象内在的因果关系,建立合乎机理规律的数学模型,那么通常的办法是搜集大量数据,基于对数据的统计分析去建立模型。本章讨论其中用途非常广泛的一类模型——统计回归模型。回归模型常用来解决预测、控制、生产工艺优化等问题。 变量之间的关系可以分为两类:一类叫确定性关系,也叫函数关系,其特征是:一个变量随着其它变量的确定而确定。另一类关系叫相关关系,变量之间的关系很难用一种精确的方法表示出来。例如,通常人的年龄越大血压越高,但人的年龄和血压之间没有确定的数量关系,人的年龄和血压之间的关系就是相关关系。回归分析就是处理变量之间的相关关系的一种数学方法。其解决问题的大致方法、步骤如下: (1)收集一组包含因变量和自变量的数据; (2)选定因变量和自变量之间的模型,即一个数学式子,利用数据按照最小二乘准则计算模型中的系数; (3)利用统计分析方法对不同的模型进行比较,找出与数据拟合得最好的模型; (4)判断得到的模型是否适合于这组数据; (5)利用模型对因变量作出预测或解释。 应用统计分析特别是多元统计分析方法一般都要处理大量数据,工作量非常大,所以在计算机普及以前,这些方法大都是停留在理论研究上。运用一般计算语言编程也要占用大量时间,而对于经济管理及社会学等对高级编程语言了解不深的人来说要应用这些统计方法更是不可能。MATLAB等软件的开发和普及大大减少了对计算机编程的要求,使数据分析方法的广泛应用成为可能。MATLAB统计工具箱几乎包括了数理统计方面主要的概念、理论、方法和算法。运用MATLAB统计工具箱,我们可以十分方便地在计算机上进行计算,从 案例六 自回归分布滞后模型(ADL )的运用实验指导 一、实验目的 理解ADL 模型的原理与应用条件,学会运用ADL 模型来估计变量之间长期稳定关系。理解从经济理论上来说,两个经济变量之间的确有长期关系采用使用该模型进行估计。理解ADL 模型的优点:不管回归项是不是1阶单整或平稳都可以进行检验和估计。而进行标准的协整分析前,必须把变量分类成(0)I 和(1)I 。 二、基本概念 Jorgenson(1966)提出的(,p q )阶自回归分布滞后模型ADL(autoregressive distributed lag):011111 i t t p t p t t q t q i t i i y y y ταφφεθεθεβ-----='=++++--+∑x ,其中t i -x 是滞后i 期 的外生变量向量(维数与变量个数相同),且每个外生变量的最大滞后阶数为i τ,i β是参数向量。当不存在外生变量时,模型就退化为一般ARMA (,p q )模型。 如果模型中不含有移动平均项,可以采用OLS 方法估计参数,若模型中含有移动平均项,线性OLS 估计将是非一致性估计,应采用非线性最小二乘估计。 三、实验内容及要求 (1)实验内容 运用ADL 模型研究1992年1月到1998年12月我国城镇居民月对数人均生活费支出yt 和对数可支配收入xt 之间的长期稳定关系。 (2)实验要求 在认真理解模型应用条件的基础上,通过实验掌握ADL 模型的实际应用方法,并熟悉Eniews 的具体操作过程。 四、实验指导 (1)数据录入 打开Eviews 软件,选择“File”菜单中的“New --Workfile”选项,在“Workfile structure type ”栏选择“Dated-regular frequency ”,在“Data specification ”栏中“Frequency ”中选择“Monthly ”即月份数据,起始时间输入1992m1即1992年1月份,止于1998m12,点击ok ,见图6-1,这样就建立了一个工作文件。 图6-1 建立工作文件窗口 第三章相关分析与回归模型的建立与分析相关分析和回归分析是统计分析方法中最重要内容之一,是多元统计分析方法的 基础。相关分析和回归分析主要用于研究和分析变量之间的相关关系,在变量之间寻求合适的函数关系式,特别是线性表达式。 ◆本章主要内容: 1、对变量之间的相关关系进行分析(Correlate)。其中包括简单相关分析 (Bivariate)和偏相关分析(Partial)。 2、建立因变量和自变量之间回归模型(Regression),其中包括线性回归分析 (Linear)和曲线估计(Curve Estimation)。 ◆数据条件:参与分析的变量数据是数值型变量或有序变量。 §3.1 相关分析 在SPSS中,可以通过Analyze菜单进行相关分析(Correlate),Correlate菜单如图3.1所示。 图3.1 Correlate 相关分析菜单 §3.1.1 简单相关分析 两个变量之间的相关关系称简单相关关系。有两种方法可以反映简单相关关系。一是通过散点图直观地显示变量之间关系,二是通过相关系数准确地反映两变量的关系程度。 §3.1.1.1 散点图 SPSS软件的绘图命令集中在Graphs菜单。下面通过例题来介绍具体操作方法。 例1:数据库SY-8中的变量X表示山东省人均国内生产总值,Y表示山东省城镇居民的消费额(资料来源:山东省2003年统计年鉴),现画出散点图来观察两个变量的关联程度。具体操作步骤如下: 首先打开数据SY-8,然后单击Graphs Scatter,打开Scatter plot散点图对话框,如图3.2所示。然后选择需要的散点图,图中的四个选项依次是: Simple 简单散点图Matrix 矩阵散点图 Overlay 重叠散点图3-D 三维散点图 图3.2 散点图对话框 如果只考虑两个变量,可选择简单的散点图Simple,然后点击Define,打开Simple Scatterplot对话框,如图3.3所示。 图3.3 Simple Scatterplot对话框 选择变量分别进入X轴和Y轴,点击OK后就可以得到散点图,见图3.4。 从下面输出的人均国内生产总值与城镇居民消费额的散点图3.4中可以粗略地看出,两个变量之间有强正相关的线性关系。残差自相关的修正
误差修正模型实例(精)
经典线性回归模型的诊断与修正
回归模型的残差分析
GM(1,1)模型应用及残差修正
高中数学 第一章 统计案例 1.1 回归分析 残差分析的相关概念辨析及应用素材 北师大版选修1-2
两种灰色GM(1,1)残差修正方法在工程造价中的对比
回归模型的残差分析
回归模型拟合精度分析
2016-2017学年高中数学 第三章 统计案例 3.1 第2课时 残差分析及回归模型的选择学案 新
误差修正模型.
误差修正模型
实验12 向量自回归模型
回归分析方法
人教版数学高二回归模型的残差分析
残差GM模型
回归分析方法
自回归分布滞后模型
spss教程第三章--相关分析与回归模型的建立与分析