MEGA蛋白序列比对-保守序列分析-进化树
生物学常用软件简介

AC
accession number giving origin of sequence
DT
dates of entry and modification
KW
key cross-reference words for lookup up this entry
OS, OC source organism
RN, RP, RX, RA, RT, RL literature reference or source
DR
i. d. In other databases
CC
Description of biological function
பைடு நூலகம்
FH, FT information about sequence by base position or range of positiions
生物学常用软件简介
前言
生物信息学是一门新兴的交叉学科,它将数 学和计算机知识应用于生物学,以获取、 加工、存储、分类、检索与分析生物大分 子的信息,从而理解这些信息的生物学意 义。
上面是狭义的生物信息学含义,也是现阶段生 物信息学的基本工作.
内容概要
一 生物信息学软件的主要功能简介
1.数据的基本处理 2.序列的比对 3.基因/基因组的注释 4.Snp分析 5.进化分析 6.基因表达分析 7.蛋白质结构预测
2.序列的比对 序列比对(alignment):为确定两个或多个序列
之间的相似性以至于同源性,而将它们按照一定 的规律排列。
将两个或多个序列排列在一起,标明其相似之处。 序列中可以插入间隔(通常用短横线“-”表示)。 对应的相同或相似的符号(在核酸中是A, T(或 U), C, G,在蛋白质中是氨基酸残基的单字母表 示)排列在同一列上。
保守结构域序列构建进化树

保守结构域序列构建进化树是一个非常常见且重要的生物信息学分析步骤。
通过将同源蛋白中的保守序列区域聚合在一起,研究者可以对同一蛋白家族的多种蛋白质进行分析,并且使用这些保守结构域的序列信息进行进化树的构建,可以帮助我们理解蛋白质家族的进化关系和进化历程。
首先,我们需要收集一组同源蛋白的保守结构域序列。
这些序列通常来自于生物数据库中的已知蛋白质序列,通过比对和分析,我们可以找到这些序列中的保守区域。
这些保守区域通常代表了蛋白质的功能和结构的重要部分,因此,通过比较和分析这些序列,我们可以了解蛋白质家族的进化关系。
接下来,我们需要将这些序列导入到一个进化树构建软件中。
常用的软件包括MEGA、PHYLIP、Clustal等。
这些软件通常会使用一种叫做邻接法(Neighbor-joining)的算法来构建进化树。
邻接法是一种基于距离的算法,它通过比较序列之间的差异来构建树状图。
这种方法在处理大样本和复杂的进化关系时表现得尤为出色。
在构建进化树的过程中,我们需要对软件中的参数进行适当的设置。
例如,我们可能需要选择适当的距离度量方法、调整树的进化模型、考虑种间或种内的系统发生信息等。
这些参数的选择和调整可能会影响到进化树的精度和可靠性。
一旦进化树构建完成,我们可以利用一些可视化的工具进行观察和解读。
例如,我们可以使用专门的绘图软件(如TREE-PUZZLE或ITOL)将进化树绘制成漂亮的图形,或者使用一些专门的软件来分析树中的分支和节点,以了解蛋白质家族的进化关系和进化历程。
总之,保守结构域序列构建进化树是一个非常有用的生物信息学分析步骤。
通过比较和分析同源蛋白中的保守序列区域,我们可以了解蛋白质家族的进化关系和进化历程,这对于理解生物多样性和物种进化的机制具有重要意义。
mega操作过程-多序列比对、进化树、

基 在NCBI/EBI的FTP服务器上可以找到下载的软件包。
础 生
ClustalW 程序用选项单逐步指导用户进行操作,用户
物
可根据需要选择打分矩阵、设置空位罚分等。
信 息
ftp:///pub/software/
学
EBI的主页还提供了基于Web的ClustalW服务,用户可以
物
信
随着序列数量的增加,算法复杂性也不断增加。用O
息
(m1m2m3…mn)表示对n个序列进行比对时的算法复杂性,
学
其中mn是最后一条序列的长度。若序列长度相差不大,则
及 应
可简化成O(mn),其中n表示序列的数目,m表示序列的长
用
度。显然,随着序列数量的增加,序列比对的算法复杂性
按指数规律增长。
第二节 多序列比对程序及应用
及 应
把序列和各种要求通过表单提交到服务器上,服务器
用
把计算的结果用Email返回用户(或在线交互使用)。
/clustalw/
Progressive Alignment Method
ClustalW 程序
基
ClustalW对输入序列的格式比较灵活,可以是FASTA格式,还可
1 2 3 4 5 6 7 8 91
ⅠY D G G A V - E AL
基
础
ⅡY D G G - - - E AL
生
物
ⅢF E G G I L V E AL
信
息
学
ⅣF D - G I L V Q AV
及
应
ⅤY E G G A V V Q AL
用
表1 多序列比对的定义
表示五个短序列(I-V)的比对结果。通过插入空位,使5个序列中 大多数相同或相似残基放入同一列,并保持每个序列残基顺序不变
植物基因家族进化树的构建

植物基因家族进化树的构建一、数据收集在构建植物基因家族进化树之前,需要收集相关的基因序列数据。
这些数据可以通过各种数据库,如NCBI、Ensembl等获取。
在收集数据时,需要注意以下几点:1. 选择具有代表性的物种,覆盖尽可能多的系统发育分支;2. 确保所收集的基因序列数据质量可靠,无测序错误和拼接错误;3. 对于每个基因家族,应尽可能收集多个成员的序列,以便进行多序列比对和树的构建。
二、序列比对在获得基因序列数据后,需要进行多序列比对。
比对的目的是为了找到不同物种间基因序列的相似性和差异性,从而确定它们之间的系统发育关系。
常用的多序列比对软件有MUSCLE、CLUSTAL W等。
在进行多序列比对时,需要注意以下几点:1. 选择合适的比对参数,以保证比对结果的准确性和可靠性;2. 在比对过程中,需要注意保持基因序列的原始阅读框,避免引入不必要的拼接错误;3. 对于较长的基因序列,可以分段进行比对,以提高计算效率和准确性。
三、距离矩阵计算在多序列比对的基础上,需要计算不同物种间基因序列之间的距离。
距离矩阵的计算是树构建的重要步骤之一。
常用的距离矩阵计算方法有:1. 欧氏距离法:直接计算不同物种间基因序列的差异数目,得到距离矩阵;2. Kimura距离法:基于Kimura模型计算不同物种间基因序列的差异概率,得到距离矩阵;3. Jukes-Cantor距离法:考虑基因序列的突变率和进化速率,计算不同物种间基因序列的差异概率,得到距离矩阵。
在选择距离矩阵计算方法时,需要根据具体情况选择适合的方法。
如果数据量较大或序列较短时,可以考虑使用欧氏距离法;如果数据量较小或序列较长时,可以考虑使用Kimura或Jukes-Cantor距离法。
四、树构建方法选择在获得距离矩阵后,需要选择合适的树构建方法来构建进化树。
常用的树构建方法有:1. UPGMA(Unweighted Pair Group Method with Arithmetic Mean):将距离矩阵中的行或列进行聚类分析,根据聚类结果构建树;2. Neighbor Joining:基于距离矩阵中的最近邻关系构建树;3. Maximum Parsimony:基于树的构建准则函数(如最小改变数、最小代价等)构建树。
MEGA使用说明书

MEGA软件构建系统发育树摘要:以白色念珠菌属下面的十个种的18s RNA 为例,构建系统发育树来说明MEGA 软件的使用方法。
1背景简介1.1 MEGA(分子进化遗传分析)MEGA 的全称是Molecular Evolutionary Genetics Analysis。
MEGA is an integrated tool for automatic and manual sequence alignment, inferring phylogenetic trees, mining web-based databases, estimating rates of molecular evolution, and testing evolutionary hypotheses. MEGA 可用于序列比对、进化树的推断、估计分子进化速度、验证进化假说等。
MEGA 还可以通过网络(NCBI)进行序列的比对和数据的搜索。
最新版本:MEGA 5.1 Beta (软件开发者建议其结果不用于发表文章)建议下载版本:MEGA 5.05 for Windows and Mac OS。
MEGA 5 has been tested on the following Microsoft Windows® operating systems: Windows 95/98, NT, 2000, XP, Vista, version 7, Linux and Mac OS [1].MEGA 5.05 可免费下载,只需输入名字及有效邮箱,下载链接会发送至邮箱,点击可下载。
1.2 系统发育树定义系统发育树(英文:Phylogenetic tree)又称为演化树(evolutionary tree),是表明被认为具有共同祖先的各物种间演化关系的树。
是一种亲缘分支分类方法(cladogram)。
在树中,每个节点代表其各分支的最近共同祖先,而节点间的线段长度对应演化距离(如估计的演化时间)1.3 系统发育树的分类根据有根和无根来区分:树可分为有根树和无根树两类。
生物信息学中的序列比对与进化树构建算法研究

生物信息学中的序列比对与进化树构建算法研究序列比对是生物信息学中重要的分析方法之一,通过比对不同生物种类的DNA、RNA或蛋白质序列,可以揭示它们之间的相似性和差异性,并为分析进化关系、功能预测等提供基础。
序列比对的基本思想是将两个或多个序列进行比对,并找出它们之间的相似性。
在序列比对中,常用的方法有全局比对、局部比对和多序列比对。
全局比对方法是将整个序列进行比对,一般采用Needleman-Wunsch算法或Smith-Waterman算法。
这些算法根据序列间的单个碱基或氨基酸之间的匹配、错配和缺失情况,计算出序列的相似度得分。
全局比对方法适用于较短的序列,优点是能够找到完全匹配的区域,但是对长序列不适用,计算复杂度较高。
局部比对方法主要用于比对较长的序列或存在较大插入缺失的序列。
常用的算法有BLAST和FASTA算法。
这些算法采用快速搜索的策略,先找出序列间的高度相似的片段,然后再进行比对和分析。
局部比对方法能够找到较长序列内的相似片段,但可能无法找到全局的最优比对。
多序列比对方法用于比对三个或更多序列,揭示它们之间的共同特征和区别。
常用的方法有多重序列比对和进化树构建。
多重序列比对旨在将多个序列按照匹配和错配的原则进行比对,以找到共同的序列区域。
进化树构建方法基于序列的相似性和进化关系,将多个序列构建成进化树,以揭示它们之间的进化关系。
在序列比对的过程中,常用的比对算法还包括Pairwise比对、局部比对、多重比对等方法。
这些方法都有自己的特点和适用范围,根据具体的研究目的和数据特点选择合适的方法进行序列比对。
进化树构建是生物信息学中的重要研究方向之一,用于揭示不同生物种类之间的进化关系。
进化树是一种图形化的表示方式,能够清晰地展示物种间的分支关系、共同祖先以及进化时间。
进化树的构建主要基于序列的相似性和进化关系。
在进化树构建中,常见的方法包括距离法、最大简约法和最大似然法。
距离法基于序列间的距离矩阵,通过测量序列间的差异程度来构建进化树。
MEGA软件——系统发育树构建方法
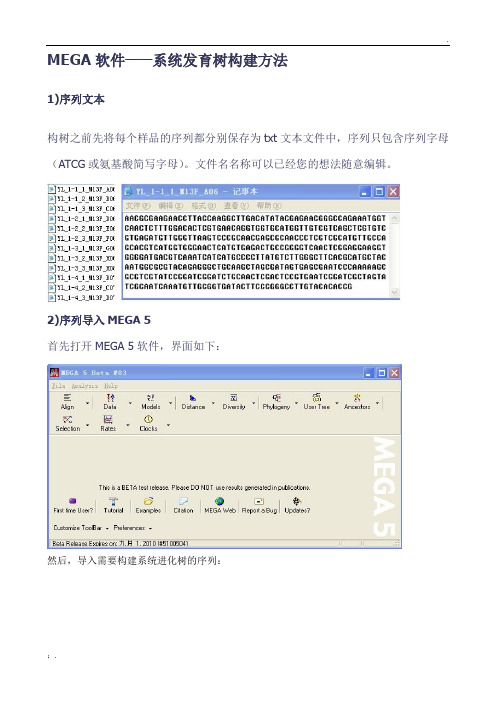
MEGA软件——系统发育树构建方法1)序列文本构树之前先将每个样品的序列都分别保存为txt文本文件中,序列只包含序列字母(ATCG或氨基酸简写字母)。
文件名名称可以已经您的想法随意编辑。
2)序列导入MEGA 5首先打开MEGA 5软件,界面如下:然后,导入需要构建系统进化树的序列:点击OK出现新的对话框,创建新的数据文件导入成功3)序列比对分析点击W,开始比对。
比对完成后删除序列两端不能完全对其的碱基。
系统分析然后,关闭该窗口,在弹出的对话框中选择保存文件,文件名随便去,比如保存为1。
4)系统发育树构建以NJ为例Bootstrap选择1000,点Computer,开始计算计算完毕后,生成系统发育树。
以下“系统发育树树的修饰”方法沿用斑竹brightfuture01的方法5)树的修饰建好树之后,往往需要对树做一些美化。
这个工作完全可以在word中完成,达到发表文章的要求。
点击image,copy to clipboard。
新建一个word文档,选择粘贴。
见下图:在图上点击右键-编辑图片,就可以对文字的字体大小,倾斜等做出修饰。
见下图:这个时候可以通过Adobe professional 对其进行图像导出:先将此word文档打印成PDF,见下图:将打印出来的PDF保存在桌面上,打开,如下图:此时,点击工具,高级编辑工具,裁剪工具,如下图所示:选择需要的区域以删除周围的空白区,双击发育树,会出现下图:点击确定,出现下图(把空边切掉了):点击文件,另存为,在保存类型一栏中选择TIFF格式,点击确定后会生成下面这个图片,所生成图片绝对可以满足文章的发表:OK,结束了,自己玩一把吧。
生物信息学中的序列比对与进化树构建

生物信息学中的序列比对与进化树构建生物信息学是一门涉及生命科学和计算科学的交叉学科,其应用在分子生物学、生物医学、生态学、进化论、生物技术等诸多领域中。
序列比对和进化树构建是生物信息学的重要组成部分,是理解生物学进化的重要途径之一。
一、序列比对序列比对是将两个或多个蛋白质或核酸序列究竟有多少相同、多少不同进行比较的过程。
序列比对在生物学中极其重要,因为它可以帮助科学家确定两个生物物种之间的相似性,进而推断它们之间的亲缘关系以及共同祖先的时间。
序列比对中最基础和常用的方法是全局比对和局部比对。
全局比对试图比较两个序列的完整长度,一般用于比较相似性较高的序列,它最先被应用于分析DNA和蛋白质,是序列比对过程中最古老、最经典的算法方法。
而局部比对则更注重比较两个序列中的相似区域,忽略其中任何间隔,通常用于比较两个较短的序列或者两个相对较不相关的序列。
例如,在核酸序列比对中,这种算法更适用于获取多个剪接变异或者重复序列之间的相似性。
另外,序列比对有一个关键问题,就是如何准确的衡量两条序列的相似性和相异性。
在这方面有很多方法,例如编辑距离、盒子型、PAM矩阵、BLOSUM 矩阵等等,其中都采用了不同的评分标准。
二、进化树构建进化树(Phylogenetic Tree)是用来表示生物物种间亲缘关系的结构,也称演化树或家谱树。
进化树是通过对基于DNA和RNA等生物分子序列进行分析,推导出各物种之间共同祖先的关系构建起来的,同时它也综合了形态、系统和分子信息等其他生物学数据。
进化树的构建过程中涉及许多算法,其中最基础的是贪心算法。
贪心法从序列的最初状态开始,一步步选择最佳的演化路径,最终得到最优的进化树;而Neighborhood-joining (NJ)算法则是以序列之间的 Jukes-Cantor 模型距离或 Kimura 二参数模型距离为基础,使用最小进化步骤(Minimum Evolution,ME)标准构建进化树,是目前应用比较广泛的算法。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
蛋白质序列进化(protein sequence phylogenetic},一种用于测定各种生物之间遗传关系的技术。
#百度百科#一般通过蛋白质的氨基酸序列进行比对后建树,方法过程如下:
首先由NCBI或其他查询基因途径获取要比对的目的蛋白氨基酸序列(网站上有很多此类说明)我的由于序列较多,就先把氨基酸序列复制到文本文件中
之后将序列文本文件扩展名改为.fas
之后打开MEGA软件进行序列比对,选择Align---Edit/Build/Alignment---Retrieve sequence from a file---选择文件---确定,输出结果默认以最右端蛋氨酸对齐,如图
在建树之前序列应该以保守序列比对模式进行,选择Alignment---Align by ClustalW,以输出以保守序列比对结果,如图
保存序列比对文件,默认格式为*.mas格式,并选择phylogeny---construct/Test UPGMA Tree进行建树,步骤如图
选择蛋白序列
之后就会输出树,如下
之后可以根据不同要求更改树形,选择下图按钮进行输出设置并输出环形树
之后可以保存到指定文件,同时也可以将树以pdf格式导出,选择image---Save as pdf file或者png file。