张伟豪AMOS培训视频7笔记
张伟豪元分析培训视频笔记示例7

先讲文章的重要性和介绍概念
然后介绍研究方法
这里介绍太笼统,没有介绍文章都从哪里来的,只说了找到30篇
H统计量再次出现
里面的H2.8值就是Q值226.61除以K-1,K就是样本数
总结:元分析文章流程
首先选定主题,告诉别人主题有多么重要
然后要决定做的是哪些变量的关系
接着做文献搜索,包括用哪些关键词、数据库,搜索了多少篇扣除掉重复的等剩下多少篇然后进行分析,首先分析是固定效果模型还是随机效果模型
如果是随机效果模型就要研究异质性,看I、H、R、Q等指标
如果存在异质性,要做调节变量分析
如果是类别变量就做次群体分析,如果是连续变量就做元回归分析
然后检验有没有出版偏误,如果有,你是怎么检查的,选择一个出版偏误的分析方法
做完了就介绍有没有出版偏误,有没有校正
接着可以做一下敏感度分析,看一下有没有离群值或者累计分析中的按一定标准的发展趋势最后就要写结论。
张伟豪元分析培训视频笔记-L5-0114-多重结果在研究中的应用

比如上图要做一个TPP计划行为理论的研究,AAA代表一篇论文,里面会有三种关系,就是outcome栏里的,那么这个就需要做多重结果
后面就需要选择相关分析correlation,如上
然后建立上图档案,红框中选择auto就行了,前面相关系数一定要输入文章中的皮尔森相关系数,不能输入回归系数,切记!
分析结果后,如果要查看分开的结果,就需要选红框中select by
选择框中的选项,就是选三个其中一个,因此左边框中的出来的结果就是选中的分析结果
如果要把三个所有结果都做出来,就选择上图红框中的选项
结果就会三种都出现
如果要将三种结果作对比,就是ATTtoBI,PBCtoBI等,就要选择group by选项,如上,选择群组比较
结果如上,那么这个和次群体比较有什么区别呢?解释如下
如果要做如上分析,相当于在前面例子的基础上又加上了性别分组
整合之后就如上,这样的话就相当于将次群体和多重结果两项功能合并了,那么就可以在一篇论文中比较不同性别结果有什么不一样,不同性别间的不同变量比较有什么不一样等。
张伟豪元分析培训视频笔记-L5-0108-异质性检验Heterogeneity

如果组间方差够大,就是有异质性,一般组间方差占组内方差超过三分之一,就是够大了。
如果异质性值大于0.1(因为异质性统计值不够大,所以显著性不用0.05,而用0.1),那么就是没有异质性。
异质性检验主要的方法是卡方检验或者称为Q检验异质性检验是检验组间差异,主要检验指标就是上图中的统计检验的三个值,T2,Q检验,I2那么I2是怎么得来的?看上图中,分析数据出来后就是上图中的森林图上图中,森林图每条线段的中间点是点估计值,点的两边线段就是区间估计值。
1.00代表没有异质性(如果是OR或CR,就是1,如果是相关分析就是0)。
也就是区间包含0或1代表不显著,比如第一条线段包含1,显著性就是0.116,不显著,第二条线段不包含1,显著性就是0.000,显著。
森林图是视觉看有没有异质性,上图看着每条线段差距比较大,有左有右,认为是有异质性,就需要看下next table。
Df自由度是12代表有13篇论文,Q-value的显著性显著,代表有异质性。
上图中的T au Squared就是组间方差,I-Squared就是Tau(组间方差)除以组间加组内。
一般I-Squared值低于25%代表没有异质性,50%以上比较严重的异质性,上图中已经是92.645,代表有很高的异质性。
上图为森林图,黑框越大,代表样本数越大,权重越大。
黑框两边为置信区间,如果穿过Y 轴,代表置信区间包含0,也就是不显著。
Y轴有可能是0,有可能是1(上边解释过原因)。
菱形代表所有样本的集合,因为是所有样本,所以置信区间很小,小到看不到。
异质性检验不能在统计结果出来后再解释为什么有异质性,应该是作者在数据建档之后就要解释“论文可能存在异质性,原因可能是。
”,而不能在统计结果出来再解释。
异质性的来源有以上几种然后要找出异质性的原因,其实就是进行调节变量分析调节变量分析就两类,一类是类别变量,就是方差分析,一类是连续变量,就是回归分析如果做回归分析,要有5个尺度,也就是5个选项。
张伟豪元分析培训视频笔记-L5-0120-出版偏误

出版偏误就是我们没有找到的文章对我们结果的影响,因为没有找到的文章都被作为缺失值,而出版偏误属于非随机缺失,因此会对结果产生影响检验出版偏误由以上几种方法运行数据后,点击红框选项,进行出版偏误分析首先出现漏斗图,发现漏斗图两侧的点并不均衡,左边很多,右边没有,说明可能有出版偏误但是还要看具体统计数据,选择view下面的选项,可以看不同的出版偏误解释方式,先看第一个以上数字的意思是还需要找多少篇不显著的文章,才能没有出版偏误,也就是将Alpha值设为0.05,也就是大于0.05(不显著),而Z值到达了1.95995,也就是小于1.96(不显著),才能达到研究不显著。
那就需要424篇,才能达到不显著。
而我们只有13篇文章,差距太大了,显然不太可能,因此说明我们没有出版偏误。
但是差距多大算差的多?如果现在不是424篇而是42篇呢?这个差距大还是小?现在还没有学者给出标准,因此只能看P值的显著性,P小于0.05就说明没有出版偏误。
下边的分析是指,不一定非要找不到的文章都是不显著的,可以有一点或一小部分是显著的也不会有大的影响,因此可以自己主观设定标准,红框中和下边的1都是不显著,可以自己设定一下,有一点显著的标准,比如0.95,0.98等我们先设定为0.9,下边的均值比率先保持1,然后计算结果显示,还需要41篇文章,才能达到我们设定的标准如果我们把均值比率也设定为0.95,那么结果显示还需要80篇文章才能达到我们设定的标准。
但是问题和上面方法一样,没有标准告诉我们究竟差多少篇才算够大,没有出版偏误。
因此我们一般用上面的经典方法,看P值就可以了。
我们再看其他几个结果,点红框中的next table红框中的上面是没有修正的结果,下边是修正后的结果,如果这个P值大于0.05,说明没有出版偏误,以上两个结果都大于0.05,说明没有出版偏误再看下一个报表,也看红框中的P值,也大于0.05,说明没有出版偏误。
那么这几个计算结果都一样,如果出现有的有偏误有的没有该怎么办呢?这就要用到最后一种方法trim and fill上图为运行结果这种方法的原理是,先把左边偏离比较多的,影响比较小的文章移除,每移除一个就计算一次,看看是否平均分布,如果没有再继续移除,直到平均分布为止,最后会算出一个校正后的效果量,trim就是剪的意思。
张伟豪元分析培训视频笔记-L5-0117-CMA分析与报表解读

以上是元分析的步骤以上为森林图点击红框中,放大图形放大后可以再调整尺寸,如红框中放大后图形,方框的大小代表权重,越大代表权重越大。
方框是点估计值,也就是左边中的ODDS ratio,两边线段是置信区间,如果不包含1,(因为是ODDS ratio,所以是1,要是RR 就是0),那么就是显著,如果包含了就是不显著,Z值小于1.96,P值大于0.05,说明就是不显著上图红框代表权重,一般文章里不会报告权重如果放大显示,权重就显示为数字,而不是图形了上图为分析的固定效应和随机效应,随机效应的置信区间明显比较宽,是因为随机效应加入了组间方差,因此会比较宽,而且点估计值也不一样。
需要报告哪个就写哪个下一步要看有没有同质性或异质性,如果没有异质性就用固定效应,有异质性就用随机效应。
从森林图中看,每个研究的估计值和区间都差很多,因此直觉判断为有异质性,然后就要看计算结果点next table看结果结果中卡方值Q为163.165,主要看P值,小于0.1,说明有异质性,I值为92.645,一般I 小于25为没有异质性,25到50之间为一般异质性,大于75为高度异质性。
T值为组间方差,I值为组间方差T除以总方差,也就是说组间方差所占比例高达92.645,每组和每组间的差异很大。
I值为标准化值,范围从0到1.另外,I值的缺点是如果样本比较少,比如只有十几篇文章,那么I值就会不太精确。
点击红框可以更改图表颜色,用以复制到word中去一般P值小于0.1就可以,说明就有异质性,如果看森林图里有明显的的偏离中心而且权重比较大的值,可以把这篇文章删掉,那么P值就可能大于0.1了,这样就说明没有异质性,直接报告固定效应的值就可以了另外一个判断异质性的标准就是I值,上图为I值的特性异质性的处理,一种是有异质性就不进行元分析,第二种是探讨原因,忽略后直接进行随机效果分析(后边会讲到这两种方法,分别是上图中的次群体分析和元回归分析),第三种是找出极端值,删除后直接用固定效果报告。
张伟豪SPSS培训视频7笔记(T检验和方差检验)
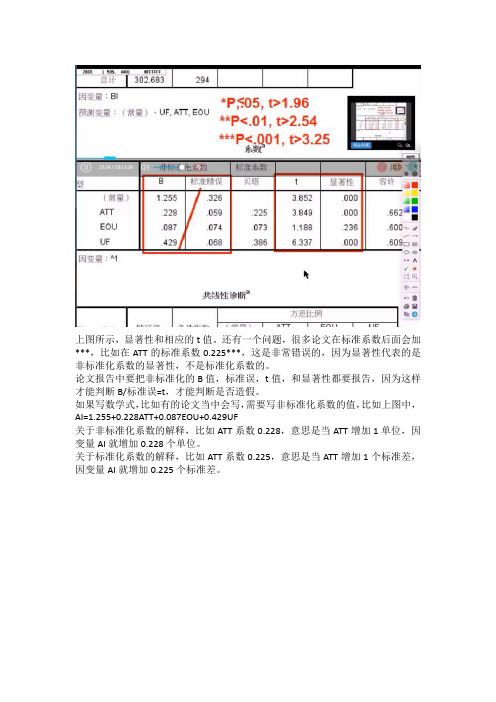
上图所示,显著性和相应的t值。
还有一个问题,很多论文在标准系数后面会加***,比如在ATT的标准系数0.225***,这是非常错误的,因为显著性代表的是非标准化系数的显著性,不是标准化系数的。
论文报告中要把非标准化的B值,标准误,t值,和显著性都要报告,因为这样才能判断B/标准误=t,才能判断是否造假。
如果写数学式,比如有的论文当中会写,需要写非标准化系数的值,比如上图中,AI=1.255+0.228ATT+0.087EOU+0.429UF关于非标准化系数的解释,比如ATT系数0.228,意思是当ATT增加1单位,因变量AI就增加0.228个单位。
关于标准化系数的解释,比如ATT系数0.225,意思是当ATT增加1个标准差,因变量AI就增加0.225个标准差。
在自变量之间不能有共线性,因为会导致有共线性的自变量太过雷同,自变量之间区分不出谁对因变量有影响,出现错误的估计。
在自变量和因变量之间同样不能有共线性,比如上图,态度如果和行为意图之间的相关性如果是0.8,那R方就是0.8的平方,也就是0.64,也就是说态度就可以解释64%的因变量,那剩下的几个自变量对因变量的解释就太少了,会导致剩下的自变量都不显著。
如果出现自变量和因变量有共线性,那么可以通过以下观察发现。
1、标准化系数贝塔会出现负值。
因为只要皮尔森相关都是正值,回归就都会是正值,出现负值就意味着有共线性存在。
2、贝塔值的平方会高于R方,正常情况下贝塔值的平方是不会高于R方的。
容许(容差)的计算方法,比如ATT的容许,是把ATT作为因变量,其他两个自变量对它进行解释,如果有共线性的话,相关性就会比较高,那么R方也会比较大,1-R方,就是容许量,因此容许量比较小,就说明有共线性,而VIF是容许的导数,容许量比较小,它的导数就会比较大,就是有共线性。
上图中的常量是不用解释的,因为它的大小无所谓,不会有影响,显不显著也没关系。
在回归分析的方法下拉菜单中,有以上几种方法,分别是什么意思呢?输入法表示,我们几个自变量对因变量是有假设的,假设他们之间有相关关系,然后再做回归。
张伟豪元分析培训视频笔记-L5-0107-固定效果与随机效果Fix and Random effect model
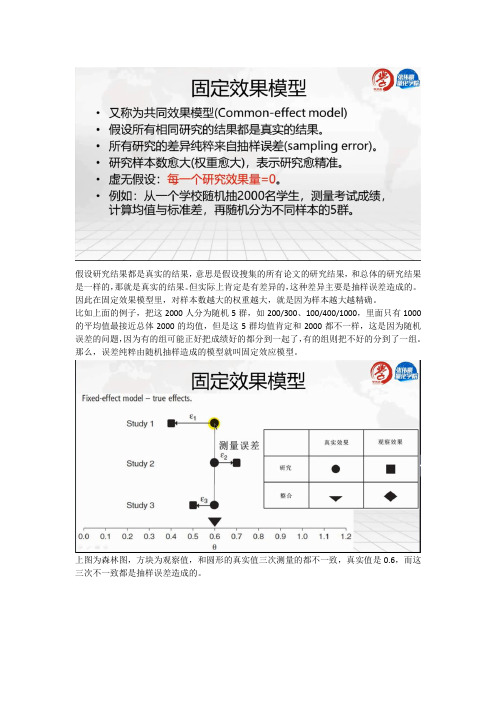
假设研究结果都是真实的结果,意思是假设搜集的所有论文的研究结果,和总体的研究结果是一样的,那就是真实的结果。
但实际上肯定是有差异的,这种差异主要是抽样误差造成的。
因此在固定效果模型里,对样本数越大的权重越大,就是因为样本越大越精确。
比如上面的例子,把这2000人分为随机5群,如200/300、100/400/1000,里面只有1000的平均值最接近总体2000的均值,但是这5群均值肯定和2000都不一样,这是因为随机误差的问题,因为有的组可能正好把成绩好的都分到一起了,有的组则把不好的分到了一组。
那么,误差纯粹由随机抽样造成的模型就叫固定效应模型。
上图为森林图,方块为观察值,和圆形的真实值三次测量的都不一致,真实值是0.6,而这三次不一致都是抽样误差造成的。
随机效果模型——每个论文之间由于样本、研究方法等的不一致,造成研究结果不一致,这叫做组间方差。
每个研究本身因为样本等原因,和真实值也会有误差,这叫做组内方差。
总方差就是组内加组间方差,当模型里面是这两个方差相加的时候,就是随机效果模型总方差就是组间方差加上组内方差(固定效果),整个的模型就是随机效果模型。
随机效果模型如上图——虚无假设是所有研究平均效果量为0,固定效果模型是每一个研究平均效果量为0.举例说明,从5个学校抽2000人,这5个学校之间就有差异,比如有的学校好,有的差,那么这个就是组间差异,而从每个学校抽的学生也会有差异,比如有的学生好,有的学生差,那么这就是组内差异。
所以随机效果既包括组间差异,也包括组内差异。
上图中上面的误差(方块到圆圈)是组内方差,是抽样时产生的误差,下面的误差是组间方差。
上面这段文字的意思是——固定效果里,如果选了很多论文,里面有的论文样本很小,有的样本很大,那么就会给小样本赋很小的权重,给大样本赋很大的权重,这样的话即使把那些小样本删掉,对总体也不会有很大影响。
但是随机效果里,就会把小样本赋比较大的权重,大样本赋比较小的权重,从而平衡两种样本。
7第七章 变量测量

2021/10/10
21
• 9.您偏好与友善但能力不强的同事共事,而不喜欢与难相 处但能力强的同事共事的程度有多高?
• 10.您喜欢独立完成工作,而不与他人共同合作的程度有 多高?
• 11.您偏好困难但具挑战性的工作,而不是简单但例行性 工作的程度有多高?
• 12.您偏好极具挑战性的工作,而非适度挑战性任务的程 度有多高?
• 13.在过去3个月中,您多常从上司那边寻求回馈,以了解 自身的工作表现?
• 14.在过去3个月中,您多常从同事那里寻求回馈可以了解 自身的工作表现?
• 15.在过去的3个月中,您多常从部属一同检讨您的作法有 无造成他们效率不彰?
• 16.如果周围的人对您的积极工作表现没有反应,这会使
您感到挫折的程度有多高?
• 1.受到工作所驱策:高成就动机的人可能为了得到“达到与完成” 的满足而整天工作;
• 2.他们常是闲不下来的,或是难以将注意力转移到工作之外的活动; • 3.由于他们总是想要获得达成目标完成的感觉,所以偏好独立作业
而非与他人合作; • 4.由于具有想要达成目标及享受事情完成的心态,他们宁愿选择具
挑战性的工作,而不是太简单、平凡单调的工作。但是也考虑到达 成的几率与期望,所以即使真的太有挑战性、失败率高的工作,他 们也不想接; • 5.渴望知道他们在工作中的进步情况,故想要从上司、同事,甚至 部属那边得到直接、频繁且细微工作表现的回馈。
• ④操作定义所提示的测量或操作必须可行; • ⑤用多种方法形成操作定义,既可以从操作入
手,也可以从测量入手。
2021/10/10
31
• 操作性定义和抽象定义的比较
操作性定义
目标 具体:描述变量的具 体行为、特征和指标
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
调节变量一般做论文很难做出来,因为中介变量是调节变量的特例,在特定状况下叫中介效应,在分散状况下叫调节效应。
做论文时很难收集到很分散的样本,因此很难做调节效应。
上图中,如果学生爱参与不参与,无所谓,那就是参与比较分散,这时候就是调
节效应。
如果学生全部都参与,而且参与度高,那就是中介效应。
如果做调节变量,所收集的样本之间的样本数不能超过4倍。
如上图中,收集的男生样本比如是500,女生样本是100,那就超过了4倍,是不能做调节的,男生样本必须在400以内,或者女生样本数调高才能做调节。
如何做调节变量的验证?如下
首先做观察变量之间的调节效应,需要的条件如上图
检验的程序如上图,操作如下
先画四个变量之间的图,如上
计算GM也就是gender*marrige需要使用spss计算,打开数据文件,选“转换”选项里的“计算变量”。
在对话框输入如上,确定后spss最后一列就会出来G*M的列。
然后代入amos 结构图,output只选前两项,运行。
结果显示GM并不显著,说明性别gender不是一个调节变量。
第二种情况,如下
当自变量x是连续变量时,调节变量m是分类变量,这时的检验操作如下
首先建立上图的简单模型,看看SQ对LOY的影响会不会受性别的影响
然后点击左边的group number1,就会出来一个对话框,点new,就会新增一个group number2.
然后双击这两个group,把他们分别命名为male和female。
这时点击数据选取,显示female还没有选取数据,选取同样的数据给female。
然后要告诉数据群组变数是谁,所以点红框中选项,在弹出的对话框中选择gender,就是告诉它群组变数是性别。
这时后边就会出现gender。
然后再点击group value,选取各自的值。
在弹出的对话框中选择1代表male,0代表female。
这时候样本数就会显示出来变化。
然后在两个group的路径上分别名称改为male和female。
注意all groups的对勾要去掉,不然它会把两个group弄混。
这个命名只能用英文,不能用数字。
在上图处要新增一个model,不要删除原来的这个。
双击红框上边的原来model,在弹出的对话框中点蓝框中的new,然后把绿框中的male和female双击选进去,他们就会自动加=号。
上图中male=famale其实就是假设零,如果检验结果他们的p值小于0.05,就说明零假设被拒绝,male不等于female,说明调节作用成立。
如果p值大于0.05,
不能拒绝零假设,male等于female,二者没有差异,说明调节作用不成立。
运行,打开output中的红框部分model comparison查看
结果显示出模型的各个拟合度,主要看p值,大于0.05,不显著,说明男女没有明显差异,调节效应不存在。
如果是三个自变量,其实大同小异,前面的操作都一样,直到下图
路径命名分别为m1/m2/m3和f1/f2/f3,然后再点击default model新增
这时每新增一个f1=m1,就要点一下new,不能一下全点进去,那样系统会认为是检验总体效果。
比如最后加了一个overall,故意让它显示总效果,把123全选进去。
最后结果显示总效应显著,为0.028,说明至少有一个显著,那就是mo1。
如果总效应不显著,那就是所有123都不显著。
因此没有必要做总效应。
第三种情况,自变量x是类别变量,调节变量m是连续变量
做法和case1(case2的第二种方法)一样
先在spss里做出性别与SQ的乘积项
然后再画模型,导入数据
最后得出0.719,不显著,调节效应不存在。
另附:
如果自变量是分类变量,而且不像性别一样是男女2个,可以分为0和1.而是像工资一样,分为高中低,那么这种自变量应该如何分析?如下
现在要将income这个变量作为自变量分析,他一共有123高中低三档。
首先要将三类变量变为哑变量(指0和1),先写在空白纸上,这样不会弄错。
在上图中,在spss中选择转换——重新编码为不同变量
在对话框中把income选进去,然后在名称上命名一个d1,选进去,就成了
income3=d1。
然后再点击旧值和新值
上边第一个图,在左边的红框里值输入2,右上红框输入1,也就是所有原来的2,都转换为1,点添加,进入框里。
上边第二个图,点击左下角,选中,在右上角输入0,意思是所有原来其他的值都成为0,点添加,进入框里。
数据里就会出现d1。
然后按以上步骤,设计另外一个d2,将原来的3转换为1,其他原来值转换为0,数据就生成d2。
然后画模型,将SQ设为调节变量,新设计的d1和d2为自变量。
然后再按上边
步骤,将SQ*d1,SQ*d2。
将新的SQ*d1,SQ*d2放进模型,画相关后运行
两个值都不显著,说明调节效应不存在。
疑问:为什么要将123的分类变量转换为哑变量1和0,直接用123不行么?老师说2类以上的分类变量都要转哑变量,2类以上不能做么?不明白,有待以后验证。
后听老师回答问题,说2类以上变量必须转哑变量也就是0和1,不然没法分析。
而只有两类时设0和1,还是1和2,还是2和100等等都无所谓,只要一个大一个小就行了,因为电脑只要计算大减小就可以。
这可能就是为什么3个以上的变量要转为两个的哑变量的原因吧。
注:形式错误1——没有说他有。
也就是得到了95%的统计显著性,而真实结果却是另外的5%。
形式错误2——有说他没有。
也就是得到95%的可能这个是不存在的,但真实结果却是另外的5%,事实上是存在的。
第四种情况
自变量和调节变量都是连续变量,上图中2都是以往的做法,张老师说这两种都不需要做,因为做不做结果都是一样的。
但是还是需要掌握这种平均中心化和标准化的技巧。
如下
首先如何计算mean center平均中心化
在spss中选中需要做的数据那三列,选择数据——汇总,
然后选择那三项数据,放入变量摘要框中,确定
最后三列就会出现那三个数据的平均值
再选择转换——计算变量
在对话框中,目标变量起个名字,选原始数据ATT减去刚才求出的它的平均数ATT_mean,确定后最后一列就会出现它的mean center平均中心化值。
剩下的两个变量eou和uf的mean center 也同样方法算出。
做哪两个的交互作用,就把这两个中心平均化的值相乘,和上边一样的做法,得出一个乘积值(交互值)。
然后画图,代入数据,看结果中交互项的显著性,也就是红框中UXEU的值。
结果发现,代入原始值,交互项是显著的
然后代入标准化值和中心平均化值后,交互项都是显著的。
刚才显示了如何做mean center中心平均化的做法,那如何将数据标准化?如下
选择分析——描述性统计——描述
然后把要标准化的值选入,勾选红框中的选项,就会另存出来标准化的数据值。