stata 实习1
stata上机实验第一讲

添加标签
1。为整个数据添加标签:例如,将数据命名
为“工资表”。 菜单:Data->Labels->Label dataset 命令:label data “工资表“ 2。为变量增加标签,例如,给变量wage增 加标签“年工资总额” 菜单:Data->Labels->Label variables 命令 label variable wage “年工资总额"
1。所有的系统自带数据可以利用sysuse命令
打开。 2。Use命令只能打开 C:\data 或者 D:\data 中的数据。 3。如果需要打开其他文件夹的数据,必须改 变目录(例如,将自己的数据放入D:\abc) cd "D:\abc” 或者直接 file------open
先学习几条最简单的命令
Stata的菜单介绍
最重要的菜单项:
Data菜单 Graphic菜单
Statistics菜单
每执行一个菜单性会自动产生相应的命令。
(以summarize为例)。 我们的讲述尽量兼顾到命令操作和菜单操作 两种方法,以命令方式为主。
安装指南
解压 setup.rar
运行 setup 安装时选择 Stata SE
装到: C:\Program file\stata10 中。 将所用系统自带的一些系统数据、应用程序、 帮助文件安装到 C:\Program file\stata10\ado\base 中 将所有升级程序安装到: C:\Program file\stata10\ado\update 中
Stata数据的录入
1。直接录入。
stata案例报告

Stata案例报告: Step by Step思考导言Stata是一种功能强大的统计分析软件,广泛应用于各个领域的研究和实践。
在本篇文章中,我们将通过一个实际的案例来展示如何使用Stata进行数据分析,并逐步呈现我们的思考过程。
数据介绍我们选取的数据是某个医院的病人信息记录,包括病人的基本信息(如年龄、性别、婚姻状况等)、疾病诊断信息以及治疗结果。
我们的目标是通过对这些数据的分析,了解不同因素对病人治疗结果的影响。
第一步:加载数据首先,我们需要将数据加载到Stata中进行分析。
我们使用use命令来加载我们的数据文件。
use "patient_data.dta"第二步:数据清洗在进行数据分析之前,我们需要对数据进行清洗和准备工作。
我们可以使用Stata提供的各种命令来完成这些任务。
例如,我们可以使用describe命令来查看数据的基本统计信息。
describe通过查看数据的描述信息,我们可以得到数据的整体情况,包括变量的类型、缺失值情况等。
如果发现数据中存在缺失值,我们可以使用drop命令或者replace命令来处理缺失值。
第三步:数据分析在进行数据分析之前,我们需要明确我们的研究目标。
在这个案例中,我们的目标是了解不同因素对病人治疗结果的影响。
因此,我们可以选择适当的统计方法来分析数据。
在这个案例中,我们可以使用Logistic回归模型来分析病人的治疗结果与其他变量之间的关系。
我们可以使用logit命令来拟合Logistic回归模型。
logit treatment_result age gender marital_status通过Logistic回归模型的结果,我们可以得到各个变量的系数和显著性水平,从而了解不同因素对病人治疗结果的影响程度。
第四步:结果解读在得到分析结果之后,我们需要对结果进行解读,从而得出结论。
在这个案例中,我们可以根据Logistic回归模型的系数和显著性水平来判断不同因素对病人治疗结果的影响。
STATA实验课

Lab 2Four topics :Do file , Data Management, Graphics and Test after estimation1 Do file⏹s tore the commands in a file⏹s ame as Program Editor in SAS⏹s ame as m-file in MATLABthe grammar of STATA:[by varlist:] command [varlist] [=exp] [if exp] [in range] [weight][using filename] [, options] Example : create a do file and save it2 Data Management(1) Stata commands in this unitcd Change directorymemory Display a report on memory usageset memory Set the size of memoryinfile Read unformatted ASCII (text) dataclear Clear the entire dataset and everything elseinput Enter data from keyboardsave Store the dataset currently in memory on disk in Stata data formatuse Load a Stata-format dataset describe Describe contents of data in memory or on diskcount Show the number of observations list List values of variableslabel data Apply a label to a data set label variable Apply a label to a variablerename Rename a variable generate Creates a new variable keep if Keep observations if condition is metkeep Keep variables orobservationsdrop Drop variables or observationsappend Append a data file to current filesort Sort observationsmerge Merge a data file with current file(2) Example:cd d:\stata /*the folder of my Stata dataset*/ memoryset memory 200minfile str20 month RM_RF SMB HML RF using ff.txt, clearinput id str20 name math1 “Jim”952 “Lucy”803 “Li Lei”90endsave math1input id str20 name math4 “Carl”100endsave math2input id str20 name economics1 “Jim”902 “Lucy”903 “Li Lei”854 “Carl”95endsave economicsuse math1describecountlistuse math1label data “grade”label variable id “the student ID”label variable name “the student name”label variable math “the student grade of math”rename math Chineserename Chinese mathgen meanmath=90gen devmath=math-meanmathuse GPA, clearkeep if female==1keep id sat race term blackdrop race blackuse math1, cleardrop meanmath devmathappend using math2save, replaceuse math1, clearsort idsave, replaceuse economics, clearsort idsave, replaceuse math1, clearmerge id using economicssave gradeuse grade, clearlist3 Graphics(1) Benchmark[graph] twoway plot [if] [in] [, twoway_options]plot is[(] plottype varlist ..., options [)] [||](2)plottypescatterlinelfitqfitlfitci(3) example: CEO Salary and Return on Equityuse ceosal1, cleargraph twoway scatter salary roetwoway (scatter salary roe) (lfit salary roe)tw (scatter salary roe) (qfit salary roe)tw (scatter salary roe) (lfitci salary roe)tw function x^2, ra(-10 10)4 Test after estimation⏹t est coeflist⏹t est exp=exp[=...]ExampleEx 4.1use wage1, clearreg lwage educ exper tenure test educ=0.1di (0.092029-0.1)/0 .0073299 Ex 4.。
stata 统计分析软件应用实训报告心得

stata作为一个初学者来说,极为上手,但是这是从窗口化操作上来说的,从窗口化操作上来说,比较简单,但是有要求是,数据必须是整理好的,否则对于数据的整理就好耗费好多的时间。
generate 和replace 以及in 、for 等基本命令必须熟记和熟练使用,才能对数据有初步的处理。
本人在进行学习Python有一年之久了,突然学习stata,不管怎说,stata跟Python比,要友好一些,操作要简单一些,但是呢,对于数据的处理还是差了好多,无论是Python还是R,对于数据的数据的处理能力是无与伦比的,尤其是对于完全没有格式的数据。
初学者对于stata的直观感受stata将窗口化操作和程序化编程语言结合起来,有自己非常独特的地方。
作为一名初学者,一些界面还是有些难度,data browser 还是do editor都是有点隐蔽,自学的人不见得会很熟练的找到。
而另一方面,graphs 和statistics的窗口化操作也是有很大的不便,很多功能不是很好找。
计量经济学课件——实验一(stata学生版)

实验一:一元线性回归模型的估计、检验和预测【演示内容】1、stata常用命令Stata常用命令的介绍。
(1) 查找帮助:search [查找内容]如:search save //查找用什么命令保存文档(键盘上按“q”键可以停止显示搜索结果)(2) use "路径+文件名"use "F:\stata files\2.6.dta"(3) 编辑数据edit(4) 删除数据表中的变量或一个观测值drop 变量名1 变量名2如:drop X Ydrop in 行数n //删除第n个观测之如:drop in 32 //删除第32个观测值(5) 保存数据文档save "文件路径+文件名"2、以教材P49 例2.6.1为例介绍用Eview实现一元线性回归的参数估计、检验和预测。
实验步骤1.录入数据点击菜单Data Editor,直接把数据拷贝进去并在右下边的variables的框中修改变量名为X和Y2. 散点图scatter Y X4.按照关系式Y=C+βX+μ进行OLS回归,regress Y X5. 预测(1) 求X=20000时,人均消费支出均值预测值的点估计值. predict [type] newvar [,statistic]举例:先执行回归命令:use "F:\stata files\2.6",clearregress Y X再用edit命令新增一个X值20000,在执行以下命令predict yhat [,xb]–此命令意为:生成一个名为yhat的变量,该变量的取值为根据解释变量的每组取值对应生成被解释变量的估计值,(在最后一行可以看到X=20000所对应的Y的估计值)(2)求当X=20000时,人均消费支出均值预测值和个值的\95%的置信区间。
use "F:\stata files\2.6.dta",clear(1) regress Y X(2) 然后在数据chapter9_1中增加一个X的取值为20000(3) predict yhat–将每个x值对应的y的估计值存放在变量yhat中,则在X=20000的最后一个观测值可以看到对应的Y的预测值的点估计值(4) predict sef, stdf–生成一个名为sef的变量,该变量的取值为预测误差的标准差(5) predict sep, stdp–生成一个名为sep的变量,该变量的取值为预测值的标准差(6) scalar tc=invttail(29,0.025)–定义标量tc,其取值为自由度为29的t变量概率为0.025的临界值。
stata 实验设计
1.选择合适的数据使用EXCEL软件进行均值、最大、最小、方差、标准差、分布、矩阵乘法、求逆、两变量线性回归、两变量多项式回归的求解与作图等。
2.选择一个合适的同质性DMU数据(如同类企业、单位)进行DEA运算。
主要包括CCR.BCC.SBM.超效率的计算。
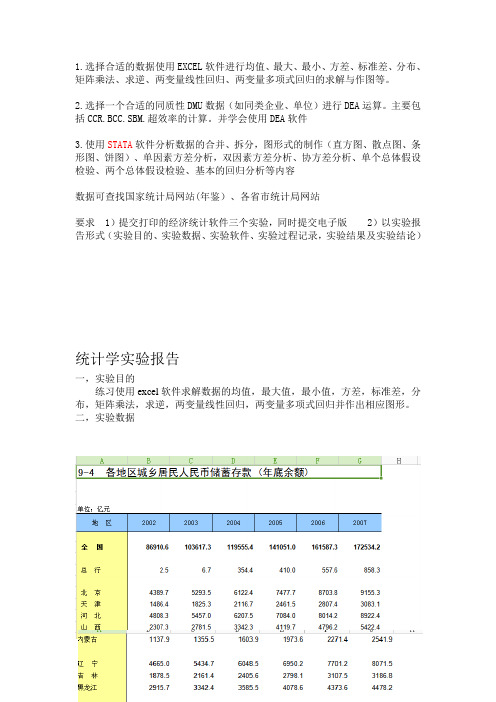
并学会使用DEA软件3.使用STATA软件分析数据的合并、拆分,图形式的制作(直方图、散点图、条形图、饼图)、单因素方差分析,双因素方差分析、协方差分析、单个总体假设检验、两个总体假设检验、基本的回归分析等内容数据可查找国家统计局网站(年鉴)、各省市统计局网站要求1)提交打印的经济统计软件三个实验,同时提交电子版2)以实验报告形式(实验目的、实验数据、实验软件、实验过程记录,实验结果及实验结论)统计学实验报告一,实验目的练习使用excel软件求解数据的均值,最大值,最小值,方差,标准差,分布,矩阵乘法,求逆,两变量线性回归,两变量多项式回归并作出相应图形。
二,实验数据三,实验软件Excel软件四,实验过程记录选取《各地区城乡居民人民币储蓄存款(年底余额)》中2007年全国各省市的数值计算均值,最大值,最小值,方差,标准差等。
得到2007年全国各地区城乡居民人民币储蓄存款的均值为5341.26亿元。
得到2007年全国各地区城乡居民人民币储蓄存款的最大值为22243.39亿元。
利用描述统计得出选取2002年的到2007 的全国城乡居民人民币储蓄存款余额与国民生产总值的值,得到下表,进行回归分析。
做出折线图如下:一元回归分析如下:y=1.4621x-14260多项式回归分析如下:103522*108*1010.48333545y x x x --=-+-。
stata学习体会

stata学习体会第一篇:stata学习体会stata学习心得(网络版存盘)2009-03-25调整变量格式:format x1 %10.3f ——将x1的列宽固定为10,小数点后取三位format x1 %10.3g ——将x1的列宽固定为10,有效数字取三位format x1 %10.3e ——将x1的列宽固定为10,采用科学计数法format x1 %10.3fc ——将x1的列宽固定为10,小数点后取三位,加入千分位分隔符 format x1 %10.3gc ——将x1的列宽固定为10,有效数字取三位,加入千分位分隔符format x1 %-10.3gc ——将x1的列宽固定为10,有效数字取三位,加入千分位分隔符,加入“-”表示左对齐合并数据:use “C:Documents and Settingsxks桌面2006.dta”, clear merge using “C:Documents and Settingsxks桌面1999.dt a” ——将1999和2006的数据按照样本(observation)排列的自然顺序合并起来use “C:Documents and Settingsxks桌面2006.dta”, clear merge id using “C:Documents and Settingsxks桌面1999.dta” ,unique sort ——将1999和2006的数据按照唯一的(unique)变量id来合并,在合并时对id进行排序(sort)建议采用第一种方法。
对样本进行随机筛选: sample 50 在观测案例中随机选取50%的样本,其余删除 sample 50,count 在观测案例中随机选取50个样本,其余删除查看与编辑数据:browse x1 x2 if x3>3(按所列变量与条件打开数据查看器)edit x1 x2 if x3>3(按所列变量与条件打开数据编辑器)数据合并(merge)与扩展(append)merge表示样本量不变,但增加了一些新变量;append表示样本总量增加了,但变量数目不变。
Stata数据描述性分析实习报告

Stata数据描述性分析实习报告
describe
describe命令可以描述数据文件的整体,包括观测总数,变量总数,生成日期,每个变量的存储类型( storage
type),标签( label)等。
list[varlist]if exp][in range]
summarize[varlist][weight][if exp][in range][,detail]
summarize可以提供varlist指定变量(可以不止-一个)的如下统计量: Percentiles (分位数),四大最大的数和四个最小的数, Variance (方差), Std. Dev. (标准差), Skewness (偏度), Kurtosis (斜度)
tabstat
tabstat varlist[weight][if exp][in range][stats(statname
[..])]
tabstat提供[stats(statname..)
]指定的统计量,可供选择的有mean(均值) ,count(非缺失观测值个数),sum(总和),max(最大值),min(最小值),range(最大值-最小值),sd(标准差),var(方差),CV(变易系数=标准差/均值),skewness(偏度), kurtosis (斜度), median (中位数), p1 ( 1%分位数,类似地有p5,
p10,p25,p50,p75,p95,
p99 ), iqr ( interquantile range=p75–p25 )。
比如,想知道变量pop在整个样本的均值和方差,可以使用如下命令: tabstat pop,stats(mean var)。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
五、 Stata的程序设计功能
Stata是一个统计分析软件 ,但它也具有很强的程序语言功能,这给用户提供了一个广阔
⑵ 可以将分组变量转换成指示变量(哑变量),将字符串变量映射成数字代码。 ⑶ 可以对数据文件进行横向和纵向链接,可以将行数据转为列数据,或反之。 ⑷ 可以恢复、修改执行过的命令。 ⑸ 可以利用数值函数或字符串函数产生新变量。 ⑹ 可以从键盘或磁盘读入数据。
二、 Stata的统计功能
Stata 的 统 计 功 能 很 强 , 除 了 传 统 的 统 计 分 析 方 法 外 , 还 收 集 了 近 20 年 发 展 起 来 的 新 方 法,如Cox比例风险回归,指数与Weibull回归,多类结果与有序结果的logistic 回归,Poisson回 归 、 负 二 项 回 归 及 广 义 负 二 项 回 归 , 随 机 效 应 模 型 等 。 具 体 说 , Stata 具 有 如 下 统 计 分 析 能 力:
⑴ 数值变量资料的一般分析:参数估计,t检验,单因素和多因素的方差分析 ,协方 差分析,交互效应模型,平衡和非平衡设计,嵌套设计,随机效应,多个均数的两两比较,缺 项数据的处理, 方差齐性检验,正态性检验,变量变换等。
⑵ 分类资料的一般分析:参数估计,列联表分析(χ2检验,列联系数,确切概率),流行
. exit 即可退出Stata 。 如未将数据按Stata指令存盘 ,或读入的数据或数据结构已被修改(Stata的有些命令会自 动修改数据结构, 如按某变量排序等 ),这 时,Stata将拒绝退出Stata状态 。若确实不需要存 盘而退出Stata ,可键入: . e,clear (e为exit的简写)即可强行退出Stata。或分两步,即先放弃所有数据, .drop _all 再退出Stata, . exit 二、 WINDOWS 版本的Stata 的进入和退出
⑺ 其它方法:质量控制,整群抽样的设计效率,诊断试验评价,kappa,等。
三、 Stata的作图功能
Stata的作图模 块,主要提供如下八种基本图形的制作: 直 方 图(histogram),条形图 (bar), 百分条图(oneway) ,百分圆图(pie),散 点 图(twoway),散点图矩阵(matrix),星形图 (star),分位数图。这些图形的巧妙应用,可以满足绝大多数用户的统计作图要求 。在有些非 绘图命令中,也提供了专门绘制某种图形的功能, 如在生存分析中,提供了绘制生存曲线图, 回归分析中提供了残差图等 。详见第五章。
/* 定义程序名 /* 定义数据库的最大记录数 /* 设置随机数种子, /* 定义变量rp,用于存放Poisson分布随机数 /* 计算lamda0=exp(λ)
local j=1 while `j’<`2’+1 {
/* j=1 /* 对 j<n循环,j表示产生的第j个Poisson分布随机数
现代医学统计方法与Stata应用 • 3
的开发应用的天地,用户可以充分发挥自己的聪明才智,熟练应用各种技巧,真正做到随心所
欲。 事实上,Stata的ado 文件 (高级统计部分)都是用Stata 自己的语言编写的 。 下面这段程序是
笔者自行编写的 ,用于产生 n个参数为λ的Poisson分布的随机数。
prog define rp set obs `2’ set seed `3’ gen rp=. local lamda0=exp(`1’)
在WINDOWS下 ,亦可用DOS的命令退出Stata。
§1.4 Stata的数据输入与储存
Stata可以从键盘输入数据,也可以从文件读入数据 。WINDOWS下的Stata还可以用Stata的 数据编辑器输入 、修改和管理数据。这里简单介绍如何从键盘输入数据 ,有关更详细的数据读
现代医学统计方法与Stata应用 •输 入Stata的 数 据 应 存 盘。 如欲将上述数据存入d :\mydata\ 子目录中, 文件名为ex1.dta ,命令为: . save d:\mydata\ex1 file d:\temp \ex1replace.dta save d 该指令在d :盘 的mydata子目录中建立了一个名为 “ex1.dta” 的Stata格式的数据文件。后 缀dta是 Stata内定的数据格式文件 。该格式文件只能在Stata中用use命令打开: . use d:\mydata\ex1
现代医学统计方法与Stata应用 • 1
第一章 Stata 概貌
§1.1 Stata的功能、特点和背景
Stata是 一 个 用 于 分 析 和 管 理 数 据 的 功 能 强 大 又 小 巧 玲 珑 的 实 用 统 计 分 析 软 件, 由美国计 算机资源中心(Computer Resource Center)研制。从1985至1998的十四年时间里,已连续推出 1.1,1.2,1.3,1.4,1.5,……及2.0,2.1,3.0,3.1,4.0,5. 0,6.0等多个版本,通过不断更 新和扩充,内容日趋完善。 它同时具有数据管理软件、统计分析软件、 绘图软件、 矩阵计算软 件和程序语言的特点 ,又在许多方面 别具一格。Stata融汇了上述程序的优点,克服了各自的 缺点,使其功能更加强大, 操作更加灵活、简单, 易学易用, 越来越受到人们的重视和欢迎。
/* i=1 /* r0=1 /* i循环 /* r1=均匀分布的随机数 /* r0=r1*t0 /* 如果 r0<lamda0 /* n0= i-1 /* i=-1
/* i循环
/* 第j个rp=n0 /* j循环
§1.2 Stata的界面
Windows版本的Stata的界面上有一级菜单行, 二级菜单窗口,命令窗口,结果窗口,图形 窗口,变量名窗口,已执行过的命令窗口,帮助窗口等。窗口的大小、 位置可根据用户需要进 行调整。
2 • 第一章 Stata概貌
病学表格分析等 。 ⑶ 等级资料的一般分析:秩变换,秩和检验,秩相关等。 ⑷ 相关与回归分析:简单相关,偏相关,典型相关,以及多达数十种的回归分析方
法,如多元线性回归,逐步回归 ,加权回归,稳键回归 ,二阶段回归,百分位数(中位数)回 归,残差分析、 强影响点分析,曲线拟合,随机效应的线性回归模型, 等。
四、 Stata的矩阵运算功能
矩阵代数是多元统计分析的重要工具 ,Stata提供了多元统计分析中所需的矩阵基本运算, 如矩阵的加、积、逆、Cholesky 分解、Kronecker 内积等;还提供了一些高级运算,如特征 根、特征向量、 奇异值分解等;在执行完某些统计分析命令后,还提供了一些系统矩阵,如估 计系数向量、估计系数的协方差矩阵等 。
1. 1 4 2. 2 5.5 3. 3 6.2 4. 4 7.7 5. 5 8.5 6. end
用list命令可以看到输入的数据。
. list x y 1. 1 4 2. 2 5.5 3. 3 6.2 4. 4 7.7 5. 5 8.5
Stata 的 突 出 特 点 是 只 占 用 很 少 的 磁 盘 空 间 , 输 出 结 果 简 洁 , 所 选 方 法 先 进 , 内 容 较 齐 全,制作的图形十分精美, 可直接被图形处理软件或字处理软件如WORD等直接调用。
一、 Stata的数据管理能力
⑴ Stata的数据管理空间受计算机的操作系统和计算机扩展内存的影响 。对640k内存的 微机, 3.1版本的Stata可 以 管 理2400 个记录×9 9个变量 ,并随计算机扩展内存的增加而增加; 对4.0的WINDOWS版本,Stata可以管理4800个记录×99个变量;对WINDOWS 95下的5.0版 本,可根据计算机的配置情况设置变量数和记录数 ,如32M扩展内存的计算机, 可处理 2千万 个 数 据。 变 量 数 和 记 录 数 可 以 互 相 交 易(trade ), 即 减 少 记 录 数 可 以 增 加 变 量 数, 减少变量 数可以增加记录数。
一、 DOS版本的Stata的进入和退出
前已述及, 要将Stata 程序所在的路径放入autoexec.bat 中,我们可在DOS下任何目录位置 进入Stata,但我们假定d:\ 盘上进行。 D :\>Stata 进入Stata 后,屏幕显示Stata的版本号,公司所在地等信息,Dos版本下的Stata即出现圆 点提示符。这时即可键入Stata的各种 命令。 若已在Stata状态读入了数据,并且已将数据按Stata指令存盘,或读入的数据虽经分析, 但对数据及数据结构等未作任何修改, 则只须键入 :
local i=1 local r0=1
while `i’>0 { local r1=uniform() local r0=`r1’*`r0’ if `r0’< `lamda0’{ local n0= `i’-1 local i=-1 } local i= `i’+1 }
quiet replace rp=`n0’if _n==`j’ local j= `j’+1 } end
已执行 过的命 令窗口
变量 窗口
结果 窗口
命令窗口
4 • 第一章 Stata概貌
§1.3 进入和退出Stata
⑸ 危险度分析:条件和非条件的logistic 回归,多类结果与有序结果的logistic 回归, Probit回归,及其他广义线性模型,随机效应的logistic 回归,随机效应的Poisson回归,等。
⑹ 生存分析:基线生存曲线的估计、相对危险度的估计,Kaplan-Meier生存曲线、寿命 表分析,对数秩检验,Mantel-Haenszel检验,Wilcoxon-Gehan检验,Cox比例风险模型 ,正态 截尾及Tobit 回归,指数回归和Weibull回归,等。