5分钟速学stata面板数据回归(初学者超实用!)
STATA面板数据回归(固定效应-随机效应-Hausman检验)

(8.1) (8.2)
其中, i = 1, 2, · · · , N , t = 1, 2, · · · , T ;xit 为 K ×1 列向量, K 为解释变量的个数, β 为 K × 1 系数列向量。对于特定的个体 i 而言, ai 表示那些不随时间改变的影响因素,而这些因 素在多数情况下都是无法直接观测或难以量化的,如个人的消费习惯、国家的社会制度等,我 们一般称其为“个体效应”(individual effects)。对“个体效应”的处理主要有两种方式:一种是 视其为不随时间改变的固定性因素,相应的模型称为“固定效应”模型;另一种是视其为随机 因素,相应的模型称为“随机效应”模型。
而关于面板数据的计量理论也几乎涉及到了以往截面分析和时间序列分析中所有可能出现的主题如近年来发展出的面板向量自回归模型panelvar面板单位根检验panelunitroottest面板协整分析panelcointegeration门槛面板数据模型panelthreshold等都是在现有截面分析和时间序列分析中的热点主题的基础上发展起来的
简言之,两种模型有各自的优缺点和适用范围,在实证分析的过程中,我们一方面要根据 分析的目的选择合适的模型,同时也要以 8.2.3 节中介绍的假设检验方法为基础进行模型筛选。
8.2.1 固定效应模型
模型的基本设定和假设条件 若视 ai 为固定效应,模型 (8.1) 可以采用向量的形式表示为:
yi = ai 1T + xi β + εi
采用面板数据模型进行分析的主要目的在于两个方向:一是控制不可观测的个体异质性; 二是描述和分析动态调整过程,处理误差成分。
使用面板数据主要有以下几方面的优点:
• 便于控制个体的异质性。比如,我们在研究全国 30 个省份居民人均消费青岛啤酒的数量 时。可以选取居民的收入、当地的啤酒价格、上一年的啤酒消费量等变量作为解释变量。 但同时我们认为民族习惯、1 风俗文化、2广告投放等因素也会显著地影响居民的啤酒消 费量。对于特定的个体而言,前两种因素不会随时间的推移而有明显的变化,通常称为个 体效应。而广告的投放往往通过电视或广播,我们可以认为在特定的年份所有省份所接受 的广告投放量是相同的,通常称为时间效应。这些因素往往因为难以获得数据或不易衡量 而无法进入我们的模型,在截面分析中者往往会引起遗漏变量的问题。而面板数据模型的 主要用途之一就在于处理这些不可观测的个体效应或时间效应。
课件用stata做面板数据回归 课件

短面板
• 短面板回归基本步骤
• (1)导入并设定为面板数据。 • (2)做固定效应模型,并报告聚类稳健标准误与普通标准误。 • (3)做随机效应模型,并报告聚类稳健标准误与普通标准误。 • (4)比较两个模型的聚类稳健标准误与普通标准误是否相差较大,并决定采取是否使用辅助回归的
Hausman检验。若相差较大则采用辅助回归的Hausman检验,若相差不大则采用传统Hausman检验。 • (5)通过Hausman检验,决定采用固定效应模型还是随机效应模型。 • (6)报告并分析结果。
• 如果聚类稳健标准误与普通标准误相差较大,则传统Hausman检验不适用。
短面板
• Hausman检验
Stata与其他计量软件比较
• Eviews
• 界面不够人性化,使用前最好熟悉每个命令操作的程序语言 • 数据处理能力较弱 • 强于时间序列分析,但其它回归分析(如面板数据等)、数据处理、统计分析较弱 • 软件小,对内存要求也不高 • 小块头,小智慧!
Stata与其他计量软件比较
• Stata
• 简单易懂、界面像Excel,操作多样化(即可编程,也可鼠标操作) • 数据管理能力弱于SAS,一次主要用于一个数据文件,可处理的单个数据文件受内存大小影响,可处
课件-用st • 面板数据的设定 • 短面板 • 长面板 • 面板回归与空间计量
Stata与其他计量软件比较
• SPSS • SAS • Eviews • Stata
Stata与其他计量软件比较
• SPSS
• 界面人性化,基本如Excel,很容易上手 • 数据文件最多4096个变量 • 强于统计分析,如方差分析,没有稳健方法,弱于计量分析,缺乏调查数据分析 • 程序较大,属于统计软件而非真正的计量软件 • 大块头,小智慧!
课件-用stata做面板数据回归

Stata软件提供了丰富的数据转换工具,如变量计算、数 据分组、数据合并等,方便用户对数据进行处理和转换。
03 面板数据回归的Stata实 现
数据的准备与处理
数据清洗
检查数据中的缺失值、异常值和重复值,并进行相应 的处理。
数据转换
对数据进行必要的转换,如对数转换、标准化等,以 满足回归模型的要求。
它利用个体和时间两个维度的信息, 通过控制个体固定效应和时间固定效 应,来估计参数的固定效应模型。
面板数据回归的应用场景
面板数据回归适用于研究不同个体在 一段时间内的行为和表现,例如经济 增长、消费行为、投资决策等。
它可以帮助我们更好地理解经济和社 会现象,为政策制定提供科学依据。
面板数据回归的基本假设
课件-用stata做面板 数据回归
目录
CONTENTS
• 面板数据回归简介 • Stata软件介绍 • 面板数据回归的Stata实现 • 面板数据回归的注意事项与建议 • Stata软件进阶技巧
01 面板数据回归简介
面板数据回归的定义
面板数据回归是一种统计方法,用于 分析时间序列和截面数据,以研究不 同个体在不同时间点的行为和表现。
按照安装向导的指引,逐步完成软件的安装过 程。
启动软件
安装完成后,双击桌面上的Stata图标,即可启动软件。
Stata软件的数据导入与整理
数据导入
Stata软件支持多种数据格式,如Excel、CSV、数据库等 ,用户可以通过“文件”菜单中的“导入数据”选项导入 数据。
数据整理
在导入数据后,用户可以使用Stata软件的数据管理功能 ,如数据排序、变量转换、缺失值处理等,对数据进行整 理和清洗。
面板数据回归的模型选择与优化
Stata面板回归操作过程、基本指令及概要
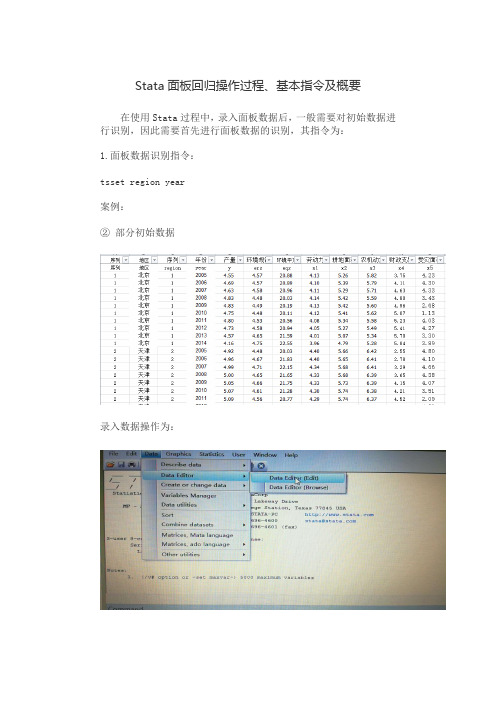
Stata面板回归操作过程、基本指令及概要在使用Stata过程中,录入面板数据后,一般需要对初始数据进行识别,因此需要首先进行面板数据的识别,其指令为:1.面板数据识别指令:tsset region year案例:②部分初始数据录入数据操作为:②将上述初始数据录入stata后(注意:录入数据及首行只能是英文字母或者数字,不能有汉字),显示如下:③输入指令tsset region year,显示如下结果. tsset region yearpanel variable: region (strongly balanced)time variable: year, 2005 to 2014delta: 1 unit2.面板数据固定效应回归指令:xtreg y ers eqs x1 x2 x3 x4 x5,fe案例:录入数据,并进行面板数据识别之后,输入以上指令:xtreg y ers eqs x1 x2 x3 x4 x5,fe其中,xtreg为面板回归指令,y为选取的因变量,ers、eqs、x1、x2、x3、x4、x5为自变量,末尾加fe表示为固定效应,如果末尾加re则是随机效应。
上述回归结果显示如下:3.面板数据随机效应回归指令:xtreg y ers eqs x1 x2 x3 x4 x5,re4.hausman 检验指令:Hausman检验是固定效应或者随机效应回归之后,需要加入的一个检验,具体指令如下:qui xtreg y ers eqs x1 x2 x3 x4 x5,feest store fequi xtreg y ers eqs x1 x2 x3 x4 x5,feest store rehausman fe re5.门限回归指令使用门限(或者门槛)回归模型的,只需要在录入数据后,使用以下指令进行回归即可,xthreg为门限回归指令,y eqs x1 x2 x3 x4 x5分别为自变量和因变量,rx和qx括号中的分别为核心解释变量与门限变量,可以一致也可以不一致。
stata面板数据分组回归的命令

stata面板数据分组回归的命令面板数据分组回归是一种常用的统计分析技术,可以用来研究面板数据中的异质性效应和个体差异。
stata是一款流行的统计软件,提供了一系列命令来进行面板数据分组回归分析。
以下是一些相关参考内容:1. xtreg命令xtreg命令是stata中面板数据分组回归的主要命令之一。
它可以用来估计固定效应模型、随机效应模型和混合效应模型。
命令的基本语法为:xtreg dependent_var independent_vars [if] [in], options其中,dependent_var表示因变量,independent_vars表示自变量,[if] [in]为可选参数,用于指定数据的子集。
options用于指定模型的控制变量和其他设置。
2. xtregar命令xtregar命令是一个用于估计带有异方差的随机效应模型的stata命令。
它可以解决面板数据中存在异方差性的问题,提供了更准确的估计结果。
命令的基本语法为:xtregar dependent_var independent_vars, options其中,dependent_var表示因变量,independent_vars表示自变量,options用于指定模型的控制变量和其他设置。
3. xtsum命令xtsum命令用于对面板数据进行描述性统计分析,提供了关于样本的均值、标准差、最小值、最大值等常见统计量的汇总统计结果。
命令的基本语法为:xtsum varlist其中,varlist表示要进行统计分析的变量。
4. xttest0命令xttest0命令用于检验随机效应模型的固定效应假设,即个体效应对于因变量的解释效果为零。
命令的基本语法为:xttest0 random_effects_model其中,random_effects_model表示要进行检验的随机效应模型。
除了以上主要命令外,stata还提供了许多其他的面板数据分组回归命令,如xtivreg、xtdpd、xtabond等,这些命令可以用于进行更复杂的面板数据分析,考虑到时间序列相关性、内生性等问题。
面板数据回归方法

面板数据回归方法
面板数据回归方法是一种用于分析面板数据(即含有个体和时间的数据)的统计方法,它允许对个体和时间的固定效应进行控制,从而更准确地估计变量之间的关系。
面板数据回归方法主要分为固定效应模型和随机效应模型。
1. 固定效应模型:面板数据回归中最常见的方法之一。
该模型将个体固定效应视为未观测到的个体特定因素,并引入虚拟变量进行控制。
这样一来,个体间差异的因素会在估计中被消除。
2. 随机效应模型:该模型将个体间差异视为随机部分,并假设其与解释变量无相关性。
通过最大似然估计方法,可以估计出个体的随机效应和其他参数。
面板数据回归方法具有以下优点:
1. 弥补了时间序列数据和横截面数据的不足:面板数据既考虑了个体间的异质性,也考虑了时间上的动态变化。
2. 提高了估计的效率:相比横截面数据或时间序列数据,面板数据利用了更多的信息,因此可以获得更准确和有效的估计结果。
3. 控制了固定效应和随机效应:固定效应模型和随机效应模型可以有效地控制个体间的固定效应和随机效应,从而消除了潜在的内生性问题。
总之,面板数据回归方法是一种广泛应用于经济学、社会学和其他社会科学研究中的统计方法,它能够更准确地估计个体间和时间间的关系,并且具有较高的估计效率。
面板数据逐步回归法stata

面板数据逐步回归法stata面板数据逐步回归法Stata 面板数据逐步回归法(Panel data stepwise regression)是Stata的一种数据分析方法,它结合了面板数据和逐步回归法的优点,可以对时间序列面板数据进行多方面的分析,包括探究内部联系以及了解各因素之间的关联性。
下面我们具体介绍一下面板数据逐步回归法的定义、适用范围、基本原理和应用方法。
一、定义面板数据逐步回归法是一种利用逐步回归法实现对面板数据分析的方法。
面板数据又叫纵向数据或追踪数据,主要指同一时间段内对同一个样本进行多次测量。
面板数据逐步回归法,主要是基于纵向数据的统计分析方法,通过逐步回归对面板数据进行分析,探究变量之间的内部联系和因素之间的关联性。
二、适用范围面板数据逐步回归法适用于时间序列分析中的面板数据,特别是适用于跨国企业、宏观经济、产业集中度等领域的分析。
面板数据逐步回归法可以对时间序列面板数据进行多方面的分析,包括探究内部联系以及了解各因素之间的关联性。
三、基本原理面板数据逐步回归法的基本原理是利用逐步回归分析面板数据中的自变量与因变量之间的关系,确定变量中的主导因素以及变量之间的相关性。
逐步回归法是利用最小二乘法进行回归分析,它会根据事先设定的显著水平,每次选取最显著的变量,逐渐建立模型,直到模型中的所有变量都显著。
四、应用方法面板数据逐步回归法在Stata中的实现主要依赖于regress命令,该命令可以对时间序列面板数据进行回归分析,包括面板数据逐步回归法。
以下是具体步骤:1. 搜集面板数据首先需要搜集所需面板数据,建立数据集。
2. 导入面板数据打开Stata,输入import命令,将我们所搜集到的面板数据导入到Stata中。
3. 运行描述性统计命令输入sum命令,运行描述性统计命令,检查数据是否存在缺失值和异常值。
4. 运行面板数据逐步回归分析命令输入regress命令,选择需要分析的自变量和因变量,根据设定的显著水平,选取最显著的变量,逐步建立模型。
5分钟搞定Stata面板数据分析小教程实用

如图: 至此,使用 stata 进行面板数据回归分析完成。
口令: reshape long var, i (样本名 )
例如: reshape long var, i(province) 其中 var 代表的是所有的年份( var2,var3,var4 ) 转化后的格式如图:
转化成功后继续重命名,其中 _j 这 里代表原始表中的年份, var 代表该变量的名 称 口令例如: rename _j year rename var taxi 也可直接在需要修改的名称处双击,在弹出的窗口中修改 如图:
步骤三:排序
口令: sort 变 量名
例如: sort province year 意思为将 province 按升序排列,然后再根据排好的 列 如图:
province 数列排 year 这一
(虽然很多时候在执行 sort 前数据就已经符合要求了,但以防万一请务期数据处理就完成了,请如法炮制的处理所有的变量。在 处理新变量前请使用
5 分钟搞定 Stata 面板数据分析 简易教程
步骤一:导入数据
口令: insheet using 文 件路径
例如: insheet using C:\STUDY\paper\taxi.csv 其中 csv 格式可用 excel 的“另存为 ”导出 数据请以时间( 1999, 2000 ,2001 )为横轴,样本名( 1,2,3 )为 纵轴 请注意:表中不能有中文字符,否则会出现错误。面板数据中不能有空值,没 有数据的位置请以 0 代替。 如图:
也可直接将数据复制粘贴到 stata 的 data editor 中 如图:
步骤二:调整格式
首先请将代表样本的 var1 重命名
口令: rename v ar1 样 本名
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
5分钟速学stata面板数据回归(超实用!)
第一步:编辑数据。
面板数据的回归,比如该回归模型为:Y it=β0+β1X1it+β2X2it+β3X3it+εt,在stata中进行回归,需要先将各个变量的数据逐个编辑好,该模型中共有Y X1 X2 X3三个变量,那么先从Y的数据开始编辑,将变量Y的面板数据编辑到stata软件中,较方便的做法是,将excel的数据直接复制到stata软件的数据编辑框中,而excel中的数据需要如下图编辑:
从数据的第二行开始选中20个样本数据,如图:
直接复制粘贴至stata中的data editor中,如图:
第二步:格式调整。
首先,请将代表样本的var1Y变量数据是选20个省份5年的数据为样本,那么口令为rename var1 province。
例如:本例中的Y变量数据编辑接下来需要输入口令为reshape long var,i(province)
其中,var代表的是所有的年份(var2,var3,var4,var5,var6),转化后格式如图:
转化成功后,继续重命名,其中_j这里代表原始表中的年份,var代表该变量的名称
例如,我们编辑的是Y变量的数据,所以口令3和口令4的输入如下:
口令3:rename _j year
口令4:rename var taxi (注:taxi就是Y变量,我们用taxi表示Y)
命名完,数据编辑框如下图所示。
第三步:排序。
例如,本例中的Y变量(taxi),是20个省份和5年的面板数据,
那么口令4为sort province year
(虽意思是将province按升序排列,然后再根据排好的province数列排year这一列升序排列。
然很多时候在执行sort之前,数据已经符合排序要求了,但为以防万一,请务必执行此操作)
第三步:保存。
按下图中圈红的保存键,保存变量Y(即taxi)的数据。
第四步:重置。
至此,变量Y的数据导入完成。
接下来将stata
此时,数据编辑框空白,接下来就可以输入X1的数据,方法与变量Y的数据输入完全一样。
第五步:合并数据。
把所有变量都导入之后,要进行回归,就需要先将所有变量合并起来。
首先确定stata重置了(即输入口令clear),然后在data editor中打开因变量Y的数据框,接下来要做的就是把X1,X2,X3等自变量逐个合并到Y中。
(文件路径可以往前面保存的找,前面所有的变量在导入数据最后一步保存时,会有该变量保存的文件路径,例如:E:\1.毕业论文\分省数据\stata文件\X1.dta)
合并数据也是一个变量一个变量逐个合并,首先合并X1变量的话,口令为merge 1:1 province year using E:\1.毕业论文\分省数据\stata文件\X1.dta
意思是将X1的数据添加到Y_merge
_merge
province year
这样就把X1合并入Y中,且已排序好,接着对X2,X3等变量如法炮制反复输入,直至自变量输入结束后保存。
接下来就可以进行回归了。
第六步:回归。
,然后可以分别进行固定效应回归和随机效应回归。
例如本例的因变量为Y自变量为X1 X2 X3,则固定效应回归口令:xtreg Y X1 X2 X3,fe
例如本例的因变量为Y自变量为X1 X2 X3,则随机效应回归口令:xtreg Y X1 X2 X3,re
第七步:检验。
至此,stata面板数据回归全部结束。