批量上传解析PDF技术难点分析
百度文档批量上传工具说明书

百度文档批量上传工具说明书一、功能说明1、支持批量添加word、ppt、xls、pdf及txt等常见格式文档2、支持文档大小范围过滤,支持文档价格定义3、支持文档标签自动获取以及修改4、支持文档分类5、支持自动拨号以及备用账户切换功能6、支持无限制账号上传7、支持文档列表导入导出,自动上传等功能二、界面介绍1、主界面2、参数界面三、使用介绍1、快速使用指南1)填写用户名密码,并选择保存,之后点击登录2)获取文档分类,点击获取按钮(如果已经存在分类,此步骤可以忽略)3)添加文档前设置文档价格设置添加文档大小范围点击左侧导航栏的参数设置栏,出现上述参数设置界面。
设置最小和最大文档大小(可直接使用默认值)●选择文档所在文件夹点击选择按钮选择文档所在的文件夹(如果添加文档和选择按钮间的编辑框为空白,可以直接点击添加文档按钮进行文件夹选择)选择文件夹后,中间的编辑框会出现文件夹所在路径可以直接把文档所在的文件夹路径复制到此编辑框中(推荐此方法,因为所选择的文件夹存在大量文档时,点击选择按钮将会花费一段时间来弹出选择框)●把此文件夹文档加入到列表中选择完文件夹后,此时直接点击添加文档按钮(如果添加文档和选择按钮间的编辑框为空白,可以直接点击添加文档按钮进行文件夹选择和添加)如果此文件夹下存在子文件夹,则会询问是否加入子文件夹下的文档,可选择是否添加如果此目录之前已经添加过,则点击添加文档按钮会询问,可选择是否重新添加此目录注:重复添加文档前,要确保下面的文档介绍编辑框为空,否则新添加的文档,文档介绍将会全部设置为编辑框中的文档介绍。
在文档列表中勾中两个或以上项就可以去掉文档标题和文档介绍,勾中一个项后可以让其此两个框变成可编辑状态。
添加文档后列表如图注:添加文档过程可以反复进行,理论支持无数文档添加注:上传时不用在文档前面的框中打勾,当选择,删除,修改文档时才需要打勾。
5)设置上传间隔时间未注册版本此间隔时间无法设置(默认为180秒),注册后可以设置为0或其它数值点击左侧导航栏的参数设置栏,出现上述参数设置界面。
百度文库上传文档常见问题以及疑难问题处理大全技巧全解

百度文库文档上传技巧大全整理人:633002019年1月一、文库文档编辑事项1.首先文档格式要美观一篇格式好的文档,首先要开头空两格,像写作文一样,标点符合规矩,段落分的合理,行距与段落的段落距离恰当。
2.文档内容要时效新颖文档内容要与现在的社会与生活实际比较贴近,时效性要好,切不可写太不合实际,不是很实用的文档。
不然别人不会下载。
3.内容要有自己的思想,可参考别人的文档,但绝不是抄袭,要有自己的见解,自己的感悟,经过自己的精心加工。
文库文档数量已经在2018年12月底超过300000000。
在如此浩瀚的文海里,你所写的东西,别人也能照样写出来大同小异的来,有的用户老说,我的文档为什么自己的原创被私有了,因为你的文档很多都是大众化的语言,官方语言,观点,看法都太套符合一定套路的话,文库在审核文档的时候第一遍是机器审核,自动识别,当你的文档与文库里已经有的文档相似度超过一定的比例,电脑系统就会自动把你的文档私有。
所以必须加入自己的感悟,因为每一个人对于同一件事情的看法各有不同,加入自己的思想,当时的感悟,你的文章就会与别人的有所不同,记得多加入自己的感悟,自己对于这件事的思考,只有这样,重复的可能才会越来越小。
传文档的成功率才会有大大的提升。
4.内容必须是完整的。
从头到尾要前后呼应,如写文章一样,一篇优秀的文档要中心突出,前后首尾呼应。
一篇优质的文档,特别是付费的文档,更需要有完整的内容,精品的内容,别人才会愿意付费去下载。
换句话说,你自己愿意花钱去下一篇没有结尾,内容杂乱,不实用的文档吗?哪怕价格很低,但你也不会去下载吧?所以要想得到高的评分,或者付费的文档要想得到收益比较好的提高,就必须要把自己的文档质量搞好,怎么搞?这就必须花心思去做文档,一篇文档如果花费了很多的时间去思考,去整理,研究,做到文档质量好并不难,想要别人去下载,特别是付费去下载,必须要用心去做每一个篇幅的内容,对得起你的定价,对得起用户付了费下载你的文档,所以我认为,文档内容完整,篇幅合适,实用,站在使用者的角度去思考问题,只有这样才能让用户下载你的文档,觉得值得去下载,也会给你文档一个不错的评价。
数据收集与处理中的难点及解决方法

数据收集与处理中的难点及解决方法随着数字化时代的到来,数据已经成为企业决策和发展所需的重要资源。
然而,数据的获取和处理并不是一项容易的任务。
在数据收集和处理的过程中,有一些难点需要我们去克服。
那么数据收集和处理中的难点是什么,又该怎么去解决呢?本篇文章就来探讨这些问题。
一、数据收集中的难点及解决方法1. 数据来源不确定数据来源的不确定性很大程度上增加了我们的工作难度。
有时数据可能来自外部供应商或第三方,这些数据的质量和真实性就无法直接得到保证。
为了克服这种难点,我们首先需要建立明确的数据来源,同时要考虑到数据质量的问题,包括数据的准确性、完整性和可靠性等问题。
2. 数据源结构复杂不同的数据源可能具有不同的数据结构,这使得数据整合变得非常困难。
因此,我们需要对数据源进行归类和划分,建立相应的数据架构,并使用一些技术手段提高数据整合的效率,例如ETL(抽取,转换和加载)工具。
3. 必要的信息缺失在收集数据的过程中,有些必要的信息可能无法直接获取,例如客户的信用记录等。
为了解决这种情况,我们可以通过外部数据源、社交媒体、用户反馈等途径来获取这些信息。
4. 数据收集速度慢在不同的业务场景下,数据的收集速度不同,而且通常是比较慢的。
对于需要较快速度的情况,我们可以使用实时数据采集技术,通过实时数据集成、流处理等技术来解决这个问题,确保数据的收集速度跟得上业务的需要。
5. 数据规模庞大在数据收集和处理过程中,通常会遇到海量数据的情况。
这时我们需要使用大数据存储和处理技术,例如分布式文件存储、MapReduce等技术,来解决数据规模过大的问题。
二、数据处理中的难点及解决方法1. 数据清洗与去重数据清洗和去重是数据处理过程中最基本的环节,需要消耗数据团队大量时间和人力成本来完成。
在这个环节中,我们需要开发专门的数据清洗和去重工具,自动或半自动地完成数据清洗和去重的工作,尽量避免人为的错误和失误。
2. 数据分析和挖掘数据分析和挖掘是数据处理过程中最核心的环节之一。
pdf结构解析

PDF(Portable Document Format)是一种常见的文档格式,被广泛应用于电子文档的交换和共享。
PDF文件的结构解析可以分为以下几个步骤:
1.确定PDF文件类型:首先需要确定PDF文件的具体类型,例如文本型、图片型、结构化PDF等。
不同类型的PDF文件解析方法有所不同。
2.解析PDF文件的元数据:元数据是PDF文件中的一些重要信息,如文件大小、创建时间、修改时间等。
可以使用一些工具来提取元数据。
3.解析PDF文件的页面结构:页面结构是指PDF文件中的页面布局和排版。
可以使用PDF编辑软件或解析工具来查看和分析PDF文件的页面结
构。
4.解析PDF文件的对象:PDF文件由一系列对象组成,包括文本对象、图像对象、图形对象等。
解析这些对象可以深入了解PDF文件的内部结
构和内容。
5.解析PDF文件的流:在解析完PDF文件的对象后,需要将这些对象按照特定的流组织起来,形成最终的PDF文件。
解析这些流可以了解文件
的结构和组成。
在解析PDF文件时,可以使用一些工具和库来辅助,如Adobe Acrobat、PDFMiner等。
这些工具可以帮助你快速解析和提取PDF文件中的信息,并且可以提供更深入的分析和理解。
PDM操作手册-02-结构公司批量上传、下载使用教程
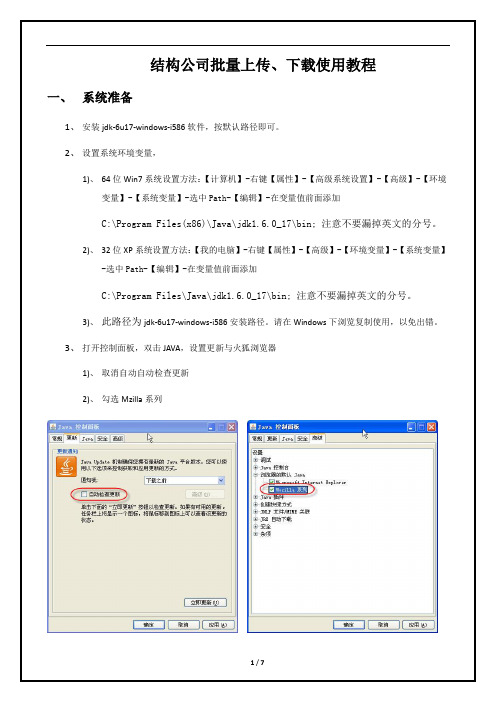
结构公司批量上传、下载使用教程一、系统准备1、安装jdk-6u17-windows-i586软件,按默认路径即可。
2、设置系统环境变量,1)、64位Win7系统设置方法:【计算机】-右键【属性】-【高级系统设置】-【高级】-【环境变量】-【系统变量】-选中Path-【编辑】-在变量值前面添加C:\Program Files(x86)\Java\jdk1.6.0_17\bin; 注意不要漏掉英文的分号。
2)、32位XP系统设置方法:【我的电脑】-右键【属性】-【高级】-【环境变量】-【系统变量】-选中Path-【编辑】-在变量值前面添加C:\Program Files\Java\jdk1.6.0_17\bin; 注意不要漏掉英文的分号。
3)、此路径为jdk-6u17-windows-i586安装路径。
请在Windows下浏览复制使用,以免出错。
3、打开控制面板,双击JAVA,设置更新与火狐浏览器1)、取消自动自动检查更新2)、勾选Mzilla系列二、批量上传1、首先浏览至要上传文档的位置,点击【新建多个文档】2、选择【01_多类型文件】3、上传文档,注意文档必须按照规范命名,以便文档的归类。
如果系统已经存在文档,将会有提示,无法检入系统。
三、批量下载:1、业务场景一:1)、下载BOM(顶层装配)关联的说明文档内容、关联的装配图的签字后的PDF2)、遍历BOM结构,获取每个物料关联的审签图纸,说明文档。
2、业务场景二:在文档下关联的内容根据参考方的方式获取其余文档内容,3、业务场景三:根据搜索内容下载普通文档及装配图签字的PDF4、业务场景四:下载模型及其图纸、同名REP文件。
chatgpt4上传pdf理解

chatgpt4上传pdf理解
ChatGPT-4可以理解并分析PDF文件。
上传PDF文件后,ChatGPT-4会对其进行自动分析,并尝试理解其中的内容。
您可以使用ChatGPT-4的文本输入框输入问题,然后ChatGPT-4会根据PDF文件中的内容回答您的问题。
例如,您可以输入:“请告诉我PDF文件中提到的关于人工智能的发展趋势是什么?”然后ChatGPT-4会根据PDF文件中的内容,回答您关于人工智能发展趋势的问题。
需要注意的是,ChatGPT-4对于PDF文件的理解程度取决于文件的质量和内容。
如果PDF文件包含复杂的技术术语或概念,或者文件质量较差,可能会影响ChatGPT-4对其内容的理解。
因此,在上传PDF文件之前,请确保文件清晰、易于理解,并使用简明扼要的标题和段落结构。
技术难点及解决方案

技术难点及解决方案一、背景介绍在当今科技快速发展的时代,技术难点是各行各业都面临的挑战。
本文将介绍一些常见的技术难点,并提供相应的解决方案。
二、1. 数据安全性随着互联网的普及,数据安全性成为了一个重要的问题。
如何保护用户的个人信息和敏感数据,防止黑客攻击和数据泄露,是许多企业和组织面临的技术难点。
解决方案:- 强化网络安全措施,包括使用防火墙、入侵检测系统和加密技术等,保护数据的机密性和完整性。
- 建立严格的访问控制机制,限制对敏感数据的访问权限,并定期审查和更新权限设置。
- 培训员工,提高他们的安全意识,加强密码管理和防范社会工程学攻击。
2. 大数据处理随着云计算和物联网的兴起,大数据处理成为了一个挑战。
如何高效地处理大量的数据,提取有价值的信息,对许多企业和研究机构来说是一个技术难点。
解决方案:- 使用分布式计算和存储系统,如Hadoop和Spark,以提高数据处理的效率和可扩展性。
- 采用机器学习和人工智能技术,对大数据进行分析和挖掘,发现隐藏在数据中的模式和趋势。
- 使用数据可视化工具,将复杂的数据转化为直观的图表和图形,帮助用户更好地理解和利用数据。
3. 跨平台兼容性随着移动互联网的普及,跨平台兼容性成为了一个重要的问题。
如何在不同的操作系统和设备上保持应用程序的一致性和稳定性,是许多开发者和企业面临的技术难点。
解决方案:- 使用跨平台开发框架,如React Native和Flutter,以实现一次编写,多平台运行的目标。
- 进行严格的测试和调试,确保应用程序在不同的操作系统和设备上都能正常运行。
- 针对不同的平台和设备,进行定制化的界面和功能优化,以提供更好的用户体验。
4. 系统性能优化随着应用程序的复杂性增加,系统性能优化成为了一个关键问题。
如何提高系统的响应速度和稳定性,减少资源的占用,是许多开发者和系统管理员面临的技术难点。
解决方案:- 进行代码优化,消除冗余和低效的操作,提高程序的执行效率。
pdf 表格内容解析

pdf 表格内容解析PDF表格内容解析是一项涉及到计算机视觉和自然语言处理的技术,其目标是从PDF文件中提取表格内容,并将这些内容以结构化的形式呈现,例如以CSV 格式导出。
下面我们将探讨如何解析PDF表格内容。
在解析PDF表格内容之前,需要了解PDF文件的结构和特点。
PDF是一种用于创建和共享文档的文件格式,它支持多种类型的元素,如文本、图像、矢量图形、超链接等。
然而,PDF文件中的表格并不像Word或Excel文件中的表格那样具有固定的单元格和行列结构,而是由文本和排版信息组成。
要解析PDF表格内容,需要使用以下技术和工具:1、PDF文件处理库:如PyPDF2、PDFMiner等,这些库提供了读取和解析PDF 文件的功能。
2、OCR(光学字符识别)技术:由于PDF文件中的表格并没有固定的单元格结构,因此需要使用OCR技术来识别表格中的文本内容。
常用的OCR技术包括Tesseract和ABBYYFineReader等。
3、表格识别算法:基于深度学习的表格识别算法可以自动识别PDF文件中的表格区域,并将这些区域分割成单元格。
常用的算法包括基于卷积神经网络(CNN)和递归神经网络(RNN)的算法。
4、数据清洗和整理:解析出的表格数据需要进行数据清洗和整理,以去除无关信息、填充缺失值、转换数据类型等,以便于进一步的数据分析和处理。
在实现PDF表格内容解析时,需要注意以下几点:1、精度和效率:PDF文件中的表格可能存在多种排版方式和格式,因此需要选择精度和效率较高的算法和技术。
2、数据清洗和整理:由于PDF文件中的表格数据可能存在格式不规范、缺失值等问题,因此需要进行数据清洗和整理,以确保数据的准确性和完整性。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第8卷第4期 江西科技学院学报 V。1.8 N0.4 201 3年12月 JOURNAL OF JIANG XI UNIVERSITY OF TECHNOLOGY December.2013
批量上传解析PDF技术难点分析 肖守柏 (江西科技学院科研处,江西南昌,330098) 摘 要:为使批量上传并解析PDF技术具备较高的扩展性和易用性,本文主张使用Adapt和StrategY等设 计模式降低第三方组件、特征字符等变化点对源程序本身的影响,甚至使用Factory设计模式和Reflect技术将 依赖关系转移至配置文件,使得只需修改配置文件就可应对未来变化。此外.还将异步环境分隔成异步上传和 同步数据库操作两段,通过Request传入值和Session传出值实现异步与同步的通信,从而提高性能。 关键词:设计模式 变化点封装 异步通信 中图分类号:TP3 文献标识码:A 文章编号:123(2013)04—054—02
1引言 目前大部分传统型的网站后台的录入工作大体主要分成 三步:1、下载文稿:编辑员首先登录邮箱下载并打开论文的 PDF文件稿。2、拷贝录入:编辑员将其中的论文标题、作者、地 址、邮箱、摘要、关键字一一拷贝出来手工录入进数据库。3、上 传文稿:将PDF文件稿上传至系统,供作者检索后下载。采用上 传解析PDF方案后,后台录入工作就可免去“拷贝录入”的步 骤,而该步骤既是编辑员工作量最大的部分,亦是容易出错的 部分。该方案的应用效果为:编辑员批量上传PDF文档,系统自 动从PDF文档中解析并提取论文标题、作者、地址、邮箱、摘要、 关键字等信息入库,有效降低后台录入的工作量和错误率。 在明确将编辑部的投稿步骤由“两步走”合并为“一步走” 这一目标后,将相应功能按由难至易划分为先实现论文批量上 传解析、再实现论文多条件检索、最后实现论文单一录入上传 修改删除。
2技术关键 为实现上述目标,必须明确指出相关技术关键,从而进一 步拟定解决方案。 (1)经过权衡,已选出适合的PDF解析算法。但该解析算法 并不能直接用于本系统所要求的信息提取算法,故拟采用 Adapt设计模式根据现有需求拟定通用接口,对现有PDF解析 算法进行适应性修正。这种做法,不仅使现有PDF解析算法更 适合当前需求,而且在未来出现更好的PDF解析算法时能够在
不修改系统核心代码的前提下,快速切换至当最新的PDF解析 文档,降低PDF解析算法与系统本身的耦合程度,适应未来变 化。 三种算法中,Aspose.OCR功能全面,既能从PDF中提取文 字亦能提取图表,但性能稍低,故排除。ItextSharp只能提取文 字,但文字间分隔不明显,故排除。PDFBox一0.7.3虽然只能提取 文字,但文字问分隔明显,且性能较高,故选择该算法。权衡的 理由是在现有需求中还不需要提取图表,为了性能,选择 PDFBox一0.7.3算法。 为使程序与算法本身解耦,拟采用Adapt设计模式封装算 法,如图1所示。
图1 Adapt设计模式 这样,在未来遇到特殊情况时便可轻松切换为其他自定义 的解析算法。 (2)已确定使用字符串的Split、IndexOf方法截取字符串,并 拟定结合策略设计模式、工厂设计模式和反射技术提高智能识 别特征字符的程度和应变程度。先将标题、作者、地址、邮箱、摘 要和关键字前面的特征字符抽象成变化点,再对这些变化点实 施默认设置和特定实现,如图2所示。
收稿日期:2013—07—08 作者简介:肖守柏(1979一),男,江西泰和人,江西科技学院,高级工程师,研究方向:计算机软件技术。 基金项目:2011年度江西科技学院自然科学研究项目(“基于IEEEXplore的PDF批量上传解析方案设计”(编号:XYKJ2011003 o
—-54—- 江西科技学院学报(2013) Pdf ext protected override string getStr(string file) public override Paper BuildPaper0
protected virtual string Trim(string str) protected virtual string TrimEmail(string str) protected virtual string[]zyFilt protected virtual strinl ̄]keyFilt protectedvirtual stringTrimAbsQian(string str) protected virtual string[tSplitAbsQian(string str) protected virtual string getTheKey(string str)
△ l
Pd{2Textl
protected override string TrimAbsQian(string str) 图2策略设计模式 之所以将文章的作者、地址、邮箱等信息抽象成变化点,是 因为任何文档都有这些内容,尽管它们的格式不竟相同。本文 提出的算法只针对IEEE Xplore会议期刊的杂志格式。对于其 他格式,还需专门指定其他算法。但无论算法内容如何变化,算 法对外公开的接口始终不变,故而使用策略设计模式对其接口 进行封装,实现“特定格式映射特定算法”的效果。这种充分考 虑扩展性的设计,使得系统在处理特定格式的文档时能自动根 据格式特征切换至指定的解析算法,有效提高系统自身的通用 性。此外,若使用工厂模式和反射技术将变化点从程序内部转 移至配置文件,将更有助于实现这种自适应切换,因为程序员 只需修改配置文件中的特征字符便能实现算法切换,而不必修 改内部源代码。 (3)因为编辑部每13处理的稿件数量庞大,故而有必要实 现批量上传。而批量上传只能选择异步上传技术。因为同步上
传会使页面出现非常不友好的假死现象。为此,确定使用一款 集Flash、Ajax、JQuery为一身的FileUpload组件实现异步上传, 并确定排除研究异步数据库操作的思路。拟采用特殊方式将原 本融合在一起的异步操作分隔成两段。前半段是适合上传的异 步操作,后半段是适合数据库录入的同步操作。
3技术指标 (1)编辑人员能够一次性批量上传1GB左右的PDF文件, 由计算机将这些PDF文件中的标题、作者、地址、邮箱、摘要和 关键字等信息自动入库供13后检索。 (2)在需求变化要求从PDF文件中提取图片和表格时,能够 在切换算法时符合程序设计中“只增加不修改”的原予陛原则。 (3)能够智能识别标题、作者、地址、邮箱、摘要和关键字前 面的特征字符,即使发生细微变化,也不必重新编写代码,只需 调整配置文件中的配置值即可应对新的变化。
4总结 综上所示,在提取算法方面,通过权衡,已确定使用 PDFBox一0.7.3算法。在智能识别特征字符方面,已确定使用字 符串的Split、IndexOf方法截取字符串,并充分使用Adapt和 Strategy等设计模式降低第三方组件、特征字符等变化点对源程 序本身的影响,甚至使用Factory设计模式和Reflect技术将依 赖关系转移至配置文件,使得只需修改配置文件就可应对未来 变化。在上传方面,已确定使用FileUpload组件实现异步上传, 将异步环境分隔成异步上传和同步数据库操作两段后,通过 Request传人值和Session传出值实现异步与同步的通信。
参考文献: 【1】李贵林,李建中,杨艳.用Plug—in实现对PDF文件的信息提取[J].计算机应用,2003(02). 【2】宋艳娟,李金铭,陈振标.基于XSLT的PDF信息抽取技术的研究[J].计算机与数字工程,2008(5):2. 【3]宋艳娟,张文德.基于XML的PDF文档信息抽取系统的研究[J].现代图书情报技术,2005(9):25. (责任鳊辑:陈辉) Analysis of the Technical Difficnities of Bulk Upload Analytic PDF 0 Shou—bo (Department ofScientific Research,Jiant ̄i University ofTechnology,Nanchang,33009&China) AbBtl翻吐:In order to batch upload and parse the PDF with high salability and usability.the paper advocates the use of the design pattern,such as Adapt and Strategy etc,to reduce the influence of the third-party components and characteristic characters change point tO the so ̄ce program itself,even to use the Factory design pattern and Reflect technology to transfer dependency to configuration files,SO that just to modify the configuration files Can cope with the change in the future.In addition,it divides the upl0ading asynchronous en ̄mnmem into asynchronous and synchronous database operations,and improves the performance by the incoming value of Request and out value of Session. Key WOI ̄;design pattern,change point encapsulation,asynchronous communication
一55—