SPSS数据整理及t检验资料
SPSS数据处理小结:T检验、相关、二分类、散点图、箱图
!!立立。
接下来我们看一一下这一一组数据:NLR和HbA1c的相关性
! 图2-‐4
(ps:SPSS中有11种曲线可以选择,我会简单概述一一下在不用用直线作图
!时,怎样选择曲线)
!例子子:为了研究糖化血血红蛋白白上升时,NLR的上升趋势,试做直线拟合。
1.打开数据库“.sav”文文件
2.分析→回归→曲线估计
!
!图!!!!!!!!!! 3-‐1
首首先r=0.509,说明他们的相关是很密切的,而而p<0.001,说明相关是成立立 的。然后在“.509”右上角角现在是有两个*号,说明是显著相关的,假如说是一一
!!!!!个*号,说明只是p值小小于0.05,相关成立立,但是没有0.000显著。
!
!三. 回归分析(regression)
!(一一).曲线估计(curve estimation)
我们在刚刚的相关性中,做出了NLR和糖化血血红蛋白白是明显相关的,相关系
数是0.509,p是小小于0.001的,但是假如说在一一个图上,它又是怎样表现出
来的呢?所以我们现在就来学习一一下,如何用用曲线方方程描述糖化血血红蛋白白和
NLR的关系。
!!0.001)
假如你的分组有三个或者更多个,那么你就要做单方方向方方差分析(one-‐way ANOVA) 因为过程大大概和t检验类似,我就只简叙述一一下: 1.分析→均数比比较→单向方方差分析 2.把需要比比较均值的变量放到上面面因变量表列中,在下面面“因子子”中添加分组 (PS:可能很多同学在分组上会遇到困难,简单介绍一一下吧,你在需要分组 的那一一列数据的旁边插入入一一列数据,在插入入的新的数据中把所需要分组的数 据分别标上1,2,3……组) 3.然后在选项中选择“描述性”然后点击继续,然后点击主面面板的确定导出数 据。 4.数据的p值读取方方法和独立立样本t检验差不多的
SPSS数据处理小结:T检验、相关、二分类、散点图、箱图
我们首首先来看一一个表格:
!!!
图6
这个表格一一般是流行行病学调研类文文章必备的表格了,上面面分为了“control”组 和“PCOS”组(不用用去管它是什么意思……)和后面面的P value,然后最下面面有 写明,数据除非非有特殊说明,都是用用均值±标准差的形式来表示示的。 需要特殊说明的是,一一般情况下,两组数据有统计学上的差异,就是后面面的 那个P值要小小于0.05~当然我们会看到“<0.01”的情况,那样表示示数据差异非非
在曲线的两侧,得分就高高。然
后我们还要关注的就是参数估
计值了,有一一个常数为1.203
和b1为0.151,而而我们的方方程
!!线性的,即:y=0.151*x +1.203
2.分析→相关→双变量
!
!图!!!!!!!!!!! 2-‐1
3.进入入之后选择要分析的两组数据:IR和年龄,pearson:矩阵相关系数,
参数方方法(属于系统默认方方法),剩下的两个均为非非参数方方法,自自行行补脑使
!! 用用。然后下面面的双侧(尾)检验也是系统默认的。
图!!!!!!!!!!! 2-‐2
!一.均值比较
(一).单样本t检验(one sample t test)
主要用于样本均数和已知总体均数的比较,还可以计算相应的描述性统 计计量及样本数据和总体均数只差的95%的可信区间。(当然你也可以做 75%,99%的可信区间,你也可以自己设置,95%和99%的可信区间比较常 用) 95%的可信区间:如该图1左侧的红色范围,是代表了数据的2.5%到97.5%的 内容。
! 图1-‐8 图1-‐9
的数值,就是均值差值(Mean Difference),首首先均值差值是否在95%的可
SPSS操作—T检验-文档资料

2021/4/21
18
④ 实例分析
以“熊猫数据. sav”为例,可比较男 女游客对于购物接待质量满意度(V12) 是否有显著性差异?
2021/4/21
19
⑤ 操作界面
从候选变量框中选择要进行T检验 的变量移入此框中。
选择分组变量,在选择变量进入 Grouping Variable框后,Define Groups…按钮将被激活 ,单击该 按钮定义分组信息。
① 单样本T检验是处理样本均值与某一指 定的检验值之间是否具有显著差异的 假设检验。加强理论、图表及其应用 的条解件释:力样本度来。自的总体要服从正态分布。
2021/4/21
10
② 在进行单样本T检验时,首先进行假设,
提出原假设H0:假设两样本均值相等;
备择假设H1:假设两样本均值不相等。
③ 单样本T检验适用问题:工厂产品规格的
是否存在显著性差异? 为什么为4?研究的
结果有何用?
2021/4/21
12
⑤ 操作界面
选择要进行T检验的 变量移入此框中,可 同时选择多个变量。
在此框中输入检验 值,即检验与什么 值有无显著性差异。
该对话框用于指 定置信水平和缺 失值的处理方法 。
图1—1—1
2021/4/21
13
⑥ 结果分析
表1—1—1 单样本统计量(这一编号 为何不为2-1?)
2021/4/21
16
2.2 独立两样本T检验 根据上面提示进行修改
① 独立两样本T检验是用于进行两个独立样本均 数的比较。所谓独立样本是指两个样本之间没有 任何关联,即:抽取其中一个样本对抽取另一个 样本没有任何影响,两个独立样本各自接受相同 的测量。样本数可以相等也可以不相等。
SPSS数据的整理与分析
数据的整理与分析chy一、数据收集-问卷星1、检查与剔除不合格问卷,比如答题时间太短、年龄不符合、问卷填写不完整等。
2、应答率/回收率:是指定的或者抽中的需要作答的对象中,最终完成作答的百分比。
3、合格率:合格数量/作答数量。
4、一般的,访问问卷的回收率最高,回收率一般要求在90%以上;邮寄问卷的回收率低,回收率在50%左右就可以了;发送式自填问卷的回收率一般,回收率要求在67%以上。
5、如果不高尽量不要写入,反而起反作用。
6、可以运用问卷星中的图与表描述,直观描述。
二、数据整理-Excel1、结果导出方式:文本、数字、分数,保存excel原版。
2、再另存一版你用于SPSS分析的表格。
3、注意反向计分的题目。
4、如果量表分为几个维度,可以单独列出来进行分析。
(如我发到群里的表格,可以用总分与其他条目分析,也可以用这个量表包括的几个维度分别与其他条目分析,观察其关联)。
5、如果分不清楚,可以标注一下变量的类型,如分类变量还是数据变量(如我的Excel的第二行,但是导入到SPSS中时需要删除)。
三、数据录入-SPSSSPSS中“变量视图”输入各变量如下:1、“类型”尽量都转换为“数字”;(选中右边的…)(点击“数字”即可)3、“值”的标记:(用于计数资料的标记,在结果中易于观察)点击…,分别输入对应的值和代表的标签,点击“添加”和确定即可4、“测量”分为三类:(1)标度:指计数资料,如年龄、108总分等;(2)有序:指等级资料,如年级等;(3)名义:指计数资料,如性别、性格等。
5、如何把计数资料转换为计量资料,即赋值(以“拖延总分为例”)步骤:(注意填写名称和标签,点击“变化量”) ----点击“旧值和新值”进行赋值:0-20赋值为1:--添加--20.1-40赋值为2:--添加--40.1-60赋值为3:--添加--然后“变量视图”最后一行就会出现新的变量“拖延分数三分类”,可以把“名义”改为“有序”,也可不改。
spss数据整理及t检验
2019/1/30
研究生SPSS上机实习
16
练习:将数据文件a.sav和b.sav合并为 c.sav。
a
c
2019/1/30
b
研究生SPSS上机实习
17
• 打开数据文件a.sav,作为工作文件 (Working Data File )。 • 从菜单选择:DataMerge files Add Cases。选定数据文件b.sav为外部文件, 单击“打开” ,单击“OK” ,将合并后 的新工作文件(New Working Data File) 另存为数据文件c.sav。
2019/1/30
研究生SPSS上机实习
22
2019/1/30
研究生SPSS上机实习
23
• 单 击 “ 打 开 ” ; 单 击 Match cases on key variables in sorted files(在已排序 的数据文件中匹配关键变量值相等的观察 单位 ) ,激活它下面的三个选项,本例选 择Both files provide cases,将“病人 编 号 ” 选 入 Key Variables 栏 ; 单 击 “ OK” ,将合并后的新工作文件另存为 数据文件e.sav。
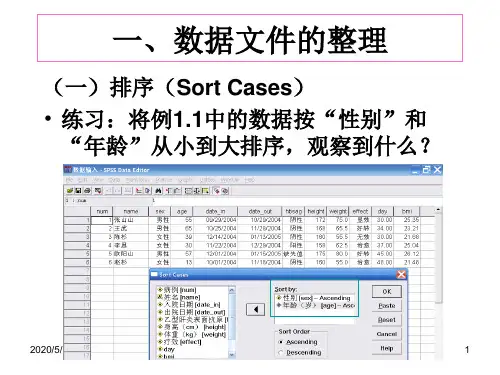
一、数据文件的整理
(一)排序(Sort Cases) • 练习:将例1.1中的数据按“性别”和 “年龄”从小到大排序,观察到什么?
2019/1/30
研究生SPSS上机实习
1
• 方法:从菜单选择Data Sort Cases,打开Sort Cases对话框,将变量“性别”和“年龄”分别选 入Sort by 栏,默认升序排列(Ascending),单击 OK按钮。
2019/1/30
研究生SPSS上机实习
SPSS-t检验

数据输入
1)启动SPSS,进入定义变量工作表,分别命名 两变量:组别、鱼产量。其中组别1表示A料,组 别2表示B料。
2)进入数据视图工作表,输入数据
统计பைடு நூலகம்析
Analyze---compare mean----indendent samples T test
Test variable(输入):产鱼量
2、选择检验方法和计算检验统计量 因为总体标准差σ未知,所以采用t检验。 Analyze →Compare Means→One-Sample T Test出现如下对话框:
•把x移入到Test Variable(s) 的变量列表; •在Test Value后输入需要 比较的总体均数20; •OK
3、根据检验统计量的结果做出统计推断 基本统计量信息:
T检验
(一)单个总体均数的t检验 (二)独立样本成组t检验 (三)成对样本t检验
(一)单个总体均数的t检验
计算公式
样本平均数与总体平均数差异显著性检验
例:成虾的平均体重为21克,在配合饲料中添加 0.5%的酵母培养物饲养成虾时,随机抽取16只对 虾,体重为20.1、21.6、22.2、23.1、20.7、19.9、 21.3、21.4、22.6、22.3、20.9、21.7、22.8、 21.7、21.3、20.7。试检验添加添加0.5%的酵母 培养物是否提高了成虾体重。
从结果中可以看出,统计量t=3.056,P=0.012<α=0.05,因此拒 绝H0,接收H1,即用该方法测量所得结果与标准浓度值有所不 同。认为该方法测量结果所对应总体均数μ与标准浓度μ0间的差 异有统计学意义。
(二)独立样本成组t检验
独立样本:又称非配对样本或成组样本。是指一组数据与另一 组数据没有任何关系,也就是说,两样本资料是相互独立的。 两组的样本容量尽可能相同,可以提高检验的精确度。其均 数差异显著性的t检验,又分为两总体方差相等(方差齐性)和 方差不等两种检验方法。
用SPSS进行T检验解析
对变量框内,单击
,输出表3-11、3-12和表3-13
所示结果。
图3-8 配对样本T检验对话框
表3-11 两种处理方法结果基本统计量 表3-12两种处理方法结果的相关关系 表3-13 两种处理方法的t 检验结果
3.结果说明(参照例3.3的结果说明)
表3-10 仔猪饲料对比试验 单位:kg
◆ 具体步骤: 1.数据输入 (1)在这数据编辑窗口底部的变量视图标签,进入变量视 图界面,分别命名变量:甲饲料和乙饲料,小数位数都 定义为1,如图3-9a所示。
图3-9a 例3.3资料的变量命名
(2)在这数据编辑窗口底部的 数据视图标签,进入数据 视图界面,按图3-9b格式输入 数据资料。
图3-3 例3.2资料的变量命名
(2)在这数据编辑窗口底部的数 据视图标签,进入数据视图 界面,按图3-3格式输入数据 资料。
组别取值1表示A料, 取值2表示B料。
图3-4 例3.2数据输入格式
2. 统计分析 (1)简明分析步骤
分析→比较均值→独立样本T检验
检验变量:产鱼量
分析的变量为产鱼量
分组变量:组别
二、本节重点、难点: 1. SPSS中进行T检验分析的基本命令与操作; 2. SPSS进行T检验分析所得结果的含义。
一、单样本t检验
(一)基本原理和方法(略)
(二)例题及统计分析
【例3.1】成虾的平均体重一般为21g,在配合饲料中添加 了0.5%的酵母培养物养成虾时,随机抽取16对成虾,体 重为20.1、21.6、22.2、23.1、20.7、19.9、21.3、 21.4、22.6、22.3、20.9、21.7、22.8、21.7、21.3、 20.7,试检验在添加了0.5%的酵母培养物养对成虾体重 是否有影响。
SPSS问卷分析之样本T检验
SPSS问卷分析篇之单样本T检验
【引入】T检验在问卷分析中经常用到,尤其是通过李克特五级量表收集到的调查数据。
比如:非常同意5、基本同意4、不能确定3、不太同意2、非常不同意1,收集到的数据都是1-5的离散值,还有诸如非常满意、比较满意、不满意等等。
很容易发现一个问题,那就是五级量表中间值是3,如果我们的汇总结果能够显著与3不同,那我们的调查基本上是由意义的。
也就是说,我们要判断一组数据是否显著不同于3,这个时候,就要用的单样本T检验。
【源数据】假设我们已经通过李克特五级量表收集并整理好一份调查数据,包括个性服务、服务态度、促销活动、服务流程、总体满意度5个维度。
量表为:非常同意5、基本同意4、不能确定3、不太同意2、非常不同意1。
现在需要做的是对这5个维度进行评价。
【分析过程】提前求出每份问卷5个维度的均值,再进行SPSS单样本T检验。
第一:在SPSS中选择T检验,需要检验的常数为3。
第二:结果1
原假设各维度均值与3没有差异,现在p值小于0.01,小概率事件不发生,所以,各维度均值与3有显著不同。
可是各维度均值大于3还是小于3呢?当然希望是大于3!
结果2
看到均值那一列数值了吗?各维度均值都明显大于3,这下放心了吧。
说明个性服务、服务态度、促销活动、服务流程还都是可以接受的,较认同,总体满意度4.4,说明我们的各方面的服务已经深得民心,不过,仍需做到最好。
SPSS:数据分析3、T检验(TTest)方差分析(ANOVA)(Chi-squareTe。。。
SPSS:数据分析3、T检验(TTest)⽅差分析(ANOVA)(Chi-squareTe。
⽬录1、数据采集2、数据是否服从正态分布3、T检验(T Test)4、⽅差分析(ANOVA)5、卡⽅检验(Chi-square Test)6、灰⾊关联度分析(Grey Relation Analysis,GRA)7、弗⾥德曼检验(Friedman Test)8、箱图(Box)1、数据采集1、数据分类定性观察、访谈、调查定量⼿动测量、⾃动测量、问卷打分主观等级、排序、感觉、有⽤性客观时间、数量、错误率、分数⾃变量不同的实验条件因素,研究的因素因变量不同的实验条件所影响的、要观测的因素连续数量值(preference)时间、数量、错误率------离散数量值(usability问卷打分等级数量值(usability)等级、排序变量类型Norminal Data 定类变量 | 变量的不同取值仅仅代表了不同类的事物,这样的变量叫定类变量。
问卷的⼈⼝特征中最常使⽤的问题,⽽调查被访对象的“性别”,就是定类变量。
对于定类变量,加减乘除等运算是没有实际意义的。
Ordinal Data 定序变量 | 变量的值不仅能够代表事物的分类,还能代表事物按某种特性的排序,这样的变量叫定序变量。
问卷的⼈⼝特征中最常使⽤的问题“教育程度“,以及态度量表题⽬等都是定序变量,定序变量的值之间可以⽐较⼤⼩,或者有强弱顺序,但两个值的差⼀般没有什么实际意义。
Interval Data 定距变量 | 变量的值之间可以⽐较⼤⼩,两个值的差有实际意义,这样的变量叫定距变量。
有时问卷在调查被访者的“年龄”和“每⽉平均收⼊”,都是定距变量。
Ratio Data 定⽐变量 | 有绝对0点,如质量,⾼度。
定⽐变量与定距变量在市场调查中⼀般不加以区分,它们的差别在于,定距变量取值为“0”时,不表⽰“没有”,仅仅是取值为0。
定⽐变量取值为“0”时,则表⽰“没有”。
SPSS应用:t检验及方差齐性检验、正态性检验
一、 统计描述:
Analyze → descriptive statistics → descriptives → variables: 分析变量→ok 例2-1:
descriptive statistics: frequencies(频数分布分析) Descriptives (描述性统计分析) Explore(探索性分析) Crosstabs (列联表资料分析) …
→paried variables:配对的两个变量 →ok 例3-6:
四.t检验: 两样本均数的比较 analyze→compare means →independent-samples t test
→test variable:分析变量 →grouping variable:分组变量
→define groups:分组变量的值 →ok Nhomakorabea例3-7:
二.t检验: 样本均数与总体均数的比较 analyze→compare means →one-sample t test
→test variable:分析变量 →test value:总体均数的值 →ok 例3-5:
三.t检验: 配对t检验 analyze→compare means →paried-samples t test
五.正态性检验和方差齐性检验:
Analyze → descriptive statisti正c态s性→检验Explore(探索性 分析)
→ dependent list:分析变量
factor:分组变量
plots:normality test
未转换数据(的方差齐性检验)
untransformed →continue
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
2018/10/21
25
SPSS之统计描述
Frequencies、Descriptives、
Means和Case Summaries程序
2018/10/21
研究生SPSS上机实习
26
• Frequencies、Descriptives、Means和 Case Summaries这4个命令都可以计算均 数、标准差、标准误等主要指标。 • 如果只计算上述3个主要指标,选用 Descriptives命令较为方便; • 如果需计算中位数、百分位数和绘制频数分 布图,应选用Frequencies命令; • 如果需分组计算均数、中位数、几何均数、 标准差、标准误等指标,应选用Means命令 (必须有分组变量); • 如果计算几何均数,选用Case Summaries 命令较为方便。
2018/10/21
研究生SPSS上机实习
3
(二)选择观察单位(Select Cases)
• 练习:将已建数据文件中“男性”及 “年龄”在 65 岁以下的观察单位选择出 来。观察到什么?
2018/10/21
研究生SPSS上机实习
4
• 方法:从菜单选择Data Select Cases, 打开Select对话框,选择if condition is satisfied,单击 if 按钮,在条件栏中输入 sex = 1 & age < 65 ,单击Continue按钮, 单击OK按钮。
32
2.5 25 50 75 97.5
研究生SPSS上机实习
2018/10/21
身高值
20
10
Frequency
Std. Dev = 5.80 Mean = 110.1 0 96.0 100.0 98.0 104.0 108.0 112.0 116.0 120.0 124.0 102.0 106.0 110.0 114.0 118.0 122.0 N = 120.00
2018/10/21
研究生SPSS上机实习
34
2018/10/21
研究生SPSS上机实习
35
结果解释
Descriptive Statistics N 身 高值 Valid N (listwise) 120 120 Minimum 95.30 Maximum 124.00 Mean 110.1100 Std. Deviation 5.8032
2018/10/21
研究生SPSS上机实习
10
• 从菜单选择TransformCompute,打开 Compute Variable对话框;在Target Variable栏 输入 day,在Function Group 栏中选择Data Extraction,在Functions and special variables 中选择Xdata.Tady,再点箭头使之进入Numeric Expression 栏,从左边变量栏内选择(data_outdata_in),进入Numeric Expression 栏,运行结 果产生新变量day。
• 从 菜 单 选 择 AnalyzeDescriptive Statistics Frequencies,打开Frequencies对话框,将变量身 高选入Variables栏。 • 单击Statistics按钮,打开Statistics对话框,选择:
2018/10/21
研究生SPSS上机实习
2018/10/21
研究生SPSS上机实习
5
• 条件符号的含义 &: and; | : or ; ~= : not。 数字和符号可从对话框中直接选择。如果从 键盘选入,应处于英文输入状态,以减少出 错的可能。
2018/10/21 研究生SPSS上机实习 6
单击右键“&”,含义“And”
2018/10/21
2018/10/21
研究生SPSS上机实习
17
练习:将数据文件a.sav和b.sav合并为 c.sav。
a
c
2018/10/21
b
研究生SPSS上机实习
18
• 打开数据文件a.sav,作为工作文件 (Working Data File )。 • 从菜单选择:DataMerge files Add Cases。选定数据文件b.sav为外部文件, 单击“打开” ,单击“OK” ,将合并后 的新工作文件(New Working Data File) 另存为数据文件c.sav。
身高值
图3.3 某地5岁女孩的身高频数分布图
2018/10/21 研究生SPSS上机实习 33
二、Descriptive
• 计算身高的最小值、最大值、均数和标准差。 • 从菜单选择AnalyzeDescriptive Statistics Descriptives,打开Descriptives对话框,将变量 身高选入Variables栏; • 单击Options按钮,打开Options对话框(打钩的是 默认项目) • 单击Continue按钮返回,单击OK按钮。
2018/10/21 研究生SPSS上机实习 27
一 、Frequencies
例:P7根据120名5岁女孩身高资料 (1)计算均数、标准差、标准误 (2)计算中位数、四分位数、P2.5 和P97.5 和P95 (3)绘制频数分布图 (4)计算参考值范围
2018/10/21
研究生SPSS上机实习
28
2018/10/21
研究生SPSS上机实习
23
2018/10/21
研究生SPSS上机实习
24
• 单 击 “ 打 开 ” ; 单 击 Match cases on key variables in sorted files(在已排序 的数据文件中匹配关键变量值相等的观察 单位 ) ,激活它下面的三个选项,本例选 择Both files provide cases,将“病人 编 号 ” 选 入 Key Variables 栏 ; 单 击 “ OK” ,将合并后的新工作文件另存为 数据文件e.sav。
(二)对变量值重新划分 (Recode)
• 练习 将图2-9数据文件中的体重指数bmi 变量值重新编码:0:<24;1:≥24; 并赋值给新变量“肥胖”。
2018/10/21
研究生SPSS上机实习
13
• 从菜单选择Transform RecodeInto Different Variables,打开Recode into Different Variables 对话框,将“bmi”选 入Numeric Variable栏,在Output Variable栏输入新变量肥胖 ,单击 Change 按钮,单击Old and New Values 按钮。
2018/10/21
研究生SPSS上机实习
19
2018/10/21
研究生SPSS上机实习
20
(二)增加变量(Add Variables)
• 从外部数据文件中增加变量(variable) 到当前数据文件中,称为横向合并。横向 合并不仅要求两个需要合并的数据文件必 须有一个共同的变量,如病人编号(变量 名和数据类型都相同),称为关键变量, 还要求两个文件中关键变量的部分变量值 是相等的,如病人编号是相同的。
• 最小值和最大值分别为95.3和124.0厘米, 均数和标准差分别为110.11和5.803厘米。
研究生SPSS上机实习
2018/10/21
36
三、频数表资料与Weight(加权)
• 例:某种传染病的潜伏期(天)如下。求平 均潜伏期M和潜伏期的第95百分位数P95
表 3.4 某种传染病的潜伏期(天)
2018/10/21
研究生SPSS上机实习
11
• 练习2:根据已建数据文件中的“身高”和 “体重”,计算体重指数,然后赋值给新 变量“ bmi” 。体重指数的计算公式如下 (注意公式中身高的单位为m): 体重指数(BMI)=体重(kg) / 身高(m)2
2018/10/21
研究生SPSS上机实习
12
2018/10/21
研究生SPSS上机实习
14
2018/10/21
研究生SPSS上机实习
15
四、数据文件的合并
(一)增加观察单位(Add Cases) (二)增加变量(Add Variables)
2018/10/21
研究生SPSS上机实习
16
(一)增加观察单位(Add Cases)
• 从外部数据文件中增加案例(cases)到当 前数据文件中,称为纵向合并。纵向合并 要求两个需要合并的数据文件必须有一个 共同的变量,如病人编号、住院天数(变 量名和数据类型都相同),称为关键变量。
研究生SPSS上机实习
7
2018/10/21
研究 用赋值方法生成新变量(Compute) • 对变量值重新划分(Recode)
2018/10/21
研究生SPSS上机实习
9
(一)用赋值方法生成新变量 (Compute)
• 练习1 根据已建数据库中的入院日期 date_in和出院日期 date_out,计算住院天 数,并生成新变量住院天数day
SPSS数据文件的整理、转换、 合并及t检验
三峡大学医学院 邓 青
2018/10/21
研究生SPSS上机实习
1
一、数据文件的整理
(一)排序(Sort Cases) • 练习:将例1.1中的数据按“性别”和 “年龄”从小到大排序,观察到什么?
2018/10/21
研究生SPSS上机实习
2
• 方法:从菜单选择Data Sort Cases,打开Sort Cases对话框,将变量“性别”和“年龄”分别选 入Sort by 栏,默认升序排列(Ascending),单击 OK按钮。