栈的类型定义与基本操作
(完整版)《栈》知识点总结

完整版)《栈》知识点总结1.栈的定义与特点栈是一种具有特定限制的数据结构,遵循“后进先出”(Last-In-First-Out,简称LIFO)的原则。
栈的特点包括:只允许在栈顶进行插入和删除操作;对栈进行插入操作称为入栈或压栈(Push);对栈进行删除操作称为出栈或弹栈(Pop);栈底是栈的最后一个入栈的元素,栈顶是栈的第一个入栈的元素;2.栈的应用领域栈在计算机科学和软件工程中有广泛的应用,常见的应用领域包括:编程语言的解析和编译;递归算法的实现;表达式求值;括号匹配;浏览器的后退和前进功能;操作系统中的函数调用栈等。
3.栈的基本操作栈的基本操作主要包括以下几个方面:初始化栈:创建一个空的栈对象,并指定栈的初始容量;判断栈是否为空:检查栈是否为空,如果栈为空则返回真,否则返回假;入栈操作:将一个元素压入栈顶;出栈操作:从栈顶弹出一个元素,并返回弹出的元素;取栈顶元素:返回栈顶的元素,但不对栈进行修改;___:删除栈中的所有元素。
4.栈的实现方式栈可以通过数组或链表来实现。
使用数组实现的栈称为顺序栈,使用链表实现的栈称为链式栈。
顺序栈通过数组的下标实现栈的操作,其特点是插入和删除操作的时间复杂度为O(1),但需要预先分配一定的内存空间。
链式栈使用链表来存储栈中的数据,插入和删除操作的时间复杂度同样为O(1),不需要预先分配固定大小的空间,但需要额外的空间存储链表节点。
5.栈的复杂度分析栈的复杂度分析主要涉及到栈的各种操作的时间复杂度和空间复杂度。
以下是一些常见操作的复杂度分析:入栈操作的时间复杂度为O(1),空间复杂度为O(1);出栈操作的时间复杂度为O(1),空间复杂度为O(1);取栈顶元素操作的时间复杂度为O(1),空间复杂度为O(1);判断栈是否为空的操作的时间复杂度为O(1),空间复杂度为O(1);清空栈的操作的时间复杂度为O(1),空间复杂度为O(1);初始化栈的操作的时间复杂度为O(1),空间复杂度为O(1);6.总结栈作为一种重要的数据结构,在计算机科学和软件工程中有着广泛的应用。
数据结构-栈与队列

栈 1.6栈的应用
运算符的优先级关系表在运算过程中非常重要,它是判定进栈、出栈的重要依据。
θ1
θ2
+
-
+
>
>
-
>
>
*
>
>
/
>
>
(
<
<
)
>
>
#
<
<
*
/
(
)
#
<
<
<
>
>
<
<
<
>
>
>
>
<
>
>
>
>
<
>
>
<
<
<
=
>
>
>
>
<
<
<
=
栈
1.6栈的应用
下面以分析表达式 4+2*3-12/(7-5)为例来说明求解过程,从而总结出表达式求值的算 法。求解中设置两个栈:操作数栈和运算符栈。从左至右扫描表达式:# 4+2*3-12/(7-5) #, 最左边是开始符,最右边是结束符。表达式求值的过程如下表所示:
1.4栈的顺序存储结构
设计进栈算法——Push 函数。首先,判断栈是否已满,如果栈已满,就运用 realloc 函 数重新开辟更大的栈空间。如果 realloc 函数返回值为空,提示溢出,则更新栈的地址以及栈 的当前空间大小。最终,新元素入栈,栈顶标识 top 加 1。
栈的概念理解

栈的概念理解栈是一种数据结构,它是一种特殊的线性表,只能在表的一端进行插入和删除操作,该一端被称为栈顶,另一端被称为栈底。
栈的特点是后进先出(Last In First Out, LIFO)。
在栈中,最后插入的元素最先弹出,而最先插入的元素最后弹出。
这就好像是一堆盘子,你只能在最上面放盘子和拿盘子,不能随意放在下面的盘子上。
栈的这种特性使得它非常适合解决一些具有“倒序”需求的问题。
栈的基本操作包括入栈和出栈。
入栈(Push)是指将元素放入栈顶;出栈(Pop)是指从栈顶弹出元素。
除此之外,还有一些常用的操作,比如获取栈顶元素(Top)、判断栈是否为空(Empty)、获取栈中元素的个数(Size)等。
栈的实现可以用数组或链表来完成。
使用数组实现的栈叫作顺序栈,使用链表实现的栈叫作链式栈。
对于顺序栈,我们需要定义一个数组和一个整数来表示栈。
数组用于存储栈中的元素,整数用于记录栈顶元素的下标。
一开始,栈为空,栈顶下标可以初始化为-1。
插入元素时,需要判断栈是否已满,如果已满则无法插入;如果未满,将元素放入栈顶,同时栈顶下标加1。
删除元素时,需要判断栈是否为空,如果为空则无法删除;如果不为空,将栈顶元素弹出,并将栈顶下标减1。
对于链式栈,我们需要定义一个结构体来表示栈中的节点。
节点包括一个数据域和一个指向下一个节点的指针域。
和顺序栈类似,链式栈也需要一个指针来表示栈顶元素。
插入元素时,需要创建一个新节点,并将栈顶指针指向该节点,新节点的指针域指向原来的栈顶元素。
删除元素时,需要判断栈是否为空,如果为空则无法删除;如果不为空,将栈顶节点删除,并将栈顶指针指向下一个节点。
栈的应用非常广泛。
在计算机科学中,栈是一种重要的数据结构,它被用于实现函数调用、表达式求值、编译器的语法分析、操作系统的进程管理等。
在编程中,我们可以使用栈来解决一些具有“倒序”性质的问题,比如字符串反转、括号匹配、计算逆波兰表达式等。
此外,栈还被用于图的深度优先搜索(DFS)算法中的节点遍历顺序。
栈的操作(实验报告)

引言:栈是一种常见的数据结构,它具有特殊的操作规则,即先进后出(LIFO)。
本文将介绍栈的操作,并结合实验报告的方式详细阐述栈的概念、基本操作以及应用场景。
概述:栈是一种线性数据结构,由相同类型的元素按照特定顺序排列而成。
在栈中,只能在栈顶进行插入和删除操作,其他位置的元素无法直接访问。
栈具有两个基本操作:压栈(push)和弹栈(pop)。
其中,压栈将一个元素添加到栈顶,弹栈则是删除栈顶的元素。
除了基本操作外,栈还具有其他常见的操作,如获取栈顶元素(top)、判断栈是否为空(empty)等。
正文内容:一、栈的基本操作1.压栈(push)push操作的实现原理和步骤在实际应用中的使用场景和例子2.弹栈(pop)pop操作的实现原理和步骤在实际应用中的使用场景和例子3.获取栈顶元素(top)top操作的实现原理和步骤在实际应用中的使用场景和例子4.判断栈是否为空(empty)empty操作的实现原理和步骤在实际应用中的使用场景和例子5.栈的大小(size)size操作的实现原理和步骤在实际应用中的使用场景和例子二、栈的应用场景1.括号匹配使用栈实现括号匹配的原理和过程在编译器、计算表达式等领域中的应用2.浏览器的后退和前进功能使用栈来记录浏览器访问历史的原理和过程实现浏览器的后退和前进功能3.函数调用和递归使用栈来实现函数调用和递归的原理和过程在程序执行过程中的应用和注意事项4.实现浏览器缓存使用栈来实现浏览器缓存的原理和过程提高用户浏览速度的实际应用案例5.撤销操作使用栈来实现撤销操作的原理和过程在编辑器、图形处理软件等领域的实际应用总结:本文详细介绍了栈的操作,包括基本操作(压栈、弹栈、获取栈顶元素、判断栈是否为空、栈的大小)和应用场景(括号匹配、浏览器的后退和前进功能、函数调用和递归、实现浏览器缓存、撤销操作)。
通过了解栈的操作和应用,我们可以更好地理解数据结构中的栈,并能够在实际问题中灵活运用栈的特性。
c语言栈的名词解释

c语言栈的名词解释在计算机科学和编程中,栈(Stack)是一种重要的数据结构。
C语言作为一种广泛应用的编程语言,自然也涉及到栈的概念和使用。
在本文中,将对C语言栈进行详细的名词解释和功能介绍。
1. 栈的定义和特点栈是一种线性的数据结构,它的特点是后进先出(Last In First Out, LIFO)。
也就是说,最后一个进入栈的元素将是第一个被访问、被移除的。
栈采用两个基本操作,即压栈(Push)和弹栈(Pop),用于对数据的插入和删除。
2. 栈的结构和实现方式在C语言中,栈可以用数组或链表来实现。
使用数组实现的栈叫作顺序栈,使用链表实现的栈叫作链式栈。
顺序栈使用数组来存储数据,通过一个指针(栈顶指针)来指示栈顶元素的位置。
当有新元素要进栈时,栈顶指针先向上移动一位,然后将新元素存入该位置。
当要弹栈时,栈顶指针下移一位,表示将栈顶元素移除。
链式栈通过链表来存储数据,每个节点包含一个数据项和一个指向下一个节点的指针。
链式栈通过头指针指示栈顶节点的位置,新元素插入时构造一个新节点,并将其指针指向原栈顶节点,然后更新头指针。
弹栈时,只需将头指针指向下一个节点即可。
3. 栈的应用场景栈在计算机科学中有广泛的应用。
以下是一些常见的应用场景:a. 函数调用:在函数调用过程中,函数的参数、局部变量和返回地址等信息会以栈的形式压入内存中,而在函数返回时将逆序地从栈中弹出这些信息。
b. 表达式求值:中缀表达式在计算机中不方便直接求值,而将中缀表达式转换为后缀表达式后,利用栈可以方便地完成求值过程。
c. 内存分配:在程序运行时,栈用于管理变量和函数的内存分配。
当变量定义时,栈会为其分配内存空间,并在其作用域结束时将其回收。
d. 括号匹配:在处理一些语法相关的问题时,栈可以很好地用来检测括号的匹配情况,例如括号是否成对出现、嵌套层次是否正确等。
4. 栈的复杂度分析栈的操作主要包括入栈和出栈两种操作,它们的时间复杂度均为O(1)。
C语言数据结构_第04讲 栈

while(n); printf("转换后的二进制数值为:"); while(s.top) // 余数出栈处理 { printf("%d",s.top->data); // 输出栈顶的余数 stacknode* p=s.top; // 修改栈顶指针 s.top=s.top->next; delete p; // 回收一个结点,C语言中用free p } }
3-3-2 表达式求值
表达式是由运算对象、运算符、括号等组成的有意义的式子。 1.中缀表达式(Infix Notation) 一般我们所用表达式是将运算符号放在两运算对象的中 间,比如:a+b,c/d等等,我们把这样的式子称为中缀表达 式。 2.后缀表达式(Postfix Notation) 后缀表达式规定把运算符放在两个运算对象(操作数) 的后面。在后缀表达式中,不存在运算符的优先级问题,也 不存在任何括号,计算的顺序完全按照运算符出现的先后次 次序进行。 3.中缀表达式转换为后缀表达式 其转换方法采用运算符优先算法。转换过程需要两个栈: 一个运算符号栈和一个后缀表达式输出符号栈。
(4)读栈顶元素
datatype ReadTop(SeqStack *s) { if (SEmpty ( s ) ) return 0; // 若栈空,则返回0 else return (s->data[s->top] );
// 否则,读栈顶元素,但指针未移动
}
(5)判栈空
int SEmpty(SeqStack *s) { if (s->top= = –1) return 1; else return 0; }
2.顺序栈运算的基本算法 (1)置空栈 首先建立栈空间,然后初始化栈顶指针。 SeqStack *Snull() { SeqStack *s; s=new (SeqStack);
栈的定义
{
SNODE *p; int x; if( top = = NULL ) { cout<<“栈溢出\n”;x=-1; } else { p = top; top = top-> link ; x = p-> data ; free(p) ; } return x }
(1) 队头指针 front = (front+1)% MAXSIZE ;
(2)队尾指针 rear = (rear +1)% MAXSIZE ;
循环队列队空、队满条件
1 2 3
队空条件 front = rear
0
MAXSIZE-1
front
...rΒιβλιοθήκη ar1 2a2 a3
3
0
a1
...
队满条件(剩下一个位置) front=(rear+1)% MAXSIZE
栈操作举例
TOP
a1 a2 …… 栈底 1.
top=0
(空栈)
an
MAXSIZE
栈顶
2. A B C
top=3 (A、B、C进栈)
3.
A B
top=2 (C出栈)
4. A B C D E F
top=MAXSIZE (栈满)
进出栈序列
有三个元素的进栈序列是1,2,3。写出可能的出 栈序列。
出栈序列
a3
a2 a1 ^ 栈底
算法1-8 进栈操作程序
push(SNODE *top , int x) { SNODE *t; t=new SNODE; if(t = = NULL ) { cout<<“内存中已无可用空间\n”; } else { t -> data = x; t -> link = top; top= t; } }
第3章栈和队列

3.1.2 栈的表示和算法实现
1.顺序栈 2.链栈
第3章栈和队列
1. 顺序栈 顺序栈是用顺序存储结构实现的栈,即利 用一组地址连续的存储单元依次存放自栈 底到栈顶的数据元素,同时由于栈的操作 的特殊性,还必须附设一个位置指针top( 栈顶指针)来动态地指示栈顶元素在顺序 栈中的位置。通常以top=-1表示空栈。
第 3 章 栈和队列
3.1 栈 3.2 队列 3.3 栈和队列的应用
第3章栈和队列
3.1 栈
3.1.1 栈的抽象数据类型定义 3.1.2 栈的表示和算法实现
第3章栈和队列
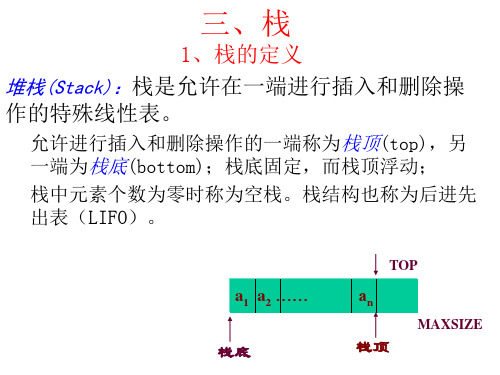
3.1.1 栈的定义
1.栈的定义 栈(stack)是一种只允许在一端进行插入和删除的线 性表,它是一种操作受限的线性表。在表中只允许进
行插入和删除的一端称为栈顶(top),另一端称为 栈 底 (bottom) 。 栈 的 插 入 操 作 通 常 称 为 入 栈 或 进 栈 (push),而栈的删除操作则称为出栈或退栈(pop)。 当栈中无数据元素时,称为空栈。
栈是按照后进先出 (LIFO)的原则组 织数据的,因此, 栈也被称为“后进 先出”的线性表。
第3章栈和队列
(2)入栈操作
Status Push(SqStack &S, Elemtype e)
【算法3.2 栈的入栈操作】
{ /*将元素e插入到栈S中,作为S的新栈顶*/
if (S->top>= Stack_Size -1) return ERROR;
else { S->top++;
S->elem[S->top]=e;
return OK;}
Push(S,’you’)
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
bool StackInit(SStack &S) { //初始化栈,即构造空栈
S.base=new SElemType[StackInitSize];
if (!S.base) return false;
S.top=S.base; S.stacksize=StackInitSize; return true;
SElemType data; SNode *next; //相当于线性表的prior
} *LStack;
void StackInit(LStack &S) { S=NULL;}
链栈的入栈
void Push(LStack &S,SElemType e) {
LStack q;
q=new SNode; q->data=e; q->next=S; S=q;
cout << ',';
PreOrderLists( T->rchild, visit );
cout << ')';
}
}
else
cout << '#';
}
先序遍历二叉树
void preorder(BiTree T,void visit(ElemType))
{
if(!T)
return ;
visit (T->data);
{
Queue q;
Tree x,y;
if(!T)
return;
QueueInit(q);
Enqueue(q,T);
while(Dequeue(q,x))
{
visit(x->data)
for(y=x->firstchild;y;y=y->nextsibling)
Enqueue(q,y);
}
}
先序遍历输出二叉树
&&MirrorSimilar(t1->rchild,t2->lchild);
}
广度优先搜索遍历
Viod BFSTraverse(ALGraph &G,void ,void visit(VexType))
{
int i,j,k;
ArcPtr p;
Queue q;
for(i=1;i<=G.Vexnum;i++)
preorder(T->lchild, visit);
preorder(T->rchild, visit);
}
判断两个二叉树是否相似
bool Similar( BiTree T1, BiTree T2 )
{
if( !T1 && !T2 )
return true;
if( !T1 || !T2 )
return false;
void PreOrderLists( BiTree T, void visit( TElemType ) )
{
if( T )
{
visit( T->data );
if( T->lchild || T->rchild )
{
cout << '(';
PreOrderLists( T->lchild, visit );
}
}Байду номын сангаас
}
链栈的出栈
bool Pop(LStack &S, SElemType &e) {
LStack q;
if (!S) return false;
e=S->data; q=S; S=S->next;
delete q; return true;
}
层序遍历树
Void TreeLevelOrder(tree T,void visit(TelemType))
{
k=p->adjvex;
if(!G.Vexs[k].visited)
{
visit(G>Vexs[k].data);
G.Vexs[k].visited=true;
Enqueue(q.k);
}
}
}
}
深度优先搜索遍历
void DFS(ALGraph &G, int i, void visit(VexType))
(S.stacksize+StackInc)*sizeof(SElemType));
if (!newbase) return false;
S.base=newbase; S.top=S.base+S.stacksize;
S.stacksize+=StackInc;
}
*S.top=e; S.top++; return true;
G.Vexs[i].visited=false;
for(i=1;i<=G.Vexnum;i++)
if(!G.vex[i].visited)
{
visit(G.Vexs[i].data);
G.Vexs[i].visited=true;
Enqueue(q,i);
while(Dequeue(q,j))
for(p=G.Vexs[j].firstarc;p;p=p->nextarc)
循环队链的出队
bool Dequeue( CSQueue &q, QElemType &e )
{
int front;
if( q.length == 0 )
return false;
front = ( q.rear + 1 - q.length + MAXQSIZE ) % MAXQSIZE;
e = q.elem[ front ];
q.length --;
return true;
}
循环队链的入队
bool Enqueue( CSQueue &q, QElemType e )
{
if( q.length == MAXQSIZE )
return false;
q.rear = ( q.rear + 1 ) % MAXQSIZE;
q.elem[ q.rear ] = e;
T->rchild = p;
Swap( T->rchild );
Swap( T->lchild );
}
二叉树的深度
int depth( BiTree T )
{
if( !T )
return 0;
int dl, dr;
dl = depth( T->lchild );
dr = depth( T->rchild );
delete p;
return true;
}
顺序栈的类型定义与基本操作:
const StackInitSize=100;
const StackInc=10;
struct SStack {
SElemType *base,*top; //栈底指针,栈顶指针
int stacksize; //当前分配的存储空间
return dl > dr? dl+1:dr+1;
}
计算树的深度
int TreeDepth( tree T )
{
if( !T )
return 0;
int d = 1;
tree p;
int depth = 1;
for( p = T->firstchild; p; p = p->nextsibling )
{ int j;
Arcptr p;
visit(G.Vexc[i].data);
G.Vexs[i].visited=true;
for(p=G.Vexs[i].firstarc ;p; p=p->nextarc)
{
J=p->adjvex;
if(!G.Vex[j].visited)
DFS(G,j,visit);
{
int i = -1;
CreateBiTree( T, s, i );
}
判断二叉树是否镜像相似
bool MirrorSimilar(BiTree t1,Bitree t2)
{
return (!t1&&!t2)||t1&&t2&&MirrorSimilar(t1->lchild,t2->rchild)
{
d = d + TreeDepth( p );
if( d > depth )
depth = d;
d = 1;
}
if( d >depth )
depth = d;
return depth;
}
构造二叉树
void CreateBiTree( BiTree &T, TElemType s[], int &i )
}
链队的出队
bool Dequeue( LQueue &q, QElemType &e )
{
LQueuePtr p;
if( q.rear->next == q.rear )
return false;
p = q.rear->next;
e = p->next->data;
q.rear->next = p->next;
{
i++;
if( s[i] =='#' )