Hadoop集群部署
Hadoop集群安装配置教程_Hadoop2.6.0_Ubuntu_CentOS

Hadoop集群安装配置教程_Hadoop2.6.0_Ubuntu/CentOS本教程讲述如何配置Hadoop 集群,默认读者已经掌握了Hadoop 的单机伪分布式配置,否则请先查看Hadoop安装教程_单机/伪分布式配置或CentOS安装Hadoop_单机/伪分布式配置。
本教程由厦门大学数据库实验室出品,转载请注明。
本教程适合于原生Hadoop 2,包括Hadoop 2.6.0, Hadoop 2.7.1 等版本,主要参考了官方安装教程,步骤详细,辅以适当说明,保证按照步骤来,都能顺利安装并运行Hadoop。
另外有Hadoop安装配置简略版方便有基础的读者快速完成安装。
为了方便新手入门,我们准备了两篇不同系统的Hadoop 伪分布式配置教程。
但其他Hadoop 教程我们将不再区分,可同时适用于Ubuntu 和CentOS/RedHat 系统。
例如本教程以Ubuntu 系统为主要演示环境,但对Ubuntu/CentOS 的不同配置之处、CentOS 6.x 与CentOS 7 的操作区别等都会尽量给出注明。
环境本教程使用Ubuntu 14.04 64位作为系统环境,基于原生Hadoop 2,在Hadoop 2.6.0 (stable)版本下验证通过,可适合任何Hadoop 2.x.y 版本,例如Hadoop 2.7.1,Hadoop 2.4.1 等。
本教程简单的使用两个节点作为集群环境: 一个作为Master 节点,局域网IP 为192.168.1.121;另一个作为Slave 节点,局域网IP 为192.168.1.122。
准备工作Hadoop 集群的安装配置大致为如下流程:1.选定一台机器作为Master2.在Master 节点上配置hadoop 用户、安装SSH server、安装Java 环境3.在Master 节点上安装Hadoop,并完成配置4.在其他Slave 节点上配置hadoop 用户、安装SSH server、安装Java 环境5.将Master 节点上的/usr/local/hadoop 目录复制到其他Slave 节点上6.在Master 节点上开启Hadoop配置hadoop 用户、安装SSH server、安装Java 环境、安装Hadoop 等过程已经在Hadoop安装教程_单机/伪分布式配置或CentOS安装Hadoop_单机/伪分布式配置中有详细介绍,请前往查看,不再重复叙述。
Hadoop集群配置详细

Linux系统配置
7安装JDK 将JDK文件解压,放到/usr/java目录下 cd /home/dhx/software/jdk mkdir /usr/java mv jdk1.6.0_45.zip /usr/java/
cd /usr/java
unzip jdk1.6.0_45.zip
从当前用户切换root用户的命令如下: 编辑主机名列表的命令
从当前用户切换root用户的命令如下:
Linux系统配置
操作步骤需要在HadoopMaster和HadoopSlave节点
上分别完整操作,都是用root用户。 从当前用户切换root用户的命令如下:
su root
从当前用户切换root用户的命令如下:
Linux系统配置
1拷贝软件包和数据包 mv ~/Desktop/software ~/
环境变量文件中,只需要配置JDK的路径
gedit conf/hadoop-env.sh
从当前用户切换root用户的命令如下: 编辑主机名列表的命令
Hadoop配置部署
3配置核心组件core-site.xml
gedit conf/core-site.xml
<configuration> <property> <name></name> /*2.0后用 fs.defaultFS代替*/ <value>hdfs://master:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/home/dhx/hadoopdata</value> </property> </configuration>
hadoop核心组件概述及hadoop集群的搭建

hadoop核⼼组件概述及hadoop集群的搭建什么是hadoop? Hadoop 是 Apache 旗下的⼀个⽤ java 语⾔实现开源软件框架,是⼀个开发和运⾏处理⼤规模数据的软件平台。
允许使⽤简单的编程模型在⼤量计算机集群上对⼤型数据集进⾏分布式处理。
hadoop提供的功能:利⽤服务器集群,根据⽤户的⾃定义业务逻辑,对海量数据进⾏分布式处理。
狭义上来说hadoop 指 Apache 这款开源框架,它的核⼼组件有:1. hdfs(分布式⽂件系统)(负责⽂件读写)2. yarn(运算资源调度系统)(负责为MapReduce程序分配运算硬件资源)3. MapReduce(分布式运算编程框架)扩展:关于hdfs集群: hdfs集群有⼀个name node(名称节点),类似zookeeper的leader(领导者),namenode记录了⽤户上传的⼀些⽂件分别在哪些DataNode上,记录了⽂件的源信息(就是记录了⽂件的名称和实际对应的物理地址),name node有⼀个公共端⼝默认是9000,这个端⼝是针对客户端访问的时候的,其他的⼩弟(跟随者)叫data node,namenode和datanode会通过rpc进⾏远程通讯。
Yarn集群: yarn集群⾥的⼩弟叫做node manager,MapReduce程序发给node manager来启动,MapReduce读数据的时候去找hdfs(datanode)去读。
(注:hdfs集群和yarn集群最好放在同⼀台机器⾥),yarn集群的⽼⼤主节点resource manager负责资源调度,应(最好)单独放在⼀台机器。
⼴义上来说,hadoop通常指更⼴泛的概念--------hadoop⽣态圈。
当下的 Hadoop 已经成长为⼀个庞⼤的体系,随着⽣态系统的成长,新出现的项⽬越来越多,其中不乏⼀些⾮ Apache 主管的项⽬,这些项⽬对 HADOOP 是很好的补充或者更⾼层的抽象。
hadoop集群部署之双虚拟机版

1、采用一台机器开两个虚拟机的方式构成两台电脑的环境,用root登录。
分别查看其IP地址:输入# ifconfig,可得主机IP:192.168.1.99;分机为:192.168.1.100。
2、在两台机器上的/etc/hosts均添加相应的主机名和IP地址:这里主机名命名为shenghao,分机名命名为slave:保存后重启网络:3、两台机器上均创立hadoop用户(注意是用root登陆)# useradd hadoop# passwd hadoop输入111111做为密码登录hadoop用户:注意,登录用户名为hadoop,而不是自己命名的shenghao。
4、ssh的配置进入centos的“系统→管理→服务器设置→服务,查看sshd服务是否运行。
在所有的机器上生成密码对:# ssh-keygen -t rsa这时hadoop目录下生成一个.ssh的文件夹,可以通过# ls .ssh/来查看里面产生的私钥和公钥:id_rsa和id_rsa.pub。
更改.ssh的读写权限:# chmod 755 .ssh在namenode上(即主机上)进入.ssh,将id_rsa.pub直接复制为authorized_keys(namenode的公钥):# cp id_rsa.pub authorized_keys更改authorized_keys的读写权限:# chmod 644 authorized_keys 【这个不必须,但保险起见,推荐使用】然后上传到datanode上(即分机上):# scp authorized_keys hadoop@slave:/home/hadoop/.ssh# cd .. 退出.ssh文件夹这样shenghao就可以免密码登录slave了:然后输入exit就可以退出去。
然后在datanode上(即分机上):将datanode上之前产生的公钥id_rsa.pub复制到namenode上的.ssh目录中,并重命名为slave.id_rsa.pub,这是为了区分从各个datanode上传过来的公钥,这里就一个datanode,简单标记下就可。
Hadoop生态系统及开发 实训手册 实训15 Kafka集群部署

实训6.3 Kafka集群部署L实训I目的通过本实训,了解Kafka的基本概念,理解Kafka工作原理,安装部署Kafka 集群。
2 .实训内容本实训通过安装和配置Kafka,学会执行Kafka,并且校验集群是否搭建成功。
3 .实训要求以小组为单元进行实训,每小组5人,小组自协商选一位组长,由组长安排和分配实训任务,具体参考实训操作环节。
小组成员需确保ZoOKeePer集群是否安装准确。
4 .准备知识(1) Kafka概念趣解①PrOdUCer:生产者,就是它来生产“鸡蛋”的。
②COnSUmer:消费者,生出的“鸡蛋”它来消费。
③TOPic:把它理解为标签,生产者每生产出来一个鸡蛋就贴上一个标签(Topic),消费者可不是谁生产的“鸡蛋”都吃的,这样不同的生产者生产出来的“鸡蛋”,消费者就可以选择性的“吃” 了。
©Broker:就是篮子了。
©Partition: Partition是物理上的概念,每个Topic包含一个或多个Partition o©Consumer Group :每个Consumer 属于一个特定的Consumer Group (可为每个Consumer指定group name,若不指定group name,则属于默认的group) 如果从技术角度,TOPiC标签实际就是队列,生产者把所有“鸡蛋(消息)” 都放到对应的队列里了,消费者到指定的队列里取。
5 .实训步骤(1)安装和配置Kafka①将kafka_2.13-3.3.1 .tgz压缩包上传至master节点的/root/PaCkage目录下。
②解压kafka_2.13-3.3.Ltgz,这里解压在/root/PaCkage 目录下:Cd ∕root∕packagetar -zxvf kafka_2.13-3.3. Ltgz -C ∕opt∕software∕(2)配置KafkaZooKeeper zookeeper.connect=localhost:2181 localhost,修改为安装ZoOKeePer 的三台节点,即master、slavel> slave2,主机刍里6-31ZooKeeper图6-32修改ZoOKeePer日志路径(3)复制master 的Kafka 到SIaVe 1、slave2(4)slavel> slave2Kafka①配置SlaVel的配置文件(修改broker.id)slave2broker.id)新打开一个终端,登录SlaVe2并执行vim ∕opt∕software∕kafka2.13-3.3.1 ∕config∕server.propertiesbroker.id=2⑤拷贝master节点的环境变量到SlaVel和slave2SlaVel SlaVe2节点中执行以下命令,使配置生效:source ZetcZprofile(5)校验Kafka①启动Kafka需确保master、slavel> SlaVe2的ZOOKeePer已启动,如未启动则用下面指令启动(执行jps,有QUorUmPeerMain进程则表示已启动):Kafka6-33图6-33查看各节点上的进程6.实训总结本次实训注意要安装配置好ZooKeeper, Kafka的安装部署与ZooKeeper的安装部署大同小异,启动的时候记得要汆启动ZOoKeeper,对于Kafka的原理要认真理解。
搭建hadoop集群的步骤

搭建hadoop集群的步骤Hadoop是一个开源的分布式计算平台,用于存储和处理大规模的数据集。
在大数据时代,Hadoop已经成为了处理海量数据的标准工具之一。
在本文中,我们将介绍如何搭建一个Hadoop集群。
步骤一:准备工作在开始搭建Hadoop集群之前,需要进行一些准备工作。
首先,需要选择适合的机器作为集群节点。
通常情况下,需要至少三台机器来搭建一个Hadoop集群。
其次,需要安装Java环境和SSH服务。
最后,需要下载Hadoop的二进制安装包。
步骤二:配置Hadoop环境在准备工作完成之后,需要对Hadoop环境进行配置。
首先,需要编辑Hadoop的配置文件,包括core-site.xml、hdfs-site.xml、mapred-site.xml和yarn-site.xml。
其中,core-site.xml用于配置Hadoop的核心参数,hdfs-site.xml用于配置Hadoop分布式文件系统的参数,mapred-site.xml用于配置Hadoop的MapReduce参数,yarn-site.xml用于配置Hadoop的资源管理器参数。
其次,需要在每个节点上创建一个hadoop用户,并设置其密码。
最后,需要在每个节点上配置SSH免密码登录,以便于节点之间的通信。
步骤三:启动Hadoop集群在完成Hadoop环境的配置之后,可以启动Hadoop集群。
首先,需要启动Hadoop的NameNode和DataNode服务。
NameNode是Hadoop分布式文件系统的管理节点,负责管理文件系统的元数据。
DataNode是Hadoop分布式文件系统的存储节点,负责实际存储数据。
其次,需要启动Hadoop的ResourceManager和NodeManager服务。
ResourceManager 是Hadoop的资源管理器,负责管理集群中的资源。
NodeManager是Hadoop的节点管理器,负责管理每个节点的资源。
实验文档1-部署Hadoop

Hadoop大数据技术实验资料airyqinHadoop大数据管理与分析处理平台部署实验手册CentOS 6集群下部署Hadoop(Airy qin)Hadoop大数据实验实战资料(请勿在互联网上传播)启动两台虚拟客户机:打开VMware Workstation10打开之前已经安装好的虚拟机:HadoopMaster和HadoopSlave出现异常,选择“否”进入Hadoop大数据实验实战资料(请勿在互联网上传播)如果之前没有打开过两个虚拟机,请使用“文件”->“打开”选项,选择之前的虚拟机安装包(在一体软件包里面的)第1步 Linux系统配置以下操作步骤需要在HadoopMaster和HadoopSlave节点上分别完整操作,都使用root用户,从当前用户切换root用户的命令如下:su root输入密码:zkpkHadoop大数据实验实战资料(请勿在互联网上传播)本节所有的命令操作都在终端环境,打开终端的过程如下图的Terminal菜单:终端打开后如下图中命令行窗口所示。
1.拷贝软件包和数据包将完整软件包“H adoop In Action Experiment”下的software包和sogou-data整体拖拽到HadoopMaster 节点的桌面上,并且在终端中执行下面的移动文件命令:mv ~/Desktop/software ~/Hadoop大数据实验实战资料(请勿在互联网上传播)mv ~/Desktop/sogou-data ~/1.1配置时钟同步1.1.1 配置自动时钟同步使用Linux命令配置crontab -e键入下面的一行代码:输入i,进入插入模式0 1 * * * /usr/sbin/ntpdate 1.1.2 手动同步时间/usr/sbin/ntpdate 1.2配置主机名1.2.1 HadoopMaster节点使用gedit 编辑主机名gedit /etc/sysconfig/network配置信息如下,如果已经存在则不修改,将HadoopMaster节点的主机名改为master,即下面代码的第3行所示。
Hadoop集群部署有几种模式?Hadoop集群部署方法介绍
Hadoop集群的部署分为三种,分别独立模式(Standalonemode)、伪分布式模式(Pseudo-Distributedmode)、完全分布式模式(Clustermode),具体介绍如下。
(1)独立模式:又称为单机模式,在该模式下,无需运行任何守护进程,所有的
程序都在单个JVM上执行。
独立模式下调试Hadoop集群的MapReduce程序非常
方便,所以一般情况下,该模式在学习或者发阶段调试使用。
(2)伪分布式模式:Hadoop程序的守护进程运行在一台节上,通常使用伪分布
式模式用来调试Hadoop分布式程序的代码,以及程序执行否正确,伪分布式模式完全分布式模式的一个特例。
(3)完全分布式模式:Hadoop的守护进程分别运行在由多个主机搭建的集群上,不同节担任不同的角色,在实际工作应用发中,通常使用该模式构建级Hadoop系统。
在Hadoop环境中,所有器节仅划分为两种角色,分别master(主节,1个)和slave(从节,多个)。
因此,伪分布模式集群模式的特例,只将主节和从节合二
为一罢了。
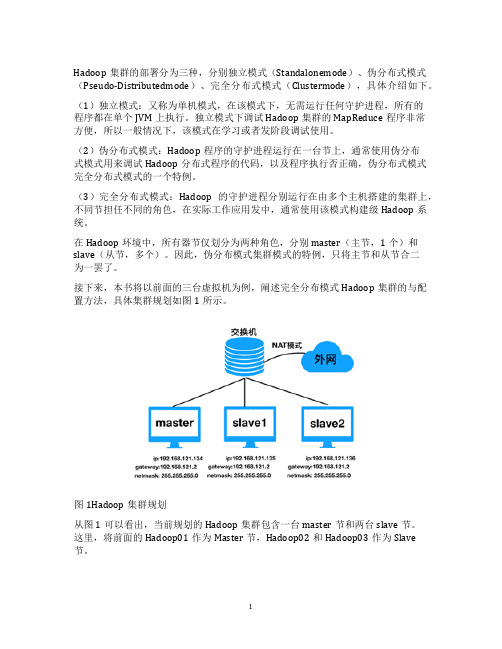
接下来,本书将以前面的三台虚拟机为例,阐述完全分布模式Hadoop集群的与配置方法,具体集群规划如图1所示。
图1Hadoop集群规划
从图1可以看出,当前规划的Hadoop集群包含一台master节和两台slave节。
这里,将前面的Hadoop01作为Master节,Hadoop02和Hadoop03作为Slave
节。
1。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
1.HDFS:HADOOP的分布式文件系统
HDFS:是一个分布式文件系统(整个系统中有多种角色<namenode、datanode、客户端、secondary namenode>,共同协作完成文件系统的功能)
功能:提供一个目录结构,顶层目录为:/
可以:创建文件夹、删除文件或文件夹、重命名文件、列出文件夹下的文件(涉及元数据操作)
保存文件、读取文件等(涉及元数据操作、文件块读写)
特点:可以存储海量的文件,如果容量不够,添加服务器(data node)即可文件被分散存储在若干台datanode服务器上(存储目录中)
一个文件也可能被切分成多个文件块(block块)分散存储在若干台datanode服务器每一个文件(文件块)在整个集群中,可以存储多个副本
(一个文件存几个副本、一个文件按多大来切块,是由客户端决定?)
hdfs的运作机制:
客户端存入的文件,
一方面由datanode存储文件内容(block)
另一方面由namenode记录文件的块信息(?块,?副本,在哪些dn上)
2.HDFS安装
2.1. 集群环境准备
1、克隆出4台linux虚拟机
2、修改每一台虚拟机的主机名:hdp20-01 hdp20-02 hdp20-03 hdp20-04
3、修改每一台虚拟机的ip地址:
192.168.33.31
192.168.33.32
192.168.33.33
192.168.33.34
4、修改每一台虚拟机的网卡物理地址
vi /etc/udev/rules.d/70-......
把eth0的那一行删掉,然后把下一行的eth1改成eth0
5、重启linux服务器:reboot
6、在windows上配置这几台linux服务器的域名映射:
改好后,同步scp给所有其他机器
7、用crt软件试连接
8、对每一台linux服务器关闭防火墙
8、对每一台linux机器配置域名映射
scp /etc/hosts hdp20-02:/etc/
scp /etc/hosts hdp20-03:/etc/
scp /etc/hosts hdp20-04:/etc/
验证:比如在hdp20-01上,
ping hdp20-02 ###看是否能ping通
9、在每台linux服务器上安装jdk
上传jdk安装包
解压
然后,将安装好的目录scp到其他所有机器的相同路径
然后,将改好的/etc/profile 拷贝scp到其他所有机器的对应路径下
然后用chat window ,统一source /etc/profile 2.2. 安装HDFS
上传hadoop的安装包
解压hadoop安装包
2.2.1.修改配置文件
补充参数:
dfs.replication 默认值3 ## 副本数量,该参数其实用于客户端软件
dfs.blocksize 默认值134217728 ##块大小,该参数其实用于客户端软件
2.2.2.启动hdfs集群
1、先初始化namenode的元数据存储目录:格式化
Hadoop namenode -format
2、先启动namenode
进入hadoop安装目录,里面有一个sbin目录,里面有一个脚本可用于启动hadoop的进程hadoop-daemon.sh
启动namenode:hadoop-daemon.sh start namenode
如果报错,说命令不认识,则应该把hadoop是sbin目录配置到linux的系统环境变量PATH 中
3、启动datanode
先将hadoop安装包从第一台配置好的机器上复制到另外3台机器
然后在后3台机器上配置好path环境变量
然后输入命令启动datanode
hadoop-daemon.sh start datanode
4、访问namenode的web页面
浏览器:http://hdp20-01:50070
可以看到3台datanode在线,即集群启动成功
2.2.
3.批量自动启动集群
1、先配置01机器到所有机器的ssh免密登陆
ssh-keygen ## 生成密钥对
ssh-copy-id hdp20-01
ssh-copy-id hdp20-02
ssh-copy-id hdp20-03
ssh-copy-id hdp20-04
检查:从01上: ssh hdp20-02 看是否要密码
2、修改slaves文件,将需要让脚本自动启动的datanode域名填入salves文件
cd /root/apps/hadoop-2.8.0/etc/hadoop
vi slaves
3、用hadoop安装目录中的sbin目录中的start-dfs.sh即可自动批启动集群
启动:start-dfs.sh
停止:stop-dfs.sh
2.2.4.HDFS命令行客户端
1、基本使用:
准备任意一台机器,上面放一个hadoop安装目录
然后,配置core-site.xml,写一个参数fs.defaultFS:值为hdfs集群的uri
然后,用安装目录中的hadoop命令即可启动hdfs的命令行客户端
hadoop fs -put /root/xx.avi /
2.3. HDFS集群常见故障原因及解决
1、namenode启动正常,但datanode启动失败
原因:datanode存储目录的VERSION文件中存储的集群id:clusterId保存的是上一次namenode所生成的集群id
解决:删除datanode的存储目录,然后再启动,会生成新的存储目录,存储新的集群id
2、datanode进程启动成功,但是不被namenode所接纳
原因:该datanode的存储目录跟另一台datanode的存储目录重复了,导致两个datanode 的uuid相同,namenode就只会认其中一台
解决:删除问题datanode上的存储目录,再启动,即可生成新的uuid
2.4. HDFS命令行客户端常用操作命令2.4.1.hdfs命令行客户端支持的所有命令:
2.4.2.需要掌握的常用命令:
1、上传文件
hadoop fs -put test.txt /
hadoop fs -copyFromLocal test.txt /test.txt.2
2、下载文件
hadoop fs -get /test.txt.2
hadoop fs -copyToLocal /test.txt.2
3、创建目录
hadoop fs -mkdir /aaa
hadoop fs -mkdir -p /bbb/xxx
4、删除目录
hadoop fs -rm -r /aaa
5、移动/重命名
hadoop fs -mv /test.txt.2 /test.txt.3
hadoop fs -mv /test.txt.3 /bbb/test.txt.4
6、拷贝文件
hadoop fs -cp /test.txt /bbb/
7、查看目录下的子文件夹和文件
hadoop fs -ls /bbb/xxx/
hadoop fs -ls -R / ##递归显示指定路径下的所有文件和文件夹信息
8、查看《文本》文件内容
hadoop fs -cat /test.txt
hadoop fs -tail /test.txt
9、下载多个文件在本地生成一个合并文件
hadoop fs -getmerge /test/*.dat ./xx.dat
客户端部署
修改core.site.xml文件
运行客户端命令
执行eclipse中HDFS的操作。