hadoop集群部署之双虚拟机版
Hadoop集群安装配置教程_Hadoop2.6.0_Ubuntu_CentOS

Hadoop集群安装配置教程_Hadoop2.6.0_Ubuntu/CentOS本教程讲述如何配置Hadoop 集群,默认读者已经掌握了Hadoop 的单机伪分布式配置,否则请先查看Hadoop安装教程_单机/伪分布式配置或CentOS安装Hadoop_单机/伪分布式配置。
本教程由厦门大学数据库实验室出品,转载请注明。
本教程适合于原生Hadoop 2,包括Hadoop 2.6.0, Hadoop 2.7.1 等版本,主要参考了官方安装教程,步骤详细,辅以适当说明,保证按照步骤来,都能顺利安装并运行Hadoop。
另外有Hadoop安装配置简略版方便有基础的读者快速完成安装。
为了方便新手入门,我们准备了两篇不同系统的Hadoop 伪分布式配置教程。
但其他Hadoop 教程我们将不再区分,可同时适用于Ubuntu 和CentOS/RedHat 系统。
例如本教程以Ubuntu 系统为主要演示环境,但对Ubuntu/CentOS 的不同配置之处、CentOS 6.x 与CentOS 7 的操作区别等都会尽量给出注明。
环境本教程使用Ubuntu 14.04 64位作为系统环境,基于原生Hadoop 2,在Hadoop 2.6.0 (stable)版本下验证通过,可适合任何Hadoop 2.x.y 版本,例如Hadoop 2.7.1,Hadoop 2.4.1 等。
本教程简单的使用两个节点作为集群环境: 一个作为Master 节点,局域网IP 为192.168.1.121;另一个作为Slave 节点,局域网IP 为192.168.1.122。
准备工作Hadoop 集群的安装配置大致为如下流程:1.选定一台机器作为Master2.在Master 节点上配置hadoop 用户、安装SSH server、安装Java 环境3.在Master 节点上安装Hadoop,并完成配置4.在其他Slave 节点上配置hadoop 用户、安装SSH server、安装Java 环境5.将Master 节点上的/usr/local/hadoop 目录复制到其他Slave 节点上6.在Master 节点上开启Hadoop配置hadoop 用户、安装SSH server、安装Java 环境、安装Hadoop 等过程已经在Hadoop安装教程_单机/伪分布式配置或CentOS安装Hadoop_单机/伪分布式配置中有详细介绍,请前往查看,不再重复叙述。
Hadoop集群配置详细

Linux系统配置
7安装JDK 将JDK文件解压,放到/usr/java目录下 cd /home/dhx/software/jdk mkdir /usr/java mv jdk1.6.0_45.zip /usr/java/
cd /usr/java
unzip jdk1.6.0_45.zip
从当前用户切换root用户的命令如下: 编辑主机名列表的命令
从当前用户切换root用户的命令如下:
Linux系统配置
操作步骤需要在HadoopMaster和HadoopSlave节点
上分别完整操作,都是用root用户。 从当前用户切换root用户的命令如下:
su root
从当前用户切换root用户的命令如下:
Linux系统配置
1拷贝软件包和数据包 mv ~/Desktop/software ~/
环境变量文件中,只需要配置JDK的路径
gedit conf/hadoop-env.sh
从当前用户切换root用户的命令如下: 编辑主机名列表的命令
Hadoop配置部署
3配置核心组件core-site.xml
gedit conf/core-site.xml
<configuration> <property> <name></name> /*2.0后用 fs.defaultFS代替*/ <value>hdfs://master:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/home/dhx/hadoopdata</value> </property> </configuration>
Hadoop环境搭建及wordcount实例运行
环境概述
虚拟平台:VirtualBox4.2.0
Linux版本:Ubuntu10.04
Hadoop版本:hadoop-0.20.2
JDK版本:1.6.0
Hadoop环境规划:一台namenode主机master,两台datanode主机salve1、slave2,master主机IP为111.111.111.2,slave1主机IP为111.111.111.3,slave2主机IP为111.111.111.4。
ssh_5.3p1-3ubuntu3_all.deb
依次安装即可
dpkg -i openssh-client_5.3p1-3ubuntu3_i386.deb
dpkg -i openssh-server_5.3p1-3ubuntu3_i386.deb
dpkg -i ssh_5.3p1-3ubuntu3_all.deb
14/02/20 15:59:58 INFO mapred.JobClient: Running job: job_201402201551_0003
14/02/20 15:59:59 INFO mapred.JobClient: map 0% reduce 0%
14/02/20 16:00:07 INFO mapred.JobClient: map 100% reduce 0%
111.111.111.2 master
111.111.111.3 slave1
111.111.111.4 slave2
然后按以下步骤配置master到slave1之间的ssh信任关系
用户@主机:/执行目录
操作命令
说明
hadoop@master:/home/hadoop
hadoop集群搭建实训报告

实训项目名称:搭建Hadoop集群项目目标:通过实际操作,学生将能够搭建一个基本的Hadoop集群,理解分布式计算的概念和Hadoop生态系统的基本组件。
项目步骤:1. 准备工作介绍Hadoop和分布式计算的基本概念。
确保学生已经安装了虚拟机或者物理机器,并了解基本的Linux命令。
下载Hadoop二进制文件和相关依赖。
2. 单节点Hadoop安装在一台机器上安装Hadoop,并配置单节点伪分布式模式。
创建Hadoop用户,设置环境变量,编辑Hadoop配置文件。
启动Hadoop服务,检查运行状态。
3. Hadoop集群搭建选择另外两台或更多机器作为集群节点,确保网络互通。
在每个节点上安装Hadoop,并配置集群节点。
编辑Hadoop配置文件,包括core-site.xml、hdfs-site.xml、mapred-site.xml等。
配置SSH无密码登录,以便节点之间能够相互通信。
4. Hadoop集群启动启动Hadoop集群的各个组件,包括NameNode、DataNode、ResourceManager、NodeManager 等。
检查集群状态,确保所有节点都正常运行。
5. Hadoop分布式文件系统(HDFS)操作使用Hadoop命令行工具上传、下载、删除文件。
查看HDFS文件系统状态和报告。
理解HDFS的数据分布和容错机制。
6. Hadoop MapReduce任务运行编写一个简单的MapReduce程序,用于分析示例数据集。
提交MapReduce作业,观察作业的执行过程和结果。
了解MapReduce的工作原理和任务分配。
7. 数据备份和故障恢复模拟某一节点的故障,观察Hadoop集群如何自动进行数据备份和故障恢复。
8. 性能调优(可选)介绍Hadoop性能调优的基本概念,如调整副本数、调整块大小等。
尝试调整一些性能参数,观察性能改善情况。
9. 报告撰写撰写实训报告,包括项目的目标、步骤、问题解决方法、实验结果和总结。
idea连接虚拟机hadoop的详细步骤

idea连接虚拟机hadoop的详细步骤以下是连接虚拟机和Hadoop的详细步骤:1. 启动虚拟机:首先,启动虚拟机,确保虚拟机的操作系统已经正常运行。
2. 检查网络设置:在虚拟机中,检查网络设置是否正确配置。
确保能够与主机(外部)网络通信。
3. 安装Java JDK:检查虚拟机是否已安装Java JDK。
如果没有安装,则需要通过下载JDK并按照安装说明进行安装。
4. 下载Hadoop:从Apache Hadoop官方网站上下载所需版本的Hadoop。
下载完毕后,将文件保存到虚拟机中的合适位置。
5. 解压Hadoop文件:将下载的Hadoop文件解压到虚拟机上的合适位置。
可以使用以下命令解压tar.gz文件:`tar -zxvf hadoop-x.x.x.tar.gz`其中,x.x.x代表具体版本号。
6. 配置Hadoop环境变量:打开虚拟机中的终端,并编辑`~/.bashrc`文件。
在文件末尾添加以下行:`export HADOOP_HOME=/path/to/hadoop` (将/path/to/hadoop替换为实际Hadoop目录的路径)`export PATH=$PATH:$HADOOP_HOME/bin``export PATH=$PATH:$HADOOP_HOME/sbin``export HADOOP_MAPRED_HOME=$HADOOP_HOME``export HADOOP_COMMON_HOME=$HADOOP_HOME` `export HADOOP_HDFS_HOME=$HADOOP_HOME``export YARN_HOME=$HADOOP_HOME``exportHADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/ lib/native``export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"`保存文件并执行以下命令使环境变量生效:`source ~/.bashrc`7. 配置Hadoop:进入Hadoop安装目录,并编辑`hadoop-env.sh`文件。
搭建hadoop集群的步骤

搭建hadoop集群的步骤Hadoop是一个开源的分布式计算平台,用于存储和处理大规模的数据集。
在大数据时代,Hadoop已经成为了处理海量数据的标准工具之一。
在本文中,我们将介绍如何搭建一个Hadoop集群。
步骤一:准备工作在开始搭建Hadoop集群之前,需要进行一些准备工作。
首先,需要选择适合的机器作为集群节点。
通常情况下,需要至少三台机器来搭建一个Hadoop集群。
其次,需要安装Java环境和SSH服务。
最后,需要下载Hadoop的二进制安装包。
步骤二:配置Hadoop环境在准备工作完成之后,需要对Hadoop环境进行配置。
首先,需要编辑Hadoop的配置文件,包括core-site.xml、hdfs-site.xml、mapred-site.xml和yarn-site.xml。
其中,core-site.xml用于配置Hadoop的核心参数,hdfs-site.xml用于配置Hadoop分布式文件系统的参数,mapred-site.xml用于配置Hadoop的MapReduce参数,yarn-site.xml用于配置Hadoop的资源管理器参数。
其次,需要在每个节点上创建一个hadoop用户,并设置其密码。
最后,需要在每个节点上配置SSH免密码登录,以便于节点之间的通信。
步骤三:启动Hadoop集群在完成Hadoop环境的配置之后,可以启动Hadoop集群。
首先,需要启动Hadoop的NameNode和DataNode服务。
NameNode是Hadoop分布式文件系统的管理节点,负责管理文件系统的元数据。
DataNode是Hadoop分布式文件系统的存储节点,负责实际存储数据。
其次,需要启动Hadoop的ResourceManager和NodeManager服务。
ResourceManager 是Hadoop的资源管理器,负责管理集群中的资源。
NodeManager是Hadoop的节点管理器,负责管理每个节点的资源。
Hadoop集群部署有几种模式?Hadoop集群部署方法介绍
Hadoop集群的部署分为三种,分别独立模式(Standalonemode)、伪分布式模式(Pseudo-Distributedmode)、完全分布式模式(Clustermode),具体介绍如下。
(1)独立模式:又称为单机模式,在该模式下,无需运行任何守护进程,所有的
程序都在单个JVM上执行。
独立模式下调试Hadoop集群的MapReduce程序非常
方便,所以一般情况下,该模式在学习或者发阶段调试使用。
(2)伪分布式模式:Hadoop程序的守护进程运行在一台节上,通常使用伪分布
式模式用来调试Hadoop分布式程序的代码,以及程序执行否正确,伪分布式模式完全分布式模式的一个特例。
(3)完全分布式模式:Hadoop的守护进程分别运行在由多个主机搭建的集群上,不同节担任不同的角色,在实际工作应用发中,通常使用该模式构建级Hadoop系统。
在Hadoop环境中,所有器节仅划分为两种角色,分别master(主节,1个)和slave(从节,多个)。
因此,伪分布模式集群模式的特例,只将主节和从节合二
为一罢了。
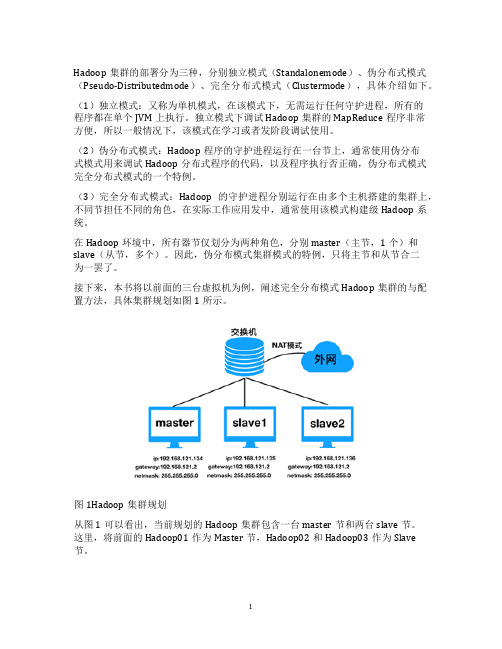
接下来,本书将以前面的三台虚拟机为例,阐述完全分布模式Hadoop集群的与配置方法,具体集群规划如图1所示。
图1Hadoop集群规划
从图1可以看出,当前规划的Hadoop集群包含一台master节和两台slave节。
这里,将前面的Hadoop01作为Master节,Hadoop02和Hadoop03作为Slave
节。
1。
Hadoop 搭建

(与程序设计有关)
课程名称:云计算技术提高
实验题目:Hadoop搭建
Xx xx:0000000000
x x:xx
x x:
xxxx
2021年5月21日
实验目的及要求:
开源分布式计算架构Hadoop的搭建
软硬件环境:
Vmware一台计算机
算法或原理分析(实验内容):
Hadoop是Apache基金会旗下一个开源的分布式存储和分析计算平台,使用Java语言开发,具有很好的跨平台性,可以运行在商用(廉价)硬件上,用户无需了解分布式底层细节,就可以开发分布式程序,充分使用集群的高速计算和存储。
三.Hadoop的安装
1.安装并配置环境变量
进入官网进行下载hadoop-2.7.5, 将压缩包在/usr目录下解压利用tar -zxvf Hadoop-2.7.5.tar.gz命令。同样进入 vi /etc/profile 文件,设置相应的HADOOP_HOME、PATH在hadoop相应的绝对路径。
4.建立ssh无密码访问
二.JDK安装
1.下载JDK
利用yum list java-1.8*查看镜像列表;并利用yum install java-1.8.0-openjdk* -y安装
2.配置环境变量
利用vi /etc/profile文件配置环境,设置相应的JAVA_HOME、JRE_HOME、PATH、CLASSPATH的绝对路径。退出后,使用source /etc/profile使环境变量生效。利用java -version可以测试安装是否成功。
3.关闭防火墙并设置时间同步
通过命令firewall-cmd–state查看防火墙运行状态;利用systemctl stop firewalld.service关闭防火墙;最后使用systemctl disable firewalld.service禁止自启。利用yum install ntp下载相关组件,利用date命令测试
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
1、采用一台机器开两个虚拟机的方式构成两台电脑的环境,用root登录。
分别查看其IP地址:输入# ifconfig,可得主机IP:192.168.1.99;分机为:192.168.1.100。
2、在两台机器上的/etc/hosts均添加相应的主机名和IP地址:这里主机名命名为shenghao,分机名命名为slave:保存后重启网络:3、两台机器上均创立hadoop用户(注意是用root登陆)# useradd hadoop# passwd hadoop输入111111做为密码登录hadoop用户:注意,登录用户名为hadoop,而不是自己命名的shenghao。
4、ssh的配置进入centos的“系统→管理→服务器设置→服务,查看sshd服务是否运行。
在所有的机器上生成密码对:# ssh-keygen -t rsa这时hadoop目录下生成一个.ssh的文件夹,可以通过# ls .ssh/来查看里面产生的私钥和公钥:id_rsa和id_rsa.pub。
更改.ssh的读写权限:# chmod 755 .ssh在namenode上(即主机上)进入.ssh,将id_rsa.pub直接复制为authorized_keys(namenode的公钥):# cp id_rsa.pub authorized_keys更改authorized_keys的读写权限:# chmod 644 authorized_keys 【这个不必须,但保险起见,推荐使用】然后上传到datanode上(即分机上):# scp authorized_keys hadoop@slave:/home/hadoop/.ssh# cd .. 退出.ssh文件夹这样shenghao就可以免密码登录slave了:然后输入exit就可以退出去。
然后在datanode上(即分机上):将datanode上之前产生的公钥id_rsa.pub复制到namenode上的.ssh目录中,并重命名为slave.id_rsa.pub,这是为了区分从各个datanode上传过来的公钥,这里就一个datanode,简单标记下就可。
# scp -r id_rsa.pub hadoop@shenghao:/home/hadoop/.ssh/slave.id_rsa.pub复制完毕,此时,由于namenode中已经存在authorized_keys文件,所以这里是追加,不是复制。
在namenode上执行以下命令,将每个datanode的公钥信息追加:# cat slave.id_rsa.pub >> authorized_keys这样,namenode和datanode之间便可以相互ssh上并不需要密码:然后输入exit就可以退出去。
5、hadoop的集群部署配置hadoop前一定要配置JDK,请参考相关资料,这里就不赘述了。
将下载好的hadoop-0.19.0.tar.gz文件上传到namenode的/home/hadoop/hadoopinstall解压文件:# tar zxvf hadoop-0.19.0.tar.gz在/erc/profile的最后添加hadoop的路径:# set hadoop pathexport HADOOP_HOME=/home/hadoop/hadoopinstall/hadoop-0.20.2export PATH=$HADOOP_HOME/bin:$PATH之后配置hadoop/conf中的4个文件:(1)*******配置core-site.xml********<configuration><property><name>hadoop.tmp.dir</name><value>/home/hadoop/hadoopinstall/tmp</value>(注意,请先在hadoopinstall目录下建立tmp文件夹)<description>A base for other temporary directories.</description></property><!-- file system properties --><property><name></name><value>hdfs://192.168.1.99:9000</value></property></configuration>(2)************配置mapred-site.xml**************<configuration><property><name>mapred.job.tracker</name><value>192.168.1.99:9001</value></property></configuration>(3)************配置hdfd-site.xml***************<configuration><property><name>dfs.replication</name><value>1</value>(replication 是数据副本数量,默认为3,datanode 少于3台就会报错)</property></configuration>(4)配置masters,加入shenghao 192.168.1.99 (建议同时去掉localhost)(5)配置slaves,加入slave 192.168.1.98 (建议同上)6、将namenode的hadoop复制到datanode之上,可以用上面所述的传送指令的方法打包传送,也可以通过VMtools的文件夹共享功能复制过去。
之后在datanode上将hadoop的路径添加到/etc/profile中(这个不是必须的):# set hadoop pathexport HADOOP_HOME=/home/zkl/hadoopinstall/hadoop-0.20.1export PATH=$HADOOP_HOME/bin:$PATH至此,配置完毕。
7、在namenode(主机)上启动hadoop并查看集群状态格式化hadoop:启动hadoop:<1>先启动dfs<2>再启动mapred【这里推荐用start-dfs.sh和start-mapred.sh来代替start-all.sh】【在退出hadoop时,也用相应的stop-dfs.sh和stop-mapred.sh来代替】查看namenode上的进程:查看datanode上的进程:在namenode(主机)上查看集群状态:7、在hadoop上执行wordcount任务将conf/目录下的core-site.xml做为输入放在input2中;执行任务,并将结果输出至output文件夹中这两个步骤如下图:查看输出结果信息:遇见的问题与解决方案:1、hadoop格式化失败###############################################################################[hadoop@shenghao hadoop-0.20.2]$ bin/hadoop namenode -format10/11/14 12:12:19 INFO Node: STARTUP_MSG:/************************************************************STARTUP_MSG: Starting NameNodeSTARTUP_MSG: host = shenghao/192.168.1.99STARTUP_MSG: args = [-format]STARTUP_MSG: version = 0.20.2STARTUP_MSG: build = https:///repos/asf/hadoop/common/branches/branch-0.20 -r 911707; compiledby 'chrisdo' on Fri Feb 19 08:07:34 UTC 2010************************************************************/10/11/14 12:12:19 INFO namenode.FSNamesystem: fsOwner=hadoop,hadoop10/11/14 12:12:19 INFO namenode.FSNamesystem: supergroup=supergroup10/11/14 12:12:19 INFO namenode.FSNamesystem: isPermissionEnabled=true10/11/14 12:12:19 ERROR Node: java.io.IOException: Cannot create directory/home/hadoop/hadoopinstall/tmp/dfs/name/currentatmon.Storage$StorageDirectory.clearDirectory(Storage.java:295)at node.FSImage.format(FSImage.java:1086)at node.FSImage.format(FSImage.java:1110)at Node.format(NameNode.java:856)atNode.createNameNode(NameNode.java:948)at Node.main(NameNode.java:965)10/11/14 12:12:19 INFO Node: SHUTDOWN_MSG:/************************************************************SHUTDOWN_MSG: Shutting down NameNode at shenghao/192.168.1.99************************************************************/###############################################################################解决方案:此时,在hadoop用户下,用ls指令可能也看不到hadoopinstall文件夹里要求新建的tmp文件夹,主要原因是在操作配置的时候,hadoop的解压和tmp文件夹的建立可能是在root下建立的,故而hadoop没有权限进行读写。