Hadoop集群--初步方案
Hadoop集群配置与数据处理入门

Hadoop集群配置与数据处理入门1. 引言Hadoop是一个开源的分布式计算框架,被广泛应用于大规模数据处理和存储。
在本文中,我们将介绍Hadoop集群的配置和数据处理的基本概念与入门知识。
2. Hadoop集群配置2.1 硬件要求架设Hadoop集群需要一定的硬件资源支持。
通常,集群中包含主节点和若干个从节点。
主节点负责整个集群的管理,而从节点负责执行具体的计算任务。
在硬件要求方面,主节点需要具备较高的计算能力和存储空间。
从节点需要具备较低的计算能力和存储空间,但数量较多。
此外,网络带宽也是一个关键因素。
较高的网络带宽可以加快数据的传输速度,提升集群的效率。
2.2 软件要求Hadoop运行在Java虚拟机上,所以首先需要确保每台主机都安装了适当版本的Java。
其次,需要安装Hadoop分发版本,如Apache Hadoop或Cloudera等。
针对集群管理,可以选择安装Hadoop的主节点管理工具,如Apache Ambari或Cloudera Manager。
这些工具可以帮助用户轻松管理集群的配置和状态。
2.3 配置文件Hadoop集群部署需要配置多个文件。
其中,最重要的是核心配置文件core-site.xml、hdfs-site.xml和yarn-site.xml。
core-site.xml配置Hadoop的核心参数,如文件系统和输入输出配置等;hdfs-site.xml用于配置Hadoop分布式文件系统;yarn-site.xml配置Hadoop资源管理器和任务调度器相关的参数。
3. 数据处理入门3.1 数据存储与处理Hadoop的核心之一是分布式文件系统(HDFS),它是Hadoop集群的文件系统,能够在集群中存储海量数据。
用户可以通过Hadoop的命令行工具或API进行文件的读取、写入和删除操作。
3.2 数据处理模型MapReduce是Hadoop的编程模型。
它将大规模的数据集拆分成小的数据块,并分配给集群中的多个计算节点进行并行处理。
Hadoop集群的三种方式

Hadoop集群的三种⽅式1,Local(Standalone) Mode 单机模式$ mkdir input$ cp etc/hadoop/*.xml input$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.2.jar grep input output 'dfs[a-z.]+'$ cat output/*解析$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.2.jar grep input output 'dfs[a-z.]+'input 夹下⾯的⽂件:capacity-scheduler.xml core-site.xml hadoop-policy.xml hdfs-site.xml httpfs-site.xml yarn-site.xml bin/hadoop hadoop 命令jar 这个命令在jar包⾥⾯share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.2.jar 具体位置grep grep 函数input grep 函数的⽬标⽂件夹output grep 函数结果的输出⽂件夹'dfs[a-z.]+' grep 函数的匹配正则条件直译:将input⽂件下⾯的⽂件中包含 'dfs[a-z.]+' 的字符串给输出到output ⽂件夹中输出结果:part-r-00000 _SUCCESScat part-r-00000:1 dfsadmin在hadoop-policy.xml 存在此字符串2,Pseudo-Distributed Operation 伪分布式在 etc/hadoop/core.site.xml 添加以下属性<configuration><property><name>fs.defaultFS</name><value>hdfs://:8020</value> 是主机名,已经和ip相互映射</property>还需要覆盖默认的设定,mkdir -p data/tmp<property><name>hadoop.tmp.dir</name><value>/opt/modules/hadoop-2.5.0/data/tmp</value> 是主机名,已经和ip相互映射</property>垃圾箱设置删除⽂件保留时间(分钟)<property><name>fs.trash.interval</name><value>10080</value></property></configuration>etc/hadoop/hdfs-site.xml: 伪分布式1个备份<configuration><property><name>dfs.replication</name><value>1</value></property>配置从节点<property><name>node.secondary.http-address</name><value>主机名:50090</value></property></configuration>格式化元数据,进⼊到安装⽬录下bin/hdfs namenode -format启动namenode,所有的命令都在sbin下,通过ls sbin/ 可以查看sbin/hadoop-daemon.sh start namenode hadoop 的守护线程启动(主数据)sbin/hadoop-daemon.sh start datanode 启动datanode(从数据)nameNode都有个web⽹页,端⼝50070创建hdfs ⽂件夹,创建在⽤户名下⾯bin/hdfs dfs -mkdir -p /user/chris查看⽂件夹bin/hdfs dfs -ls -R / 回调查询本地新建⽂件夹mkdir wcinput mkdir wcoutput vi wc.input创建wc.input⽂件,并写⼊内容hdfs⽂件系统新建⽂件夹bin/hdfs dfs -mkdir -p /user/chris/mapreduce/wordcount/input本地⽂件上传hdfs⽂件系统bin/hdfs dfs -put wcinput/wc.input /user/chris/mapreduce/wordcount/input/在hdfs⽂件系统上使⽤mapreduce$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.2.jar wordcount /user/chris/mapreduce/wordcount/input /user/chris/mapreduce/wordcount/output红⾊代表:读取路径蓝⾊代表:输出路径所以mapreduce的结果已经写到了hdfs的输出⽂件⾥⾯去了Yarn on a Single Node/opt/modules/hadoop-2.5.0/etc/hadoop/yarn-site.xml 在hadoop的安装路径下<configuration><property><name>yarn.resourcemanager.hostname</name><value></value></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property></configuration>yarn 的配置已经完成在同⼀⽬录下slave⽂件上添加主机名或者主机ip,默认是localhostyarn-env.sh 和 mapred-env.sh把JAVA_HOME 更改下,防⽌出错export JAVA_HOME=/home/chris/software/jdk1.8.0_201将mapred-site.xml.template 重命名为mapred-site.xml,同时添加以下配置<configuration><property><name></name><value>yarn</name></property></configuration>先将/user/chris/mapreduce/wordcount/output/删除再次执⾏$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.2.jarwordcount /user/chris/mapreduce/wordcount/input /user/chris/mapreduce/wordcount/output伪分布式执⾏完毕,mapreduce 执⾏在了yarn 上3,完全分布式基于伪分布式,配置好⼀台机器后,分发⾄其它机器step1: 配置ip 和 hostname 映射vi /etc/hosts192.168.178.110 hella-hadoop192.168.178.111 hella-hadoop02192.168.178.112 hella-hadoop03同时在window以下路径也得设置C:\Windows\System32\drivers\etc\hosts192.168.178.110 hella-hadoop192.168.178.111 hella-hadoop02192.168.178.112 hella-hadoop03具体可参考linux ip hostname 映射step2:部署(假设三台机器)不同机器配置不同的节点部署:hella-hadoop hella-hadoop02 hella-hadoop03HDFS:NameNodeDataNode DataNode DataNodeSecondaryNameNodeYARN:ResourceManagerNodeManager NodeManager NodeManager MapReduce:JobHistoryServer配置:* hdfshadoop-env.shcore.site.xmlhdfs-site.xmlslaves*yarnyarn-env.shyarn-site.xmlslaves*mapreducemapred-env.shmapred-site.xmlstep3:修改配置⽂件core.xml<configuration><property><name>fs.defaultFS</name><value>hdfs://:8020</value></property><property><name>hadoop.tmp.dir</name><value>/opt/app/hadoop-2.5.0/data/tmp</value></property><property><name>fs.trash.interval</name><value>10080</value></property></configuration>hdfs-site.xml<configuration><property><name>node.secondary.http-address</name><value>:50090</value></property></configuration>slavesyarn-site.xml<configuration><property><name>yarn.resourcemanager.hostname</name><value></value></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><!--NodeManager Resouce --><property><name>yarn.nodemanager.resource.memory-mb</name><value>4096</value></property><property><name>yarn.nodemanager.resource.cpu-vcores</name><value>4</value></property><property><name>yarn.log-aggregation-enable</name><value>true</value></property><property><name>yarn.log-aggregation-retain-seconds</name><value>640800</value></property></configuration>mapred-site.xml<configuration><property><name></name><value>yarn</value></property><property><name>mapreduce.jobhistory.address</name><value>:10020</value></property><property><name>mapreduce.jobhistory.webapp.address</name><value>:19888</value></property></configurationstep4:集群的配置路径在各个机器上要⼀样,⽤户名⼀样step5: 分发hadoop 安装包⾄各个机器节点scp -p 源节点⽬标节点使⽤scp 命令需要配置ssh ⽆密钥登陆,博⽂如下:step6:启动并且test mapreduce可能会有问题No route to Host 的Error,查看hostname 以及 ip 配置,或者是防⽕墙有没有关闭防⽕墙关闭,打开,状态查询,请参考以下博⽂:4,完全分布式+ HAHA全称:HDFS High Availability Using the Quorum Journal Manager 即 HDFS⾼可⽤性通过配置分布式⽇志管理HDFS集群中存在单点故障(SPOF),对于只有⼀个NameNode 的集群,若是NameNode 出现故障,则整个集群⽆法使⽤,知道NameNode 重新启动。
hadoop核心组件概述及hadoop集群的搭建

hadoop核⼼组件概述及hadoop集群的搭建什么是hadoop? Hadoop 是 Apache 旗下的⼀个⽤ java 语⾔实现开源软件框架,是⼀个开发和运⾏处理⼤规模数据的软件平台。
允许使⽤简单的编程模型在⼤量计算机集群上对⼤型数据集进⾏分布式处理。
hadoop提供的功能:利⽤服务器集群,根据⽤户的⾃定义业务逻辑,对海量数据进⾏分布式处理。
狭义上来说hadoop 指 Apache 这款开源框架,它的核⼼组件有:1. hdfs(分布式⽂件系统)(负责⽂件读写)2. yarn(运算资源调度系统)(负责为MapReduce程序分配运算硬件资源)3. MapReduce(分布式运算编程框架)扩展:关于hdfs集群: hdfs集群有⼀个name node(名称节点),类似zookeeper的leader(领导者),namenode记录了⽤户上传的⼀些⽂件分别在哪些DataNode上,记录了⽂件的源信息(就是记录了⽂件的名称和实际对应的物理地址),name node有⼀个公共端⼝默认是9000,这个端⼝是针对客户端访问的时候的,其他的⼩弟(跟随者)叫data node,namenode和datanode会通过rpc进⾏远程通讯。
Yarn集群: yarn集群⾥的⼩弟叫做node manager,MapReduce程序发给node manager来启动,MapReduce读数据的时候去找hdfs(datanode)去读。
(注:hdfs集群和yarn集群最好放在同⼀台机器⾥),yarn集群的⽼⼤主节点resource manager负责资源调度,应(最好)单独放在⼀台机器。
⼴义上来说,hadoop通常指更⼴泛的概念--------hadoop⽣态圈。
当下的 Hadoop 已经成长为⼀个庞⼤的体系,随着⽣态系统的成长,新出现的项⽬越来越多,其中不乏⼀些⾮ Apache 主管的项⽬,这些项⽬对 HADOOP 是很好的补充或者更⾼层的抽象。
利用Hadoop实现分布式数据处理的步骤与方法

利用Hadoop实现分布式数据处理的步骤与方法随着数据量的急剧增长和计算任务的复杂化,传统的数据处理方法已经无法满足当今大数据时代的需求。
分布式数据处理技术由此应运而生,它能够将庞大的数据集分解为多个小块,然后在多个计算节点上并行处理,提高数据处理的效率和可靠性。
Hadoop作为目前最流行的分布式数据处理框架之一,具备高可靠性、高扩展性以及良好的容错性,并且能够在廉价的硬件上运行。
下面将介绍使用Hadoop实现分布式数据处理的步骤与方法。
1. 数据准备在开始之前,首先需要准备需要处理的数据集。
这些数据可以是结构化数据、半结构化数据或非结构化数据。
在准备数据时,需要考虑数据的格式、大小以及数据的来源。
可以从本地文件系统、HDFS、数据库或云存储等不同的数据源中获取数据。
确保数据的完整性和正确性非常重要。
2. Hadoop集群搭建接下来,需要搭建一个Hadoop集群来支持分布式数据处理。
Hadoop集群由一个主节点(Master)和多个从节点(Slaves)组成。
主节点负责任务调度、资源管理和数据分发,而从节点负责实际的数据处理任务。
搭建Hadoop集群的过程包括设置主节点和从节点的配置文件、创建HDFS文件系统以及配置各个节点的网络设置等。
可以采用Apache Hadoop的标准发行版或者使用商业发行版(如Cloudera或Hortonworks)来搭建Hadoop集群。
3. 数据分析与计算一旦完成Hadoop集群的搭建,就可以开始进行数据处理了。
Hadoop通过MapReduce模型来实现数据的并行处理。
Map阶段将输入数据分割为若干个小的数据块,并将每个数据块交给不同的计算节点进行处理。
Reduce阶段将Map阶段输出的结果进行合并和汇总。
为了实现数据的分析与计算,需要编写Map和Reduce函数。
Map函数负责将输入数据转换成键值对(Key-Value Pair),而Reduce函数负责对Map函数输出的键值对进行操作。
Hadoop集群部署有几种模式?Hadoop集群部署方法介绍
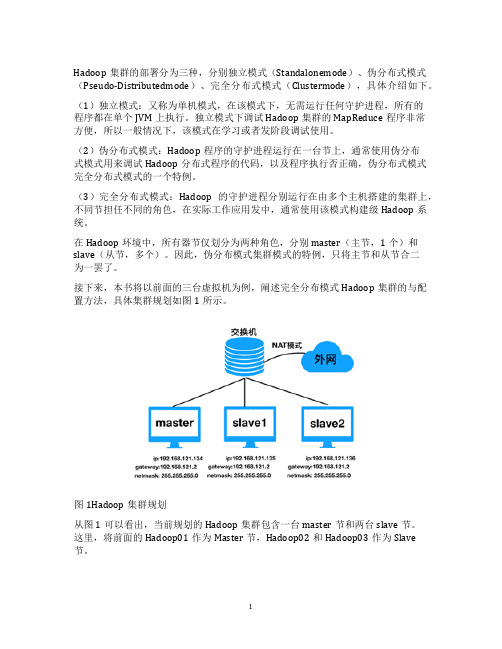
Hadoop集群的部署分为三种,分别独立模式(Standalonemode)、伪分布式模式(Pseudo-Distributedmode)、完全分布式模式(Clustermode),具体介绍如下。
(1)独立模式:又称为单机模式,在该模式下,无需运行任何守护进程,所有的
程序都在单个JVM上执行。
独立模式下调试Hadoop集群的MapReduce程序非常
方便,所以一般情况下,该模式在学习或者发阶段调试使用。
(2)伪分布式模式:Hadoop程序的守护进程运行在一台节上,通常使用伪分布
式模式用来调试Hadoop分布式程序的代码,以及程序执行否正确,伪分布式模式完全分布式模式的一个特例。
(3)完全分布式模式:Hadoop的守护进程分别运行在由多个主机搭建的集群上,不同节担任不同的角色,在实际工作应用发中,通常使用该模式构建级Hadoop系统。
在Hadoop环境中,所有器节仅划分为两种角色,分别master(主节,1个)和slave(从节,多个)。
因此,伪分布模式集群模式的特例,只将主节和从节合二
为一罢了。
接下来,本书将以前面的三台虚拟机为例,阐述完全分布模式Hadoop集群的与配置方法,具体集群规划如图1所示。
图1Hadoop集群规划
从图1可以看出,当前规划的Hadoop集群包含一台master节和两台slave节。
这里,将前面的Hadoop01作为Master节,Hadoop02和Hadoop03作为Slave
节。
1。
Hadoop集群配置心得(低配置集群+自动同步配置)

Hadoop集群配置⼼得(低配置集群+⾃动同步配置)本⽂为本⼈原创,⾸发到炼数成⾦。
情况是这样的,我没有⼀个⾮常强劲的电脑来搞出⼀个性能⾮常NB的服务器集群,相信很多⼈也跟我差不多,所以现在把我的低配置集群经验拿出来写⼀下好了。
我的配备:1)五六年前的赛扬单核处理器2G内存笔记本 2)公司给配的ThinkpadT420,i5双核处理器4G内存(可⽤内存只有3.4G,是因为装的是32位系统的缘故吧。
)就算是⽤公司配置的电脑,做出来三台1G内存的虚拟机也显然是不现实的。
企业笔记本运⾏的软件多啊,什么都不做空余内存也才不到3G。
所以呢,我的想法就是:⽤我⾃⼰的笔记本(简称PC1)做Master节点,⽤来跑Jobtracker,Namenode 和SecondaryNamenode;⽤公司的笔记本跑两个虚拟机(简称VM1和VM2),⽤来做Slave节点,跑Tasktracker和Datanode。
这么做的话,就需要让PC1,VM1和VM2处于同⼀个⽹段⾥,保证他们之间可以互相连通。
⽹络环境:我的两台电脑都是通过⼀个⽆线路由上⽹。
构建跟外部的电脑同⼀⽹段的虚拟机配置过程:准备⼯作:构建⼀个集群,⾸先前提条件是每台服务器都要有⼀个固定的IP地址,然后才可能进⾏后续的操作。
所以呢,先把我的两台笔记本电脑全部设置成固定IP(注意,如果像我⼀样使⽤⽆线路由上⽹,那就要把⽆线⽹卡的IP设置成固定IP)。
⽤来做Master节点的PC1:192.168.33.150,⽤来跑虚拟机的宿主笔记本:192.168.33.157。
⽬标:VM1和VM2的IP地址分别设置成192.168.33.151和152。
步骤:1)新建VM1虚拟机。
2)打开VM1的⽹卡设置界⾯,连接⽅式选Bridge。
(桥接)关于桥接的具体信息,可以百度⼀下。
我们需要知道的,就是⽤桥接的⽅式,可以让虚拟机通过本机的⽹关来上⽹,所以就可以跟本机处于同⼀个⽹段,互相之间可以进⾏通信。
《hadoop基础》课件——第三章 Hadoop集群的搭建及配置

19
Hadoop集群—文件监控
http://master:50070
20
Hadoop集群—文件监控
http://master:50070
21
Hadoop集群—文件监控
http://master:50070
22
Hadoop集群—任务监控
http://master:8088
23
Hadoop集群—日志监控
http://master:19888
24
Hadoop集群—问题 1.集群节点相关服务没有启动?
1. 检查对应机器防火墙状态; 2. 检查对应机器的时间是否与主节点同步;
25
Hadoop集群—问题
2.集群状态不一致,clusterID不一致? 1. 删除/data.dir配置的目录; 2. 重新执行hadoop格式化;
准备工作:
1.Linux操作系统搭建完好。 2.PC机、服务器、环境正常。 3.搭建Hadoop需要的软件包(hadoop-2.7.6、jdk1.8.0_171)。 4.搭建三台虚拟机。(master、node1、node2)
存储采用分布式文件系统 HDFS,而且,HDFS的名称 节点和数据节点位于不同机 器上。
2、vim编辑core-site.xml,修改以下配置: <property>
<name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/opt/soft/hadoop-2.7.6/tmp</value> </property> <property> <name>fs.trash.interval</name> <value>1440</value> </property>
Hadoop集群的搭建方法与步骤

Hadoop集群的搭建方法与步骤随着大数据时代的到来,Hadoop作为一种分布式计算框架,被广泛应用于数据处理和分析领域。
搭建一个高效稳定的Hadoop集群对于数据科学家和工程师来说至关重要。
本文将介绍Hadoop集群的搭建方法与步骤。
一、硬件准备在搭建Hadoop集群之前,首先要准备好适合的硬件设备。
Hadoop集群通常需要至少三台服务器,一台用于NameNode,两台用于DataNode。
每台服务器的配置应该具备足够的内存和存储空间,以及稳定的网络连接。
二、操作系统安装在选择操作系统时,通常推荐使用Linux发行版,如Ubuntu、CentOS等。
这些操作系统具有良好的稳定性和兼容性,并且有大量的Hadoop安装和配置文档可供参考。
安装操作系统后,确保所有服务器上的软件包都是最新的。
三、Java环境配置Hadoop是基于Java开发的,因此在搭建Hadoop集群之前,需要在所有服务器上配置Java环境。
下载最新版本的Java Development Kit(JDK),并按照官方文档的指引进行安装和配置。
确保JAVA_HOME环境变量已正确设置,并且可以在所有服务器上运行Java命令。
四、Hadoop安装与配置1. 下载Hadoop从Hadoop官方网站上下载最新的稳定版本,并将其解压到一个合适的目录下,例如/opt/hadoop。
2. 编辑配置文件进入Hadoop的安装目录,编辑conf目录下的hadoop-env.sh文件,设置JAVA_HOME环境变量为Java的安装路径。
然后,编辑core-site.xml文件,配置Hadoop的核心参数,如文件系统的默认URI和临时目录。
接下来,编辑hdfs-site.xml文件,配置Hadoop分布式文件系统(HDFS)的相关参数,如副本数量和数据块大小。
最后,编辑mapred-site.xml文件,配置MapReduce框架的相关参数,如任务调度器和本地任务运行模式。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
NameNode
NameNode 要记录 HDFS 中的元数据,即包括 文件名、权限、所有者、所有组、每个文件 对应的Block列表,以及每个Block的副本目前 存在于哪个机器上。这些信息会随着集群的 使用以及规模而增加。
– 双路四核CPU – DDR3内存 24G-36G – 双千兆以太网网卡 – 至少两块 1-2T的SATA 硬盘,JBOD配置
DataNode
DataNode是Hadoop集群中主要的工作节点,它承 担两种角色:一将数据存储在HDFS文件系统上; 二执行MapReduce任务。DataNode是Hadoop主要 的存储和计算资源。
• 4个磁盘驱动器(单盘1-2T,3.5寸,7200转),支 持JBOD • 2个4核CPU,至少2.5GHz • 16-24GB内存 • 千兆以太网
Hadoop简介
• HDFS采用Master/Slave架构,一个HDFS集群 由一个Namenode和一定数目的Datanodes组 成。Namenode是一个中心服务器,负责管 理文件系统的名字空间(Namespace)以及 客户端对文件的访问。集群中的Datanode 一般是一个节点一个,负责管理其所在节 点上的存储
Hadoop简介
• HDFS有如下基本特征 : • (1)对于整个集群有单一的命名空间。 (2)数据一致性 。适合一次写入多次读取 的模型。 • (3)文件会被分割成多个文件块,每个文 件块被分配存储到数据节点上,而且根据 配置会有 复制文件块来保证数据的安全性。
Hadoop集群模块逻辑结构
网络拓扑
目前数据概况
• 1、当前存储数据量
– Mysql库-------除去索引,日志数据在1T左右 – SQLServer-----? – 其他库-------?
• 2、数据增长
– 15~25G/天 – 20*30=600G左右/月 – 600*6=3.6T左右/半年 – 注:考虑到每月会产生一定量的数据增长
集群规模(存储和计算)
• Mysql库每天数据增长目前在20G左右 • 采用3备份存储 • 以半年时间为规划期
– 3.6*3T+预留存储等(20%-30%)-----15T
• 节点规模:1主3从节点
2.Hadoop版本
• 目前流行的Hadoop版本分三个大类
– Apache Hadoop – Cloudera Hadoop – Hortonworks Hadoop
2.Hadoop版本
• 综合考虑,先暂定选择目前绝大部分公司 在使用的版本,Cloudera CDH5.5.0免费版, 或者Apache Hadoop2.6.0版本
– 注:根据从网上和开源社区还有身边朋友了解 的信息,大部分都认为CDH的运维、管理、监 控及Hadoop相关组件,在使用方面有助于后期 的维护管理,CDH版本趋于稳定
网络拓扑
Hadoop简介
Hadoop简介
Hadoop-HA集群运作机制图
集群搭建需要考虑的几点问题
• 1.选择和规划Hadoop集群的硬件
• 2.Hadoop版本的选取 • 3.Hadoop集群操作系统的选择
1.Hadoop集群硬件
• 一个基本的Hadoop集群中的节点主要有: Namenode负责协调集群中的数据存储 • DataNode存储被拆分的数据块 • Jobtracker协调数据计算任务 • TaskTracker执行任务 • Secondarynamenode(2.2版本以后,实现 HA,有StandBy NameNode备用,与 NameNode配置一样),帮助NameNode收 集文件系统运行的状态信息。
• 先对CDH版本在虚拟机上进行安装测试
2.Hadoop版本
• Hadoop生态圈其他组件
– hadoop-2.6.0<====>cdh5.5.0 – hive-1.1.0 – hbase-solr-1.5 – impala2.3.0 – spark-1.5.0(后期再装) – hue3.9.0
3.操作系统
• 注:还有其他的版本在国内比较少见,只从以上三 个版本选择 • 另外国内比较普遍的是Apache和Cloudera的Hadoop 版本,从Hadoop开源社区得到各种问题解决方案比 较容易,暂不考虑Hortonworks Hadoop
2.Hadoop版本
• 选择版本的考虑主要有以下几个方面:
– 所需要的稳定程度 – 所需要的功能
• 三节点
• 生产环境
– 服务器部署
集群构建步骤
1、在DSP平台中,运用定时任务根据CTR算法每小时计算 一次每个广告位的CTR值存入竞价服务器,供RTB广告进 行实时竞价; 2、在DSP和SSP平台中,运用MapReduce从Kafka批量提取 上一小时的请求、响应、展示、点击广告日志数据,存入 规定好的目录结构,根据业务需要,用Hive,Shell脚本等 对广告数据进行分类汇总和分析,将处理后的数据存入业 务系统Mysql,供广告主和媒体主进行数据查询和展示; 3、在DSP平台中,从Kafka提取实时的广告数据,主要运 用SparkStreaming,实时统计和计算请求数、响应数、展 示数、点击数、点击率、胜出率、广告投放剩余金额,并 写入Redis,供广告主实时查询分析各自投放的广告情况; 4、每周统计一次每个广告尺寸占比,展示在DSP和SSP业 务系统,供运营人员进行分析和投放调整;
• Hadoop 的版本号是很混乱的,而且小分支很多。 就现在情况而言,可以总结为两大分支: • 0.20 ⇨ 1.x • 0.23 ⇨ 2.x
2.Hadoop版本
• 按照功能考虑: • • • • • • • • • Feature 0.20 0.23 HDFS append ✔ Kerberos ✔ HDFS symlink ✔ YARN (MRv2) ✔ MRv1 ✔ Namenode Federation✔ Namenode HA ✔ Spark 1.x ✔ ✔ ✔ ✔ ✔ ✔ ✔ 2.x ✔ ✔ ✔ ✔ CDH 3 ✔ ✔ ✔ ✔ CDH 4 ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✔ CDH 5 ✔ ✔ ✔ ✔ ✔ ✔ ✔ ✔
• 操作系统 • 目前国内企业服务器用的操作系统以Redhat Linux和CentOS为主 • 从免费角度,选CentOS(缺点:缺少技术支持) • 从付费角度,选Redhat Linux
– CentOS 6.5 – Java JDK 1.8
集群环境
• 测试环境
– 利用虚拟平台搭建测试环境
• VMware Worktation 10
离线分析
MySQL库 SQLServer库
sqoop
HDFS
MR Hive
实时查询
APPUser实时查询源自kafkaHDFS
Redis
Spark (or Storm)
• 搭建hadoop集群主要分为两种途径:
– 一种是公司购买服务器自己搭建
• 优点:便于对集群的管理和维护
– 另一种是使用现成的云平台服务
Hadoop集群规划
---初步方案
Hadoop简介
• Hadoop是 Apache 下的一个项目,它是一个 开源的可运行于大规模集群上的分布式并 行编程框架,由HDFS、MapReduce、HBase、 Hive和ZooKeeper等成员组成。其中,HDFS 和MapReduce 是两个最基础最重要的成员, 他们分别是Google GFS和MapReduce的开源 实现。HDFS是一个高度容错的分布式文件 系统,它能够提供高吞吐量的数据访问, 适合存储海量(PB级)的大小(通常超过 64M)
• 优点:不需要购买硬件,相当于租用云服务器 • 缺点:不便于后期的管理,无法接触服务器集群