基于K—means聚类的客户细分案例分析
客户价值评估 (2)

客户价值评估客户价值评估是一种通过分析客户的行为和需求,评估客户对企业的价值和潜在利润的方法。
它帮助企业了解客户的价值,为企业制定有效的市场营销策略和客户关系管理计划提供依据。
本文将详细介绍客户价值评估的步骤和方法,并提供相关数据和案例分析。
一、客户价值评估的步骤1. 收集客户数据:首先,企业需要收集客户的基本信息和购买行为数据。
可以通过客户调查、购买记录、社交媒体分析等方式获取客户数据。
2. 客户细分:根据客户的特征和行为将客户进行细分。
可以根据购买频率、购买金额、产品偏好等指标将客户分为不同的细分群体。
3. 评估客户价值指标:根据企业的业务目标和市场策略,选择合适的客户价值指标进行评估。
常用的客户价值指标包括客户生命周期价值(CLV)、购买频率、购买金额、客户满意度等。
4. 分析客户行为:通过分析客户的购买行为、产品偏好、投诉记录等数据,了解客户的需求和行为模式。
可以使用数据挖掘和统计分析等方法进行客户行为分析。
5. 评估客户潜在利润:根据客户的购买行为和潜在需求,评估客户的潜在利润。
可以通过交叉销售分析、客户细分分析等方法预测客户的购买潜力。
6. 制定市场营销策略:根据客户价值评估的结果,制定相应的市场营销策略。
可以针对高价值客户提供个性化的服务和优惠,提高客户满意度和忠诚度。
二、客户价值评估的方法1. 客户生命周期价值(CLV)方法:客户生命周期价值是评估客户对企业的长期价值的指标。
它基于客户的购买行为和消费模式,预测客户在未来一段时间内的价值。
可以使用统计模型和数据分析方法计算客户的生命周期价值。
2. RFM模型:RFM模型是一种常用的客户细分方法,通过客户的最近一次购买时间(Recency)、购买频率(Frequency)和购买金额(Monetary)三个指标对客户进行评估。
根据客户的RFM得分,可以将客户分为不同的细分群体,制定相应的市场营销策略。
3. K-means聚类分析:K-means聚类分析是一种无监督学习方法,通过将客户根据相似性进行聚类,发现潜在的客户群体。
R语言用K-mean进行聚类对用户细分

options(digits = 18) #小数可以显示到第18位lss_all_cust_ls_info <- read.table('E:\\Udacity\\Data Analysis High\\R\\R_Study\\高级课程代码\\数据head(lss_all_cust_ls_info)lss_cust_payment <- read.table('E:\\Udacity\\Data Analysis High\\R\\R_Study\\高级课程代码\\数据集\\ head(lss_cust_payment)lss_cust_spend_info <- read.table('E:\\Udacity\\Data Analysis High\\R\\R_Study\\高级课程代码\\数据集head(lss_cust_spend_info)#客户信息head(lss_all_cust_ls_info)str(lss_all_cust_ls_info)summary(lss_all_cust_ls_info)#支付信息head(lss_cust_payment)str(lss_cust_payment)summary(lss_cust_payment)#商品信息head(lss_cust_spend_info)str(lss_cust_spend_info)summary(lss_cust_spend_info)data_cat_wide = dcast(lss_cust_spend_info,cust_id~ls_category,value.var = "ls_spd_share")head(data_cat_wide)names(data_cat_wide)data_cat_wide = data_cat_wide[,-2]#dim(data_cat_wide)#summary(data_cat_wide)data_payment_wide = dcast(lss_cust_payment,cust_id~payment_category_desc,value.var = "payment_am head(data_payment_wide)#dim(data_payment_wide)### 3. join data##把三张表进行合并,通过cust_id来进行列合并cust_all = merge(lss_all_cust_ls_info,data_payment_wide, by="cust_id")cust_all_fnl = merge(cust_all,data_cat_wide, by="cust_id")## 查看合并后的结果head(cust_all_fnl,10)dim(cust_all_fnl)summary(cust_all_fnl)## 提取出客户ID和性别cust_id = cust_all_fnl[,1]cust_sex = cust_all_fnl[,2]## 去除客户ID和性别,同时将除了这两个列之外的缺失值填充0cust_all_fnl2 = cust_all_fnl[,-c(1,2)]cust_all_fnl2[is.na(cust_all_fnl2)] =0## 把性别缺失值变成1.5cust_sex [is.na(cust_sex )] =1.5##把处理后的数据合并cust_all_fnl = data.frame(cust_id,cust_sex,cust_all_fnl2)head(cust_all_fnl)#summary(cust_all_fnl)## 对于异常值进行处理,如果百分比小于0,则变成0,如果百分比大于1 则等于1dim(cust_all_fnl)for(i in 7:dim(cust_all_fnl)[2]){cust_all_fnl[,i][cust_all_fnl[,i]<0] = 0cust_all_fnl[,i][cust_all_fnl[,i]>1] = 1}dim(cust_all_fnl)## 去除礼品字段,因为0值较多,会给后期的聚类操作带来影响mydata = cust_all_fnl[,-28]dim(mydata)summary(mydata) 结论:生成一张所有属性的统计值,查看是否还有NA的值6.选择K值# 如果数据集中的变量过多,要先使用主成分分析找到影响因子在95%以上的列即可# 选择K使得差异最小,下降幅度最小comp = scale(mydata[,-1])wss <- (nrow(comp)-1)*sum(apply(comp,2,var))for (i in 2:15) wss[i] <- sum(kmeans(comp,centers=i)$withinss)plot(1:15, wss, type="b", xlab="Number of Clusters",ylab="Within groups sum of squares")7.使用K-media找到中心点的坐标# 如果数据量较大,首先应对数据进行抽样,然后在找中心点s = sample(1:dim(mydata)[1],2000,replace = F)clus = 4medk = pam(scale(mydata[s,-1]),clus,trace=T)plotcluster(scale(mydata[s,-1]),medk$clustering)table(medk$clustering)Kcenter = medk$medoids8.使用K-mean进行聚类# 每次抽取1000个点进行聚类k = kmeans(scale(mydata[,-1]),centers = Kcenter,nstart = 25,iter.max = 1000) plotcluster(scale(mydata),k$cluster)# 写入到csv文件write.csv(mydata_mean_sd,'E:\\Udacity\\Data Analysis High\\R\\R_Study\\高级课程代码\\数据集\\第一天\# 写入数据库data_sql <- data.frame(mydata, cluster=k$cluster)data_sql_out = data_sql[,c(1,dim(data_sql)[2])] 结论:通过生成的csv文件,我们可以得出如下结论: 通过tot_spend可以得出2,4组的顾客对超市的贡献度较大,其中2类客户是最应该保留的优质客户 通过promo_share可以得出4类客户对折扣较为敏感 通过wz_spend_share可以得出4类用户最喜欢参与打5折的活动 通过对比购物时间段来看1,2类用户喜欢晚上购物,3类用户喜欢下午的时候购物,4类用户喜欢早上购物 通过对比支付方式1,3,4组大部分是现金支付,2组客户喜欢用银行卡支付 通过对比消费商品可得出结论: 2类客户喜欢购买大家电,手机通讯设备,母婴食品的高价格产品 4类客户喜欢购买生鲜,蔬菜等农产品 1类客户喜欢购买一些零食,饮料之类的商品 3类客户是散客,会不定期的购买一些商品 针对1类客户,在下午的时间段可以对零食,饮料进行一些促销和活动 针对2类客户,在晚上的时间段,一些大商品的家电,手机等高价格的产品做一些捆绑销售,同时定期去推送一些新的手机,电器,母婴食品的信息,会有不错的销售业绩 针对4类客户,在早上对农产品,生鲜,肉类等商品可以进行一些打折,买一赠一的,兑换券等活动,提升生鲜商品的业绩 针对3类用户,不是超市的重点客户,暂时不知道如何提升到店率。
基于某百货商场销售数据的K-means聚类分析
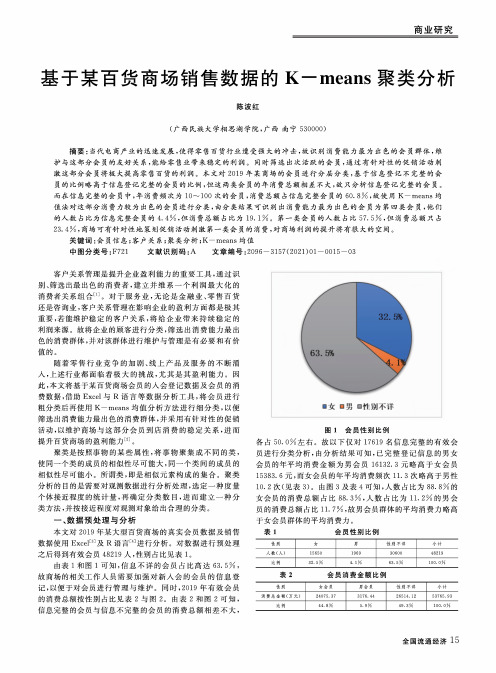
基于某百货商场销售数据的K—means聚类分析陈波红(广西民族大学相思湖学院,广西南宁530000)摘要:当代电商产业的迅速发展,使得零售百货行业遭受强大的冲击,故识别消费能力最为出色的会员群体,维护与这部分会员的友好关系,能给零售业带来稳定的利润。
同时筛选出次活跃的会员,通过有针对性的促销活动刺激这部分会员将极大提高零售百货的利润。
本文对2019年某商场的会员进行分层分类,基于信息登记不完整的会员的比例略高于信息登记完整的会员的比例,但这两类会员的年消费总额相差不大,故只分析信息登记完整的会员。
而在信息完整的会员中,年消费频次为10〜100次的会员,消费总额占信息完整会员的60.8%,故使用K-means均值法对这部分消费力较为出色的会员进行分类,由分类结果可识别出消费能力最为出色的会员为第四类会员,他们的人数占比为信息完整会员的4.4%,但消费总额占比为19.1%。
第一类会员的人数占比57.5%,但消费总额只占23.4%,商场可有针对性地策划促销活动刺激第一类会员的消费,对商场利润的提升将有很大的空间。
关键词:会员信息;客户关系;聚类分析;K-means均值中图分类号:F721文献识别码:A文章编号:2096-3157(2021)01-0015-03客户关系管理是提升企业盈利能力的重要工具,通过识别、筛选出最出色的消费者,建立并维系一个利润最大化的消费者关系组合旳。
对于服务业,无论是金融业、零售百货还是咨询业,客户关系管理在影响企业的盈利方面都是极其重要,若能维护稳定的客户关系,将给企业带来持续稳定的利润来源。
故将企业的顾客进行分类,筛选出消费能力最出色的消费群体,并对该群体进行维护与管理是有必要和有价值的。
随着零售行业竞争的加剧、线上产品及服务的不断涌入,上述行业都面临着极大的挑战,尤其是其盈利能力。
因此,本文将基于某百货商场会员的入会登记数据及会员的消费数据,借助Excel与R语言等数据分析工具,将会员进行粗分类后再使用K-means均值分析方法进行细分类,以便筛选出消费能力最出色的消费群体,并采用有针对性的促销活动,以维护商场与这部分会员到店消费的稳定关系,进而提升百货商场的盈利能力⑵。
聚类分析案例

聚类分析案例聚类分析是一种常见的数据分析方法,它能够将数据集中的观测值划分为若干个类别,使得同一类别内的观测值相似度较高,不同类别之间的观测值相似度较低。
聚类分析在市场细分、社交网络分析、医学图像分析等领域都有着广泛的应用。
本文将以一个实际的案例来介绍聚类分析的应用过程。
案例背景:某电商平台希望对其用户进行细分,以便更好地了解用户需求,精准推荐商品。
为此,他们收集了用户的浏览、购买、评价等行为数据,希望通过聚类分析将用户分成不同的群体。
数据准备:首先,我们需要对数据进行清洗和整理。
去除缺失值、异常值,对数据进行标准化处理,以便消除不同维度之间的量纲影响。
然后,我们可以利用主成分分析(PCA)等方法对数据进行降维,以便更好地展现数据的内在结构。
模型选择:在数据准备完成后,我们需要选择合适的聚类算法。
常见的聚类算法包括K均值聚类、层次聚类、密度聚类等。
在本案例中,我们选择了K均值聚类算法,因为该算法简单易实现,并且适用于大规模数据。
聚类分析:经过数据准备和模型选择后,我们开始进行聚类分析。
首先,我们需要确定聚类的数量K。
这里我们可以采用肘部法则、轮廓系数等方法来确定最佳的K值。
然后,我们利用K均值聚类算法对数据进行分组,得到每个用户所属的类别。
结果解释:得到聚类结果后,我们需要对每个类别进行解释和分析。
通过对每个类别的特征进行比较,我们可以揭示出不同类别用户的行为特点和偏好。
比如,某一类用户可能更倾向于购买高价值商品,而另一类用户更注重商品的品质和口碑。
应用建议:最后,我们可以根据聚类结果给出相应的应用建议。
比如,对于高价值用户群体,电商平台可以加大对其的推荐力度,提供更多的个性化服务;对于偏好品质和口碑的用户群体,可以加强品牌营销和口碑传播,以吸引更多类似用户。
总结:通过本案例的介绍,我们可以看到聚类分析在用户细分和个性化推荐方面的重要作用。
通过对用户行为数据的聚类分析,电商平台可以更好地了解用户需求,提供更精准的推荐服务,从而提升用户满意度和交易量。
somk-means聚类分区案例

somk-means聚类分区案例K-means聚类分区案例第一篇在数据分析领域,聚类是一种常用的无监督学习方法,能够将数据集中具有相似特征的数据样本划分为不同的类别或群组。
其中,K-means聚类是一种常见而有效的方法,它通过为每个数据样本分配一个与之最相似的聚类中心来实现分类。
在本文中,我们将介绍一个关于K-means聚类分区的案例。
将我们的案例定位于零售行业,想象一家超市的连锁店正计划在不同区域开设新的分店。
为了确定最佳的分店位置,他们决定利用K-means聚类算法对特定区域的顾客进行分析。
这样可以使他们对不同的市场细分,更好地了解各个区域的消费者需求和购物习惯。
通过这种方式,企业可以制定更有针对性的市场营销策略,提高销售额和市场份额。
首先,我们需要收集一些与消费者行为相关的数据。
这些数据可以包括每个顾客的购买记录、年龄、性别、消费金额等信息。
假设我们已经获得了一份包含500个顾客的数据集。
接下来,我们需要对数据进行预处理。
这包括去除异常值、处理缺失值以及数据标准化等步骤。
这些步骤旨在保证数据质量和可靠性,在分析过程中不会产生误导性的结果。
一旦数据预处理完成,我们可以开始使用K-means聚类算法。
该算法的基本思想是,通过计算每个数据样本与聚类中心的距离,将其归类到距离最近的聚类中心。
为了完成这个过程,我们首先需要确定聚类的数量K,也就是分店的数量。
为了确定最佳的K值,我们可以使用一种称为肘方法的技巧。
该方法基于聚类误差平方和(SSE),即聚类中心与其所包含数据样本距离的平方和,来评估聚类质量。
我们可以通过尝试不同的K值,计算相应的SSE,然后选择SSE曲线上的“肘点”作为最佳的K值。
在确定了最佳的K值之后,我们可以应用K-means算法进行聚类分析。
通过迭代更新聚类中心和重新分配样本,我们可以获取最终的聚类结果。
这些结果可以帮助我们理解不同区域顾客的消费行为和购物偏好。
最后,我们可以将聚类结果可视化,并提取有关每个聚类的关键特征。
利用KMeans聚类进行航空公司客户价值分析

利⽤KMeans聚类进⾏航空公司客户价值分析准确的客户分类的结果是企业优化营销资源的重要依据,本⽂利⽤了航空公司的部分数据,利⽤Kmeans聚类⽅法,对航空公司的客户进⾏了分类,来识别出不同的客户群体,从来发现有⽤的客户,从⽽对不同价值的客户类别提供个性化服务,指定相应的营销策略。
⼀、分析⽅法和过程1.数据抽取——>2.数据探索与预处理——>3。
建模与应⽤传统的识别客户价值应⽤最⼴泛的模型主要通过3个指标(最近消费时间间隔(Recency)、消费频率(Frequency)和消费⾦额(Monetary))来进⾏客户细分,识别出价值⾼的客户,简称RFC模型。
点击查看在RFC模型中,消费⾦额表⽰在⼀段时间内,客户购买产品的总⾦额。
但是不适⽤于航空公司的数据处理。
因此我们⽤客户在⼀段时间内的累计飞⾏⾥程M和客户在⼀定时间内乘坐舱位的折扣系数C代表消费⾦额。
再在模型中增加客户关系长度L,所以我们⽤LRFMC模型。
因此本次数据挖掘的主要步骤:1).从航空公司的数据源中进⾏选择性抽取与新增数据抽取分别形成历史数据和增量数据2).对步骤1)中形成的两个数据集进⾏数据探索分析和预处理,包括数据缺失值和异常值分析。
即数据属性的规约、清洗和变换3).利⽤步骤2)中的处理的数据进⾏建模,利⽤Python下Sklearn库中提供的KMeans⽅法,进⾏聚类4)。
针对模型的结果进⾏分析。
⼆。
数据处理1.下⾯是本次试验数据集的⼀部分截图,数据集抽取2012-4-1到2014-3-31内乘客的数据,⼀个62988条数据。
包括了会员卡号、⼊会时间、性别、年龄等44个属性。
2.数据探索分析:主要是对数据进⾏缺失值分析与异常值的分析。
通过发现原始数据中存在票价为空值,票价最⼩值为0,折扣率最⼩值为0、总飞⾏公⾥数⼤于0的记录。
其Python代码如下:def explore(datafile,exploreoutfile):"""进⾏数据的探索@Dylan:param data: 原始数据⽬录:return: 探索后的结果"""data=pd.read_csv(datafile,encoding='utf-8')explore=data.describe(percentiles=[],include='all').T####包含了对数据的基本描述,percentiles参数是指定计算多少分位数explore['null']=len(data)-explore['count'] ##⼿动计算空值数explore=explore[['null','max','min']]####选取其中的重要列explore.columns=['空值数','最⼤值','最⼩值']"""describe()函数⾃动计算的字段包括:count、unique、top、max、min、std、mean。
基于聚类分析的市场细分研究
基于聚类分析的市场细分研究一、前言市场细分研究是市场营销的重要内容之一,其核心是以不同特征的顾客为基础,对市场进行划分。
市场细分研究可以帮助企业更好地了解其目标顾客,并制定相应的市场营销策略。
在市场细分研究中,聚类分析是一种常用的方法。
二、聚类分析聚类分析是一种将相似对象归为一类的统计学方法。
在市场细分研究中,聚类分析可以将顾客按相似性进行分类,从而更好地了解不同市场细分的特征。
聚类分析是一种无监督学习方法,其主要分为两种类型:层次聚类和K-means聚类。
1. 层次聚类层次聚类分为聚合聚类和分裂聚类,聚合聚类是将不同的个体通过合并操作进行聚合,直到形成一个聚类为止;分裂聚类是将一个聚类逐步分解为多个较小的聚类。
2. K-means聚类K-means聚类是将数据分为K个不同的类别,具体流程为:从数据样本中随机选择K个数据点作为初始聚类中心,对于其他数据,根据其与聚类中心的距离进行分类,然后重新计算每个聚类的中心点,直到收敛为止。
三、基于聚类分析的市场细分研究市场细分研究可以通过聚类分析来实现。
聚类分析可以将顾客按照不同的特征进行划分,从而更好地了解顾客的需求和特点,为市场营销策略的制定提供支持。
市场细分研究的具体步骤如下:1. 收集数据:市场细分研究的第一步是收集顾客的相关数据,例如年龄、性别、教育程度、收入水平、购买习惯等。
2. 数据预处理:在聚类分析之前需要对数据进行预处理,例如对缺失数据进行填充,对异常数据进行处理等。
3. 特征选择:选择合适的特征是市场细分研究的关键,需要根据实际情况进行选择并进行统计学分析。
4. 聚类分析:利用聚类分析方法将顾客按不同特征划分为不同的类别,并对每个类别进行描述和解释。
5. 评估和选择:根据业务需求选择最佳的聚类方法,并评估和选择最佳的特征。
6. 分析结果:分析聚类结果,并根据分析结果制定相应的市场营销策略。
四、实例分析在市场细分研究中,聚类分析可以帮助企业更好地了解顾客的需求和特点,从而制定更有效的市场营销策略。
机器学习技术中的聚类算法应用案例
机器学习技术中的聚类算法应用案例聚类算法是机器学习领域中一种常用的无监督学习方法,它通过将数据集中的样本划分为具有相似特征的不同类别,实现数据的聚集和分类。
在机器学习中,聚类算法被广泛应用于数据挖掘、图像处理、自然语言处理等领域,具有重要的实际应用价值。
下面将介绍三个聚类算法的应用案例。
1. K-means算法在客户细分中的应用K-means是一种简单且易于实现的聚类算法,被广泛应用于数据挖掘和客户细分领域。
以电子商务为例,企业经常需要将客户进行分类,以便对不同类别的客户采取个性化的营销策略。
K-means算法可以通过分析客户的购买行为、兴趣偏好等特征,将客户划分为具有相似购买行为或兴趣偏好的不同群体。
企业可以根据不同群体的特点来实施针对性的推广和营销活动,提高客户转化率和满意度。
2. DBSCAN算法在异常检测中的应用DBSCAN是一种基于密度的聚类算法,它可以发现具有较高密度的样本,并将其视为聚类簇。
由于DBSCAN算法可以有效地处理噪声和异常值,因此在异常检测领域具有广泛的应用。
例如,在金融领域中,通过对银行交易数据进行聚类分析,可以发现存在异常交易行为的用户。
这些异常交易可以是欺诈行为,通过及时检测并采取措施,有助于保护用户利益和降低风险。
3. 层次聚类算法在文本聚类中的应用层次聚类是一种自底向上的聚类算法,通过将最相似的样本逐步归为一类,实现层次化的聚类结果。
这种算法特别适用于文本数据的聚类分析。
例如,在新闻分类中,层次聚类算法可以将相似主题的新闻文章归为一类,并进一步划分为更具体的子类别。
这种方式可以帮助用户快速获取感兴趣的新闻内容,提高新闻推荐系统的准确性和个性化程度。
总结起来,聚类算法在机器学习中有着广泛的应用。
无论是客户细分、异常检测还是文本聚类,聚类算法都可以帮助我们从大量的数据中发现有用的模式和结构,为实际问题的解决提供支持。
随着机器学习技术的不断发展,我们相信聚类算法在更多领域中的应用将能够带来更多的创新和价值。
kmeans算法一维例题
kmeans算法一维例题K-means算法一维例题K-means算法是一种常用的聚类算法,它通过将n个数据对象划分为k个不同的组或簇,使得每个对象在同一簇内的相似度最大化,而在不同簇之间的相似度最小化。
本文将通过一个一维数据的例题来探讨K-means算法的应用。
假设我们有以下一维数据集合:[5, 6, 9, 10, 14, 15, 18, 21, 23, 25]。
我们的目标是将这些数据划分为3个不同的簇。
首先,我们需要选择3个初始的簇中心点,可以是随机选择或者根据经验选择。
在本例中,我们选择簇中心点分别为6、15和23。
接下来,我们将每个数据点与这些簇中心点进行比较,并将其分配到最近的簇中。
第一次迭代后,我们得到了以下的划分结果:簇1:[5, 6, 9, 10]簇2:[14, 15, 18]簇3:[21, 23, 25]然后,我们需要重新计算每个簇的中心点。
在本例中,我们可以计算得到新的簇中心点为7.5、15.7和23。
接着,我们再次将每个数据点与新的簇中心点进行比较,并重新将其分配到最近的簇中。
第二次迭代后,我们得到了以下的划分结果:簇1:[5, 6, 9, 10]簇2:[14, 15, 18]簇3:[21, 23, 25]再次计算每个簇的中心点,我们可以得到新的簇中心点为7.5、15.7和23。
由于没有数据点发生改变,算法收敛并达到了停止的条件。
最终的聚类结果为:簇1:[5, 6, 9, 10]簇2:[14, 15, 18]簇3:[21, 23, 25]在本例中,K-means算法成功地将一维数据划分为3个不同的簇。
这个例题展示了K-means算法的基本步骤和流程。
通过多次迭代,算法不断优化簇中心点的位置,直到收敛为止。
需要注意的是,K-means算法对于初始簇中心点的选择是敏感的,不同的初始选择可能导致不同的聚类结果。
因此,在实际应用中,需要通过多次尝试来选择最优的初始簇中心点,或者采用其他改进的K-means变种算法。
聚类算法在客户细分中的实践应用是什么
聚类算法在客户细分中的实践应用是什么在当今竞争激烈的商业环境中,企业越来越重视客户关系管理,以实现精准营销、提高客户满意度和忠诚度。
而客户细分作为客户关系管理的重要环节,能够帮助企业更好地理解客户需求和行为特征,从而制定更有针对性的营销策略。
聚类算法作为一种有效的数据分析工具,在客户细分中发挥着重要作用。
一、聚类算法简介聚类算法是一种无监督学习算法,它的目的是将数据集中相似的数据点归为一类,不同类的数据点之间具有较大的差异。
聚类算法不需要事先知道数据的类别标签,而是通过数据的内在特征和相似性自动进行分类。
常见的聚类算法包括 KMeans 算法、层次聚类算法、密度聚类算法等。
KMeans 算法是一种基于距离的聚类算法,它通过不断迭代计算每个数据点到各个聚类中心的距离,将数据点分配到距离最近的聚类中心所属的类中,然后重新计算聚类中心,直到聚类结果收敛。
层次聚类算法则是通过构建聚类树的方式进行聚类,它可以分为自下而上的凝聚层次聚类和自上而下的分裂层次聚类。
密度聚类算法则是根据数据点的密度来进行聚类,能够发现任意形状的聚类。
二、客户细分的重要性客户细分是指将客户按照某些特征或行为模式划分为不同的群体。
通过客户细分,企业可以更好地了解客户的需求和偏好,从而为不同细分群体提供个性化的产品和服务。
这有助于提高客户满意度和忠诚度,增加客户的购买频率和消费金额,进而提升企业的市场竞争力和盈利能力。
例如,对于一家电商企业来说,如果能够将客户细分为价格敏感型客户、品质追求型客户和时尚潮流型客户等不同群体,就可以针对每个群体的特点制定相应的营销策略。
对于价格敏感型客户,可以提供更多的优惠活动和折扣;对于品质追求型客户,可以强调产品的质量和品牌形象;对于时尚潮流型客户,可以及时推出最新的时尚款式和流行元素。
三、聚类算法在客户细分中的应用步骤1、数据收集和预处理首先,需要收集与客户相关的数据,如客户的基本信息、购买记录、浏览行为、投诉反馈等。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
基于K—means聚类的客户细分案例分析
作者:蔡巧宇
来源:《商情》2015年第10期
【摘要】当今流行的客户细分理论的视角主要关注在消费市场的细分上,现有的客户细分理论中根据客户购买的产品特征进行细分的分析和研究相对较少,因此本文的研究就是把某品牌鞋子的风格特征作为细分变量,基于某企业的销售数据来进行分析,选择K-means聚类分析方法结合企业的实际情况,划分出不同的客户群,企业可以根据不同客户群的需求和对企业的贡献制定不同的宣传营销策略,降低企业的销售成本,提高企业的竞争力。
【关键词】客户细分 K-means聚类案例分析营销策略
一、案例介绍
某公司是一个以鞋类的研发制造及品牌管理为主的时尚集团公司,业务遍及大中华区(中国大陆、香港、台湾)、亚洲、欧洲及北美洲,是中国最成功的国内品牌之一。
该公司在中国经营的组织架构为:总公司——分公司——专卖店。
其中,总公司负责拓展策略和公司年度工作计划的制定,以及成本控制和分公司事务管理。
分公司负责执行总公司的战略,对专卖店、专卖店人员实施管理,工作内容包括:新开专卖店寻址、申请开店、签约、开店;对分公司人员管理、分公司销售指标达成、执行总公司促销活动等。
二、数据处理
(一)数据准备
原始数据包括两张表:客户交易记录表和鞋子具体属性表,其中客户交易记录表与鞋子属性表连接的变量是鞋子ID,交易记录数据的时间是过去一年2013年9月1日到2014年9月1日。
(二)数据清洗
该企业一年的交易记录有几千万条,所以原始的交易数据量非常大,这样就很容易出现噪声数据、空缺数据和不一致数据,所以必须要经过一系列的分析与处理,包括对缺失值的处理和异常值的处理,例如:去除客户属性为空的客户记录、剔除消费额和消费次数不在正常范围内的客户记录等。
(1)剔除异常的正负交易。
从客户交易记录表中选出过去一年交易ID不为空的正常交易记录,交易记录表中的金额有正负之分,正表示购买记录,负表示退货记录,要剔除掉没有正交易与之对应的退货记录。
(2)剔除异常的购买数量和金额。
由于有些客户不是会员,专卖店的销售员会帮客户刷自己的会员卡,这样就会出现一个会员ID在一段时间内交易数量和交易金额超出正常范围。
本文用3δ准则剔除不在正常范围内异常客户。
(三)数据转换和整合
清洗后的数据是不能直接用来进行客户细分,需要对变量进行转换。
(1)按照消费金额给每个客户打标签。
先计算每个客户在一年内消费的总金额MON,再结合企业的实际情况,在价值方面给每个客户打标签。
(2)选出有重复购买行为的客户,只有一次购买的客户多为一次性客户,本文不对其进行细分。
(3)连接交易记录表和鞋的属性表。
按照鞋子的ID匹配,把鞋子的具体属性整合到客户的交易记录表中。
(4)根据客户购买时间定义大促和非大促,根据购买价格和上市价的比值,定义新品期和清仓期。
(5)把原来作为具体值出现的标签转换为变量,作为客户对该属性的偏好进入细分模型。
(6)把细分变量、消费金额和价值变量整合到一张宽表中,由于[其他类]比较宽泛的鞋类占比较少,而且进入细分的意义也不大,故本文将其剔除。
(7)计算各变量的相关系数。
除了[女鞋]和[童鞋]的相关系数为-0.7,[大促]和[非大促]的相关系数为-0.93外较高外,其他变量之间的相关系数都较小。
由于该品牌鞋子的客户群多为女性,把[女鞋]作为细分变量的代表性较差,故剔除[女鞋]保留[童鞋];考虑到变量的重要性,[大促]较为重要,故剔除[非大促]保留[大促]。
最终进入细分模型的变量为27个。
三、客户细分过程
把SQL里整理好的变量建立一张表导入到R里进行聚类分析,由于K-means聚类方法要求提前设定聚的类数,本文从聚为5类到12类全部运行一遍把运行结果导入到SQL里与客户
ID连接,分别计算各类客户群每个变量的均值以及普通会员、潜力会员、高价值会员和VIP 的占比。
结合实际情况和分类特征要明显的原则,本文最终将客户细分为9类,为了方便分析将变量值进行一下转换,即将每一个变量值除以变量的均值再乘以100。
四、客户细分结果分析
第一类,高端会员,该类会员客单价最高,对促销不敏感,偏爱基本款半皮材质单鞋,客单价662,人数占比9%,销售占比12%;第二类,时尚追求者,在新品初期购买时尚款毛绒高跟靴,销售占比14%,82%为高价值会员和VIP;第三类,凉鞋爱好者,多在清仓期购买舒软凉鞋,喜欢非皮材质,VIP会员和高价值会员占比都最少,分别为7%和27%;第四类,铆钉链条控,偏爱铆钉链条以及毛绒风格,对其他都不太敏感,13%的客户群以及11%的销售额,各价值类人群分布较均匀;第五类,促销空,多在大促期间购买高跟鞋;第六类,超值学生妈妈族,喜欢超值款,多在大促期间购买童鞋和男鞋,客单价600较高,人数占比和销售占比都最高。
第七类,俏丽优雅,喜欢中跟经典款,对男鞋和童鞋及其不敏感,客单价365最少,销售占比6%也最少。
第八类,真皮靴子控,喜欢核心款和基本款,多在新品初期购买妈妈风格的真皮靴子,人数占比8%最少,近90%的VIP和高价值会员;第九类,贤惠妈妈群,购买超值款低跟休闲的童鞋和男鞋,VIP和高价值人群较少。
通过上面的分析,可以看出,第六类和第九类的客户群相似度较大,本文考虑合并第六类和第九类。
五、营销对策
由于某些原因的限制,本文提出的营销策略仅限于发送手机短信和EDM邮件。
针对第一类对促销不敏感高端会员,可以在节假日之外的时间发送价格较高的应季单鞋;第二类时尚追求者的客户群,喜欢买靴子,可以在冬季向VIP和高价值会员发送新品靴子的信息;第三类凉鞋爱好者,多为普通会员和潜力会员,在夏末清仓凉鞋的时候发送信息较为合适;第四类和第五类客户群目标性不太强,可以有选择性的分别发送畅销的铆钉链条风格的鞋子和各类高跟鞋促销信息;合并后的第六类和第九类客户是一个很大的群体,多为已婚妈妈为自己、丈夫和孩子购买鞋子,可以针对潜力会员发送超值款的男鞋或童鞋信息;第七类优雅俏丽一族,客单价较低,可以向高价值会员发送相应风格的经典款中跟鞋子,以提高客单价;第八类真皮靴子控,人数最少,但价值最高,需重点关注,在真皮靴新品首发的第一时间发送信息。