a CRAY T3E parallel system
高性能计算机和曙光集群系统

• Cluster
– 每个节点都是一个完整的计算 机
– 各个节点通过高性能网络相互 连接
– 网络接口和I/O总线松耦合连 接
– 每个节点有完整的操作系统 – 曙光2000、 3000、4000,
ASCI Blue Mountain
UMA: NUMA:
访存模型
NORMA:
多处理机(单地址空间共享存储器) UMA: Uniform Memory Access NUMA: Nonuniform Memory Access
高性能计算机系统架构
➢ 并行向量机 ➢ SMP ➢ DSM(NUMA) ➢ MPP,节点可以是单处理器的节点,也可以是SMP,
DSM ➢ Cluster ➢ Constellation
高性能计算机的制造厂商
➢ Cray ➢ SGI ➢ IBM
➢ 曙光 ➢ 银河 ➢ 神威
并行计算机系统类型
➢ Flynn分类:
现代高性能计算机都属于MIMD。MIMD从结构上和访 存方式上,又可以分为:
– 结构模型:PVP, SMP, MPP, DSM, COW – 访存模型:UMA, NUMA, COMA, CC-NUMA, NORMA结构模型对称多处理机系统(SMP)
• SMP
– 对称式共享存储:任意处理器 可直接访问任意内存地址,且 访问延迟、带宽、机率都是等 价的; 系统是对称的;
并行可扩展科学计算工具箱PETSc简介与应用

PETSc简介莫则尧(北京应用物理与计算数学研究所)一、PETSc的起源与现状二、PETSc的成功应用典范三、PETSc的体系结构四、PETSc的核心组件五、PETSc程序示例六、PETSc的具体应用与比较七、PETSc的优点与缺陷一、PETSc的起源与现状1.全称:●并行可扩展科学计算工具箱●Parallel Extensible Toolkits for Scientific Computing●/petsc2.起源:●美国能源部ODE2000支持的20多个ACTS(AdvanvedComputing Test & Simulation program, 美国能源部超级计算中心/)工具箱之一,其中包括:⏹能提供算法的工具:Aztec :分布式存储并行机求解大规模稀疏线性代数系统库;Hypre :线性系统求解预条件库;Opt++ :串行非线性优化问题数值库;PETSc :并行可扩展科学计算工具箱,提供大量面向对象的并行代数数据结构、解法器和相关辅助部件,适合并行可扩展求解PDE方程(有限差分、有限元、有限体离散的隐式和显示格式);PVODE :并行常微分方程求解库;ScaLAPACK :SuperLU :代数系统直接求解库;⏹算法开发辅助工具:Global Arrays :以共享存储并行程序设计风格简化分布存储并行机上程序设计;Overture :网格生成辅助工具;POET :并行面向对象环境与工具箱;POOMA :并行面向对象方法与应用,提供大量适合有限差分和粒子类模拟方法的数据并行程序设计(HPF)的C++类;⏹运行调试与支持工具:CUMULVS,Globus,PAWS,SILOON,TAU,Tulip;⏹软件开发工具:ATLAS & PHiPAC :针对当代计算机体系结构的高性能特征,自动产生优化的数值软件,可与手工调试的BLAS库相比较(?);Nexus , PADRE, PETE;3.现状●时间:1995年—现在;●目前版本:PETSc-2.0.28 + patch,源代码公开(不包含用户自己加入的核心计算子程序);●核心人员:数学与计算机部,Argonne国家重点实验室,Satish Balay, William Gropp, Lois C.McInnes, Barry Smith;●参研人员:相关访问学者(几十人次,不同组件实现);●可移植性:CRAY T3D,T3E,Origin 2000, IBM SP, HPUX, ASCI Red, Blue Mountain, NOWs,LINUX,ALPHA等;●目前,已下载上百套;二、PETSc的成功应用典范1.PETSc-FUN3D:●参考:W.K.Anderson etc., Achieving high sustainedperformance in an unstructured mesh CFD applications,SC’99. ()●FUN3D:四面体三维无结构网格离散、求解可压或不可压Euler和Navire-Stokes方程、串行程序、百万量级的非结构网格点,NASA Langley 研究中心W.K.Anderson开发,适合飞行器、汽车和水下工具的设计优化;●核心算法:非线性方程拟时间步逼近定常解、隐格式离散、Newton线性化、Krylov子空间迭代算法、加性Schwarz预条件(每个子区域近似精确求解),具有很好的数值可扩展性(即非线性迭代次数不随处理机个数的增加而显著增加);●移植周期:五个月(初步1996.10—1997.3),包括熟悉FUN3D与网格预处理器、学习ParMetis无结构网格剖分工具并集成到PETSc中、加入和测试PETSc的新功能、优化FUN3D面向向量机的代码段到面向cache的代码段、PETSc移植(非常少的时间,小于20天),并行I/O与后处理阶段还没完成;●并行性能:⏹代码行从14400减少为3300行(77%),包含I/O;⏹优化后,串行程序发挥各微处理器峰值性能的78%-26%;(附页1)⏹ONERA M6 Wing, 2.8百万个网格单元(11百万个未知量),512—3072个ASCI Red 节点(双PentiumPro 333MHz,每节点一个进程),保持95%以上的并行效率,发挥峰值性能的22.48%;(附页2)⏹其他并行机:CRAY T3E、Origin 2000、IBM SP;●奖励:SC’99 Gordon Bell最佳应用奖;2.石油:21世纪新一代油藏数值模拟框架;(USA Texas 大学油藏数值模拟中心)3.空气动力学数值模拟中多模型多区域耦合流场问题:(USA 自然科学交叉学科重点项目);4.天体物理中恒星热核爆炸问题数值模拟;(USA Chicago大学)三、PETSc 的体系结构PETSc 层次四、PETSc的核心组件1.程序设计技术●面向对象程序设计风格+ 标准C语言实现;●标准C语言(C++)和FORTRAN语言接口;●强调以面向对象的数据结构为中心设计数值库软件,并组织科学数值计算程序的开发;●PETSc应用:a)根据应用需求,通过调用PETSc子程序建立数据结构(如向量、规则网格阵列、矩阵等);b)调用PETSc各功能部件(如索引、排序、基于规则网格的拟边界数据分布与收集、线性解法器、非线性解法器、常微分方程解法器、简单的图形输出等)的子程序来对数据对象进行处理,从而获取PETSc提供的科学计算功能;2.核心组件(component ,class):●向量(Vectors):创建、复制和释放指定长度和自由度的串行或MPI并行向量(数据段被自动分配到不同的进程);向量操作:元素的赋值与索引、类似于BLAS的向量运算、向量的可视化显示等;●索引与排序(Index Sets,Ordering):向量和矩阵元素的局部与全局、自然与多色序号的对应关系;建立和释放任意两个集合的元素之间的对应和映射关系;适合无结构网格在进程间的的任意网格剖分,以及通过数据映射操作,完成相应无规则网格拟边界数据交换的消息传递;●分布阵列(DA:Distributed Array):建立在规则网格之上,一维、二维和三维(i=1,...,L, j=1,...,N, k=1,...,N),自动或指定阵列在进程间的区域划分,并沿拟边界设置宽度任意(离散格式需求)的影象(ghost)数组,存储邻近进程在相应位置包含的网格点的数值;阵列元素可包含多个自由度,且可以任意索引和访问,属于向量的一种特殊情形,多有向量操作均适合于它;数值计算中应用最为广泛的数据结构;局部序和全局序可以索引和映射;●矩阵(Matrices):指定维数和自由度大小的串行和MPI并行矩阵的生成、复制和释放;矩阵元素的索引与访问;稀疏矩阵压缩存储格式:AIJ稀疏行、BAIJ块稀疏行、Bdiag块对角;稠密矩阵;类似BLAS的基本矩阵操作,以及矩阵元素的标准或可视化输出;矩阵的隐式形成与使用;基于无结构网格划分工具(ParMetis)的并行矩阵的形成与使用;●线性代数方程解法器(SLES):基于稀疏矩阵与向量数据结构;SLES的建立、访问、设置和释放;目前实现的解法器:Krylov子空间方法(GMRES、CG、CGS、BiCGSTAB、TFQMR、Richardson、Chebychev),预条件(Additive Schwarz、Block Jacobi(ILU)、Jacobi、serial ILU、serial ICC、serial LU);收敛性测试与监控(实时图形显示迭代误差下降趋势);●非线性代数方程与无约束优化方程解法器(SNES):基于稀疏矩阵、向量和SLES数据结构;SNES的建立、访问、设置和释放;Newton线性化:line serach、trust region;收敛性测试与监控(实时图形显示迭代误差下降趋势);●PDE或ODE时间依赖方程解法器(TS):基于稀疏矩阵、向量、SLES和SNES数据结构;TS的建立、访问、设置和释放;方法:Euler、Backward Euler、拟时间步逼近定常解等;●对象的打印、图形和可视化输出:●选项数据库支持:对所有用户指定的算法和功能部件的性能监控,可在MPI程序运行时由命令行参数输入,非常方便;mpirun –np 4 example -ksp_type bcgs –ksp_xmonitor并行性能自动统计、输出(—log_summary);用户自定义选项(如网格规模、进程个数、图形可视化输出等);3.与其他库软件的功能互用与接口:●BlockSolve95(并行ICC(0)、ILU(0)预条件);●ESSL(IBM 快速稀疏矩阵LU分解);●Matlab(数据的图形和数值后处理);●ParMeTis(并行无结构网格图剖分);●PVODE(并行常微分积分);●SPAI(并行稀疏近似逆预条件);●SAMRAI,Overture(并行网格管理软件包);五、PETSc示例1.例一:(petsc-2.0.28/src/sles/examples/tutorial/ex2f.F)! 求解二维规则区域上Dirichlet问题,其中调用PETSc的SLES部件求解!有限叉分离散所得的稀疏线性代数方程组。
生物化学笔记英文
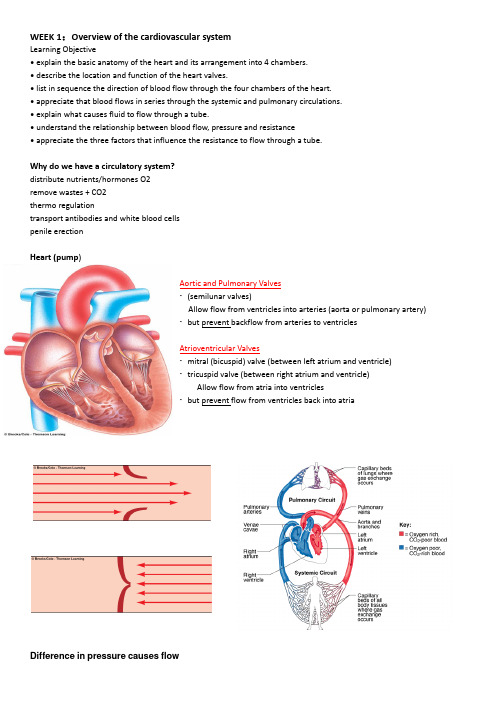
WEEK 1:Overview of the cardiovascular systemLearning Objective• explain the basic anatomy of the heart and its arrangement into 4 chambers.• describe the location and function of the heart valves.• list in sequence the direction of blood flow through the four chambers of the heart.• appreciate that blood flows in series through the systemic and pulmonary circulations.• explain what causes fluid to flow through a tube.• understand the relationship between blood flow, pressure and resistance• appreci ate the three factors that influence the resistance to flow through a tube.Why do we have a circulatory system?distribute nutrients/hormones O2remove wastes + CO2thermo regulationtransport antibodies and white blood cellspenile erectionHeart (pump)Aortic and Pulmonary Valves∙(semilunar valves)Allow flow from ventricles into arteries (aorta or pulmonary artery)∙but prevent backflow from arteries to ventriclesAtrioventricular Valves∙mitral (bicuspid) valve (between left atrium and ventricle)∙tricuspid valve (between right atrium and ventricle)Allow flow from atria into ventricles∙but prevent flow from ventricles back into atriaDifference in pressure causes flowFlow is always from region of high pressure toregion of lower pressureIt is the DIFFERENCE in pressure that is important,not the absolute pressure.Flow is proportional to the pressure difference(F P)Directly proportional if flow is laminar.What is the main anatomical difference between the femoral artery andthe popliteal artery?Which artery has the higher peripheral resistance (PR)?What do you think is the relationship between artery lengthandperipheral resistance (to blood flow)?Changing the radius alters the resistance to flowFlow through a vessel increases in proportion to the fourth power of the radius of the vessel (Poiseuille’s law).Viscosity = blood is thicker than water% volume of blood occupied by red blood cellsHaematocrit = 45% in men= 42% in womenMen have a slightly higher oxygen carrying capacity of their blood (more haemoglobin)Athletes sometimes artificially elevate their haematocrit (e.g. with synthetic erythropoietin/EPO or via blood doping). What effect will this have on viscosity and blood flow in arterioles supplying the leg?Why are athletes so tempted by ‘blood doping’?Blood viscosity is largely determined by haematocrit:Haematocrit is usually maintained relatively constant:- can be abnormally low in anaemia- abnormally high with severe dehydration or synthetic erythropoietin (EPO/blood doping)3 factors determine resistance to flow:∙the length of the tube:∙the radius of the tube:∙the viscosity of the fluid:BASIC FLOW EQUATION: F = delta PRQ1 Under control conditions, flow through a blood vessel is 100 ml/min under apressure gradient of 50 mm Hg. What would be the approximate flow through thevessel after increasing the vessel radius to four times normal, assuming the pressuregradient was maintained at 50 mm Hg?(a) 300 ml/min(b) 1600 ml/min(c) 1000 ml/min(d) 16,000 ml/min(e) 25,600 ml/minQ2 Which blood vessel has the highest vascular resistance (A, B, C, D or E)?Blood flow (ml/min) Pressure gradient (mmA 1000 100C 1400 20D 1600 80E 1800 40Q3 Blood flows in continuous loop through the systemic & pulmonary circulations (blood flow equal) MAP pulmonary ~15 mmHgMAP systemic ~95 mmHgWhy the same flow but different driving pr essures?WEEK 2 & 3 Excitation of the heartREFERENCES:Vander (Human Physiology, 13th edition) = see page references throughout lecture notesPracs/simulation = Practical 2: Human Cardiovascular Function’; simulations(MOODLE) = Heart conduction.Learning objective• descri be the conducting system of the heart and how electrical activity spreads from the sino-atrial node to the rest of the heart.• describe the main ionic movements during a ventricular action potential.• explain how sino-atrial node pacemaker cells spontaneously generate action potentials.• describe the 3 phases of the ECG, including how they relate to excitation of the heart and the cardiac action potentials • describe some common cardiac arrhythmias• explain why the sino-atrial node acts as the normal pacemaker of the heart.• explain how sino-atrial node pacemaking (i.e. heart rate) is regulated by the autonomic nervous system.Heart rate ↑ during exercise∙HR ↑ in linear fashion to increase O2 delivery to active muscle.∙Exercise training ↓ resting HR. Trained athletes: resting HR as low as 40 beats/min.∙Maximum HR not altered (↓ with age).∙Return of HR to normal post exercise is indicative of aerobic fitnessExcitation (action potential) is essential for cardiac contraction:Electrical conduction: cardiac myocytes connected via gap junctionsExcitation of the heart:Excitation originates in the sinoatrial node→internodal pathways in the atria→atrioventricular node(slowed conduction ~0.05 m/s)→Bundle of His (two branches)→Purkinje fibres (rapid conduction ~3 - 5 m/s)Slow conduction through the atrio-ventricular node, WHY?Cardiac action potentials cause the excitation of the heart:Voltage difference across the cell membrane =membrane potentialVentricular action potential= stable resting membranepotential, plateau phasePacemaker action potential = no stable resting potential(pacemaker potential), less negative maximum diastolicpotential (MDP)Ionic mechanisms underlying the ventricular action potentialVentricular resting membrane potential:EXTRACELLULAR FLUID INTRACELLULAR FLUID[Na+]e 145 mM [Na+]i 15 mM[Ca2+]e 2 mM [Ca2+]i 0.0001 mM[K+]e 5 mM [K+]i 150 mMVentricular action potential (depolarization)Depolarization= opens ‘fast’ voltage-sensitive Na+ channelsDepolarization & plateau= ‘slow’ voltage-sensitive Ca2+ channelsRepolarization = voltage-sensitive K+ channelsIonic mechanisms underlying the spontaneous sino-atrial node (pacemaker) action potential:The puffer fish contains tetrodotoxin (TTX) = selective inhibitor of fast Na+ channelsTTX does nothing to cardiac pacemaker action potentials!What is the pacemaker (or funny) current?Called the ‘f’ for funny or ‘h’ for hyperpolarization current.Inward flux of Na+.The slope of the pacemaker potential determines heart rate.Sino-atrial node (pacemaker) action potential:- Inward Na+ and Ca2+- Gradual decrease in outward K+The electrocardiogram (ECG):∙ A record of the heart’s electrical activity, recorded from the surface of the body.∙As excitation sweeps over the heart at any instant some parts of the heart will be positively charged while other parts are negatively charged.∙This causes currents to flow in the medium surrounding the heart.∙Because the body is a very good conductor these small currents can be detected at the body surface.∙The ECG is a recording of these small currents and reflects the depolarisation and repolarisation of different regions ofthe heart.The ECG used as clinical diagnostic tool:Used by cardiologists to determine:(1) the anatomical orientation of the heart and the relative sizes of its chambers(2) disturbances in cardiac rhythm and conduction(3) the extent and location of ischaemic damage to the myocardium(4) the effects of drugs or abnormal concentrations of various plasma electrolytes on the hear。
剑桥8真题阅读解析

剑桥雅思8-第三套试题-阅读部分-PASSAGE 1-阅读真题原文部分:READING PASSAGE 1You should spend about 20 minutes on Questions 1-13 which are based on Reading Passage 1 below.Striking Back at Lightning With LasersSeldom is the weather more dramatic than when thunderstorms strike. Their electrical fury inflicts death or serious injury on around 500 people each year in the United States alone. As the clouds roll in, a leisurely round of golf can become a terrifying dice with death - out in the open, a lone golfer may be a lightning bolt's most inviting target. And there is damage to property too. Lightning damage costs American power companies more than $100 million a year.But researchers in the United States and Japan are planning to hit back. Already in laboratory trials they have tested strategies for neutralising the power of thunderstorms, and this winter they will brave real storms, equipped with an armoury of lasers that they will be pointing towards the heavens to discharge thunderclouds before lightning can strike.The idea of forcing storm clouds to discharge their lightning on command is not new. In the early 1960s, researchers tried firing rockets trailing wires into thunderclouds to set up an easy discharge path for the huge electric charges that these clouds generate. The technique survives to this day at a test site in Florida run by the University of Florida, with support from the Electrical Power Research Institute (EPRI), based in California. EPRI, which is funded by powercompanies, is looking at ways to protect the United States' power grid from lightning strikes. 'We can cause the lightning to strike where we want it to using rockets, ' says Ralph Bernstein, manager of lightning projects at EPRI. The rocket site is providing precise measurements of lightning voltages and allowing engineers to check how electrical equipment bears up.Bad behaviourBut while rockets are fine for research, they cannot provide the protection from lightning strikes that everyone is looking for. The rockets cost around $1, 200 each, can only be fired at a limited frequency and their failure rate is about 40 per cent. And even when they do trigger lightning, things still do not always go according to plan. 'Lightning is not perfectly well behaved, ' says Bernstein. 'Occasionally, it will take a branch and go someplace it wasn't supposed to go. 'And anyway, who would want to fire streams of rockets in a populated area? 'What goes up must come down, ' points out Jean-Claude Diels of the University of New Mexico. Diels is leading a project, which is backed by EPRI, to try to use lasers to discharge lightning safely - and safety is a basic requirement since no one wants to put themselves or their expensive equipment at risk. With around $500, 000 invested so far, a promising system is just emerging from the laboratory.The idea began some 20 years ago, when high-powered lasers were revealing their ability to extract electrons out of atoms and create ions. If a laser could generate a line of ionisation in the air all the way up to a storm cloud, this conducting path could be used to guide lightning to Earth, before the electric field becomes strong enough to break down the air in an uncontrollable surge. To stop the laser itself being struck, it would not be pointed straight at theclouds. Instead it would be directed at a mirror, and from there into the sky. The mirror would be protected by placing lightning conductors close by. Ideally, the cloud-zapper (gun)would be cheap enough to be installed around all key power installations, and portable enough to be taken to international sporting events to beam up at brewing storm clouds.A stumbling blockHowever, there is still a big stumbling block. The laser is no nifty portable: it's a monster that takes up a whole room. Diels is trying to cut down the size and says that a laser around the size of a small table is in the offing. He plans to test this more manageable system on live thunderclouds next summer.Bernstein says that Diels's system is attracting lots of interest from the power companies. But they have not yet come up with the $5 million that EPRI says will be needed to develop a commercial system, by making the lasers yet smaller and cheaper. 'I cannot say I have money yet, but I'm working on it, ' says Bernstein. He reckons that the forthcoming field tests will be the turning point - and he's hoping for good news. Bernstein predicts 'an avalanche of interest and support' if all goes well. He expects to see cloud-zappers eventually costing 100, 000 each.Other scientists could also benefit. With a lightning 'switch' at their fingertips, materials scientists could find out what happens when mighty currents meet matter. Diels also hopes to see the birth of 'interactive meteorology' - not just forecasting the weather but controlling it. 'If we could discharge clouds, we might affect the weather, ' he says.And perhaps, says Diels, we'll be able to confront some other meteorological menaces. 'We think we could prevent hail by inducing lightning, ' he says. Thunder, the shock wave that comes from a lightning flash, is thoughtto be the trigger for the torrential rain that is typical of storms. A laser thunder factory could shake the moisture out of clouds, perhaps preventing the formation of the giant hailstones that threaten crops. With luck, as the storm clouds gather this winter, laser-toting researchers could, for the first time, strike back.Questions 1-3Choose the correct letter, A, B, C or D.Write the correct letter in boxes 1-3 on your answer sheet.1 The main topic discussed in the text isA the damage caused to US golf courses and golf players by lightning strikes.B the effect of lightning on power supplies in the US and in Japan.C a variety of methods used in trying to control lightning strikes.D a laser technique used in trying to control lightning strikes.2 According to the text, every year lightningA does considerable damage to buildings during thunderstorms.B kills or injures mainly golfers in the United States.C kills or injures around 500 people throughout the world.D damages more than 100 American power companies.3 Researchers at the University of Florida and at the University of New MexicoA receive funds from the same source.B are using the same techniques.C are employed by commercial companies.D are in opposition to each other.Questions 11-13Do the following statements agree with the information given in Reading Passage 1?In boxes 11-13 on your answer sheet writeYES if the statement agrees with the claims of the writerNO if the statement contradicts the claims of the writerNOT GIVEN if it is impossible to say what the writer thinks about this11 Power companies have given Diels enough money to develop his laser.12 Obtaining money to improve the lasers will depend on tests in real storms.13 Weather forecasters are intensely interested in Diels's system.READING PASSAGE 1篇章结构解题地图难度系数:★★★解题顺序:按题目顺序解答即可友情提示:烤鸭们注意:本文中的SUMMARY题目顺序有改变,解题要小心;MULTIPLE CHOICE的第三题是个亮点,爱浮想联翩的烤鸭们可能会糊掉。
并行计算体系结构

8
最新的TOP500计算机
12:12
9
最新的TOP500计算机
12:12
10
来自Cray的美洲豹“Jaguar”,凭借1.75 PFlop/s(每秒1750万亿 次)的计算能力傲视群雄。“Jaguar”采用了224162个处理器核 心
12:12
2
结构模型
共享内存/对称多处理机系统(SMP)
PVP:并行向量机
单地址空间 共享存ess) SMP:共享内存并行机( Shared Memory Processors )。多个处理器通过交叉开关 (Crossbar)或总线与共享内存互连。
来自中国的曙光“星云”系统以1271万亿次/s的峰值速度名列 第二
• 采用了自主设计的HPP体系结构、高效异构协同计算技术
• 处理器是32nm工艺的六核至强X5650,并且采用了Nvidia Tesla C2050 GPU做协处理的用户编程环境;
异构体系结构 专用 通用
TOP500中85%的系统采用了四核处理器,而有5%的系统已经使
12:12
6
Cluster:机群系统
Cluster(Now,Cow): 群集系统。将单个节点,用商业网 络 :Ethernet,Myrinet,Quadrics, Infiniband,Switch等连结起来形成群 集系统。
• 每个节点都是一个完整的计算机 (SMP或DSM),有自己磁盘和操 作系统
系统在物理上分布、逻辑上共享。各结点有
自己独立的寻址空间。
• 单地址空间 、分布共享
• NUMA( Nonuniform Memory Access )
02_2并行计算机(系统结构)

P
M
P M
P M
...
P M
2019/2/23
23
构建并行机系统的不同存储结构
PVP (Cray
中央存储器 T90)
UMA SMP SGI
多处理机 ( 单地址 空间 共享 存储器 ) (Intel SHV,SunFire,DEC 8400, PowerChallenge,IBMR60,etc.) (KSR-1,DDM) (Stanford Dash, SGI Origin 2000,Sequent NUMA-Q, HP/Convex Exemplar) (Cray T3E)
2019/2/23 10
MPP(Massively Parallel Processor)
处理节点采用微处理器 系统中有物理上的分布式存储器 采用高通信带宽和低延迟的互连网络(专门设 计和定制的) 能扩展至成百上千乃至上万个处理器 异步MIMD,构成程序的多个进程有自己的地 址空间,进程间通信消息传递相互作用
16
Origin3000 与 Altix3000
Origin3000
2019/2/23
Altix3000
17
并行计算机内存访问模型
UMA / NUMA / COMA / CC-NUMA / NORMA
2019/2/23
18
并行计算机访存模型(1)
UMA(Uniform Memory Access)模型是均匀存储访问模型的 简称。其特点是:
节 点1 P / C 节 点N M e m P / C
… P/C
交 叉 开 关 总 线 或
…
I / O
…P/C
开 关 总 线 或 交 叉
妇产科英语试题及答案

妇产科英语试题及答案一、选择题(每题1分,共10分)1. Which of the following is a common gynecological examination?A. Blood pressure testB. Pap smearC. Chest X-rayD. Electrocardiogram2. What is the medical term for the first stage of labor?A. Latent phaseB. Active phaseC. Transition phaseD. Expulsion phase3. The hormone responsible for the development of female reproductive organs is:A. EstrogenB. ProgesteroneC. TestosteroneD. Insulin4. Which of the following is not a symptom of polycystic ovary syndrome (PCOS)?A. Irregular menstrual cyclesB. AcneC. InfertilityD. Excessive thirst5. What is the term used to describe the process of a fertilized egg implanting into the uterine lining?A. ImplantationB. ConceptionC. EmbryogenesisD. Parturition6. The most common type of birth is:A. Vaginal birthB. Cesarean sectionC. Breech birthD. Forceps-assisted birth7. Which of the following is a prenatal diagnostic test?A. UltrasoundB. AmniocentesisC. Blood pressure monitoringD. Fetal heart rate monitoring8. The hormone that stimulates the production of breast milk is:A. OxytocinB. ProlactinC. EstrogenD. Cortisol9. What is the medical term for the surgical removal of the uterus?A. HysterectomyB. OophorectomyC. SalpingectomyD. Cystoscopy10. Which of the following is a risk factor for gestational diabetes?A. Family history of diabetesB. SmokingC. Alcohol consumptionD. All of the above二、填空题(每空1分,共10分)1. The process of childbirth is divided into three stages: the _______ phase, the _______ phase, and the _______ phase.2. The medical condition characterized by the presence of cysts in the ovaries is known as _______.3. A _______ is a type of imaging technique used to visualize the fetus during pregnancy.4. The hormone _______ is responsible for the thickening of the uterine lining during the menstrual cycle.5. A _______ is a surgical procedure used to remove fibroids from the uterus.6. The _______ is the process by which a baby is born through the vagina.7. The _______ is a condition that affects the female reproductive system and can cause infertility.8. The _______ is the process of a woman's body preparing for childbirth.9. The _______ is a condition where the cervix opens too early during pregnancy, leading to a risk of preterm birth.10. The _______ is the period of time after childbirth when the mother's body returns to its pre-pregnancy state.三、简答题(每题5分,共20分)1. Explain the difference between a Pap smear and a colposcopy.2. Describe the stages of labor and the signs that indicate the onset of labor.3. What are the common symptoms of menopause, and how are they managed?4. Discuss the importance of prenatal care and the types of tests that are typically performed.四、论述题(每题15分,共30分)1. Discuss the various methods of contraception and their effectiveness, side effects, and suitability for different individuals.2. Elaborate on the role of a midwife in the process of childbirth and the importance of continuous support during labor.五、病例分析题(共30分)A patient presents to the gynecologist with complaints of heavy menstrual bleeding and severe cramps. She also mentions that she has been experiencing these symptoms for the pastsix months. Based on the information provided, discuss the possible causes of these symptoms, the diagnostic tests that may be performed, and the potential treatment options.答案:一、选择题1. B2. A3. A4. D5. A6. A7. B8. B9. A 10. A二、填空题1. First, second, third2. Polycystic ovary syndrome (PCOS)3. Ultrasound4. Progesterone5. Myomectomy6. Vaginal delivery7. Endometriosis8. Childbirth9. Cervical insufficiency10. Postpartum period三、简答题1. A Pap smear is a screening test for cervical cancer, whilea colposcopy is a more detailed examination of the cervix using a magnifying instrument.。
大学英语新视野3第三单元单词详解

LOGO
Paragraph 3-11 5. spread: spread to: (cause to) reach sb. or sth. else, as by touching or other means of passing 消防队员成功地防止了火势蔓延到其他办公楼。 Firemen succeeded in preventing the fire from spreading to other office buildings. 这项运动已经发展到了牛津大学。 This movement spread to Oxford. 医生认为癌症已经扩散到了他的胃部,因此治疗起 来比较困难。 The doctor thought that the cancer has spread to his stomach, so it will be difficult to deal with.
LOGO
Paragraph 1-2
(2) prepare and use (land, soil, etc.) for growing crops 那里的大部分土地太贫瘠,无法耕种。 Most of the land there is too poor to cultivate. 他用一台大型拖拉机耕地。 He cultivated the field with a large tractor. 他退休以后就在家里种花,生活很舒适。 After he retired, he cultivated some flowers at home and he led a very comfortable life. 这里的人们主要种植稻子和豆类。 The people cultivate mainly rice and beans.
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
CONCURRENCY AND COMPUTATION:PRACTICE AND EXPERIENCEConcurrency Computat.:Pract.Exper.2003;15:607–621(DOI:10.1002/cpe.718)A scalable HPF implementationof afinite-volume computational electromagnetics application ona CRAY T3E parallel system‡Yi Pan1,∗,†,Joseph J.S.Shang2and Minyi Guo31Department of Computer Science,Georgia State University,Atlanta,GA30303,U.S.A.2Air Vehicle Directorate,Air Force Research Laboratory,WPAFB,OH45433-7521,U.S.A.3Department of Computer Software,The University of Aizu,Aizu-Wakamatsu City,Fukushima,965-8580JapanSUMMARYThe time-dependent Maxwell equations are one of the most important approaches to describing dynamic or wide-band frequency electromagnetic phenomena.A sequentialfinite-volume,characteristic-based procedure for solving the time-dependent,three-dimensional Maxwell equations has been successfully implemented in Fortran before.Due to its need for a large memory space and high demand on CPU time,it is impossible to test the code for a large array.Hence,it is essential to implement the code on a parallel computing system.In this paper,we discuss an efficient and scalable parallelization of the sequential Fortran time-dependent Maxwell equations solver using High Performance Fortran(HPF). The background to the project,the theory behind the efficiency being achieved,the parallelization methodologies employed and the experimental results obtained on the Cray T3E massively parallel computing system will be described in detail.Experimental runs show that the execution time is reduced drastically through parallel computing.The code is scalable up to98processors on the Cray T3E and has a performance similar to that of an MPI implementation.Based on the experimentation carried out in this research,we believe that a high-level parallel programming language such as HPF is a fast, viable and economical approach to parallelizing many existing sequential codes which exhibit a lot of parallelism.Copyright c 2003John Wiley&Sons,Ltd.KEY WORDS:parallel computers;execution time;efficiency;scalability;loop parallelization;Cray T3E;high performance Fortran∗Correspondence to:Yi Pan,Department of Computer Science,Georgia State University,Atlanta,GA30303,U.S.A.†E-mail:pan@‡A preliminary version of this paper appeared in ICA3PP2000,Hong Kong,December2000.Contract/grant sponsor:Air Force Office of Scientific Research;contract/grant number:F49620-93-C-0063Contract/grant sponsor:National Science Foundation;contract/grant number:CCR-9211621,OSR-9350540,CCR-9503882, ECS-0010047Contract/grant sponsor:Air Force Avionics Laboratory,Wright Laboratory;contract/grant number:F33615-C-2218Contract/grant sponsor:Japan Society for the Promotion of Science;contract/grant number:14580386Received11October2001 Copyright c 2003John Wiley&Sons,Ltd.Revised8August2002608Y.PAN,J.J.S.SHANG AND M.GUO1.INTRODUCTIONComputational electromagnetics(CEM)in the time domain is the most general numerical approach for describing dynamic or wide-band frequency electromagnetic putational simulations are derived from discretized approximations to the time-dependent Maxwell equations[ Copyright c 2003John Wiley&Sons,Ltd.Concurrency Computat.:Pract.Exper.2003;15:607–621HPF IMPLEMENTATION FOR CEM ON A CRAY T3E609 parallelize many existing sequential codes which exhibit a lot of parallelism besides MPI.In many cases,using HPF to implement a sequential Fortran code is more economical than using MPI.HPF also solves the problem of limited memory size on a single processor and provides a fast way to port the code on parallel computer systems.In the following sections,we will describe the numerical formulation of the problem and the related subroutines in the sequential code.We then present the parallelization schemes used,the results achieved during the research and outline the impact of the achieved research results.2.THE MAXWELL EQUATIONSThe behavior of electromagnetic phenomena is modeled by the set of four equations collectively known as Maxwell’s equations.In differential vector form for a Cartesian reference frame,these equations are written as follows(see[∂t+∇×E=0(1)Amp`e re’s law:∂D∂t−∇×H=−J(2) Gauss’s law:∇·B=0,B=µH(3)∇·D=0,D= E(4) where andµare the electric permittivity and the magnetic permeability which relate the electric displacement to the electricfield intensity and magneticflux density to the magneticfield intensity, respectively.Using a coordinate transformation from the Cartesian coordinates,the time-dependent Maxwell equations can be cast in a general body-conformal curvilinear frame of reference.The resultant governing equations influx-vector form acquire the following form[∂t +∂Fξ∂ξ+∂Fη∂η+∂Fζ∂ζ=−J(5)where U is the transformed dependent variable now scaled by the local cell volume,V.Fξ,Fηand Fζare the contravariant components of theflux vectors of the Cartesian coordinates.U={B x V,B y V,B z V,D x V,D y V,D z V}T(6)Fξ=ξx F x+ξy F y+ξz F zFη=ηx F x+ηy F y+ηz F zFζ=ζx F x+ζy F y+ζz F z(7) Copyright c 2003John Wiley&Sons,Ltd.Concurrency Computat.:Pract.Exper.2003;15:607–621610Y.PAN,J.J.S.SHANG AND M.GUOwhere theflux-vector components of the Cartesian frame are:F x={0,−D z/ ,D y/ ,0,B z/µ,−B y/µ}TF y={D z/ ,0,−D x/ ,−B z/µ,0,B x/µ}TF z={−D y/ ,D x/ ,0,B y/µ,−B x/µ,0}T(8)andξx,ηx,ζx,ξy,ηy,ζy,ξz,ηz,as well asζz are the nine metrics of the coordinate transformation. The characteristic-basedfinite-volume approximation is achieved by splitting theflux vector according to the signs of the eigenvalues of the coefficient matrix in each spatial direction.Theflux vector at any cell interface is represented by the superposition of two components:F+ξ,F−ξ,F+η, F−η,F+ζand F−ζaccording to the direction of the wave motion[2=F+ξ(U Li+12)+F−ξ(U Ri+12)Fη,j+12=F+η(U Lj+12)+F−η(U Rj+12)Fζ,k+12=F+ζ(U Lk+12)+F−ζ(U Rk+12)(9)where U L and U R denote the reconstructed dependent variables at the left-and right-hand side of the cell interface.A single-step,two-stage Runge–Kutta scheme is adopted for the temporal integration process:the resultant numerical procedure is capable of generating numerical solutions accurate in space fromfirst to third order and accurate in time to second order.The initial and boundary conditions for a perfectly electrical conducting(PEC)sphere can be summarized as follows.The incident wave consists of a linearly polarized harmonicfield propagating in the negative z-axis direction[Copyright c 2003John Wiley&Sons,Ltd.Concurrency Computat.:Pract.Exper.2003;15:607–621HPF IMPLEMENTATION FOR CEM ON A CRAY T3E611 .....C START THE SOLVING SEQUENCESDO10N=1,NENDT=FLOAT(N-1)*DTCALL IC(N,NEND)DO12M=1,2CALL FXICALL GETACALL HZETACALL SUM(M,N,NEND)12CONTINUEIF((N.GT.NES).OR.(N.LT.NBS))GO TO10C PERFORM FOURIER’S TRANSFORMWT=W*(T+DT)DO14L=1,6DO14K=1,KLDO14J=1,JLFU(J,K,L)=FU(J,K,L)+U1(IB,J,K,L)*CEXP(RI*WT)14CONTINUE10CONTINUE.....After testing and performance profiling of the sequential code MAX3D,we found that the subroutines FXI,GETA,HZETA and SUM occupy the most time for the sequential code and deserve special attention.Subroutines FXI,GETA,and HZETA generate electromagnetic coefficients for theflux vectors and SUM computes the new time level solution.These subroutines are related to Equations(Copyright c 2003John Wiley&Sons,Ltd.Concurrency Computat.:Pract.Exper.2003;15:607–621612Y.PAN,J.J.S.SHANG AND M.GUOtuning to produce more efficient code.For example,when we parallelize the MAX3D code using automatic parallelization on SGI Origin2000,the parallel time is worse than the sequential time due to data dependence and the heavy communication overhead in the code.In our research,only hand parallelization(inserting directives manually versus automatic code generation by software)is used to avoid memory waste and increase efficiency.The HPF model can be seen as a collection of distinguishable,but complementary,programming styles.The models and methods we used in the implementation are data-and work-sharing.In data-sharing,data,such as an array,are spreaded over the memory of all of the available processors so that each processor operates primarily on its own part.In work-sharing,the loop iterations are distributed within loops among the system’s processors with the goal of executing them in parallel.For instance, the INDEPENDENT directive can be used to divide the iterations of a DO loop among processors or the compiler can divide the work by choosing an implicit array syntax.One natural and powerful strategy involves distributing an array,data-sharing and the iterations of a DO loop that operate on that array,work-sharing,over your available processors.Processors executing a DO loop in parallel to help realize the power of the CRAY T3E and other parallel computing systems.In the following sections, the details of data allocation and parallelization schemes are discussed.In order for a parallel code to run efficiently,it is also essential that the sequential code uses the cache effectively.The overall optimization steps adopted in our research are:(1)locate the‘hot spot’of the sequential code via profiling tools;(2)study these subroutines identified in step1carefully for performance improvement;(3)improve the cache locality behavior of these subroutines through a series of systematic looptransformations;(4)study the listingfile produced by the HPF compiler and locate the overhead caused by inefficientparallel loops;and(5)insert HPF compiler directives to direct the compiler to parallelize the code so that most of theoverhead is eliminated and the most time-consuming loops are parallelized.Note that some of the goals may be in conflict.Hence,these steps may need to be repeated several times to achieve an overall good performance.3.1.Distributed data allocationIn a parallel program on a distributed memory architecture,data can be shared(distributed)or private (replicated).Arrays can also be distributed to speedup the code.Arrays are distributed across all processors via the!HPF$DISTRIBUTE directive in HPF.The DISTRIBUTE directive names the variables that are to be shared data objects and specifies how they are to be distributed across the PEs. If the data are not specified as shared,they are private(the default).In a program that declares a private data item,each processor gets a copy of storage for that item.In many programming models,this datum is called replicated.When an array is shared,its elements are distributed across the available PEs. The DISTRIBUTE directive can specify array distribution within the directive by following the array name with distribution information contained in parentheses.The distribution information may include the keywords BLOCK or CYCLIC,which tell the compiler how to distribute the array elements among the available PEs.The BLOCK distribution distributes a block of consecutive memory locations to a processor,while the CYCLIC distribution distributes an array in a cyclic manner.Copyright c 2003John Wiley&Sons,Ltd.Concurrency Computat.:Pract.Exper.2003;15:607–621HPF IMPLEMENTATION FOR CEM ON A CRAY T3E613 The DISTRIBUTE directive allows data to be distributed over processors in a variety of patterns. The ALIGN directive is used to specify that certain data objects are to be mapped in the same way as certain other data objects in order to reduce inter-processor communication.Operations between aligned data objects are likely to be more efficient than operations between data objects that are not known to be aligned.In our MAX3D implementation,U0,U1,U2,F and G are all aligned and have the same distribution,as shown later.Hence,we can parallelize the code across dimension K efficiently when working on these large arrays.The ONTO clause specifies the processor arrangement declared in a PROCESSORS directive.In our case,the arrangement is PROCS.!HPF$PROCESSORS PROCS(NUMBER_OF_PROCESSORS())!HPF$ALIGN U1(I,J,K,L)WITH U0(I,J,K,L)!HPF$ALIGN U2(I,J,K,L)WITH U0(I,J,K,L)!HPF$ALIGN F(I,J,K,L)WITH U0(I,J,K,L)!HPF$ALIGN G(I,J,K,L)WITH U0(I,J,K,L)!HPF$DISTRIBUTE U0(*,*,BLOCK,*)ONTO PROCSSimilarly,since we need to parallelize HZETA on dimension J,the H array is distributed on dimension J as follows:!HPF$DISTRIBUTE H(*,BLOCK,*,*)ONTO PROCSSince different phases require different data distributions,it would be nice to dynamically distribute an array during execution.HPF provides such a mechanism—the DYNAMIC and REDISTRIBUTE directives.Although various redistribution methods have been studied and a lot of improvements have been made,the redistribution of large arrays still takes a huge amount of time in general[ Copyright c 2003John Wiley&Sons,Ltd.Concurrency Computat.:Pract.Exper.2003;15:607–621614Y.PAN,J.J.S.SHANG AND M.GUOIn HPF,we may use a FORALL statement to parallelize a nested loop[Copyright c 2003John Wiley&Sons,Ltd.Concurrency Computat.:Pract.Exper.2003;15:607–621HPF IMPLEMENTATION FOR CEM ON A CRAY T3E615 Some data dependencies cannot be eliminated due to the nature of the computations involved in the code.Our strategy is to parallelize the loops which have no data dependencies.For example,loop K in subroutine HZETA has data dependencies.However,loop J does not.Hence,we parallelized loop J instead of loop K in subroutine HZETA.The code segment of the subroutine HZETA is as follows. The data dependencies exist in the statements S1,S2,and S3for loop K:SUBROUTINE HZETAPARAMETER(IL=73,JL=61,KL=97)......!HPF$INDEPENDENT,NEW(K,KM,KP,I,SSZT,RSSZT,....)DO2J=1,JLMDO2K=1,KLMKM=K-1KP=K+1DO2I=1,ILMC S1UP1(I,K)=U1(I,J,K,1)+0.25*RP*((1.0-RK)*(U1(I,J,K,1)-U1(I,J,KM,1))1+(1.0+RK)*(U1(I,J,KP,1)-U1(I,J,K,1)))......C S2UC1=UI1(I,KM)*UP1(I,K)+UI2(I,KM)*UP2(I,K)+UI3(I,KM)*UP3(I,K)......C S3H(I,J,K-1,1)=SSZT*(HP(I,K-1,1)+HM(I,K,1))......2CONTINUE......RETURNENDSimilarly,we parallelized loop K in subroutines FXI and GETA.This is also reflected in their data distributions:array F,G and H are distributed on different dimensions as shown previously.4.PERFORMANCE RESULTSDuring this research,we used a CRAY T3E computer system at the Ohio Supercomputer Center, which is a powerful scalable parallel system with128processing elements.Its peak performance can reach76.8GFLOPS.Each processor is a DECchip64-bit super-scalar RISC processor.It has four-way instruction issue with twofloating-point operations per clock.Each processor has on-chip8kbyte direct-mapped L1instruction cache and an on-chip8kbyte direct-mapped L1data cache.It also has an on-chip96kbyte three-way-set-associative L2unified cache.Each processor has a local memory of 16Mwords(or128Mbyte).The clock speed of the processor is300MHz and its peak performance is 600MFLOPS.Although the speed is quite fast compared with other parallel systems such as the SGI Origin2000,the cache and local memory sizes of the T3E are much smaller(each processor in the SGI Origin2000contains a4Mbyte secondary cache).This limits the power of the T3E for programs using a lot of memory space such as the MAX3D code.Actually,the T3E’s smaller cache size effects sequential programs as well as parallel programs.Copyright c 2003John Wiley&Sons,Ltd.Concurrency Computat.:Pract.Exper.2003;15:607–621616Y .PAN,J.J.S.SHANG AND M.GUOTable I.Execution times of the major subroutines.No.of processorsFXI GETA HZETA SUM 40.592360.895350.8809 2.889480.314000.456460.44389 1.4939160.169630.252900.226040.83692320.0997330.150420.118620.50716480.0744170.108900.115010.37680640.0535830.0765010.0648940.25680900.0537340.076400.0647640.25511980.029480.041190.064060.14431280.029480.041080.063840.143000.20.40.60.811.21.41.61.822.22.42.62.834142434445464748494104114124Number of Processors FXI GETA HZETA SUM Figure 1.Execution times of the major subroutines.Several experiments were carried out to tune our parallel code and to adjust our strategy as to how to distribute the various arrays and which loops and subroutines to parallelize.The HPF compiler used is PGHPF [Copyright c 2003John Wiley &Sons,Ltd.Concurrency Computat.:Pract.Exper.2003;15:607–621HPF IMPLEMENTATION FOR CEM ON A CRAY T3E617Table II.Total parallel execution times for problem size (73×61×97)on T3E.No.of processorsExecution time41633188713164853322919641659711680901688981127128114810003000500070009000110001300015000170004142434445464748494104114124Number of ProcessorsTimes in SecondsFigure 2.Execution times of the HPF code.code.As shown in FigureCopyright c 2003John Wiley &Sons,Ltd.Concurrency Computat.:Pract.Exper.2003;15:607–621618Y.PAN,J.J.S.SHANG AND M.GUOthe parallel program could be run on a T3E with one or two processors.Hence,TableCopyright c 2003John Wiley&Sons,Ltd.Concurrency Computat.:Pract.Exper.2003;15:607–621HPF IMPLEMENTATION FOR CEM ON A CRAY T3E619Table III.Speedups for problem size (73×61×97).No.of processorsSpeedup 11224487.491613.463222.386439.387138.889038.709857.9612856.90161116212631364146515661661112131415161718191101111121Number of ProcessorsHPF MPIFigure parison of speedups using HPF on T3E and MPI on SP2.Copyright c 2003John Wiley &Sons,Ltd.Concurrency Computat.:Pract.Exper.2003;15:607–621620Y.PAN,J.J.S.SHANG AND M.GUO5.CONCLUSIONSAs we all know,a low-level message-passing programming language such as MPI has several disadvantages compared with a high-level parallel programming language:the cost of producing a message-passing code is usually much higher,the length of the code grows significantly and it is much less readable and maintainable than the one produced using a high-level parallel programming language such as HPF.For these reasons,it is widely agreed that a higher level programming paradigm is essential if parallel systems are to be widely adopted.HPF has reached a critical stage in its history. Having struggled while the compiler technology evolved into a usable state,the parallel computing community has now found it possible to write portable,high-performance implementations for selected applications in HPF.HPF is becoming a standard for high-level parallel programming and is available on almost every major parallel computer system.This research indicates that large-scale data-parallel applications such as CEM simulations can use HPF to achieve a reasonable performance.This research addresses the portability and scalability problems of the MAX3D code through using HPF.Our results achieved during the research have demonstrated that the sequential MAX3D code can be parallelized quickly by simple directives insertion and yet the code produced this way can still be executed efficiently.Furthermore,the code is still quite scalable.While the MPI code is more scalable than the HPF code due to different data distribution schemes(3D versus1D)when using a larger number of processors,the labor cost of producing the MPI code is much larger than the HPF code. As new versions of commercial HPF compilers emerge in the market,and the HPF technology becomes more mature,we expect that the performance of the HPF MAX3D code will be improved substantially in the near future with little change in the code.We believe that high-level parallel programming languages such as HPF is the future for fast implementation of parallel codes. ACKNOWLEDGEMENTSThis research was supported by the Air Force Office of Scientific Research under grant F49620-93-C-0063. Additional support has been provided by the National Science Foundation under grants CCR-9211621, OSR-9350540,CCR-9503882,and ECS-0010047,the Air Force Avionics Laboratory,Wright Laboratory,under grant F33615-C-2218,and the Japan Society for the Promotion of Science Grant-in-Aid Basic Research(C) No.14580386.We would also like to thank Mark Young of Portland Group for his help in using PGI’s High Performance Fortran compiler putational resources for the work presented here were provided by the Ohio Supercomputing Center,Columbus,Ohio.Many thanks also go to the three reviewers and Professor Mark Baker for their constructive comments and suggestions which improved our paper greatly.REFERENCES1.Shang JS.A fractional-step method for solving3-D time-domain Maxwell equations.31th Aerospace Sciences Meetingand Exhibit.American Institute of Aeronautics and Astronautics:New York,1993.2.Shang JS.Characteristics based methods for the time-domain Maxwell equations.29th Aerospace Sciences Meeting.American Institute of Aeronautics and Astronautics:New York,1991.3.Shang JS,Calahan DA,Vikstrom B.Performance of afinite volume CEM code on puting Systems inEngineering1995;6(3):241–250.4.Shang JS,Fithen RM.A comparative study of characteristic-based algorithms for the Maxwell equations.Journal ofComputational Physics1996;125:378–394.5.Shang JS,Gaitonde D.Scattered electromagneticfield of a re-entry vehicle.Journal of Spacecraft and Rockets1995;32(2):294–301.Copyright c 2003John Wiley&Sons,Ltd.Concurrency Computat.:Pract.Exper.2003;15:607–621HPF IMPLEMENTATION FOR CEM ON A CRAY T3E621 6.Shang JS,Gaitonde D.Characteristic-based,time-dependent Maxwell equation solvers on a general curvilinear frame.American Institute of Aeronautics and Astronautics Journal1995;33(3):491–498.7.Shang JS,Gaitonde D,Wurtzler K.Scattering simulations of computational electromagnetics.27th AIAA Plasmadynamicsand Lasers Conference.American Institute of Aeronautics and Astronautics:New York,1996.8.Shang JS,Gaitonde D.High-orderfinite-volume schemes in wave propagation phenomena.27th AIAA Plasmadynamicsand Lasers Conference.American Institute of Aeronautics and Astronautics:New York,1996.9.Shang JS,Gaitonde D.On high resolution schemes for time-dependent Maxwell equations.34th Aerospace SciencesMeeting and Exhibit.American Institute of Aeronautics and Astronautics:New York,1996.10.Shang JS,Scherr SJ.Time-domain electromagnetic scattering simulations on multicomputers.26th AIAA Plasmadynamicsand Lasers Conference.American Institute of Aeronautics and Astronautics:New York,1995.11.Snir M et al..MPI:The Complete Reference.MIT Press:Cambridge,MA,1996.12.Gropp W,Lusk E,Skjellum ing MPI:Portable Parallel Programming with the Message-passing Interface.MITPress:Cambridge,MA,1994.13.Shang JS,Wagner M,Pan Y,Blake DC.Strategies for adopting FVTD on multicomputers.IEEE Computing in Scienceand Engineering(formerly known as IEEE Computational Science and Engineering)2000;2(1):10–21.14.Hogue C.MIPSpro(TM)Power Fortran77Programmer’s Guide.Silicon Graphics.Inc.,1996.15.Pan Y.Improvement of cache utilization and parallel efficiency of a time-dependent Maxwell equation solver on the SGIOrigin2000.Final Report for AFOSR Summer Faculty Research Program,Air Force Office of Scientific Research,Bolling Air Force Base,DC,August1997.es D,Schuster V,Young M.The PGHPF high performance Fortran compiler:Status and future directions.2nd AnnualHPF User Group Meeting.Springer:Berlin,1998;25–26.17.Shang JS,Gaitonde D.Characteristic-based,time-dependent Maxwell equations solvers on a general curvilinear frame.American Institute of Aeronautics and Astronautics Journal1995;33(3):491–498.18.Anderson WK,Thomas JL,Van Leer B.A comparison offinite volumeflux splittings for the Euler equations.AmericanInstitute of Aeronautics and Astronautics Journal1986;24(9):1453–1460.19.Koelbel CH.The High Performance Fortran Handbook.MIT Press:Cambridge,MA,1994.20.Guo M,Yamashita Y,Nakata I.An efficient data distribution technique for HPF compliers on distributed memory parallelcomputers.Transactions of Information Processing Society of Japan1998;39(6):1718–1728.21.Wolfe M.High Performance Compilers for Parallel Computing.Addison-Wesley:Reading,MA,1996.22.Guo M.A denotational semantic model of an HPF-like language.Proceedings of The First International Conference onParallel and Distributed Computing,Applications and Technologies,University of Hong Kong,May2000;1–8.23.Pan Y.Parallel implementation of computational electromagnetics simulation using high performance Fortran.Final Reportfor AFOSR Summer Research Extension Program,Air Force Office of Scientific Research,Bolling Air Force Base,DC, November1998.Copyright c 2003John Wiley&Sons,Ltd.Concurrency Computat.:Pract.Exper.2003;15:607–621。