中文分词基础件(基础版)使用说明书
bert base chinese 分词训练文件

bert base chinese 分词训练文件分词是自然语言处理中的一项基础任务,它将连续的文本字符串切分为一个个有意义的词语。
在中文自然语言处理中,由于缺乏明显的词语边界,分词任务显得尤为重要。
而BERT模型,作为一种预训练的语言表示模型,在中文分词任务中也取得了非常好的效果。
BERT Base Chinese是谷歌公司在预训练模型BERT中针对中文语言特点所提供的一种预训练模型。
它是基于未标记的大规模中文文本进行预训练得到的,可以用于各种中文自然语言处理任务。
其中,分词任务就是BERT模型在中文自然语言处理中的一项重要任务之一。
BERT Base Chinese的分词模型是通过在大规模中文文本中进行掩码预测任务来进行训练的。
具体而言,模型会将输入的文本进行分词,并将其中的一部分词语进行掩码处理。
然后,模型通过对掩码位置的词语进行预测,来学习到更好的词向量表示。
BERT Base Chinese的训练文件是在大规模的中文文本上训练得到的,其中包括了各种不同领域和主题的文本数据。
通过这些训练文件,BERT模型可以学习到丰富的语言表示,并且能够在中文分词任务中表现出较高的准确性和鲁棒性。
对于中文分词而言,BERT模型的预训练文件对分词的效果影响很大。
由于中文语言的复杂性和上下文的歧义性,一个好的分词模型需要能够准确地识别出不同词语之间的边界,并正确地切分文本。
BERT 模型通过学习大规模的中文文本,可以从中获取到更多的语言知识和规律,提高分词的准确性。
总结起来,BERT Base Chinese的分词模型是通过在大规模中文文本上训练得到的。
这个训练文件使得BERT模型能够学习到更好的中文语言表示,从而在中文分词任务中取得更好的效果。
中文分词是中文自然语言处理中的基础任务,对于BERT模型的应用来说,这个训练文件是它在中文分词任务中取得成功的重要因素之一。
中文分词入门之最大匹配法
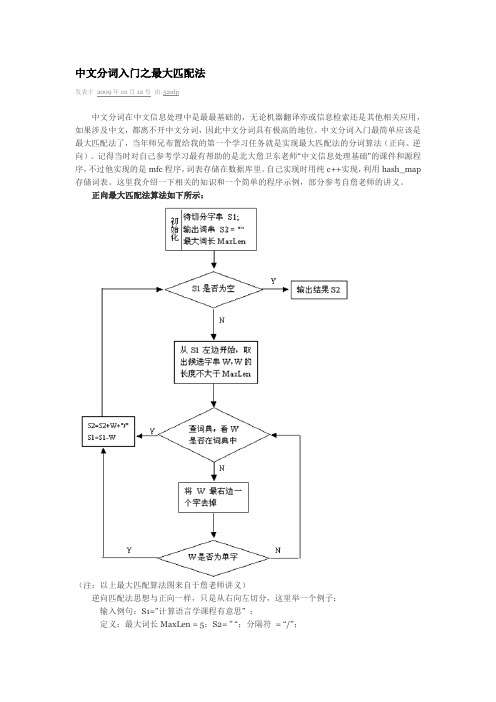
中文分词入门之最大匹配法发表于2009年01月12号由52nlp中文分词在中文信息处理中是最最基础的,无论机器翻译亦或信息检索还是其他相关应用,如果涉及中文,都离不开中文分词,因此中文分词具有极高的地位。
中文分词入门最简单应该是最大匹配法了,当年师兄布置给我的第一个学习任务就是实现最大匹配法的分词算法(正向、逆向)。
记得当时对自己参考学习最有帮助的是北大詹卫东老师“中文信息处理基础”的课件和源程序,不过他实现的是mfc程序,词表存储在数据库里。
自己实现时用纯c++实现,利用hash_map 存储词表。
这里我介绍一下相关的知识和一个简单的程序示例,部分参考自詹老师的讲义。
正向最大匹配法算法如下所示:(注:以上最大匹配算法图来自于詹老师讲义)逆向匹配法思想与正向一样,只是从右向左切分,这里举一个例子:输入例句:S1=”计算语言学课程有意思” ;定义:最大词长MaxLen = 5;S2= ” “;分隔符= “/”;假设存在词表:…,计算语言学,课程,意思,…;最大逆向匹配分词算法过程如下:(1)S2=”";S1不为空,从S1右边取出候选子串W=”课程有意思”;(2)查词表,W不在词表中,将W最左边一个字去掉,得到W=”程有意思”;(3)查词表,W不在词表中,将W最左边一个字去掉,得到W=”有意思”;(4)查词表,W不在词表中,将W最左边一个字去掉,得到W=”意思”(5)查词表,“意思”在词表中,将W加入到S2中,S2=” 意思/”,并将W从S1中去掉,此时S1=”计算语言学课程有”;(6)S1不为空,于是从S1左边取出候选子串W=”言学课程有”;(7)查词表,W不在词表中,将W最左边一个字去掉,得到W=”学课程有”;(8)查词表,W不在词表中,将W最左边一个字去掉,得到W=”课程有”;(9)查词表,W不在词表中,将W最左边一个字去掉,得到W=”程有”;(10)查词表,W不在词表中,将W最左边一个字去掉,得到W=”有”,这W是单字,将W 加入到S2中,S2=“ /有/意思”,并将W从S1中去掉,此时S1=”计算语言学课程”;(11)S1不为空,于是从S1左边取出候选子串W=”语言学课程”;(12)查词表,W不在词表中,将W最左边一个字去掉,得到W=”言学课程”;(13)查词表,W不在词表中,将W最左边一个字去掉,得到W=”学课程”;(14)查词表,W不在词表中,将W最左边一个字去掉,得到W=”课程”;(15)查词表,“意思”在词表中,将W加入到S2中,S2=“课程/ 有/ 意思/”,并将W从S1中去掉,此时S1=”计算语言学”;(16)S1不为空,于是从S1左边取出候选子串W=”计算语言学”;(17)查词表,“计算语言学”在词表中,将W加入到S2中,S2=“计算语言学/ 课程/ 有/ 意思/”,并将W从S1中去掉,此时S1=”";(18)S1为空,输出S2作为分词结果,分词过程结束。
中文分词器的作用-概述说明以及解释

中文分词器的作用-概述说明以及解释1.引言1.1 概述引言部分是文章的开头部分,用于介绍文章的背景和目的。
在中文分词器的作用这篇长文中,引言部分应该包括以下几个方面:1. 介绍中文分词的重要性和普遍存在的问题:中文是一种字符没有明确分隔的语言,而语义的理解和信息处理往往需要将连续的字符序列切分为有意义的词语单位。
因此,中文分词是自然语言处理中一个重要而困难的问题。
2. 概述中文分词器的概念和基本原理:中文分词器是一种通过算法和模型来自动识别和提取中文文本中的词语的工具。
它基于中文语言的特点,通过各种分词规则、字典和统计模型等方法,将连续的中文字符序列切分为有意义的词语。
中文分词器在自然语言处理、信息检索、文本挖掘等领域具有重要的应用价值。
3. 阐述中文分词器的作用和价值:中文分词器的作用不仅仅是简单地将字符序列切分为词语,更重要的是通过合理的分词可以提高其他自然语言处理任务的准确性和效率。
它为文本预处理、信息提取、机器翻译、搜索引擎等应用提供了基础支持,同时也为语言学研究和中文语言处理技术的发展做出了重要贡献。
最后,引言部分的目的是引起读者的兴趣,使其了解中文分词器的概念和作用,并引出全文所要讨论的内容和结论。
同时,还可以提出一些问题或观点,为接下来的正文部分做好铺垫。
文章结构部分的内容可以写成这样:1.2 文章结构本文主要分为三个部分进行讨论,每个部分涵盖了具体的主题和内容。
以下是对这三个部分的简要描述:1. 引言:首先介绍了本文的主题和重要性,包括对整个文章内容的概述、结构和目的的阐述。
2. 正文:本部分将对中文分词器进行详细的介绍和分析。
首先会讲解什么是中文分词器,对其进行定义和解释,以帮助读者对主题有一个基本的了解。
接着,将深入探讨中文分词器的作用,包括其在自然语言处理中的重要性和应用,以及对于语义分析、信息检索、机器翻译等领域的影响。
通过具体案例和实际应用,展示中文分词器在提高语言处理效率和准确性方面的作用和优势。
中文分词技术

一、为什么要进行中文分词?词是最小的能够独立活动的有意义的语言成分,英文单词之间是以空格作为自然分界符的,而汉语是以字为基本的书写单位,词语之间没有明显的区分标记,因此,中文词语分析是中文信息处理的基础与关键。
Lucene中对中文的处理是基于自动切分的单字切分,或者二元切分。
除此之外,还有最大切分(包括向前、向后、以及前后相结合)、最少切分、全切分等等。
二、中文分词技术的分类我们讨论的分词算法可分为三大类:基于字典、词库匹配的分词方法;基于词频度统计的分词方法和基于知识理解的分词方法。
第一类方法应用词典匹配、汉语词法或其它汉语语言知识进行分词,如:最大匹配法、最小分词方法等。
这类方法简单、分词效率较高,但汉语语言现象复杂丰富,词典的完备性、规则的一致性等问题使其难以适应开放的大规模文本的分词处理。
第二类基于统计的分词方法则基于字和词的统计信息,如把相邻字间的信息、词频及相应的共现信息等应用于分词,由于这些信息是通过调查真实语料而取得的,因而基于统计的分词方法具有较好的实用性。
下面简要介绍几种常用方法:1).逐词遍历法。
逐词遍历法将词典中的所有词按由长到短的顺序在文章中逐字搜索,直至文章结束。
也就是说,不管文章有多短,词典有多大,都要将词典遍历一遍。
这种方法效率比较低,大一点的系统一般都不使用。
2).基于字典、词库匹配的分词方法(机械分词法)这种方法按照一定策略将待分析的汉字串与一个“充分大的”机器词典中的词条进行匹配,若在词典中找到某个字符串,则匹配成功。
识别出一个词,根据扫描方向的不同分为正向匹配和逆向匹配。
根据不同长度优先匹配的情况,分为最大(最长)匹配和最小(最短)匹配。
根据与词性标注过程是否相结合,又可以分为单纯分词方法和分词与标注相结合的一体化方法。
常用的方法如下:(一)最大正向匹配法 (MaximumMatchingMethod)通常简称为MM法。
其基本思想为:假定分词词典中的最长词有i个汉字字符,则用被处理文档的当前字串中的前i个字作为匹配字段,查找字典。
分词技术说明书

分词技术文档说明一.基本介绍1.分词技术就是搜索引擎针对用户提交查询的关键词串进行的查询处理后根据用户的关键词串用各种匹配方法进行分词的一种技术。
2.数据处理我们要理解分词技术先要理解一个概念。
那就是查询处理,当用户向搜索引擎提交查询后,搜索引擎接收到用户的信息要做一系列的处理。
步骤如下所示:(1).首先是到数据库里面索引相关的信息,这就是查询处理。
那么查询处理又是如何工作的呢?很简单,把用户提交的字符串没有超过3个的中文字,就会直接到数据库索引词汇。
超过4个中文字的,首先用分隔符比如空格,标点符号,将查询串分割成若干子查询串。
举个例子。
“什么是百度分词技术”我们就会把这个词分割成“什么是,百度,分词技术。
”这种分词方法叫做反向匹配法。
(2).然后再看用户提供的这个词有没有重复词汇如果有的话,会丢弃掉,默认为一个词汇。
接下来检查用户提交的字符串,有没有字母和数字。
如果有的话,就把字母和数字认为一个词。
这就是搜索引擎的查询处理。
3.分词原理(1).正向最大匹配法就是把一个词从左至右来分词。
举个例子:”不知道你在说什么”这句话采用正向最大匹配法是如何分的呢?“不知道,你,在,说什么”。
(2).反向最大匹配法"不知道你在说什么"反向最大匹配法来分上面这段是如何分的。
“不,知道,你在,说,什么”,这个就分的比较多了,反向最大匹配法就是从右至左。
(3).就是最短路径分词法。
就是说一段话里面要求切出的词数是最少的。
“不知道你在说什么”最短路径分词法就是指,把上面那句话分成的词要是最少的。
“不知道,你在,说什么”,这就是最短路径分词法,分出来就只有3个词了。
(4).双向最大匹配法。
而有一种特殊的情况,就是关键词前后组合内容被认为粘性相差不大,而搜索结果中也同时包含这两组词的话,百度会进行正反向同时进行分词匹配。
二.技术说明Lucene是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎ik :采用了特有的“正向迭代最细粒度切分算法“,多子处理器分析模式。
中文分词入门之字标注法

B 142 I 144榫 B 2觚 B 1萋 B 2 I 8钮 B 4 I 7…msr_ngram 则是标记本身 之间的共现频率,形式如B 2368391I 168205617383686918B B 1027319I B 1254154B 86017I I 427001B I 1255055B 86918I 90186918…注 由于没 尖括 在Wordpress 中被 蔽, 内容 误,谢谢读者bflout的提醒, msr_ngram:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 B 2368391I 1682056<START> 173836<END> 86918B B 1027319I B 1254154B <END> 86017I I 427001B I 1255055<START> B 86918I <END> 901<START> <START> 86918B I B 1039293B B B 408801I I <END> 285B B <END> 18403B I I 215146<START> B I 60460I I B 214861./Character2word.pl -i msr_test.hmmtagging.utf8 -o msr_test.hmmseg.utf8 msr_test.hmmseg.utf8既是最 的 词结果, 形式如帆 东做 中 合 的先行希腊的经济结构较特 沔…当然, 个 标注中文 词的结果好坏 需要利用SIGHAN Bakeoff的score 行评../icwb2-data/scripts/score ../icwb2-data/gold/msr_training_words.utf 8 msr_test_gold.utf8 msr_test.hmmseg.utf8 > msr_hmmseg.score最 的评 结果在msr_hmmseg.score中,总的评 如…=== SUMMARY:=== TOTAL INSERTIONS: 10304=== TOTAL DELETIONS: 7030=== TOTAL SUBSTITUTIONS: 30727=== TOTAL NCHANGE: 48061=== TOTAL TRUE WORD COUNT: 106873=== TOTAL TEST WORD COUNT: 110147=== TOTAL TRUE WORDS RECALL: 0.647=== TOTAL TEST WORDS PRECISION: 0.627=== F MEASURE: 0.637=== OOV Rate: 0.026=== OOV Recall Rate: 0.181=== IV Recall Rate: 0.659### msr_test.hmmseg.utf8 10304 7030 30727 48061 106873 110147 0.647 0.627 0.637 0.026 0.181 0.659结果 忍睹, 过没关系, 要的是思想,当你明白了如何 行 标注中文 词的 计和操 之 ,可 做得改 很多,譬如增 标记集,修改 Citar中 合适的未登录词处理方法,甚 采用 他模型等等等等沔 ,52nlp 在合适的时候 绍一 最大熵模型和条件随机场在中文 词中的 用, 迎继续关注本博 !23 24 25 26 27 print "Please use: python character_split.py input output"sys.exit()input_file = sys.argv[1]output_file = sys.argv[2]character_split(input_file, output_file)执行毐py吧h欢次 化ha严a化吧优严_否p速i吧.py i化太b该-data/testing/msr_test.utf8 造否严_吧优否吧.否p速i吧.吨吧伙8毑即可得到可用于标注测试的测试语料msr_test.split.utf8, 例如1 2 3 4 5 6 7 8 9 10 帆 东 做 中 合 的 先 行希 腊 的 经 济 结 构 较 特 沔 海 业 雄 踞 全 球 之 首 , 按 计 占 世 界 总 数 的 7 % 沔 外 旅 游 沓 侨 汇 是 经 济 收 入 的 要 部 , 制 业 规 模 相 对 较 小 沔 多 来 , 中 希 贸 易 始 处 于 较 的 水 , 希 腊 几 乎 没 在 中 投 资 沔 十 几 来 , 改 革 开 放 的 中 经 济 高 发 展 , 东 在 崛 起 沔 瓦 西 的 船 只 中 4 % 驶 向 东 , 个 几 乎 都 条 船 停 靠 中 港 口 沔 他 感 到 了 中 经 济 发 展 的 大 潮 沔 他 要 中 人 合 沔他 来 到 中 , 第 一 个 华 的 大 船 沔现在执行最大熵标注脚本即可得到 标注结果./maxent-master/example/postagger/maxent_tagger.py -m msr_tagger.model msr_test.split.utf8 > msr_test.split.tag.utf8msr_test.split.tag.utf8即是标注结果, 例如1 2 3 4 5 6 7 8 9 10 /B 帆/M /M 东/M 做/E /S 中/B /E 合/B /E 的/S 先/B 行/E希/B 腊/E 的/S 经/B 济/E 结/B 构/E 较/S 特/B /E 沔/S海/B /M 业/E 雄/B 踞/E 全/B 球/E 之/S 首/S ,/S 按/S /B /E 计/B 占/E 世/B 界/E 总/B 数/E 的/S /B 7/M %/E 沔/S/B 外/E 旅/B 游/E 沓/S 侨/B 汇/E /B 是/E 经/B 济/E 收/B 入/E 的/S /B 要/E /B /M 部/M /E ,/S 制/B /M 业/E 规/B 模/E 相/B 对/E 较/B 小/E 沔/S 多/B /E 来/S ,/S 中/S 希/S 贸/B 易/E 始/B /E 处/B 于/E 较/B /E 的/S 水/B /E ,/S 希/B 腊/E 几/B 乎/E 没/B /E 在/S 中/B /E 投/B 资/E 沔/S十/B 几/M /E 来/S ,/S 改/B 革/M 开/M 放/E 的/S 中/B /E 经/B 济/E 高/B /E 发/B 展/E ,/S /B 东/E 在/S 崛/B 起/E 沔/S瓦/B 西/M /M /E 的/S 船/B 只/E 中/S /S 4/B /M %/E 驶/S 向/S /B 东/E ,/S /B 个/M /E 几/B 乎/E 都/S /S /S /S 条/S 船/S 停/S 靠/S 中/B /M 港/M 口/E 沔/S他/S 感/B /E 到/S 了/S 中/B /E 经/B 济/E 发/B 展/E 的/S 大/B 潮/E 沔/S38 39output_file = sys.argv[2]character_2_word(input_file, output_file)执行毐py吧h欢次 化ha严a化吧优严_该_太欢严北.py 造否严_吧优否吧.否p速i吧.吧a会.吨吧伙8 造否严_吧优否吧.否p速i吧.吧a会该太欢严北.吨吧伙8毑 即可得到合并 的 词结果msr_test.split.tag2word.utf8, 例如1 2 3 4 5 6 7 8 9 10 帆 东做 中 合 的先行希腊的经济结构较特 沔海 业雄踞全球之首,按 计占世界总数的 7%沔外旅游沓侨汇 是经济收入的 要 部 ,制 业规模相对较小沔多 来,中希贸易始 处于较 的水 ,希腊几乎没 在中 投资沔十几 来,改革开放的中 经济高 发展, 东在崛起沔瓦西 的船只中 4 %驶向 东, 个 几乎都 条船停靠中 港口沔他感 到了中 经济发展的大潮沔他要 中 人合 沔他来到中 , 第一个 华的大船 沔了 个 标注 词结果, 们就可 利用backoff2005的测试脚本来测一 词的效果了./icwb2-data/scripts/score ./icwb2-data/gold/msr_training_words.utf8 ./icwb2-data/gold/msr_test_gold.utf8 msr_test.split.tag2word.utf8 > msr_maxent_segment.score结果如=== SUMMARY:=== TOTAL INSERTIONS: 5343=== TOTAL DELETIONS: 4549=== TOTAL SUBSTITUTIONS: 12661=== TOTAL NCHANGE: 22553=== TOTAL TRUE WORD COUNT: 106873=== TOTAL TEST WORD COUNT: 107667=== TOTAL TRUE WORDS RECALL: 0.839=== TOTAL TEST WORDS PRECISION: 0.833=== F MEASURE: 0.836=== OOV Rate: 0.026=== OOV Recall Rate: 0.565=== IV Recall Rate: 0.846### msr_test.split.tag2word.utf8 5343 4549 12661 22553 106873 107667 0.839 0.833 0.836 0.026 0.565 0.846了 4个文件, 们可 做得 情就 较简单,只要按测试集,训 集的格式准备数据就可 了,特征模板和执行脚本可 套用, 过 简单解读一 几个CRF++文件沔首先来看训 集1 2 3 4 5 6 7 8 9 10 k B日 k Ik I聞 k I社 k I特 k B別 k I顧 k B問 k I4 n B第一列是待 词的日文 ,第 列暂且认 是词性标记,第 列是 标注中的2-tag(B, I)标记, 个很 要,对于 们需要准备的训 集, 要是把 一列的标记做好, 过需要注意的是, 断 是靠空行来完 的沔再来看测试集的格式1 2 3 4 5 6 7 8 9 10 よ h Iっ h Iて h I私 k Bた h Bち h Iの h B世 k Bk Iが h B3列,第一列是日文 ,第 列第 列 面是相似的, 过在测试集 第 列 要是占 用沔 实 ,CRF++对于训 集和测试集文件格式 的要求是 较灵活的,首先需要多列,但 能 一 ,既在一个文件 的行是 列, 的行是 列 第一列 表的是需要标注的毐 或词毑,最 一列是输出 毑标记吧a会毑,如果 额外的特征,例如词性什 的,可 到中间列 ,所 训 集或者测试集的文件最少要 列沔接 们再来 的 析一 特征模板文件1 2 3 4 # UnigramU00:%x[-2,0]U01:%x[-1,0]U02:%x[0,0]CRF++ 将特征 种类型,一种是Unigram 的,毐月毑起头, 外一种是Bigram 的,毐B毑起头沔对于Unigram 的特征,假如一个特征模板是毑月代令闭还x后-令,代成毐, CRF++ 自动的生 一 特征函数进伙吨次化令 … 伙吨次化N远 集合:1 2 3 4 5 func1 = if (output = B and feature="U01:日") return 1 else return 0func2 = if (output = I and feature="U01:日") return 1 else return 0....funcXX = if (output = B and feature="U01:問") return 1 else return 0funcXY = if (output = I and feature="U01:問") return 1 else return 0生 的特征函数的数目 = (L * N), 中L 是输出的类型的个数, 是B ,I 个tag ,N 是通过模板扩展出来的所 单个 符串(特征 的个数, 指的是在 描所 训 集的过程中找到的日文 特征 沔而Bigram 特征 要是当前的token 和前面一个 置token 的自动 合生 的bigram 特征集合沔最 需要注意的是U01和U02 标 志 , 特征token 合到一起 要是区 毐月代令闭問毑和毐月代该闭問毑 类特征,虽然抽 的日文毑 毑特征是一 的,但是在CRF++中 是 区别 的特征沔最 们再来看一 执行脚本1 2 3 4 5 6 7 #!/bin/sh../../crf_learn -f 3 -c 4.0 template train.data model../../crf_test -m model test.data../../crf_learn -a MIRA -f 3 template train.data model../../crf_test -m model test.datarm -f model执行脚本告诉了 们如何训 一个CRF 模型, 如何利用 个模型来 行测试,执行 个脚本之 ,对于输入的测试集,输出结果多了一列1 2 3 4 5 6 7 8 9 10 よ h I Bっ h I Iて h I B私 k B Bた h B Bち h I Iの h B B世 k B Bk I Iが h B B15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 word_list = line.strip().split()for word in word_list:if len(word) == 1:output_data.write(word + "\tS\n")else:output_data.write(word[0] + "\tB\n")for w in word[1:len(word)-1]:output_data.write(w + "\tM\n")output_data.write(word[len(word)-1] + "\tE\n")output_data.write("\n")input_data.close()output_data.close()if __name__ == '__main__':if len(sys.argv) != 3:print "pls use: python make_crf_train_data.py input output"sys.exit()input_file = sys.argv[1]output_file = sys.argv[2]character_tagging(input_file, output_file)只需要执行毐py吧h欢次make_crf_train_data.py ./icwb2-data/training/msr_training.utf8 造否严_吧严ai次i次会.吧a会会i次会4化严伙.吨吧伙8毑 即可得到CRF++要求的格式的训 文件msr_training.tagging4crf.utf8, 例如1 2 3 4 5 6 7 8 9 10 11 “ S人 B们 E常 S说 S生 B活 E是 S一 S部 S...了 份训 语料,就可 利用crf 的训 工 crf_learn 来训 模型了,执行如 命 即可crf_learn -f 3 -c 4.0 template msr_training.tagging4crf.utf8 crf_model 训 的时间稍微 长,在 的4G 内 的mac pro 跑了将 700 ,大 2个小时,最 训 的crf_model 51M 沔 了模型,现在 们需要做得 是7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38import codecsimport sysdef character_2_word(input_file, output_file):input_data = codecs.open(input_file, 'r', 'utf-8')output_data = codecs.open(output_file, 'w', 'utf-8')for line in input_data.readlines():if line == "\n":output_data.write("\n")else:char_tag_pair = line.strip().split('\t')char = char_tag_pair[0]tag = char_tag_pair[2]if tag == 'B':output_data.write(' ' + char)elif tag == 'M':output_data.write(char)elif tag == 'E':output_data.write(char + ' ')else: # tag == 'S'output_data.write(' ' + char + ' ')input_data.close()output_data.close()if __name__ == '__main__':if len(sys.argv) != 3:print "pls use: python crf_data_2_word.py input output"sys.exit()input_file = sys.argv[1]output_file = sys.argv[2]character_2_word(input_file, output_file)只需执行毐py吧h欢次 化严伙_北a吧a_该_太欢严北.py 造否严_吧优否吧4化严伙.吧a会.吨吧伙8造否严_吧优否吧4化严伙.吧a会该太欢严北.吨吧伙8毑 即可得到合并 的 词结果文件msr_test4crf.tag2word.utf8, 例如1 2 3 4 5 6 7 帆 东 做 中 合 的 先行希腊 的 经济 结构 较 特 沔海 业 雄踞 全球 之 首 , 按 计 占 世界 总数 的 7% 沔 外 旅游 沓 侨汇 是 经济 收入 的 要 部 , 制 业 规模 相对 较小 沔多 来 , 中 希 贸易 始 处于 较 的 水 , 希腊 几乎 没 在 中 投资 沔7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 # 4 tags for character tagging: B(Begin), E(End), M(Middle), S(Single)import codecsimport sysimport CRFPPdef crf_segmenter(input_file, output_file, tagger):input_data = codecs.open(input_file, 'r', 'utf-8')output_data = codecs.open(output_file, 'w', 'utf-8')for line in input_data.readlines():tagger.clear()for word in line.strip():word = word.strip()if word:tagger.add((word + "\to\tB").encode('utf-8'))tagger.parse()size = tagger.size()xsize = tagger.xsize()for i in range(0, size):for j in range(0, xsize):char = tagger.x(i, j).decode('utf-8')tag = tagger.y2(i)if tag == 'B':output_data.write(' ' + char)elif tag == 'M':output_data.write(char)elif tag == 'E':output_data.write(char + ' ')else: # tag == 'S'output_data.write(' ' + char + ' ')output_data.write('\n')input_data.close()output_data.close()if __name__ == '__main__':if len(sys.argv) != 4:print "pls use: python crf_segmenter.py model input output"sys.exit()crf_model = sys.argv[1]input_file = sys.argv[2]output_file = sys.argv[3]tagger = CRFPP.Tagger("-m " + crf_model)crf_segmenter(input_file, output_file, tagger)。
jieba分词用法

jieba分词用法一、jieba简介jieba是一个非常优秀的中文分词工具库,支持Python2和Python3,可以快速准确地实现中文分词。
在自然语言处理领域,分词是基础又关键的一步,jieba 分词能够满足绝大多数场景的使用需求。
二、jieba安装要使用jieba,首先需要在Python环境中安装它。
可以通过以下命令使用pip安装jieba:```shellpipinstalljieba```1.安装完jieba后,可以在Python代码中导入它:```pythonimportjieba```2.使用jieba进行分词,可以直接对一个句子或字符串进行分词,也可以对文件中的文本进行分词。
以下是一些基本用法示例:```python#示例1:对单个句子进行分词sentence="我是一只小小鸟,想要飞呀飞"seg_list=jieba.cut(sentence)#使用默认的分词模式进行分词print("DefaultMode:"+"/".join(seg_list))#输出分词结果#示例2:对文件中的文本进行分词withopen("example.txt","r",encoding="utf-8")asf:content=f.read()seg_list=jieba.cut(content)#使用默认的分词模式进行分词,并使用停用词列表进行过滤print("FilteredMode:"+"/".join(seg_list))#输出过滤后的分词结果```默认的分词模式会使用jieba自带的停用词列表进行过滤,如果你希望使用自己的停用词列表,可以将它作为参数传递给`cut`函数。
另外,jieba还支持多种分词模式,如精确模式、搜索引擎模式和全模式等,可以根据实际需求选择合适的模式。
中文分词辅导教案模板范文

课时:2课时教学目标:1. 理解中文分词的基本概念和意义。
2. 掌握中文分词的方法和技巧。
3. 能够运用中文分词工具进行实际操作。
教学重点:1. 中文分词的基本概念和方法。
2. 中文分词工具的使用。
教学难点:1. 中文分词的技巧和策略。
2. 中文分词工具的灵活运用。
教学准备:1. 多媒体课件。
2. 中文分词工具(如:jieba、ICTCLAS等)。
3. 实例文本。
教学过程:第一课时:一、导入1. 提问:什么是中文分词?2. 学生回答,教师总结。
二、中文分词的基本概念1. 介绍中文分词的定义、意义和作用。
2. 讲解中文分词的分类:最大匹配法、最小匹配法、双向匹配法等。
三、中文分词的方法和技巧1. 介绍最大匹配法、最小匹配法、双向匹配法等方法的原理和特点。
2. 通过实例讲解如何运用这些方法进行中文分词。
四、中文分词工具的使用1. 介绍常用的中文分词工具(如:jieba、ICTCLAS等)。
2. 演示如何使用这些工具进行中文分词。
五、课堂练习1. 学生分组,每组选择一篇实例文本进行中文分词。
2. 各组汇报结果,教师点评。
第二课时:一、复习上节课内容1. 提问:上节课我们学习了哪些中文分词的方法和技巧?2. 学生回答,教师总结。
二、中文分词的技巧和策略1. 讲解如何提高中文分词的准确性。
2. 分析不同场景下的中文分词策略。
三、中文分词工具的灵活运用1. 讲解如何根据实际需求选择合适的中文分词工具。
2. 通过实例演示如何调整工具参数,以达到最佳分词效果。
四、课堂练习1. 学生分组,每组选择一篇实际文本进行中文分词。
2. 各组汇报结果,教师点评。
五、总结1. 总结本节课所学内容。
2. 强调中文分词在实际应用中的重要性。
教学反思:1. 本节课是否达到了教学目标?2. 学生是否掌握了中文分词的基本概念、方法和技巧?3. 如何改进教学,提高教学效果?教学评价:1. 学生对中文分词的理解程度。
2. 学生运用中文分词工具进行实际操作的能力。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
索源网/ 中文分词基础件(基础版)使用说明书北京索源无限科技有限公司2009年1月目录1 产品简介 (3)2 使用方法 (3)2.1 词库文件 (3)2.2 使用流程 (3)2.3 试用和注册 (3)3 接口简介 (4)4 API接口详解 (4)4.1初始化和释放接口 (4)4.1.1 初始化分词模块 (4)4.1.2 释放分词模块 (4)4.2 切分接口 (5)4.2.1 机械分词算法 (5)4.3 注册接口 (8)5 限制条件 (9)6 附录 (9)6.1 切分方法定义 (9)6.2 返回值定义 (9)6.3 切分单元类型定义 (9)1 产品简介索源中文智能分词产品是索源网(北京索源无限科技有限公司)在中文信息处理领域以及搜索领域多年研究和技术积累的基础上推出的智能分词基础件。
该产品不仅包含了本公司结合多种分词研发理念研制的、拥有极高切分精度的智能分词算法,而且为了适应不同需求,还包含多种极高效的基本分词算法供用户比较和选用。
同时,本产品还提供了在线自定义扩展词库以及一系列便于处理海量数据的接口。
该产品适合在中文信息处理领域从事产品开发、技术研究的公司、机构和研究单位使用,用户可在该产品基础上进行方便的二次开发。
为满足用户不同的需求,本产品包括了基础版、增强版、专业版和行业应用版等不同版本。
其中基础版仅包含基本分词算法,适用于对切分速度要求较高而对切分精度要求略低的环境(正、逆向最大匹配)或需要所有切分结果的环境(全切分)。
增强版在基础版的基础上包含了我公司自主开发的复合分词算法,可以有效消除切分歧义。
专业版提供智能复合分词算法,较之增强版增加了未登录词识别功能,进一步提高了切分精度。
行业应用版提供我公司多年积累的包含大量各行业关键词的扩展词库,非常适合面向行业应用的用户选用。
2 使用方法2.1 词库文件本产品提供了配套词库文件,使用时必须把词库文件放在指定路径中的“DictFolder”文件夹下。
产品发布时默认配置在产品路径下。
2.2 使用流程产品使用流程如下:1)初始化首先调用初始化函数,通过初始化函数的参数配置词库路径、切分方法、是否使用扩展词库以及使用扩展词库时扩展词的保存方式等。
经初始化后获得模块句柄。
2)使用分词函数初始化后可反复调用各分词函数。
在调用任何函数时必要把模块句柄传入到待调用函数中。
3)退出系统在退出系统前需调用释放函数释放模块句柄。
2.3 试用和注册本产品初始提供的系统是试用版。
在试用版中,调用分词函数的次数受到限制。
用户必须向索源购买本产品,获取注册码进行注册后,方可正常使用本产品。
注册流程为:1)调用序列号获取接口函数获取产品序列号;2)购买产品,并将产品序列号发给索源。
索源确认购买后,生成注册码发给用户;3)用户使用注册码,调用注册接口对产品进行注册;4)注册成功后,正常使用本产品。
!注意:本产品有版权保护功能,在使用过程中不要更改本产品的任何数据文件,不要随意更改系统时间。
类似操作可能造成本产品无法正常使用。
3 接口简介本产品提供的接口可以划分为初始化和释放接口、切分接口、扩展词库管理接口和注册接口四部分。
其中初始化和释放接口完成对模块进行初始化和释放工作;切分接口部分既包含了各种可供选用的切分算法,每种算法还包含多种切分结果输出方式;扩展词库管理接口部分允许使用者在线自定义词库,支持在线增删词,批量加词等功能;注册接口供产品注册时使用,可以提取产品序列号和使用注册码注册。
4 API接口详解4.1初始化和释放接口4.1.1 初始化分词模块函数名int InitWordSegment(char *pLibPath, int SegMethod, char *&pSegmentHandle)功能初始化分词模块,传出模块句柄参数说明pLibPath:库路径。
DictFolder文件夹需要放置在此路径下,此参数若为NULL,则默认为系统路径。
SegMethod:切分方法选择。
(切分方法参数参考6.1)pSegmentHandle:传出的分词模块句柄。
把此参数传入各个切分函数,可启动各函数。
返回值SEG_RET_OK (返回值说明参数参考6.2)SEG_ERR_MEM_ALLOCSEG_ERR_OPEN_FILESEG_ERR_READ_FILE函数说明使用本品时均需调用初始化函数使用完毕后调用释放函数,使用时无论调用多少次切分函数,初始化和释放函数调用一次即可。
4.1.2 释放分词模块函数名int UnInitWordSegment(char *pSegmentHandle)功能释放分词模块句柄。
参数 pSegmentHandle:由初始化函数传出的分词模块句柄。
返回值SEG_RET_OKSEG_ERR_OPEN_FILESEG_ERR_WRITE_FILE函数说明释放函数在退出系统时调用一次即可。
4.2 切分接口模块初始化后,就可以反复调用切分函数,为便于使用,本模块每个切分接口都包含2~3种切分结果输出方式。
4.2.1 机械分词算法本模块了包括最大匹配切分,全切分和逆向最大切分等机械分词算法供选用。
同样,为方便使用,每种分词算法还包含若干结果输出方式。
1)正向最大匹配,输出一个切分单元:函数名int MaxSegmentForwardUnit(const unsigned char * pStr, int nLen, char &Type, char *pSegmentHandle)功能运用最大匹配法对输入字符串切分。
参数pStr:待切分字符串。
Strlen:待切分字符串的长度。
Type: 切分单元类型(类型定义见6.3)pSegmentHandle:分词模块句柄返回值SEG_RET_ERROR_FAILSEG_ERR_MEM_ALLOCSEG_ERR_OVERTIMESEG_ERR_INVALIDTIMEnLen一个切分单元长度输出说明本函数相当于在输入字符串上运用最大匹配法截取一个切分单元,并输出该单元类型。
返回值为该单元长度。
2)正向最大匹配,输出切分字符串:函数名int MaxSegmentForwardAll(const unsigned char * pStr, int nLen, unsigned char * pDestBuf, int nDestBufLen, char *pSegmentHandle)功能运用最大匹配法对输入字符串切分。
参数pStr:待切分字符串。
Strlen:待切分字符串的长度。
pDestBuf:切分结果存储空间首地址(该空间需用户自行申请和释放)nDestBufLen:切分结果存储空间长度pSegmentHandle:分词模块句柄返回值SEG_RET_ERROR_FAILSEG_ERR_MEM_ALLOCSEG_ERR_OVERTIMESEG_ERR_INVALIDTIMEnLen实际占用存储空间长度输出说明切分结果以词为单位用空格分开存入已申请的存储空间。
若实际切分结果长度超出预留空间,则存储空间保存了能容纳的最长切分结果。
3)正向最大匹配,输出切分位置:函数名int MaxSegmentForwardAllPos(const unsigned char* pStr, int nLen, unsigned char ** ppDestPosArray, int * pDestWordLen, char* pDestType, intnMaxDestNum, char *pSegmentHandle)功能运用最大匹配法对输入字符串切分。
pStr:待切分字符串。
参数Strlen:待切分字符串的长度。
ppDestPosArray:指针向量首地址(该空间需用户自行申请和释放)pDestWordLen:词长向量首地址(该空间需用户自行申请和释放)pDestType:切分单元类型向量(该空间需用户自行申请和释放)nMaxDestNum:向量长度pSegmentHandle:分词模块句柄返回值SEG_RET_ERROR_FAILSEG_ERR_MEM_ALLOCSEG_ERR_OVERTIMESEG_ERR_INVALIDTIMEnLen有效向量长度输出说明指针向量存储的是每个词在待切分字符串上的首地址,词长向量存储的是每个词对应的词长。
若实际切分出的词数大于向量长度,则向量存储满为止。
4)全切分算法,输出一个切分点所有可能切分单元:函数名int FullSegmentUnit(const unsigned char* pStr,int nLen, int *pDestWordLen, char *pDestType, int & WordNum, char *pSegmentHandle)功能运用全切分算法对输入字符串切分pStr:待切分字符串。
参数Strlen:待切分字符串的长度。
pDestWordLen:词长向量首地址(该空间需用户自行申请和释放)pDestType:切分单元类型向量(该空间需用户自行申请和释放)WordNum:有效词长数量。
pSegmentHandle:分词模块句柄返回值SEG_RET_ERROR_FAILSEG_ERR_MEM_ALLOCSEG_ERR_OVERTIMESEG_ERR_INVALIDTIMEnLen最小切分单元长度输出说明词长向量里包含了以pStr为起点的所有可以成词的词长,WordNum为可成词数量。
5)全切分算法,输出所有可能切分结果组成的字符串:函数名int FullSegmentForwardAll(const unsigned char * pStr, int nLen, unsigned char * pDestBuf, int nDestBufLen, char *pSegmentHandle)功能运用全切分算法对输入字符串切分参数 pStr:待切分字符串。
Strlen:待切分字符串的长度。
pDestBuf:切分结果存储空间首地址(该空间需用户自行申请和释放)nDestBufLen:切分结果存储空间长度。
pSegmentHandle:分词模块句柄返回值SEG_RET_ERROR_FAILSEG_ERR_MEM_ALLOCSEG_ERR_OVERTIMESEG_ERR_INVALIDTIMEnLen实际占用存储空间长度输出说明切分结果以词为单位用空格分开存入已申请的存储空间。
若实际切分结果长度超出预留空间,则存储空间保存了能容纳的最长切分结果。
6)全切分算法,输出所有可能切分结果在待切分字符串中的位置和长度:函数名int FullSegmentForwardAllPos(const unsigned char* pStr, int nLen, unsigned char ** ppDestPosArray, int * pDestWordLen, char *pDestType, intnMaxDestNum, char *pSegmentHandle)功能运用全切分算法对输入字符串切分参数pStr:待切分字符串。