NOIP2011普及组复赛(试题+源程序)
CSP-J(NOIP普及组) 复赛2010-2020考查内容一览表

CSP-J (NOIP普及组) 复赛2010-2020考查内容CSP-J2020序号题名考查内容T1优秀的拆分位运算、进制转换T2直*播*获*奖桶排序T3表达式栈、深搜T4方格取数动态规划(高级)CSP-J2019序号题名考查内容T1数*字*游*戏字符串T2公交换乘模拟、队列T3纪念品背包T4加*工*领*奖广搜、最短路NOIP2018普及组序号题名考查内容T1标题统计字符串T2龙*虎*斗枚举、预处理T3摆渡车动态规划(高级)T4对称二叉树二叉树NOIP2017普及组序号题名考查内容T1成绩顺序结构T2图书管理员结构体排序T3棋盘深搜、剪枝T4跳*房*子二分、动态规划NOIP2016普及组序号题名考查内容T1买铅笔一重循环T2回文日期回文T3海港大模拟、队列T4魔*法*阵枚举、前缀和NOIP2015普及组序号题名考查内容T1金*币一重循环T2扫*雷*游*戏二维数组T3求和组合数学T4推销员贪心、优先队列NOIP2014普及组序号题名考查内容T1珠心算测验模拟T2比例简化枚举、gcdT3螺旋矩阵模拟、找规律T4子矩阵动态规划(高级)NOIP2013普及组序号题名考查内容T1记数问题二重循环T2表达式求值栈T3小朋友的数字动态规划(高级)T4车站分级拓扑排序NOIP2012普及组序号题名考查内容T1质因数分解一重循环、质数T2寻*宝模拟、取模T3摆花背包、动态规划T4文化之旅最短路NOIP2011普及组序号题名考查内容T1数字反转进制转换T2统计单词数字符串T3瑞士轮归并排序T4表达式的值动态规划(高级)、栈NOIP2010普及组序号题名考查内容T1数字统计二维数组T2接水问题模拟T3导*弹*拦*截贪心T4三*国*游*戏贪心、博弈。
全国信息学联赛(NOIP)模拟试题-一试

全国信息学奥林匹克联赛(NOIP2011)复赛提高组模拟模拟试题试题试题(一试)(一试)(请选手务必仔细阅读本页内容)一.题目概况中文题目名称订正作业怪兽对对碰采油区域英文题目与子目录名correct monster oil 可执行文件名correct monster oil 输入文件correct.in monster.in oil.in 输出文件correct.out monster.out oil.out 每个测试点时限1秒1秒 1.5秒测试点数目101010每个测试点分值101010附加样例文件有有有结果比较方式全文比较(过滤行末空格及文末回车)题目类型传统传统传统二.提交源程序文件名三.运行内存限制对于pascal 语言correct.pas ball.pas .pas 对于C 语言correct.c ball.c .c 对于C++语言correct.cppball.cpp.cpp内存上限128M128M128M1.订正作业(correctcorrect.pas/c/cpp).pas/c/cpp)【问题描述】丁丁是个富有爱心的哥哥。
他上小学的弟弟小丁丁刚刚学习了四则运算,并做了作业。
现在小丁丁把自己的作业给了丁丁,请他帮忙检查订正一下作业。
作业题都是一些含有括号的四则运算等式。
丁丁发现他的弟弟对于括号的使用不太明白,在作业中写了不少多余的括号。
现在丁丁的任务是找出这些多余的括号,并把他们擦去。
但是为了尽可能避免自己的笔迹出现,只能改动括号。
要求保持原表达式中变量和运。
另外,由于弟弟在上小学,不必考虑“+”“-”作为正负号的情况。
即输入的表达式中”“-”用于“+X”(正数)或是“-X”(负数)的情况。
也不必考虑式子中有超过20输入文件名为correct.in。
第一行为一个正整数n,表示作业题的数量。
接下来的n行,每行有n个含括号的等式,表示待丁丁订正的作业题。
【输出】输出文件名为correct.out。
2011noip普及组初赛试题(c语言)

第十七届全国青少年信息学奥林匹克联赛初赛试题(普及组●● C 语言两小时完成)一、单项选择题(共20 题,每题 1.5 分,共计30 分。
每题有且仅有一个正确选项。
)1.在二进制下,1100100 + ()= 1110001A. 1011B. 1101C. 1010D. 1111 。
2.字符“0”的ASCII 码为48,则字符“9”的ASCII 码为()A. 39B. 57C. 120D. 视具体的计算机而定3.一片容量为8GB 的SD 卡能存储大约()张大小为2MB 的数码照片。
A. 1600B. 2000C. 4000D. 160004.摩尔定律(Moore's law)是由英特尔创始人之一戈登·摩尔(Gordon Moore)提出来的。
根据摩尔定律,在过去几十年以及在可预测的未来几年,单块集成电路的集成度大约每()个月翻一番。
A. 1B. 6C. 18D. 365.无向完全图是图中每对顶点之间都恰有一条边的简单图。
已知无向完全图G 有7 个顶点,则它共有()条边。
A. 7B. 21C. 42D. 496.寄存器是()的重要组成部分。
A. 硬盘B. 高速缓存C. 内存D. 中央处理器(CPU)7.如果根结点的深度记为1,则一棵恰有2011 个叶结点的二叉树的深度最少是()A. 10B. 11C. 12D. 138. 体育课的铃声响了,同学们都陆续地奔向操场,按老师的要求从高到矮站成一排。
每个同学按顺序来到操场时,都从排尾走向排头,找到第一个比自己高的同学,并站在他的后面。
这种站队的方法类似于()算法。
A. 快速排序B. 插入排序C. 冒泡排序D. 归并排序位。
9.一个正整数在二进制下有100 位,则它在十六进制下有()位。
A. 7B. 13C. 25D. 不能确定10.有人认为,在个人电脑送修前,将文件放入回收站中就是已经将其删除了。
这种想法是()。
A. 正确的,将文件放入回收站意味着彻底删除、无法恢复B. 不正确的,只有将回收站清空后,才意味着彻底删除、无法恢复C. 不正确的,即使将回收站清空,文件只是被标记为删除,仍可能通过恢复软件找回D. 不正确的,只要在硬盘上出现过的文件,永远不可能被彻底删除11.广度优先搜索时,需要用到的数据结构是()。
NOIP2011普及组复赛(精彩试题+源程序)

NOIP2011 普及组复赛1.数字反转(reverse.cpp/c/pas)【问题描述】给定一个整数,请将该数各个位上数字反转得到一个新数。
新数也应满足整数的常见形式,即除非给定的原数为零,否则反转后得到的新数的最高位数字不应为零。
(参见样例2)【输入】输入文件名为reverse.in。
输入共一行,一个整数N。
【输出】输出文件名为reverse.out。
输出共1行,一个整数,表示反转后的新数。
-1,000,000,000≤N≤1,000,000,000。
【解题】这道题非常简单,可以读字符串处理,也可以读数字来处理,只不过要注意符号问题(以及-0,但测试数据没出)。
【法一】字符串处理Var i,l,k:integer;s:string;p:boolean;beginassign(input, 'reverse.in'); reset(input);assign(output, 'reverse.out'); rewrite(output);readln(s);l:=length(s);k:=1;if s[1]='-' thenbeginwrite('-');k:=2;end;p:=true;;for i:=l downto k dobeginif(p)and((s[i]='0')) then continueelsebeginwrite(s[i]);p:=false;;end;end;close(input); close(output);end.【法二】数字处理Var f:integer;n,ans:longint;beginassign(input, 'reverse.in'); reset(input);assign(output, 'reverse.out'); rewrite(output);readln(n);if n<0 thenbeginf:=-1;n:=-n;endelsef:=1;ans:=0;while n<>0 dobeginans:=ans*10+n mod 10;n:=n div 10;end;ans:=ans*f;writeln(ans);close(input); close(output);end.2.统计单词数(stat.pas/c/cpp)【问题描述】一般的文本编辑器都有查找单词的功能,该功能可以快速定位特定单词在文章中的位置,有的还能统计出特定单词在文章中出现的次数。
noip普及组复赛试题及答案

noip普及组复赛试题及答案一、选择题1. 在计算机科学中,以下哪个概念与数据结构最相关?A. 算法B. 操作系统C. 网络协议D. 编译原理答案:A2. 以下哪种排序算法的时间复杂度为O(n^2)?A. 快速排序B. 归并排序C. 堆排序D. 冒泡排序答案:D3. 在C++中,以下哪个关键字用于定义类?A. structB. unionC. enumD. typedef答案:A4. 以下哪个选项不是数据库管理系统(DBMS)的特性?A. 数据持久性B. 数据共享C. 数据加密D. 数据独立性答案:C5. 在计算机网络中,TCP和UDP协议分别属于哪一层?A. 传输层B. 应用层C. 网络层D. 物理层答案:A二、填空题1. 在计算机程序中,______ 用于定义数据的存储方式和组织形式。
答案:数据结构2. 一个算法的时间复杂度为O(1),表示该算法的执行时间与输入数据的规模______。
答案:无关3. 在C++中,______ 是一种特殊的类,它提供了一种方式来定义数据类型。
答案:typedef4. 数据库管理系统(DBMS)通常包含数据定义语言(DDL)、数据操纵语言(DML)和______。
答案:数据控制语言(DCL)5. 在计算机网络中,______ 协议负责在网络层进行数据包的路由选择。
答案:IP三、简答题1. 请简述面向对象编程(OOP)的三个基本特征。
答案:封装、继承、多态2. 描述二分查找算法的基本步骤。
答案:二分查找算法的基本步骤包括:首先确定数组是有序的,然后取中间元素与目标值比较,如果中间元素等于目标值,则查找成功;如果目标值小于中间元素,则在左半部分继续查找;如果目标值大于中间元素,则在右半部分继续查找,直到找到目标值或查找范围为空。
四、编程题1. 编写一个函数,实现对整数数组的排序。
答案:以下是一个简单的冒泡排序算法实现:```cppvoid bubbleSort(int arr[], int n) {for (int i = 0; i < n-1; i++) {for (int j = 0; j < n-i-1; j++) {if (arr[j] > arr[j+1]) {swap(arr[j], arr[j+1]);}}}}```2. 编写一个函数,实现计算一个整数的阶乘。
NOIP2011普及组复赛试题+源程序

NOIP2011 普及组复赛1.数字反转(reverse.cpp/c/pas )【问题描述】给定一个整数,请将该数各个位上数字反转得到一个新数。
新数也应满足整数的常见形式,即除非给定的原数为零,否则反转后得到的新数的最高位数字不应为零。
(参见样例2)【输入】输入文件名为reverse.in。
输入共一行,一个整数N。
【输出】输出文件名为reverse.out。
输出共1行,一个整数,表示反转后的新数。
【输入输出样例1】据范围】-1,000,000,000WNW1,000,000,000。
【解题】这道题非常简单,可以读字符串处理,也可以读数字来处理,只不过要注意符号问题(以及~0,但测试数据没出)。
【法一】字符串处理Var i,l,k:integer;s:string;p:boolean;beginassign(input, 'reverse.in'); reset(input);assign(output, 'reverse.out'); rewrite(output);readln(s);l:=length(s);k:=1;if s[1]='-' thenbeginwrite('-');k:=2;end;p:=true;;for i:=l downto k dobeginif(p)and((s[i]='0')) then continue elsebegin write(s[i]); p:=false;;end;end;close(input); close(output);end.【法二】数字处理Var f:integer;n,ans:longint;begin assign(input, 'reverse.in'); reset(input);assign(output, 'reverse.out'); rewrite(output); readln(n);if n<0 then begin f:=-1; n:=-n;endelsef:=1;ans:=0;while n<>0 do beginans:=ans*10+n mod 10;n:=n div 10;end;ans:=ans*f;writeln(ans);close(input); close(output);end.2.统计单词数(stat.pas/c/cpp)【问题描述】一般的文本编辑器都有查找单词的功能,该功能可以快速定位特定单词在文章中的位置,有的还能统计出特定单词在文章中出现的次数。
NOIP2011模拟试题及解析

NOIP2011模拟试题及解析128MClass(class.pas/c/cpp)【问题描述】信息班这期的课将要结束了,老师要从现在班上的同学中选出比较优秀的同学进入下一期的学习。
而录取标准则是将平时作业和考试一起考虑,综合成绩排在前面的则录取。
经过一番思考,老师作了以下的筛选计划:1、设计两个参数x,y,学生总成绩为平时成绩的x%和考试成绩的y%。
2、将同学按总成绩排名,招收总成绩在前15的学生,不够15则全部录取。
注:总成绩在第15的如果有多人,则可以被同时录取。
例如:18个人总成绩从大到小依次为95,93,93,88,87,84,80,75,70,68,66,65,60,58,57,57,56,55。
那么93,93同为第2名,而88为第4名,57,57同为第15名,都被录取。
而56,55则不被录取。
老师因为招生培训的事情很忙,所以现在她把信息班学生的成绩表给了你,希望你能告诉她哪些同学被录取了。
【输入】输入文件class.in第一行有三个数N,x,y。
表示信息班有N个同学以及参数x,y。
第二行N个数,分别为A1,A2,A3 … AN。
Ai表示编号为i的同学的平时成绩。
第三行N个数,分别为B1,B2,B3 … BN。
Bi表示编号为i的同学的考试成绩。
【输出】输出文件class.out共一行,为被录取同学的编号,按照升序输出。
【输入输出样例】【数据说明】1<=N<=1000<=x,y<=1000<=平时成绩,考试成绩<=100以上数据皆为整数模拟。
首先求出所有人的总分,然后进行快排(注意第15名的并列情况),人数小于15时,输出1到n;否则将入围人员的编号进行排序升序输出。
程序如下:program zk;varp,k,h,zong:array [0..200] of longint;i,j,a,b,c,n,x,y,xian,f:longint;procedure qsort(x,y:longint);varxo,yo,zz,mid,z:longint;beginxo:=x; yo:=y;mid:=zong[(xo+yo) div 2];repeatwhile zong[xo]>mid do inc(xo);while zong[yo]<mid do dec(yo);if xo<=yo thenbeginz:=zong[xo];zong[xo]:=zong[yo];zong[yo]:=z;zz:=h[xo];h[xo]:=h[yo];h[yo]:=zz;inc(xo); dec(yo);end;until xo>yo;if x<yo then qsort(x,yo);if xo<y then qsort(xo,y);end;procedure qsorth(x,y:longint); varxo,yo,zz,mid,z:longint;beginxo:=x; yo:=y;mid:=h[(xo+yo) div 2]; repeatwhile h[xo]<mid do inc(xo);while h[yo]>mid do dec(yo);if xo<=yo thenbeginzz:=h[xo];h[xo]:=h[yo];h[yo]:=zz;inc(xo); dec(yo);end;until xo>yo;if x<yo then qsorth(x,yo);if xo<y then qsorth(xo,y); end;beginassign(input,'class.in'); assign(output,'class.out'); reset(input);rewrite(output);readln(n,x,y);for i:=1 to n doread(p[i]);readln;for i:=1 to n dobeginh[i]:=i;read(k[i]);end;for i:=1 to n dozong[i]:=p[i]*x+k[i]*y;qsort(1,n);xian:=15;if n>=15 thenbeginf:=zong[xian];while zong[xian+1]=f doxian:=xian+1;endelse xian:=n;qsorth(1,xian);for i:=1 to xian dowrite(h[i],' ');close(input);close(output);end.Clean(clean.pas/c/cpp)【问题描述】最近甲型H1N1流感病毒肆虐。
最新NOIP复赛普及组试题资料
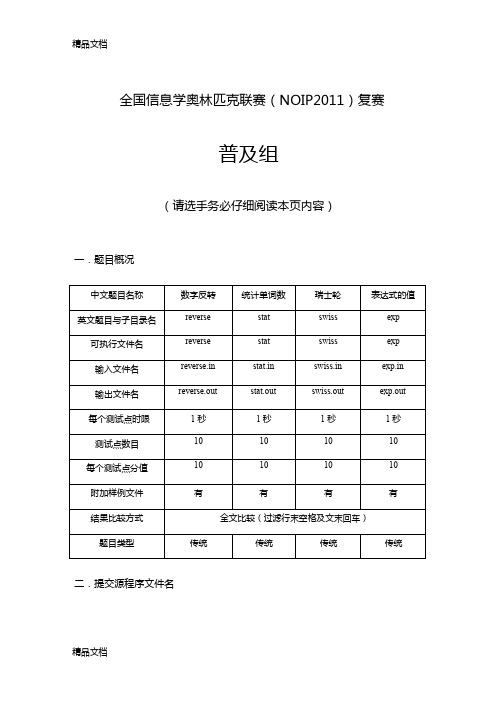
全国信息学奥林匹克联赛(NOIP2011)复赛普及组(请选手务必仔细阅读本页内容)一.题目概况二.提交源程序文件名三.编译命令(不包含任何优化开关)四.运行内存限制注意事项:1、文件名(程序名和输入输出文件名)必须使用英文小写。
2、C/C++中函数main()的返回值类型必须是int,程序正常结束时的返回值必须是0。
3、全国统一评测时采用的机器配置为:CPU P4 3.0GHz,内存1G,上述时限以此配置为准。
4、特别提醒:评测在NOI Linux 下进行。
1.数字反转(reverse.cpp/c/pas)【问题描述】给定一个整数,请将该数各个位上数字反转得到一个新数。
新数也应满足整数的常见形式,即除非给定的原数为零,否则反转后得到的新数的最高位数字不应为零(参见样例2)。
【输入】输入文件名为reverse.in。
输入共1 行,一个整数N。
【输出】输出文件名为reverse.out。
输出共1 行,一个整数,表示反转后的新数。
【输入输出样例1】【输入输出样例2】【数据范围】-1,000,000,000 ≤ N ≤ 1,000,000,000。
2.统计单词数(stat.cpp/c/pas)【问题描述】一般的文本编辑器都有查找单词的功能,该功能可以快速定位特定单词在文章中的位置,有的还能统计出特定单词在文章中出现的次数。
现在,请你编程实现这一功能,具体要求是:给定一个单词,请你输出它在给定的文章中出现的次数和第一次出现的位置。
注意:匹配单词时,不区分大小写,但要求完全匹配,即给定单词必须与文章中的某一独立单词在不区分大小写的情况下完全相同(参见样例1),如果给定单词仅是文章中某一单词的一部分则不算匹配(参见样例2)。
【输入】输入文件名为stat.in,2 行。
第1 行为一个字符串,其中只含字母,表示给定单词;第2 行为一个字符串,其中只可能包含字母和空格,表示给定的文章。
【输出】输出文件名为stat.out。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
NOIP2011 普及组复赛1 .数字反转(reverse.cpp/c/pas )【问题描述】给定一个整数,请将该数各个位上数字反转得到一个新数。
新数也应满足整数的常见形式,即除非给定的原数为零,否则反转后得到的新数的最高位数字不应为零。
(参见样例2)【输入】输入文件名为reverse. in 。
输入共一行,一个整数No【输出】输出文件名为reverse.out 。
输出共1行,一个整数,表示反转后的新数。
【输入输出样例1】-1,000,000,000 < N< 1,000,000,000 。
【解题】这道题非常简单,可以读字符串处理,也可以读数字来处理,只不过要注意符号问题(以及但测试数据没出)。
-0 , 【法一】字符串处理Var i,l,k:i nteger;s:stri ng;p:boolea n;beginassig n(i nput, 'reverse.i n'); reset(i nput);assig n(o utput, 'reverse.out'); rewrite(output);readl n( s);l:=le ngth(s);k:=1;if s[1]=' -' the nbeginwrite('-');k:=2;en d;p:=true;;for i:=l dow nto k dobeginif(p)a nd((s[i]='0')) the n continueelsebeginwrite(s[i]); p:=false;;en d;en d;close(i nput); close(output);en d.【法二】数字处理Var f:i nteger;n,an s:lo ngint;beginassig n(i nput, 'reverse.i n'); reset(i nput);assig n(o utput, 'reverse.out'); rewrite(output);readl n(n);if n<0 the nbegin f:=-1; n :=-n;endelsef:=1;an s:=0;while n<>0 dobeginan s:=a ns*10+n mod 10; n:=n div 10;en d;an s:=a ns*f;writel n(a ns);close(i nput); close(output);en d.2.统计单词数(stat.pas/c/cpp)【问题描述】一般的文本编辑器都有查找单词的功能,该功能可以快速定位特定单词在文章中的位置,有的还能统计出特定单词在文章中出现的次数。
现在,请你编程实现这一功能,具体要求是:给定一个单词,请你输出它在给定的文章中出现的次数和第一次出现的位置。
注意:匹配单词时,不区分大小写,但要求完全匹配,即给定单词必须与文章中的某一独立单词在不区分大小写的情况下完全相同(参见样例1),如果给定单词仅是文章中某一单词的一部分则不算匹配(参见样例2)【输入】输入文件名为stat.in, 2行。
第1行为一个字符串,其中只含字母,表示给定单词;第2行为一个字符串,其中只可能包含字母和空格,表示给定的文章。
【输出】输出文件名为stat.out。
只有一行,如果在文章中找到给定单词则输出两个整数,两个整数之间用一个空格隔开,分别是单词在文章中出现的次数和第一次出现的位置(即在文章中第一次出现时,单词首字母在文章中的位置,位置从0开始);如果单词在文章中没有出现,则直接输出一个整数-1。
【输入输出样例1】1输出结果表示给定的单词To在文章中出现两次,第一次出现的位置为0。
2表示给定的单词to在文章中没有出现,输出整数-1。
【数据范围】1W单词长度w 10。
1W文章长度w 1,000,000。
【解题】这道题也不是很难,program stat; var l,n, p:l ongint;s,s1:stri ng; c:char;beginassig n(i nput,'stat.i n'); reset(i nput);assig n(o utput,'stat.out'); rewrite(output);readl n( s);s:=upcase(s); // 函数upcase() 参数可为char,也可为stringi:=-1; //i统计读入的字符位置,首个字符出现的位置是0s1:=”;〃s1累加读入的字符n:=0; 〃n统计出现次数p:=-1; 〃p标记第一次出现的位置repeatread(c);c:=upcase(c); // 统一大小写i:=i+1;if c=' ' the n //遇到空格,匹配是否相同beginif s=s1 the nbeginn:=n+1;if p=-1 then 〃p标记第一次出现的位置,如果p是第一次更改,记录位置p:=i-le ngth(s);en d;s1:=";endelses1:=s1+c; //不是空格,继续叠加un til eoln (i nput);if s1=s then //处理最后一个单词是否相同的情况beginn:=n+1;if p=-1 the np:=i-le ngth(s) +1; // 最后没有空格en d;if n=0 then writel n(-1)else writel n(n,' ',p);close(i nput);close(output);en d.3.瑞士轮(swiss.cpp/c/pas)【背景】在双人对决的竞技性比赛,如乒乓球、羽毛球、国际象棋中,最常见的赛制是淘汰赛和循环赛。
前者的特点是比赛场数少,每场都紧张刺激,但偶然性较高。
后者的特点是较为公平,偶然性较低,但比赛过程往往十分冗长。
本题中介绍的瑞士轮赛制,因最早使用于1895年在瑞士举办的国际象棋比赛而得名。
它可以看作是淘汰赛与循环赛的折衷,既保证了比赛的稳定性,又能使赛程不至于过长。
【问题描述】2*N名编号为1~2N的选手共进行R轮比赛。
每轮比赛开始前,以及所有比赛结束后,都会按照总分从高到低对选手进行一次排名。
选手的总分为第一轮开始前的初始分数加上已参加过的所有比赛的得分和。
总分相同的,约定编号较小的选手排名靠前。
每轮比赛的对阵安排与该轮比赛开始前的排名有关:第1名和第2名、第3名和第4名、……、第2K - 1名和第2K名、……、第2N - 1名和第2N名,各进行一场比赛。
每场比赛胜者得1分,负者得0分。
也就是说除了首轮以外,其它轮比赛的安排均不能事先确定,而是要取决于选手在之前比赛中的表现。
现给定每个选手的初始分数及其实力值,试计算在R轮比赛过后,排名第Q的选手编号是多少。
我们假设选手的实力值两两不同,且每场比赛中实力值较高的总能获胜。
【输入】输入文件名为swiss.in 。
输入的第一行是三个正整数N、R、Q,每两个数之间用一个空格隔开,表示有2*N名选手、R轮比赛,以及我们关心的名次Q。
第二行是2*N个非负整数S1, S2,…,S N,每两个数之间用一个空格隔开,其中s表示编号为i的选手的初始分数。
第三行是2*N个正整数W1, W2,…,WN,每两个数之间用一个空格隔开,其中wi表示编号为i的选手的实力值。
【输出】输出文件名为swiss.out 。
输出只有一行,包含一个整数,即R轮比赛结束后,排名第Q的选手的编号。
【输入输出样例】【输入输出样例说明】【数据范围】对于30%的数据,1 < N < 100;对于50%的数据,1 < N< 10,000;对于100%的数据,1 < N < 100,000, K R< 50, K Q< 2N, 0< S1, S2,…,S N w 108, K w1,W2,…,ww 108。
【解题】题目虽然长,但理解题意后就发现解题的瓶颈在于排序。
如果每一轮比赛的结果都进行快速排序,时间复杂度为0 (Rlongn ),但事实证明这样只能拿60分。
如何AC,这需要一个巧算法:分析得知,快速排序实际上进行了许多无用的工作:如果两个人在第i轮都赢了,那么第i轮后的先后关系与第i-1轮是一样的;反之,如果两人都输了,他们的先后关系也不会变。
所以,我们有一个新算法:一开始做一趟快速排序,然后对于每一轮,将此轮的n个赢者(他们的先后关系和上一轮不变)和n个输者(他们的先后关系和上一轮也不变分开,然后就是归并,于是时间复杂度0 (Rn)) (实践证明,如果单纯的排序r次,必然结果是超时。
事实上只需一次真正意义上的排序以后,在以后的比赛中,按原顺序分成两组,获胜组和失败组,这两组依然是有序的,再把这两组归并成一组,就可以了。
总时间复杂度O(N*R)program swiss;var a,b,v:array[1..200000]of Ion gi nt;c,d:array[1..100000,1..2]of Ion gi nt;n ,r,q,i,j:l on gi nt;procedure qsort(l,r:l ongin t); var i,j,mid1,mid2,t:lo ngint; begini:=l;j:=r; mid1:=a[(l+r)div 2]; mid2:=v[(l+r)div 2];repeat 〃按分数从高到低排序,分数相同的,编号较小的选手排名靠前while (a[i]>mid1) or (a[i]=mid1) and (v[i]<mid2) do in c(i);while (a[j]<mid1) or (a[j]=mid1) and (v[j]>mid2) do dec(j);if i<=j the nbegint:=a[i]; a[i]:=a[j]; a[j]:=t;t:=v[i]; v[i]:=v[j]; v[j]:=t;in c(i); dec(j);en d;un til i>j;if i<r the n qsort(i,r);if l<j then qsort(l,j);en d;procedure mergesort; // 归并排序var i,l1,l2:lo ngi nt; begini:=0; l1:=1; l2:=1; repeatif (c[l1,1]>d[l2,1])or (c[l1,1]=d[l2,1])a nd(c[l1,2]<d[l2,2]) then begini:=i+1;a[i]:=c[l1,1]; v[i]:=c[l1,2]; 11:=11+1; end elsebegini:=i+1;a[i]:=d[l2,1]; v[i]:=d[l2,2]; 12:=12+1; en d;un til (l1> n)or(l2> n); while l1<=n dobegini:=i+1;a[i]:=c[l1,1]; v[i]:=c[l1,2]; 11:=11+1; en d; while l2<=n dobegini:=i+1;a[i]:=d[l2,1]; v[i]:=d[l2,2]; 12:=12+1; en d; en d;begin//王程序assig n(i nput,'swiss.i n');reset(i nput); assig n(o utput,'swiss.out');rewrite(output);c[j,1]:=a[2*j]; c[j,2]:=v[2*j]; d[j,1]:=a[2*j-1];readl n(n ,r,q);for i:= 1 to n*2 do read(a[i]); for i:= 1 to n*2 do read(b[i]); for i:=1 to n*2 do v[i]:=i; qsort(1,2* n); for i:= 1 to r dobeginfor j:= 1 to n doif b[v[2*j-1]]>b[v[2*j]] thenbeginin c(a[2*j-1]); c[j,1]:=a[2*j-1]; c[j,2]:=v[2*j-1]; d[j,1]:=a[2*j]; d[j,2]:=v[2*j]; endelsebeginin c(a[2*j]);//数组a 保存初始分数〃数组b 保存实力值〃数组v[i]保存排名第i 的选手编号〃数组c[j,1]保存嬴方的总分;数组 〃数组d[j,1]保存输方的总分;数组c[j,2]保存嬴方的号码;d[j,2]保存输方的号码;d[j,2]:=v[2*j-1]; en d;mergesort;en d;writel n(v[q]);close(i nput);close(output); en d.4.表达式的值(exp.cpp/c/pas)【问题描述】1运算的优先级是:1.先计算括号内的,再计算括号外的。