《生物统计学》实验指导
《生物统计附实验设计》实验指导书(生物)

目录实验一 Excel常用生物统计功能简介及应用 (2)实验二方差分析 (9)实验三单因素试验结果分析 (13)实验四多因素试验结果分析 (17)实验五直线回归与相关 (20)实验六 DPS 统计分析软件的应用 (22)常用统计分析软件研究性学习提示 (35)统计网站 (38)参考文献 (39)实验一Excel常用生物统计功能简介及应用1. 实验目的及要求:1.1 实验目的:通过上机作业,掌握Excel常用生物统计功能的应用方法。
1.2 实验要求:根据实验原理,按照实验方法与步骤独立完成作业。
1.3 实验规定学时:4学时1.4 实验性质:综合2. 实验原理:Microft Excel电子表格虽然不是专门的统计软件,但其具有丰富的统计分析功能,界面中文表述,操作简易,可以利用其内置的“分析工具库”进行生物统计中常用的t检验、方差分析、回归分析和次数分布表与直方图的编制等。
2.1 Excel 分析工具库的安装Excel提供了一组统计分析工具,称为“分析工具库”,可以利用其进行统计中常用的t检验、方差分析、回归分析和次数分布表与直方图的编制等。
分析工具库需安装后才可以使用。
打开Excel工作表,在菜单栏单击“工具”选项,如果存在“数据分析”条目,表示分析工具库已经安装,若无,可在“工具”菜单中单击“加载宏”命令,在“加载宏”对话框中选中“分析工具库”,单击“确定”按钮(有的需要插入Excel安装光盘),在“工具”菜单中即出现“数据分析”条目。
2.2 分析工具库的运行及主要统计分析方法在“工具”菜单中单击“数据分析”选项,弹出“数据分析”对话框(见图1),其主要统计分析方法有:(1)方差分析:单因素方差分析、交叉分组有重复双因素方差分析、交叉分组无重复双因素方差分析。
(2)描述统计:计算平均数,标准差等常用统计量。
(3)t检验:配对资料的t检验、等方差非配对资料的t检验、异方差非配对资料的t检验等。
(4)计算多个变量两两之间的相关系数。
生物统计学中的实验设计与数据分析方法

生物统计学中的实验设计与数据分析方法一、引言生物统计学作为一门重要的学科,运用统计学的原理和方法来解决生物科学领域的研究问题。
在生物学研究中,实验设计与数据分析方法起着至关重要的作用。
本文将介绍生物统计学中常用的实验设计与数据分析方法。
二、实验设计实验设计是生物研究中最重要的环节之一,合理的实验设计可以保证实验结果的可靠性和科学性。
在生物统计学中常用的实验设计方法包括随机分组设计、区组设计和因子设计等。
1. 随机分组设计随机分组设计是最常见的实验设计方法之一。
它通过将实验对象随机分为若干组,每组进行相同的处理,以消除非实验因素对实验结果的影响。
随机分组设计通常用于比较不同处理间的差异。
2. 区组设计区组设计是处理两个或更多变量时常用的实验设计方法。
其通过将实验对象进行分组,每组内部处理相同,不同组之间处理不同,以减小因组内差异对实验结果的影响。
区组设计常用于对实验因素和区组效应进行分析。
3. 因子设计因子设计是通过改变实验的因子(自变量)来观察和研究不同因子对结果的影响。
在因子设计中,通过对不同水平的因子进行处理,可以分析因子对结果的主效应和交互效应。
三、数据收集与处理在生物统计学中,合理的数据收集和处理方法对最终的数据分析结果至关重要。
常见的数据收集与处理方法包括样本选择、数据清洗和缺失值处理等。
1. 样本选择样本选择是数据收集的第一步。
在生物研究中,合理的样本选择可以保证样本代表性和数据可靠性。
样本选择的原则包括随机抽样、分层抽样和配对抽样等。
2. 数据清洗数据清洗是保证数据质量的重要环节。
在数据清洗过程中,需要排除掉异常值、重复值和无效值等错误数据。
数据清洗的目的是保证数据的准确性和一致性。
3. 缺失值处理缺失值是数据分析中常见的问题之一。
对于存在缺失值的数据,可以采用插补、删除或引入虚拟变量等方法进行处理。
最常见的缺失值处理方法包括均值插补、中位数插补和最近邻法等。
四、数据分析方法数据分析是生物统计学的核心内容之一。
生物统计学实验设计
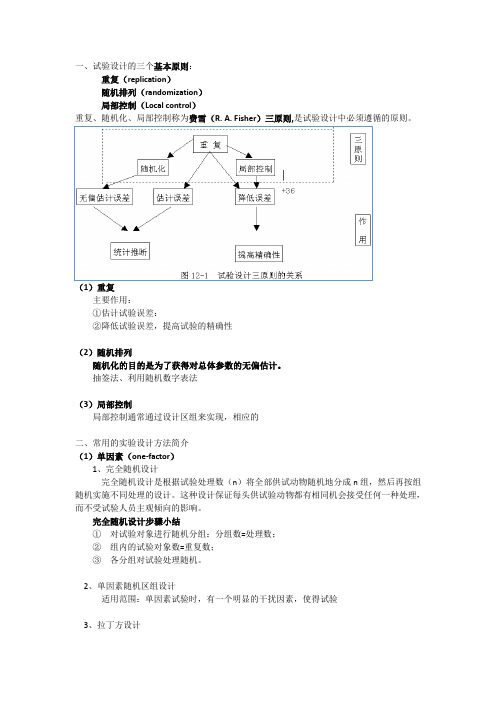
一、试验设计的三个基本原则:
重复(replication)
随机排列(randomization)
局部控制(Local control)
重复、随机化、局部控制称为费雪(R. A. Fisher)三原则,是试验设计中必须遵循的原则。
(1)重复
主要作用:
①估计试验误差:
②降低试验误差,提高试验的精确性
(2)随机排列
随机化的目的是为了获得对总体参数的无偏估计。
抽签法、利用随机数字表法
(3)局部控制
局部控制通常通过设计区组来实现,相应的
二、常用的实验设计方法简介
(1)单因素(one-factor)
1、完全随机设计
完全随机设计是根据试验处理数(n)将全部供试动物随机地分成n组,然后再按组随机实施不同处理的设计。
这种设计保证每头供试验动物都有相同机会接受任何一种处理,而不受试验人员主观倾向的影响。
完全随机设计步骤小结
①对试验对象进行随机分组:分组数=处理数;
②组内的试验对象数=重复数;
③各分组对试验处理随机。
2、单因素随机区组设计
适用范围:单因素试验时,有一个明显的干扰因素,使得试验
3、拉丁方设计
(2)两因素
1、交叉分组设
2、两因素随机区组设计
3、裂区设计
(3)多因素
正交设计。
生物统计学中的实验设计与分析

生物统计学中的实验设计与分析生物统计学是一门跨学科的学科,它涉及统计学、医学、生物学、物理学和计算机科学等领域。
其中实验设计与分析是生物统计学的重点内容之一,它是生物学研究中构建实验、分析实验数据的重要方法。
实验设计实验设计是生物学研究中对实验方案进行构建、随机分组和其他试验设计。
一个好的实验必须经过规划、实施、记录和分析。
实验设计的好坏直接影响实验的结果和结论的可靠性。
实验设计中的一些重要因素包括样本大小、实验控制、测量误差、随机性、重复性、缺失值等。
为了减小样本误差,应当适当增大样本量,同时,根据实验的需要,可以选择单因素、双因素或多因素设计。
实验控制包括不同组之间的控制、不同时间点之间的对照、实验环境和处理方法等等。
测量误差和随机性是不可避免的,但是可以通过设计备份样本、测试偏差等方法减小误差。
随机化的设计可以减小实验结果受样本偏差的影响。
重复性设计可以检验实验结果的可靠性,检验实验差异的稳定性。
缺失值处理可以减少实验结果的影响,也可以减小实验结果的误差,提高实验的有效性。
实验分析实验分析是在实验的基础上通过计算结果、对数据的变异性和统计分析,将实验结果转化为有价值的信息、发现、结论。
实验分析中的一些重要方法包括统计分析、单因素、双因素、多因素方差分析、线性回归分析、非线性回归分析、生存分析等等。
实验结果的可靠性和有用性直接受到实验分析的影响。
统计分析是实验分析的根本工具,它可以对实验中的数据进行描述性和推断性分析。
在描述性分析中,可以了解样本的基本情况、样本之间的关系;在推断性分析中,可以从样本中推断总体的性质,例如对总体均值或总体比例的估计。
单因素、双因素、多因素方差分析可以用来分析实验结果和不同因素之间的关系。
线性回归分析可以发现哪些因素对实验效果有重要影响,而非线性回归分析可以发现实验效果与因素之间的非线性关系。
生存分析可以发现实验结果与生命期的关系,例如药物对病人生命期的影响。
总结实验设计和分析是生物学研究中非常重要的方法,它可以帮助研究者规划实验方案、提高实验效率和可靠性,发掘更加真实和有意义的实验结果。
生物统计学与实验设计

生物统计学与实验设计生物统计学是一门研究生物学数据处理和解释的学科,是生物学实验设计和数据分析的重要工具。
合理的实验设计和有效的统计分析可以帮助我们得出可靠的结论和科学的推断。
本文将介绍生物统计学的基本原理和常用方法,以及如何进行合理的实验设计。
一、生物统计学的基本原理生物统计学是应用统计学原理和方法研究生物学数据的科学。
它的基本原理包括以下几个方面:1. 变量类型:生物学实验中通常涉及不同类型的变量,包括定性变量和定量变量。
定性变量是指描述事物属性的变量,如性别、颜色等;定量变量是指可以进行数值计量的变量,如体重、血压等。
2. 数据采集:在生物学实验中,我们需要收集相应的数据来进行分析。
数据采集应该尽量精确、全面和可靠。
采集数据的过程中要严格按照实验设计的要求进行,避免任何干扰因素的影响。
3. 数据整理和清洗:收集到的数据需要进行整理和清洗,包括去除异常值、缺失值的处理等。
数据整理和清洗是保证数据质量和准确性的重要环节。
4. 描述统计分析:描述统计是通过统计指标来描述数据的基本特征。
包括均值、标准差、频数分布等。
描述统计是对数据的第一层次的分析,可以帮助我们对数据有一个直观的认识。
5. 推断统计分析:推断统计是通过样本数据对总体进行推断。
常用的方法包括假设检验、置信区间估计等。
推断统计可以帮助我们从样本数据中得出总体特征的结论。
二、实验设计合理的实验设计是进行科学研究的基础,也是保证实验结果可靠性的重要因素。
一个良好的实验设计应具备以下几个要素:1. 研究目的和假设:明确研究的目的和假设,假设应具备可验证性和明确性。
2. 实验设计:选择适当的实验设计,包括对照组设计、随机分组设计等。
实验设计应遵循科学原理,能够有效控制干扰因素。
3. 样本大小确定:确定合适的样本大小是保证实验结果可靠性的重要环节。
样本大小的确定需要考虑效应大小、显著水平、样本方差等因素。
4. 随机分配:在实验中对实验对象进行随机分配是避免实验结果的偏倚和提高实验效力的重要手段。
生物统计学中的生物学试验设计与分析

生物统计学中的生物学试验设计与分析生物统计学是一门研究生物学问题的数学分支学科,以数据收集、处理、分析和解释为基础。
在生命科学领域中,进行生物学实验是一项非常基础和关键的内容。
而生物学实验中的实验设计和数据分析都离不开生物统计学的基础知识。
I. 实验设计生物学实验设计的目的是为了建立一个合理、可靠、有意义的实验设计方案,使得实验结果能够准确、可靠地反映研究对象的真实情况。
因此,实验设计是研究成果的先决条件,一个好的实验设计方案是直接决定研究成果的重要因素。
实验设计一般包括以下几个步骤:1.确定研究问题和目的首先,研究人员需要明确研究的问题和目的,以便对研究对象的特点和要求做出正确的判断。
例如,不同的研究问题可能需要不同的研究对象和实验方法。
2.确定实验的处理因子和响应变量处理因子是指实验中操作的主要因素,而响应变量是指受到操作影响的主要变量。
研究人员需要根据研究问题的特点来确定实验中需要控制和测量的变量,以便获得准确的数据结果。
3.选择实验的设计类型根据研究问题和目的的不同,可以选择不同的实验设计类型,例如,随机处理设计、区组设计、分层设计等。
每种设计类型都有其适用的场合和优缺点,需要根据研究问题的不同进行选择。
4.样本数和数据收集样本数是实验设计中一个非常重要的考虑因素。
样本数的大小对实验是否能够得出显著结论具有很大的影响。
在数据收集时需要尽可能地减小误差的影响,可以选择合适的仪器和测量方法,采用合适的实验操作方法等。
II. 数据分析经过实验设计和数据收集后,需要对实验数据进行统计分析来得出结论。
生物统计学是进行实验分析的基础理论和方法,常用的方法包括描述性统计学、参数推断、变异数分析、因素分析、回归分析等。
1.描述性统计学描述性统计学是对数据的集中趋势、分散程度、偏态和峰态等进行描述和分析的统计学方法。
常用的描述性统计量包括平均数、中位数、众数、标准差等。
2. 参数推断参数推断是通过对样本数据进行推断,得出样本总体的参数值。
生物统计学实习报告

实习报告一、实习背景与目的随着生物科学领域的不断发展,生物统计学作为一门结合生物学与统计学的交叉学科,在生物科学研究中发挥着越来越重要的作用。
本次实习旨在通过实际操作,掌握生物统计学的基本原理和方法,提高在生物学研究中的数据处理和分析能力。
二、实习内容与过程1. 实习前的准备在实习开始前,我们对生物统计学的基本概念、原理和方法进行了系统的学习,包括描述性统计、概率分布、假设检验、线性回归等。
同时,学习了统计软件的使用,如SPSS、R语言等。
2. 实习过程(1)数据收集与整理实习过程中,我们首先收集了生物学实验数据,如基因表达数据、酶活性数据等。
对这些数据进行了清洗、整理和转换,使之符合统计分析的要求。
(2)描述性统计分析我们对收集到的数据进行了描述性统计分析,包括计算均值、标准差、中位数等统计量,绘制直方图、箱线图等统计图表,以直观地了解数据的分布特征。
(3)假设检验结合实验设计,我们选择了适当的假设检验方法,如t检验、方差分析等,对数据进行了显著性分析,判断实验组与对照组之间是否存在显著差异。
(4)线性回归分析针对实验数据,我们运用线性回归分析方法,探讨了变量之间的关系,如基因表达与实验条件的关系等。
通过回归方程的建立,揭示了变量之间的内在联系。
(5)结果呈现与解读我们将统计分析结果以图表的形式呈现出来,如条形图、折线图等,同时对结果进行了详细的解读,分析了实验数据背后的生物学意义。
三、实习收获与反思通过本次实习,我们深入了解了生物统计学的基本原理和方法,提高了在生物学研究中的数据处理和分析能力。
同时,我们也认识到生物统计学在科研中的重要性,以后在实验设计和数据分析过程中,要更加注重生物统计学的应用。
实习过程中,我们也发现自己在统计知识和技能方面的不足,如对某些统计方法的理解不够深入,统计软件操作不熟练等。
今后,我们将继续努力学习生物统计学知识,提高自己的实践能力。
四、实习总结本次生物统计学实习让我们受益匪浅,不仅提高了我们在生物学研究中的数据处理和分析能力,也使我们更加认识到生物统计学在科研中的重要性。
生物统计学实验

单击主菜单Transform(转换)→Recode→Into Different Variables(转换成不同变量)→Name,定义一个新变量→Label中输入“数据分组”,点击Change→Old and New Value。在Value下输入组数,在Range下输入与组数相对应的组限,每增一组,点击Add添加。最后点击OK确定。
(2)点击工作表下方Data View命令,进入“数据视图”工作表,将100例30~40岁健康男子血清总胆固醇数据分别输入到变量名为“D”的各个单元格内。
分组:
(1)求全距:最大值—最小值=7.22—2.70=4.52(mol/L)
(2)确定组数和组距:根据样本含量初步确定分为10组,组距=全距/组数=4.52/10=0.452≈0.5
次数分布表的编制:
单击主菜单Analyze(分析)→Descriptive Statistics(描述性统计)→Frequency(频数)
二、实验内容
1、 实验现象及数据
表1-1某地100例30~40岁健康男子血清总胆固醇(mol/L)的次数分布表
总胆固醇含量次数频率累积频率
2.5~3.0 1 0.01 0.01
本科学生实验报告
学号*********姓名史佳茜
学院生命科学学院专业、班级11级生物科学A班
实验课程名称生物统计学实验
指导教师及职称孟丽华
开课时间2012至2013学年下学期
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
当ν=7 时, t0.05 =
推断:
(2)单株产量总体平均数µ在 95%置信度下的置信区间的下限和上限为:
L1= x -tα× sx =
L2= x +tα× sx =
所以单株产量总体平均数µ在 95%置信度下的置信区间为[
]
excel 的分析工具中没有单个平均数的 t 测验方法,但可以巧妙地利用成对数据的 t 测 验法完成有关计算。
1.先进入统计运算的状态。操作方法为:先按 现“SD”时,即可进行统计运算。
键,再按数字键
,在屏幕上出
INV
2.清空贮存库中的内容。操作方法:
。
3.输入数据。如有一样本,其观察值为:1, 2, 3, 4, 5。试计算 n、Σx、Σx2 、 x 、s。
操作方法:1
2
3
4
5
如刚输入的数据出错,可用部分清除键
验三),并发送到老师指定的微机的文件夹中。 习题 5.9 选面积为 30m2 的玉米小区 10 个,各分成两半,一半去雄另一半不去雄,得产 量(kg)为:
去 雄:28,30,31,32,30,29,30,28,34,27。 不去雄:25,28,29,29,31,25,28,27,32,27。 (1) 用成对比较法测验 H0:µd=0 的假设; (2) 求包括µd 在内置信度为 95%的区间; (3) 试按成组平均数比较法测验假设 H0:µ1=µ2; (4) 求包括µ1−µ2在内置信度为 95%的区间; (5) 比较上述第(1)项和第(3)项测验结果并加以解释。
三、解题指导
解:(1)提出假设 假设Η0:µd=0,对ΗA:µd≠0 确定显著水平
α =0.05 测验计算:
d = Σd n
sd
=
sd n
t= d sd
查 t 临界值
当ν=10-1=9 时,t0.05=, 推断:
(2) 包括µd 在内,置信度为 95%的置信区间的下限和上限为:
L1= d -t0.05× sd =
),屏幕
上显示出“M”;将 5 累加到独立存储器中(5
);提取独立存储器中的数
INV 据( ),此时为 17;将独立存储器中的数据减 3(3
);提取独
立存储器中的数据( ),此时为 14。
12、
INV :乘方或乘方根键。 功能。
(二)平均数和标准差的计算:
INV 或
1
:可相应执行 x y 或 x y 的
(4) 包括µ1−µ2在内,置信度为 95%的置信区间的下限和上限为:
L1= ( x1 − x2 ) – t0.05 S x1−x2 =
216。(1)试测验 H0:µ=250;(2)估计单株产量总体平均数µ在 95%置信度下的置信区间。
三、解题指导
(1)提出无效假设和对应假设
H0:µ=µ0=250 (该杂交水稻的单株产量的总体平均数为 250g) HA:µ≠250 确定显著水平
α=0.05 测验计算:
x=
sx =
s
=
n
t = x − 250 = sx
ห้องสมุดไป่ตู้
按
钮。即得到假设测验的结果。
9、在工作表中计算出样本平均数的标准误 sx 和总体平均数µ的 95%置信限 L1、L2。
10、将结果填入 word 文档。
8
实验三 两个样本平均数的统计推断
一、目的:通过实验掌握两个样本平均数的假设测验及区间估计的方法。
二、要求:用自己的学号后两位数及姓名作文件名,保存 word 和 excel 文件(×××××实
2、
:状态键,与.及数字键 1~9 配合使用。常用的包括:
∫ :显示 dx ,即积分运算状态;
:显示 LR,即:回归计算状态;
:显示 SD,即统计运算状态;
3、
:程序改正清除键。
4、
、
:程序序号指定显示键。
5、
:正负符号转换键。单独按该键执行黑色字(+/-)的功能,即改变符号。
6、
:求平方键。:按 INV 及该键执行红色字(x2)的功能,即求平方。
的关系,得结果于表 11.1。试计算直线回归方程。
x 累积温度 35.5 34.1 31.7 40.3 36.8 40.2 31.7 39.2 44.2
y 盛发期 12 16 9 2 7 3 13 9 -1 分别求变数 x、y 的(1)总和数(Σx、Σy);(2)平方和(Σx2、Σy2);
(3)平均数( x 、 y ); (4)xy 的乘积和(Σxy);
(5)回归截距 a; (6)回归系数 b; (7)相关系数 r。
输 入 数 据 : 35.5
12
, 34.1
1
。
(如刚输入的数据出错,也可用部分清除键 4.提取特征数。
16 删除)。
, …… , 44.2
5
提取的特征数名称 x 的平方和(Σx2) x 的总和数(Σx)
x 的个数(n)
x 的平均数( x )
5
INV 6
显
2×5
示 0.6。
9、
:常数库输出键。上例中存到 2 号库中的 15 可用
2 显示 15。
2 提取出来,即按
10、
,
:本计算器还有一个独立存储器,进行存储运算时,屏幕上
INV
显示“M”。其使用方法如下:清除独立存储器中的数据(
),
INV 屏幕上显示的“M”消失;将 12 存入到独立存储器中(12
L2=
d
+
t0.05×
s d
=
所以包括µd 在内置信度为 95%的区间为[
]。
(3)假设 H0:µ1=µ2,则ΗA:µ1≠µ2
显著水平α =0.05
测验计算:
x1 − x2 =
9
S = x1 − x2
t = x1 − x2 = s x1 − x2
查 t 临界值表
当ν=20-2=18 时,t0.05= , 推断:
7、
:a b/c 分数键。单独按该键执行黑色字(a b/c)的功能,即进行分数运算,
如
1
1
+2 3 ,操作方法:1
45
1
4
5
显示 3 ↵17↵20 ,即 3 17 ;
20
2
3
INV 8、 :倒数键。按 及该键执行红色字(1/x)的功能,即求倒数。
3
7、
:统计运算双变数 x 的输入键(在 LR 状态时使用)。
本书是我们几年来从事生物统计实验课教学的经验总结,书中不乏有许多应用技巧。 由于受软件掌握的程度所限,不妥之处在所难免,望使用者多提宝贵意见和建议。
联系方式:zhibinch@ guanxin73@
编者 2006 年 11 月于沈阳农业大学
1
目
录
实验一 计算器的使用............................................................. 3 实验二 单个样本平均数的统计推断 ..................................... 7 实验三 两个样本平均数的统计推断 ..................................... 9 实验四 卡平方测验................................................................13 实验五 单因素试验结果的统计分析 ....................................18 实验六 多因素试验结果的统计分析 ....................................22 实验七 直线回归与相关 ........................................................26 实验八 多元回归与相关 ........................................................32
2
实验一 计算器的使用
一、实验目的:
1.通过实验掌握函数型电子计算器的使用,特别是统计功能键的使用。。
2.掌握利用计算器进行平均数、标准差及相关计算的方法。
二、实验要求:
完成习题 3.3 和 3.4。
三、方法及步骤:
(一)计算器的常用键盘的名称及作用(以 CASIO fx-180P 为例)
1、INV :第二功能键,与红色字符键配合使用,以完成第二种功能。
《生物统计学》实验指导
(Excel 篇)
陈志斌 关欣 杨淑兰 编著
沈阳农业大学农学院 2006 年 11 月修订
前言
生物统计学是农科院校许多专业的专业基础课,涉及试验设计与统计分析两方面内 容,是科研工作者从事科学研究必备的工具。过去,由于计算工具的落后,一度限制了它 的应用,随着计算机的迅速发展和普及,计算工具已不再成为限制因素,大量应用软件的 研制成功,使生物统计学有了突飞猛进的发展。为了适应这种发展的需要,我们改革了生 物统计实验教学,编写了这本实验指导,旨在帮助同学们通过实验实践,掌握应用计算机 完成常用的统计分析的基本方法,为进一步学习打下一个良好的基础。该书不仅是在校学 生学习生物统计的实验指导书,也可作为农业科研工作者的参考书。
将所有的数据与假设的平均数 250 配成对,这样组成的成对数据的 t 值计算式为:
t = d ,其分子上的差数平均数 d 必与本题的 t 的计算式的分子( x − 250 )相等;而分 sd
母的差数平均数的标准误 sd ,是用在原观察值的基础上均减去 250 后得到的值 di 计算的, 所以其值必与用原观察值计算的标准误 s x 相等,因此,可通过添加 8 个 250,构成成对数
钮。
4、在“变量 1 的区域”选样本观察值(A2:A9),变量 2 的区域选 8 个“250”的数据 区域(B2:B9)。