【能源消费】EViews计量经济学实验
EViews计量经济学实验报告

EViews 计量经济学实验报告实验一 EViews软件的基本操作小组成员: 【实验目的】了解EViews软件的基本操作对象,掌握软件的基本操作。
【实验内容】数据的输入、编辑与序列生成;实验内容以表1-1所列出的消费支出和可支配收入的统计资料为例进行操作。
表1-1 中国内地各地区城镇居民家庭人均全年可支配收入与人均全年消费性支出单位:元地区消费支出Y 可分配收入 X 地区消费支出 Y 可支配收入 X北京 19977.52 14825.41 湖北 9802.65 7397.32天津 14283.09 10548.05 湖南 10504.67 8169.30河北 10304.56 7343.49 广东 16015.58 12432.22山西 10027.70 7170.94 广西 9898.75 6791.95 内蒙古 10357.99 7666.61 海南 9395.13 7126.78辽宁 10369.61 7987.49 重庆 11569.74 9398.69吉林 9775.07 7352.64 四川 9350.11 7524.81 黑龙江 9182.31 6655.43 贵州 9116.61 6848.39上海 20667.91 14761.75 云南 10069.89 7379.81江苏 14084.26 9628.59 西藏 8941.08 6192.57浙江 18265.10 13348.51 陕西 9267.70 7553.28安徽 9771.05 7294.73 甘肃 8920.59 6974.21福建 13753.28 9807.71 青海 9000.35 6530.11江西 9551.12 6645.54 宁夏 9177.26 7205.57山东 12192.24 8468.40 新疆 8871.27 6730.01河南 9810.26 6685.18资料来源:《中国统计年鉴》(2007)【实验步骤】一、创建工作文件启动EViews软件之后,进入EViews主窗口(如图1-1所示)。
【能源消费】EViews计量经济学实验
一、模型的估计与调整(一)参数估计1、双击“Eviews”,进入主页。
输入数据:点击主菜单中的File/Open /EV Workfile—Excel—多重共线性的数据.xls ;2、在EV主页界面的窗口,输入“ls y c x2 x3 x4 x5 x6 x7”,按“Enter”.出现OLS回归结果,图2:Dependent Variable: YMethod: Least SquaresDate: 11/01/10 Time: 11:34Sample: 1985 2007Included observations: 23Variable Coefficient Std. Error t-Statistic Prob.C 168326.2 108641.0 1.549381 0.1408 X2 -0.142290 0.763550 -0.186353 0.8545 X3 0.503108 0.248552 2.024157 0.0600 X4 8.294237 10.43112 0.795143 0.4382 X5 -0.203037 0.111019 -1.828841 0.0861 X6 233.9125 388.5188 0.602062 0.5556 X7-1373.3761588.868-0.8643730.4002R-squared0.980436 Mean dependent var 139364.6 Adjusted R-squared 0.973099 S.D. dependent var 51705.05 S.E. of regression 8480.388 Akaike info criterion 21.17469 Sum squared resid 1.15E+09 Schwarz criterion 21.52028 Log likelihood -236.5089 F-statistic 133.6365 Durbin-Watson stat 1.380303 Prob(F-statistic)0.000000由此可见,该模型的可决系数为0.995,修正的可决系数为0.993,模型拟和很好,F 统计量为701.47,模型拟和很好,回归方程整体上显著。
计量经济学实验报告1(共6篇)

篇一:计量经济学实验报告 (1)计量经济学实验基于eviews的中国能源消费影响因素分析学院:班级:学号:姓名:基于e views的中国能源消费影响因素分析一、背景资料能源消费是指生产和生活所消耗的能源。
能源消费按人平均的占有量是衡量一个国家经济发展和人民生活水平的重要标志。
能源是支持经济增长的重要物质基础和生产要素。
能源消费量的不断增长,是现代化建设的重要条件。
我国能源工业的迅速发展和改革开放政策的实施,促使能源产品特别是石油作为一种国际性的特殊商品进入世界能源市场。
随着国民经济的发展和人口的增长,我国能源的供需矛盾日益紧张。
同时,煤炭、石油等常规能源的大量使用和核能的发展,又会造成环境的污染和生态平衡的破坏。
可以看出,它不仅是一个重大的技术、经济问题,而且以成为一个严重的政治问题。
在20世纪的最后二十年里,中国国内生产总值(gdp)翻了两番,但是能源消费仅翻了一番,平均的能源消费弹性仅为0.5左右。
然而自2002年进入新一轮的高速增长周期后,中国能源强度却不断上升,经济发展开始频频受到能源瓶颈问题的困扰。
鉴于此,研究能源问题不仅具有必要性和紧迫性,更具有很大的现实意义。
由于我国目前面临的所谓“能源危机”,主要是由于需求过大引起的,而我国作为世界上最大的发展中国家,人口众多,所需能源不可能完全依赖进口,所以,研究能源的需求显得更加重要。
二、影响因素设定根据西方经济学消费需求理论可知,影响消费需求的因素有:商品的价格、消费者收入水平、相关商品的价格、商品供给、消费者偏好以及消费者对商品价格的预期等。
对于相关商品价格的替代效应,我们认为其只存在能源品种内部之间,而消费者偏好及消费者对商品价格的预期数据差别较大,不容易进行搜集整理在此暂不涉及。
另外,发展经济学认为,来自知识、人力资本的积累水平所体现的技术进步不仅可以带动劳动产出的增长,而且会通过外部效应可以提高劳动力、自然资源、物质资本与生产要素的生产效率,消除其中收益递减的内在联系,带来递增的规模收益。
计量经济学eviews实验报告

大连海事大学实验报告Array实验名称: 计量经济学软件应用专业班级:财务管理2013-1姓名: 安妮指导教师:赵冰茹交通运输管理学院二○一六年十一月一、实验目标学会常用经济计量软件得基本功能,并将其应用在一元线性回归模型得分析中。
具体包括:Eview得安装,样本数据基本统计量计算,一元线性回归模型得建立、检验及结果输出与分析,多元回归模型得建立与分析,异方差、序列相关模型得检验与处理等。
二、实验环境WINDOWSXP或2000操作系统下,基于EVIEWS5、1平台。
三、实验模型建立与分析案例1:我国1995-2014年得人均国民生产总值与居民消费支出得统计资料(此资料来自中华人民共与国统计局网站)如表1所示,做回归分析。
表1我国1995—2014年人均国民生产总值与居民消费水平情况(1)做出散点图,建立居民消费水平随人均国内生产总值变化得一元线性回归方程,并解释斜率得经济意义;利用eviews软件输出结果报告如下: Dependent Variable:CONSUMPTIONMethod: Least SquaresDate:06/11/16Time: 19:02Sample: 1995 2014Included observations:20Variable Coefficient Std、Errort—Statistic Prob、C 691、0225113、3920 6、0941040、0000AVGDP 0、352770 0、004908 71、88054 0、0000R-squared 0、996528 Mean dependent var 7351、300Adjusted R-squared 0、996335 S、D、dependent var4828、765S、E、of regression292、3118 Akaike info criterion 14、28816Sum squaredresid 1538032、 Schwarz criterion14、38773Log likelihood -140、8816Hannan-Quinn criter、14、30760F-statistic 5166、811Durbin-Watsonstat0、403709Prob(F—statistic)0、000000由上表可知财政收入随国内生产总值变化得一元线性回归方程为:(令Y=CONSUMPTION,X=AVGDP(此处代表人均GDP))Y = 691、0225+0、352770* X其中斜率0、352770表示国内生产总值每增加一元,人均消费水平增长0、35277元.检验结果R2=0、996528,说明99、6528%得样本可以被模型解释,只有0、3472%得样本未被解释,因此样本回归直线对样本点得拟合优度很高.(2)对所建立得回归方程进行检验:(5%显著性水平下,t(18)=2、101)对于参数c假设: H0:c=0、对立假设:H1:c≠0对于参数GDP假设: H0: GDP=0、对立假设:H1: GDP≠0由上表知:对于c,t=6、094104>t(n-2)=t(18)=2、101因此拒绝H0: c=0,接受对立假设:H1: c≠0对于GDP, t=71、88054﹥t(n—2)=t(18)=2、101因此拒绝H0: GDP=0,接受对立假设: H1: GDP≠0此外F统计量为5166、811,数值很大,可以判定,人均国内生产总值对居民消费水平在5%得显著性水平下有显著性影响。
计量经济学eviews实习报告.doc
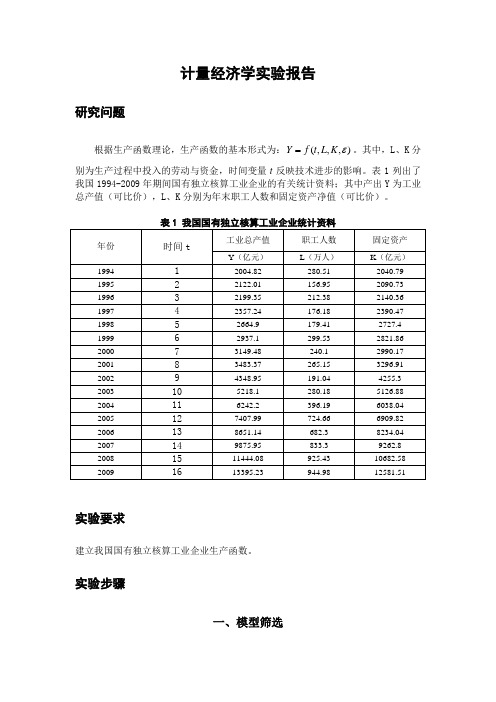
计量经济学实验报告研究问题根据生产函数理论,生产函数的基本形式为:),,,(εK L t f Y =。
其中,L 、K 分别为生产过程中投入的劳动与资金,时间变量t 反映技术进步的影响。
表1列出了我国1994-2009年期间国有独立核算工业企业的有关统计资料;其中产出Y 为工业总产值(可比价),L 、K 分别为年末职工人数和固定资产净值(可比价)。
实验要求建立我国国有独立核算工业企业生产函数。
实验步骤一、模型筛选(一)建立多元线性回归方程回归结果如下:图1因此,我国国有独立工业企业的生产函数为:K L t Y 00998.171897.022674.90897.191+++-=∧(模型1)t =(-5.4) (0.862) (3.57) (40.44)999742.02=R 999677.02=R 57.15483=F模型的计算结果表明,我国国有独立核算工业企业的劳动力边际产出为0.71897,资金的边际产出为1.00998,技术进步的影响使工业总产值平均每年递增9.22674亿元。
回归系数的符号和数值是较为合理的。
999742.02=R ,说明模型有很高的拟合优度,F 检验也是高度显著的,说明职工人数L 、资金K 和时间变量t 对工业总产值的总影响是显著的。
从图1看出,解释变量资金K 的t 统计量值为40.44,表明资金对企业产出的影响是显著的。
但是,模型中时间变量T 的t 统计量值都较小,未通过检验。
因此,需要对以上三元线性回归模型做适当的调整,按照统计检验程序,一般应先剔除t 统计量较小的变量(即时间变量)而重新建立模型。
(二)建立剔除时间变量的二元线性回归模型回归结果如下:图2因此,我国国有独立工业企业的生产函数为:K L Y 026137.1669964.02778.176++-=∧(模型2)t =(-5.76) (3.5) (62.79)999726.02=R 999684.02=R 95.23692=F(三)建立非线性回归模型——C-D 生产函数C-D 生产函数为:εβαe K AL Y =。
计量经济学eviews实验报告

大连海事大学实验报告Array实验名称:计量经济学软件应用专业班级:财务管理2013-1姓名:安妮指导教师:赵冰茹交通运输管理学院二○一六年十一月一、实验目标学会常用经济计量软件的基本功能,并将其应用在一元线性回归模型的分析中。
具体包括:Eview的安装,样本数据基本统计量计算,一元线性回归模型的建立、检验及结果输出与分析,多元回归模型的建立与分析,异方差、序列相关模型的检验与处理等。
二、实验环境WINDOWSXP或2000操作系统下,基于EVIEWS5.1平台。
三、实验模型建立与分析案例1:我国1995-2014年的人均国民生产总值和居民消费支出的统计资料(此资料来自中华人民共和国统计局网站)如表1所示,做回归分析。
表1我国1995-2014年人均国民生产总值与居民消费水平情况(1)做出散点图,建立居民消费水平随人均国内生产总值变化的一元线性回归方程,并解释斜率的经济意义;利用eviews软件输出结果报告如下:Dependent Variable: CONSUMPTIONMethod: Least SquaresDate: 06/11/16 Time: 19:02Sample: 1995 2014Included observations: 20Variable Coefficient Std. Error t-Statistic Prob.C 691.0225 113.3920 6.094104 0.0000AVGDP 0.352770 0.004908 71.88054 0.0000R-squared 0.996528 Mean dependent var 7351.300Adjusted R-squared 0.996335 S.D. dependent var 4828.765S.E. of regression 292.3118 Akaike info criterion 14.28816Sum squared resid 1538032. Schwarz criterion 14.38773Log likelihood -140.8816 Hannan-Quinn criter. 14.30760F-statistic 5166.811 Durbin-Watson stat 0.403709Prob(F-statistic) 0.000000由上表可知财政收入随国内生产总值变化的一元线性回归方程为:(令Y=CONSUMPTION,X=AVGDP(此处代表人均GDP))Y = 691.0225+0.352770* X其中斜率0.352770表示国内生产总值每增加一元,人均消费水平增长0.35277元。
eviews计量经济学实验报告

eviews计量经济学实验报告EViews计量经济学实验报告引言计量经济学是经济学领域中的一个重要分支,它运用数学、统计学和计量学的方法来分析经济现象。
EViews是一个常用的计量经济学软件,它提供了丰富的数据分析和模型建立工具,被广泛应用于学术研究和实际经济分析中。
本实验报告将利用EViews软件进行计量经济学实验,以探讨经济现象并得出相关结论。
实验目的本实验旨在利用EViews软件对某一经济现象进行实证分析,通过建立相应的计量经济模型,对经济现象进行量化分析,并得出相关结论。
实验步骤1. 数据收集:首先,我们需要收集与所研究经济现象相关的数据,包括时间序列数据和横截面数据等。
这些数据可以来自于官方统计机构、学术研究机构或者自行收集整理。
2. 数据预处理:接下来,我们需要对收集到的数据进行预处理,包括数据清洗、缺失值处理、异常值处理等,以确保数据的质量和完整性。
3. 模型建立:在数据预处理完成后,我们可以利用EViews软件建立计量经济模型,包括回归分析、时间序列分析、面板数据分析等,以探讨经济现象的内在规律和影响因素。
4. 模型估计:建立模型后,我们需要对模型进行参数估计,得到模型的具体参数估计值,并进行显著性检验和模型拟合度检验,以验证模型的可靠性和有效性。
5. 结果分析:最后,我们将对模型估计结果进行分析,得出与经济现象相关的结论,并对实证分析结果进行解释和讨论。
实验结论通过以上实验步骤,我们得出了关于某一经济现象的实证分析结果,并得出了相关的结论。
这些结论对于理解经济现象的内在规律和制定经济政策具有重要的参考价值。
总结EViews计量经济学实验报告通过利用EViews软件进行实证分析,对经济现象进行了深入探讨,并得出了相关结论。
这些结论对于经济学研究和实际经济分析具有重要的理论和实践意义,为我们深入理解经济现象和推动经济发展提供了重要的参考依据。
EViews软件的应用为我们提供了一个强大的工具,帮助我们更好地理解和分析经济现象,为经济学领域的研究和实践提供了重要的支持和帮助。
计量经济学试验-Eviews

12
0.759316100176
27
13
24.0588008707
0.027744 -0.008265 38.94474 40950.71 -146.3152 1.698005
Mean dependent var S.D. dependent var Akaike info criterion Schwarz criterion F-statistic Prob(F-statistic)
下:
序号
Y
X
序号
Y
X
1
2940
3547
16
1609
1963
2
2322
2769
17
2048
2450
3
1898
2334
18
2087
2688
4
1560
1957
19
3777
4632
5
1585189320源自230328956
1977
2314
21
2404
3072
7
1596
1953
22
2034
2421
8
1660
1960
0.133926 271.8586
7.278296 -1.056384
Mean dependent var S.D. dependent var Akaike info criterion Schwarz criterion F-statistic Prob(F-statistic)
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
一、模型的估计与调整(一)参数估计1、双击“Eviews”,进入主页。
输入数据:点击主菜单中的File/Open /EV Workfile—Excel—多重共线性的数据.xls ;2、在EV主页界面的窗口,输入“ls y c x2 x3 x4 x5 x6 x7”,按“Enter”.出现OLS回归结果,图2:Dependent Variable: YMethod: Least SquaresDate: 11/01/10 Time: 11:34Sample: 1985 2007Included observations: 23Variable Coefficient Std. Error t-Statistic Prob.C 168326.2 108641.0 1.549381 0.1408 X2 -0.142290 0.763550 -0.186353 0.8545 X3 0.503108 0.248552 2.024157 0.0600 X4 8.294237 10.43112 0.795143 0.4382 X5 -0.203037 0.111019 -1.828841 0.0861 X6 233.9125 388.5188 0.602062 0.5556 X7-1373.3761588.868-0.8643730.4002R-squared0.980436 Mean dependent var 139364.6 Adjusted R-squared 0.973099 S.D. dependent var 51705.05 S.E. of regression 8480.388 Akaike info criterion 21.17469 Sum squared resid 1.15E+09 Schwarz criterion 21.52028 Log likelihood -236.5089 F-statistic 133.6365 Durbin-Watson stat 1.380303 Prob(F-statistic)0.000000由此可见,该模型的可决系数为0.995,修正的可决系数为0.993,模型拟和很好,F 统计量为701.47,模型拟和很好,回归方程整体上显著。
但是当α=0.05时,)(2/k n t -α=)23(025.0t =2.069,不仅X4、X5、X6、X7的系数t 检验不显著,而且X2、X4、X6系数的符号与预期相反,这表明很可能存在严重的多重共线性。
(即除了农业增加值2X 、工业增加值3X 外,其他因素对财政收入的影响都不显著,且农业增加值2X 、建筑业增加值4X 、最终消费6X 的回归系数还是负数,这说明很可能存在严重的多重共线性。
)(二)多重共线性的诊断与修正3、计算各解释变量的相关系数:在Workfile 窗口,选择X2、X3、X4、X5、X6、X7数据,点击“Quick ”—Group Statistics —Correlations —OK,出现相关系数矩阵,如图3:图3: 相关系数矩阵由相关系数矩阵可以看出,各解释变量相互之间的相关系数较高,特别是农业增加值2X 、工业增加值3X 、建筑业增加值4X 、最终消费之间6X ,相关系数都在0.8以上。
这表明模型存在着多重共线性。
1、采用逐步回归法,去检验和解决多重共线性问题。
分别作Y 对X2、X3、X4、X5、X6、X7的一元回归,结果如下图4:在EV 主页界面的窗口,输入“ls y c x2”,“回车键”。
依次如上推出X3、X4、X5、X6、X7的一元回归。
综上所述,结果如下图4:2、其中,加入 的2R 最大,以 为基础,顺次加入其他变量逐步回归。
结果如下图5:图5.加入新变量的回归结果(一)2X 2X(三)异方差的诊断与修正该模型样本回归估计式的书写形式为:Y = 11.44213599 + 0.6267829962*X (3.629253) (0.019872)t= 3.152752 31.5409720.944911R = 20.943961R = S.E.=9.158900 DW=1.597946 F=994.8326※(一)图形法1、在“Workfile ”页面:选中x,y 序列,点击鼠标右键,点击Open —as Group —Yes2、在“Group ”页面:点击View -Graph —Scatter —Simple Scatter, 得到X,Y 的散点图(图3所示):2、Goldfeld-Quandt 法进行检验。
a.将样本X 按递增顺序排序,去掉中间1/4的样本,再分为两个部分的样本,即n1=n2=9。
Dependent Variable: Y Method: Least Squares Date: 11/01/10 Time: 11:07 Sample: 1 9Included observations: 9Variable Coefficient Std. Error t-Statistic Prob.C -15.15272 0.772901 -19.60500 0.0000 X0.0002108.01E-06 26.285140.0000R-squared0.989970 Mean dependent var 5.000000 Adjusted R-squared 0.988537 S.D. dependent var 2.738613 S.E. of regression 0.293208 Akaike info criterion 0.577264 Sum squared resid 0.601798 Schwarz criterion 0.621092 Log likelihood -0.597687 F-statistic 690.9084 Durbin-Watson stat 1.352108 Prob(F-statistic)0.000000Dependent Variable: Y Method: Least Squares Date: 11/01/10 Time: 11:08 Sample: 1 9Included observations: 9Variable Coefficient Std. Error t-Statistic Prob.C 8.851030 0.991996 8.922445 0.0000 X5.42E-055.14E-06 10.537710.0000R-squared0.940700 Mean dependent var 19.00000 Adjusted R-squared 0.932228 S.D. dependent var 2.738613 S.E. of regression 0.712943 Akaike info criterion 2.354299 Sum squared resid 3.558014 Schwarz criterion 2.398127 Log likelihood -8.594347 F-statistic 111.0434 Durbin-Watson stat 0.632734 Prob(F-statistic)0.000015b.分别对两个部分的样本求最小二乘估计,得到两个部分的残差平方和,即21∑ei= 0.601798 ,22∑ei= 3.558014求F 统计量为 F=∑∑⎥⎦⎤⎢⎣⎡--⎥⎦⎤⎢⎣⎡--k cn e k cn e i i 2/2/2122 = 5.912306给定0.05α=,查F 分布表,得临界值为⎪⎭⎫⎝⎛----k c n k c n 22F ,)(α = 3.79 c.比较临界值与F 统计量值,有F=5.912306 ﹥)(αF =3.79 ,说明该模型的随机误差项存在异方差。
修正异方差在运用加权最小二乘法估计过程中,分别选用了权数t 1ω=1/t X ,t 2ω=1/2t X ,t 3ω=1/t X 。
1、在“Workfile ”页面:点击“Generate ”,输入“w1=1/x ”—OK ;同样的输入“w2=1/x^2” “w3=1/sqr(x)”;2、在“Equation ”页面:点击“Estimate Equation ”,输入“y c x ”,点击“weighted ”,输入“w1”,出现如图6:Dependent Variable: Y Method: Least Squares Date: 11/01/10 Time: 12:31 Sample: 1985 2007 Included observations: 23 Weighting series: W1Variable Coefficient Std. Error t-Statistic Prob.C 75342.48 1955.930 38.52002 0.0000 X2 0.8614960.0873089.867306 0.0000Weighted StatisticsR-squared0.986045 Mean dependent var 102600.2 Adjusted R-squared 0.985380 S.D. dependent var 77372.86 S.E. of regression 9355.386 Akaike info criterion 21.20823 Sum squared resid 1.84E+09 Schwarz criterion 21.30697 Log likelihood -241.8947 F-statistic 97.36373 Durbin-Watson stat0.269103 Prob(F-statistic) 0.000000Unweighted StatisticsR-squared0.925702 Mean dependent var 139364.6 Adjusted R-squared0.922164 S.D. dependent var51705.05S.E. of regression 14425.26 Sum squared resid 4.37E+09 Durbin-Watson stat 0.141803Dependent Variable: YMethod: Least SquaresDate: 11/01/10 Time: 12:33Sample: 1985 2007Included observations: 23Weighting series: W2Variable Coefficient Std. Error t-Statistic Prob.C 61583.22 2022.139 30.45449 0.0000X2 1.867721 0.173762 10.74873 0.0000Weighted StatisticsR-squared 0.998194 Mean dependent var 89007.62 Adjusted R-squared 0.998108 S.D. dependent var 134618.1 S.E. of regression 5855.843 Akaike info criterion 20.27121 Sum squared resid 7.20E+08 Schwarz criterion 20.36995 Log likelihood -231.1189 F-statistic 115.5353 Durbin-Watson stat 0.389451 Prob(F-statistic) 0.000000Unweighted StatisticsR-squared -3.468653 Mean dependent var 139364.6 Adjusted R-squared -3.681446 S.D. dependent var 51705.05 S.E. of regression 111872.4 Sum squared resid 2.63E+11 Durbin-Watson stat 0.023839Dependent Variable: YMethod: Least SquaresDate: 11/01/10 Time: 12:34Sample: 1985 2007Included observations: 23Weighting series: W3Variable Coefficient Std. Error t-Statistic Prob.C 79134.39 2101.452 37.65700 0.0000 X2 0.7416510.04145717.88981 0.0000Weighted StatisticsR-squared0.892994 Mean dependent var 117941.4 Adjusted R-squared 0.887898 S.D. dependent var 26545.81 S.E. of regression 8887.964 Akaike info criterion 21.10572 Sum squared resid 1.66E+09 Schwarz criterion 21.20446 Log likelihood -240.7158 F-statistic 320.0453 Durbin-Watson stat0.251182 Prob(F-statistic) 0.000000Unweighted StatisticsR-squared0.968188 Mean dependent var 139364.6 Adjusted R-squared 0.966673 S.D. dependent var 51705.05 S.E. of regression 9439.115 Sum squared resid 1.87E+09Durbin-Watson stat 0.303249用权数t 1ω的估计结果为: i Y ˆ= 75342.48 + 0.861496 iX (38.52002) (9.867306)2R = 0.986045 DW= 0.269103 F=97.36373括号中的数据为t 统计量值。