空气质量模型精选版
基于WRF-CMAQ_的空气质量等级预报模型

Operations Research and Fuzziology 运筹与模糊学, 2023, 13(1), 120-128 Published Online February 2023 in Hans. https:///journal/orf https:///10.12677/orf.2023.131014基于WRF-CMAQ 的空气质量等级预报模型杨 洁*,魏正元,徐慧颖,吴 镜重庆理工大学,理学院,重庆收稿日期:2022年12月29日;录用日期:2023年2月1日;发布日期:2023年2月9日摘要空气质量与气象条件之间存在较强的相关关系,目前我国常用的WRF-CMAQ 模型预测效果并不理想,本文在此一次预报数据的基础上,结合实测气象数据、实测主要污染物浓度数据,建立了空气质量二次预报模型。
利用中国环境监测总站发布的相关数据,对污染物浓度进行K 均值聚类,将天气分型,再按类别逐步回归拟合模型,最后分析二次预报模型的预测准确性。
结果表明相较于一次预报,二次预报准确率显著提升。
关键词空气质量,二次预报,聚类分析,逐步回归Air Quality Index Prediction Model Based on WRF-CMAQJie Yang *, Zhengyuan Wei, Huiying Xu, Jing WuDepartment of Science, Chongqing University of Technology, ChongqingReceived: Dec. 29th , 2022; accepted: Feb. 1st , 2023; published: Feb. 9th, 2023AbstractThere is a strong correlation between air quality and meteorological conditions, and the predic-tion effect of the commonly used WRF-CMAQ model is not ideal. Based on this first prediction data, combined with the measured meteorological data and the measured pollutant concentration data, this paper establishes a secondary prediction model for air quality. Using the relevant data re-leased by China Environmental Monitoring Station, the pollutant concentration is clustered by K-means, the weather is classified, and then the model is fitted by stepwise regression according*通讯作者。
空气污染等级确定模型

空气质量等级分类及推广模型摘要本文对空气污染主要因素的相关数据进行分析,建立了如何对空气污染程度等一类问题进行分类的模型。
针对问题一,要对该市的空气污染进行分类,按照国家《环境空气质量标准》采用二氧化硫、氮氧化物和漂尘三个主要因素建立空气污染指数模型:()I I I C C I C C -=-+-大小小小大小 通过该模型计算得出其污染物含量对应的API 指数,再综合对人体危害的程度将空气质量情况分为优、良、普通、不佳和差五类。
针对问题二,在问题一的基础上,我们依据该市的污染物含量范围与国家标准进行对比,将该市污染类别分为严重污染,一般污染和基本没有污染,按照各个监测点污染程度由重到轻排出的顺序为:其中,9、13、16三个监测点属于严重污染地区,1、2、3、6、7、8、10、12、14、18的十个监测点属于一般污染地区,4、5、11、15、17的五个监测点属于基本没有污染的地区。
针对问题三,采用空气指数法对19、20、21监测点进行归属分析分别为一般污染、基本没有污染和严重污染。
但空气指数法采用的单个监测点最高指标来衡量并不能综合评价该地区空气污染程度。
为了使模型具有广泛应用性,我们采用主成分分析法对这类问题进行综合分析,求出综合得分与主成分的综合评价模型:120.8980.079 F f f =+同时,为解决个别指标超标对模型贡献不明显的缺陷,在用主成分分析法分析后,引入了对个别指标分析的方法,综合各个要素分析考虑,得出上述19、20、21监测点的归属是正确的,验证了模型的有效准确性。
针对问题四,采用从公民对于政府采取措施、环境保护以及环境现状的看法三个方面来开展问卷调查,用0-1模型把公民对环境关心程度的看法0—1化,0为不关心,1为非常关心。
为了量化公民对环境的关心程度,随机生成20组数据,并用问题三的主成分分析法从这三个方面对公民关于环境的关心程度进行单项综合评价、整体综合评价和分类,得到下面整体综合评价模型:1230.5323 0.3206 0.1471 F t t t =++通过对整体综合得分的分类达到了解单个公民和整体对环境的关心程度的目的。
空气质量预测模型的分析与应用

空气质量预测模型的分析与应用一、引言随着人们环保意识的增强以及大气污染日益加重,对空气质量的关注度越来越高,如何准确预测空气质量成为了人们关注的焦点。
本文将对空气质量预测模型进行分析,并探讨其在实际应用中的作用和应用前景。
二、空气质量预测模型的分类空气质量预测模型根据预测方法和数据来源的不同,可以分为传统预测模型和新型预测模型。
1. 传统预测模型传统预测模型主要包括统计学方法、经验模型和物理模型。
(1) 统计学方法统计学方法直接根据历史数据进行预测,包括回归方法、时间序列方法等。
其中,回归方法是一种基于样本观测的条件期望值的预测方法,可以用来描述响应变量与一个或多个自变量之间的关系,对于空气质量预测模型的建立具有一定的参考价值。
时间序列方法则是根据历史数据的趋势、季节性等相似特征进行预测。
(2) 经验模型经验模型是基于实验或实际经验得出的模型,其基本思想是先建立统计模型,再通过模型形式简单化来试图推断未知现象。
经验模型可分为简单经验模型和人工神经网络模型两种。
其中,简单经验模型主要是一些经验公式或经验关系式,而人工神经网络模型则是一种利用神经元之间相互连接的方式进行模拟物理系统的方法。
(3) 物理模型物理模型是基于基本物质力学、化学、气象学原理与方程式等,建立空气质量的数学模型,从而预测未来的空气质量。
比如,气象模型、化学反应模型等。
2. 新型预测模型新型预测模型是近年来兴起的一种空气质量预测方法,主要包括机器学习方法、深度学习方法和灰色系统模型等。
(1) 机器学习方法机器学习是利用计算机高效的处理海量数据并从中学习规律的一种方法。
在空气质量预测中,机器学习方法可以通过数据挖掘来得到更加准确的预测结果。
目前,常用的机器学习方法主要包括决策树、支持向量机等。
(2) 深度学习方法深度学习是一种新型的机器学习方法,主要应用于人工智能领域的大规模数据处理。
深度学习通过构建多层神经网络来实现对数据的学习和预测。
空气质量监测预测模型研究

空气质量监测预测模型研究近年来,随着城市人口增加和交通工具使用量的增加,空气质量问题已成为城市面临的一大挑战。
因此,建立一个准确可靠的空气质量监测预测模型至关重要。
一、当前的空气质量监测预测模型存在的问题当前空气质量监测预测模型存在的问题主要有以下三点:1. 数据质量不足:空气质量监测需要大量数据支持,但是目前的监测站点数量有限,监测数据也具有时空分布不均的特点,导致监测数据质量不足。
2. 监测范围有限:监测点通常只能覆盖城市中心区域,而城市的郊区和乡村地区监测点数量较少,监测覆盖面较小。
3. 模型精度较低:当前的预测模型主要基于统计和数据挖掘算法,精度较低,容易出现误差较大的情况,影响模型的可靠性。
二、基于深度学习的空气质量监测预测模型随着深度学习技术的发展,基于深度学习的空气质量监测预测模型正在逐渐成为研究热点。
基于深度学习的空气质量监测预测模型主要有以下特点:1. 数据处理能力强:深度学习能够从大量的数据中提取关键特征,有效解决数据质量不足的问题。
2. 模型精度高:深度学习模型能够利用大量历史数据进行训练,提高模型的预测精度。
3. 适应性强:深度学习模型适应能力强,能够应对不同气象条件和污染源对空气质量的影响。
三、基于深度学习的空气质量监测预测模型的优化方法基于深度学习的空气质量监测预测模型的优化方法主要有以下三种:1. 增加数据样本量:深度学习模型的训练需要大量的样本数据,通过采集更多的监测数据可以有效提高模型的预测精度。
2. 采用卷积神经网络模型:卷积神经网络是目前较为成熟的深度学习模型之一,对图像和时序数据的特征提取具有优异的效果。
将卷积神经网络应用到空气质量监测预测模型中,能够有效提高模型精度。
3. 引入机器学习算法:深度学习模型的训练需要大量的数据和计算资源,而机器学习算法则能够利用少量样本数据进行训练,所需计算资源也较少。
因此,将机器学习算法与深度学习模型相结合,不仅可以提高模型的预测精度,还能够实现模型的在线学习和实时更新。
空气质量综合评价模型
1 问题重述从2011年开始,我国多个城市出现了严重的雾霾天气,形成雾霾的PM2.5逐渐被人们所关注。
2012年,空气质量新标准——《环境空气质量标准》出台。
AQI评价的6种污染物浓度限值各有不同,在评价时各污染物都会根据不同的目标浓度限值折算成空气质量分指数AQI,范围从0~500,大于100的污染物为超标污染物。
这种计算方法就存在一个问题,当污染物浓度超出最高上限时,AQI的值最高也只能是500,在这之上的指数不存在,这种情况称为“爆表”,即用AQI就不能描述这类特别严重的污染天气。
因此,需要对AQI上限设为500的计算方法进行改进。
2 问题分析空气质量分指数是针对单项污染物而规定的指标。
从各项污染物的IAQI中选择最大值确定为AQI,当AQI大于50时将IAQI最大的污染物确定为首要污染物;当污染物浓度超出最高上限,AQI 的值发生“爆表”,上述算法已不适用,因此,采用新的算法,模糊综合指数法来进行改进。
将收集的数据运用所建模型进行计算,把得到的结果与原始算法的结果进行对比,发现两种算法所得的评价指标各不相同,但均能反映出空气质量的好坏。
而建立的模型能够基本克服AQI 指数“爆表”的情况。
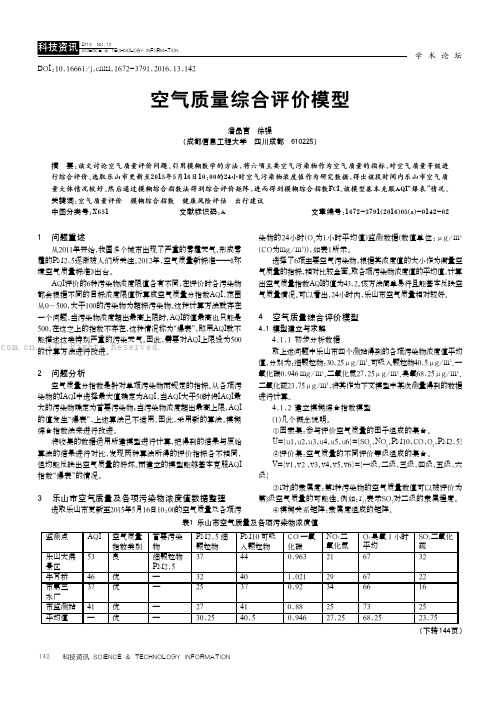
3 乐山市空气质量及各项污染物浓度值数据整理选取乐山市更新至2015年5月16日10:00的空气质量及各项污染物的24小时(O3为1小时平均值)监测数据(数值单位:μg/m3(CO为mg/m3)),如表1所示。
选择了6项主要空气污染物,根据其浓度值的大小作为衡量空气质量的指标,相对比较全面。
取各项污染物浓度值的平均值,计算出空气质量指数AQI的值为43.2。
该方法简单易行且能基本反映空气质量情况。
可以看出,24小时内,乐山市空气质量相对较好。
4 空气质量综合评价模型4.1 模型建立与求解4.1.1 初步分析数据取上述问题中乐山市四个测站得到的各项污染物浓度值平均值,分别为:细颗粒物:30.25μg/m3、可吸入颗粒物40.5μg/m3、一氧化碳0.946mg/m3、二氧化氮27.25μg/m3、臭氧68.25μg/m3、二氧化硫23.75μg/m3,将其作为下文模型中某次测量得到的数据进行计算。
空气质量等级与数学建模

承诺书我们仔细阅读了五一数学建模联赛的竞赛规则。
我们完全明白,在竞赛开始后参赛队员不能以任何方式(包括电话、电子邮件、网上咨询等)与本队以外的任何人(包括指导教师)研究、讨论与赛题有关的问题。
我们知道,抄袭别人的成果是违反竞赛规则的, 如果引用别人的成果或其它公开的资料(包括网上查到的资料),必须按照规定的参考文献的表述方式在正文引用处和参考文献中明确列出。
我们郑重承诺,严格遵守竞赛规则,以保证竞赛的公正、公平性。
如有违反竞赛规则的行为,我们愿意承担由此引起的一切后果。
我们授权五一数学建模联赛赛组委会,可将我们的论文以任何形式进行公开展示(包括进行网上公示,在书籍、期刊和其他媒体进行正式或非正式发表等)。
我们参赛选择的题号为(从A/B/C中选择一项填写): B我们的参赛报名号为:1653参赛组别(研究生或本科或专科):本科所属学校(请填写完整的全名)西南交通大学参赛队员(打印并签名) :1. 卢延鹏2. 侯亚飞3. 刘洪义日期:2015 年 5 月 3 日获奖证书邮寄地址:四川省成都市高新区西部园区西南交通大学犀浦校区X5401 邮政编码:611756收件人姓名:卢延鹏联系电话:177****4865编号专用页竞赛评阅编号(由竞赛评委会评阅前进行编号):裁剪线裁剪线裁剪线竞赛评阅编号(由竞赛评委会评阅前进行编号):参赛队伍的参赛号码:(请各参赛队提前填写好):1653题目空气污染问题研究摘要本文运用高斯扩散模型,污染物自由扩散模型,烟团模型等数学模型,结合适当的分析解决了空气污染问题。
对于问题一,我们查找国标与美标,并分析两者存在的差别与各自的优劣,然后根据京津冀地区近期的空气质量,参考国标和美标的参数值,选择更严格的浓度限值,建立针对于京津冀地区的衡量空气质量优劣程度等级的数学模型。
对于问题二,我们利用网络在相关官方权威网站查找京津冀地区近期的空气污染物相关数据及其空气质量指数,并通过数据计算分析和比较,列出京津冀地区主要污染源和污染参数,并结合京津冀地区的具体情况分析影响空气质量的主要污染源的性质和种类。
我国城市环境空气质量预报主要模型及应用
我国城市环境空气质量预报主要模型及应用我国城市环境空气质量预报主要模型及应用一、引言随着我国城市化进程的加快,城市环境污染问题日益突出。
其中,空气质量问题成为影响居民身心健康的重要因素之一。
为了及时有效地预警和控制空气污染,我国不断完善城市环境空气质量预报系统,采用各种预报模型进行研究和应用。
本文将介绍我国城市环境空气质量预报主要模型及其应用。
二、主要模型及原理1. 线性回归模型线性回归模型是一种较为简单和常用的模型,其基本思想是通过建立气象、大气污染物浓度和其他可能影响空气质量的因素之间的线性关系,进行空气质量预报。
该模型的主要优点是计算速度快,但也存在着对数据分布假设较强、对气象和污染物之间关系的线性描述可能不准确等问题。
因此,在实际应用中,往往需要结合其他模型进行校正和优化。
2. 时间序列模型时间序列模型基于历史数据建立统计模型,利用时间维度的信息进行预测。
常用的时间序列模型有ARIMA(自回归综合移动平均模型)、VAR(向量自回归模型)等。
这些模型能够较好地捕捉空气质量的季节性、周期性和趋势性变化,并针对性地进行预测。
不过,时间序列模型对数据的平稳性要求较高,对于非平稳数据的预测效果可能较差。
3. 统计学模型统计学模型包括传统的回归模型、聚类模型和时间序列模型等。
这些模型通过对历史数据进行统计分析和建模,获取不同时段的变化规律,并进行预测。
这些模型尤其适用于长期变化较为缓慢的城市空气质量预报。
4. 机器学习模型机器学习模型是近年来在城市环境空气质量预报中得到广泛应用的一种方法。
这些模型通过大量的历史数据进行学习和训练,以获取数据特征之间的关系,并做出预测。
常用的机器学习模型包括支持向量机(SVM)、人工神经网络(ANN)、随机森林(Random Forest)等。
这些模型的优点是可以很好地应对非线性关系,能够更准确地预测空气质量。
三、模型应用我国城市环境空气质量预报主要用于预警和控制空气污染,保护居民身心健康。
空气质量预测模型的建立与优化
空气质量预测模型的建立与优化空气质量是衡量城市环境质量的重要指标之一,对人们的健康和生活质量有着重要的影响。
为了及时了解和预测空气质量,建立有效的模型成为了当前研究的焦点之一。
本文将介绍空气质量预测模型的建立与优化方法。
1. 数据采集与预处理为了建立空气质量预测模型,首先需要获取相关的数据。
目前,常用的数据来源包括气象站点观测数据、空气质量监测站点观测数据、卫星遥感数据等。
这些数据需要经过预处理,包括缺失值处理、异常值处理、数据差分等。
2. 特征选择与提取在建立空气质量预测模型时,选择合适的特征对于模型的准确性至关重要。
常用的特征选择方法包括相关性分析、主成分分析等,可以根据特征与目标变量之间的关系选择最相关的特征。
此外,还可以利用卷积神经网络等方法进行特征提取,提取更具有代表性和判别性的特征。
3. 模型选择与建立空气质量预测模型的建立可以使用传统的统计模型,如线性回归、逻辑回归等,也可以使用机器学习算法,如支持向量机、随机森林、深度学习等。
模型的选择需考虑模型的性能、计算复杂度和实际应用的需求。
同时,可以结合多个模型进行集成学习,提高模型的预测准确性。
4. 模型训练与调优在选择好模型后,需要对模型进行训练和调优。
模型的训练可以使用交叉验证等方法,将数据集划分为训练集和验证集,通过验证集来评估模型的性能。
调优可以采用网格搜索、遗传算法等方法,寻找模型的最优超参数,提高模型的泛化能力。
5. 模型评估与优化模型的评估是验证模型的性能的重要环节。
常用的评估指标包括均方根误差(RMSE)、平均绝对误差(MAE)、决定系数(R^2)等。
通过与实际测量结果对比,可以评估模型的准确性和稳定性。
如果模型存在较大偏差或方差,可以通过增加样本量、优化特征选择、调整模型参数等方法进行优化。
6. 模型应用与展望建立好的空气质量预测模型可以应用于空气污染预警、环境保护政策制定等方面。
通过预测和监测空气质量,可以及时采取措施,保障公众健康和城市可持续发展。
大气污染模型
OPTIMIZED EMISSIONS
英国空气质量模型
Measurement platform: new FAAM BAe-146
Measured species
Gases:
Long-lived: CO2, CO, N2O, CH4 Reactive inorganic: SO2, NO, NO2, O3 NH3, HNO3 Organic: VOCs Mercury Non-refractory sub-micron NH4+, NO3-, SO42-, organics Heavy metals
•所采用模型必须提供对地球系统尽可能完整、翔实的表述。 •模型中必须包罗地球系统内各组分间的相互作用、过程、 转化等; •模型所模拟的尺度巨大(时间、空间); •模型的建立是基于对地球系统中主要圈层(水圈、大气 圈等)的作用机制的充分认识与理解; •模型-非线性;预测结果?
地球系统模型的发展
ATMOSPHERE LAND OCEAN ICE SULPHUR LAND OCEAN ICE SULPHUR LAND OCEAN ICE SULPHUR LAND OCEAN ICE LAND OCEAN CARBON CHEMISTRY
CH4 and N2O modelling
Enhancement of CH4 due to UK emissions Enhancement of N2O due to UK emissions -1. predicted with FRAME under W wind at 8.6 m s-1. predicted with FRAME under W wind at 8.6 m s
Anthropogenic NOx emissions [IPCC, 2001]
空气质量数据校准问题的数学模型
空气质量数据校准问题的数学模型
空气质量数据校准问题的数学模型可以使用线性回归模型来描述。
线性回归模型的一般形式为:
Y = β0 + β1X1 + β2X2 + ... + βnXn + ε
其中,Y表示观测到的空气质量数据,X1, X2, ..., Xn表示校准参考因素,β0, β1, β2, ..., βn表示模型的回归系数,ε表示模型的误差项。
为了确定回归系数,可以使用最小二乘法来进行估计。
最小二乘法的目标是最小化残差平方和,即使得ε的平方和最小化。
通过最小二乘法可以得到回归系数的估计值。
在空气质量数据校准问题中,校准参考因素可以包括气象数据、地理位置、污染源等。
通过收集并观测这些参考因素和空气质量数据,建立数学模型后,可以使用最小二乘法估计回归系数,从而校准空气质量数据。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
空气质量模型
Document serial number【KKGB-LBS98YT-BS8CB-BSUT-BST108】
空气质量模型是用数学方法来模拟影响大气污染物的扩散和反应的物理和化学过程。
基于输入的气象数据和污染源信息如排放率,烟囱高度等,这些模型可以模拟直接排入大气的一次污染物和由于复杂的化学反应形成的二次污染物。
这些模型对空气质量管理是非常重要的,因为他们被许多机构用来测算源分担率,同时帮助制定有效的削减污染物排放的政策。
例如空气质量模型可以用来预测一个新的污染源会不会达标排放,如果超标的话,还可以给出适当的控制措施。
此外,空气质量模型还可以预测未来新的政策法规实施后的污染物的浓度。
可以估计政策法规的有效性以及减少人类和环境暴露。
最常用的控制质量模型包括以下3类:
一。
扩散模型。
这些模型主要用来模拟污染源附近接收点的污染物浓度。
扩散模型运用数学公式可描绘污染物扩散过程,基于源强和气象数据,扩散模型可以用来预测下风向接收点的浓度。
这些模型用来评估NationalAmbientAirQualityStandards(NAAQS),andotherregulatoryrequireme ntssuchasNewSourceReview(NSR)andPreventionofSignificantDeterioration( P S D)r e g u l a t i o n s的有效性。
扩散模型主要包括:
1.A e r m o d模型系统
是稳态大气扩散模式,适用于地面源和抬升源,简单和复杂地形。
2.C a l p u f f模型系统
是非稳态大气扩散模式,适用于大范围传输和复杂地形。
3.B L P BLp是一个高斯烟流模型,适用于处理烟气抬升和下洗来自于固定线源
4.C A L I N E 3
CALINE3是一个稳定的高斯扩散模型,用来预测不是很复杂地形的区域的高速路下风向接收点的浓度
5.C A L3Q H C/C A L3Q H C R
CAL3QHC基于CALINE3开发,适用于十字路口的延误和排队等待。
CAL3QHCR是C A L3Q H C的精简版本
6.C T D M P L U S
ComplexTerrainDispersionModelPlusAlgorithmsforUnstableSituations(CTD MPLUS)是一个精简的点源高斯空气质量模型,适用于稳定气象条件和复杂地形,这个模型完全涵盖了稳定和中性气象条件。
C T S C R E E N是一个t h e s c r e e n i n g v e r s i o n o f C T D M P L U S.
7.O C D
OffshoreandCoastalDispersionModelVersion5(OCD)海岸扩散模型是一个线性高斯模型,用来预测海岸线附近点源,面源,线源排放引起的排放,该模型融入了烟流传输和扩散,需要输入小时气象数据
二。
光化学模型。
这些模型主要用在大空间的多种污染源作用下的污染物浓度及其惰性污染物和非惰性污染物的沉降。
大气光化学模型分两类:一类是拉个朗日法,该法计算简单,但是大气物理过程描述不全面,一类是欧拉法能更好的刻画大气物理化学过程。
1.C M A Q(C o m m u n i t y m u l t i-s c a l e a i r q u a l i t y)
E P A's C M A Q模型系统包括i n c l u d e s s t a t e-o f-t h e-sciencecapabilitiesforconductingurbantoregionalscalesimulationsofmult ipleairqualityissues,包括O3,PM,空气毒物,酸沉降,能见度下降等。
2.C A M x(c o m p r e h e n s i v e a i r q u a l i t y m o d e l w i t h e x t e n s i o n s)
模型可以处理大量的惰性和化学活性物质,包括臭氧,颗粒物,有机,无机的PM2.5/PM10,汞等有毒有害物质,该模型还可以源分配功能和plume-in-grid功能。
3.REMSAD(Regionalmodelingsystemforaerosolsandedposition)
REMSAD通过预测一定区域内的大气物理和化学过程来计算惰性的和化学活性物质的浓度,可以处理地区灰霾,颗粒物,及其他外来传输的大气污染物,包括可溶性的酸和汞。
4.U A M-V(U r b a n a i r s h e d m o d e l v a r i a b l e g r i d) UAM-V光化学模型系统主要用来研究臭氧,它是一个3维的光化学网格模型,模型可以处理大量的惰性和化学活性物质,这个模型主要应用在计算不利气象条件下臭氧浓度。
三。
接收点模型这些模型运用观测技术,通过对接收点和源的排放污染物的的测量来衡量源对接收点的污染的贡献。
不像光化学模型和扩散模型,接收点模型不用源强,气象数据,化学传输机理来预测污染源对接收点的污染贡献率。
而是用源和接收点气体或者颗粒物的理化特征来鉴别污染源对接收点的浓度贡献率.1.CMB(ChemicalMassBalance)TheEPA-CMBVersion8.2用源信息和空气质量数据来界别源分担率,理化特征相同的源排放物质该模型不能将其区别开来.2.UNMIX模型不用源的化学数据,而是使用大气监测数据通过该模型来给出源的化学特征,利用数学公式进行因子分析,源解析,对一个特定的污染物,该模型可以估计源的数量,源的组成和源的分担率。
3.P M F(P o s t i v e M a t r i x F a c t o r i z a t i o n。