关于数据库表的说明
数据库表描述-概述说明以及解释

数据库表描述-概述说明以及解释1.引言1.1 概述在数据库管理系统中,表是一种结构化的数据存储单元,它由行和列组成,用于存储具有相似特性的数据。
数据库表描述着整个数据库的结构和关系,是数据存储和管理的基本单位之一。
通过对数据库表的描述,我们可以清晰地了解数据的组织结构,实现数据的高效存储和管理。
在本文中,我们将介绍数据库表的定义、作用以及相关的设计原则,以帮助读者深入了解数据库表的重要性和设计要点。
通过本文的学习,读者将能够更好地理解和应用数据库表,提高数据库系统的性能和可维护性。
1.2文章结构文章结构部分主要包括本文的组织结构和内容安排。
在本文中,我们将分为引言、正文和结论三个部分来介绍数据库表的描述。
在引言部分,我们会概述本文的主题,介绍数据库表描述的重要性和背景,以及本文的目的和结构。
在正文部分,我们将详细讨论数据库表的定义、作用、组成要素和设计原则,从而帮助读者深入了解数据库表的概念和特点。
在结论部分,我们会总结数据库表描述的重要性,强调数据库表设计的关键因素,并对数据库表描述的未来发展进行展望。
通过全面地介绍数据库表的描述和设计原则,我们希望读者可以更好地理解和应用数据库表,提高数据管理和存储的效率和质量。
1.3 目的在数据库系统中,数据库表描述是非常重要的。
它可以帮助开发人员更好地了解数据库表的结构和功能,帮助维护人员更好地管理和维护数据库表,帮助用户更好地理解数据库表中存储的数据。
因此,本文的目的是通过对数据库表描述的介绍,帮助读者了解数据库表的重要性和作用,掌握数据库表的基本概念和设计原则,以提高数据库表设计的质量和效率。
同时,希望通过本文的讨论,引发对数据库表描述的思考和讨论,推动数据库表描述在未来的进一步发展和应用。
2.正文2.1 数据库表的定义和作用数据库表是数据库中的一个重要组成部分,它是用来存储数据的结构化方式。
每个数据库表都包含了一定数量的行和列,行代表记录,列代表属性。
数据库表描述

数据库表描述全文共四篇示例,供读者参考第一篇示例:数据库表是数据库系统中的基本组成单元,用来存储特定类型的数据。
它由行和列组成,行代表数据记录,列代表数据属性。
在数据库设计中,表的结构和字段类型需要经过精心设计,以确保数据的存储和检索效率。
本文将探讨数据库表的描述和设计方法。
一、数据库表的描述1. 表名:数据库表需要有一个唯一的名称来区分不同的表。
表名应该简洁明了,能够清晰地表达表所存储的数据类型。
一般来说,表名采用复数形式,并使用下划线或驼峰命名规则。
2. 字段(列):数据库表由多个字段组成,每个字段代表数据的一个属性。
字段的命名应该具有描述性,能够清晰地表达该字段存储的数据内容。
常见的字段类型包括整型、字符型、日期型等。
3. 数据类型:字段的数据类型决定了字段可以存储的数据范围和格式。
常见的数据类型包括整型(INT)、字符型(VARCHAR)、日期型(DATE)等。
选择合适的数据类型可以提高数据库的存储效率和数据完整性。
4. 主键:主键是表中用来唯一标识每条记录的字段,通常是一个或多个字段的组合。
主键的值必须唯一且不能为空,可以通过主键索引来加快数据检索速度。
主键的选择应该遵循唯一性和稳定性原则。
5. 外键:外键是表与表之间建立关联关系的依据。
外键是指在一个表中存在的另一个表的主键,用来确保数据的一致性和完整性。
外键约束可以在数据库设计时设置,以确保引用表的数据不会出现错误或不一致。
6. 索引:索引是一种提高数据检索效率的数据结构,可以加速查询操作。
在数据库表中设置适当的索引可以减少搜索时间,并提高数据库的性能。
常见的索引类型包括主键索引、唯一索引、组合索引等。
7. 约束:约束是用来确保数据完整性和一致性的规则。
常见的约束包括主键约束、唯一约束、外键约束、默认值约束等。
在设计数据库表时,应该根据业务需求和数据关系来设置适当的约束。
二、数据库表的设计方法1. 标识表的对象:在设计数据库表时,首先需要确定要存储的数据对象和关系,然后根据需求来设计表的结构和字段。
数据库表的说明书

数据库表的说明书概述本文档旨在提供有关数据库表的详细信息和说明。
它将介绍数据库表的结构、字段和关系,以帮助用户更好地理解和使用数据库。
以下是数据库表的详细说明。
表名称:[表名称]表说明:[表说明]表结构字段名数据类型约束条件说明-------------------------------------------------------------[字段1] [数据类型] [约束条件] [字段1说明][字段2] [数据类型] [约束条件] [字段2说明]...[字段n] [数据类型] [约束条件] [字段n说明]字段说明:- 字段名:指数据库表中的字段名称。
- 数据类型:指字段的数据类型,如字符串、整数、日期等。
- 约束条件:指字段的约束条件,如唯一性、非空等。
- 说明:对字段进行详细说明。
关系本数据库表与其他表之间存在以下关系:关系类型相关表名关系说明-------------------------------------------------------------[关系1] [相关表1] [关系1说明][关系2] [相关表2] [关系2说明]...[关系n] [相关表n] [关系n说明]关系说明:- 关系类型:指关系的类型,如一对一、一对多、多对多等。
- 相关表名:指与本表存在关系的其他表的名称。
- 关系说明:对关系进行详细说明。
使用示例以下是一个使用本数据库表的示例:INSERT INTO [表名称] ([字段1], [字段2], ..., [字段n]) VALUES ([值1], [值2], ..., [值n]);说明:- 表名称:指要插入数据的表的名称。
- 字段1、字段2、...、字段n:指要插入数据的字段名称。
- 值1、值2、...、值n:指要插入的值。
注意事项在使用本数据库表时,请注意以下事项:1. 确保按照字段的约束条件输入有效的数据。
2. 遵守本数据库表与其他表之间的关系。
Mysql数据库information_schema系统表说明
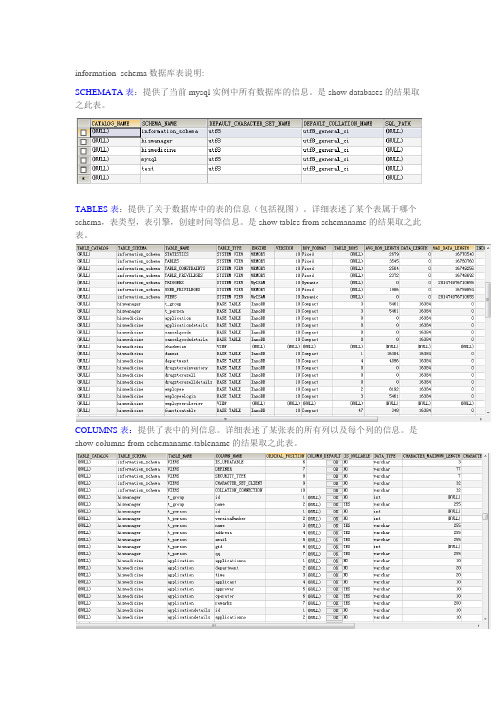
information_schema数据库表说明:SCHEMATA表:提供了当前mysql实例中所有数据库的信息。
是show databases的结果取之此表。
TABLES表:提供了关于数据库中的表的信息(包括视图)。
详细表述了某个表属于哪个schema,表类型,表引擎,创建时间等信息。
是show tables from schemaname的结果取之此表。
COLUMNS表:提供了表中的列信息。
详细表述了某张表的所有列以及每个列的信息。
是show columns from schemaname.tablename的结果取之此表。
STATISTICS表:提供了关于表索引的信息。
是show index from schemaname.tablename的结果取之此表。
USER_PRIVILEGES(用户权限)表:给出了关于全程权限的信息。
该信息源自er 授权表。
是非标准表。
SCHEMA_PRIVILEGES(方案权限)表:给出了关于方案(数据库)权限的信息。
该信息来自mysql.db授权表。
是非标准表。
TABLE_PRIVILEGES(表权限)表:给出了关于表权限的信息。
该信息源自mysql.tables_priv 授权表。
是非标准表。
COLUMN_PRIVILEGES(列权限)表:给出了关于列权限的信息。
该信息源自mysql.columns_priv授权表。
是非标准表。
CHARACTER_SETS(字符集)表:提供了mysql实例可用字符集的信息。
是SHOW CHARACTER SET结果集取之此表。
COLLATIONS表:提供了关于各字符集的对照信息。
COLLATION_CHARACTER_SET_APPLICABILITY表:指明了可用于校对的字符集。
这些列等效于SHOW COLLATION的前两个显示字段。
TABLE_CONSTRAINTS表:描述了存在约束的表。
以及表的约束类型。
KEY_COLUMN_USAGE表:描述了具有约束的键列。
数据库中三种基本类型的表

数据库中三种基本类型的表
在数据库中,通常会有三种基本的表,它们分别是:
1. 主表(Main Table):
-主表是数据库中的核心表,通常包含系统中最关键的信息,是其他表的关联点。
-主表的每一行通常代表一个独特的实体,它可能包含与其他表关联的外键,以建立不同表之间的关系。
-例如,在一个图书管理系统中,书籍信息的表可能是主表,包含书籍的基本信息,如书名、作者、出版日期等。
2. 从表(Subsidiary Table):
-从表是与主表相关联的表,通过外键与主表建立关系,用于存储与主表相关的详细信息。
-从表中的每一行通常与主表中的一行相对应,通过外键建立联系。
-以图书管理系统为例,书籍的借阅记录可能存储在一个从表中,与主表中的书籍信息关联,包含借阅者、借阅日期等信息。
3. 关联表(Associative Table):
-关联表通常用于解决多对多关系,它包含两个或更多个表的主键,建立了这些表之间的关联关系。
-关联表不存储实际的业务数据,而是用于表示多对多关系中的对应关系。
-以图书管理系统为例,如果一个作者可以写多本书,一本书也可以有多个作者,那么可以使用一个关联表来表示书籍和作者之间的多对多关系。
总体而言,这三种基本类型的表在数据库设计中起到了不同的作用,通过合理地设计和使用这些表,可以更好地组织和管理数据,确保数据库结构的合理性和数据的完整性。
数据库递归表设计-概述说明以及解释

数据库递归表设计-概述说明以及解释1.引言1.1 概述概述数据库递归表设计是在数据库中使用递归表达式来处理层次结构数据的一种方法。
在许多实际应用中,数据往往以层次结构的形式存在,即数据之间存在一种父子或祖先后代的关系。
递归表设计可以很好地处理这种层次结构数据,并提供了一种有效的方式来组织和查询这些数据。
在递归表设计中,一张表可以包含指向自己的外键,也就是说一个记录可以有一个或多个指向同一表的记录作为它的“父节点”。
这个概念类似于树形结构中的父子关系,通过递归表达式的应用,可以轻松地对这种层次结构数据进行查询和操作。
递归表的设计不仅局限于处理层次结构数据,也可以用于解决其他相关问题,比如图论中的图数据结构。
递归表的设计原则可以应用于多种情况,只要数据存在某种递归的关系,都可以考虑使用递归表设计方法。
本文的目的是介绍数据库递归表设计的概念、应用场景和设计原则。
通过深入了解递归表的概念和原理,读者可以更好地理解和应用递归表设计来解决实际问题。
接下来的文章将分别介绍递归表的定义、应用场景和设计原则,并对其进行总结和展望。
1.2 文章结构文章结构部分的内容:文章的结构包括引言、正文和结论三个主要部分。
引言部分主要对本篇文章的主题进行概述,并介绍文章的结构和目的。
首先,我们会简要介绍递归表的定义和应用场景,引起读者的兴趣。
接着,我们会明确本文的目的,即通过对递归表的设计原则的探讨,提供一个有效的指导方针,帮助读者在数据库设计中灵活运用递归表。
正文部分将对递归表的定义、应用场景和设计原则进行详细阐述。
在2.1小节中,我们将会从理论的角度来介绍递归表的定义,包括递归关系的概念和递归表的特点。
在2.2小节中,我们将会列举一些递归表常见的应用场景,例如组织结构、树形结构等,并分析这些场景下递归表的设计原则和注意事项。
最后,在2.3小节中,我们将会总结出一些通用的递归表的设计原则,并给出一些实际案例进行详细说明,帮助读者更好地理解和运用这些原则。
数据库表设计的规范与准则

数据库表设计的规范与准则数据库是现代软件系统中不可或缺的一部分,而数据库表的设计则是数据库系统的基石。
合理的数据库表设计能够提高数据库的性能和可维护性,对系统的稳定运行起着重要作用。
在本文中,我们将探讨数据库表设计的规范与准则,帮助开发人员合理、高效地设计数据库表结构。
一、数据库表设计原则1. 单一职责原则在数据库表设计中,每个表应该只负责存储一种类型的数据,并且该项数据的意义应该相互独立。
例如,我们不应该在用户表中同时存储用户的地址信息和登录信息,而应该将其拆分为用户信息表和地址信息表。
2. 唯一主键原则每个表都应该有一个唯一的主键,用于唯一标识表中每一行数据。
这有助于提高查询和更新数据的效率,并避免数据冗余和不一致。
主键的选择可以是自增长整数、全局唯一标识符(UUID)或其他具有唯一性的属性。
3. 数据类型选择规范在选择数据类型时,应根据需求和数据的属性选择合适的数据类型。
例如,对于存储金额的字段,应选择Decimal而不是Double,以确保精确度和计算准确性。
另外,避免使用过大的数据类型,以减少资源消耗和存储空间的浪费。
4. 关系规范化数据库的关系规范化是指对数据进行合理、有效的组织,以消除冗余和数据不一致。
根据关系数据库的三大范式,应将数据分解为不可再分的最小单位,并通过引入外键建立表与表之间的关系。
这样可以提高数据的一致性和查询性能。
二、数据库表设计规范1. 表名规范每个表应具有具有相关的、有意义的名称,易于理解和识别。
表名应该使用小写字母,并使用下划线分隔单词以提高可读性。
避免使用特殊字符、缩写和不相关的词汇作为表名。
2. 字段名规范字段名应具有描述性,并明确表示字段的用途和数据类型。
字段名应使用小写字母,并使用下划线分隔单词以提高可读性。
避免使用特殊字符和不相关的词汇作为字段名。
3. 主键设计规范主键字段应该是短小、简单、易于识别的。
一般情况下,整数类型字段是首选,例如自增长的整数或UUID。
数据库 关联表

数据库关联表介绍数据库关联表是关系型数据库中的一种重要概念,用于建立不同表之间的关联关系。
通过关联表,可以实现数据的集成、查询以及数据一致性的保证。
本文将从数据库关联表的概念入手,深入探讨数据库关联表的原理、常见类型以及使用时的注意事项。
数据库关联表的概念数据库关联表是指在关系型数据库中,通过一个或多个字段与其他表建立关联关系的表。
关联表可以将多个表之间的数据进行连接,实现数据的集成与查询。
数据库关联表的原理数据库关联表的原理主要基于关系型数据库的基本特性,即通过表之间的关联字段建立关联关系。
常见的关联表类型有三种:一对一关联、一对多关联和多对多关联。
一对一关联一对一关联是指两个表之间的关联关系是一对一的关系。
这种关联通常是通过主键和外键进行连接,即在一个表中的记录与另一个表中的记录一一对应。
一对多关联一对多关联是指一个表中的记录与另一个表中的多条记录建立关联关系。
这种关联关系通常是通过外键进行连接,即一个表中的外键与另一个表中的主键建立关联。
多对多关联多对多关联是指两个表之间的关系是多对多的关系。
这种关联关系通常需要借助关联表来实现。
关联表中的记录与两个关联表中的记录建立关联关系,实现两个表之间的多对多连接。
数据库关联表的常见类型在数据库中,常见的关联表类型有三种:内连接、左连接和右连接。
内连接内连接是指连接两个表时,只选择两个表中都有匹配记录的行。
通过内连接,可以实现多个表之间的数据交集查询。
左连接左连接是指连接两个表时,选择左表中的所有记录以及两个表中都有匹配记录的行。
通过左连接,可以实现左表中的所有数据与右表中匹配数据的查询。
右连接右连接是指连接两个表时,选择右表中的所有记录以及两个表中都有匹配记录的行。
通过右连接,可以实现右表中的所有数据与左表中匹配数据的查询。
数据库关联表的使用注意事项选择适当的关联关系在建立关联表时,需要选择适当的关联关系。
一对一、一对多和多对多关联关系各有不同的应用场景,需要根据具体需求来选择合适的关联关系。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
关于数据库表的说明
T_CD表存放所有要调用:物料名称、物料代码、库存地名称、指令执行情况、普通或者连续供料、班次、班组。
T_EMPLOYEE表存放的是:班组、班次、用户名称等用户信息。
T_ERROR表存放的是:程序执行中所出现的记录,都存放到这张表中。
T_FACTORY_TO_FACTORY_ORDER表存放的是:厂际间的指令都存放到这张表中。
T_FACTORY_TO_FACTORY_PLAN表存放的是:从3级下发的厂际计划都存放到这张表中。
T_FACTORY_TO_FACTORY_RSLT表存放的是:厂际间所有产生的实绩记录都在这张表中。
T_FLOW表存放的是:所有流程的使用情况。
T_FLOW_CHILD表存放的是:每一条流程包括的皮带设备名称,流程选择时,出现的该流程所包含的设备。
T_FLOW_ENABLE表存放的是:每条流程的相干性。
T_FLOW_L2L1_RELATION表存放的是:每条流程是普通供料,还是连续供料情况,在TR中绑定的一级程序点。
T_FLOW_STACK_RELATION表存放的是:流程选择时,堆取料机所对应的料堆情况。
T_GET_FLOW_ENABLED表存放的是:每条留成当前的可用状
态。
T_IN_ORDER表存放的是:所有入库指令都存放在该表中,只要存储的指令都存放到该表中。
T_IN_PLAN表存放的是:三级系统给二级系统下发的入库作业计划,都存放到该表中。
T_IN_RSLT表存放的是:执行完的入库指令,所生成的入库作业实绩记录都存放在该表中。
T_JOB_DEL_LOG表存放的是:绑定TNS要执行的数据定期删除工作项目。
T_L1_CONTROL表存放的是:TNS绑定的流程设备是否通过TNS 下发给一级了,可以到该表中查询,并且能更改状态。
T_L2L1_HY_DISK_FLUX表存放的是:混匀14台圆盘给料机的当前瞬时流量。
T_L2L1_HY_DZC表存放的是:混匀电子称累计重量、启动状态、清零指令。
T_L2L1_JL_PDC表存放的是:24台皮带秤的清零、当前重量、当前状态。
T_L2L1_SET_HYGJ表存放的是:二级给一级下发圆盘给料机的瞬时流量值。
T_L2L1_SFY_AVR表存放的是:水分仪的实时值。
T_L2L1_STORE_BLAST表存放的是:料仓料位计的当前实际数值。
T_L2L1_STORE_BLAST_VALUE表存放的是:料仓料位设定的安全值,低于安全值该料仓就变成红色了。