informix学习总结
informix数据库SQL学习

简单的SELECT语句SELECT语句是最重要也是最复杂的SQL语句,它和insert update和delete 语句一起用于数据操作,主要用于:●从数据库中检索数据●作为INSERT语句的一部分产生新的行●作为UPDATE语句的一部分更新信息1.S ELETE语句的简要介绍●构成:SELECT 子句指定要查询的表FROM 子句指定要查询的列WHERE子句选择特定的列或创建一个新的连接条件ORDER BY子句改变数据产生的次序INTO TEMP子句把结果以表的形式存放起来,供以后使用其中SELECT、FORM子句是必选的。
●权限查询数据库必须对该数据库具有connect权限以及对表具有SELECT权限,这些权限通常作为默认值赋给用户。
与数据库的操作权限有关的grant 和revoke语句将在后面讲到。
●关系操作选择:在表中满足特定条件的行的水平子集。
这一类型的SELECT 子句返回表中的一部分行的所有列。
选择是通过SELECT语句的WHERE子句来实现的。
例:SELECT *FROM customWHERE state=”NJ”显示结果如下:customer_num 107fname Charleslname Reamcompany Athletic Suppliesaddressl 41 Jordan Avenueaddress2city Palo Altostate CAzipcode 94304phone 415-356-9876投影:在表中一些列的垂直子集,子集包含了表中这些列的所有行。
这样的SELECT 语句返回表中所有行的一些列。
投影是通过在SELECT语句中的SELECT子句的选项来实现的。
例:SELECT UNIQUE city, state,zipcodeFROM customer查询结果包含了与customer 表中的相同数目的行,但仅投影了列的一个子集显示结果如下:city state zipcodeBartlesville OK 74006Blue Island NY 60406Brighton MA 02135Cheey Hill NJ 08002Denver CO 80219Jacksonville FL 32256Los Altos CA 94022Menlo Park CA 94025Moutain View CA 94040Moutain View CA 94063Oakland CA 94609Palo Alto CA 94303Palo Alto CA 94304Phoenix AZ 85008SELECT语句在大多数情况下同时使用选择和投影,查询返回表中的一些行和一些列。
INFORMIX -4GL新手进阶整理
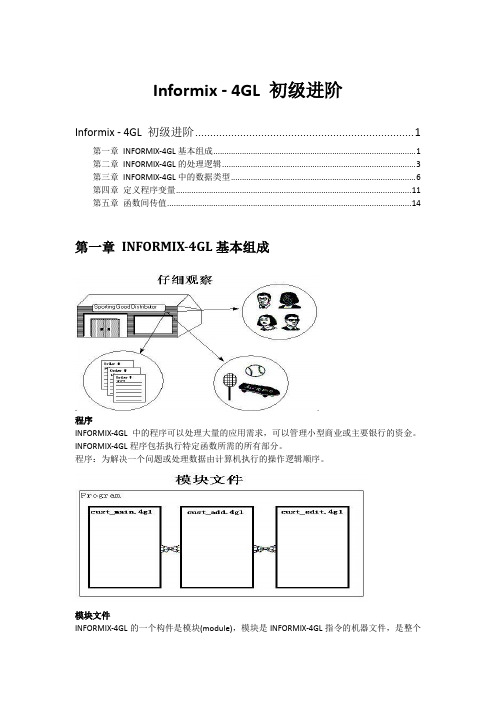
Informix - 4GL 初级进阶Informix - 4GL 初级进阶 (1)第一章INFORMIX-4GL基本组成 (1)第二章INFORMIX-4GL的处理逻辑 (3)第三章INFORMIX-4GL中的数据类型 (6)第四章定义程序变量 (11)第五章函数间传值 (14)第一章INFORMIX-4GL基本组成程序INFORMIX-4GL中的程序可以处理大量的应用需求,可以管理小型商业或主要银行的资金。
INFORMIX-4GL程序包括执行特定函数所需的所有部分。
程序:为解决一个问题或处理数据由计算机执行的操作逻辑顺序。
模块文件INFORMIX-4GL的一个构件是模块(module),模块是INFORMIX-4GL指令的机器文件,是整个程序的一部分。
把一组模块组合在一起,就成为整个程序,上图中有三个模块,合在一起就组成了客户程序。
在上图,跟踪记录客户的程序分成了三个模块,每个模块有其特殊的作用,cust_main.4gl 模块用于驱动和控制程序,cust_add.4gl模块用于管理新增客户记录,cust_edit.4gl模块包括改变或删除客户记录的INFORMIX-4GL代码。
模块包括一个或多个函数的集合。
函数(function)是INFORMIX-4GL代码最基本的单元,它是在被调用时执行的一组INFORMIX-4GL语句序列。
在INFORMIX-4GL程序中函数一次也没执行过也是有可能的,例如,如果从没删除过客户,那么函数delete_cust就不会被调用函数类型在INFORMIX-4GL中有四种函数,不同的函数名表示不同种类的INFORMIX-4GL语句功能。
GLOBALS:在这个函数只用于说明变量声明语句,它也让其它模块知道变量的存在,每个程序只允许有一个GLOBALS函数。
MAIN:给出INFORMIX-4GL开始的位置,INFORMIX-4GL首先总是先读MAIN函数,MAIN函数驱动程序的其余部分,因此,每个程序要有一个MAIN函数(否则INFORMIX-4GL不知从哪儿开始)执行。
Informix导数总结

Infoxmix命令语法总结:1)导出数据库中所有的表结构到文件db.sql$>dbschema -d your_database -t all db.sql2)导出数据库中所有的存储过程到文件db.sql$>dbschema -d your_database -f all db.sql3)导出数据库中的所有对象(包含表,存储过程,触发器。
)到文件db.sql $>dbschema -d your_database db.sql4)导出数据库中一个表的结构到文件db.sql$>dbschema -d your_database_name -t your_table_name db.sql5)导出一个存储过程定义到文件db.sql$>dbschema -d your_database_name -f your_procedure_name db.sql6)如果导出更多的表的信息(EXTENT...)$>dbschema -d your_database_name -ss db.sql7)导出数据库中对用户或角色的授权信息$>dbschema -d your_database_name -p all$>dbschema -d your_database_name -r all8)导出数据库中的同义词$>dbschema -d your_database_name -s all9)导出数据库中的Sequence。
$>dbschema -d payment -seq all cre_seq.sql10)导出表中所有数据$>unload to xxx.txt select * from tablename;11)导入数据到表中$>load from xxx.txt insert into tablename;。
最新informix笔记学习资料
第一章Informix介绍Informix提供了为开放系统开发和实现信息管理应用的先进产品。
核心产品包括应用开发和应用工具,数据库服务器以及中间件。
所有的产品都基于ANSI标准的SQL。
INFORMIX-OnLine:快速容错服务器,可以进行联机事务处理方面的应用; INFORMIX-OnLine是Informix的高性能、容错的、OLTP数据库服务器。
OnLine允许在数据库的字段中存放和使用二进制大对象(BLOBs),从而扩展了数据处理使之可以处理多媒体信息。
它还允许分布式数据库应用。
INFORMIX-SE:低维护服务器,适用于中、小规模的应用环境;INFORMIX-SE服务器适用于需要多用户的数据库服务器的环境,但是高的可用性(availability)和OLTP级别的性能不是关键。
它适用的环境是多用户共享数据库,运行中、小规模的应用。
INFORMIX-SE基于事实上的工业标准的UNIX的文件访问方法,即Informix C-ISAM。
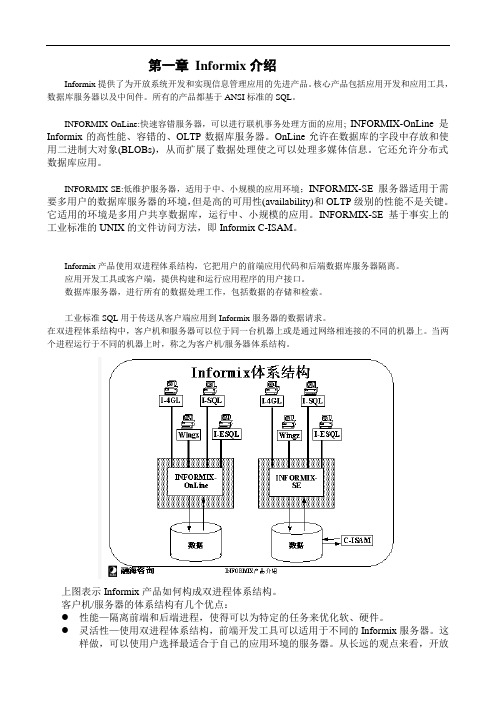
Informix产品使用双进程体系结构,它把用户的前端应用代码和后端数据库服务器隔离。
应用开发工具或客户端,提供构建和运行应用程序的用户接口。
数据库服务器,进行所有的数据处理工作,包括数据的存储和检索。
工业标准SQL用于传送从客户端应用到Informix服务器的数据请求。
在双进程体系结构中,客户机和服务器可以位于同一台机器上或是通过网络相连接的不同的机器上。
当两个进程运行于不同的机器上时,称之为客户机/服务器体系结构。
上图表示Informix产品如何构成双进程体系结构。
客户机/服务器的体系结构有几个优点:●性能—隔离前端和后端进程,使得可以为特定的任务来优化软、硬件。
●灵活性—使用双进程体系结构,前端开发工具可以适用于不同的Informix服务器。
这样做,可以使用户选择最适合于自己的应用环境的服务器。
从长远的观点来看,开放式的体系结构使得来自于不同厂商的前端开发工具和服务器可以协同工作。
informix入门基础学习教程

informix入门基础学习教程Informix是一个关系型数据库管理系统(RDBMS),是IBM公司开发的一种数据库管理系统。
它具有高效、可靠、安全的特点,被广泛应用于企业级应用程序中。
本文将介绍Informix的基础知识和学习教程。
一、Informix的概述Informix是一种面向企业级应用的数据库管理系统,它提供了高性能、可扩展、可靠的数据存储和处理能力。
Informix支持多种操作系统平台,包括Windows、Linux、Unix等。
它的特点包括事务处理、并发控制、数据安全等。
二、安装和配置Informix2. 配置Informix服务器,设置数据库存储路径、内存大小等参数。
3.创建数据库实例,设置数据库名称、用户名和密码等信息。
三、Informix的基本概念1. 数据库:Informix中的数据库是一组相关表的集合,用于存储和管理数据。
2.表:表是数据库中的基本组成单元,用于存储数据。
每个表包含多个列,每个列定义了一种数据类型。
3.列:列是表中的一个字段,用于存储特定类型的数据。
4.行:行是表中的一条记录,包含了一组相关的数据。
5.索引:索引是对表中一列或多列的值进行排序的数据结构,用于提高查询性能。
6.视图:视图是一个虚拟的表,它是基于一个或多个表的查询结果。
视图可以简化复杂的查询操作。
四、基本操作1.创建数据库:使用CREATEDATABASE语句创建一个新的数据库。
2.创建表:使用CREATETABLE语句创建一个新的表,并定义表中的列和其数据类型。
3.插入数据:使用INSERTINTO语句将数据插入到表中。
4.查询数据:使用SELECT语句从表中检索数据。
5.更新数据:使用UPDATE语句修改表中的数据。
6.删除数据:使用DELETEFROM语句从表中删除数据。
7.创建索引:使用CREATEINDEX语句在表上创建索引,以提高查询性能。
8.创建视图:使用CREATEVIEW语句创建一个新的视图。
(最新)informix SQL汇总(包括效率分析)(精品文档)

informix SQL汇总每个数据库管理系统(DBMS)都有其自己的数据处理语言(DML),但所有DML都基于一种语言SQL语言——结构化查询语言(SQL),其发音为“sequel”或“S-Q-L”。
目前SQL的前身是E.F.Codd博士70年代发明的。
第一个实现是在76年,称为sequel。
而SQL首先被采用是在IBM的System R项目中。
86年10月由ANSI确定为正式的关系查询语言标准。
ISO在对其修改后在90年制定为国际工业标准。
无论进行何种数据库学习,SQL语言都是必学内容。
在我国数据库语言SQL标准(GB12991)中规定了两个数据库语言的语法与语义:模式定义语言(SQL-DDL),描述SQL数据库的结构与完整性的约束;数据操纵语言(SQL-DML),描述操作数据库的执行语句在本文章中涉及以上两个中的主要部分,(为叙述方便,以下对其统称为SQL),由于SQL 在嵌入C时表现略有不同,所以下面均以非嵌入时的SQL进行。
另外本文章也不是SQL的入门教材,阅读者应学习并实际用SQL操作过某种数据库。
如果你系统学习过数据库理论,又能熟练操作INFORMIX关系数据库,甚至从事过有关数据库程序的设计,还那么作者在此恭喜你了。
如果你尚未系统学习过数据库理论,并对INFORMIX数据库了解甚少,建议你先阅读有关的文档。
informix SQL汇总【主要SQL语句详解】CREATE DATABASE database_name [WITH LOG IN “pathname”]创建数据库。
database_name:数据库名称。
“pathname”:事务处理日志文件。
创建一database_name.dbs目录,存取权限由GRANT设定,无日志文件就不能使用BEGIN WORK等事务语句(可用START DATABASE语句来改变)。
可选定当前数据库的日志文件。
如:select dirpath form systables where tabtype = “L”;例:create databse customerdb with log in “/usr/john/log/customer.log”;DATABASE databse-name [EXCLUSIVE]选择数据库。
informix数据库的查询优化技术
informix数据库的查询优化技术1.合理使用索引索引是数据库中重要的数据结构,它的根本目的就是为了提高查询效率。
现在大多数的数据库产品都采用IBM最先提出的ISAM索引结构。
索引的使用要恰到好处,其使用原则如下:●在经常进行连接,但是没有指定为外键的列上建立索引,而不经常连接的字段则由优化器自动生成索引。
●在频繁进行排序或分组(即进行group by或order by操作)的列上建立索引。
●在条件表达式中经常用到的不同值较多的列上建立检索,在不同值少的列上不要建立索引。
比如在雇员表的“性别”列上只有“男”与“女”两个不同值,因此就无必要建立索引。
如果建立索引不但不会提高查询效率,反而会严重降低更新速度。
●如果待排序的列有多个,可以在这些列上建立复合索引(compound index)。
●使用系统工具。
如Informix数据库有一个tbcheck工具,可以在可疑的索引上进行检查。
在一些数据库服务器上,索引可能失效或者因为频繁操作而使得读取效率降低,如果一个使用索引的查询不明不白地慢下来,可以试着用tbcheck工具检查索引的完整性,必要时进行修复。
另外,当数据库表更新大量数据后,删除并重建索引可以提高查询速度。
2.避免或简化排序应当简化或避免对大型表进行重复的排序。
当能够利用索引自动以适当的次序产生输出时,优化器就避免了排序的步骤。
以下是一些影响因素:●索引中不包括一个或几个待排序的列;●group by或order by子句中列的次序与索引的次序不一样;●排序的列来自不同的表。
为了避免不必要的排序,就要正确地增建索引,合理地合并数据库表(尽管有时可能影响表的规范化,但相对于效率的提高是值得的)。
如果排序不可避免,那么应当试图简化它,如缩小排序的列的范围等。
3.消除对大型表行数据的顺序存取在嵌套查询中,对表的顺序存取对查询效率可能产生致命的影响。
比如采用顺序存取策略,一个嵌套3层的查询,如果每层都查询1000行,那么这个查询就要查询10亿行数据。
Informix数据库-长事务解析
Informix数据库“长事务”分析解析要理解什么是“长事务”,还要从“事务”本身及数据库的逻辑日志工作原理谈起。
所谓“事务”(transaction),是一个完整的不可分割的数据处理单元。
该单元中所有的数据处理操作要么全部处理成功,要么因其中任意一个操作的失败而完全回滚至整个事务处理前状态。
为了保证事务的完整性,Informix 数据库通过逻辑日志(logical log) 来记录所有的事务操作及其处理的数据。
逻辑日志的作用之一在于对数据所发生的变化进行记录以满足可能的回滚需要。
Informix 数据库服务器把逻辑日志分成多个相互分离的磁盘空间,每个磁盘空间称为一个逻辑日志文件。
由于逻辑日志文件的大小和个数由参数指定,整个逻辑日志的空间是相对固定的,并不能无限制的增长。
所以对于逻辑日志文件的使用是循环进行的。
Informix 数据库服务器按数字顺序依次填充空闲的(即状态为free 或available)的逻辑日志文件。
当第一个逻辑日志文件变满时,接着开始填充下一个逻辑日志文件,直到填充完最后一个逻辑日志文件。
这时,数据库服务器回到第一个逻辑日志文件,试图将其内容释放,以循环使用( 如图1)。
图1. 循环使用的逻辑日志释放已经使用过的逻辑日志,需要具备很多条件。
其中之一就是该日志不能包含仍然活动的( 即还没有提交) 的事务。
因为活动的事务随时存在需要回滚的可能性,如果在事务还没有提交时,包含该事务记录的日志由于被释放重用,原来的事务操作记录被覆盖,当事务由于各种原因需要回滚时,回滚所需的记录就会缺失,从而导致无法保证事务的原子性和完整性。
那么,当数据库服务器需要循环使用某个逻辑日志文件,而该文件又包含有还没有提交的事务时,数据库系统就将被挂起(hang), 处于一种停滞状态,任何对数据库的更新操作都无法继续,从而影响系统的正常处理工作( 如图2)。
图 2. 长事务导致系统挂起为了防止这种现象的发生,我们把占用整个逻辑日志空间在一定比例以上的事务,就叫做“长事务”。
提高INFORMIX数据库运行效率的策略与措施
……
update satmxhz
set
sbrq=b.sbrq,
ye=b.ye,
lxjs=b.lxjs,
wdbs=wdbs+1,
dac=dac
where rowid=id;
……
如原为:
declare ps2 cursor for
select *,rowid
into b,id
from satmxhz
where zh[1,9]=vvjgbm
and bz=″0″
order by zh;
open ps2;
fetch ps2;
fetch cur_mxh;
}
close mx_cur;
close cur_mxh;
commit work;
以上一段程序是将satmxh表中记录转移到satmx表中,虽然可用
begin work;
insert into satmx select * from satmxh;
open ps2;
fetch ps2;
while (sqlca.sqlcode==0){
……
update satmxhz
set
sbrq=b.sbrq,
ye =b.ye,
lxjs=b.lxjs,
wdbs=b.wdbs,
dac=dac
4.建库的日志方式:
(1)No logging:不能进行事务处理。
(2)buffered log:共享缓存满即刷新写入磁盘。
(3)unbuffered log:当一个交易完成时即刷新写入磁盘。
Informix数据库性能常见问题典型情况浅析
Informix数据库性能常见问题典型情况浅析张生成(酒泉职业技术学院,甘肃酒泉735000)摘要:数据库配置安装完成投入运行后。
数据库运行的性能就成为数据库管理人员(DBA)的一个重要任务。
根据教学过程中对Informix数据库的使用,总结出了一些常见性问题的处理经验,希望能和大家共同交流。
关键词:日常信息;处理思路;代价信息TP311.13:A:1672-7800(2010)04-0169-021平时的信息收集和维护工作为了更好地处理可能出现的性能问题,需要在乎时就注意积累操作系统、数据库的日常运行信息,这样可以了解系统的运行特点和基本负荷变化情况,当数据库出现性能问题的时候,这些都是非常有用的信息。
收集Infonxix数据库的日常信息,最简单的可以仅观察onstat-p的输出结果,和数据库性能相关的主要是读缓存率(第一个%cached)、写缓存率(第二个%cached)、顺序扫描数(seqscans)。
读缓存率不应该低于90%,否则就应该关注顺序扫描数,找出经常被顺序扫描的大表,创建相应索引或修改应用SQL,必要时还需要增加数据库BUFFERS。
写缓存率通常不应该低于85%,不过由于受到应用写库的方式和LRU设置的影响,稍微低一些也可以接受。
数据库日志中记录的检查点持续时间(checkpoint durationtime)也需要关注,性能良好的实例中,该值不超过3秒。
在日常维护时,注意定期收集数据库的统计信息(update statistics),如果担心库太大,在业务空闲期间无法完成,至少应该对变化比较频繁的大表针对索引中的第一个字段收集统计信息,语法:update statistics for table mytab(coll);当性能问题出现后,可以按如下步骤来定位问题:首先应该利用操作系统命令查看一下当时操作系统状态:CPU/IO/SWAP,是否和平时差别很大;查看操作系统日志是否最近有异常报错;检查数据库日志,看看是否有断言错误(Assert Failed),是否有数据库内部错误发生,数据库的检查点持续时间相比平常是否有显著增加。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
i n f o r m i x学习总结-标准化文件发布号:(9556-EUATWK-MWUB-WUNN-INNUL-DDQTY-KIIINFORMIX的学习第一章 ESQL/C的数据类型数据类型SQL与C数据类型的对应简单类型SQL CCHAR(n) char(n+1)CHARCTER(n) char *SMALLINT short intINTERGERINT long intSMALLFLOATREAL floatFLOATDOUBLE PRECISIONdoubleSERIAL long intDATE long int复杂类型SQL CDECIMALDEC NUMERIC dec_t or struct decimalMONEY dec_t or struct decimalDATETIME dtime_t or struct dtimeINREVER intrvl_t or struct intrvlVARCHAR varchar or string数据类型转换转换类型转换后FLOAT DECIMAL(16)SMALLFLOAT DECIMAL(8)INTERGER DECIMAL(10,0)SAMLLINT DECIMAL(5,0)数据类型的转换函数有关CHAR类型的函数1、以空值结尾的串的操作函数rdownshift(char *s) 把一个字符串中的所有字母转换成小写形式。
rupshift(char *s) 把一个字符串中的所有字母转换成大写形式。
stcat(char *s, char *dest) 把一个字符串同另一个字符串相连接。
stcmpr(char *s1, char *s2) 比较两个字符串。
stcopy(char *from, char *to) 把一个字符串拷贝到另一个字符串。
stleng(char *string) 统计字符串的长度。
2、定长串的操作函数bycmpr(char byte1, byte2, rpt len) 比较两组连续的字节内存块。
bycopy(char *from, char *to, int len) 把一块内存的内容拷贝到另一块内存。
byfill(char *to, int len, char ch) 用字符填充指定的内存块。
byleng(char from, int count) 统计有效字符的数目。
有效字符是指字符串去除了末尾空格所剩的字符。
3、字符串操作函数ldchar(char *from, int num, char *to) 拷贝定长串到空值结尾的串。
stchar(char *from, char *to, int num) 拷贝空值结尾的串到定长串。
4、字符串函数简单数值转换rstod(char *str, double *dblval) 把以空值结束的字符串转换成C的double型rstoi(char *str, int *intval) 把以空值结束的字符串转换成C的int类型。
rstol(char *str, long *lngval) 把以空值结束的字符串转换成C的long类型。
DATE类型的函数1、创建内部日期rdefmtdate(long *jdate, char *frmt char *str) 生成具有确定格式的日期字符串。
(str 字符串和fmt必须按月、日、年的同一顺序)返回代码:0操作成功。
-1204在str参数中有非法的月份。
-1206在str参数中有非法的日期。
-1209由于str中没有包含年、月、日各部分间的定界符,str的长度必须准确定义为6或8个字节长。
-1212fmt中没有包含年、月、日部分。
fmt和str的有效组合fmt str“mmddyy”“DEC 25th 1997”“mmm.dd.yyyy”“dec 25 1997”“mmm.dd.yyyy”“DEC-25-1997”“mmm.dd.yyyy”“12251997”“mmm.dd.yyyy”“12/25/1997”“yy/mm/dd”“97/12/25”“yy/mm/dd”“1997,December, 25th"“yy/mm/dd”“In the year 1997, the month of December, its 25th day”“dd-mm-yy”“This 25th day of December, 1997”rmdyjul(short mdy[3], long *jdate) 用三个短整数生成一个内部日期这三个整数是有关年、月、日的数字值。
(年必须以完整的形式表达)返回代码:0操作成功。
-1204在mdy[2]中有非法年份。
-1205在mdy[1]中有非法月份。
-1206在mdy[0]中有非法日期。
rstrdate(char *str, long *jdate) 将一个字符串日期转换成一内部格式的日期。
rtoday(long *jdate) 从系统日期创建一个内部日期值。
2、从内部日期转换成其他类型rfmtdate(ling jdate, char *fmt, char *str) 从内部格式的日期类型值创建格式化的字符串。
返回代码:0操作成功。
-1210内部日期不能被转换成月-日-年格式。
-1211程序存储溢出,即存储分配错误。
rjulmdy(long jdate, short mdy[3]) 从一个内部日期生成一个含有3个短整数的数组对应内部日期的月、日、年。
rdatestr(long jdate, char *str) 从一个内部日期值创建缺省的日期字符串。
rdayofweek(long jdate) 给定一内部格式表示的日期,此函数返回所对应的星期中的某一天。
rleapyear(int year) 用来判断给定的年份是否为闰年。
返回值:TRUE(1)是闰年FALSE(0)不是闰年简单数值类型的格式化函数rfmtdouble(double dbval, char *fmt, char *str) 将双精度格式化为指定的模板格式。
rfmtlong(double longval, char *fmt, char *str) 将长整型值格式化为指定的模板格式。
可以构成格式模板串的字符:*以星号代替空格。
&以0代替空格。
#代表一个数字或空格的位置。
<左调整,显示一个逗号,仅当左边有数字时才显示。
.显示一个小数点,一个格式模板串只能有一个小数点。
-显示负号,当数字为负的时候显示。
+显示正号,当数字为正的时候显示。
(显示一个负号,同(一起显示负值。
)显示一个负号,同)一起显示负值。
$显示美元符号。
处理空值的数值类型函数risnull(int type, char *cvar) 检查C变量是否为空值。
rsetnull(int type, char *cvar) 给C变量置空值。
(五)其他函数typalign(int pos, int type) 返回一具有指定数据类型变量的下一个位置。
rtypmsize(int sqltype, int sqllen) 返回你必须分配在存储单元中的指定的C或RDSQLD的字节数。
rtyname(int sqltype) 返回一包含指定RDSQL类型名的以空结尾的串。
rtypwidth(int sqltype, intsqllen) 返回一具有RDSQL类型的值转换为一字符类型时避免截取所需的最小字符数。
ESQL/C数据类型的进一步说明DECIMAL数据类型的使用1、DECIMAL函数——把C的数据类型转换为DECIMAL值deccvasc(char *from, int len, dec_t *to) 把ASCII字符串转换成DECIMAL值。
返回值:0转换成功-1200数字太大,上溢。
-1201数字太小,下溢。
-1213存在非数值字符。
-1216存在错误指数。
注意事项:(1)字符串的前导空格被忽略。
(2)字符串可以有前导符号“+”或“-”。
(3)字符串可以包含e或E的指数形式,指数前可带符号“+”或“-”。
deccvint(int from, dec_t *to) 把C的整数转化成DECIMAL值。
deccvlong(long from, dec_t *to) 把C的长整数转化成DECIMAL值。
deccvdbl(double from, dec_t *to) 把C的双精度值转化成DECIMAL值。
2、DECIMAL函数——把DECIMAL值转换成字符型dectoasc(dec_t *from, char *to, int len, int rt) 把DECIMAL值转换成ASCII字符串。
说明:len串缓冲区字节的最大长度。
rt表示十进制小数右边十进制的位数。
(1)rt=-1,则十进制位的个数有*from的十进制值决定。
(2)如果此数不适合长度len的字符串,则该函数将这个数转换为指数表示的形式。
如果仍不适合,则串用“*”号填满。
如果数的长度短于串长,则右对齐且左部用空格填充。
dececvt(dec_t *from, int ndgt, int *decpt, int *sign) 将一十进制数转换成以空格结束的具有指定个数的字符串,且返回此字符串的指针。
decfcvt(dec_t *from, int ndgt, int *decpt, int *sign) 将一十进制数转换成以空格结束、小数点右边具有指定位数的字符串,且返回此字符串的指针。
rfmtdec(dec_t *from, char *format, char *to) 将DECIMAL值转换成格式化的字符串。
1、DECIMAL函数——把DECIMAL值转换成数值型dectoint(dec_t *from, int *to);dectolong(dec_t *from, long *to);dectodbl(dec_t *from, double *to)2、DECIMAL函数——算术运算decadd(dec_t *op1, dec_t *op2, dec_t *result);decsub(dec_t *op1, dec_t *op2, dec_t *result);decmul(dec_t *op1, dec_t *op2, dec_t *result);decdiv(dec_t *op1, dec_t *op2, dec_t *result);返回代码:0操作成功-1200操作产生上溢-1201操作产生下溢-1202试图用零作除数3、DECIMAL函数——DECIMAL操作deccmp(dec_t *dec1, dec_t *dec2);-1dec1<dec20dec1=dec21dec1>dec2DECUNKNOW有一个是空值deccopy(dec_t *dec1, dec_t *dec2);decround(dec_t *dec1, int scale);dectrunc(dec_t *dec1, int scale);DATETIME和INTERVAL使用方式及实例1、概述DATETIME数据类型存放时间,时间由以下部分组成:YEAR,MONTH,DAY,HOUR,MINUTE,SECOND和秒的FRACTION(n)。