数据库B+树ppt
B+树
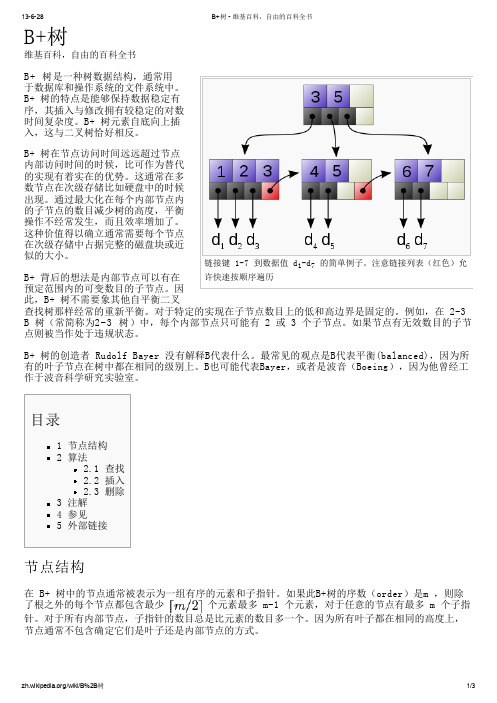
B+ 背后的想法是内部节点可以有在 许快速按顺序遍历
预定范围内的可变数目的子节点。因
此,B+ 树不需要象其他自平衡二叉
查找树那样经常的重新平衡。对于特定的实现在子节点数目上的低和高边界是固定的。例如,在 2-3
B 树(常简称为2-3 树)中,每个内部节点只可能有 2 或 3 个子节点。如果节点有无效数目的1/3
13-6-28
B+树 - 维基百科,自由的百科全书
每个内部节点的元素充当分开它的子树的分离值。例如,如果内部节点有三个子节点(或子树)则它 必须有两个分离值或元素 a1 和 a2。在最左子树中所有的值都小于 a1,在中间子树中所有的值都在
1. 它的兄弟节点,就是同一个父节点的子节点,可以把一个或多个它的子节点转移到当前节 点,而把它返回为合法状态。如果是这样,在更改父节点和两个兄弟节点的分离值之后处 理结束。
2. 它的兄弟节点由于处在低边界上而没有额外的子节点。在这种情况下把两个兄弟节点合并 到一个单一的节点中,而且我们递归到父节点上,因为它被删除了一个子节点。持续这个 处理直到当前节点是合法状态或者到达根节点,在其上根节点的子节点被合并而且合并后 的节点成为新的根节点。
注解
假定 L 是节点允许拥有子节点的最小数目,而 U 是最大数目。则每个节点总是有在 L 和 U 之间 (包含它们在内)个子节点,除了一个例外:根节点有从2到U(包含它们在内)个子节点。换句话 说,根节点豁免于低边界限制,而拥有它自己的低边界2。这允许树持有小数目的元素。根有一个子节 点没有意义,因为附着在这个子节点上的子树可以简单的附着在根节点上。允许根节点没有子节点也 是不需要的,因为没有元素的树典型的表示为没有根节点。
a1 和 a2 之间,而在最右子树中所有的值都大于 a2。
数据结构之B树和B树B树和B树的特性应用场景和性能优势

数据结构之B树和B树B树和B树的特性应用场景和性能优势B树和B+树:特性、应用场景和性能优势在计算机科学中,数据结构是指组织和存储数据的方式,而B树(B-Tree)和B+树(B+ Tree)是常用的数据结构之一。
本文将重点介绍B树和B+树的特性、应用场景和性能优势。
一、B树和B+树的特性1. B树特性B树是一种多叉树,它的每个节点可以拥有多个子节点。
B树的特点如下:- 根节点至少有两个子节点,除非它是叶子节点。
- 所有叶子节点在同一层级上,也就是说,B树是平衡的。
- 节点中的键值按照升序排列。
- 节点的子节点数可以超过2。
2. B+树特性B+树是B树的一种变体,相比B树,B+树的特点更适合数据库索引的实现。
B+树的特点如下:- 非叶子节点只存储键值信息,数据只存储在叶子节点。
- 所有叶子节点通过链表连接在一起,方便范围查询。
- 叶子节点之间通过指针相互连接,提高查找效率。
二、B树和B+树的应用场景1. B树应用场景- 文件系统:B树可用于文件系统的索引结构,方便文件的快速定位和存取。
- 数据库:B树可以作为数据库索引的存储结构,加快数据库查询的速度。
- 图书馆管理系统:B树可用于图书馆系统中书籍索引的实现,便于查找和管理。
2. B+树应用场景- 数据库:B+树是关系型数据库中常用的索引结构,能够提高查找效率和范围查询的性能。
- 文件系统:B+树可以作为文件系统的块索引结构,方便大规模文件的管理与存取。
- 排序算法:B+树可以用于外部排序的算法实现,提高排序的效率。
三、B树和B+树的性能优势1. B树的性能优势- 查询性能好:B树的节点可以存储多个键值,使得在查找过程中减少IO操作,提高查询效率。
- 范围查询性能优越:B树是平衡的,叶子节点之间通过指针相互连接,可方便实现范围查询。
2. B+树的性能优势- 更高的存储密度:B+树的非叶子节点只存储键值信息,不存储数据,因此可以存储更多的键值,提高存储密度。
《数据库》ppt课件

分布式存储、并行计算、数据挖掘等技术在大数据处理中的应用。
分布式数据库技术
分布式数据库概述
分布式数据库的定义、特点、架构和分类。
分布式数据库的关键技术
数据分区、数据复制、事务管理、负载均衡 等。
分布式数据库的应用场景
云计算、大数据处理、高可用性和可扩展性 应用等。
数据库技术的发展趋势与挑战
数据库技术的发展趋势
型、半结构化数据模型等。
概念数据模型(信息模型) 按用户的观点对数据和信息建模,如 实体-联系模型(E-R模型)。
物理数据模型
描述数据在存储介质上的组织结构, 它不但与具体的DBMS有关,而且还 与操作系统和硬件有关。
关系数据模型
关系数据结构
采用二维表来表示,简称表,由行和列组成。
关系操作
包括查询操作和插入、删除、修改等操作。查询操作又分为选择、 投影、连接操作。
将概念模型转换为数据库逻辑模型, 包括表结构、索引、视图、存储过程 等数据库对象的设计。
数据库管理工具与使用
常见数据库管理工
具
如SQL Server Management Studio、Oracle SQL Developer、 MySQL Workbench等,提供数 据库创建、管理、维护等功能。
04
数据库设计与管理
数据库设计概述
数据库设计的定义
01
数据库设计是指根据用户需求,运用数据库技术,设计
数据库结构、建立数据库及其应用系统的过程。
数据库设计的重要性
02
良好的数据库设计可以提高数据存储的效率,保证数据
的完整性和安全性,降低系统开发和维护的成本。
数据库设计的原则
03
包括一致性、完整性、安全性、可维护性、可扩展性等
文件的索引结构

哈希索引能够提供快速的查找速度,因为哈希表的大小是固定的,且每个元素 的查找时间复杂度为O(1)。此外,哈希索引适用于大量数据的快速查找和插入 操作。
缺点
哈希索引的缺点是它不适用于范围查询和排序操作,因为哈希索引只能提供精 确匹配的查询结果。此外,如果哈希函数设计不当或数据分布不均,可能会导 致哈希冲突过多,影响查询效率。
文件的索引结构
目录
• 索引结构概述 • B树索引结构 • B+树索引结构 • 哈希索引结构 • 全文索引结构
01
索引结构概述
定义与作用
定义
索引结构是指用于快速检索文件 系统中文件的组织方式。
作用
提高文件检索速度,方便用户快 速找到所需文件。
索引结构的分类
线性索引
将文件信息按照一定顺 序排列,通过顺序查找
平衡多路搜索树
阶数与度数
B树是一种平衡的多路搜索树,能够 保持树的平衡,使得搜索效率相对稳 定。
B树的阶数决定了每个节点的最大关 键字数量,而度数决定了树的高度, 两者相互关联。
节点分裂与合并
当插入或删除节点导致节点内关键字 数量小于最小值时,需要进行节点分 裂或合并操作,以保持树的平衡。
B树的插入操作
检索速度快,但插入和删除操作较为复杂 ,需要维护树形结构的平衡。
B树索引
哈希索引
平衡多路搜索树,能够高效处理大量数据 ,但实现较为复杂,需要维护树形结构的 平衡。
检索速度快,但哈希函数的选择和数据的 分布情况对索引效果影响较大,适用于关 键字唯一或数据量较小的情况。
02
B树索引结构
B树的结构特点
节点合并
如果删除后节点关键字数 量小于最小值,需要与兄 弟节点合并,将部分关键 字下移至兄弟节点。
B树的结构详细讲解

B树的结构详细讲解B树(B-tree)是一种非常常用的数据结构,被广泛应用于文件系统和数据库中用于存储和管理大量数据的索引结构。
B树在磁盘和其他外部存储设备中高效地存储和访问数据,具有快速的插入和删除操作,并且可以高效地支持区间查询。
本文将详细介绍B树的结构和特点。
一、B树的定义B树是一种平衡的m叉树(m-way search tree),特点是每个节点最多含有m个孩子和m-1个关键字。
B树的定义还规定:1.根节点至少有两个孩子,除非它是叶节点;2.所有叶节点都在同一层次上,也就是说它们具有相同的深度。
二、B树的特点B树有以下几个特点:1.B树是一种多路树,每个节点可以拥有多个孩子,普通的二叉树只有两个孩子;2.所有节点的孩子数量是相同的,对于非叶节点,关键字数量比孩子数少一个;3.B树的高度非常低,这是因为每个节点存储多个关键字,减少了树的高度,加快了和插入操作的速度;4. B树的、插入和删除操作的时间复杂度都是O(log n),其中n是数据的规模。
三、B树的结构示意图下面是一个B树的结构示意图:```CG/,\ABDF```在这个示意图中,根节点有三个孩子,图中的关键字为C和G。
A和B是C的两个孩子,D和F是G的两个孩子。
四、B树的操作B树的操作与二叉树的操作类似,只是多了一层循环。
操作从根节点开始,将目标关键字与节点中的关键字进行比较:1.如果目标关键字小于节点中的最小关键字,则进入左子树进行下一轮;2.如果目标关键字大于等于节点中的最小关键字,并且小于等于节点中的最大关键字,则说明已经找到目标关键字;3.如果目标关键字大于节点中的最大关键字,则进入右子树进行下一轮;4.如果节点中没有更多的孩子,则说明目标关键字不存在于B树中。
五、B树的插入操作B树的插入操作有以下几个步骤:1.从根节点开始,按照操作找到关键字应该插入的位置,即找到关键字所在的叶节点。
2.在叶节点中插入关键字。
如果叶节点未满,则直接插入;如果叶节点已满,则需要进行分裂操作。
《数据库》ppt课件

• 背景: 20世纪50年代后期到60年代中期,计算机硬件方面
出现直接存取设备磁盘,软件方面出现了操作系统
• 主要特点:数据管理方面,数据被组织到文件内存储在
磁带、磁盘上,可以反复使用和保存。程序与数据的关系如
下: 应用程序1
数据组1
应用程序2
文件 管理系统
数据组2
应用程序n
数据组n
4
5.1 数据库系统概论 — 数据库阶段
S_no S_name S_gender Department Age Place
95001 李勇 男
计算机
20 江苏
95004 张立 男
计算机
19 北京
95700 杨晓冬 男
计算机
21 山西
UPDATE students SET Age=20 WHERE S_no =‘95004’
INSERT INTO students VALUES(95060, ‘王英’,‘女’ ,‘物 理’, 19,‘浙江’)
SQL功能
SQL命令
数据定义 CREATE,DROP,ALTER
数据更新 INSERT,UPDATE,DELETE
数据查询 SELECT
数据控制 GRANE,REVOKE
33
5.2 关系模型 — 数据操作示例
SELECT * FROM students WHERE Department=‘计算机’
– 或者等于S中某个元组的主码值
• 用户定义的完整性: 针对某一具体关系数据库的约束条件, 反映某一具体应用所涉及的数据必须满足的语义要求
返回
35
5.3 关系规范化设计理论 — 概念
数据关系规范化理论:定义了五种规范化模式 (Normal Form,NF,简称范式)1971年E.F.Codd
数据结构 第9章 查找3-B树
插入关键字 = 60, 90, 30
2、B-树的删除
在深度为(h+l)的m阶B-树中删除一个键值k,首先要查 到键值k所在的结点及在结点中的位置。若k在非终端 节点中,则把该结点的右边(或左边)指针所指子树中 的最小(或最大)键值与k对调,使k移到终端节点。 在终端节点中删除一个键值后,使得该结点的值个数n 减1,此时应分以下三种情况进行处理: – (1)若删除后结点中键值数目n≥ ┌m/2┐-1,在该结点 中删去键值k连同右边的指针。 – (2)若删除后结点中键值数目n< ┌m/2┐ -1,且左(或 右)兄弟结点的关键字数目> ┌m/2┐-1,则把左(或 右)兄弟结点中最大(或最小)键值移到父结点中,再 把父结点大于(或小于)上移键值的键值下移到被删 关键字所在结点中。
(3)若删除后结点中键值数目n< ┌m/2┐ -1,及 其左、右兄弟结点的键值数目都等于┌m/2┐ -1,则就必须进行结点的“合并”,即把应删 的键值删去后,将该结点中的剩余键值和指针 连同父结点中指向该结点指针的左边(或右边) 一个键值ki一起合并到左兄弟(或右兄弟)结点 中,将ki从父结点中删去。如果因此使父结点 中关键字数目< ┌m/2┐-1,则对此父结点做同 样处理,以致于可能直到对根结点做这样的处 理而使整个树减少一层。
2.查找性能的分析
在B-树中进行查找时,其查找时间 主要花费在搜索结点(访问外存)上, 即主要取决于B-树的深度 树的深度。 树的深度
问:含 N 个关键字的 m 阶 B-树可 能达到的最大深度 H 为多少?
反过来问: 深度为H的B-树中, 至少含有多少个结点? 先推导每一层所含最少结点数: 第1层 第2层 第3层 第4层 … … 第 H+1 层 1个 2个 2×m/2 个 × 2×(m/2)2 个 × 2×(m/2) H-1 个 ×
数据结构 B树
动态查找结构
动态的m路查找树
现在我们所讨论的m路查找树多为可以动态调 整的多路查找树,它的一般定义为: 一棵m路查找树, 它或者是一棵空树, 或者是满 足如下性质的树:
根最多有 m 棵子树, 并具有如下的结构:
n, A0, ( K1, A1 ), ( K2, A2 ), ……, ( Kn, An ) 其中,Ai 是指向子树的指针,0 i n < m; Ki 是关键码,1 i n < m。 Ki < Ki+1, 1 i < n。
B-树的插入
B-树是从空树起,逐个插入关键码而生成的。
在B-树,除根节点外每个非失败结点的关键码
个数都在
[ m/2 -1, m-1] 之间。
插入在某个最底层非终端节点开始。如果在关 键码插入后结点中的关键码个数超出了上界 m-1,则结点需要“分裂”,否则可以直接插入。
实现结点“分裂”的原则是:
设结点 A 已有 m-1 个关键码,当再插入一个 关键码,结点从中间位置K m/2分裂,左半部 留在A中,右半部分离成一新节点Q, K m/2 升至父节点中,并把其右指针指向新节点Q
(等比级数前 h 项求和)
h mi
1
m h1 1
i 0
m 1
每个结点中最多有 m-1 个关键码,在一棵高 度为 h 的 m 路查找树中关键码的最大个数为 mh+1-1。
对于高度 h=2 的二叉树,关键码最大个数为 7;
对于高度 h=3 的3路查找树,关键码最大个 数为 34-1 = 80。
h-1 log m / 2 ( (N +1) / 2 ) 示例:若B-树的阶数 m = 199,关键码总数 N = 1999999,则B-树的高度 h 不超过
B树的原理及应用场景
B树的原理及应用场景B树是一种自平衡的树数据结构,通常用于数据库和文件系统中,能够高效地支持插入、删除和查找操作。
B树的原理和应用场景是数据库系统和文件系统设计中的重要内容,下面将详细介绍B树的原理及其应用场景。
一、B树的原理1. 结构特点B树是一种多路搜索树,每个节点可以包含多个子节点。
B树的特点包括:- 根节点至少有两个子节点。
- 每个非叶子节点有m个子节点,其中[m/2]到m个子节点非空。
- 每个节点中的关键字按递增顺序排列。
- 位于节点n的关键字同时也是节点n的子树的分界线。
2. 插入操作在B树中插入一个新的关键字时,首先找到合适的叶子节点,如果该节点未满,则直接插入;如果该节点已满,则进行节点分裂操作,将中间的关键字上移,并将左右子树分别作为新的子树。
3. 删除操作在B树中删除一个关键字时,首先找到包含该关键字的叶子节点,如果该节点关键字个数大于等于[m/2],则直接删除;如果小于[m/2],则进行节点合并操作,将该关键字从父节点中删除,并将左右子树合并为一个新的子树。
二、应用场景1. 数据库系统B树广泛应用于数据库系统中的索引结构,如MySQL、Oracle等数据库管理系统。
在数据库中,B树可以加快数据的查找速度,提高数据库的性能。
通过B树索引,可以快速定位到需要查询的数据,减少磁盘IO 操作,提高查询效率。
2. 文件系统B树也常用于文件系统中的索引结构,如NTFS、EXT4等文件系统。
在文件系统中,B树可以加快文件的查找速度,提高文件系统的性能。
通过B树索引,可以快速定位到需要访问的文件或目录,减少磁盘IO操作,提高文件读写效率。
3. 搜索引擎搜索引擎中的倒排索引通常采用B树结构,用于存储关键字与文档之间的映射关系。
通过B树索引,搜索引擎可以快速定位到包含查询关键字的文档,提高搜索结果的准确性和响应速度。
4. 文件压缩在文件压缩算法中,B树也有一定的应用场景。
通过B树索引,可以快速定位到需要压缩或解压缩的数据块,提高文件的压缩效率和解压速度。
mysql b树和b+树 原理
mysql b树和b+树 原理
MySQL中的B树和B+树是两种常见的索引结构,用于提高数据库系统的查询效率。
B树和B+树原理如下:
B树是一种平衡多路搜索树,用于存储和查找数据。
它的原理是将索引和数据
都存储在树的节点中。
具体来说,在B树中,每个节点都有一个键值和关联的数据,同时它可以有多个子节点。
每个节点中的键值按照顺序排列,这使得在查找时可以通过二分法快速定位到目标节点。
B树的特点是所有叶子节点位于同一层,这样可以加快搜索效率。
B+树也是一种平衡多路搜索树,与B树相似,但在存储方式和叶子节点上有
所不同。
在B+树中,只有叶子节点存储了实际的数据,而非叶子节点只存储键值
和子节点的指针。
叶子节点之间使用链表连接,这样可以更快地遍历所有数据。
B+树的另一个特点是所有叶子节点按照顺序链接,形成一个排序的结构。
这种存
储方式使得范围查询更加高效,也有利于支持数据库的顺序扫描和范围查询操作。
总的来说,B树和B+树都是通过平衡多路搜索树的结构来存储和查找数据的
索引。
它们的原理相似,但在存储方式和叶子节点上有所不同。
B树适用于随机查找和精确查询,而B+树适用于范围查询和顺序扫描。
了解B树和B+树的原理对
于数据库系统的性能优化和索引设计非常重要。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
3阶B+树插入简单示例
roo t
插入100 59 59 100 97
100 15 44 59
sqt
72 91 100 72 100 72 97
10 15
21 37 44
51 59 63 72
97 97 100 85 85 91 91 85 91
B+树索引结构
For man is man and master of his fate.
B+树功能
快速的Record查找
A
快速的Record遍历
B C
不通过overflow page的形式维护排序树结构
2
B+树索引管理机 A ction speak louder than words. 制
You cannot improve your past, but you can improve your future. Once time is wasted, life is wasted.
B+树索引管理机制
For man is man and master of his fate.
B+树索引的查找管理
对B+树可以进行两种查找运算: 1.从最小关键字起; 2.从根结点开始,进行随机查找。 在查找时,若非终端结点上的关键值等于给定值, 并不终止,而是继续向下直到叶子结点。因此,在 B+树中,不管查找成功与否,每次查找都是走了一 条从根到叶子结点的路径。其余同B-树的查找类似。
随机访问
每次读取一个数据块 (通过等待事件“db file sequential read” 体现出来)。
顺序访问
每次读取多个数据 块(通过等待事件 “db file scattered read” 体现出来)。
B+树索引结构
For man is man and master of his fate.
Interior Node
K1 K2 K3
B+树索引结构
For man is man and master of his fate.
roo t
引导查找 只存储搜索码
B+树简单示例
50 90 20 50 60 80 90
内部结点
sqt
12 16 20
26 30 50
55 60 62 70 80
82 86 90
树上的操作(插入,删除)能 保持数的平衡 如果能实现删除算法,则除根节 点外,每一个节点都将保证最小 50%的占有率。但是,删除的实 现通常是简单的定位数据项,并 移走它,而不为保证50%的占有 率而调整它,这主要是因为文件 在典型情况下是增长而不是缩小。
搜索记录需要从根开始遍历到合 适的叶子。从根到叶子的路径长 度称为树的高度,因为是平衡树, 所以从根到任意叶子的长度都是 相同的。
B+树的索引
CONTENTS
Never put off what you can do today until tomorrow
B+树索引结构
对B+树索引的整体结构进行讲 解
B+树索引管理机 制 B+树索引实现方 式
对B+树查询和更新操作进行讲 解
对B+树的文件组织进行描述
B+树的比较分析
对B+树进行比较分析
B+树索引结构
For man is man and master of his fate.
B+树索引的访问
当oracle需要获得一个索引块时,首先从根节点开始,根据所要查找的 键值,从而知道其所在的下一层的分支节点,然后访问下一层的分支节点, 再次同样根据键值访问再下一层的分支节点,如此这般,最终访问到最底 层的叶子节点。可以看出,其获得物理I/O块时,是一个接着一个,按照 顺序,串行进行的。在获得最终物理块的过程中,我们不能同时读取多个 块,因为我们在没有获得当前块的时候是不知道接下来应该访问哪个块的。 因此,在索引上访问数据块时,会对应到db file sequential read等待事 件,其根源在于我们是按照顺序从一个索引块跳到另一个索引块,从而找 到最终的索引块的。
B+树索引管理机制
For man is man and master of his fate.
B+树索引的删除管理
当删除表里的一条记录时,其对应于索引里的索引条目并 不会被物理的删除,只是做了一个删除标记
当一个新的索引条目进入一个索引叶子节点的时候, Oracle会检查该叶子节点里是否存在被标记为删除的索引 条目,如果存在,则会将所有具有删除标记的索引条目从 该叶子节点里物理的删除。
B+树索引结构
B+树的特性
有n棵子树的结点中含有n 个关键码
所有的叶子结点中包含了全部 关键码的信息,及指向含有这些 关键码记录的指针,且叶子结点 本身依关键码的大小自小而大的 顺序链接。
所有的非终端结点可以看成是 索引部分,结点中仅含有其子树 根结点中最大(或最小)关键码。
B+树索引结构
B+树的特性
1
B+树索引结构
对B+树索引的整体结构进行讲解
You cannot improve your past, but you can improve your future. Once time is wasted, life is wasted.
B+树索引结构
For man is man and master of his fate.
B+树索引管理机制
For man is man and master of his fate.
B+树索引的插入管理
第一种情况
一种是在一个已经充满了数据的表上创建索引时,索引是怎 么管理的。 当在一个充满了数据的表上创建索引(create index命令) 时, Oracle 会先扫描表里的数据并对其进行排序,然后生成叶 子节点。生成所有的叶子节点以后,根据叶子节点的数量生成若 干层级的分支节点,最后生成根节点。这个过程是很清晰的。 另一种则是当一行接着一行向表里插入或更新或删除数据 时,索引是怎么管理的。 当一开始在一个空的表上创建索引的时候,该索引没有根 节点,只有一个叶子节点。随着数据不断被插入表里,该叶 子节点中的索引条目也不断增加,当该叶子节点充满了索引 条目而不能再放下新的索引条目时,该索引就必须扩张,必 须再获取一个可用的叶子节点。这时,索引就包含了两个叶 子节点,但是两个叶子节点不可能单独存在的,这时它们两 必须有一个上级的分支节点,其实这也就是根节点了。
B+树索引管理机制
For man is man and master of his fate.
B+树索引删除的简单示例
roo t
删除关键字91
59 97 15 44 59
sqt
72 97
10 15
21 37 44
51 59
63 72
85 85 91 97 97
B+树索引管理机制
For man is man and master of his fate.
B+树索引删除的简单示例
roo t
删除关键字91
91 59 97
15 44 59
sqt
72 91 97
10 15
21 37 44
51 59
63 72
85 85 91 91 97
B+树索引管理机制
For man is man and master of his fate.
B+树索引删除的简单示例
roo t
B+树索引的访问
第一种方式则是访问索引里的数据块,而第二种方式的I/O操作属于全 表扫描。这里顺带有一个问题,为何随机访问会对应到db file sequential read等待事件,而顺序访问则会对应到db file scattered read等待事件呢?这似乎反过来了,随机访问才应该是分散(scattered) 的,而顺序访问才应该是顺序(sequential)的。其实,等待事件主要根 据实际获取物理I/O块的方式来命名的,而不是根据其在I/O子系统的逻辑 方式来命名的。下面对于如何获取索引数据块的方式中会对此进行说明。
Leaf Node
P1 Pn K1 P2 K2 …… Kn-1
B+树索引结构
For man is man and master of his fate.
B+树的结点结构
B+树的非叶结点形成叶结点上的一个多 级(稀疏)索引。非叶结点的结构和叶结点和 同,只不过非叶结点中的所有指针都指向树 中的结点。一个非叶结点至少包含 [n/2] 个 指针,最多n个。结点的指针数称为该 15 44 59
终端结点 存储记录
B+树索引结构
For man is man and master of his fate.
B+树索引的访问
我们已经知道了B树索引的体系结构,那么当 Oracle 需 要 访 问 索 引 里 的 某 个 索 引 条 目 时 , Oracle 是如何找到该索引条目所在的数据块的 呢? 当oracle进程需要访问数据文件里的数据块时, oracle会有两种类型的I/O操作方式:
当一个新的索引条目进入索引时,oracle会将当前所有被 清空的叶子节点(该叶子节点中所有的索引条目都被设置 为删除标记)收回,从而再次成为可用索引块。
B+树索引管理机制
For man is man and master of his fate.
尽管被删除的索引条目所占用的空间大部分情况下都能够被重用,但仍然存在一些情况 可能导致索引空间被浪费,并造成索引数据块很多但是索引条目很少的后果,这时该索 引可以认为出现碎片。而导致索引出现碎片的情况主要包括: