ORACLE 执行计划介绍与测试
oracle执行计划解读

oracle执行计划解读执行计划是Oracle数据库查询优化器生成的一个重要工具,用于指导数据库在执行查询语句时的执行路线和资源分配。
通过解读执行计划,我们可以深入了解查询语句的执行情况,进而优化查询性能。
以下是对Oracle执行计划的详细解读:1. 访问方法(Access Method):执行计划的第一步是选择合适的访问方法来获取所需的数据。
这取决于表的大小、索引的可用性和查询条件等。
常见的访问方法包括全表扫描(Full Table Scan)、索引扫描(Index Scan)和索引唯一扫描(Index Unique Scan)等。
2. 连接方式(Join Method):如果查询语句中包含连接操作(如JOIN),执行计划会根据连接条件选择合适的连接方式。
常见的连接方式有Nested Loops(嵌套循环连接)、Merge Sort(合并排序连接)和Hash Join(哈希连接)等。
优化器会根据表的大小和索引的可用性等因素选择最佳的连接方式。
3. 过滤条件(Filter):执行计划中的过滤条件显示了查询语句中使用的WHERE子句以及相关的索引和扫描操作。
过滤条件可以帮助我们判断查询是否使用了正确的索引和是否存在过多的全表扫描。
4. 排序方式(Sort):如果查询语句包含ORDER BY子句或GROUP BY子句,执行计划中会显示排序操作的方式。
排序方式分为内部排序(In-Memory Sort)和外部排序(Disk Sort)。
内部排序会将数据加载到内存中进行排序,适用于较小的数据集。
外部排序会将数据写入磁盘进行排序,适用于较大的数据集。
5. 访问路径(Access Path):执行计划中的访问路径显示了查询语句中使用的索引、分区和子查询等相关操作。
通过分析访问路径,我们可以判断查询语句是否使用了合适的索引和是否存在不必要的数据访问操作。
6. 成本估算(Cost Estimate):执行计划中的成本估算显示了优化器对执行每个操作所需的资源消耗的估计值。
oracle执行计划解释

oracle执行计划解释一.相关概念1·rowid,伪列:就是系统自己给加上的,每个表都有一个伪列,并不是物理存在。
它不能被修改,删除,和添加,rowid在该行的生命周期是唯一的,如果向数据库插入一列,只会引起行的变化,但是rowid并不会变。
2·recursive sql概念:当用户执行一些SQL语句时,会自动执行一些额外的语句,我们把这些额外的SQL语句称为“recursive calls” 或者是“recursive sql statement”,当在执行一个DDL语句时,Oracle总会隐含的发出一些Recursiv sql语句,用于修改数据字典,如果数据字典没有在共享内存中,则就执行“resursive calls”,它会把数据字典从物理读取到共享内存。
当然DML和select语句都可能引起recursive SQL。
3·row source 行源:在查询中,由上一操作返回的符合条件的数据集,它可能是整个表,也可能是部分,当然也可以对2个表进行连接操作(join)最后得到的数据集4·predicate:一个查询中的where限制条件5·driving table 驱动表:该表又成为外层表,这个感念用于内嵌和HASH连接中,如果返回数据较大,会有负面影响,返回行数据较小的适合做驱动表6·probed table 被探查表:该表又称为内层表,我们在外层表中取得一条数据,在该表中寻找符合连接的条件的行。
7·组合索引(concatenated index)由多个列组成的索引,在组合索引中有一个重要的概念,就是引导索引,create index idx_tab on tab(col1,col2,col3),indx_tab则称为组合索引,col1则称为引导列在查询条件where后,必须使用引导索引,才会使用该组合索引8.可选择性(selectivity)比较一下列中唯一键的数量和表中的行数,就可以判断该列的可选择性。
oracle基础知识(十三)----执行计划
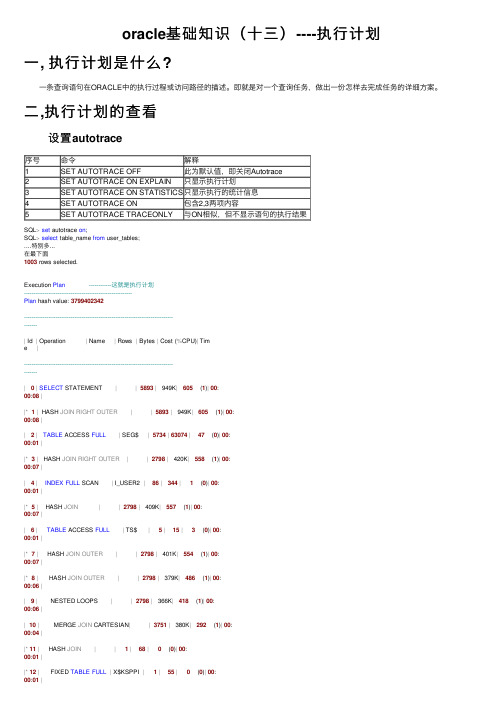
oracle基础知识(⼗三)----执⾏计划⼀, 执⾏计划是什么? ⼀条查询语句在ORACLE中的执⾏过程或访问路径的描述。
即就是对⼀个查询任务,做出⼀份怎样去完成任务的详细⽅案。
⼆,执⾏计划的查看 设置autotrace序号命令解释1SET AUTOTRACE OFF此为默认值,即关闭Autotrace2SET AUTOTRACE ON EXPLAIN只显⽰执⾏计划3SET AUTOTRACE ON STATISTICS只显⽰执⾏的统计信息4SET AUTOTRACE ON包含2,3两项内容5SET AUTOTRACE TRACEONLY与ON相似,但不显⽰语句的执⾏结果SQL>set autotrace on;SQL>select table_name from user_tables;....特别多...在最下⾯1003 rows selected.Execution Plan------------这就是执⾏计划----------------------------------------------------------Plan hash value: 3799402342---------------------------------------------------------------------------------------| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |---------------------------------------------------------------------------------------|0|SELECT STATEMENT ||5893| 949K|605 (1)|00:00:08||*1| HASH JOIN RIGHT OUTER||5893| 949K|605 (1)|00:00:08||2|TABLE ACCESS FULL| SEG$ |5734|63074|47 (0)|00:00:01||*3| HASH JOIN RIGHT OUTER||2798| 420K|558 (1)|00:00:07||4|INDEX FULL SCAN | I_USER2 |86|344|1 (0)|00:00:01||*5| HASH JOIN||2798| 409K|557 (1)|00:00:07||6|TABLE ACCESS FULL| TS$ |5|15|3 (0)|00:00:01||*7| HASH JOIN OUTER||2798| 401K|554 (1)|00:00:07||*8| HASH JOIN OUTER||2798| 379K|486 (1)|00:00:06||9| NESTED LOOPS ||2798| 366K|418 (1)|00:00:06||10| MERGE JOIN CARTESIAN||3751| 380K|292 (1)|00:00:04||*11| HASH JOIN||1|68|0 (0)|00:00:01||*12| FIXED TABLE FULL| X$KSPPI |1|55|0 (0)|00:00:01||13| FIXED TABLE FULL| X$KSPPCV |100|1300|0 (0)|00:00:01||14| BUFFER SORT ||3751| 131K|292 (1)|00:00:04||*15|TABLE ACCESS FULL| OBJ$ |3751| 131K|292 (1)|00:00:04||*16|TABLE ACCESS CLUSTER| TAB$ |1|30|1 (0)|00:00:01||*17|INDEX UNIQUE SCAN | I_OBJ# |1||0 (0)|00:00:01||18|INDEX FAST FULL SCAN | I_OBJ1 |86281| 421K|68 (0)|00:00:01||19|INDEX FAST FULL SCAN | I_OBJ1 |86281| 674K|68 (0)|00:00:01|---------------------------------------------------------------------------------------Predicate Information (identified by operation id):---------------------------------------------------1- access("T"."FILE#"="S"."FILE#"(+) AND "T"."BLOCK#"="S"."BLOCK#"(+) AND"T"."TS#"="S"."TS#"(+))3- access("CX"."OWNER#"="CU"."USER#"(+))5- access("T"."TS#"="TS"."TS#")7- access("T"."DATAOBJ#"="CX"."OBJ#"(+))8- access("T"."BOBJ#"="CO"."OBJ#"(+))11- access("KSPPI"."INDX"="KSPPCV"."INDX")12- filter("KSPPI"."KSPPINM"='_dml_monitoring_enabled')15- filter("O"."OWNER#"=USERENV('SCHEMAID') AND BITAND("O"."FLAGS",128)=0) 16- filter(BITAND("T"."PROPERTY",1)=0)17- access("O"."OBJ#"="T"."OBJ#")Statistics-----这⾥是统计信息----------------------------------------------------------8 recursive calls0 db block gets8809 consistent gets0 physical reads0 redo size31347 bytes sent via SQL*Net to client1250 bytes received via SQL*Net from client68 SQL*Net roundtrips to/from client1 sorts (memory)0 sorts (disk)1003 rows processed 使⽤sql查看SQL>set autotrace off;SQL> explain plan for select*from WRI$_DBU_FEATURE_METADATA;Explained.SQL>SELECT plan_table_output FROM TABLE(DBMS_XPLAN.DISPLAY('PLAN_TABLE')); PLAN_TABLE_OUTPUT--------------------------------------------------------------------------------Plan hash value: 563503327-----------------------------------------------------------------------------------------------| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |-----------------------------------------------------------------------------------------------PLAN_TABLE_OUTPUT--------------------------------------------------------------------------------|0|SELECT STATEMENT ||176|91344|5(0)|00:00:01||1|TABLE ACCESS FULL| WRI$_DBU_FEATURE_METADATA |176|91344|5(0)|00:00:01|-----------------------------------------------------------------------------------------------8 rows selected.SQL>select*from table(dbms_xplan.display);PLAN_TABLE_OUTPUT--------------------------------------------------------------------------------Plan hash value: 563503327-----------------------------------------------------------------------------------------------| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |-----------------------------------------------------------------------------------------------PLAN_TABLE_OUTPUT--------------------------------------------------------------------------------|0|SELECT STATEMENT ||176|91344|5(0)|00:00:01||1|TABLE ACCESS FULL| WRI$_DBU_FEATURE_METADATA |176|91344|5(0)|00:00:01|-----------------------------------------------------------------------------------------------8 rows selected.SQL> 客户端的话界⾯有解释选项⾃⼰找找三,执⾏计划解释 01.执⾏顺序的原则 执⾏顺序的原则是:由上⾄下,从右向左 由上⾄下:在执⾏计划中⼀般含有多个节点,相同级别(或并列)的节点,靠上的优先执⾏,靠下的后执⾏ 从右向左:在某个节点下还存在多个⼦节点,先从最靠右的⼦节点开始执⾏。
Oracle优化之执行计划解析

Oracle优化之执行计划解析执行计划是Oracle数据库中一个非常重要的概念。
它是在执行SQL语句之前由Oracle优化器生成的一种指导性的路线图,用于指导数据库引擎执行查询和更新操作。
执行计划可以帮助我们理解SQL语句的执行过程,以及找出可能存在的性能瓶颈和优化机会。
执行计划是一个树状结构,其中每个节点表示一个SQL操作,如表扫描、索引扫描、排序、连接等。
每个节点都包含了一些关键信息,如访问方法、访问对象、访问行数等。
一般而言,执行计划中的节点都按照一定的顺序执行。
例如,首先进行表扫描,然后进行索引扫描,最后进行连接操作。
执行计划中的每个节点都有一个估计的成本,该成本与执行该操作所需的时间和资源有关。
优化器会根据这些成本来选择最佳的执行计划。
要解析执行计划,我们需要关注以下几个方面:1.访问方法:执行计划中的每个节点都有一个访问方法,用于告诉数据库引擎如何获取数据。
常见的访问方法包括表扫描、索引扫描、索引范围扫描、连接等。
通过分析访问方法,我们可以了解到数据库引擎是如何获取数据的,从而找出潜在的性能问题。
2.访问对象:执行计划中的每个节点都会访问一个或多个数据库对象,如表、索引等。
通过分析访问对象,我们可以了解到数据库引擎是如何获取和处理数据的,从而找出可能存在的性能瓶颈。
3.访问行数:执行计划中的每个节点都会访问一定数量的数据行。
通过分析访问行数,我们可以了解到数据库引擎是如何处理数据的,从而找出性能优化的机会。
4.执行顺序:执行计划中的节点是按照一定的顺序执行的。
通过分析执行顺序,我们可以了解到查询的执行过程,从而找出可能存在的性能问题。
在解析执行计划时,我们可以使用多种工具和技术。
常用的工具包括SQL*Plus的AUTOTRACE功能、Oracle SQL Developer的执行计划窗口等。
这些工具可以将执行计划以图形或文本的形式展示出来,方便我们进行分析和理解。
此外,我们还可以使用一些Oracle提供的视图和函数来获取和分析执行计划的信息。
ORACLE的执行计划

ORACLE的执行计划
一、Oracle执行计划
1.概念
Oracle执行计划是指Oracle数据库根据用户提交的SQL语句以及其执行需要的资源,使用一系列步骤来完成数据库操作的一个流程。
Oracle 根据执行计划来选择最优的执行步骤,从而把用户提交的任务在经济高效的方式完成。
Oracle会在执行时分析语句,收集有关语句的信息,构建一个执行计划,并选择一些优化操作去完成SQL的执行,从而达到最优的性能。
2.作用
Oracle的执行计划不仅可以帮助我们识别SQL语句的生成过程,也可以识别其它的执行步骤,如执行的索引使用情况、连接的表数量、执行步骤的顺序等。
通过分析执行计划,我们可以找到瓶颈,分析出SQL语句的性能瓶颈,并根据瓶颈可以有效的改进SQL的性能,从而提高系统的效率。
3.类型
Oracle的执行计划可以分为Cost Based和Rule Base两种。
Cost Based执行计划是Oracle的主要执行计划,它会对查询中使用的资源(索引、表空间、大小等)进行评估,并根据评估结果来选择执行步骤,从而得到一个当前SQL最优的执行计划。
而Rule Base执行计划会根据Oracle的规则去生成一个执行计划,不会根据优化的考虑。
4.工具
在查看Oracle执行计划之前,我们首先要拿到Oracle的查询优化器产生的执行计划,有两种办法可以查看Oracle的执行计划:(1)SQL*Plus的Explain Plan命令:我们可以使用Explain Plan 命令。
oracle的执行计划

oracle的执行计划Oracle是一种关系型数据库管理系统,执行计划是指在Oracle数据库中执行SQL语句的方式和过程。
它是由Oracle优化器生成的一种“蓝图”,它描述了通过何种方式来执行SQL以获得所需结果集。
这个“蓝图”包含有关要使用哪种访问方法,如何组合表和索引以及如何过滤结果集的信息,执行计划的准确性和有效性是影响SQL执行效率的主要因素之一。
一、Oracle执行计划的基本原理Oracle在执行SQL的时候,会自动根据查询条件和表结构等因素生成一份执行计划。
在执行计划的生成过程中,Oracle会根据不同的查询方法和算法,通过消耗最少的时间来获取查询结果。
因此,对于复杂的SQL查询,可能会有多个执行计划可供选择,而不同的执行计划会对查询效率产生显著的影响。
在考虑生成执行计划的方法和算法时,Oracle优化器一般会考虑以下几个因素:1. 索引的选择:如果有可用的索引可以用于查询,优化器就会选择使用索引。
2. 连接方式:Oracle查询可以使用多种连接方式,如NL join, Hash join和Sort merge join等,优化器会尝试选择最适合当前查询的连接方式。
3. 筛选条件的处理:Oracle会尝试使用所有可用的筛选条件来限制查询结果,以便从数据表中检索出尽可能少的行。
4. 查询方式:Oracle可以使用多种查询方式来获得所需结果,如扫描整个表或仅使用部分表,或使用合并或排序等操作来产生所需结果。
在执行计划的生成过程中,优化器通过对表统计信息的分析和对SQL语句分析,可以获得优化方案的估计成本,并选择代价最小的执行计划来执行查询。
二、Oracle执行计划的格式在Oracle中,可以使用EXPLAIN PLAN语句来查看SQL执行计划。
执行计划的输出结果通常包括以下几个部分:1. ID: 执行计划中每个操作的唯一标识符,可以作为连接其他操作的依据。
2. Operation: 执行计划中每个操作的名称。
oracle执行计划详解
oracle执⾏计划详解⼀:什么是Oracle执⾏计划?执⾏计划是⼀条查询语句在Oracle中的执⾏过程或访问路径的描述⼆:怎样查看Oracle执⾏计划?因为我⼀直⽤的PLSQL远程连接的公司数据库,所以这⾥以PLSQL为例:①:配置执⾏计划需要显⽰的项:⼯具 —> ⾸选项 —> 窗⼝类型 —> 计划窗⼝ —> 根据需要配置要显⽰在执⾏计划中的列执⾏计划的常⽤列字段解释:基数(Rows):Oracle估计的当前操作的返回结果集⾏数字节(Bytes):执⾏该步骤后返回的字节数耗费(COST)、CPU耗费:Oracle估计的该步骤的执⾏成本,⽤于说明SQL执⾏的代价,理论上越⼩越好(该值可能与实际有出⼊)时间(Time):Oracle估计的当前操作所需的时间②:打开执⾏计划:在SQL窗⼝执⾏完⼀条select语句后按 F5 即可查看刚刚执⾏的这条查询语句的执⾏计划注:在PLSQL中使⽤SQL命令查看执⾏计划的话,某些SQL*PLUS命令PLSQL⽆法⽀持,⽐如SET AUTOTRACE ON三:看懂Oracle执⾏计划①:执⾏顺序:根据Operation缩进来判断,缩进最多的最先执⾏;(缩进相同时,最上⾯的最先执⾏)例:上图中 INDEX RANGE SCAN 和 INDEX UNIQUE SCAN 两个动作缩进最多,最上⾯的 INDEX RANGE SCAN 先执⾏;同⼀级如果某个动作没有⼦ID就最先执⾏同⼀级的动作执⾏时遵循最上最右先执⾏的原则例:上图中 TABLE ACCESS BY GLOBAL INDEX ROWID 和 TABLE ACCESS BY INDEX ROWID 两个动作缩进都在同⼀级,则位于上⾯的 TABLE ACCESS BY GLOBAL INDEX ROWID 这个动作先执⾏;这个动作⼜包含⼀个⼦动作 INDEX RANGE SCAN,则位于右边的⼦动作 INDEX RANGE SCAN 先执⾏;图⽰中的SQL执⾏顺序即为:INDEX RANGE SCAN —> TABLE ACCESS BY GLOBAL INDEX ROWID —> INDEX UNIQUE SCAN —> TABLE ACCESS BY INDEX ROWID —> NESTED LOOPS OUTER —> SORT GROUP BY —> SELECT STATEMENT, GOAL = ALL_ROWS(注:PLSQL提供了查看执⾏顺序的功能按钮(上图中的红框部分) )②:对图中动作的⼀些说明:1. 上图中 TABLE ACCESS BY … 即描述的是该动作执⾏时表访问(或者说Oracle访问数据)的⽅式;表访问的⼏种⽅式:(⾮全部)TABLE ACCESS FULL(全表扫描)TABLE ACCESS BY ROWID(通过ROWID的表存取)TABLE ACCESS BY INDEX SCAN(索引扫描)(1) TABLE ACCESS FULL(全表扫描):Oracle会读取表中所有的⾏,并检查每⼀⾏是否满⾜SQL语句中的 Where 限制条件;全表扫描时可以使⽤多块读(即⼀次I/O读取多块数据块)操作,提升吞吐量;使⽤建议:数据量太⼤的表不建议使⽤全表扫描,除⾮本⾝需要取出的数据较多,占到表数据总量的 5% ~ 10% 或以上(2) TABLE ACCESS BY ROWID(通过ROWID的表存取) :先说⼀下什么是ROWID?ROWID是由Oracle⾃动加在表中每⾏最后的⼀列伪列,既然是伪列,就说明表中并不会物理存储ROWID的值;你可以像使⽤其它列⼀样使⽤它,只是不能对该列的值进⾏增、删、改操作;⼀旦⼀⾏数据插⼊后,则其对应的ROWID在该⾏的⽣命周期内是唯⼀的,即使发⽣⾏迁移,该⾏的ROWID值也不变。
oracle执行计划
oracle执行计划Oracle执行计划。
Oracle执行计划是数据库系统中非常重要的一个概念,它指的是Oracle数据库在执行SQL语句时所选择的最优执行路径。
通过执行计划,我们可以了解到Oracle是如何执行SQL语句的,从而可以对SQL语句进行优化,提高数据库的性能。
在本文中,我们将深入探讨Oracle执行计划的相关内容,包括执行计划的基本概念、执行计划的生成方式、执行计划的解读和优化等方面。
首先,我们来了解一下执行计划的基本概念。
执行计划是Oracle数据库优化器根据SQL语句和数据库对象的统计信息,通过优化算法生成的一种执行路径。
这个执行路径包括了SQL语句的执行顺序、访问方法、连接方式等信息。
通过执行计划,我们可以知道数据库是如何执行SQL语句的,从而可以对SQL语句进行优化,提高数据库的性能。
接下来,我们将介绍执行计划是如何生成的。
在Oracle数据库中,执行计划是由优化器根据SQL语句和数据库对象的统计信息生成的。
优化器会根据SQL语句的复杂度、表的大小、索引的选择等因素,选择最优的执行路径。
在生成执行计划时,优化器会考虑多种执行路径,并选择成本最低的执行路径作为最终的执行计划。
然后,我们将讨论如何解读执行计划。
执行计划通常以树状结构的方式呈现,包括了SQL语句的执行顺序、访问方法、连接方式等信息。
我们可以通过执行计划了解到SQL语句的执行路径,从而可以对SQL语句进行优化。
例如,我们可以通过执行计划了解到是否使用了索引、是否进行了全表扫描等信息,从而可以对SQL语句进行优化,提高数据库的性能。
最后,我们将介绍如何优化执行计划。
通过执行计划,我们可以了解到SQL语句的执行路径,从而可以对SQL语句进行优化。
例如,我们可以通过执行计划了解到是否使用了索引、是否进行了全表扫描等信息,从而可以对SQL语句进行优化,提高数据库的性能。
在优化执行计划时,我们可以考虑对SQL语句进行重写、创建索引、收集统计信息等方式,从而提高数据库的性能。
oracle执行计划详解
oracle执行计划详解Oracle执行计划详解。
在Oracle数据库中,执行计划是指数据库系统为了执行SQL语句而选择的最佳执行路径。
通过分析执行计划,我们可以了解数据库是如何执行SQL语句的,以及如何优化查询性能。
本文将详细介绍Oracle执行计划的相关内容,希望能对大家有所帮助。
执行计划是由Oracle优化器生成的,它会根据表的统计信息、索引信息和系统参数等因素来选择最佳的执行路径。
执行计划通常以树状图的形式展现,其中包括了SQL语句的执行顺序、访问方法、访问顺序等信息。
在执行计划中,我们经常会遇到以下几种重要的概念:1. 访问方法,包括全表扫描、索引扫描、索引范围扫描、唯一索引扫描等。
不同的访问方法对于不同的查询条件和表结构会有不同的性能影响。
2. 访问顺序,包括顺序访问和随机访问。
顺序访问通常发生在全表扫描的情况下,而随机访问则通常发生在索引扫描的情况下。
顺序访问的性能往往优于随机访问。
3. 连接方法,包括嵌套循环连接、哈希连接和排序-合并连接。
不同的连接方法对于不同的连接条件和表大小会有不同的性能影响。
通过分析执行计划,我们可以了解SQL语句的执行状况,并且可以根据执行计划来进行SQL语句的优化。
比如,我们可以通过创建索引、重写SQL语句、调整统计信息等方式来改善执行计划,从而提升查询性能。
在实际的数据库应用中,执行计划往往是优化性能的关键。
一个高效的执行计划可以大大减少查询的响应时间,提升系统的整体性能。
因此,我们需要深入了解执行计划的生成原理和优化方法,以便能够更好地优化数据库应用。
总之,执行计划是数据库优化的重要工具,它可以帮助我们了解SQL语句的执行情况,并且可以指导我们进行优化工作。
通过深入研究执行计划,我们可以更好地掌握Oracle数据库的优化技巧,提升系统的性能和稳定性。
希望本文能够对大家对Oracle执行计划有所帮助,也希望大家能够在实际的数据库应用中灵活运用执行计划来优化系统性能。
oracle固定执行计划
oracle固定执行计划
Oracle中的执行计划是指数据库执行语句时所使用的查询计划。
在执行语句时,Oracle会根据表的结构、索引、数据大小等多方面因素,选择一种最优的执行计划来执行查询语句,以提高查询性能。
但是,在某些情况下,Oracle会选择不太理想的执行计划,导致查询性能下降。
为了避免这种情况,我们可以通过使用Oracle提供的固定执行计划功能来强制Oracle使用我们指定的执行计划。
固定执行计划可以通过使用Outline(轮廓线)或SQL Profile (SQL剖析)来实现。
Outline是一组执行计划提示,它告诉Oracle 在执行某个查询时应该使用哪种执行计划。
SQL Profile则是一种特殊的Outline,它可以在执行某个查询时对查询语句进行剖析,以获取最优的执行计划。
固定执行计划的主要优点是可以提高查询性能,并且可以避免在数据库结构或数据大小变化时导致的执行计划变化。
但是,由于执行计划可能会受到多种因素的影响,因此固定执行计划并不是适用于所有情况的最佳解决方案。
在使用固定执行计划时,需要注意一些问题,如在更新表结构时可能会导致提示失效、在数据库版本升级时可能会导致SQL Profile 无法使用等。
因此,在使用固定执行计划前,需要仔细考虑是否真的需要使用该功能,以及如何正确地使用该功能。
- 1 -。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
ORACLE 执行计划介绍与测试(沈克勤)2005-3-31.目的:本文档的目的是通过介绍常用的HINT来了解ORACLE的优化器的工作原理及执行计划,以期望起到抛砖引玉的作用。
在实际开发中有意识地控制SQL的执行计划,以达到SQL 执行性能的最优以及执行计划稳定。
为了减少枯燥的文档描述,使用了较多的图示。
2.如何查看执行计划首先创建EXPLAIN_PLAN表不同版本的ORACLE,该表结构可能会不同。
请使用的ORACLE中$ORACLE_HOME/rdbms/admin/utlxplan.sql去创建该表。
方法1:使用SQL*PLUS 的SET AUTOTRACE :SQL>SET AUTOTRACE ON EXPLAIN 执行SQL,且仅显示执行计划SQL>SET AUTOTRACE ON STATISTICS 执行SQL,且仅显示执行统计信息SQL>SET AUTOTRACE ON 执行SQL,且显示执行计划与执行统计信息SQL>SET AUTOTRACE TRACEONLY 仅显示执行计划与统计信息,无执行结果SQL>SET AUTOTRACE OFF 关闭跟踪显示计划与统计方法2:使用PL/SQL Developer工具方法3:使用DBMS_XPLAN.DISPLAY()方法4:直接查看表:EXPLAIN_TABLESELECT lpad(' ',level-1)||operation||' '||options||' '||object_name "Plan"FROM plan_tableCONNECT BY prior id = parent_idAND prior statement_id = statement_idSTART WITH id = 0AND statement_id = '&1'ORDER BY id;3.如何控制与改变执行计划我并没有见过单独介绍ORACLE SQL优化器原理方面的资料。
但可以从ORACLE的HINT这个侧面来了解ORACLE的优化器的原理,从而最有效地书写SQL。
方法1:使用ORACLE的HINTORACLE的HINT是用来提示ORACLE的优化器,以期选择用户期望的执行计划。
在许多情况下,ORACLE默认的执行方式并不总是最优的,只不过我们平时大多数所操作的数据量比较小,好的执行计划与差的执行计划所消耗的时间上的差很少,用户感觉不到而已。
但于对书写操作大数据量的SQL而言,其SQL的书写则需要先了解一下执行计划是否最优或满足生产需要。
通常从开发环境迁移到生产环境下时,往往会出现此类情况。
例如:假设有一张客户表,在客户类别上有索引。
如果想查找某一类别用户,而该类别用户占总数的比例高达90%,则此时采用全表扫描方式将会比索引扫描方式快。
如果不使用HINT,ORACLE很可能会选择使用索引方式来执行。
使用HINT可以:1.改变SQL中的表的关联顺序2.改变SQL中的表的关联方式3.使用并行来执行DML、DDL、以及SELECT语句4.改变表的访问路径5.重写SQL6.其他等HINT的书写方式如下:{DELETE|INSERT|SELECT|UPDATE} /*+ hint [text] [hint[text]]... */如:select /*+ index(emp)*/ count(*) from emp方法2:使用OUTLINE来改变已有SQL的执行计划在实际项目中,通常在开发环境下一些SQL执行没有任何问题,而到了生产环境或生产环境的数据量发生较大的变量时,其SQL的执行效率会异常的慢。
此时如果更改SQL,则可能需要重新修改源程序以及重新编译程序。
如果觉得修改源程序的成本比较大,则可以使用OUTLINE在不改变原应用程序的情况下更改特定SQL的执行计划。
OUTLINE的原理是将调好的SQL的执行计划(一系列的HINT)存贮起来,然后该执行计划所对应的SQL用目前系统那个效率低下的SQL来替代之。
从而使得系统每次执行该SQL时,都会使用已存贮的执行计划来执行。
因此可以在不改变已有系统SQL的情况下达到改变其执行计划的目的。
OUTLINE方式也是通过存贮HINT的方式来达到执行计划的稳定与改变。
4.常用的HINT介绍(部分)FULL1)功能:用于指定对某个表进行全表扫描。
语法如下:2)使用场景:¾如果查询的结果占全表的数据量的比例比较高(即选择率较高,其经验值为>30%),则选择使用全表扫描的方式会比索引来得快。
因为如果查询结果字段不是索引字段的话,则将进行两次IO:一次执行索引的选择,另一次根据其索引中存贮的ROWID来查询表中的结果字段值。
¾另外一种情况也可能需要使用FULL提示。
如两个表进行关联操作,你希望其中一个表为全表扫描,另一表为索引扫描(如使用NESTED LOOPS方式).INDEX1)功能:与FULL相对应,用于指定对某个表进行索引扫描。
INDEX提示的可以不需要指定所使用的索引名,如果一个表有多个索引,则系统会选择合适的一个。
语法如下:2)使用场景:¾查询结果占全表的比例较小或只返回几行,则需要使用INDEX提示。
¾如果查询的结果字段存在于所提示的索引中,则使用全索引扫描方式也可能比全表扫描方式快。
因为索引的数据量通常比表的数据量要小,因此其IO的次数也会比扫描表少。
如:(可以看出,下图的执行计划将不进行表的扫描。
)INDEX_COMBINE1)功能该提示用于提示优化器在单个表中使用多于一个的位图索引。
语法如下:2)使用场景:¾在数据仓库项目中,常会创建位图索引来提高查询效率以及减少索引存贮量。
但在OLTP系统中,建议不要创建位图索引,因为在有位图索引的表上大量更新或插入数据的话,则将导致索引容量快速增长,此时需要将索引重建或在更新前置无效。
注:如果割舍不了位图索引的高性能以及低存贮的话,可以参照以下方式来解决其更新的问题:a) A workaround for this problem would be to commit after every update.Committing will enable index logic to reclaim the wasted space created by these deleted records.b)The best workaround is still to rewrite your application to use bulk dml.This may be done by creating a table to store up all the changes youintend to make. This table should enable you to code a bulk dmlstatement that applies all the changes. Since bitmap index dml isspecially optimized for bulk dml this would probably be the bestmechanism to rapidly apply many changes to a bitmap indexed table.c)One workaround is to drop the index, do the updates and then againrecreate the indexd)Last workaround is to set the Bitmap to UNUSED.USE_CONCAT1)功能用于提示优化器使用UNION ALL方式来替代范围查询。
语法如下:2)使用场景:¾如果查询条件字段上有索引、查询条件表达式为IN或OR,且通过索引方式会比全表扫描方式快的话,则可以考虑使用该种提示。
但如果查询结果占全表的比例比较高时,则使用全表扫描反而会更快。
ORDERED1)功能用于提示优化器使用FROM子名中表出现的顺序来关联各表。
语法如下:`2)使用场景:¾如以上三表:设serv为用户表,有100个用户,cdr_gsm为用户语音清单表,有1000万个用户的1亿条清单,cdr_sms为用户短信清单表,也有1000万用户的1亿条清单,如果不使用该提示,则如果ORACLE使用关联顺序为((cdr_gsm,cdr_sms)serv),则系统将先进行致命的两个清单表的关联操作。
USE_NL1)功能当需要进行多表关联操作时,选择使用嵌套循环方式进行关联操作。
语法如下:2)使用场景:¾相对于使用HASH JOIN或MERGE JOIN,NESTED LOOPS JOIN方式可以获得最快的用户响应。
例如上图所示,优化器的执行过程如下:a)扫描CDR表,取得一条记录b)根据步骤a扫描得到的记录中的prod_id,查找prod中的相同prod值c)将该prod_id关联的结果返回给用户d)继续执行步骤a,直到CDR表结束。
¾另外一种情况也需要使用该种提示:如果关联的两个表,其中在第一个表中的选择结果很小,而第二表个的选择结果很大,且第二个表中在关联字段上有索引,此时使用该种提示将比其他二种JOIN方式更有优势。
见下图:在索引上进行范围扫描USE_MERGE1)功能当需要进行多表关联操作时,选择使用先按关联字段进行排序,然后从相关联的已排序的结果中取得关联结果。
语法如下:2)使用场景:¾如果相关联的表都是一个数量级,且其中一个或多个表在关联字段上有索引,此时使用该提示将可获得的比其他两种JOIN方式更好的性能。
MERGE JOIN的执行过程如下:a)对关联的其中的一个表进行排序操作,其排序方式可以为全表扫描获得关联字段上的ROWID顺序及相关结果字段,也可以通过关联字段上的索引来获得所需ROWID的顺序、并根据此ROWID从表中获得结果字段b)对第二张表进行排序,方法同步骤ac)从步骤a与步骤b的结果中按顺序取得匹配结果即为所关联的结果集。
注:如果相关系的表是同一数量级,且相关联的表在关联字段上没有索引,该种方式下系统将会对所关联的表都进行全表扫描排序,其成本极高。
所以在有的数据库系统中(如INFORMIX IDS7以后的版本)已不使用MERGE JOIN的关联方式。
取而代之的是使用HASH JOIN方式。
USE_HASH1)功能当需要进行多表关联操作时,选择使用全表扫描的方式在其中一个表的关联字段上创建HASH表(该表一般选择较小的表,以便可以存于SGA内存中,并达到提高探测的速度的目的),然后对另一表上进行全表扫描且以同样的算法构建HASH表,同时探测基于第一个表中上HASH表,查找匹配的键值。