oracle执行计划学习文档
Oracle数据库中级培训(执行计划)第6讲

上海全成通信技术有限公司 金刚(seniordba@) 金刚 2009-12
目录
PLAN(执行计划 执行计划) 一. SQL EXECUTION PLAN(执行计划) 成本分析入门) 二. SQL COST(成本分析入门 成本分析入门 表分区)设计 三. PARTITION(表分区 设计 表分区 四. INDEX(索引 索引) 索引 并行) 五. PARALLEL(并行 并行 提示) 六. HINT(提示 提示 七. 设计开发误区
步骤一:人工设置 和存储子系统处理能力。 用户下执行) 步骤一:人工设置CPU和存储子系统处理能力。(在sys用户下执行 和存储子系统处理能力 在 用户下执行 begin dbms_stats.set_system_stats('MBRC',12); dbms_stats.set_system_stats('MREADTIM',30); dbms_stats.set_system_stats('SREADTIM',5); dbms_stats.set_system_stats('CPUSPEED',1500); end; /
案例1:关于 案例 关于CPU成本讨论 关于 成本讨论
步骤三: 步骤三:分析执行计划
1)explain plan for select /*+ cpu_costing ordered_predicates */ * from t1 where v1 = 1 and n2 = 18 and n1 = 998 ;
分析如下: 分析如下: 1)类型转换30000次,比较30000+1500+75=31574 2)类型转换1次, 比较30002 3)类型转换30000次,比较30000+1500+1=31501 4)类型转换1次, 比较30002 5)类型转换30000次,比较1502次 结论: 结论: 1.COST(CPU)= 10,456,833/(1500*5000)=1.39 2.优化技巧,避免数据类型转换 优化技巧, 优化技巧
oracle基础知识(十三)----执行计划
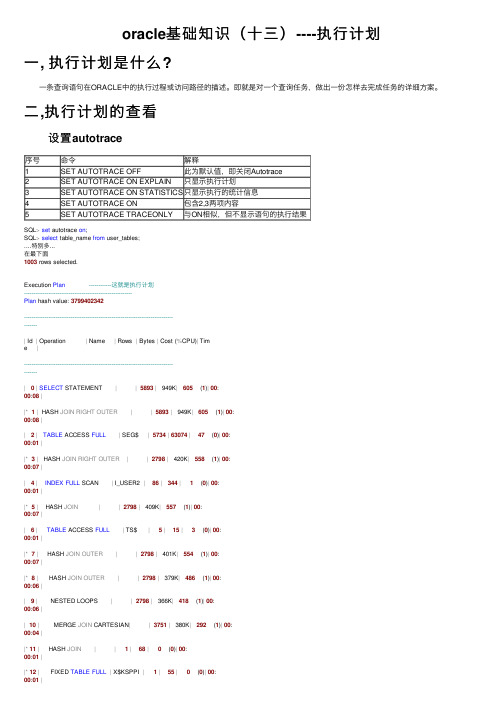
oracle基础知识(⼗三)----执⾏计划⼀, 执⾏计划是什么? ⼀条查询语句在ORACLE中的执⾏过程或访问路径的描述。
即就是对⼀个查询任务,做出⼀份怎样去完成任务的详细⽅案。
⼆,执⾏计划的查看 设置autotrace序号命令解释1SET AUTOTRACE OFF此为默认值,即关闭Autotrace2SET AUTOTRACE ON EXPLAIN只显⽰执⾏计划3SET AUTOTRACE ON STATISTICS只显⽰执⾏的统计信息4SET AUTOTRACE ON包含2,3两项内容5SET AUTOTRACE TRACEONLY与ON相似,但不显⽰语句的执⾏结果SQL>set autotrace on;SQL>select table_name from user_tables;....特别多...在最下⾯1003 rows selected.Execution Plan------------这就是执⾏计划----------------------------------------------------------Plan hash value: 3799402342---------------------------------------------------------------------------------------| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |---------------------------------------------------------------------------------------|0|SELECT STATEMENT ||5893| 949K|605 (1)|00:00:08||*1| HASH JOIN RIGHT OUTER||5893| 949K|605 (1)|00:00:08||2|TABLE ACCESS FULL| SEG$ |5734|63074|47 (0)|00:00:01||*3| HASH JOIN RIGHT OUTER||2798| 420K|558 (1)|00:00:07||4|INDEX FULL SCAN | I_USER2 |86|344|1 (0)|00:00:01||*5| HASH JOIN||2798| 409K|557 (1)|00:00:07||6|TABLE ACCESS FULL| TS$ |5|15|3 (0)|00:00:01||*7| HASH JOIN OUTER||2798| 401K|554 (1)|00:00:07||*8| HASH JOIN OUTER||2798| 379K|486 (1)|00:00:06||9| NESTED LOOPS ||2798| 366K|418 (1)|00:00:06||10| MERGE JOIN CARTESIAN||3751| 380K|292 (1)|00:00:04||*11| HASH JOIN||1|68|0 (0)|00:00:01||*12| FIXED TABLE FULL| X$KSPPI |1|55|0 (0)|00:00:01||13| FIXED TABLE FULL| X$KSPPCV |100|1300|0 (0)|00:00:01||14| BUFFER SORT ||3751| 131K|292 (1)|00:00:04||*15|TABLE ACCESS FULL| OBJ$ |3751| 131K|292 (1)|00:00:04||*16|TABLE ACCESS CLUSTER| TAB$ |1|30|1 (0)|00:00:01||*17|INDEX UNIQUE SCAN | I_OBJ# |1||0 (0)|00:00:01||18|INDEX FAST FULL SCAN | I_OBJ1 |86281| 421K|68 (0)|00:00:01||19|INDEX FAST FULL SCAN | I_OBJ1 |86281| 674K|68 (0)|00:00:01|---------------------------------------------------------------------------------------Predicate Information (identified by operation id):---------------------------------------------------1- access("T"."FILE#"="S"."FILE#"(+) AND "T"."BLOCK#"="S"."BLOCK#"(+) AND"T"."TS#"="S"."TS#"(+))3- access("CX"."OWNER#"="CU"."USER#"(+))5- access("T"."TS#"="TS"."TS#")7- access("T"."DATAOBJ#"="CX"."OBJ#"(+))8- access("T"."BOBJ#"="CO"."OBJ#"(+))11- access("KSPPI"."INDX"="KSPPCV"."INDX")12- filter("KSPPI"."KSPPINM"='_dml_monitoring_enabled')15- filter("O"."OWNER#"=USERENV('SCHEMAID') AND BITAND("O"."FLAGS",128)=0) 16- filter(BITAND("T"."PROPERTY",1)=0)17- access("O"."OBJ#"="T"."OBJ#")Statistics-----这⾥是统计信息----------------------------------------------------------8 recursive calls0 db block gets8809 consistent gets0 physical reads0 redo size31347 bytes sent via SQL*Net to client1250 bytes received via SQL*Net from client68 SQL*Net roundtrips to/from client1 sorts (memory)0 sorts (disk)1003 rows processed 使⽤sql查看SQL>set autotrace off;SQL> explain plan for select*from WRI$_DBU_FEATURE_METADATA;Explained.SQL>SELECT plan_table_output FROM TABLE(DBMS_XPLAN.DISPLAY('PLAN_TABLE')); PLAN_TABLE_OUTPUT--------------------------------------------------------------------------------Plan hash value: 563503327-----------------------------------------------------------------------------------------------| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |-----------------------------------------------------------------------------------------------PLAN_TABLE_OUTPUT--------------------------------------------------------------------------------|0|SELECT STATEMENT ||176|91344|5(0)|00:00:01||1|TABLE ACCESS FULL| WRI$_DBU_FEATURE_METADATA |176|91344|5(0)|00:00:01|-----------------------------------------------------------------------------------------------8 rows selected.SQL>select*from table(dbms_xplan.display);PLAN_TABLE_OUTPUT--------------------------------------------------------------------------------Plan hash value: 563503327-----------------------------------------------------------------------------------------------| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |-----------------------------------------------------------------------------------------------PLAN_TABLE_OUTPUT--------------------------------------------------------------------------------|0|SELECT STATEMENT ||176|91344|5(0)|00:00:01||1|TABLE ACCESS FULL| WRI$_DBU_FEATURE_METADATA |176|91344|5(0)|00:00:01|-----------------------------------------------------------------------------------------------8 rows selected.SQL> 客户端的话界⾯有解释选项⾃⼰找找三,执⾏计划解释 01.执⾏顺序的原则 执⾏顺序的原则是:由上⾄下,从右向左 由上⾄下:在执⾏计划中⼀般含有多个节点,相同级别(或并列)的节点,靠上的优先执⾏,靠下的后执⾏ 从右向左:在某个节点下还存在多个⼦节点,先从最靠右的⼦节点开始执⾏。
oracle学习计划3篇

oracle学习计划3篇oracle学习计划一:swufe oracle club bi学习计划一、学习内容:〔一〕工具〔老成员〕:1、 oracle bi:娴熟运用该工具:重点学习报表设计;权限管理;bi publisher。
2、 e*cel:娴熟适用常用的统计、分析函数能够高效地提升项目进度。
3、pl/sql:侧重学习数据在该工具与数据库、bi工具间信息流的相关知识。
4、oracle database:娴熟查询历史数据,擅长发觉重点信息,能够开发依据项目需求和后端报表展示的数据存储模型。
5、etl〔odi,informatic,sql语言〕:实现依据项目需求对杂乱的历史数据进行整理、分析、加载。
6、数据模型:依据项目需求,以及后端展示工具设计数据模型。
工具〔新成员〕:1、oracle bi:通过step by step娴熟操作oracle bi基本工具。
2、e*cel:学习常用的统计、分析函数。
3、pl/sql〔后期〕4、oracle database〔后期〕〔二〕软实力:1、管理:管理是我们学习的核心,始于自己、究竟他人。
本学期采纳项目管理由老成员一对一〔多〕方式带领潜在核心成员。
2、英语:基础技能,特别是外企。
3、写作:基础技能,会议记录是提高写作技能很好方式,项目文档亦是如此〔每个项目都会形成大量的项目文档。
项目文档能够清楚、全面的反映该项目,同时也是解决项目的基本内容之一〕。
4、沟通:基础技能,团队内部;客户沟通。
一切的需求和产出都需要通过沟通实现。
5、分析:基础技能,规律分析有利于理解客户需求,充分挖掘数据潜在价值,推动项目高效地完成。
6、统计学:发觉数据规律、联系,展示其潜在价值。
二、工作内容:〔一〕日常维护:306作为我们的学习基地,每个成员有责任和义务使之维持一个舒适的学习环境。
〔二〕个人总结:定期总结是对自己和组织负责。
〔三〕成员沟通:团队的沟通是重要的社交形式,也是人生存的基本技能与需要。
oracle执行计划学习文档

oracle执行计划学习文档一、O racl e 执行SQL的步骤1.1、SQL 语句的两种类型DDL语句,不共享,每次执行硬解析;DML语句,会共享,硬解析或者软解析。
1.2、SQL执行步骤1、语法检测。
判断一条SQL语句的语法是否符合SQL的规范;2、语义检查。
语法正确的SQL语句在解析的第二个步骤就是判断该SQL语句所访问的表及列是否准确?用户是否有权限访问或更改相应的表或列?3、检查共享池中是否有相同的语句存在。
假如执行的SQL语句已经在共享池中存在同样的副本,那么该SQL语句将会被软解析,也就是可以重用已解析过的语句的执行计划和优化方案,可以忽略语句解析过程中最耗费资源的步骤,这也是我们为什么一直强调避免硬解析的原因。
这个步骤又可以分为两个步骤:(1)验证SQL语句是否完全一致。
(2)验证SQL语句执行环境是否相同。
比如同样一条SQL语句,一个查询会话加了/*+ first_rows */的HINT,另外一个用户加/*+ all_rows */的HINT,他们就会产生不同的执行计划,尽管他们是查询同样的数据。
通过如上三个步骤检查以后,如果SQL语句是一致的,那么就会重用原有SQL语句的执行计划和优化方案,也就是我们通常所说的软解析。
如果SQL语句没有找到同样的副本,那么就需要进行硬解析了。
4、Oracle根据提交的SQL语句再查询相应的数据对象是否有统计信息。
如果有统计信息的话,那么CBO将会使用这些统计信息产生所有可能的执行计划(可能多达成千上万个)和相应的Cost,最终选择Cost最低的那个执行计划。
如果查询的数据对象无统计信息,则按RBO的默认规则选择相应的执行计划。
这个步骤也是解析中最耗费资源的,因此我们应该极力避免硬解析的产生。
至此,解析的步骤已经全部完成,Oracle将会根据解析产生的执行计划执行SQL语句和提取相应的数据。
二、优化器介绍Oracle在执行一个SQL之前,首先要分析一下语句的执行计划,然后再按执行计划去执行。
Oracle执行计划

基本使用方式:SQL> set autotrace on; (SQL PLUS中使用)
3.其他工具
PPT文档演模板
Oracle执行计划
准备:创建Plan_table表
PPT文档演模板
create table plan_table ( statement_id
long,
Oracle执行计划
PPT文档演模板
AUTO TRACE
SQL> set autotrace on; SQL> select * from dual; D X Execution Plan ----------------------------------------------------------
cost
integer,
cardinality
integer,
bytes
integer,
other_tag
varchar2 (255),
partition_start varchar2 (255),
partition_stop varchar2 (255),
partition_id
integer,
other
connect by prior id=parent_id ;
Oracle执行计划
第一个执行 计划
对应SQL语句:
select * from dual;
执行计划:
PPT文档演模板
Oracle执行计划
怎样看执行计划
执行计划其实是一棵树,层次最深的最先执行,层次 相同,上面的先执行。显示时已经按照层次缩进,因 此从最里面的看起。最后一组就是驱动表。例:
oracle的执行计划

oracle的执行计划Oracle是一种关系型数据库管理系统,执行计划是指在Oracle数据库中执行SQL语句的方式和过程。
它是由Oracle优化器生成的一种“蓝图”,它描述了通过何种方式来执行SQL以获得所需结果集。
这个“蓝图”包含有关要使用哪种访问方法,如何组合表和索引以及如何过滤结果集的信息,执行计划的准确性和有效性是影响SQL执行效率的主要因素之一。
一、Oracle执行计划的基本原理Oracle在执行SQL的时候,会自动根据查询条件和表结构等因素生成一份执行计划。
在执行计划的生成过程中,Oracle会根据不同的查询方法和算法,通过消耗最少的时间来获取查询结果。
因此,对于复杂的SQL查询,可能会有多个执行计划可供选择,而不同的执行计划会对查询效率产生显著的影响。
在考虑生成执行计划的方法和算法时,Oracle优化器一般会考虑以下几个因素:1. 索引的选择:如果有可用的索引可以用于查询,优化器就会选择使用索引。
2. 连接方式:Oracle查询可以使用多种连接方式,如NL join, Hash join和Sort merge join等,优化器会尝试选择最适合当前查询的连接方式。
3. 筛选条件的处理:Oracle会尝试使用所有可用的筛选条件来限制查询结果,以便从数据表中检索出尽可能少的行。
4. 查询方式:Oracle可以使用多种查询方式来获得所需结果,如扫描整个表或仅使用部分表,或使用合并或排序等操作来产生所需结果。
在执行计划的生成过程中,优化器通过对表统计信息的分析和对SQL语句分析,可以获得优化方案的估计成本,并选择代价最小的执行计划来执行查询。
二、Oracle执行计划的格式在Oracle中,可以使用EXPLAIN PLAN语句来查看SQL执行计划。
执行计划的输出结果通常包括以下几个部分:1. ID: 执行计划中每个操作的唯一标识符,可以作为连接其他操作的依据。
2. Operation: 执行计划中每个操作的名称。
oracle学习计划3篇

oracle学习计划3篇oracle学习打算一:swufe oracle club bi学习打算一、学习内容:(一)工具(老成员):1、oracle bi:熟练使用该工具:重点学习报表设计;权限治理;bi publisher。
2、e_cel:熟练适用常用的统计、分析函数能够高效地提升项目进度。
3、pl/sql:侧重学习数据在该工具与数据库、bi工具间信息流的相关知识。
4、oracle database:熟练查询历史数据,善于发觉重点信息,能够开发依照项目需求和后端报表展示的数据存储模型。
5、etl(odi,informatic,sql语言):实现依照项目需求对杂乱的历史数据进行整理、分析、加载。
6、数据模型:依照项目需求,以及后端展示工具设计数据模型。
工具(新成员):1、oracle bi:通过step by step熟练操作oracle bi差不多工具。
2、e_cel:学习常用的统计、分析函数。
3、pl/sql(后期)4、oracle database(后期)(二)软实力:1、治理:治理是我们学习的核心,始于自己、终于他人。
本学期采纳项目治理由老成员一对一(多)方式带领潜在核心成员。
2、英语:基础能力,专门是外企。
3、写作:基础能力,会议记录是提高写作能力非常好方式,项目文档亦是如此(每个项目都会形成大量的项目文档。
项目文档能够清晰、全面的反映该项目,同时也是解决项目的差不多内容之一)。
4、沟通:基础能力,团队内部;客户沟通。
一切的需求和产出都需要通过沟通实现。
5、分析:基础能力,逻辑分析有利于理解客户需求,充分挖掘数据潜在价值,推动项目高效地完成。
6、统计学:发觉数据规律、联系,展示其潜在价值。
二、工作内容:(一)日常维护:306作为我们的学习基地,每个成员有责任和义务使之维持一个舒适的学习环境。
(二)个人总结:定期总结是对自己和组织负责。
(三)成员交流:团队的交流是重要的社交形式,也是人一辈子存的差不多能力与需要。
ORACLE中的执行计划

Oracle 执行计划1,什么是执行计划所谓执行计划,顾名思义,就是对一个查询任务,做出一份怎样去完成任务的详细方案。
举个生活中的例子,我从珠海要去英国,我可以选择先去香港然后转机,也可以先去北京转机,或者去广州也可以。
但是到底怎样去英国划算,也就是我的费用最少,这是一件值得考究的事情。
同样对于查询而言,我们提交的SQL仅仅是描述出了我们的目的地是英国,但至于怎么去,通常我们的SQL中是没有给出提示信息的,是由数据库来决定的。
我们先简单的看一个执行计划的对比:SQL> set autotrace traceonly执行计划一:SQL> select count(*) from t;COUNT(*)----------24815Execution Plan0 SELECT STATEMENT Optimizer=CHOOSE1 0 SORT (AGGREGATE)2 1 TABLE Access (FULL) OF 'T'执行计划二:SQL> select count(*) from t;COUNT(*)24815Execution Plan0 SELECT STATEMENT Optimizer=CHOOSE (Cost=26 Card=1)1 0 SORT (AGGREGATE)2 1 INDEX (FULL SCAN) OF 'T_INDEX' (NON-UNIQUE) (Cost=26 C ard=28180)这两个执行计划中,第一个表示求和是通过进行全表扫描来做的,把整个表中数据读入内存来逐条累加;第二个表示根据表中索引,把整个索引读进内存来逐条累加,而不用去读表中的数据。
但是这两种方式到底哪种快呢?通常来说可能二比一快,但也不是绝对的。
这是一个很简单的例子演示执行计划的差异。
对于复杂的SQL(表连接、嵌套子查询等),执行计划可能几十种甚至上百种,但是到底那种最好呢?我们事前并不知道,数据库本身也不知道,但是数据库会根据一定的规则或者统计信息(statistics)去选择一个执行计划,通常来说选择的是比较优的,但也有选择失误的时候,这就是这次讨论的价值所在。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
oracle执行计划学习文档一、O racl e 执行SQL的步骤1.1、SQL 语句的两种类型DDL语句,不共享,每次执行硬解析;DML语句,会共享,硬解析或者软解析。
1.2、SQL执行步骤1、语法检测。
判断一条SQL语句的语法是否符合SQL的规范;2、语义检查。
语法正确的SQL语句在解析的第二个步骤就是判断该SQL语句所访问的表及列是否准确?用户是否有权限访问或更改相应的表或列?3、检查共享池中是否有相同的语句存在。
假如执行的SQL语句已经在共享池中存在同样的副本,那么该SQL语句将会被软解析,也就是可以重用已解析过的语句的执行计划和优化方案,可以忽略语句解析过程中最耗费资源的步骤,这也是我们为什么一直强调避免硬解析的原因。
这个步骤又可以分为两个步骤:(1)验证SQL语句是否完全一致。
(2)验证SQL语句执行环境是否相同。
比如同样一条SQL语句,一个查询会话加了/*+ first_rows */的HINT,另外一个用户加/*+ all_rows */的HINT,他们就会产生不同的执行计划,尽管他们是查询同样的数据。
通过如上三个步骤检查以后,如果SQL语句是一致的,那么就会重用原有SQL语句的执行计划和优化方案,也就是我们通常所说的软解析。
如果SQL语句没有找到同样的副本,那么就需要进行硬解析了。
4、Oracle根据提交的SQL语句再查询相应的数据对象是否有统计信息。
如果有统计信息的话,那么CBO将会使用这些统计信息产生所有可能的执行计划(可能多达成千上万个)和相应的Cost,最终选择Cost最低的那个执行计划。
如果查询的数据对象无统计信息,则按RBO的默认规则选择相应的执行计划。
这个步骤也是解析中最耗费资源的,因此我们应该极力避免硬解析的产生。
至此,解析的步骤已经全部完成,Oracle将会根据解析产生的执行计划执行SQL语句和提取相应的数据。
二、优化器介绍Oracle在执行一个SQL之前,首先要分析一下语句的执行计划,然后再按执行计划去执行。
分析语句的执行计划的工作是由优化器(Optimizer)来完成的。
不同的情况,一条SQL 可能有多种执行计划,但在某一时点,一定只有一种执行计划是最优的,花费时间是最少的。
Oracle目前提供RBO和CBO两种优化器。
2.1 RBO(RULE-BASE Optimization)基于规则的优化器RBO的执行路径和等级:1、Single Row by Rowid(等级最高)2、Single Row by Cluster Join3、Single Row by Hash Cluster Key with Unique or Primary Key4、Single Row by Unique or Primary Key5、Clustered Join6、Hash Cluster Key7、Indexed Cluster Key8、Composite Index9、Single-Column Indexes10、Bounded Range Search on Indexed Columns11、Unbounded Range Search on Indexed Columns12、Sort Merge Join13、MAX or MIN of Indexed Column14、ORDER BY on Indexed Column15、Full Table Scan(等级最低)优化器根据上述等级优先选择高效的执行路径,以上涉及到的概念在后面详细分析。
2.2 CBO(COST-BASE Optimization)基于代价的优化器Oracle把一个代价引擎集成在数据库内核,用来估计每个执行计划的代价,并量化执行计划所耗费资源,从而选择选择最优的执行计划,查询耗费资源分为以下三种。
I/0代价,即从磁盘读数据到内存的代价,从数据文件中数据块的内容读取到SGA数据高速缓存中,这是数据访问最主要的代价,故优化原则一般以降低查询产生的I/0次数为主;CPU代价,即处理在内存中数据所需代价,如对数据进行排序(sort)或者连接(join)操作等;NetWork代价,对访问跨服务器数据库的数据,需要花费的传输操作耗费的资源。
CBO 方式通过表和索引的统计数据计算出相对准确的代价,然后采用最佳的执行计划,所以定期对表和索引进行分析是非常必要的,否则得不偿失,关于数据分析技术详见第三章。
2.3 优化器模式Optimization-mode 即优化器模式,可选值包括:1、Rule ,采用的是RBO;2、CHOOSE,根据实际情况,如果数据字典中包含了引用表的统计数据,则采用CBO优化器,否则采用RBO;3、ALL-Rows是CBO使用的第一种优化方法,以数据吞吐量为目标,以便可以使用最少的资源完成查询;4、FIRST-ROWS是CBO使用的第二种优化方法,以数据的响应时间为目标,以便快速查询出开始的几行;5、FIRST-ROWS_[1|10|100|1000] 是CBO使用的第三种优化方法,选择一个响应时间最小的计划,迅速查询出结果。
2.4 查看执行计划2.4.1、查看能执行计划方式1、通过下面的sql查询:explain plan forSELECT * FROM bss_org WHERE bss_org_id=1;SELECT * FROM table(dbms_xplan.display);2、直接看pl/sql的explain Plan。
2.4.2 Estimator共 3 种度量标准:1、Selectivity表示有多少 rows 可以通过谓词被选择出来,大小介于 0.0~1.0,0 表示没有 row 被选择出来。
如果没有 statistics,estimator 会使用一个默认的 selectivity 值,这个值根据谓词的不同而异。
比如 '=' 的 selectivity 小于 '<'。
如果有statistics,比如对于last_name = 'Smith',estimator 使用last_name 列的 distinct 值的倒数(注:是指表中所有 last_name 的 distinct 值),作为 selectivity。
如果 last_name 列上有 histogram,则使用 histogram 根据 last_name 值的分布情况产生的 selectivity 作为 selectivity。
Histogram 在当列有数据倾斜时可以大大帮助 CBO 产生好的 selectivity。
2. Cardinality表示一个 row set 的行数。
Base cardinality:base table 的行数。
如果表分析过了,则直接使用分析的统计信息。
如果没有,则使用表 extents 的数量来估计。
Effective cardinality:有效行集,指从基表中选择出来的行数。
是 Base cardinality 和表上所有谓词的组合 Selectivity 的乘积。
如果表上没有谓词,那么 Effective cardinality = Base cardinality。
Join cardinality:两表 join 后产生的行数。
是两表 cardinality 的乘积(Cartesian)乘以 Join 谓词的 selectivity。
Distinct cardinality:列上 distinct 值的行数。
Group cardinality:GROUP BY 操作之后 row set 的行数。
由 grouping columns 的distinct cardinality 和整个 row set 的行数决定。
group cardinality lies between max ( dist. card. colx , dist. card. coly ) and min ( (dist. card. colx * dist. card. coly) , num rows in row set )3. CostCost 表现了 Disk I/O, CPU usage, Memory usage 资源单位的使用数量(units of work or resource used)。
Access path 决定从 base table 获得数据所需的 units of work 的数量。
也就是说Access path 决定 Cost 的值。
Access path 可以是 table scan, fast full index scan, index scan。
Oracle10G中,优化器默认为CBO,OPTIMIZER_MODE默认值为ALL_ROWS。
不再使用古老的RBO模式,但RULE、CHOOSE并没有彻底消失,有些时候仍然可以作为我们调试的工具。
另DBMS_XPLAN.DISPLAY_CURSOR观察更为详细的执行计划。
2.5 Scan方式2.5.1、Full T able Scan 全表扫描优点:可以同时读多个数据块,减少了i/0访问次数,而且每个数据块只会被读一次。
在查询一个表>5%~10%的时候,或者想用并行查询时,可以考虑使用。
全表扫描的Hint: Full T able Scan Hints: /*+ FULL(table alias) */;2.5.2、Rowid Scans获得一行数据的最快方法。
一般要先通过index scan 获得Rowid,如果需要的列不在index 中,再进行Rowid Scans 获得相应的行,如果在index 中,则不需要Rowid Scans。
HINT(很少用到):/*+ ROWID ( table ) */2.5.3、Index Scans1)、Index Unique Scans最多返回一个rowid,用于Unique Index 且index cols 在条件中使用"等于"。
如:SELECT * from serv where serv_id='518108574'。
2)、Index Range Scans返回的数据按照index columns 升序排列,index column 为同一个值的多行按照行rowid 的升序排列。
如果order by/group by 的顺序和Index Range Scans 返回的row set 的顺序相同就不需要再sort 了,否则还需要再对row set 进行sort。
如: SELECT * from serv where prop_cust_id='518108574'.Unique index 中的< > 条件,以及nonunique indexe 的< = > 条件,都会引起Index Range Scans。