spss操作
SPSS统计软件的操作与应用

SPSS统计软件的操作与应用SPSS(Statistical Package for the Social Sciences,社会科学统计软件包)是一种用于数据统计和分析的软件工具。
它提供了广泛的功能和分析选项,适用于各种研究领域和数据类型。
本文将介绍SPSS的操作步骤和应用场景。
一、SPSS的基本操作步骤:1.数据输入:在SPSS中,可以通过手动输入数据或导入其他文件格式的数据。
点击“文件”-“打开”命令,选择数据文件并确认导入选项。
4.数据转换与清洗:SPSS提供了强大的数据转换和清洗功能。
可以使用“计算变量”命令来创建新的变量,通过数学公式、逻辑操作或函数运算来计算新的变量。
可以使用“数据筛选”命令来选择特定的数据子集进行分析。
5.数据分析:SPSS提供了丰富的统计分析功能,包括描述性统计、频率分析、多元回归、因子分析、聚类分析、生存分析等。
可以使用“统计”-“描述统计”命令进行描述性统计分析,使用“分析”-“回归”命令进行回归分析。
6.图表绘制和结果解释:SPSS可以绘制各种类型的图表,如柱形图、线形图、散点图等,以可视化方式展示数据。
分析结果可以通过图表、表格和文字报告的方式进行解释。
7. 输出和导出结果:SPSS的分析结果可以输出为SPSS输出文件( .spo )或HTML格式,也可以导出为Microsoft Office软件(如Excel、Word、PowerPoint)或PDF格式。
二、SPSS的应用场景:1.社会科学研究:SPSS是社会科学研究中最常用的统计软件之一、它可用于分析民意调查数据、人口统计数据、教育问卷数据等。
可以进行统计描述、相关分析、卡方检验、T检验、方差分析、逻辑回归等分析。
2.医学研究:医学研究中需要对大量的数据进行分析和解释,SPSS 可以进行生存分析、队列研究、临床试验等统计分析,帮助研究人员发现疾病的原因、评估治疗方法的效果等。
3.市场研究:市场研究中需要对调查数据进行分析和预测,SPSS可以进行市场细分、购买选择行为分析、品牌忠诚度分析等统计分析,帮助企业了解市场需求和制定市场策略。
spss软件操作步骤
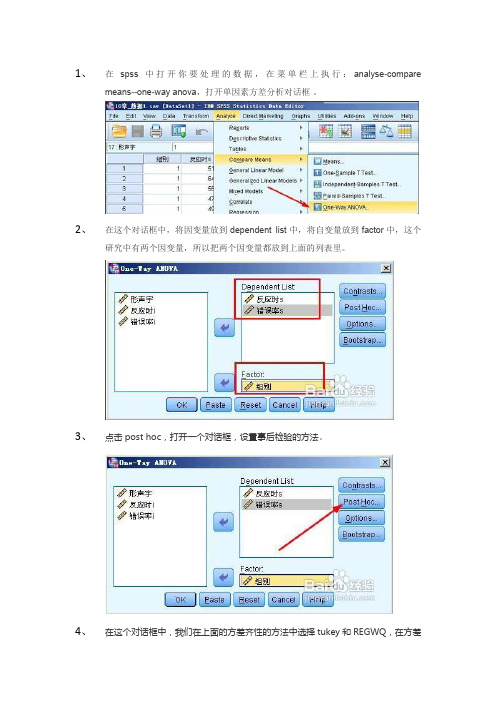
1、在spss中打开你要处理的数据,在菜单栏上执行:analyse-comparemeans--one-way anova,打开单因素方差分析对话框。
2、在这个对话框中,将因变量放到dependent list中,将自变量放到factor中,这个研究中有两个因变量,所以把两个因变量都放到上面的列表里。
3、点击post hoc,打开一个对话框,设置事后检验的方法。
4、在这个对话框中,我们在上面的方差齐性的方法中选择tukey和REGWQ,在方差不齐性的方法中选择dunnetts,点击continue继续。
5、回到了anova的对话框,点击options按钮,设置要输出的基本结果。
6、这里选择描述统计结果和方差齐性检验,点击continue按钮。
7、点击ok按钮,开始处理数据。
8、我们看到的结果中,第一个输出的表格就是描述统计,从这个表格里我们可以看到均值和标准差,在研究报告中,通常要报告这两个参数。
9、接着看方差齐性检验,方差不齐性的话是不能够用方差齐性的方法来检验的,还好,这里显示,显著性都没有达到最小值0.05,所以是不显著的,这证明方差是齐性的。
10、接着看单因素方差分析表,反应时sig值不显著,而错误率达到了显著的水平,这说明实验处理对错误率产生了影响,但是对反应时没有影响。
11、接着看事后检验,因为反应时是没有显著差异的,所以就不必再看反应时的事后检验,直接看错误率的事后检验,从图中标注的红色方框可以看到,第一组和二三组都有显著的差异,而第二组和第三组没有显著差异。
关于dunnet方法,它适合在方差不齐性的时候使用,因为方差齐性,不必去看这个方法的检验结果了。
12、最后我们看这个表格,这里有两个检验方法都是在方差齐性的时候使用的,我们从红色方框可以看出第一组分为一组,第二三组分为一组,它的意思是上面的结果是一致的。
spss常用分析方法操作步骤

SPSS常用分析方法操作步骤一、单变量单因素方差分析例题:某个年级有三个班,现在对他们的一次数学考试成绩进行随机抽(见下表),试在显著性水平0.005下检验各班级的平均分数有无显著差异(数据文件:数学考试成绩.sav)。
(1)建立数学成绩数据文件。
(2)选择“分析”→“比较均值”→“单因素方差”,打开单因素方差分析窗口,将“数学成绩”移入因变量列表框,将“班级”移入因子列表框。
(3)单击“两两比较”按钮,打开“单因素ANOV A两两比较”窗口。
(4)在假定方差齐性选项栏中选择常用的LSD检验法,在未假定方差齐性选项栏中选择Tamhane’s检验法。
在显著性水平框中输入0.05,点击继续,回到方差分析窗口。
(5)单击“选项”按钮,打开“单因素ANOV A选项”窗口,在统计量选项框中勾选“描述性”和“方差同质性检验”。
并勾选均值图复选框,点击“继续”,回到“单因素ANOV A选项”窗口,点击确定,就会在输出窗口中输出分析结果。
二、单变量多因素方差分析研究不同温度与不同湿度对粘虫发育历期的影响,得试验数据如表5-7。
分析不同温度和湿度对粘虫发育历期的影响是否存在着显著性差异(数据文件:粘虫.sav)。
(1)建立数据文件“粘虫.sav”。
(2)选择“分析”→“一般线性模型”→“单变量”,打开单变量设置窗口。
(3)分析模型选择:此处我们选用默认;(4)比较方法选择:在窗口中单击“对比”按钮,打开“单变量:对比”窗口进行设置,单击“继续”返回;(5)均值轮廓图选择:单击“绘制”按钮,设置比较模型中的边际均值轮廓图,单击“继续”返回;(6)“两两比较”选择,用于设置两两比较检验,本例中设置为“温度”和“湿度”。
三、相关分析调查了29人身高、体重和肺活量的数据见下表,试分析这三者之间的相互关系。
(1)建立数据文件“学生生理数据.sav”。
(2)选择“分析”→“相关”→“双变量”,打开双变量相关分析对话框。
(3)选择分析变量:将“身高”、“体重”和“肺活量”分别移入分析变量框中。
spss简单操作步骤

相应结果解释参考统计数或相关文献
7 一般线性模型:可以考察多自变量间的交互作用,先看交互作用是否显著,不显著就只考察各自变量的主效应
“分析”--“一般线性模型”--选择合适的统计方法,把自变量、因变量拉进去后选择要考察的结果后“确定”
8 相关:“分析”--“相关”--选择要做的相关--拉入要考察的变量--选取合适的相关法--“确定”
(4也是反向计分时需要的操作,如1-7计分时,把1-7这些旧值重新编码成7-1这些新值)
5 描述性结果:“分析”--“描述统计”--“频率”或“描述”--源自相应变量点入右侧框内--“确定”
6 比较均值(t检验、F检验):“分析”--“比较均值”--如果分两组选t检验,如果是多于两组选单因素方差分析(F),进入对话框后把分组变量拉入“分组变量”或“因子”下,因变量拉入相应框内,更改需要考察的结果后“确定”
1 数据排序:“数据”--“排序个案”--把需排序的变量排序框(貌似一次只能一个变量)--“确定”
2 删除个案:排序后,拉到排序后的变量,删除缺失值项
3 替换缺失值:“转换”--“替换缺失值”--把要替换的变量拉入右侧框内--“确定”
(2、3均是处理缺失值的方法)
4 分组或重新编码变量:“转换”--“重新编码为不同变量”--把相应变量拉入中间大框--在“输出变量”下的“名称”框内输入新名字--点击“更改”--“旧值与新值”赋予相应值
spss数据分析简单操作流程

spss数据分析简单操作流程1.打开SPSS软件。
Open the SPSS software.2.在数据编辑器中导入你的数据集。
Import your dataset into the data editor.3.检查数据是否被正确导入。
Check if the data has been imported correctly.4.在变量视图中检查数据变量。
Check the data variables in the variable view.5.在数据视图中查看数据记录。
View the data records in the data view.6.进行数据清洗,处理缺失值和异常值。
Clean the data, handle missing and outlier values.7.进行描述性统计分析,了解数据的基本特征。
Conduct descriptive statistical analysis to understand the basic characteristics of the data.8.选择合适的分析方法,比如t检验、方差分析等。
Select appropriate analysis methods, such as t-tests, ANOVA, etc.9.运行所选的分析方法。
Run the selected analysis methods.10.解释分析结果,得出结论。
Interpret the analysis results and draw conclusions.11.导出分析结果为表格或图表。
Export the analysis results as tables or charts.12.保存分析的数据和结果。
Save the analyzed data and results.。
SPSS基本操作步骤详解

SPSS基本操作步骤详解本文采用SPSS21.0版本,其它版本操作步骤大体相同一、基本步骤(一)检查数据在进行项目分析或统计分析之前,要检核输入的数据文件有无错误,即检核missing。
例,“XX量表”采用Likert scale五点量表式填答,每个题项的数据只有五个水平:1,2,3,4,5。
1.执行次数分布表的程序Analyze(分析)→Descriptive statistics(描述统计)→将题项变量【例,a1—a10】键入至Variables(变量)框中→Frequencies(频率)→Statistics(统计量)→Minimum (最小值)、Maximum(最大值)→Continue(继续)→OK(确定)2.执行描述统计量的程序Analyze(分析)→(描述统计)→将题项变量【例,a1—a10】键入至Variables(变量)框中→Descriptives(描述)→Options(选项)→Minimum(最小值)、Maximum(最大值)【此处一般为默认状态即可】→Continue(继续)→OK(确定)(二)反项计分若是分析的预试量表中没有反向题,则此操作步骤可以省略;量表或问卷题中如果有反向题,则在进行题项加总之前将反向题反向计分,否则测量分数所表示的意义刚好相反。
例,“XX量表”采用Likert scale五点量表式填答,反向题重向编码计分:1→5,2→4,3→3【可不写】,4→2,5→1。
Transform(转换)→Recode into same Variables(重新编码为相同变量)→将要反向的题目键入至Variables(变量)框中【例,a1,a3,a5】→Old and new values(旧值和新值)→在左边Old value—value中键入1,在右边New value—value中键入5,Add (添加)→……依次进行此步骤……在左边Old value—value中键入5,在右边New value —value中键入1,Add(添加)→Continue(继续)→OK(确定)【注意不同量表计分方式不同,因而反向编码计分也不同,常见的有四点量表、五点量表和六点量表等】(三)题项加总量表题项加总的目的在于便于进行观察值得高低分组。
SPSS操作步骤及解析

SPSS操作步骤及解析SPSS(Statistical Package for the Social Sciences)是一种用于数据分析的统计软件包。
它可以进行数据整理、描述统计分析、统计推断、回归分析、因子分析、聚类分析等各种统计分析。
下面是SPSS的操作步骤及解析。
1.数据导入:在SPSS中,数据可以以多种格式导入,如Excel文件、CSV文件、数据库导入等等。
点击“文件”按钮,然后选择“导入数据”选项。
在出现的对话框中选择要导入的文件,然后按照指示逐步完成导入过程。
3.描述统计分析:描述统计分析是指对数据进行基本的统计描述,包括计数、平均数、标准差、最小值、最大值等等。
点击“统计”按钮,在出现的下拉菜单中选择“描述统计”选项。
在打开的对话框中,选择要统计的变量,然后点击“确定”按钮即可生成统计描述。
4.数据转换:数据转换是指通过运算或者函数对数据进行转换,以得到更有意义的变量或者指标。
点击“转换”按钮,在出现的下拉菜单中选择“计算变量”选项。
在打开的对话框中,输入要进行的运算或者函数,然后点击“确定”按钮即可生成新的变量。
5.统计推断:统计推断是指通过样本数据对总体数据进行推断性统计分析。
点击“分析”按钮,在出现的下拉菜单中选择“统计推断”选项。
根据具体需求选择适当的统计方法,如t检验、方差分析、相关分析等等。
在打开的对话框中选择变量,并进行相应的设置,然后点击“确定”按钮即可生成推断性分析结果。
6.回归分析:回归分析是指通过对自变量和因变量之间的关系进行建模,预测因变量的取值。
点击“分析”按钮,在出现的下拉菜单中选择“回归”选项。
在打开的对话框中选择要进行回归分析的变量,然后进行相应的设置,如回归方法、模型选择等等,最后点击“确定”按钮即可生成回归分析结果。
7.图表制作:总结:。
spss基本操作完整版

spss基本操作完整版SPSS(Statistical Package for the Social Sciences)是一款广泛应用于数据分析和统计建模的软件。
它提供了一系列强大的功能和工具,可以帮助用户处理和分析大量的数据,从而得到准确的结果并支持决策制定。
本文将介绍SPSS的基本操作,并分享一些常用功能的使用方法。
一、数据导入与编辑在使用SPSS进行数据分析之前,首先需要导入要分析的数据,并对其进行编辑和整理。
下面介绍SPSS中的数据导入与编辑的基本操作。
1. 导入数据打开SPSS软件后,点击菜单栏中的"文件"选项,再选择"打开",然后选择要导入的数据文件(一般为Excel、CSV等格式)。
点击"打开"后,系统将自动将数据导入到SPSS的数据视图中。
2. 数据编辑在数据视图中,我们可以对导入的数据进行编辑,例如添加变量、删除无效数据、更改数据类型等操作。
双击变量名或者右键点击变量名,可以对变量属性进行修改。
通过点击工具栏上的"变量视图"按钮,可以进入变量视图进行更复杂的编辑。
二、数据清洗与处理数据清洗和处理是数据分析的重要步骤,它们能够提高数据的质量和可靠性。
下面介绍SPSS中的数据清洗与处理的基本操作。
1. 缺失值处理在实际的数据分析过程中,往往会遇到一些数据缺失的情况。
SPSS 提供了处理缺失值的功能,例如可以使用平均值或众数填补缺失值,也可以剔除含有缺失值的样本。
2. 数据筛选与排序当数据量较大时,我们通常需要根据一定的条件筛选出符合要求的数据进行分析。
SPSS提供了数据筛选和排序的功能,可以按照指定的条件筛选数据,并可以按照某个或多个变量进行数据排序。
三、统计分析SPSS作为统计分析的重要工具,提供了丰富的统计分析功能,下面介绍部分常用的统计分析方法。
1. 描述统计描述统计是对数据进行整体概述的统计方法,包括计数、求和、平均值、中位数、标准差、最大值、最小值等指标。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
SPSS 回顾:1描述性统计分析1.1基本描述性统计量的概念(1)操作步骤:Analyze→Descriptive Statistics→Descriptives(2)概念集中趋势的统计量:平均值、中位数、众数、求和离散趋势的统计量:方差、标准差、极差、最小值、最大值、均值标准误差分布形态的统计量:偏度、峰度1.2频数分析(1)操作步骤:Analyze →Descriptive Statistics→Frequencies(2)概念频数(Frenquency):变量值落在某个区间或者某个取值点的个数。
百分比(Percent):各频数占总样本数的百分比。
有效百分比(Valid Percent):各频数占有效样本数的百分比。
累计百分比(Cumulative Percent):各百分比逐级累加起来的结果,最终取值是100。
1.3探索性分析(1)操作步骤:Analyze →Descriptive Statistics→Explore(2)看得懂以下图形:箱图、茎叶图、QQ图特别注意:以下内容都与假设检验有关。
不同的检验有不同的零假设,但基本上对检验结果的判断都遵循以下判别规则,不再赘述。
(1)如果相伴概率值(P值或Sig.值)小于或等于显著性水平α,则拒绝H0。
(2)相伴概率值(P值或Sig.值)大于显著性水平α,则接受H0。
(3)相伴概率值在spss运行结果中查找。
显著性水平可由用户自行设定,如没有特别要求可取默认值0.05。
2两总体均值比较2.1单样本T检验(1)基本原理:检验样本均值与已知总体均值之间是否存在差异。
(2)操作步骤:Analyze→Compare Means→One Sample T Test(3)原假设H0:样本均值和总体均值之间不存在显著差异。
(4)关键结果标题和统计量:One Sample Test表和其中的t统计量和sig值。
2.2独立样本T检验(1)基本原理:检验两个独立正态样本的总体均值之间是否存在显著差异(2)应用的条件:两个样本相互独立且满足正态分布,样本数量可以不同(3)操作步骤:Analyze →Compare Means→Independent Samples T Test(4)原假设H0:两个独立样本的总体均值不存在显著差异。
(5)关键结果标题和统计量:Independent Samples Test表(a)首先,利用F检验判断两样本的方差是否相同(方差齐性)。
方差齐性原假设H0:认为两总体方差之间不存在显著性差异,方差齐性。
Levene’s Test for…部分的F统计量和sig值。
(b)根据第一步结果,决定T统计量和自由度计算公式,进而对T检验的结论作出判断。
T Test部分的t统计量和sig值。
取Levene’s Test for…部分有F统计量和sig值的行所对应的t统计量和sig值。
2.3 配对样本T检验(1)基本原理:检验两个配对正态样本的总体均值之间是否存在显著差异(2)应用的条件:两个样本配对且满足正态分布,样本数量一般相同。
配对的理解,两组同质受试样本配成对子或同一受试样本分别接受两种不同的处理。
(3)操作步骤:Analyze →Compare Means→Paired Samples T Test(4)原假设H0:两个配对样本的总体均值不存在显著差异。
(5)关键结果标题和统计量:Paired Samples Test表和其中的t统计量和sig值。
3方差分析(1)基本原理:检验两个以上正态样本的总体均值之间是否存在显著差异。
找到影响因变量变化的主要因素,确定各因素对因变量变化的影响程度。
(2)基本概念:因素(自变量)、水平、因变量、控制因素和随机因素。
(3)应用的条件:总体正态分布、方差齐性,样本随机且独立。
3.1单因素方差分析(4)操作步骤:Analyze →Compare Means→One-Way ANOVAOption和Post Hoc…按钮的设置(5)原假设H0:因素的不同水平下,因变量的总体均值没有显著性差异。
或者m个样本的总体均值都相同,即μ1=μ2=μ3=…=μm=μ。
(6)关键结果标题和统计量:Test of Homogeneity of Variances表和其中的Levene统计量和sig值,做方差齐性检验。
ANOVA表中的F统计量和sig值,判断多个样本的均值是否相等,从而判断可控因素是否是因变量的主要影响因素。
ANOVA表中的Between Group值,判断组间影响的大小,即可控因素影响的大小。
ANOVA表中的Within Group值,判断组内影响的大小,即随机因素影响的大小。
Multiple Comparisons表,根据Mean Difference值上的正负号和*号,判断哪个水平最显著。
3.2 多因素方差分析(4)操作步骤:Analyze→General Linear Model→UnivariateOption和Post Hoc…按钮的设置(5)原假设H0:不同因素的不同水平下,因变量的总体均值没有显著性差异。
或者m个样本的总体均值都相同,即μ1=μ2=μ3=…=μm=μ。
(6)关键结果标题和统计量:Levene’sTest of …表和其中的F统计量和sig值,做方差齐性检验。
Test of Between-Subjects Effects表中的F统计量和sig值,判断多个样本的均值是否相等。
从而判断不同可控因素是否是因变量的主要影响因素,并且根据F值的大小可判断哪个可控因素影响更大。
Multiple Comparisons表,根据Mean Difference值上的正负号和*号,判断哪个水平最显著。
4非参数检验4.1卡方检验(1)基本原理:检验样本观察值的频数与期望频数之间是否存在显著性差异。
(2)基本概念:观测频数和期望频数(3)操作步骤:以下两步缺一不可Date →Weight CasesAnalyze →Nonparametric Tests →Chi-Square有很多操作上的注意请参看ppt(4)原假设H0:样本来自的总体分布形态与期望分布(或理论分布)不存在显著差异。
(5)关键结果标题和统计量:Test Statistic表和其中的chi square和sig值,做卡方检验。
4.2二项分布检验(1)基本原理:检验观测数据是否来自二项分布总体的一种检验方法。
(2)基本概念:二分变量(3)操作步骤:以下两步缺一不可Analyze →Nonparametric Tests →BinomialTest Proportion的设置与样本数据的第1个各案所处的分布区间有关系。
(4)原假设H0:样本来自的总体分布与指定的二项分布不存在显著差异。
(5)关键结果标题和统计量:Binomial Test表和其中的Test Prop和sig值,做二项分布检验。
Test Prop值必须和所处的类别行的期望分布值对应。
4.3游程检验(1)基本原理:游程检验又称为链检验,主要用于检验一个变量的两个值(0和1)的分布是否呈现随机分布。
(2)基本概念:游程数的判断。
如以下:投掷硬币十次,出现正反面的变量值序列为0011101100,则游程个数为5,流程总个数为10。
(3)操作步骤:Analyze →Nonparametric Tests →Runs(4)原假设H0:样本的总体分布是随机的。
(5)关键结果标题和统计量:Run Test表和其中的sig值。
Number of Runs值给出游程数。
4.4单样本K-S检验(1)基本原理:用于检验样本数据是否服从某一特定的分布(正态分布、均匀分布、指数分布和泊松分布等)。
(2)基本概念:正态分布、均匀分布、指数分布和泊松分布(3)操作步骤:Analyze →Nonparametric Tests →1-sample K-S(4)原假设H0:样本来自的总体分布与指定的理论分布不存在显著差异。
(5)关键结果标题和统计量:1-sample K-S l Test表和其中的K-S Z和sig值。
(1)基本原理:对两组独立样本的分析来推断样本来自的两个总体的分布是否存在显著差异。
(2)基本概念:独立样本、秩(3)操作步骤:Analyze→Nonparametric Tests→2 Independent Samples(4)原假设H0:两独立样本的总体分布不存在显著差异。
(5)关键结果标题和统计量:Ranks表和其中Mean Rank值,表示每个分组的平均秩。
Test Statistic表和其中的Z和sig值,进行非参数检验。
4.6多独立样本非参检验(1)基本原理:对多组独立样本的分析来推断样本来自的多个总体的分布是否存在显著差异。
(2)基本概念:独立样本、秩(3)操作步骤:Analyze→Nonparametric Tests→k Independent Samples(4)原假设H0:多个独立样本的总体分布不存在显著差异。
(5)关键结果标题和统计量:Ranks表和其中Mean Rank值,表示每个分组的平均秩。
Test Statistic表和其中的chi square和sig值,进行非参数检验。
4.7两相关样本非参检验(1)基本原理:对两组相关样本的分析来推断样本来自的两个总体的分布是否存在显著差异。
(2)基本概念:配对样本(3)操作步骤:Analyze→Nonparametric Tests→2 Related Samples(4)原假设H0:两相关样本的总体分布不存在显著差异。
(5)关键结果标题和统计量:…Ranks Test表和其中Mean Rank值,表示每个分组的平均秩。
Test Statistic表和其中的Z和sig值,进行非参数检验。
(1)基本原理:对多组相关样本的分析来推断样本来自的多个总体的分布是否存在显著差异。
(2)基本概念:配对样本(3)操作步骤:Analyze→Nonparametric Tests→K Related Samples(4)原假设H0:多相关样本的总体分布不存在显著差异。
(5)关键结果标题和统计量:…Ranks Test表和其中Mean Rank值,表示每个分组的平均秩。
Test Statistic表和其中的Z和sig值,进行非参数检验。
5相关分析(1)基本原理:检验两个及以上变量之间是否存在相关性。
根据散点图判断是否存在相关关系,及正负方向。
根据相关系数,判断总体相关的程度。
(2)基本概念:相关程度(完全相关、不相关、相关)、相关形式(线形、非线形)、相关方向(正负)。
r=0 |r|<0.3 |r|=0.3~0.5 |r|=0.5~0.8 |r|>0.8 |r|=1相关系数取值范围相关程度无相关微弱相关低度相关显著相关高度相关完全相关(3)操作步骤:Graphs→Scatter/Dot绘制散点图Analyze →Correlate →Bivariate计算相关系数(4)原假设H0:两(或多)总体线性不相关。