模式识别实验报告
模式识别 实验报告一
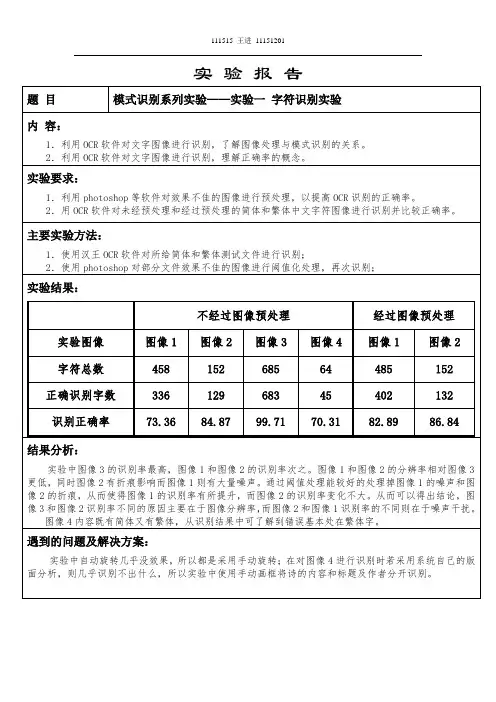
402
132
识别正确率
73.36
84.87
99.71
70.31
82.89
86.84
结果分析:
实验中图像3的识别率最高,图像1和图像2的识别率次之。图像1和图像2的分辨率相对图像3更低,同时图像2有折痕影响而图像1则有大量噪声。通过阈值处理能较好的处理掉图像1的噪声和图像2的折痕,从而使得图像1的识别率有所提升,而图像2的识别率变化不大。从而可以得出结论,图像3和图像2识别率不同的原因主要在于图像分辨率,而图像2和图像1识别率的不同则在于噪声干扰。
实验报告
题目
模式识别系列实验——实验一字符识别实验
内容:
1.利用OCR软件对文字图像进行识别,了解图像处理与模式识别的关系。
2.利用OCR软件对文字图像进行识别,理解正确率的概念。
实验要求:
1.利用photoshop等软件对效果不佳的图像进行预处理,以提高OCR识别的正确率。
2.用OCR软件对未经预处理和经过预处理的简体和繁体中文字符图像进行识别并比较正确率。
图像4内容既有简体又有繁体,从识别结果中可了解到错误基本处在繁体字。
遇到的问题及解决方案:
实验中自动旋转几乎没效果,所以都是采用手动旋转;在对图像4进行识别时若采用系统自己的版面分析,则几乎识别不出什么,所以实验中使用手动画框将诗的内容和标题及作者分开识别。
主要实验方法:
1.使用汉王OCR软件对所给简体和繁体测试文件进行识别;
2.理,再次识别;
实验结果:
不经过图像预处理
经过图像预处理
实验图像
图像1
图像2
图像3
图像4
图像1
图像2
字符总数
458
实验一模式识别范文

实验一模式识别范文
模式识别是计算机科学领域一个研究内容,它的目的是识别永久存在
的模式,以实现有效的数据处理和决策。
它主要集中在分类机制和分类算
法上,并且对特征结构及分类的准确性进行测试以应用到实际需求中。
模式识别是处理大量信息的基础,是一些新的有用信息与其他类别信
息区分的过程。
它可以建模出特殊情况,并有效的对这些类别判断准确性。
模式识别也可以改善监督学习、无监督学习、半监督学习的模式学习和其
他机器学习中的性能。
模式识别有各种应用,比如计算机视觉、声音识别、语言识别、手写
识别、面部识别、自然语言处理等,它们都是基于模式识别技术实现的。
模式识别技术可以大大提升机器人的视觉系统,以实现更准确和更快速的
行为。
在安全管理、公共交通、智能制造和生物医学等领域中,模式识别
技术也有广泛的应用。
模式识别也有其缺点,比如分类算法的运算速度容易延迟,特征选取
也有可能不太准确。
因此要正确使用模式识别,需要为特征选取和算法进
行合理的优化,以保证正确的识别结果。
总之,模式识别是一项广泛应用的技术,它可以提高机器学习的精确度,在计算机视觉等各个领域中有着广泛的应用。
实验七基于神经网络的模式识别实验

实验七基于神经网络的模式识别实验一、实验目的利用神经网络实现模式识别,并验证其性能。
掌握基于神经网络的模式识别方法。
二、实验原理1.神经网络神经网络是一种模仿生物神经系统的计算模型,它由大量的神经元节点相互连接而成。
在模式识别中,我们一般采用多层前向神经网络进行模式的训练和识别。
2.神经网络的训练过程神经网络的训练过程可以分为两步:前向传播和反向传播。
前向传播是指将输入样本通过网络的各个层传递到输出层,并计算输出结果。
反向传播是指根据输出结果和目标结果之间的误差,将误差反向传播到网络的各个层,并根据误差调整网络中的权值。
3.模式识别对于模式识别问题,我们首先需要将输入模式转化为特征向量,然后通过神经网络来训练这些特征向量,并将其与已知类别的模式进行比较,从而进行模式的识别。
三、实验步骤1.数据准备选择适当的模式识别数据集,例如手写数字识别的MNIST数据集,将其分为训练集和测试集。
2.特征提取对于每个输入模式,我们需要将其转化为一个特征向量。
可以使用各种特征提取方法,例如像素值,轮廓等。
3.神经网络设计设计合适的神经网络结构,包括输入层、隐藏层和输出层,并确定各层的神经元数目。
4.神经网络训练使用训练集对神经网络进行训练,包括前向传播和反向传播过程。
可以使用各种优化算法,例如梯度下降法。
5.模式识别使用测试集对训练好的神经网络进行测试和验证,计算识别的准确率和性能指标。
6.性能评估根据得到的结果,评估神经网络的性能,并分析可能的改进方法。
四、实验结果通过实验我们可以得到神经网络模式识别的准确率和性能指标,例如精确度、召回率和F1-score等。
五、实验总结在本次实验中,我们利用神经网络实现了模式识别,并验证了其性能。
通过实验,我们可以掌握基于神经网络的模式识别方法,了解神经网络的训练和识别过程,以及模式识别中的特征提取方法。
实验结果表明,神经网络在模式识别问题中具有较好的性能,并且可以根据需要进行改进和优化。
模式识别实习报告

一、实习背景随着科技的飞速发展,人工智能、机器学习等技术在各个领域得到了广泛应用。
模式识别作为人工智能的一个重要分支,具有广泛的应用前景。
为了更好地了解模式识别技术,提高自己的实践能力,我在2023年暑假期间参加了某科技有限公司的模式识别实习。
二、实习单位简介某科技有限公司是一家专注于人工智能、大数据、云计算等领域的科技创新型企业。
公司致力于为客户提供智能化的解决方案,业务涵盖智能识别、智能监控、智能分析等多个领域。
此次实习,我将在该公司模式识别部门进行实践学习。
三、实习内容1. 实习前期(1)了解模式识别的基本概念、原理和应用领域;(2)熟悉模式识别的相关算法,如神经网络、支持向量机、决策树等;(3)掌握Python编程语言,学会使用TensorFlow、Keras等深度学习框架。
2. 实习中期(1)参与实际项目,负责模式识别算法的设计与实现;(2)与团队成员协作,完成项目需求分析、算法优化和系统测试;(3)撰写项目报告,总结实习过程中的收获与不足。
3. 实习后期(1)总结实习期间的学习成果,撰写实习报告;(2)针对实习过程中遇到的问题,查找资料、请教同事,提高自己的解决问题的能力;(3)为后续实习工作做好充分准备。
四、实习收获与体会1. 理论与实践相结合通过实习,我深刻体会到理论与实践相结合的重要性。
在实习过程中,我将所学的模式识别理论知识运用到实际项目中,提高了自己的动手能力。
同时,通过解决实际问题,我更加深入地理解了模式识别算法的原理和应用。
2. 团队协作能力实习期间,我学会了与团队成员有效沟通、协作。
在项目中,我们共同面对挑战,分工合作,共同完成项目任务。
这使我认识到团队协作的重要性,为今后的工作打下了基础。
3. 解决问题的能力在实习过程中,我遇到了许多问题。
通过查阅资料、请教同事、独立思考等方式,我逐渐学会了如何分析问题、解决问题。
这种能力对我今后的学习和工作具有重要意义。
4. 深度学习框架的使用实习期间,我学会了使用TensorFlow、Keras等深度学习框架。
模式识别实习报告

实习报告一、实习背景及目的随着科技的飞速发展,模式识别技术在众多领域发挥着越来越重要的作用。
模式识别是指对数据进行分类、识别和解释的过程,其应用范围广泛,包括图像处理、语音识别、机器学习等。
为了更好地了解模式识别技术的原理及其在实际应用中的重要性,我参加了本次模式识别实习。
本次实习的主要目的是:1. 学习模式识别的基本原理和方法;2. 掌握模式识别技术在实际应用中的技巧;3. 提高自己的动手实践能力和团队协作能力。
二、实习内容及过程实习期间,我们团队共完成了四个模式识别项目,分别为:手写数字识别、图像分类、语音识别和机器学习。
下面我将分别介绍这四个项目的具体内容和过程。
1. 手写数字识别:手写数字识别是模式识别领域的一个经典项目。
我们使用了MNIST数据集,这是一个包含大量手写数字图片的数据集。
首先,我们对数据集进行预处理,包括归一化、数据清洗等。
然后,我们采用卷积神经网络(CNN)作为模型进行训练,并使用交叉验证法对模型进行评估。
最终,我们得到了一个识别准确率较高的模型。
2. 图像分类:图像分类是模式识别领域的另一个重要应用。
我们选择了CIFAR-10数据集,这是一个包含大量彩色图像的数据集。
与手写数字识别项目类似,我们先对数据集进行预处理,然后采用CNN进行训练。
在模型训练过程中,我们尝试了不同的优化算法和网络结构,以提高模型的性能。
最终,我们得到了一个识别准确率较高的模型。
3. 语音识别:语音识别是模式识别领域的又一项挑战。
我们使用了TIMIT数据集,这是一个包含大量语音样本的数据集。
首先,我们对语音样本进行预处理,包括特征提取、去噪等。
然后,我们采用循环神经网络(RNN)作为模型进行训练。
在模型训练过程中,我们尝试了不同的优化算法和网络结构。
最后,我们通过对模型进行评估,得到了一个较为可靠的语音识别系统。
4. 机器学习:机器学习是模式识别领域的基础。
我们使用了UCI数据集,这是一个包含多个数据集的数据集。
实验七基于神经网络的模式识别实验

实验七基于神经网络的模式识别实验
一、实验背景
模式识别是机器学习领域中的一项重要研究领域,它可以被应用于多个领域,包括计算机视觉,图像处理,智能交通,自然语言处理和生物信息学等。
模式识别的目的是从观察到的数据中检测,理解和预测结果。
其中,神经网络(应用模式识别)是人工智能的关键部分,它模拟人类的神经元的工作方式,并且可以被用来识别,分类,计算和获取模式。
二、实验目标
本次实验的目的是,探讨神经网络在模式识别中的应用,并使用一个基于神经网络的模式识别系统来识别模式。
三、实验内容
(一)数据预处理
在进行本次实验之前,需要进行数据预处理,以便能够更好地使用神经网络。
数据预处理的目的是通过将原始数据处理成神经网络可以处理的格式,以便更好地提取特征。
(二)神经网络模型设计
(三)神经网络模型训练
在训练神经网络模型时,首先需要准备一组被识别的模式。
模式识别实验
模式识别实验
一、实验任务
本次实验任务是模式识别,主要包括形式化的目标追踪、字符流分类和语音识别等。
二、所需软件
本实验所需软件包括MATLAB、Python等。
三、实验步骤
1. 首先需要安装MATLAB 和Python等软件,并建立实验环境。
2. 然后,通过MATLAB 进行基于向量量化(VQ) 的目标追踪实验,搭建端到端的系统,并使用Matlab编程实现实验内容。
3. 接着,使用Python进行字符流分类的实验,主要包括特征提取、建模和识别等,并使用Python编程实现实验内容。
4. 最后,使用MATLAB 进行语音识别的实验,主要是使用向量量化方法识别语音,并使用Matlab编程实现实验内容。
四、结果分析
1.在基于向量量化的目标追踪实验中,我们通过计算误差,确定了最优参数,最终获得了较高的准确率。
2.在字符流分类实验中,我们通过选择最佳分类器,得到了较高的准确率。
3.在语音识别实验中,我们使用向量量化方法,最终也获得了不错的准确率。
五、总结
本次实验研究了基于向量量化的目标追踪、字符流分类和语音识别等三项模式识别技术,经实验,探讨了不同方法之间的优劣,并获得了较高的准确率。
本次实验的结果为日常模式识别工作提供了有价值的参考。
模式识别实验报告
模式识别实验报告关键信息项:1、实验目的2、实验方法3、实验数据4、实验结果5、结果分析6、误差分析7、改进措施8、结论1、实验目的11 阐述进行模式识别实验的总体目标和期望达成的结果。
111 明确实验旨在解决的具体问题或挑战。
112 说明实验对于相关领域研究或实际应用的意义。
2、实验方法21 描述所采用的模式识别算法和技术。
211 解释选择这些方法的原因和依据。
212 详细说明实验的设计和流程,包括数据采集、预处理、特征提取、模型训练和测试等环节。
3、实验数据31 介绍实验所使用的数据来源和类型。
311 说明数据的规模和特征。
312 阐述对数据进行的预处理操作,如清洗、归一化等。
4、实验结果41 呈现实验得到的主要结果,包括准确率、召回率、F1 值等性能指标。
411 展示模型在不同数据集或测试条件下的表现。
412 提供可视化的结果,如图表、图像等,以便更直观地理解实验效果。
5、结果分析51 对实验结果进行深入分析和讨论。
511 比较不同实验条件下的结果差异,并解释其原因。
512 分析模型的优点和局限性,探讨可能的改进方向。
6、误差分析61 研究实验中出现的误差和错误分类情况。
611 分析误差产生的原因,如数据噪声、特征不充分、模型复杂度不足等。
612 提出减少误差的方法和建议。
7、改进措施71 根据实验结果和分析,提出针对模型和实验方法的改进措施。
711 描述如何优化特征提取、调整模型参数、增加训练数据等。
712 预测改进后的可能效果和潜在影响。
8、结论81 总结实验的主要发现和成果。
811 强调实验对于模式识别领域的贡献和价值。
812 对未来的研究方向和进一步工作提出展望。
在整个实验报告协议中,应确保各项内容的准确性、完整性和逻辑性,以便为模式识别研究提供有价值的参考和借鉴。
模式识别学习报告(团队)
模式识别学习报告(团队)
简介
本报告是我们团队就模式识别研究所做的总结和讨论。
模式识别是一门关于如何从已知数据中提取信息并作出决策的学科。
在研究过程中,我们通过研究各种算法和技术,了解到模式识别在人工智能、机器研究等领域中的重要性并进行实践操作。
研究过程
在研究过程中,我们首先了解了模式识别的基本概念和算法,如KNN算法、朴素贝叶斯算法、决策树等。
然后我们深入研究了SVM算法和神经网络算法,掌握了它们的实现和应用场景。
在实践中,我们使用了Python编程语言和机器研究相关的第三方库,比如Scikit-learn等。
研究收获
通过研究,我们深刻认识到模式识别在人工智能、机器研究领域中的重要性,了解到各种算法和技术的应用场景和优缺点。
同时我们也发现,在实践中,数据的质量决定了模型的好坏,因此我们需要花费更多的时间来处理数据方面的问题。
团队讨论
在研究中,我们也进行了很多的团队讨论和交流。
一方面,我们优化了研究方式和效率,让研究更加有效率;另一方面我们还就机器研究的基本概念和算法的前沿发展进行了讨论,并提出了一些有趣的问题和方向。
总结
通过学习和团队讨论,我们深刻认识到了模式识别在人工智能和机器学习领域中的核心地位,并获得了实践经验和丰富的团队协作经验。
我们相信这些学习收获和经验会在今后的学习和工作中得到很好的应用。
模式识别实验报告
实验一Bayes 分类器设计本实验旨在让同学对模式识别有一个初步的理解,能够根据自己的设计对贝叶斯决策理论算法有一个深刻地认识,理解二类分类器的设计原理。
1实验原理最小风险贝叶斯决策可按下列步骤进行:(1)在已知)(i P ω,)(i X P ω,i=1,…,c 及给出待识别的X 的情况下,根据贝叶斯公式计算出后验概率: ∑==cj iii i i P X P P X P X P 1)()()()()(ωωωωω j=1,…,x(2)利用计算出的后验概率及决策表,按下面的公式计算出采取i a ,i=1,…,a 的条件风险∑==cj j jii X P a X a R 1)(),()(ωωλ,i=1,2,…,a(3)对(2)中得到的a 个条件风险值)(X a R i ,i=1,…,a 进行比较,找出使其条件风险最小的决策k a ,即则k a 就是最小风险贝叶斯决策。
2实验内容假定某个局部区域细胞识别中正常(1ω)和非正常(2ω)两类先验概率分别为 正常状态:P (1ω)=0.9; 异常状态:P (2ω)=0.1。
现有一系列待观察的细胞,其观察值为x :-3.9847 -3.5549 -1.2401 -0.9780 -0.7932 -2.8531 -2.7605 -3.7287 -3.5414 -2.2692 -3.4549 -3.0752 -3.9934 2.8792 -0.9780 0.7932 1.1882 3.0682 -1.5799 -1.4885 -0.7431 -0.4221 -1.1186 4.2532 已知类条件概率密度曲线如下图:)|(1ωx p )|(2ωx p 类条件概率分布正态分布分别为(-2,0.25)(2,4)试对观察的结果进行分类。
3 实验要求1) 用matlab 完成分类器的设计,要求程序相应语句有说明文字。
2) 根据例子画出后验概率的分布曲线以及分类的结果示意图。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
模式识别实验报告————————————————————————————————作者:————————————————————————————————日期:实验报告实验课程名称:模式识别姓名:王宇班级: 20110813 学号: 2011081325实验名称规范程度原理叙述实验过程实验结果实验成绩图像的贝叶斯分类K均值聚类算法神经网络模式识别平均成绩折合成绩注:1、每个实验中各项成绩按照5分制评定,实验成绩为各项总和2、平均成绩取各项实验平均成绩3、折合成绩按照教学大纲要求的百分比进行折合2014年 6月实验一、 图像的贝叶斯分类一、实验目的将模式识别方法与图像处理技术相结合,掌握利用最小错分概率贝叶斯分类器进行图像分类的基本方法,通过实验加深对基本概念的理解。
二、实验仪器设备及软件 HP D538、MATLAB 三、实验原理 概念:阈值化分割算法是计算机视觉中的常用算法,对灰度图象的阈值分割就是先确定一个处于图像灰度取值范围内的灰度阈值,然后将图像中每个像素的灰度值与这个阈值相比较。
并根据比较的结果将对应的像素划分为两类,灰度值大于阈值的像素划分为一类,小于阈值的划分为另一类,等于阈值的可任意划分到两类中的任何一类。
最常用的模型可描述如下:假设图像由具有单峰灰度分布的目标和背景组成,处于目标和背景内部相邻像素间的灰度值是高度相关的,但处于目标和背景交界处两边的像素灰度值有较大差别,此时,图像的灰度直方图基本上可看作是由分别对应于目标和背景的两个单峰直方图混合构成。
而且这两个分布应大小接近,且均值足够远,方差足够小,这种情况下直方图呈现较明显的双峰。
类似地,如果图像中包含多个单峰灰度目标,则直方图可能呈现较明显的多峰。
上述图像模型只是理想情况,有时图像中目标和背景的灰度值有部分交错。
这时如用全局阈值进行分割必然会产生一定的误差。
分割误差包括将目标分为背景和将背景分为目标两大类。
实际应用中应尽量减小错误分割的概率,常用的一种方法为选取最优阈值。
这里所谓的最优阈值,就是指能使误分割概率最小的分割阈值。
图像的直方图可以看成是对灰度值概率分布密度函数的一种近似。
如一幅图像中只包含目标和背景两类灰度区域,那么直方图所代表的灰度值概率密度函数可以表示为目标和背景两类灰度值概率密度函数的加权和。
如果概率密度函数形式已知,就有可能计算出使目标和背景两类误分割概率最小的最优阈值。
假设目标与背景两类像素值均服从正态分布且混有加性高斯噪声,上述分类问题可以使用模式识别中的最小错分概率贝叶斯分类器来解决。
以1p 与2p 分别表示目标与背景的灰度分布概率密度函数,1P 与2P 分别表示两类的先验概率,则图像的混合概率密度函数可用下式表示为1122()()()p x P p x P p x =+式中1p 和2p 分别为2121()2111()2x p x e μσπσ--=2222()2221()2x p x eμσπσ--=121P P +=1σ、2σ是针对背景和目标两类区域灰度均值1μ与2μ的标准差。
若假定目标的灰度较亮,其灰度均值为2μ,背景的灰度较暗,其灰度均值为1μ,因此有12μμ<现若规定一门限值T 对图像进行分割,势必会产生将目标划分为背景和将背景划分为目标这两类错误。
通过适当选择阈值T ,可令这两类错误概率为最小,则该阈值T 即为最佳阈值。
把目标错分为背景的概率可表示为12()()TE T p x dx -∞=⎰把背景错分为目标的概率可表示为21()()TE T p x dx +∞=⎰总的误差概率为2112()()()E T P E T PE T =+为求得使误差概率最小的阈值T ,可将()E T 对T 求导并令导数为零,可得1122()()P p T P p T =代换后,可得221212222111()()ln 22P T T P σμμσσσ---=-此时,若设12σσσ==,则有2122121ln 2P T P μμσμμ⎛⎫+=+ ⎪-⎝⎭若还有12P P =的条件,则122T μμ+=这时的最优阈值就是两类区域灰度均值1μ与2μ的平均值。
上面的推导是针对图像灰度值服从正态分布时的情况,如果灰度值服从其它分布,依理也可求出最优阈值来。
一般情况下,在不清楚灰度值分布时,通常可假定灰度值服从正态分布。
在实际使用最优阈值进行分割的过程中,需要利用迭代算法来求得最优阈值。
设有一幅数字图像(,)f x y ,混有加性高斯噪声,可表示为(,)(,)(,)g x y f x y n x y =+此处假设图像上各点的噪声相互独立,且具有零均值,如果通过阈值分割将图像分为目标与背景两部分,则每一部分仍然有噪声点随机作用于其上,于是,目标1(,)g x y 和2(,)g x y 可表示为11(,)(,)(,)g x y f x y n x y =+ 22(,)(,)(,)g x y f x y n x y =+迭代过程中,会多次地对1(,)g x y 和2(,)g x y 求均值,则111{(,)}{(,)(,)}{(,)}E g x y E f x y n x y E f x y =+= 222{(,)}{(,)(,)}{(,)}E g x y E f x y n x y E f x y =+=可见,随着迭代次数的增加,目标和背景的平均灰度都趋向于真实值。
因此,用迭代算法求得的最佳阈值不受噪声干扰的影响。
四、实验步骤及程序 1、实验步骤(1)确定一个初始阈值0T ,0T 可取为min max02S S T +=式中,min S 和max S 为图像灰度的最小值和最大值。
(2)利用第k 次迭代得到的阈值将图像分为目标1R 和背景2R 两大区域,其中1{(,)|(,)}k R f x y f x y T =≥ 2{(,)|0(,)}k R f x y f x y T =<<(3)计算区域1R 和2R 的灰度均值1S 和2S 。
(4)计算新的阈值1k T +,其中1212k S S T ++=(5)如果1||k k T T +-小于允许的误差,则结束,否则1k k =+,转步骤(2)。
2、实验源程序I=imread('1.jpg'); Im=rgb2gray(I);subplot(121),imhist(Im);title('Ö±·½Í¼') ZMax=max(max(I)); ZMin=min(min(I)); TK=(ZMax+ZMin)/2; bCal=1; iSize=size(I); while (bCal) iForeground=0; iBackground=0; ForegroundSum=0; BackgroundSum=0; for i=1:iSize(1) for j=1:iSize(2) tmp=I(i,j); if (tmp>=TK)iForeground=iForeground+1;ForegroundSum=ForegroundSum+double(tmp); elseiBackground=iBackground+1;BackgroundSum=BackgroundSum+double(tmp); end end endZO=ForegroundSum/iForeground; ZB=BackgroundSum/iBackground; TKTmp=double((ZO+ZB)/2); if (TKTmp==TK) bCal=0; elseTK=TKTmp; end enddisp(strcat('µü´úºóµÄãÐÖµ£º',num2str(TK))); newI=im2bw(I,double(TK)/255); subplot(121),imshow(I) title('Ô-ͼÏñ')subplot(122),imshow(newI) title('·Ö¸îºóµÄͼÏñ')五、实验结果与分析 1、实验结果20040060080010001200直方图100200原图像图1 原图像以及其灰度直方图原图像分割后的图像图2 原图像以及分割后图像2、实验结果分析迭代后的阈值:94.8064实验中将大于阈值的部分设置为目标,小于阈值的部分设置为背景,分割结果大体上满足要求。
实际过程中在利用迭代法求得最优阈值后,仍需进行一些人工调整才能将此阈值用于实验图像的分割,虽然这种方法利用了图像中所有像素点的信息,但当光照不均匀时,图像中部分区域的灰度值可能差距较大,造成计算出的最优阈值分割效果不理想。
具体的改进措施分为以下两方面:一方面,在选取图片时,该图片的两个独立的峰值不够明显,因此在分割后产生误差,应改进选择的图片的背景和物体的对比度,使得分割的效果更好;另一方面,实验程序中未涉及计算最优阈值时的迭代次数,无法直观的检测,应在实验程序中加入此项,便于分析。
实验二、K 均值聚类算法一、实验目的将模式识别方法与图像处理技术相结合,掌握利用K 均值聚类算法进行图像分类的基本方法,通过实验加深对基本概念的理解。
二、实验仪器设备及软件 HP D538、MATLAB 、WIT 三、实验原理K 均值聚类法分为三个步骤: 初始化聚类中心1、根据具体问题,凭经验从样本集中选出C 个比较合适的样本作为初始聚类中心。
2、用前C 个样本作为初始聚类中心。
3、将全部样本随机地分成C 类,计算每类的样本均值,将样本均值作为初始聚类中心。
初始聚类1、按就近原则将样本归入各聚类中心所代表的类中。
2、取一样本,将其归入与其最近的聚类中心的那一类中,重新计算样本均值,更新聚类中心。
然后取下一样本,重复操作,直至所有样本归入相应类中。
判断聚类是否合理1、采用误差平方和准则函数判断聚类是否合理,不合理则修改分类。
循环进行判断、修改直至达到算法终止条件。
2、聚类准则函数误差平方和准则函数(最小平方差划分)∑∑=Γ∈-=ci x i im x J 12e∑Γ∈=ix ii x N m 13、单样本改进:每调整一个样本的类别就重新计算一次聚类的中心(){(){}22min 1k m x k m x d l j li j ji -=-=i=1,2,...c 只调整一个样本四、实验步骤及程序 1、实验步骤理解K 均值算法基本原理,编写程序实现对自选图像的分类,并将所得结果与WIT 处理结果进行对比。