数据挖掘复习题和答案
《数据挖掘》试题与答案

一、解答题(满分30分,每小题5分)1. 怎样理解数据挖掘和知识发现的关系?请详细阐述之首先从数据源中抽取感兴趣的数据,并把它组织成适合挖掘的数据组织形式;然后,调用相应的算法生成所需的知识;最后对生成的知识模式进行评估,并把有价值的知识集成到企业的智能系统中。
知识发现是一个指出数据中有效、崭新、潜在的、有价值的、一个不可忽视的流程,其最终目标是掌握数据的模式。
流程步骤:先理解要应用的领域、熟悉相关知识,接着建立目标数据集,并专注所选择的数据子集;再作数据预处理,剔除错误或不一致的数据;然后进行数据简化与转换工作;再通过数据挖掘的技术程序成为模式、做回归分析或找出分类模型;最后经过解释和评价成为有用的信息。
2. 时间序列数据挖掘的方法有哪些,请详细阐述之时间序列数据挖掘的方法有:1)、确定性时间序列预测方法:对于平稳变化特征的时间序列来说,假设未来行为与现在的行为有关,利用属性现在的值预测将来的值是可行的。
例如,要预测下周某种商品的销售额,可以用最近一段时间的实际销售量来建立预测模型。
2)、随机时间序列预测方法:通过建立随机模型,对随机时间序列进行分析,可以预测未来值。
若时间序列是平稳的,可以用自回归(Auto Regressive,简称AR)模型、移动回归模型(Moving Average,简称MA)或自回归移动平均(Auto Regressive Moving Average,简称ARMA)模型进行分析预测。
3)、其他方法:可用于时间序列预测的方法很多,其中比较成功的是神经网络。
由于大量的时间序列是非平稳的,因此特征参数和数据分布随着时间的推移而变化。
假如通过对某段历史数据的训练,通过数学统计模型估计神经网络的各层权重参数初值,就可能建立神经网络预测模型,用于时间序列的预测。
3. 数据挖掘的分类方法有哪些,请详细阐述之分类方法归结为四种类型:1)、基于距离的分类方法:距离的计算方法有多种,最常用的是通过计算每个类的中心来完成,在实际的计算中往往用距离来表征,距离越近,相似性越大,距离越远,相似性越小。
数据挖掘-题库带答案

数据挖掘-题库带答案1、最早提出“大数据”时代到来的是全球知名咨询公司麦肯锡()答案:正确2、决策将日益基于数据和分析而作出,而并非基于经验和直觉()答案:错误解析:决策将日益基于数据和分析而作出,而并非基于经验和直觉3、2011年被许多国外媒体和专家称为“大数据元年”()答案:错误解析:2013年被许多国外媒体和专家称为“大数据元年”4、我国网民数量居世界之首,每天产生的数据量也位于世界前列()答案:正确5、商务智能的联机分析处理工具依赖于数据库和数据挖掘。
()答案:错误解析:商务智能的联机分析处理工具依赖于数据仓库和多维数据挖掘。
6、数据整合、处理、校验在目前已经统称为 EL()答案:错误解析:数据整合、处理、校验在目前已经统称为 ETL7、大数据时代的主要特征()A、数据量大B、类型繁多C、价值密度低D、速度快时效高答案: ABCD8、下列哪项不是大数据时代的热门技术()A、数据整合B、数据预处理C、数据可视化D、 SQL答案: D9、()是一种统计或数据挖掘解决方案,包含可在结构化和非结构化数据中使用以确定未来结果的算法和技术。
A、预测B、分析C、预测分析D、分析预测答案: C10、大数据发展的前提?答案:解析:硬件成本的降低,网络带宽的提升,云计算的兴起,网络技术的发展,智能终端的普及,电子商务、社交网络、电子地图等的全面应用,物联网的兴起11、调研、分析大数据发展的现状与应用领域。
?答案:解析:略12、大数据时代的主要特征?答案:解析:数据量大(Volume)第一个特征是数据量大。
大数据的起始计量单位至少是P(1000个T)、E(100万个T)或Z(10亿个T)。
类型繁多(Variety)第二个特征是数据类型繁多。
包括网络日志、音频、视频、图片、地理位置信息等等,多类型的数据对数据的处理能力提出了更高的要求。
价值密度低(Value)第三个特征是数据价值密度相对较低。
如随着物联网的广泛应用,信息感知无处不在,信息海量,但价值密度较低,如何通过强大的机器算法更迅速地完成数据的价值“提纯”,是大数据时代亟待解决的难题。
数据挖掘考试题及答案

数据挖掘考试题及答案### 数据挖掘考试题及答案#### 一、选择题(每题2分,共20分)1. 数据挖掘的目的是发现数据中的:- A. 错误- B. 模式- C. 异常- D. 趋势答案:B2. 以下哪项不是数据挖掘的常用算法:- A. 决策树- B. 聚类分析- C. 线性回归- D. 神经网络答案:C3. 关联规则挖掘中,Apriori算法用于发现:- A. 频繁项集- B. 异常值- C. 趋势- D. 聚类答案:A4. K-means算法是一种:- A. 分类算法- B. 聚类算法- C. 预测算法- D. 关联规则挖掘算法答案:B5. 以下哪个指标用于评估分类模型的性能:- A. 准确率- B. 召回率- C. F1分数- D. 所有以上答案:D#### 二、简答题(每题10分,共30分)1. 描述数据挖掘中的“过拟合”现象,并给出避免过拟合的策略。
答案:过拟合是指模型对训练数据拟合得过于完美,以至于失去了泛化能力。
避免过拟合的策略包括:使用交叉验证、正则化技术、减少模型复杂度、获取更多的训练数据等。
2. 解释什么是“数据清洗”以及它在数据挖掘中的重要性。
答案:数据清洗是指从原始数据中识别并纠正(或删除)错误、重复或不完整的数据的过程。
它在数据挖掘中至关重要,因为脏数据会导致分析结果不准确,影响最终的决策。
3. 描述“特征选择”在数据挖掘中的作用。
答案:特征选择是数据挖掘中用来降低数据维度、提高模型性能和减少计算成本的过程。
通过选择最有信息量的特征,可以去除冗余或无关的特征,从而提高模型的准确性和效率。
#### 三、应用题(每题25分,共50分)1. 假设你正在分析一个电子商务网站的用户购买行为,描述你将如何使用数据挖掘技术来识别潜在的营销机会。
答案:首先,我会使用聚类分析来识别不同的用户群体。
然后,通过关联规则挖掘来发现不同用户群体的购买模式。
接着,利用分类算法来预测用户可能感兴趣的产品。
大数据分析与挖掘复习 题集附答案

大数据分析与挖掘复习题集附答案大数据分析与挖掘复习题集附答案一、选择题1. 数据挖掘的主要任务是:A. 模式发现和模型评估B. 数据收集和整理C. 数据分析和可视化D. 数据传输和存储答案:A2. 在数据挖掘过程中,数据预处理的目的是:A. 提取有价值的信息B. 去除异常值和噪声C. 构建合适的模型D. 优化数据存储结构答案:B3. 关联规则挖掘是指:A. 发现不同属性之间的关联关系B. 预测未来事件的发生C. 分析数据的变化趋势D. 构建数据的分类模型答案:A4. 在数据挖掘中,分类和聚类的主要区别在于:A. 数据来源的不同B. 目标的不同C. 算法的不同D. 结果的不同答案:B5. 大数据分析的核心挑战是:A. 数据存储和处理速度B. 数据质量和准确性C. 数据安全和隐私保护D. 数据可视化和展示答案:A二、填空题1. __________是指通过对海量数据进行深入分析和挖掘,从中发现有价值的信息。
答案:大数据分析与挖掘2. 在数据挖掘过程中,将数据按照一定的规则进行重新排列,以便更方便地进行分析和挖掘,这个过程称为__________。
答案:数据预处理3. 数据挖掘中的分类算法主要是通过对已有的样本进行学习和训练,从而预测新的样本所属的__________。
答案:类别4. 聚类算法是将相似的数据样本归为一类,不需要事先知道数据的__________。
答案:类别5. 在大数据分析中,数据的__________对于结果的准确性和可靠性至关重要。
答案:质量三、简答题1. 请简要说明大数据分析与挖掘的步骤和流程。
答:大数据分析与挖掘的步骤主要包括数据收集与清洗、数据预处理、模式发现、模型评估和应用。
首先,需要从各个数据源收集所需数据,并对数据进行清洗,去除异常值和噪声。
然后,通过数据预处理,对数据进行规范化、离散化等处理,以便于后续的分析和挖掘。
接着,利用合适的算法和技术,进行模式发现,例如关联规则挖掘、分类和聚类等。
历年数据挖掘期末考试试题及答案

历年数据挖掘期末考试试题及答案2019年春选择题1. 关于数据挖掘下列叙述中,正确的是:- A. 数据挖掘只是寻找数据中的有用信息- B. 数据挖掘就是将数据放置于数据仓库中,方便查询- C. 数据挖掘是指从大量有噪音数据中提取未知、隐含、先前未知的、重要的、可理解的模式或知识- D. 数据挖掘就是从数据中提取出数值型变量2. 下列关于聚类分析的说法中,正确的是:- A. 聚类分析是无监督研究- B. 聚类分析的目的是找到一组最优特征- C. 聚类分析只能用于数值型变量- D. 聚类分析是一种监督研究方法3. 一般的数据挖掘流程包括以下哪些步骤:- A. 数据采集- B. 数据清洗- C. 数据转换- D. 模型构建- E. 模型评价- F. 模型应用- G. A、B、C、D、E- H. A、B、C、D、E、F- I. B、C、D、E、F- J. C、D、E、F简答题1. 什么是数据挖掘?介绍一下数据挖掘的流程。
数据挖掘是从庞大、复杂的数据集中提取有价值的、对决策有帮助的信息。
包括数据采集、数据清洗、数据转换、模型构建、模型评价和模型应用等步骤。
2. 聚类分析和分类分析有什么不同?聚类分析和分类分析都是数据挖掘的方法,不同的是聚类分析是无监督研究,通过相似度,将数据集分为不同的组;分类分析是监督研究,通过已知的训练集数据来预测新的数据分类。
也就是说在分类中有“标签”这个中间过程。
3. 请介绍一个你知道的数据挖掘算法,并简单阐述它的流程。
Apriori算法:是一种用于关联规则挖掘的算法。
主要流程包括生成项集、计算支持度、生成候选规则以及计算可信度四步。
首先生成单个项集,计算各项集在数据集中的支持度;然后根据单个项集生成项集对,计算各项集对在数据集中的支持度;接着从项集对中找出支持度大于某个阈值的,生成候选规则;最后计算规则的置信度,保留置信度大于某个阈值的规则作为关联规则。
数据挖掘原理与应用---试题及答案试卷十二答案精选全文完整版

数据挖掘原理与应用 试题及答案试卷一、(30分,总共30题,每题答对得1分,答错得0分)单选题1、在ID3算法中信息增益是指( D )A、信息的溢出程度B、信息的增加效益C、熵增加的程度最大D、熵减少的程度最大2、下面哪种情况不会影响K-means聚类的效果?( B )A、数据点密度分布不均B、数据点呈圆形状分布C、数据中有异常点存在D、数据点呈非凸形状分布3、下列哪个不是数据对象的别名 ( C )A、样品B、实例C、维度D、元组4、人从出生到长大的过程中,是如何认识事物的? ( D )A、聚类过程B、分类过程C、先分类,后聚类D、先聚类,后分类5、决策树模型中应如何妥善处理连续型属性:( C )A、直接忽略B、利用固定阈值进行离散化C、根据信息增益选择阈值进行离散化D、随机选择数据标签发生变化的位置进行离散化6、假定用于分析的数据包含属性age。
数据元组中age的值如下(按递增序):13,15,16,16,19,20,20,21,22,22,25,25,25,30,33,33,35,35,36,40,45,46,52,70。
问题:使用按箱平均值平滑方法对上述数据进行平滑,箱的深度为3。
第二个箱子值为:( A )A、18.3B、22.6C、26.8D、27.97、建立一个模型,通过这个模型根据已知的变量值来预测其他某个变量值属于数据挖掘的哪一类任务?( C )A、根据内容检索B、建模描述C、预测建模D、寻找模式和规则8、如果现在需要对一组数据进行样本个体或指标变量按其具有的特性进行分类,寻找合理的度量事物相似性的统计量,应该采取( A )A、聚类分析B、回归分析C、相关分析D、判别分析9、时间序列数据更适合用( A )做数据规约。
A、小波变换B、主成分分析C、决策树D、直方图10、下面哪些场景合适使用PCA?( A )A、降低数据的维度,节约内存和存储空间B、降低数据维度,并作为其它有监督学习的输入C、获得更多的特征D、替代线性回归11、数字图像处理中常使用主成分分析(PCA)来对数据进行降维,下列关于PCA算法错误的是:( C )A、PCA算法是用较少数量的特征对样本进行描述以达到降低特征空间维数的方法;B、PCA本质是KL-变换;C、PCA是最小绝对值误差意义下的最优正交变换;D、PCA算法通过对协方差矩阵做特征分解获得最优投影子空间,来消除模式特征之间的相关性、突出差异性;12、将原始数据进行集成、变换、维度规约、数值规约是在以下哪个步骤的任务?( C )A、频繁模式挖掘B、分类和预测C、数据预处理D、数据流挖掘13、假设使用维数降低作为预处理技术,使用PCA将数据减少到k维度。
数据挖掘考试题库及答案

数据挖掘考试题库及答案一、选择题1. 数据挖掘是从大量数据中提取有价值信息的过程,以下哪项不是数据挖掘的主要任务?A. 预测B. 分类C. 聚类D. 数据可视化答案:D2. 以下哪种技术不属于数据挖掘的常用方法?A. 决策树B. 支持向量机C. 关联规则D. 数据仓库答案:D3. 数据挖掘中,以下哪项技术常用于分类和预测?A. 神经网络B. K-均值聚类C. 主成分分析D. 决策树答案:D4. 在数据挖掘中,以下哪个概念表示数据集中的属性?A. 数据项B. 数据记录C. 数据属性D. 数据集答案:C5. 数据挖掘中,以下哪个算法用于求解关联规则?A. Apriori算法B. ID3算法C. K-Means算法D. C4.5算法答案:A二、填空题6. 数据挖掘的目的是从大量数据中提取______信息。
答案:有价值7. 在数据挖掘中,分类任务分为有监督学习和______学习。
答案:无监督8. 决策树是一种用于分类和预测的树形结构,其核心思想是______。
答案:递归划分9. 关联规则挖掘中,支持度表示某个项集在数据集中的出现频率,置信度表示______。
答案:包含项集的记录中同时包含结论的记录的比例10. 数据挖掘中,聚类分析是将数据集划分为若干个______的子集。
答案:相似三、判断题11. 数据挖掘只关注大量数据中的异常值。
()答案:错误12. 数据挖掘是数据仓库的一部分。
()答案:正确13. 决策树算法适用于处理连续属性的分类问题。
()答案:错误14. 数据挖掘中的聚类分析是无监督学习任务。
()答案:正确15. 关联规则挖掘中,支持度越高,关联规则越可靠。
()答案:错误四、简答题16. 简述数据挖掘的主要任务。
答案:数据挖掘的主要任务包括预测、分类、聚类、关联规则挖掘、异常检测等。
17. 简述决策树算法的基本原理。
答案:决策树算法是一种自顶向下的递归划分方法。
它通过选择具有最高信息增益的属性进行划分,将数据集划分为若干个子集,直到满足停止条件。
数据挖掘汇总(题库含答案)
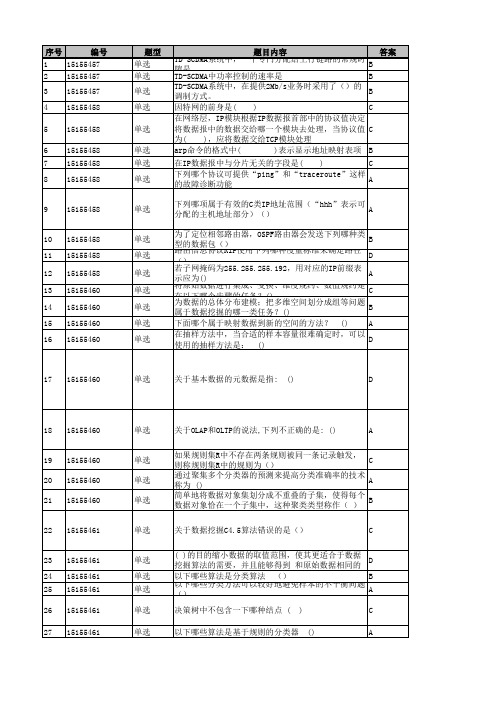
单选
单选 单选 单选
单选
单选 单选 单选 单选 单选
关于OLAP和OLTP的说法,下列不正确的是: ()
A
如果规则集R中不存在两条规则被同一条记录触发, 则称规则集R中的规则为()
C
通过聚集多个分类器的预测来提高分类准确率的技术 称为 ()
A
简单地将数据对象集划分成不重叠的子集,使得每个 数据对象恰在一个子集中,这种聚类类型称作( )
在抽样方法中,当合适的样本容量很难确定时,可以 使用的抽样方法是: ()
D
17 15155460
单选
关于基本数据的元数据是指: ()
D
18 15155460
19 15155460 20 15155460 21 15155460
22 15155461
23 15155461 24 15155461 25 15155461 26 15155461 27 15155461
多选
关于TCP协议,描述正确的是哪些?
A;C
多选
多选 多选 多选 多选
下面SNMP协议,下面哪两个表述是正确的?
A;D
TD-SCDMA系统中功率控制步长可为
A;B;C
通过数据挖掘过程所推倒出的关系和摘要经常被称 为:()
A;B
以下哪些学科和数据挖掘有密切联系?()
A;D
在聚类分析当中,( 簇。
)等技术可以处理任意形状的 A;D
)的时候,
A
BIRCH是一种( )
B
下面列出的条目中,哪些是数据仓库的基本特征: A;C;D
下面哪些属于可视化高维数据技术 ()
A;B;C;E
对于OSPF协议,你认为哪些是正确的?
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
一、考虑表中二元分类问题的训练样本集
1.整个训练样本集关于类属性的熵是多少?
2.关于这些训练集中a1,a2的信息增益是多少?
3.对于连续属性a3,计算所有可能的划分的信息增益。
4.根据信息增益,a1,a2,a3哪个是最佳划分?
5.根据分类错误率,a1,a2哪具最佳?
6.根据gini指标,a1,a2哪个最佳?
答1.
P(+) = 4/9 and P(−) = 5/9
−4/9 log2(4/9) −5/9 log2(5/9) = 0.9911.
答2:
(估计不考)
答3:
答4: According to information gain, a1 produces the best split.
答5:
For attribute a1: error rate = 2/9.
For attribute a2: error rate = 4/9.
Therefore, according to error rate, a1 produces the best split.
答6:
二、考虑如下二元分类问题的数据集
1.计算a.b信息增益,决策树归纳算法会选用哪个属性
2.计算a.b gini指标,决策树归纳会用哪个属性?
这个答案没问题
3.从图4-13可以看出熵和gini指标在[0,0.5]都是单调递增,而[0.5,1]之间单调递减。
有没有可能信息增益和
gini指标增益支持不同的属性?解释你的理由
Yes, even though these measures have similar range and monotonous
behavior, their respective gains, Δ, which are scaled differences of the
measures, do not necessarily behave in the same way, as illustrated by
the results in parts (a) and (b).
贝叶斯分类
1.P(A = 1|−) = 2/5 = 0.4, P(B = 1|−) = 2/5 = 0.4,
P(C = 1|−) = 1, P(A = 0|−) = 3/5 = 0.6,
P(B = 0|−) = 3/5 = 0.6, P(C = 0|−) = 0; P(A = 1|+) = 3/5 = 0.6, P(B = 1|+) = 1/5 = 0.2, P(C = 1|+) = 2/5 = 0.4,
P(A = 0|+) = 2/5 = 0.4, P(B = 0|+) = 4/5 = 0.8,
P(C = 0|+) = 3/5 = 0.6.
2.
3.P(A = 0|+) = (2 + 2)/(5 + 4) = 4/9,
P(A = 0|−) = (3+2)/(5 + 4) = 5/9,
P(B = 1|+) = (1 + 2)/(5 + 4) = 3/9,
P(B = 1|−) = (2+2)/(5 + 4) = 4/9,
P(C = 0|+) = (3 + 2)/(5 + 4) = 5/9,
P(C = 0|−) = (0+2)/(5 + 4) = 2/9.
4.Let P(A = 0,B = 1, C = 0) = K
5.当的条件概率之一是零,则估计为使用m-估计概率的方法的条件概率是更好的,因为我们不希望整个表达
式变为零。
1.P(A = 1|+) = 0.6, P(B = 1|+) = 0.4, P(C = 1|+) = 0.8, P(A =
1|−) = 0.4, P(B = 1|−) = 0.4, and P(C = 1|−) = 0.2
2.
Let R : (A = 1,B = 1, C = 1) be the test record. To determine its
class, we need to compute P(+|R) and P(−|R). Using Bayes theorem, P(+|R) = P(R|+)P(+)/P(R) and P(−|R) = P(R|−)P(−)/P(R).
Since P(+) = P(−) = 0.5 and P(R) is constant, R can be classified by
comparing P(+|R) and P(−|R).
For this question,
P(R|+) = P(A = 1|+) × P(B = 1|+) × P(C = 1|+) = 0.192
P(R|−) = P(A = 1|−) × P(B = 1|−) × P(C = 1|−) = 0.032
Since P(R|+) is larger, the record is assigned to (+) class.
3.
P(A = 1) = 0.5, P(B = 1) = 0.4 and P(A = 1,B = 1) = P(A) ×
P(B) = 0.2. Therefore, A and B are independent.
4.
P(A = 1) = 0.5, P(B = 0) = 0.6, and P(A = 1,B = 0) = P(A =1)× P(B = 0) = 0.3. A and B are still independent.
5.
Compare P(A = 1,B = 1|+) = 0.2 against P(A = 1|+) = 0.6 and
P(B = 1|Class = +) = 0.4. Since the product between P(A = 1|+)
and P(A = 1|−) are not the same as P(A = 1,B = 1|+), A and B are
not conditionally independent given the class.
三、使用下表中的相似度矩阵进行单链和全链层次聚类。
绘制树状况显示结果,树状图应该清楚地显示合并的次序。
There are no apparent relationships between s1, s2, c1, and c2.
A2: Percentage of frequent itemsets = 16/32 = 50.0% (including the null set).
A4: False alarm rate is the ratio of I to the total number of itemsets. Since the count of I = 5, therefore the false alarm rate is 5/32 = 15.6%.
(注:文档可能无法思考全面,请浏览后下载,供参考。
)。