第七章 命名空间和预处理
PHP命名空间(Namespace)的使用详解

PHP命名空间(Namespace)的使⽤详解命名空间⼀个最明确的⽬的就是解决重名问题,PHP中不允许两个函数或者类出现相同的名字,否则会产⽣⼀个致命的错误。
这种情况下只要避免命名重复就可以解决,最常见的⼀种做法是约定⼀个前缀。
例:项⽬中有两个模块:article和message board,它们各⾃有⼀个处理⽤户留⾔的类Comment。
之后我可能想要增加对所有⽤户留⾔的⼀些信息统计功能,⽐如说我想得到所有留⾔的数量。
这时候调⽤它们Comment提供的⽅法是很好的做法,但是同时引⼊各⾃的Comment类显然是不⾏的,代码会出错,在另⼀个地⽅重写任何⼀个Comment也会降低维护性。
那这时只能重构类名,我约定了⼀个命名规则,在类名前⾯加上模块名,像这样:Article_Comment、MessageBoard_Comment可以看到,名字变得很长,那意味着以后使⽤Comment的时候会写上更多的代码(⾄少字符多了)。
并且,以后如果要对各个模块增加更多的⼀些整合功能,或者是互相调⽤,发⽣重名的时候就需要重构名字。
当然在项⽬开始的时候就注意到这个问题,并规定命名规则就能很好的避免这个问题。
另⼀个解决⽅法可以考虑使⽤命名空间。
注明:本⽂提到的常量:PHP5.3开始const关键字可以⽤在类的外部。
const和define都是⽤来声明常量的(它们的区别不详述),但是在命名空间⾥,define的作⽤是全局的,⽽const则作⽤于当前空间。
我在⽂中提到的常量是指使⽤const声明的常量。
基础命名空间将代码划分出不同的空间(区域),每个空间的常量、函数、类(为了偷懒,我下边都将它们称为元素)的名字互不影响,这个有点类似我们常常提到的’封装’的概念。
创建⼀个命名空间需要使⽤namespace关键字,这样:<?php//创建⼀个名为'Article'的命名空间namespace Article;>要注意的是,当前脚本⽂件的第⼀个命名空间前⾯不能有任何代码,下⾯的写法都是错误的:例⼀//在脚本前⾯写了⼀些逻辑代码<?php$path = "/";class Comment { }namespace Article;>例⼆</html><?phpnamespace Article;>为什么要说第⼀个命名空间呢?因为同⼀脚本⽂件中可以创建多个命名空间。
C#命名空间(namespace)不可不知的那些事

C#命名空间(namespace)不可不知的那些事 命名空间本质上就是⼀个逻辑分组,就和我们⽂件夹分组是⼀致的,允许我们将相关的类型集合在⼀起。
命名空间是⼀个⽐较通⽤的概念,在很多语⾔⾥⾯都存在,只不过可能存在⼀些细微差别以及使⽤不同的名称。
⽐如Java就叫包(package)。
接下来,我们将从以下五个⽅⾯来讲解命名空间: 定义命名空间使⽤命名空间正确理解命名空间含义使⽤命名空间alias解决简单类名冲突使⽤extern alias解决Assembly中的完整类名冲突定义命名空间 命名空间的定义很简单,是以关键字namespace(命名空间的英⽂名)开始,后跟命名空间的名字和⼀对⼤括号。
⼤括号⾥的内容都属于这个命名空间。
格式如下: namespace namespace_name { } namespace_name是以点号(.)作为层级隔离的。
⽐如System.IO就可以认为System是第⼀层命名空间,IO是第⼆层命名空间。
由于命名空间其实就是⼀个逻辑分组,所以namespace这个关键字,我们可以理解为“如果不存在namespace_name这个命名空间,就创建⼀个。
如果存在,就使⽤这个命名空间”。
因此,我们是可以在多个地⽅定义同⼀个命名空间的,只要保证同⼀个命名空间中的内容不冲突即可,如下: namespace System.IO { class MemoryStream {} } namespace System.IO { class BufferedStream {} }使⽤命名空间 在程序中使⽤特定类型的时候,我们需要使⽤完整的限定名,⽐如System.IO.MemoryStream。
但是如果每次都这么写,除了增加了开发⼈员打字的成本,毫⽆益处。
因此我们可以使⽤using关键字来表明我们需要使⽤某个命名空间中的类型。
如下: //使⽤完整限定名 public static void Main() { System.Text.StringBuilder sb=new System.Text.StringBuilder(); } //使⽤using 关键字 using System.Text; public static void Main() { StringBuilder sb=new StringBuilder(); } using关键字,其实是告诉编译器可以尝试在这个特定的命名空间中查找类型。
C语言预处理的相关知识

C语言预处理的相关知识C语言预处理的相关知识导语:在C语言编译的时候,会经历以下几个步骤:预处理,编译,汇编,链接,然后生成可执行文件。
整个过程是一连串动作完成的。
而预处理阶段呢,也是在最先执行的一个步骤。
相对来说,也是比较重要的一个步骤。
那么C语言预处理的相关知识呢?一起来学习下吧:概念:以“#”号开头的预处理指令如包含#include,宏定义制定#define等,在源程序中这些指令都放在函数之外,而且一般放在源文件的前面,所谓预处理其实就是在编译的第一遍扫描之前的所作的工作,预处理是c语言的一个重要的功能,它由预处理程序单独完成,当对一个源文件进行编译时,系统自动引用预处理程序,预处理在源代码编译之前对其进行的一些文本性质的操作,对源程序编译之前做一些处理,生成扩展的C源程序预处理阶段做了任务:1:将头文件中的内容(源文件之外的文件)插入到源文件中2:进行了宏替换的过程,定义和替换了由#define指令定义的符号3:删除掉注释的过程,注释是不会带入到编译阶段4:条件编译预处理指令:gcc -E bin/helloworld.i src/helloworld.c预处理生成的是.i的文本文件,这个文本文件是可以直接通过cat 命令进行文本文件查看的宏定义在C语言中允许用一个标识符来表示一个字符串;称为宏,在预处理时,对程序的宏进行替换,其中宏定义是由源程序中的#define来完成,而宏的替换,主要是由预处理程序完成的#define PI 3.1415宏定义的规则:#表示一条预处理的指令,以#开头的均是预处理指令#define是宏定义的指令,标识符是所定义的宏名宏名一般都是大写的字母表示,以便和变量名区别宏定义其实并不是C语言的语句,所以后面是不用去加;号宏体可以是常数,表达式,格式化字符串等,为表达式的时候应该用括号阔起来宏替换不分配内存空间,也不做正确性的检查宏的范围是从定义后到本源文件的结束,但是可以通过#undef来进行提前取消宏定义分为有参宏定义和无参宏定义:无参宏定义:语法:#define 标识符(宏名)[字符串]宏体可缺省:#define YES 1#define NO 0#define OUT printf("Hello world")#define WIDTH 80#define LENGTH (WIDTH+40)宏的移除语法#undef 宏名功能:删除前面定义的宏事例:#undef PI#undef OUT#undef YES#undef NO带参宏定义:带参宏定义的语法结构#define 宏名(形参列表) 字符串(宏体)带参数宏定义调用:宏名(实参表);C语言中允许宏带有参数,在宏定义的参数中称为形式参数,形式参数不分配内存单元,没有类型定义;#define S(a,b) a*b;area = S(3,2);宏展开 area = 3 * 2;注意事项:带参数宏定义中,宏名和形式参数列表之间不能有空格出现。
程序预处理的详细解释

程序预处理的详细解释程序预处理是指在编译过程中对源代码进行预处理操作的过程。
预处理器是编译器的一部分,它负责根据预处理指令来处理源代码,将源代码中的预处理指令替换成相应的内容,以及执行一些宏定义、文件包含和条件编译等操作。
预处理器的主要作用包括:1. 宏定义:通过使用#define指令,可以在源代码中定义一些宏,将一些常用的代码片段或常量定义为宏,以便在程序中多次使用。
预处理器会将宏定义的地方替换为相应的宏内容。
2. 文件包含:通过使用#include指令,可以将其他源代码文件包含到当前的源文件中,以便在当前文件中使用包含文件中的定义和函数。
预处理器会将包含指令替换为被包含文件的内容。
3. 条件编译:通过使用#if、#ifdef、#ifndef、#elif、#else和#endif等指令,可以根据条件选择性地编译源代码的不同部分。
预处理器会根据条件表达式的结果来决定是否编译相应的代码。
4. 预定义宏:预处理器会定义一些特殊的预定义宏,如__FILE__表示当前源文件的文件名,__LINE__表示当前行号,__DATE__表示当前的日期等。
可以在程序中使用这些预定义宏,以便在编译时获取一些相关的信息。
5. 条件编译错误:预处理器可以检测到一些条件编译错误,如未关闭的#if、#ifdef等指令,或者条件表达式中出现的未定义的宏等,从而帮助开发者及早发现和解决问题。
预处理操作是在编译过程的第一个阶段进行的,它将源代码中的预处理指令替换为相应的内容后,生成一个经过预处理的中间代码。
这个中间代码会被传递给编译器的下一个阶段进行编译和链接,最终生成可执行文件。
程序预处理是在编译过程中对源代码进行一系列文本替换和操作的过程,它可以通过宏定义、文件包含和条件编译等功能来简化和优化源代码,提高程序的可维护性和可移植性。
预处理指令——精选推荐

预处理指令预处理命令1 . 基本介绍使⽤库函数之前,应该⽤#include引⼊对应的头⽂件,这种以#开头的命令称为预处理命令这些在编译之前对源⽂件进⾏简单加⼯的过程,就称为预处理(即预先处理,提前处理)预处理主要是处理以#开头的命令。
例如#include<stdio.h>,预处理命令要放在所有函数之外,⽽且⼀般都放在源⽂件的前⾯预处理是C语⾔的⼀个重要功能,由预处理程序完成,当对⼀个源⽂件进⾏编译时,系统将⾃动调⽤预处理程序对源程序中的预处理部分做处理,处理完毕⾃动进⼊对源程序的编译C语⾔提供了多种预处理功能,如宏定义,⽂件包含,条件编译,合理的使⽤会使编写的程序便于阅读,修改,移植和调试,也有利于程序模块化设计2 . 快速⼊门2.1 具体要求开发⼀个C语⾔程序,让它暂停5秒以后再输出内容“hello 尚硅⾕”,并且要求跨平台,在Windows和Linux下都能运⾏2.2 提⽰Windows平台下的暂停函数的原型是void Sleep(DWORD dwMilliseconds),参数的单位是“毫秒”,位于<windows.h>头⽂件linux平台下暂停函数的原型是unsigned int sleep(unsigned int second),参数的单位是“秒”,位于<unistd.h>头⽂件if ,#endif ,就是预处理命令,他们都是在编译之前由预处理程序来执⾏的2.3 代码实现#include<stdio.h>//说明:在Windows操作系统和Linux操作系统下,⽣成源码不⼀样#incLude<windows.h>int main(){Sleep(5000);puts("hello ,尚硅⾕");getchar();rerurn 0;}#if_WIN32 //如果是windows平台,就执⾏#include<windows.h>#include<windows.h>#elif_linux_//否则判断是不是linux,如果是linux就引⼊<unistd.h>#include<unistd.h>#endifint main(){//不同的平台调⽤不同的函数#if_WIN32Sleep(5000);#elif_linux_sleep(5);#endifputs("hello,尚硅⾕");getchar();return 0;}3 . 宏定义3.1 基本介绍define叫做宏定义命令,它⼜是C语⾔预处理命令的⼀种。
预处理的原理

预处理的原理预处理(preprocessing)是指在进行数据分析或机器学习任务之前,对原始数据进行一系列处理和转换的过程。
预处理步骤是数据分析和机器学习中至关重要的一步,可以清洗、转换、归一化和缩放数据,以便让后续的任务更加精确和高效。
预处理的原理包括以下几个方面:1. 数据清洗:数据清洗是预处理的第一步,目的是去除数据中的噪声、空值、重复值和异常值等不符合要求的数据。
数据清洗可以通过数据的查看、筛选和转换等方法来进行,保证数据的可靠性和有效性。
2. 数据转换:数据转换是将原始数据转换为合适的形式,以便应用到后续的任务中。
数据转换可以包括特征选择、特征提取和特征构造等方法。
特征选择是指从原始特征中选择出对后续任务有用的特征,可以通过统计方法、特征相关性分析和模型选择等方法来进行。
特征提取是指通过数学和统计方法从原始数据中提取出具有代表性的特征,例如主成分分析(PCA)和线性判别分析(LDA)等。
特征构造是指通过组合原始特征创建新的特征,例如特征交叉、多项式特征和时间序列特征等。
3. 数据归一化:数据归一化是将不同范围和单位的数据转换为具有相同范围和单位的数据。
常见的数据归一化方法包括最小-最大归一化和标准化归一化。
最小-最大归一化将数据线性转换到[0,1]的范围内,公式为:X' = (X - X_min) / (X_max - X_min)其中,X'是归一化后的数据,X是原始数据,X_min和X_max分别是原始数据的最小值和最大值。
标准化归一化将数据转换为均值为0,方差为1的分布,公式为:X' = (X - mean) / std其中,X'是归一化后的数据,X是原始数据,mean是原始数据的均值,std 是原始数据的标准差。
4. 数据缩放:数据缩放是将数据映射到指定的范围内,以便更好地满足模型的训练和预测需求。
数据缩放常用于特征工程和模型训练阶段。
常见的数据缩放方法包括中心化和缩放至单位方差。
C语言-预处理
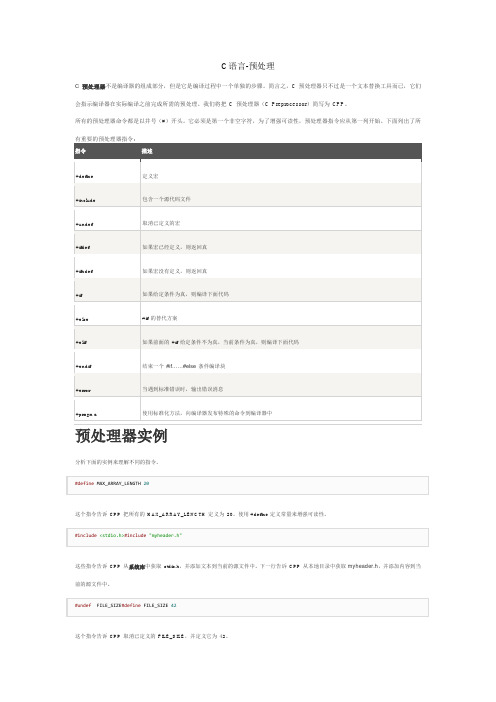
C语言-预处理C 预处理器不是编译器的组成部分,但是它是编译过程中一个单独的步骤。
简言之,C 预处理器只不过是一个文本替换工具而已,它们预处理器实例分析下面的实例来理解不同的指令。
这个指令告诉CPP 把所有的MAX_ARRAY_LENGTH 定义为20。
使用#define定义常量来增强可读性。
这些指令告诉CPP 从系统库中获取stdio.h,并添加文本到当前的源文件中。
下一行告诉CPP 从本地目录中获取myheader.h,并添加内容到当前的源文件中。
这个指令告诉CPP 取消已定义的FILE_SIZE,并定义它为42。
这个指令告诉CPP 只有当MESSAGE 未定义时,才定义MESSAGE。
这个指令告诉CPP 如果定义了DEBUG,则执行处理语句。
在编译时,如果您向gcc 编译器传递了-DDEBUG开关量,这个指令就非常有用。
它定义了DEBUG,您可以在编译期间随时开启或关闭调试。
预定义宏让我们来尝试下面的实例:实例当上面的代码(在文件test.c中)被编译和执行时,它会产生下列结果:预处理器运算符C 预处理器提供了下列的运算符来帮助您创建宏:宏延续运算符(\)一个宏通常写在一个单行上。
但是如果宏太长,一个单行容纳不下,则使用宏延续运算符(\)。
例如:字符串常量化运算符(#)在宏定义中,当需要把一个宏的参数转换为字符串常量时,则使用字符串常量化运算符(#)。
在宏中使用的该运算符有一个特定的参数或参数列表。
例如:实例当上面的代码被编译和执行时,它会产生下列结果:标记粘贴运算符(##)宏定义内的标记粘贴运算符(##)会合并两个参数。
它允许在宏定义中两个独立的标记被合并为一个标记。
例如:实例当上面的代码被编译和执行时,它会产生下列结果:这是怎么发生的,因为这个实例会从编译器产生下列的实际输出:这个实例演示了token##n 会连接到token34 中,在这里,我们使用了字符串常量化运算符(#)和标记粘贴运算符(##)。
预处理

预处理基本流程
数据清洗
去除重复数据、处理缺失值和 异常值等。
数据变换
进行数据规范化、离散化、标 准化等变换操作,以满足后续 分析的需求。
特征选择
从原始特征中选择出对于后续 分析任务最有用的特征子集。
数据降维
通过主成分分析、线性判别分析 等方法降低数据的维度,以便于
后续的可视化和建模等操作。
02
数据清洗
特征编码
将类别型特征转换为数值型特征 ,如独热编码、标签编码等。
特征降维策略
线性降维
通过线性变换将高维特征映射到低维空间,如主成分分析、线性 判别分析等。
非线性降维
通过非线性变换实现特征降维,如流形学习、自编码器等。
特征选择降维
通过选择部分重要特征实现降维,如基于模型的特征选择、基于 统计检验的特征选择等。
通过人工合成新样本的方法来增加 少数类样本的数量,新样本由少数 类样本及其近邻样本随机线性插值 产生。
SMOTE过采样
根据少数类样本的分布情况,自适 应地合成不同数量的新样本,以更 好地平衡不同类别的样本数量。
欠采样技术原理及实现
原理
通过减少多数类样本的数量,使得不同类别的样本数量达到平衡,从 而避免模型在训练过程中对多数类样本产生偏好。
结合业务背景和数据特点,构造具有实际意义的 特征。
多项式特征扩展
通过多项式扩展增加特征的多样性,如多项式回 归中的特征构造。
3
交叉特征构造
将不同特征进行组合,构造交叉特征,以揭示更 多信息。
特征变换技术
标准化与归一化
消除特征量纲和数量级的影响, 使不同特征具有可比性。
离散化
将连续特征转换为离散特征,以 便于某些模型的处理和解释。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
7.2 预处理
7.2.2 #if、#elif、#else和#endif指令 、 、 和 指令 #if指令的基本形式如下: #if symbol_expression_1 statement_sequence_1 #elif symbol_expression_2 statement_sequence_2 #else statement_sequence_n #endif
7.2 预处理
7.2.8 #program指令 指令 #program指令是C#2.0新增的,它用于 给出指令,例如为编译器指定选项。其基本 形式如下: #program option 其中,option是传递给编译器的指令。 在C#2.0中,#program支持两个选项。 一个是warning,它用于启用或禁用某个具体 的编译器警告。对于的命名如下: #program warning disable warnings //禁 用警告 #program warning restore warnings //启 用警告
7.2 预处理
7.2.7 #region和#endregion指令 和 指令 #region和#endregion用于定义一个区域, 该区域可以在Visual Studio IDE的大纲视图中 被扩展或收缩。其基本形式如下: #region region_name //code #endregion 其中,region_name用于指定区域的名称
7.2.4 #error指令 指令 #error指令主要用于调试,它可以迫使编译器 停止编译。该指令的基本形式如下: #error error_message 其中,error_message是错误信息。例如: #error An error occurred here! 7.2.5 #warning指令 指令 #warning类似于#error,不过它产生的是警告 消息而不是错误消息。因此,编译过程不会停止。 其基本形式如下: #warning warning_message
7.2 预处理
7.2.2 #if、#elif、#else和#endif指令 、 、 和 指令 其中,symbol_expression_i是一个 symbol或多个symbol构成的逻辑表达式。如 果表达式的值为真,则编译 statement_sequence_i,如果所有的 symbol_expression都为假,则编译 statement_sequence_n 例 P7_5
7.1 命名空间
7.1.2 using命令 命令 using ns_name;//形式一 或 using alias=ns_name; //形式二 其中ns_name是命名空间的名称,alias 是为命名空间指定的别名。例如: using Counter; using CC=Counter;
7.1 命名空间
7.1 命名空间
7.1.4 使用命名空间限定符“::” 使用命名空间限定符“::” 例P7_4中创建了两个命名空间,Counter1和
Counter2。这两个命名空间中都定义了CountDown类,并且 都被using语句引入程序。因此,在Main方法中使用下面的语 句创建对象cd的时候就会出现错误,其原因在于两个命名空 间Counter1和Counter2中都定义了类CountDown,并且都被 引入到程序中。在使用下面的语句创建CountDown类型的对 象cd时,到底该使用哪一个命名空间中的类CountDown,编 译系统无法确定,从而产生二义性错误。为解决这样的错误, 就必须使用::运算符来实现。 CountDown cd=new CountDown(); 使用运算符::,必须先为要限定的命名空间定义一个别 名。接着使用别名来限定具有二义性错误的元素即可。
7.1.3 嵌套的命名空间 一个命名空间可以声明在另一个命名空 间中,称为命名空间的嵌套。例P7_3。 另外,使用单个namespace也可以嵌套 命名空间,方法是使用句点将每一个命名空间 隔开。例如: namespace NS1.NS2 {//members} 例P7_3的另一种表示形式。
7.1 命名空间
7.1.4 使用命名空间限定符“::” 使用命名空间限定符“::” 尽管命名空间可以帮助避免命名冲突,但不能 完全消除这种冲突。如果在两个不同的命名空间中 声明了同名的成员。如果两个不同的命名空间中声 明了同名的成员,而应用程序又同时引入了这两个 命名空间,就会发生名称冲突。在这种情况下,我 们可以使用命名空间限定符::来显示地指定希望使用 的命名空间。命名空间限定符::是C#2.0中新引入的 功能。 ::运算符的基本形式为: namespace_alias::identifier 其中,namespace_alias是命名空间的别名, identifier是该命名空间中成员的名称。例P7_4。
7.2 预处理
7.2.6 #line指令 指令 #line指令可以为它所在的文件设置行号和文件名。编 译过程中如果出现错误或警告就会用到这里的行号和文件名。 #line指令的基本形式为: #line number "filename" 其中,number是任意的正整数,它用作新行的行号。 可选的filename表示一个任意有效的文件标识符,它被用作 新的文件名。#line主要用于调试和特殊的应用程序。 #line指令还有两个选秀,一个是default,它根据原来 的位置返回行号。其用法为: #line default 另一个是hidden,在逐步调试一个程序的时候, hidden选项允许编译器跳过该指令与下一个不包含hidden选 项的#line指令之间的行。其用法如下: #line hidden
7.1 命名空间
7.1.1 命名空间的声明 使用namespace关键字可以声明一个命名空间, 其基本形式为: namespace ns_name { //members } 其中,ns_name是命名空间的名称。所有定义 在命名空间中的内容都被限制在该命名空间的范围 内。因此,命名空间实际上定义了一个范围。 members是命名空间的成员列表,在命名空间中用 户可以定义类、结构体、委托、枚举、接口或另一 个命名空间等成员。例 P7_1。
7.2 预处理
7.2.8 #program指令 指令
其中,warnings是一个逗号分隔的警告编号列 表。例如: #program warning disable 168 //禁用168号 警告 另一个选项是checksum。它用于为 项目生成校验和。其基本形式如下: #program checksum "filename""{GUID}""check-sum" 其中,filename是文件名,GUID是与文件名 相关的全局唯一标识符,check-sum是一个包含校 验和的十六进制数。该字符串必须包含偶数个数字。
7.2 预处理
7.2.3 #undef指令 指令 #undef指令可以取消之前定义的符号, 基本形式如下: #undef symbol 例如: #define SMALL //这个位置之前SMALL是被定义的 #if SMALL #undef SMALL //这个位置之后SMALL就没有定义了
7.2 预处理
7.2 预处理
C#定义了多个预处理指令,它们可以改变编译 系统解释源程序文件的方式。在把程序翻译为目标 代码之前,预处理指令首先对源文件中的文本产生 作用,即编译哪些文本。C#中所有的预处理指令都 以#开头,并且每个预处理指令都单独占用一行。 C#2.0中的预处理指令如表7-1所示。 表7-1 C#预处理指令 #define #endregion #program #elif #error #region #else #if #undef #endif #line #warning
第七章 命名空间和预处理
主要内容 7.(namespace)定义了一个声明区域, 它提供了将一组名称与另一组名称进行区别的方法。 本质上,就是使得一个命名空间中的名称不会与另 一个命名空间中相同的名称冲突。前面的程序中我 们使用了.NET的命名空间System。 在过去的几年里,在类库、第三方控件及用户 代码中出现了大量的类、方法、属性,因此命名空 间就显得十分重要了。如果不区分命名空间,那么 索引的名称就只能共享同一个全局空间,进而不可 避免地引发命名冲突。比如,如果用户在自己的命 名空间中定义了类Sort,它可能与第三方类库中的 Sort类相冲突。幸运的是,命名空间可以避免这样的 冲突发生,它可以限制声明在其中的名称的可见性。
第七章 命名空间和预处理
基本要求 1.掌握命名空间的声明、使用using引入命名 空间; 2.了解嵌套的命名空间的定义和命名空间限定 符“::”的使用; 3.掌握#define、#if、#elif、#else、#endif、 #undef、#error、#warning、#region、 #endregion和 #program指令的使用。
7.2 预处理
7.2.1 #define指令 指令 #define指令用于定义一个称为符号(symbol) 的字符序列。#if和#elif指令可以判断某个符合是否已 经存在,并据此控制编译过程。#define指令的基本 形式如下: #define symbol 注意,这里没有以分号结束,因为它不是C#的 语句,而是一个预处理指令。#define和symbol之间 至少要用一个空格隔开。C#该指令不同于C和C++中 的#define指令(C、C++中是用来定义宏的)。 例如: #define Windows
7.1 命名空间
7.1.1 命名空间的声明
命名空间的作用在于,在一个命名空间中声明 的名称不会与其他命名空间中声明的同名的名称产 生冲突。例 P7_2。
7.1.2 using命令 命令
如果程序需要频繁地引用某个命名空间中定义 的成员,那么如果每次都指定命名空间就很麻烦。 使用using命名可以解决这个问题。前面的例子中我 们使用using来引入.NET的命名空间System。此外, 用户定义的命名空间也可以使用using引入。using指 令有两种形式,如下: