极大似然估计和广义矩估计
DSGE模型的估计:ML与GMM方法

计 的 基本 原理 , 后通 过 两个 例 子说 明 了如 何 进 行 具 体 的 应 用 。 然
【 键 词 】 随机动态一般均衡模型 ; 大似 然法 ; 矩法 关 极 广义 【 中图分类号 】 24 【 F2. 0 文献标识码 】 【 A 文章编号 】0426(082—040 10—7820 ) 02—3 0
.
三
g ( ̄Y ) T q;T =
h y, ) ( 。‘ P
() 7
J I= 1
g( ) r ・也是一个 i xl n 的向量值 函数 。G MM的思想就是选 择 ‘的估计量‘ 使样本矩 g ( y ) P P, r ‘ 尽可能接近 由式 ( ) P; 6 表示 的总体矩。为此 , 定义一个距离 函数来评价它们之间的接近 要 程度。我们可以使用 以下的距离函数 ( asn 18 ) H ne ,92 :
一
、
引论
∑的估计量 由下式给出:
‘
一
实际商业周期理论( B 产生以来 , R C) 它所使用的随机动态 般均衡 ( S E) D G 的分析框架在经济 周期波 动理论 以及 资产定 价中得到 了广泛的应用 。但其在 求解模型参数的方法中 , 多是 从其它的研究中直接获得模型 中的参数值来 观察 不同 的冲击 下主要宏观经济变量 的各种性质 , 量的方法很少 被使 用。只 计 是在近些 年才出现了一些使用计量 方法进行模 型的参数估计 的方 法 , 中主 要 是 极 大 似 然法 和广 义 矩 法 。 其 极大似然法是建立在极大似然原理基础上的方法 , 进行的 参数估计是根据将 被估计的参数选为最有可能被观察到的值 。 这一方法 的缺点是要求我们说明似然函数 的具体形式。 广义矩 法 的观念 虽然 已使 用 了很 长时 间 ,最早 由皮 尔 逊 ( er n Pao , s 19 ) 84 给出 , 对其进行一般 的表 述却 是 由汉森( asn 18 ) 但 H se ,9 2 发展起来 的。与极 大似然法相 比, 广义矩法的优点是它仅需要 说明一些矩条件 , 而不需要知道具体的密度函数。它的缺点就 是不 能对样本 中的全部信息进行有效利用 ( a io ,9 4 。 H ml n 19 ) 下 t 面我们分别简要介绍一下它们的基本原理 。 ( ) 一 ML方 法 的 原 理 使用 ML对动态最优模型进行估计 , 从以下的计量模 型开
矩估计和极大似然估计正式版PPT文档

pˆX1 n ni1
Xi
fn(A)
(即出现不合格产品的频率).
例5 设总 X~U 体 [a,b]a ,,b未知 X1, ; ,Xn
是一个 求:样 a, b的本 矩估计; 量。
解 令 2 1 E a( E 2X bX2 ) aAD 12X b 1n, ( iE n1X X)2 i (b 1 2 a )2 (a 4 b )2
参数估计
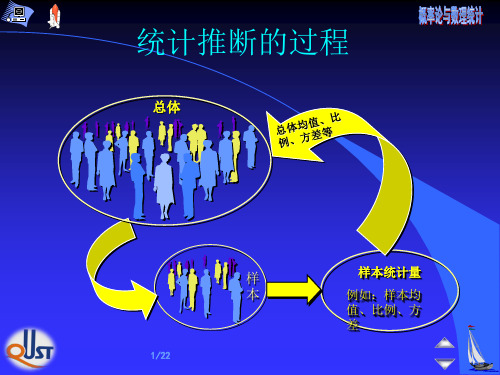
统计推断:参数估计和假设检验。 参数估计问题是利用从总体抽样得到的信息 来估计总体的某些参数或者参数的某些函数。
估计湖中鱼数
估计平均降雨量
……
参数估计要解决问题:
总体分布函数的形式为, 但其中参数θ 未知时,需要确定未知参数。只有当参数θ 确定后,
才能通过率密度函数计算概率。
对于未知参数,如何应用样本 X1,X2,,Xn
一 . 矩估计法
根本原理:总体矩是反映总体分布的最简单的 数字特征,当总体含有待估计参数时,总体矩是 待估计参数的函数。
样本取自总体,Ak PE(Xk) k1,2,.
样本矩在一定程度上可以逼近总体矩, 故用样本矩来估计总体矩
由英国统计学家K.皮尔逊最早提出的。
设总体X的分布函数为 F(x;1, ,k)
参数估计: 点估计:估计θ的具体数值; 区间估计:估计θ的所在范围.
点估计问题:
构造一个适当的统计量 ˆ(X1,X2, ,Xn)
用它的观察值 ˆ(x1,x2,,xn)来估计未知参数θ.
称 ˆ(X1,X2,Xn) 为θ的估计量, ˆ(x1,x2,,xn) 为θ的估计值.
第一节 矩法估计
第七章
一 、矩法估计 二、常用分布参数的矩法估计
则ˆX, ˆ21 ni n1(XiX)2
矩估计和极大似然估计
^ 2
1 n
n i1
Xi2
2
X .
14/22
即
ˆ X ,
ˆ 2
1 n
n i 1
(Xi
X )2.
故,均值,方差2的矩估计为
ˆ ˆ
X, 2 1
n
n
(X
i1
i
X )2
即
n 1S2. n
15/22
如:正态总体N(, 2) 中和2的矩估计为
)2
i1 2
(2 ) e , 2
n 2
1
2
2
n i1
( xi )2
对数似然函数为
ln
L(,
2
)
n 2
ln( 2
)
n 2
ln
2
1
2
2
n
( xi
i1
)2,
35/22
似然方程组为
ln L(, 2 ) 1 2
ln L(, 2 )
X1, X2 , … , Xn . 依样本对参数θ 做出估计,或估计参数θ 的 某个已知函数 g(θ ) 。 这类问题称为参数估计。
参数估计包括:点估计和区间估计。
4/22
为估计参数 µ,需要构造适当的统计量 T( X1, X2 , … , Xn ),
一旦当有了样本,就将样本值代入到该统计 量中,算出一个值作为µ的估计, 称该计算 值为 µ的一个点估计。
7/22
总体 k 阶原点矩 ak E(X k ),
样本 k 阶原点距
Ak
1 n
地理距离和技术外溢效应对技术和经济集聚现象的空间计量学解释

地理距离和技术外溢效应对技术和经济集聚现象的空间计量学解释一、本文概述本文旨在通过空间计量学的视角,深入探讨地理距离和技术外溢效应对技术和经济集聚现象的影响。
随着全球化的推进和科技的快速发展,技术和经济集聚现象在全球范围内愈发显著,成为了经济学、地理学等多个学科研究的热点。
本文将从理论分析和实证研究两个方面入手,分析地理距离和技术外溢效应对技术和经济集聚现象的作用机制,为政策制定和实践操作提供理论支持和决策依据。
在理论分析方面,本文将系统梳理相关文献,探讨地理距离和技术外溢效应对技术和经济集聚的影响机理。
地理距离不仅影响信息的传递和知识的扩散,还影响企业和个人的空间选择行为。
技术外溢效应则是指技术在空间上的传播和扩散,对技术创新和经济增长具有重要影响。
本文将深入分析地理距离和技术外溢效应如何共同作用于技术和经济集聚现象,构建相应的理论模型。
在实证研究方面,本文将运用空间计量学方法,对地理距离和技术外溢效应与技术和经济集聚现象的关系进行量化分析。
通过收集相关数据,建立空间计量模型,实证检验地理距离和技术外溢效应对技术和经济集聚的影响程度。
本文还将考虑不同区域、不同行业的异质性,探讨地理距离和技术外溢效应在不同背景下的作用差异。
本文的研究不仅对深入理解技术和经济集聚现象具有重要意义,也为政策制定者提供了有益的参考。
通过揭示地理距离和技术外溢效应对技术和经济集聚的影响机理,本文旨在为政策制定者提供科学依据,促进技术创新和经济增长的空间均衡发展。
二、文献综述随着全球化的推进和科技的快速发展,技术和经济集聚现象逐渐成为了经济学、地理学等领域研究的热点。
地理距离和技术外溢效应作为影响技术和经济集聚的关键因素,其相关研究已逐渐深入。
地理距离作为传统地理学中的核心概念,一直被用来解释各种经济和社会现象。
在技术和经济集聚的研究中,地理距离不仅影响了创新思想的传播和技术的扩散,还决定了资源和要素的空间配置。
诸多学者通过实证研究发现,地理距离越近,技术和经济活动的集聚现象越明显。
广义矩估计和极大似然估计

广义矩估计一、背景我们前面学了OLS 估计、工具变量估计方法,前面这几种方法都有重要假设就是需要知道分布才能估计,但是往往现实理论我们无法得到关于分布的信息,因此矩估计方法应运而生。
矩估计方法的基本思想是利用样本矩的信息组成方程组来求总体矩,以此得到渐进性质下的一致性估计量。
那么在构成方程组求解的过程中涉及识别问题和解决。
本章详细介绍矩估计方法。
矩估计方法实际应用非常广泛,应注意将矩估计与OLS 估计、工具变量估计和极大似然估计方法结合对比进行应用。
二、知识要点 1,应用背景2,矩估计存在的问题(识别) 3,矩正交方程和矩条件 4,矩估计的属性 三、要点细纲 1、应用背景其基本思想是:在随机抽样中,样本统计量(在一个严格意义上,一个统计量是观察的n 维随机向量即子样(),,,12X X X n =X 的一个(波雷尔可测)函数,且要求它不包含任何未知参数)将依概率收敛于某个常数。
这个常数又是分布中未知参数的一个函数。
即在不知道分布的情况下,利用样本矩构造方程(包含总体的未知参数),利用这些方程求得总体的未知参数。
基本定义统计量 11n m X i n i νν∑= 为子样的ν阶矩(ν阶原点矩); 统计量 ()11n B X X i n i νν∑-= 为子样的ν阶中心矩。
子样矩的均值与方差()()()()2222EX Var X E X E X kk EX E X kkμμμοαμμ=-=--我们用到k k αμ或时假定它是存在的。
基本做法设:母体X 的可能分布族为(){},,F x θθ∈Θ,其中属于参数空间Θ的(),,,12k θθθθ= 是待估计的未知参数。
假定母体分布的k 阶矩存在,则母体分布的ν阶矩()(),,,,112x dF x k k ναθθθθνν∞=≤≤⎰-∞是(),,,12k θθθθ= 的函数。
对于子样(),,,12X X X n = X ,其ν阶子样矩是1,11n m X k i n i ννν=≤≤∑= 现在用子样矩作为母体矩的估计,即令:()1,,,1,2,,121n m X k ik n i ναθθθννν===∑= (1)(1)式确定了包含k 个未知参数(),,,12k θθθθ= 的k 个方程式。
极大似然估计和广义矩估计

05
案例分析
极大似然估计的案例
线性回归模型
在回归分析中,极大似然估计常用于估计线性回归模型的参数。通过最大化似然 函数,可以得到最佳线性无偏估计,使得预测值与实际观测值之间的误差最小。
正态分布参数估计
极大似然估计在正态分布的参数估计中也有广泛应用。例如,假设一组数据来自 正态分布,我们可以通过极大似然估计来估计均值和方差。
极大似然估计和广义矩估 计
• 引言 • 极大似然估计 • 广义矩估计 • 极大似然估计与广义矩估计的比较 • 案例分析 • 总结与展望
01
引言
主题简介
极大似然估计
极大似然估计是一种参数估计方 法,基于观测数据的概率分布模 型,通过最大化似然函数来估计 未知参数。
广义矩估计
广义矩估计是一种非参数估计方 法,通过最小化一系列矩(如一 阶矩、二阶矩等)的离差来估计 未知参数。
唯一性
在某些条件下,极大似然估计具有唯一性,即真实参 数值是极大似然函数的唯一最大值。
极大似然估计的步骤和实现
1 2
定义似然函数
根据数据分布和模型假设,定义似然函数。
求导并求解
对似然函数求导,并使用优化算法求解导数为零 的点,得到参数的极大似然估计值。
3
验证估计值
使用验证数据集验证估计值的准确性和有效性。
3. 优化目标函数
实现
使用优化算法(如牛顿法、拟牛顿法等) 最小化目标函数,以找到最优的模型参数 。
在编程语言(如Python、R等)中,可以 使用相应的统计库(如statsmodels、 EMMA等)来方便地实现广义矩估计。
04
极大似然估计与广义矩估计的比较
相似之处
理论基础
01
经典参数估计方法(3种方法)

经典参数估计方法:普通最小二乘(OLS)、最大似然(ML)和矩估计(MM)普通最小二乘估计(Ordinary least squares,OLS)1801年,意大利天文学家朱赛普.皮亚齐发现了第一颗小行星谷神星。
经过40天的跟踪观测后,由于谷神星运行至太阳背后,使得皮亚齐失去了谷神星的位置。
随后全世界的科学家利用皮亚齐的观测数据开始寻找谷神星,但是根据大多数人计算的结果来寻找谷神星都没有结果。
时年24岁的高斯也计算了谷神星的轨道。
奥地利天文学家海因里希.奥尔伯斯根据高斯计算出来的轨道重新发现了谷神星。
高斯使用的最小二乘法的方法发表于1809年他的著作《天体运动论》中。
法国科学家勒让德于1806年独立发现“最小二乘法”,但因不为世人所知而默默无闻。
勒让德曾与高斯为谁最早创立最小二乘法原理发生争执。
1829年,高斯提供了最小二乘法的优化效果强于其他方法的证明,因此被称为高斯-莫卡夫定理。
最大似然估计(Maximum likelihood,ML)最大似然法,也称最大或然法、极大似然法,最早由高斯提出,后由英国遗传及统计学家费歇于1912年重新提出,并证明了该方法的一些性质,名称“最大似然估计”也是费歇给出的。
该方法是不同于最小二乘法的另一种参数估计方法,是从最大似然原理出发发展起来的其他估计方法的基础。
虽然其应用没有最小二乘法普遍,但在计量经济学理论上占据很重要的地位,因为最大似然原理比最小二乘原理更本质地揭示了通过样本估计总体的内在机理。
计量经济学的发展,更多地是以最大似然原理为基础的,对于一些特殊的计量经济学模型,最大似然法才是成功的估计方法。
对于最小二乘法,当从模型总体随机抽取n组样本观测值后,最合理的参数估计量应该使得模型能最好地拟合样本数据;而对于最大似然法,当从模型总体随机抽取n组样本观测值后,最合理的参数估计量应该是使得从模型中抽取该n组样本观测值的概率最大。
从总体中经过n次随机抽取得到的样本容量为n的样本观测值,在任一次随机抽取中,样本观测值都以一定的概率出现。
矩估计与最大似然估计

矩估计与最大似然估计
矩估计是基于样本矩与总体矩之间的对应关系来估计总体参数
的方法。
在确定矩估计量时,首先需要确定估计量所对应的矩的阶数,并且需要保证样本矩与总体矩之间存在一一对应关系。
矩估计方法具有简单、易于计算和解释的优点,但是在样本容量较小时可能存在较大的估计误差。
最大似然估计是基于样本数据在不同总体参数下出现的概率大
小来估计总体参数的方法。
最大似然估计量是使得样本数据出现的概率最大的总体参数取值。
最大似然估计方法具有渐进无偏性、有效性和一致性等优点,但是在计算过程中需要确定似然函数,并且需要对极值进行求解。
总之,矩估计和最大似然估计方法各有优缺点,在具体应用中需要根据实际情况进行选择。
- 1 -。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第一节 极大似然估计法
极大似然估计法(Maximum Likelihood method ,ML)的应用虽然没有普通最小二乘法广泛,但它是 一个具有更强理论性质的点估计方法,它以极大似然 原理为基础,通过概率密度函数或者分布律来估计总 体参数。 极大似然估计的出发点是已知被观测现象的分布, 但不知道其参数。极大似然法用得到观测值(样本) 最高概率的那些参数的值来估计该分布的参数,从而 提供一种用于估计刻画一个分布的一组参数的方法。
上式中的表达式可看作是未知参数p的函数,被 称为似然函数(Likelihood function)。对p的极大 似然估计意味着我们选择使似然函数达到最大的p值, 从而得到p的极大似然估计量。
4
实际计算中,极大化似然函数的对数往往比较方便, 这给出对数似然函数
ln L( p) lnc
d ln L( p)
10
三、极大似然估计量的性质
极大似然估计量(MLE)的优势在于它们的大样本 性质(渐近性质)。 为介绍这些渐近性质,我们用表示参数向量的极大 似然估计量(MLE),表示参数向量的真值。 如果极大似然函数被正确设定,可以证明,在弱正 则条件下,极大似然估计量具有以下渐近性质:
11
ˆ ˆ 是 的一致估计量,即, p lim (1)一致性: ML 0 ML
ˆ 是渐近有效的且达到所有一 (2) 渐近有效性: ML 致估计量的Cramè r-Rao下界,即在所有一致渐近正 态估计量(consistent asymptotically normal estimators )中具有最小方差。
ˆ ~ N ,V ( ) (3) 渐近正态性: ML 0 0 即渐近地服从正态分布,其中V是渐近协方差矩阵
3
一、极大似然法的思路
设有一枚不均衡的硬币,我们关心的是在每次抛 掷该硬币出现正面的概率p。抛掷该硬币N次,假设 N N1 次反面。由于每次抛硬币都是 得到 N1 次正面, 相互独立的,根据二项分布,得到这样一个样本的概 率为: N1 N1 P( N1次正面) C N p (1 p) N N1
第一节 极大似然估计法
第二节似然比检验、沃尔德检验和拉格
朗日乘数检验
第三节广义矩(GMM)估计 小结
除普通最小二乘法(OLS)外,极大似然估 计(MLE)和广义矩估计(GMM)也是计 量经济学中重要的估计方法。
极大似然估计法和广义矩估计法适用于大样 本条件下参数的估计,它们在大样本条件下 显示了优良的性质。 本章主要介绍极大似然法和广义矩方法以及 基于极大似然估计的似然比(LR)检验、 沃尔德(W)检验和拉格朗日乘数(LM) 检验。1 2 nn Nhomakorabea1
1
2
2
n
n
1
2
n
i 1
i
1
2
k
这一概率随 的取值而变化,它是 的函数,L( ) 称 为样本的似然函数。 极大似然估计法就是在 取值的可能范围内挑选使 似然函数 L( x1, x2 ,, xn ; )达到最大的参数值 ˆ 作为参数 L( x1, x2 ,..., xn ; ) 的估计值,即求ˆ ,使得 L( x1, x2 ,..., xn ;ˆ) Max
7
•一般通过微分的方法求得 ˆ ,即,令 L( ) / 0得 到,有时候也可通过迭代法来求ˆ ,具体的计算方 法根据随机变量的分布来确定。 这样得到的 ˆ 称为参数 的极大似然估计值 ,而相 应的统计量通常记为 ˆ ,称为参数 的极大似然 估计量。
ML
8
(二)连续型随机变量极大似然原理 与离散型的情况一样,我们取 的估计值 ˆ 使 f ( x , )dx 取到极大值,但 dx 不随 而变,故只需考虑函数 L( ) L( x , x ,..., x ; ) f ( x ; ) 的极大值,这里 L ( ) 称为样 本的似然函数。
6
(一)离散型随机变量极大似然原理
若总体为离散型分布,容易求得从样本 X , X ,...X 取到 观察值 x1, x2 ,..., xn 的概率,亦即事件发生的概率 L( ) L( x , x ,..., x ; ) p( x ; ) X x , X x ,..., X x 为: 其中, ( , ,..., ) 是待估参数向量。
n
n
i 1
i
i 1
n
1
2
n
i 1
i
若 L( x , x ,..., x ;ˆ) Max L( x , x ,..., x ; ) 则 计量,记为 ˆ 。
1 2 n
1
2
n
ˆ
称为 的极大似然估
ML
9
L( )关于 可微,这时 ˆ 可从方程 通常情况下, L( ) / 0 解得。因为 L( )与 ln L( )在同一点处取到 ˆ通常从方程 L( ) / 0 极值,的极大似然估计值 解得,式中 ln L( ) 称为对数似然函数。 为了后面内容表述方便起见,我们将对数似然函数 的一阶导数向量表示为 S( ) lnL( )/ , S( ) 称为score向量或梯度向量, 的极大似然估计量 通过求解得到, S( ) 0 因此 S( ) 0 称为似然方程。
N1 N
N1 ln( p) (N - N1 )ln(1 - p)
上式达到极大的一阶条件是
d
p
N1 N N1 0 p 1 p
解之,得到p的极大似然估计量
ˆ N1 / N p
5
二、极大似然原理
极大似然法的思路是,设 f ( x, ) 是随机变量X的密度函 数,其中 是该分布的未知参数,若有一随机样本 X1 , X 2 ,..., X n ,则 的极大似然估计值是具有产生该观 值,或者换句话说,的极 测样本的最高概率的那个 大似然估计值是使密度函数f ( x, )达到最大的值。 由于总体有离散型和连续型两种分布,离散型分布通 过分布律来构造似然函数,而连续型分布通过概率密 度函数来构造似然函数,因此二者有区别,下面分别 讨论。