顺序查找、折半查找和分块查找算法的适用范围
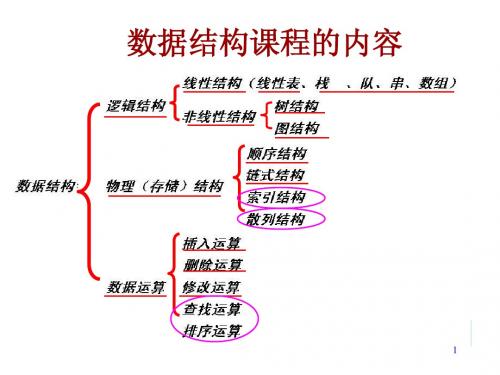
查找排序
解:① 先设定3个辅助标志: low,high,mid, 显然有:mid= (low+high)/2 ② 运算步骤:
(1) low =1,high =11 ,故mid =6 ,待查范围是 [1,11]; (2) 若 S[mid] < key,说明 key[ mid+1,high] , 则令:low =mid+1;重算 mid= (low+high)/2;. (3) 若 S[mid] > key,说明key[low ,mid-1], 则令:high =mid–1;重算 mid ; (4)若 S[ mid ] = key,说明查找成功,元素序号=mid; 结束条件: (1)查找成功 : S[mid] = key (2)查找不成功 : high<low (意即区间长度小于0)
while(low<=high)
{ mid=(low+high)/2; if(ST[mid].key= = key) return (mid); /*查找成功*/
else if( key< ST[mid].key) high=mid-1; /*在前半区间继续查找*/ else } return (0); /*查找不成功*/
4 5 6 7
0
1
2
90
10
(c)
20
40
K=90
80
30
60
Hale Waihona Puke 25(return i=0 )
6
讨论:怎样衡量查找效率?
——用平均查找长度(ASL)衡量。
如何计算ASL?
数据结构练习3答案

数据结构练习(三)参考一、选择题1.顺序查找法适合于存储结构为的线性表A)哈希存储C)压缩存储D)索引存储2.一个长度为100的已排好序的表,用二分查找法进行查找,若查找不成功,至少比较________次。
A)9 B)8 C)73.采用顺序查找方法查找长度为n的线性表时,平均比较次数为。
A)n B)n/2 n+1)/2 D)(n-1)/24.对线性表进行折半查找时,要求线性表必须。
A)以顺序方式存储C)以链表方式存储D)以链表方式存储,且结点按关键字有序排列5.采用二分查找法查找长度为n的线性表时,每个元素的平均查找长度为。
A)O(n2)B)O(nlog2n)C)O(n)(log2n)6.有一个长度为12的有序表R[0…11],按折半查找法对该表进行查找,在表内各元素等概率查找情况下查找成功所需的平均比较次数为。
A)35/12 C)39/12 D)43/127.有一个有序表为{1,3,9,12,32,41,45,62,75,77,82,95,99},当采用折半查找法查找关键字为82的元素时,次比较后查找成功。
A)1 B.2 D)88.当采用分块查找时,数据的组织方式为。
A)数据分成若干块,每块内存数据有序每块内数据不必有序,但块间必须有序,每块内最大(或最小)的数据组成索引块C)数据分成若干块,每块内数据有序,每块内最大(或最小)的数据组成索引块D)数据分成若干块,每块(出最后一块外)中的数据个数需相同9.采用分块查找时,若线性表中共有625个元素,查找每个元素的概率相同,假设采用顺序查找来确定结点所在的块时,每块应有个结点最佳。
A)10 C)6 D)62510.不能生成右图所示二叉排序树的关键字序列是_____。
B)42531 C)45213 D)4231511.按____遍历二叉排序树,可以得到按值递增或递减次序的关键码序列。
A)先序C)后序D)层序12.在一棵平衡二叉树中,每个结点的平衡因子的取值范围是。
[课程]查找与排序部分习题集
![[课程]查找与排序部分习题集](https://img.taocdn.com/s3/m/7a2537cca48da0116c175f0e7cd184254b351b71.png)
查找与排序部分习题一、选择题1.设有100个元素,用折半查找法进行查找时,最大比较次数是______。
A、25 B、8 C、10 D、72.有一个有序表为{1,3,9,12,32,41,45,62,75,77,82,95,100},当折半查找值82的结点时,______次比较后查找成功。
(注:计算中间位置时取下整)A、1B、2C、4D、83.顺序查找法适合于存储结构为______的线性表。
A、散列存储B、顺序存储或链接存储C、压缩存储D、索引存储4.某顺序存储的表格中有90000个元素,以按关键字值升序排列,假定对每个元素进行查找的概率是相同的,且每个元素的关键字的值皆不相同,用顺序查找法查找时,平均比较次数约为______;最大比较次数约为______。
A、25000B、30000C、45000D、900005.设散列地址空间为0到m-1,k为关键字,用p去除k,将所得的余数作为k的散列地址,即H(k)=k%p。
为了减少发生冲突的频率,一般取p为______。
A、小于m的最大奇数B、小于m的最大偶数C、小于m的最大素数D、大于m的最大素数6.设有9个数据记录组成的线性表,它们的排序关键字的取值分别是(11,15,20,27,30,35,46,88,120),已将它们按照排序关键字递增有序的方式存放在一维结构数组a[0..8]中从下标0开始到下标8结束的位置,则当采用折半查找算法查找关键字值等于20的数据记录时,所需比较的元素下标依次是:______。
(注:计算中间位置时取下整)A、0,1,2B、4,1,2C、4,2D、4,3,27.顺序查找一个共有n个元素的线性表,其时间复杂度为______。
A、O(n)B、O(log2n)C、O(n2)D、O(nlog2n)8.设有100个元素,用折半查找法进行查找时,最小比较次数是______。
A、7B、4C、2D、19.哈希法中,除了考虑构造“均匀”的哈希函数外,还要解决冲突的问题,以下选项中______不是解决冲突的办法。
查找表结构——精选推荐

查找表结构查找表介绍在⽇常⽣活中,⼏乎每天都要进⾏⼀些查找的⼯作,在电话簿中查阅某个⼈的电话号码;在电脑的⽂件夹中查找某个具体的⽂件等等。
本节主要介绍⽤于查找操作的数据结构——查找表。
查找表是由同⼀类型的数据元素构成的集合。
例如电话号码簿和字典都可以看作是⼀张查找表。
⼀般对于查找表有以下⼏种操作:在查找表中查找某个具体的数据元素;在查找表中插⼊数据元素;从查找表中删除数据元素;静态查找表和动态查找表在查找表中只做查找操作,⽽不改动表中数据元素,称此类查找表为静态查找表;反之,在查找表中做查找操作的同时进⾏插⼊数据或者删除数据的操作,称此类表为动态查找表。
关键字在查找表查找某个特定元素时,前提是需要知道这个元素的⼀些属性。
例如,每个⼈上学的时候都会有⾃⼰唯⼀的学号,因为你的姓名、年龄都有可能和其他⼈是重复的,唯独学号不会重复。
⽽学⽣具有的这些属性(学号、姓名、年龄等)都可以称为关键字。
关键字⼜细分为主关键字和次关键字。
若某个关键字可以唯⼀地识别⼀个数据元素时,称这个关键字为主关键字,例如学⽣的学号就具有唯⼀性;反之,像学⽣姓名、年龄这类的关键字,由于不具有唯⼀性,称为次关键字。
如何进⾏查找?不同的查找表,其使⽤的查找⽅法是不同的。
例如每个⼈都有属于⾃⼰的朋友圈,都有⾃⼰的电话簿,电话簿中数据的排序⽅式是多种多样的,有的是按照姓名的⾸字母进⾏排序,这种情况在查找时,就可以根据被查找元素的⾸字母进⾏顺序查找;有的是按照类别(亲朋好友)进⾏排序。
在查找时,就需要根据被查找元素本⾝的类别关键字进⾏排序。
具体的查找⽅法需要根据实际应⽤中具体情况⽽定。
顺序查找算法(C++)静态查找表既可以使⽤顺序表表⽰,也可以使⽤链表结构表⽰。
虽然⼀个是数组、⼀个链表,但两者在做查找操作时,基本上⼤同⼩异。
顺序查找的实现静态查找表⽤顺序存储结构表⽰时,顺序查找的查找过程为:从表中的最后⼀个数据元素开始,逐个同记录的关键字做⽐较,如果匹配成功,则查找成功;反之,如果直到表中第⼀个关键字查找完也没有成功匹配,则查找失败。
数据结构(八)查找

99
250
110
300
280
类C程序实现: void InsertBST(*&t,key) //在二叉排序树中插入查找关键字key { if(t= = NULL){ t=new BiTree; t->lchild=t->rchild=NULL; t->data=key; return; } if(key<t->data ) InsertBST(t->lchild,key); else InsertBST (t->rchild, key ); } void CreateBiTree(tree,d[ ],n) //n个数据在数组d中,tree为二叉排序树根 { tree=NULL; for(i=0;i<n;i++) InsertBST(tree,d[i]); }
p q
void delete(*&p) { if(p->rchild = = NULL) { q=p; p=p->lchild; delete q; } else if(p->lchild= =NULL) { q=p; p=p->rchild; delete q; } else { q=p; s=p->lchild; while(s->rchild!=NULL) {q=s; s=s->rchild;} p->data=s->data; if(q!=p) q->rchild=s->lchild; else q->lchild=s->lchild; } delete s; }
在xL中选值最大的代替x,该数据按二叉排序树的性质应在 最右边。
f x f s c
数据结构中的查找算法总结

数据结构中的查找算法总结静态查找是数据集合稳定不需要添加删除元素的查找包括:1. 顺序查找2. 折半查找3. Fibonacci4. 分块查找静态查找可以⽤线性表结构组织数据,这样可以使⽤顺序查找算法,再对关键字进⾏排序就可以使⽤折半查找或斐波那契查找等算法提⾼查找效率,平均查找长度:折半查找最⼩,分块次之,顺序查找最⼤。
顺序查找对有序⽆序表均适⽤,折半查找适⽤于有序表,分块查找要求表中元素是块与块之间的记录按关键字有序动态查找是数据集合需要添加删除元素的查找包括: 1. ⼆叉排序树 2. 平衡⼆叉树 3. 散列表 顺序查找适合于存储结构为顺序存储或链接存储的线性表。
顺序查找属于⽆序查找算法。
从数据结构线形表的⼀端开始,顺序扫描,依次将扫描到的结点关键字与给定值k相⽐较,若相等则表⽰查找成功 查找成功时的平均查找长度为: ASL = 1/n(1+2+3+…+n) = (n+1)/2 ; 顺序查找的时间复杂度为O(n)。
元素必须是有序的,如果是⽆序的则要先进⾏排序操作。
⼆分查找即折半查找,属于有序查找算法。
⽤给定值value与中间结点mid的关键字⽐较,若相等则查找成功;若不相等,再根据value 与该中间结点关键字的⽐较结果确定下⼀步查找的⼦表 将数组的查找过程绘制成⼀棵⼆叉树排序树,如果查找的关键字不是中间记录的话,折半查找等于是把静态有序查找表分成了两棵⼦树,即查找结果只需要找其中的⼀半数据记录即可,等于⼯作量少了⼀半,然后继续折半查找,效率⾼。
根据⼆叉树的性质,具有n个结点的完全⼆叉树的深度为[log2n]+1。
尽管折半查找判定⼆叉树并不是完全⼆叉树,但同样相同的推导可以得出,最坏情况是查找到关键字或查找失败的次数为[log2n]+1,最好的情况是1次。
时间复杂度为O(log2n); 折半计算mid的公式 mid = (low+high)/2;if(a[mid]==value)return mid;if(a[mid]>value)high = mid-1;if(a[mid]<value)low = mid+1; 折半查找判定数中的结点都是查找成功的情况,将每个结点的空指针指向⼀个实际上不存在的结点——外结点,所有外界点都是查找不成功的情况,如图所⽰。
Java常见的七种查找算法

Java常见的七种查找算法1. 基本查找也叫做顺序查找,说明:顺序查找适合于存储结构为数组或者链表。
基本思想:顺序查找也称为线形查找,属于无序查找算法。
从数据结构线的一端开始,顺序扫描,依次将遍历到的结点与要查找的值相比较,若相等则表示查找成功;若遍历结束仍没有找到相同的,表示查找失败。
示例代码:public class A01_BasicSearchDemo1 {public static void main(String[] args){//基本查找/顺序查找//核心://从0索引开始挨个往后查找//需求:定义一个方法利用基本查找,查询某个元素是否存在//数据如下:{131, 127, 147, 81, 103, 23, 7, 79}int[] arr ={131,127,147,81,103,23,7,79};int number =82;System.out.println(basicSearch(arr, number));}//参数://一:数组//二:要查找的元素//返回值://元素是否存在public static boolean basicSearch(int[] arr,int number){//利用基本查找来查找number在数组中是否存在for(int i =0; i < arr.length; i++){if(arr[i]== number){return true;}}return false;}}2. 二分查找也叫做折半查找,说明:元素必须是有序的,从小到大,或者从大到小都是可以的。
如果是无序的,也可以先进行排序。
但是排序之后,会改变原有数据的顺序,查找出来元素位置跟原来的元素可能是不一样的,所以排序之后再查找只能判断当前数据是否在容器当中,返回的索引无实际的意义。
基本思想:也称为是折半查找,属于有序查找算法。
用给定值先与中间结点比较。
比较完之后有三种情况:•相等说明找到了•要查找的数据比中间节点小说明要查找的数字在中间节点左边•要查找的数据比中间节点大说明要查找的数字在中间节点右边代码示例:package com.itheima.search;public class A02_BinarySearchDemo1 {public static void main(String[] args){//二分查找/折半查找//核心://每次排除一半的查找范围//需求:定义一个方法利用二分查找,查询某个元素在数组中的索引//数据如下:{7, 23, 79, 81, 103, 127, 131, 147}int[] arr ={7,23,79,81,103,127,131,147};System.out.println(binarySearch(arr,150));}public static int binarySearch(int[] arr,int number){//1.定义两个变量记录要查找的范围int min =0;int max = arr.length-1;//2.利用循环不断的去找要查找的数据while(true){if(min > max){return-1;}//3.找到min和max的中间位置int mid =(min + max)/2;//4.拿着mid指向的元素跟要查找的元素进行比较if(arr[mid]> number){//4.1 number在mid的左边//min不变,max = mid - 1;max = mid -1;}else if(arr[mid]< number){//4.2 number在mid的右边//max不变,min = mid + 1;min = mid +1;}else{//4.3 number跟mid指向的元素一样//找到了return mid;}}}}3. 插值查找在介绍插值查找之前,先考虑一个问题:为什么二分查找算法一定要是折半,而不是折四分之一或者折更多呢?其实就是因为方便,简单,但是如果我能在二分查找的基础上,让中间的mid点,尽可能靠近想要查找的元素,那不就能提高查找的效率了吗?二分查找中查找点计算如下:mid=(low+high)/2, 即mid=low+1/2*(high-low);我们可以将查找的点改进为如下:mid=low+(key-a[low])/(a[high]-a[low])*(high-low),这样,让mid值的变化更靠近关键字key,这样也就间接地减少了比较次数。
形考作业四及答案

形考作业四及答案(本部分作业覆盖教材第8-9章的内容)一、单项选择题1、顺序查找方法适合于存储结构为()的线性表。
A.散列存储B.索引存储C.散列存储或索引存储D.顺序存储或链接存储2、对线性表进行二分查找时,要求线性表必须()。
A.以顺序存储方式B.以链接存储方式C.以顺序存储方式,且数据元素有序D.以链接存储方式,且数据元素有序3、对于一个线性表,若要求既能进行较快地插入和删除,又要求存储结构能够反映数据元素之间的逻辑关系,则应该()。
A.以顺序存储方式B.以链接存储方式C.以索引存储方式D.以散列存储方式4、采用顺序查找方法查找长度为n的线性表时,每个元素的平均查找长度为()。
A.n B.n/2C.(n+1)/2 D.(n-1)/25、哈希函数有一个共同的性质,即函数值应当以()取其值域的每个值。
A.最大概率B.最小概率C.平均概率D.同等概率6、有一个长度为10的有序表,按折半查找对该表进行查找,在等概率情况下查找成功的平均比较次数为()。
A.29/10 B.31/10 C.26/10 D.29/97、已知一个有序表为{11,22,33,44,55,66,77,88,99},则顺序查找元素55需要比较()次。
A.3 B.4 C.5 D.68、顺序查找法与二分查找法对存储结构的要求是()。
A.顺序查找与二分查找均只是适用于顺序表B.顺序查找与二分查找均既适用于顺序表,也适用于链表C.顺序查找只是适用于顺序表D.二分查找适用于顺序表9、有数据{53,30,37,12,45,24,96},从空二叉树开始逐个插入数据来形成二叉排序树,若希望高度最小,应该选择的序列是()。
A.45,24,53,12,37,96,30 B.37,24,12,30,53,45,96C.12,24,30,37,45,53,96 D.30,24,12,37,45,96,5310、对有18个元素的有序表作二分(折半)查找,则查找A[3]的比较序列的下标可能为()。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
顺序查找、折半查找和分块查找算法的适用范围
1.顺序查找适用范围:
(1)数据量比较小的线性表;
(2)对线性表的操作进行频繁的情况,如链表或数组中删除、插入操作;
(3)线性表中元素无序排列的情况。
2.折半查找适用范围:
(1)线性表有序排列;
(2)查找频繁,但不需要频繁插入和删除操作;
(3)数据量较大,相对于顺序查找来说,提高了查找的速度。
3.分块查找适用范围:
(1)线性表较大,有序排列;
(2)查找频繁,但不需要频繁插入和删除操作;
(3)对于线性表中分布均匀的元素进行查找。