刘小平《统计学基础与实务》章后习题答案:第7章 相关与回归分析
第七章 相关与回归分析

正线性相关
2019年12月14日12时 28分
完全负线性相关
负线性相关
非线性相关
不相关
11
(二)相关系数和判定系数
1. 都是对变量之间关系密切程度的度量;
2. 判定系数=相关系数的平方; 3. 不同类型的相关,相关系数的计算方法也不同.
3. 利用所求的关系式,根据一个或几个变量的 取值来预测或控制另一个特定变量的取值, 并给出这种预测或控制的精确程度。
• 相关程度的三级划分法:
|r|<0.3, 微相关或不相关 0.3≤|r|<0.5, 低度相关 0.5≤|r|<0.8, 显著相关
r的绝对值在0.8以上的为高度相关 一般情况下,只有r的绝对值在0.5以上, 才进一步进行相关分析。
2019年12月14日12时
28分
15
统
计 学
第三节 回归分析的一般问题
2019年12月14日12时
28分
7
3、按相关方向分为: 正相关——两变量大体上呈同方向变化; 负相关——两变量大体上呈反方向变化。 4、按相关密切程度分: 完全相关——两变量间有确定函数关系。 不完全相关——两变量不存在严格函数关系。 不相关——当一个变量变化,另一个变量不
2019年12月14日12时
28分
6
相关关系的类型
1、按相关关系涉及的因素多少分为:
•单相关——一元相关,两变量间的相关关系; •复相关——多元相关,三个(或以上)变量间的相 关关系;
2、按相关的表现形态分为:
•直线相关——观察点的分布大致呈现为一条直线; •曲线相关——观察点的分布大致呈现为一条曲线
袁卫《统计学》(第3版)课后习题-相关与回归分析(圣才出品)

称为总体回归函数(简记为 PRF)。 (2)如果把因变量 y 的样本条件期望表示为自变量 x 的某种函数,这个函数称为样本
回归函数(简记为 SRF)。 (3)总体回归函数和样本回归函数的区别
2 / 24
量以外的所有因素对 y 的影响,称为随机误差项。
(2)因变量 y 的实际观测值 yi 并不完全等于样本条件期望 yˆi ,二者之偏差称为残差项 或剩余项,用 ei 表示,则 yi − yˆi = ei 。
(3)总体回归函数中的 i 是不可直接观测的,而样本回归函数中的 ei 是只要估计出样
本回归的参数就可以计算的数值。
圣才电子书 十万种考研考证电子书、题库视频学习平台
①总体回归函数虽然未知,但它是确定的;而由于从总体中每次抽样都能获得一个样本, 就都可以拟合一条样本回归线,所以样本回归线是随抽样的样本而变化的,可以有许多条。 所以,样本回归线还不是总体回归线,至多只是未知总体回归线的近似表现。
圣才电子书
十万种考研考证电子书、题库视频学习平台
第 7 章 相关与回归分析
思考题 1.相关分析与回归分析的区别和联系是什么? 答:(1)相关分析与回归分析的联系 相关分析与回归分析具有共同的研究对象,都是对变量间相关关系的分析,二者可以相 互补充。相关分析可以表明变量间相关关系的性质和程度,只有当变量间存在相当程度的相 关关系时,进行回归分析去寻求变量间相关的具体数学形式才有实际的意义。同时,在进行 相关分析时,如果要具体确定变量间相关的具体数学形式,又要依赖于回归分析,而且在多 个变量的相关分析中相关系数的确定也是建立在回归分析基础上的。 (2)相关分析与回归分析的区别 ①从研究目的上看,相关分析是用一定的数量指标(相关系数)度量变量间相互联系的 方向和程度;回归分析却是要寻求变量间联系的具体数学形式,是要根据自变量的固定值去 估计和预测因变量的平均值。 ②从对变量的处理看,相关分析对称地对待相互联系的变量,不考虑二者的因果关系, 也就是不区分自变量和因变量,相关的变量不一定具有因果关系,均视为随机变量;回归分 析是在变量因果关系分析的基础上研究其中的自变量的变动对因变量的具体影响,必须明确 划分自变量和因变量,所以回归分析中对变量的处理是不对称的,在回归分析中通常假定自 变量在重复抽样中是取固定值的非随机变量,只有因变量是具有一定概率分布的随机变量。
统计学7-10章课后作业答案

第7章 相关与回归分析1、设销售收入x 为自变量,销售成本y 为因变量。
现已根据某百货公司某年12个月的有关资料计算出以下数据(单位:万元):2()425053.73ix x -=∑ 647.88x =2()262855.25iy y -=∑549.8y =()()334229.09iix x y y --=∑(1)拟合简单线性回归方程,并对方程中回归系数的经济意义作出解释。
(2)计算可决系数和回归估计的标准误差。
(3)对回归系数进行显著性水平为5%的显著性检验。
(4)假定下年一月销售收入为800万元,利用拟合的回归方程预测销售成本,并给出置信度为95%的预测区间。
解:(1)定性分析可知,销售收入影响销售成本,以销售收入为自变量,销售成本为因变量拟合线性回归方程i i i y x u αβ=++,采用最小二乘法估计回归参数得:22()()(,)334229.09ˆ0.7863()425053.73ii xix x y y Cov x y x x βσ--===≈-∑∑ˆˆ549.80.7863647.8840.372y x αβ=-=-⨯= 因此,拟合的回归方程为:ˆˆˆ40.3720.7863i i iy x x αβ=+=+ 其中,回归系数β表示自变量每变动一个单位,因变量的平均变量幅度。
在此,表示销售收入每增加1万元,销售成本平均增加0.7863万元。
(2)可决系数22222[()()]334229.090.9998()()425053.73262855.25i i i i x x y y SSR R SST x x y y --===≈-⋅-⨯∑∑∑ (本问接下来的计算不做要求:为计算回归系数的标准误差,根据离差平方和分解,可知:2222222[()()]ˆˆˆˆˆˆ()[()()]()()334229.09262811.68425053.73i i i iiix x y y SSR y y x x x x x x αβαββ--=-=+-+=-=-==∑∑∑∑∑22ˆ()()262855.25262811.6843.57i i SSE SST SSR y y yy =-=---=-=∑∑因此有ˆ()0.0032S β===≈) (3)陈述假设:01:0 :0H H ββ=≠在原假设成立的前提下,构造t 检验统计量245.598t ===在5%的双侧检验显著性水平下,查自由度为10的t 分布表,得临界值0.025(10) 2.228t t =<,因此拒绝原假设。
统计学课后习题答案第七章相关分析与回归分析

统计学课后习题答案第七章相关分析与回归分析第七章相关分析与回归分析⼀、单项选择题1.相关分析是研究变量之间的A.数量关系B.变动关系C.因果关系D.相互关系的密切程度2.在相关分析中要求相关的两个变量A.都是随机变量B.⾃变量是随机变量C.都不是随机变量D.因变量是随机变量3.下列现象之间的关系哪⼀个属于相关关系A.播种量与粮⾷收获量之间关系B.圆半径与圆周长之间关系C.圆半径与圆⾯积之间关系D.单位产品成本与总成本之间关系4.正相关的特点是A.两个变量之间的变化⽅向相反B.两个变量⼀增⼀减C.两个变量之间的变化⽅向⼀致D.两个变量⼀减⼀增5.相关关系的主要特点是两个变量之间A.存在着确定的依存关系B.存在着不完全确定的关系C.存在着严重的依存关系D.存在着严格的对应关系6.当⾃变量变化时, 因变量也相应地随之等量变化,则两个变量之间存在着A.直线相关关系B.负相关关系C.曲线相关关系D.正相关关系7.当变量X值增加时,变量Y值都随之下降,则变量X和Y之间存在着A.正相关关系B.直线相关关系C.负相关关系D.曲线相关关系8.当变量X值增加时,变量Y值都随之增加,则变量X和Y之间存在着A.直线相关关系B.负相关关系C.曲线相关关系D.正相关关系9.判定现象之间相关关系密切程度的最主要⽅法是A.对现象进⾏定性分析B.计算相关系数C.编制相关表D.绘制相关图10.相关分析对资料的要求是A.⾃变量不是随机的,因变量是随机的B.两个变量均不是随机的C.⾃变量是随机的,因变量不是随机的D.两个变量均为随机的11.相关系数A.既适⽤于直线相关,⼜适⽤于曲线相关B.只适⽤于直线相关C.既不适⽤于直线相关,⼜不适⽤于曲线相关D.只适⽤于曲线相关12.两个变量之间的相关关系称为A.单相关B.复相关C.不相关D.负相关13.相关系数的取值范围是≤r≤1 ≤r≤0≤r≤1 D. r=014.两变量之间相关程度越强,则相关系数A.愈趋近于1B.愈趋近于0C.愈⼤于1D.愈⼩于115.两变量之间相关程度越弱,则相关系数A.愈趋近于1B.愈趋近于0C.愈⼤于1D.愈⼩于116.相关系数越接近于-1,表明两变量间A.没有相关关系B.有曲线相关关系C.负相关关系越强D.负相关关系越弱17.当相关系数r=0时,A.现象之间完全⽆关B.相关程度较⼩B.现象之间完全相关 D.⽆直线相关关系18.假设产品产量与产品单位成本之间的相关系数为,则说明这两个变量之间存在A.⾼度相关B.中度相关C.低度相关D.显着相关19.从变量之间相关的⽅向看可分为A.正相关与负相关B.直线相关和曲线相关C.单相关与复相关D.完全相关和⽆相关20.从变量之间相关的表现形式看可分为A.正相关与负相关B.直线相关和曲线相关C.单相关与复相关D.完全相关和⽆相关21.物价上涨,销售量下降,则物价与销售量之间属于A.⽆相关B.负相关C.正相关D.⽆法判断22.配合回归直线最合理的⽅法是A.随⼿画线法B.半数平均法C.最⼩平⽅法D.指数平滑法23.在回归直线⽅程y=a+bx中b表⽰A.当x增加⼀个单位时,y增加a的数量B.当y增加⼀个单位时,x增加b的数量C.当x增加⼀个单位时,y的平均增加量D.当y增加⼀个单位时, x的平均增加量24.计算估计标准误差的依据是A.因变量的数列B.因变量的总变差C.因变量的回归变差D.因变量的剩余变差25.估计标准误差是反映A.平均数代表性的指标B.相关关系程度的指标C.回归直线的代表性指标D.序时平均数代表性指标26.在回归分析中,要求对应的两个变量A.都是随机变量B.不是对等关系C.是对等关系D.都不是随机变量27.年劳动⽣产率(千元)和⼯⼈⼯资(元)之间存在回归⽅程y=10+70x,这意味着年劳动⽣产率每提⾼⼀千元时,⼯⼈⼯资平均A.增加70元B.减少70元C.增加80元D.减少80元28.设某种产品产量为1000件时,其⽣产成本为30000元,其中固定成本6000元,则总⽣产成本对产量的⼀元线性回归⽅程为:=6+ =6000+24x=24000+6x =24+6000x29.⽤来反映因变量估计值代表性⾼低的指标称作A.相关系数B.回归参数C.剩余变差D.估计标准误差⼆、多项选择题1.下列现象之间属于相关关系的有A.家庭收⼊与消费⽀出之间的关系B.农作物收获量与施肥量之间的关系C.圆的⾯积与圆的半径之间的关系D.⾝⾼与体重之间的关系E.年龄与⾎压之间的关系2.直线相关分析的特点是A.相关系数有正负号B.两个变量是对等关系C.只有⼀个相关系数D.因变量是随机变量E.两个变量均是随机变量3.从变量之间相互关系的表现形式看,相关关系可分为A.正相关B.负相关C.直线相关D.曲线相关E.单相关和复相关4.如果变量x与y之间没有线性相关关系,则A.相关系数r=0B.相关系数r=1C.估计标准误差等于0D.估计标准误差等于1E.回归系数b=05.设单位产品成本(元)对产量(件)的⼀元线性回归⽅程为y=,则A.单位成本与产量之间存在着负相关B.单位成本与产量之间存在着正相关C.产量每增加1千件,单位成本平均增加元D.产量为1千件时,单位成本为元E.产量每增加1千件,单位成本平均减少元6.根据变量之间相关关系的密切程度划分,可分为A.不相关B.完全相关C.不完全相关D.线性相关E.⾮线性相关7.判断现象之间有⽆相关关系的⽅法有A.对现象作定性分析B.编制相关表C.绘制相关图D.计算相关系数E.计算估计标准误差 8.当现象之间完全相关的,相关系数为 B.-1 E.- 9.相关系数r =0说明两个变量之间是A.可能完全不相关B.可能是曲线相关C.肯定不线性相关D.肯定不曲线相关E.⾼度曲线相关10.下列现象属于正相关的有A.家庭收⼊愈多,其消费⽀出也愈多B.流通费⽤率随商品销售额的增加⽽减少C.产量随⽣产⽤固定资产价值减少⽽减少D.⽣产单位产品耗⽤⼯时,随劳动⽣产率的提⾼⽽减少E.⼯⼈劳动⽣产率越⾼,则创造的产值就越多 11.直线回归分析的特点有A.存在两个回归⽅程B.回归系数有正负值C.两个变量不对等关系D.⾃变量是给定的,因变量是随机的E.利⽤⼀个回归⽅程,两个变量可以相互计算 12.直线回归⽅程中的两个变量A.都是随机变量B.都是给定的变量C.必须确定哪个是⾃变量,哪个是因变量D.⼀个是随机变量,另⼀个是给定变量E.⼀个是⾃变量,另⼀个是因变量13.从现象间相互关系的⽅向划分,相关关系可以分为A.直线相关B.曲线相关C.正相关D.负相关E.单相关 14.估计标准误差是A.说明平均数代表性的指标B.说明回归直线代表性指标C.因变量估计值可靠程度指标D.指标值愈⼩,表明估计值愈可靠E.指标值愈⼤,表明估计值愈可靠 15.下列公式哪些是计算相关系数的公式16.⽤最⼩平⽅法配合的回归直线,必须满⾜以下条件A.?(y-y c )=最⼩值B.?(y-y c )=0C.?(y-y c )2=最⼩值D.?(y-y c )2=0E.?(y-y c )2=最⼤值 17.⽅程y c =a+bx222222)()(.)()())((...))((.y y n x x n yx xy n r E y y x x y y x x r D L L L r C L L L r B n y y x x r A xxxy xyyy xx xy y x ∑-∑?∑-∑∑?∑-∑=-∑?-∑--∑===--∑=σσA.这是⼀个直线回归⽅程B.这是⼀个以X为⾃变量的回归⽅程C.其中a是估计的初始值D.其中b是回归系数是估计值18.直线回归⽅程y c=a+bx中的回归系数bA.能表明两变量间的变动程度B.不能表明两变量间的变动程度C.能说明两变量间的变动⽅向D.其数值⼤⼩不受计量单位的影响E. 其数值⼤⼩受计量单位的影响19.相关系数与回归系数存在以下关系A.回归系数⼤于零则相关系数⼤于零B.回归系数⼩于零则相关系数⼩于零C.回归系数等于零则相关系数等于零D.回归系数⼤于零则相关系数⼩于零E.回归系数⼩于零则相关系数⼤于零20.配合直线回归⽅程的⽬的是为了A.确定两个变量之间的变动关系B.⽤因变量推算⾃变量C.⽤⾃变量推算因变量D.两个变量相互推算E.确定两个变量之间的相关程度21.若两个变量x和y之间的相关系数r=1,则A.观察值和理论值的离差不存在的所有理论值同它的平均值⼀致和y是函数关系与y不相关与y是完全正相关22.直线相关分析与直线回归分析的区别在于A.相关分析中两个变量都是随机的;⽽回归分析中⾃变量是给定的数值,因变量是随机的B.回归分析中两个变量都是随机的;⽽相关分析中⾃变量是给定的数值,因变量是随机的C.相关系数有正负号;⽽回归系数只能取正值D.相关分析中的两个变量是对等关系;⽽回归分析中的两个变量不是对等关系E.相关分析中根据两个变量只能计算出⼀个相关系数;⽽回归分析中根据两个变量只能计算出⼀个回归系数三、填空题1.研究现象之间相关关系称作相关分析。
统计学高教版相关与回归分析课后习题答案
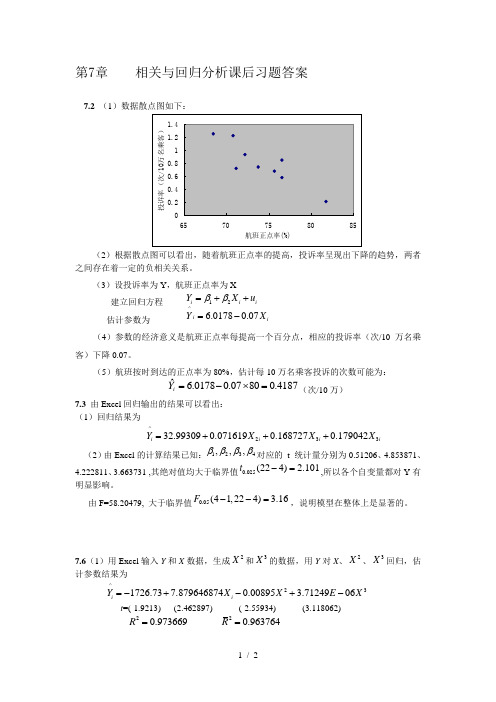
第7章 相关与回归分析课后习题答案7.2 (1)数据散点图如下:(2)根据散点图可以看出,随着航班正点率的提高,投诉率呈现出下降的趋势,两者之间存在着一定的负相关关系。
(3)设投诉率为Y ,航班正点率为X建立回归方程 12i i i Y X u ββ=++估计参数为 ^6.01780.07i i Y X =-(4)参数的经济意义是航班正点率每提高一个百分点,相应的投诉率(次/10万名乘客)下降0.07。
(5)航班按时到达的正点率为80%,估计每10万名乘客投诉的次数可能为: 4187.08007.00178.6ˆ=⨯-=i Y (次/10万)7.3 由Excel 回归输出的结果可以看出:(1)回归结果为^23332.993090.0716190.1687270.179042i i i i Y X X X =+++(2)由Excel 的计算结果已知:1234,,,ββββ对应的 t 统计量分别为0.51206、4.853871、4.222811、3.663731 ,其绝对值均大于临界值0.025(224) 2.101t -=,所以各个自变量都对Y 有明显影响。
由F=58.20479, 大于临界值0.05(41,224) 3.16F --=,说明模型在整体上是显著的。
7.6(1)用Excel 输入Y 和X 数据,生成2X 和3X 的数据,用Y 对X 、2X 、3X 回归,估计参数结果为^231726.737.8796468740.00895 3.7124906i i Y X X E X =-+-+- t =(-1.9213) (2.462897) (-2.55934) (3.118062)20.973669R = 20.963764R =(2)检验参数的显著性:当取0.05α=时,查t 分布表得0.025(124) 2.306t -=,与t 统计量对比,除了截距项外,各回归系数对应的t 统计量的绝对值均大于临界值,表明在这样的显著性水平下,回归系数显著不为0。
《统计学概论》第七章课后练习题答案

《统计学概论》第七章课后练习题答案一、思考题1.抽样推断的意义和作用是什么?2.抽样推断的特点是什么?3.为什么抽样调查要遵循随机原则?4.总体参数与样本统计各有什么特点?5.为什么区间估计比点估计优越?6.样本平均误差的定义就是什么?它存有什么关键意义?7.影响样本平均误差的因素存有哪些?8.优良估计量的衡量标准存有哪些?9置信区间、置信度、概率度之间的关系怎样?10.区间估计的原理是什么?11.为什么说道在n紧固的情况下参数区间估算的精确度和可靠性就是此消彼长的?12.怎样同时提升区间估算的精确度和可靠性?13.影响样本音速误差的因素存有哪些?14.怎样正确理解样本音速误差的概念?15.确认样本容量的因素存有哪些?16.样本方案设计的基本原则就是什么?17.怎样认知类型样本的原理和意义?18.等距样本的原理和意义就是什么?19.整群抽样的原理以及与类型抽样的区别是什么?二、单项选择题1.以()为基础理论的统计调查方法就是抽样调查法。
a.高等代数b.微分几何c.概率论d.博弈论2.典型调查与抽样调查的相同之处为()。
a.均遵守随机原则b.以部分推断总体c.误差均可估计d.误差均可控制3.抽样推断必须遵守的首要原则是()。
a.大量性原则b.随机原则c.可比性原则d.总体性原则4.既可进行点估计又可进行区间估计的是()。
a.重点调查b.典型调查c.普查d.抽样调查5.误差可以计算并加以控制的是()。
a.抽样调查b.普查c.典型调查d.重点调查6.()可以对于某种总体的假设展开检验。
a.回归分析法b.抽样推断法c.综合指数法d.加权平均法7.以下正确的是()。
a.总体指标与样本指标均为随机变量b.总体指标与样本指标均为常数c.总体指标是常数而样本指标是随机变量d.总体指标是随机变量而样本指标是常数8.总体属性变量平均数恰等于()。
a.1-pb.pc.p(1-p)d.p(1?p)9.总体属性变量的方差等于()。
第七章相关与回归分析习题答案.doc

334229.09425053.730.7863334229.0922.0889V425053.73=0.003204 245.4120第七章相关与回归分析习题答案一、填空题1.完全相关、不完全相关、不相关2. —iWrWl3.函数、|r| = l4.无线性相关、完全正相关、完全负相关5.密切程度6.正相关、负相关7.直线相关、曲线相关8.回归系数9.随机的、给定的10.最小二乘法,残差平方和二、 单项选择题I. B 2. B 3. A 4. A 5. B 6. C 7. D 8. B9. A 10. CII. C 12. B 13. D 14. B 15. C三、 多项选择题1. BCD2. ACD3. ABD4. ABCD5. ACE四、 计算题1解:B\=V - p 2x = 549.8 - 0.7863 * 647.88 = 40.37202 _ [£ (匕顼(X,侦)]2 '"£(x,-x )2£(y,-y )20.999834425053.73*262855.25 ;2=(1-产切 _y )2 =43.6340= 2.0889 n — 2(3) H°:”2=0,H I :”2 邳腐 _ 0.7863~S~ ~ 0.003204〃2券(〃-2)=诲(10) = 2.228t 值远大于临界值2.228,故拒绝零假设,说明月在5%的显著性水平下通过了显著性 检验。
(4) Y f =40.3720 + 0.7863*800 = 669.41 (万元)0.0273 S' =S l + 厂 Xf =2.0089」1 + 土 +华°「647・88)2 = 2 1429 所以,Yf 的置信度为 7V n Z (X,-X )2 V 12 425053.73 95 %的预测区间为:Y f ±t a/2(n-2)S ef = 669.41 ±2.228* 1.0667 = 669.41 ±2.3767 所以,区间预测为: 664.64 < Y f <674.182解:A _ £(匕一双%一灭)—N £X ,E —£x,£匕) 乃一 Z (x,一文尸一 (£x )9*803.02-13.54*472 八= ------------------------------------ =0.02739*28158-472*472& = Y-$2X =13.54/9-0.0273 * 472/9 = 0.0727(2)决定系数: , [y (y-F )(x-%)]2 r 2 =¥,_ 盘——;=0.9723Z (x,-x )Na-V )-残差平方和^<=(l-r 2)^(y-y )2 =0.0722 (3)身高与体重的相关系数: r =序=J0.9723 = 0.9861H O :A = A = O ,H 1:A W 2不同时为零厂。
统计学第七章、第八章课后题答案

统计学复习笔记第七章 参数估计一、 思考题1. 解释估计量和估计值在参数估计中,用来估计总体参数的统计量称为估计量。
估计量也是随机变量。
如样本均值,样本比例、样本方差等。
根据一个具体的样本计算出来的估计量的数值称为估计值。
2. 简述评价估计量好坏的标准(1)无偏性:是指估计量抽样分布的期望值等于被估计的总体参数。
(2)有效性:是指估计量的方差尽可能小。
对同一总体参数的两个无偏估计量,有更小方差的估计量更有效。
(3)一致性:是指随着样本量的增大,点估计量的值越来越接近被估总体的参数。
3. 怎样理解置信区间在区间估计中,由样本统计量所构造的总体参数的估计区间称为置信区间。
置信区间的论述是由区间和置信度两部分组成。
有些新闻媒体报道一些调查结果只给出百分比和误差(即置信区间),并不说明置信度,也不给出被调查的人数,这是不负责的表现。
因为降低置信度可以使置信区间变窄(显得“精确”),有误导读者之嫌。
在公布调查结果时给出被调查人数是负责任的表现。
这样则可以由此推算出置信度(由后面给出的公式),反之亦然。
4. 解释95%的置信区间的含义是什么置信区间95%仅仅描述用来构造该区间上下界的统计量(是随机的)覆盖总体参数的概率。
也就是说,无穷次重复抽样所得到的所有区间中有95%(的区间)包含参数。
不要认为由某一样本数据得到总体参数的某一个95%置信区间,就以为该区间以0.95的概率覆盖总体参数。
5. 简述样本量与置信水平、总体方差、估计误差的关系。
1. 估计总体均值时样本量n 为2. 样本量n 与置信水平1-α、总体方差、估计误差E 之间的关系为 其中: 2222α2222)(E z n σα=n z E σα2=▪ 与置信水平成正比,在其他条件不变的情况下,置信水平越大,所需要的样本量越大;▪ 与总体方差成正比,总体的差异越大,所要求的样本量也越大;▪ 与与总体方差成正比,样本量与估计误差的平方成反比,即可以接受的估计误差的平方越大,所需的样本量越小。