聚类分析实验报告记录
聚类分析实验报告

聚类分析实验报告一、实验目的:通过聚类分析方法,对给定的数据进行聚类,并分析聚类结果,探索数据之间的关系和规律。
二、实验原理:聚类分析是一种无监督学习方法,将具有相似特征的数据样本归为同一类别。
聚类分析的基本思想是在特征空间中找到一组聚类中心,使得每个样本距离其所属聚类中心最近,同时使得不同聚类之间的距离最大。
聚类分析的主要步骤有:数据预处理、选择聚类算法、确定聚类数目、聚类过程和聚类结果评价等。
三、实验步骤:1.数据预处理:将原始数据进行去噪、异常值处理、缺失值处理等,确保数据的准确性和一致性。
2.选择聚类算法:根据实际情况选择合适的聚类算法,常用的聚类算法有K均值算法、层次聚类算法、DBSCAN算法等。
3.确定聚类数目:根据数据的特征和实际需求,确定合适的聚类数目。
4.聚类过程:根据选定的聚类算法和聚类数目进行聚类过程,得到最终的聚类结果。
5. 聚类结果评价:通过评价指标(如轮廓系数、Davies-Bouldin指数等),对聚类结果进行评价,判断聚类效果的好坏。
四、实验结果:根据给定的数据集,我们选用K均值算法进行聚类分析。
首先,根据数据特点和需求,我们确定聚类数目为3、然后,进行数据预处理,包括去噪、异常值处理和缺失值处理。
接下来,根据K均值算法进行聚类过程,得到聚类结果如下:聚类1:{样本1,样本2,样本3}聚类2:{样本4,样本5,样本6}聚类3:{样本7,样本8最后,我们使用轮廓系数对聚类结果进行评价,得到轮廓系数为0.8,说明聚类效果较好。
五、实验分析和总结:通过本次实验,我们利用聚类分析方法对给定的数据进行了聚类,并进行了聚类结果的评价。
实验结果显示,选用K均值算法进行聚类分析,得到了较好的聚类效果。
实验中还发现,数据预处理对聚类分析结果具有重要影响,必要的数据清洗和处理工作是确保聚类结果准确性的关键。
此外,聚类数目的选择也是影响聚类结果的重要因素,过多或过少的聚类数目都会造成聚类效果的下降。
模糊聚类分析实验报告
实验报告(一)一、实验内容模糊聚类在土地利用分区中的应用二、实验目的本次上机实习主要以指导学生掌握“如何应用模糊聚类方法进行土地利用规划分区”为目标。
三、实验方法本次试验是在Excel中实现。
利用《土地利用规划学》P114页数据,使用“欧氏距离法”、建模糊相似矩阵,并进行模糊聚类分析实现土地利用分区。
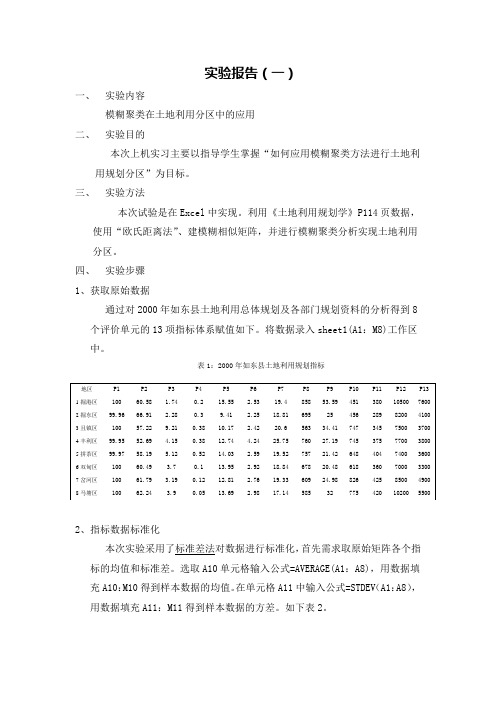
四、实验步骤1、获取原始数据通过对2000年如东县土地利用总体规划及各部门规划资料的分析得到8个评价单元的13项指标体系赋值如下。
将数据录入sheet1(A1:M8)工作区中。
表1:2000年如东县土地利用规划指标2、指标数据标准化本次实验采用了标准差法对数据进行标准化,首先需求取原始矩阵各个指标的均值和标准差。
选取A10单元格输入公式=AVERAGE(A1:A8),用数据填充A10:M10得到样本数据的均值。
在单元格A11中输入公式=STDEV(A1:A8),用数据填充A11:M11得到样本数据的方差。
如下表2。
表2:13个指标值得均值和标准差选取A13单元格输入公式=(A1-A$10)/A$11,并用数据填充A13:M20区域得到标准化矩阵如下表3。
表3:标准化数据矩阵3、求取模糊相似矩阵本次试验是通过欧氏距离法求取模糊相似矩阵。
其数学模型为:mr ij=1−c√∑(x ik−x jk)2k=1选取A23单元格输入公式=SQRT((A$13-A13)^2+(B$13-B13)^2+(C$13-C13)^2+(D$13-D13)^2+(E$13-E13)^2+(F$13-F13)^2+(G$13-G13)^2+(H$13-H13)^2+(I$13-I13)^2+(J$13-J13)^2+(K$13-K13)^2+(L$13-L13)^2+(M$13-M13)^2)求的d11,B23中输入公式=SQRT((A$14-A13)^2+(B$14-B13)^2+(C$14-C13)^2+(D$14-D13)^2+(E$14-E13)^2+(F$14-F13)^2+(G$14-G13)^2+(H$14-H13)^2+(I$14-I13)^2+(J$14-J13)^2+(K$14-K13)^2+(L$14-L13)^2+(M$14-M13)^2)q 求的d12。
《系统工程》聚类分析实验报告

40
22.518
0
0
25
20
10
13
22.555
13
17
22
21
19
23
22.598
16
14
31
22
10
30
24.485
20
0
24
23
6
9
26.682
0
0
25
24
7
10
27.548
0
22
26
25
6
12
30.848
23
19
28
26
3
7
32.276
0
24
28
27
4
29
32.492
0
0
29
28
3
6
34.821
0
11
10
13
27
12.894
4
6
12
11
17
37
14.224
9
0
12
12
13
17
15.818
10
11
17
13
10
15
16.179
0
0
20
14
23
28
16.547
0
0
21
15
19
22
16.718
8
0
16
16
19
33
20.091
15
0
21
17
13
26
20.703
12
0
20
聚类分析算法实验报告(3篇)

第1篇一、实验背景聚类分析是数据挖掘中的一种重要技术,它将数据集划分成若干个类或簇,使得同一簇内的数据点具有较高的相似度,而不同簇之间的数据点则具有较低相似度。
本实验旨在通过实际操作,了解并掌握聚类分析的基本原理,并对比分析不同聚类算法的性能。
二、实验环境1. 操作系统:Windows 102. 软件环境:Python3.8、NumPy 1.19、Matplotlib 3.3.4、Scikit-learn0.24.03. 数据集:Iris数据集三、实验内容本实验主要对比分析以下聚类算法:1. K-means算法2. 聚类层次算法(Agglomerative Clustering)3. DBSCAN算法四、实验步骤1. K-means算法(1)导入Iris数据集,提取特征数据。
(2)使用Scikit-learn库中的KMeans类进行聚类,设置聚类数为3。
(3)计算聚类中心,并计算每个样本到聚类中心的距离。
(4)绘制聚类结果图。
2. 聚类层次算法(1)导入Iris数据集,提取特征数据。
(2)使用Scikit-learn库中的AgglomerativeClustering类进行聚类,设置链接方法为'ward'。
(3)计算聚类结果,并绘制树状图。
3. DBSCAN算法(1)导入Iris数据集,提取特征数据。
(2)使用Scikit-learn库中的DBSCAN类进行聚类,设置邻域半径为0.5,最小样本数为5。
(3)计算聚类结果,并绘制聚类结果图。
五、实验结果与分析1. K-means算法实验结果显示,K-means算法将Iris数据集划分为3个簇,每个簇包含3个样本。
从聚类结果图可以看出,K-means算法能够较好地将Iris数据集划分为3个簇,但存在一些噪声点。
2. 聚类层次算法聚类层次算法将Iris数据集划分为3个簇,与K-means算法的结果相同。
从树状图可以看出,聚类层次算法在聚类过程中形成了多个分支,说明该算法能够较好地处理不同簇之间的相似度。
聚类的实验报告

一、实验目的1. 理解聚类算法的基本原理和过程。
2. 掌握K-means算法的实现方法。
3. 学习如何使用聚类算法对数据集进行有效划分。
4. 分析不同聚类结果对实际应用的影响。
二、实验环境1. 操作系统:Windows 102. 编程语言:Python3. 库:NumPy、Matplotlib、Scikit-learn三、实验内容本次实验主要使用K-means算法对数据集进行聚类,并分析不同参数设置对聚类结果的影响。
1. 数据集介绍实验所使用的数据集为Iris数据集,该数据集包含150个样本,每个样本包含4个特征(花瓣长度、花瓣宽度、花萼长度、花萼宽度),以及对应的分类标签(Iris-setosa、Iris-versicolor、Iris-virginica)。
2. K-means算法原理K-means算法是一种基于距离的聚类算法,其基本思想是将数据集中的对象划分为K个簇,使得每个对象与其所属簇的质心(即该簇中所有对象的平均值)的距离最小。
3. 实验步骤(1)导入数据集首先,使用NumPy库导入Iris数据集,并提取特征值和标签。
(2)划分簇使用Scikit-learn库中的KMeans类进行聚类,设置聚类个数K为3。
(3)计算聚类结果计算每个样本与对应簇质心的距离,并将样本分配到最近的簇。
(4)可视化结果使用Matplotlib库将聚类结果可视化,展示每个样本所属的簇。
(5)分析不同参数设置对聚类结果的影响改变聚类个数K,观察聚类结果的变化,分析不同K值对聚类效果的影响。
四、实验结果与分析1. 初始聚类结果当K=3时,K-means算法将Iris数据集划分为3个簇,如图1所示。
图1 K=3时的聚类结果从图1可以看出,K-means算法成功地将Iris数据集划分为3个簇,每个簇对应一个Iris物种。
2. 不同K值对聚类结果的影响(1)当K=2时,K-means算法将Iris数据集划分为2个簇,如图2所示。
聚类分析实习报告

聚类分析实习报告(经典版)编制人:__________________审核人:__________________审批人:__________________编制单位:__________________编制时间:____年____月____日序言下载提示:该文档是本店铺精心编制而成的,希望大家下载后,能够帮助大家解决实际问题。
文档下载后可定制修改,请根据实际需要进行调整和使用,谢谢!并且,本店铺为大家提供各种类型的经典范文,如报告总结、演讲发言、活动方案、条据文书、合同协议、心得体会、社交礼仪、教学资料、作文大全、其他范文等等,想了解不同范文格式和写法,敬请关注!Download tips: This document is carefully compiled by this editor. I hope that after you download it, it can help you solve practical problems. The document can be customized and modified after downloading, please adjust and use it according to actual needs, thank you!Moreover, our store provides various types of classic sample essays, such as report summaries, speeches, activity plans, written documents, contract agreements, personal experiences, social etiquette, teaching materials, complete essays, and other sample essays. If you want to learn about different sample formats and writing methods, please stay tuned!聚类分析实习报告聚类分析是一种常用的数据分析技术,能够将一组相似的样本数据分为若干个不同的类别或簇。
实验报告 聚类分析

实验四聚类分析实验要求:选取一组有实际意义的数据,利用SAS的五种系统聚类方法将n个样本进行分类,要求:1)说明每一种方法的分类结果;2)利用主成分分析说明哪一种分类结果更合理。
实验目的:学会利用SAS语言编写程序以实现聚类分析过程。
实验过程与结果分析:我们仍对实验一的数据集chengshi(2006年各省市主要城市建设水平指标年度统计数据)进行聚类分析。
第一步:编写SAS程序。
proc cluster data=chengshi method=single outtree=tree1;id region;proc tree data=tree1 horizontal graphics;id region;run;proc cluster data=chengshi method=complete outtree=tree2;id region;proc tree data=tree2 horizontal graphics;id region;run;proc cluster data=chengshi method=centroid outtree=tree3;id region;proc tree data=tree3 horizontal graphics;id region;run;proc cluster data=chengshi method=average outtree=tree4;id region;proc tree data=tree4 horizontal graphics;id region;run;proc cluster data=chengshi method=ward outtree=tree5;id region;proc tree data=tree5 horizontal graphics;id region;run;第二步: 将数据集提交运行,运行结果见图1-图10;图1 利用最小距离法所得到的树状分类图图2 最小距离法的聚类过程图3 利用最大距离法所得到的树状分类图图4 最大距离法的聚类过程图5 利用重心法所得到的树状分类图图6 重心法的聚类过程图7 利用平均距离法所得到的树状分类图图8 平均距离法的聚类过程图9 利用离差平方和法所得到的树状分类图图10 离差平方和法的聚类过程第三步:对输出的结果进行分析。
《多元统计实验》---聚类分析实验报告二

《多元统计实验》---聚类分析实验报告
rownames(ex4)=ex4.4[,1]
KM<-kmeans(ex4,4,nstart = 20,algorithm = "Hartigan-Wong")
KM
sort(KM$cluster)
三、实验结果分析:
第一题:
如下图为20种啤酒最小距离法系统聚类树状图,当取合并距离为20时,20种啤酒可以分为3类,第一类为{16,19},第二类为{10,12,9,20},第三类为{2,7,4,3,5,15,13,14,8,17,11,1,6,18}。
如下图为20种啤酒最大距离法系统聚类树状图,如果将啤酒分为4类,则第一类为{16,19},第二类{10,12,9,20},第三类{4,2,7},第四类{13,17,11,8,6,18,5,15,3,14},即蓝色框出。
如下截图为当20种啤酒分为3类是的最大距离法聚类出的结果,即分为{1,3,5,6,8,11,13,14,15,17,18}、{2,4,7}、{9,10,12,16,19,20}。
第二题:
如下截图,31个地区被聚成大小为4、3、16、8的四个类,means表示各类均值,
如下截图得出的结果,按地区原顺序聚类后的分类情况以及类间平方和在总平方和中的占比为79.7%,分类结果为:
第一类:天津、江苏、福建、广东
第二类:北京、上海、浙江
第三类:河北、山西、辽宁、吉林、黑龙江、山东、河南、广西、贵州、云南、西藏、陕西、甘肃、青海、宁夏、新疆
第四类:内蒙古、安徽、江西、湖北、湖南、海南、重庆、四川。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
聚类分析实验报告记录————————————————————————————————作者:————————————————————————————————日期:《应用多元统计分析》课程实验报告实验名称:用聚类分析的方法研究山东省17个市的产业类型的差异化学生班级:统计0901学生姓名:贾绪顺杜春霖陈维民张鹏指导老师:____________张艳丽_____________________完成日期:2011.12.12一,实验内容根据聚类分析的原理,使用系统聚类分析的COMplete linkage (最长距离法)和WARD(离差平方和法),运用SPSS软件对2009年山东省17个城市生产总值的数据进行Q型聚类,将17个城市分为5类,发现不同城市产业类型的差异化,并解释造成这种差异的原因二,实验目的希望通过实验研究山东省17个市的生产总值的差异化,并分析造成这种差异化的原因,可以更深刻的掌握聚类分析的原理;进一步熟悉聚类分析问题的提出、解决问题的思路、方法和技能;达到能综合运用所学基本理论和专业知识;锻炼收集、整理、运用资料的能力的目的;希望能会调用SPSS软件聚类分析有关过程命令,并且可以对数据处理结果进行正确判断分析,作出综合评价。
三,实验方法背景与原理3.1方法背景聚类分析又称群分析,是多元统计分析中研究样本或指标的一种主要的分类方法,在古老的分类学中,人们主要靠经验和专业知识,很少利用数学方法。
随着生产技术和科学的发展,分类越来越细,以致有时仅凭经验和专业知识还不能进行确切分类,于是数学这个有用的工具逐渐被引进到分类学中,形成了数值分类学。
近些年来,数理统计的多元分析方法有了迅速的发展,多元分析的技术自然被引用到分类学中,于是从数值分类学中逐渐的分离出聚类分析这个新的分支。
结合了更为强大的数学工具的聚类分析方法已经越来越多应用到经济分析和社会工作分析中。
在经济领域中,主要是根据影响国家、地区及至单个企业的经济效益、发展水平的各项指标进行聚类分析,然后很据分析结果进行综合评价,以便得出科学的结论。
聚类分析源于很多领域,包括数学,计算机科学,统计学,生物学和经济学。
在不同的应用领域,很多聚类技术都得到了发展,这些技术方法被用作描述数据,衡量不同数据源间的相似性,以及把数据源分类到不同的簇中。
聚类分析的主要应用,在商业方面,最常见的就是客户群的细分问题,可以从客户人口特征、消费行为和喜好方面的数据,对客户进行特征分析,充分利用数据进行客户的客观分组,使诸多特征有相似性的客户能被分在同一组内,而不相似的客户能被区分到另一些组中。
在生物方面,聚类分析可以用来对动植物进行分类,对基因进行分类等,从而获取对动植物种群固有结构的认识,对物种进行很好的分类。
在电子商务方面,聚类分析在电子商务中网站建设数据挖掘中也是很重要的一个方面,通过对客户的浏览行为、浏览网站、客户的年龄等,对客户进行分析,找出不同客户的共同特征,通过共同特征对客户进行分类,可以帮助电子商户更好的了解他们的客户,并向客户提供更合适的服务。
在保险行业上,根据产、寿险进行分类,不同类别的公司进行分类,对保险投资比例进行分类管理,从而提高保险投资的效率。
3.2实验的方法与原理聚类分析是研究“物以类聚”的一种科学有效的方法。
做聚类分析时,出于不同的目的和要求,可以选择不同的统计量和聚类方法。
聚类分析方法中最常用的一种是系统聚类法,其基本思想是:先将待聚类的n个样品(或者变量)各自看成一类,共有n类;然后按照选定的方法计算每两类之间的聚类统计量,即某种距离(或者相似系数),将关系最为密切的两类合为一类,其余不变,即得到n-1类;再按照前面的计算方法计算新类与其他类之间的距离(或相似系数),再将关系最为密切的两类并为一类,其余不变,即得到n-2类;如此下去,每次重复都减少一类,直到最后所有的样品(或者变量)都归为一类为止。
系统聚类分析有两种类型:Q 型样本聚类和R 型变量聚类。
这里我们运用的是Q 型聚类。
Q 型聚类是对样本进行聚类,它使具有相似特征的样本聚集在一起,使差异性大的样本分离开来。
本实验中,分别采用最长距离法和离差平方和法对样本进行分类。
方法一:用最长距离对样本进行分类个体与小类间的最长距离是该个体与小类每个个体距离的最大值 在聚类分析前,首先把数据进行标准化变换()n j n i R x x x jjij ij ,,2,1,,,2,1ΛΛ==-=*,变换后的数据,每个变量样本均值为0,标准差为1,而且标准化变换后的数据{}*ij x 与变量的量纲无关。
采用系统聚类的方法,用最长距离法计算欧氏距离()n j i x x d mi jtit ij ,,2,1,12Λ=-=∑=,其中it x 表示第i 个样品的第t 个指标的观测值,jt x 表示第j 个样品的第t 个指标的观测值,ij d 为第i 个样品与第j 个样品之间的欧式距离。
若ij d 越小,那么第i 与j 两个样品之间的性质就越接近。
最长距离法求类与类之间的距离,设类p G 和q G 合并r G 后,按照最长距离计算新类r G 与k G 其他类的类间距离,其递推公式为{}(){}{}(),,,max ,=maxmax ,max =max ,,r kp kq krk ij r p q ij ij pk qk i G j G i G j G i G j G D d G G G d d D D k p q ∈∈∈∈∈∈==≠方法二:用离差平方和法(WARD )对样品进行分类离差平方和法是Ward (1936)提出的,也称为Ward 法。
它基于方差分析思想,如果类分得正确,则同类样品之间的离差平方和应当较小,不同类样品之间的离差平方和应当较大。
假定已将n 个样品分为k 类,记为1G ,2G ,…,k G ,t n 表示t G 类的样品个数,(t)X表示t G 的重心,(t )i X ()表示t G 中第i 个样品(i=1,…,t n ),则t G 中样品的离差平方和为 ()()tn (t)(t)(t)(t)t i i 1=i W X X X X='--∑()(), 其中(t )i X (),(t)X为m 维向量,t W 为一数值(t=1,2,…,k )。
k 个类的总离差平方和为()()tn kk(t)(t)(t)(t)t i i t=1t=11==i W W X X X X ='--∑∑∑()().当k 固定时,要选择使W 达到极小的分类。
Ward 法的基本思想是,先将n 个样品各自成一类,此时W =0;然后每次将其中某两类合并为一类,因每缩小一类离差平方和就要增加,每次选择使W 增加最小的两类进行合并,直至所有样品合并为一类为止。
Ward 法把某两类合并后增加的离差平方和看成为类间的平方距离,即令()2pq r p q =D W W W -+表示类p G 和q G 的平方距离,其中{},r p q G G G =,r W ,p W ,q W 分别为r G ,p G ,q G 类中样品的离差平方和。
利用r W 的定义,可得()()rn (r)(r)(r)(r)r t t t 1=W X X X X='--∑()()()()()()pqn n (p)(r)(p)(r)(q)(r)(q)(r)i i i i i 1i 1=XXX X X X X X==''--+--∑∑()()()(), 其中1r p q p q rXn X n X n ()()()⎡⎤=+⎣⎦.经整理可得 ()()2p q p q p q pq rn n D XX X X n ()()()()'=--.当样品间距离采用欧氏距离时,上式可表为22p q pqpqrn n D d n =, 其中2pq d 表示,p q G G 的重心p X()与q X()的平方距离:()22,p q pq d d X X ()()=.这表明此时Word 法定义的类间距离与重心法只相差一个常数倍。
当p G 和q G 合并为r G 后,r G 与其他类k G 的距离有如下递推公式2222k p k q k rk pk qk pqr kr kr kn n n n n D D D D n n n n n n ++=+-+++ 上述两种方法都是将性质接近的样品划为一类。
聚类分析依据的基本原则是直接比较样本中各事物之间的性质,将性质相近的归为一类,而将性质相差比较大的分在不同类。
也就是说,同类事物之间性质差异小,类与类之间的性质相差比较大。
系统聚类分析是聚类分析中应用的最广泛的一种方法。
首先将n 个样品每个自成一类,然后每次将具有最小距离的两类合并成一类,合并后重新计算类与类之间的距离,这个过程一直持续到所有样品归为一类为止。
分类结果可以画成一张直观的聚类谱系图。
应用系统聚类法进行聚类分析的步骤如下:①确定待分类的样品的指标②收集数据③对数据进行变换处理④使各个样品自成一类,即n个样品一共有n类⑤计算各类之间的距离,得到一个距离对称矩阵,将距离最近的两个类并成一类⑥并类后,如果类的个数大于1,那么重新计算各类之间的距离,继续并类,直至所有样品归为一类为止⑦最后绘制系统聚类谱系图,按不同的分类标准或不同的分类原则,得出不同的分类结果。
四、实验数据与实验结果我们根据2010年山东统计年鉴的数据,运用SPSS软件进行分析,得到如下实验数据与结果:1,原始数据表1-1 山东省17城市生产总值原始数据地区X1 X2 X3 X4 X5 X6 X7 X8济南市20686756 20704772 3918747 20639608 3784306 8943039 214.9 18024610青岛市27503964 70619047 31956998 55733587 4831806 8137064 274.8 19611331淄博市14061888 58081899 9491580 30244829 1884145 5053392 105.7 10056751枣庄市5064995 22437375 1753203 6651504 2207428 1592207 66.0 4228513东营市15345343 41199590 4554293 15809465 1696382 2383391 67.4 3887417烟台市16417465 66453587 38086756 49475292 5975883 5008978 175.8 14126854潍坊市10497502 60488560 11709800 26141577 6548044 4473999 183.2 12148004济宁市13006720 22645751 5242998 16033364 6219252 2895386 130.3 10042495泰安市9325693 25301440 1632878 13970449 3382994 4859536 77.3 6978426威海市1821752 35641945 14747879 20280903 3008526 1668404 81.8 7092776日照市1731442 18934672 5202300 4998376 1762907 1478668 50.9 3195391莱芜市5668429 5868280 363118 3045801 725138 451164 21.3 1888211临沂市3547197 39162992 7750708 15125262 4778789 2876138 161.9 11587531德州市4265744 33622261 2620289 10973162 4432973 1295397 82.8 6586211聊城市7202729 31048684 1005847 11917024 4032858 1027917 87.9 5585951滨州市3256739 33182983 2627798 8352382 3004112 1480444 72.2 4507461菏泽市3674339 21236454 1950326 6628429 3945037 1340737 108.8 6655095(来源:2010年山东统计年鉴)X1-规模以上国有控股工业总产值(单位:万元) X2-规模以上非公有工业总产值(单位:万元) X3-规模以上外商和港澳台投资工业总产值(单位:万元) X4-规模以上高新技术产业总产值(单位:万元) X5-农林牧渔业总产值(单位:万元) X6-建筑业总产值(单位:万元) X7-邮电业务总量(单位:亿元) X8-社会消费品零售总额 (单位:万元)2,SPSS软件处理结果我们首先对原始数据进行标准化,然后采用系统聚类分析法的Furthest Neighbor(最长距离法)和Ward’s Method(离差平方和)分别对标准化的数据进行处理,下面对软件输出结果进行详细介绍。