聚类分析实验报告
SPSS聚类分析实验报告

SPSS聚类分析实验报告一、实验目的本实验的目的是通过应用SPSS软件进行聚类分析,对样本进行分类和分组,通过群组间的比较来发现变量之间的关系和特征。
通过聚类分析的结果,可以帮助我们更好地理解和解释数据。
二、实验步骤1.数据准备:选择合适的数据集进行分析。
数据集应包含若干个已知变量,以及我们需要进行聚类的目标变量。
2.打开SPSS软件,导入数据集。
3.对数据集进行数据清洗和预处理,包括处理缺失数据、异常值等。
4.进行聚类分析:选择合适的聚类方法和变量,进行聚类分析。
5.对聚类结果进行解释和分析,确定最佳的聚类数目。
6.对不同的聚类进行比较,看是否存在显著差异。
7.结果展示和报告撰写。
三、实验结果及分析在实验过程中,我们选择了学校学生的体测数据作为聚类分析的样本。
数据集共包含身高、体重、肺活量等指标,共有200个样本。
首先,我们进行了数据预处理,包括处理缺失数据和异常值。
对于缺失数据,我们选择用平均值进行填充;对于异常值,我们使用离群值检测方法进行处理。
然后,我们选择了合适的聚类方法和变量,使用K-means聚类算法对样本进行分组。
我们尝试了不同的聚类数目,从2到10进行了分析。
根据轮廓系数和手肘法定量评估了不同聚类数目下聚类效果的好坏。
最终,我们选择了聚类数目为4的结果进行进一步分析。
通过比较不同聚类结果的均值,我们发现不同聚类之间的身高、体重和肺活量等指标存在较大差异。
这说明聚类分析对样本的分类和分组是合理和有效的。
四、实验总结本次实验通过应用SPSS软件进行聚类分析,对样本进行分类和分组,通过群组间的比较来发现变量之间的关系和特征。
通过分析聚类结果,我们发现不同聚类之间存在显著差异,这为进一步研究和探索提供了参考。
聚类分析是一种常用的数据分析方法,可以帮助我们更好地理解和解释数据,对于从大量数据中发现规律和特征具有重要的应用价值。
总之,聚类分析是一种有力的数据分析工具,可以帮助我们更好地理解和解释数据。
聚类分析实验报告

聚类分析实验报告一、实验目的:通过聚类分析方法,对给定的数据进行聚类,并分析聚类结果,探索数据之间的关系和规律。
二、实验原理:聚类分析是一种无监督学习方法,将具有相似特征的数据样本归为同一类别。
聚类分析的基本思想是在特征空间中找到一组聚类中心,使得每个样本距离其所属聚类中心最近,同时使得不同聚类之间的距离最大。
聚类分析的主要步骤有:数据预处理、选择聚类算法、确定聚类数目、聚类过程和聚类结果评价等。
三、实验步骤:1.数据预处理:将原始数据进行去噪、异常值处理、缺失值处理等,确保数据的准确性和一致性。
2.选择聚类算法:根据实际情况选择合适的聚类算法,常用的聚类算法有K均值算法、层次聚类算法、DBSCAN算法等。
3.确定聚类数目:根据数据的特征和实际需求,确定合适的聚类数目。
4.聚类过程:根据选定的聚类算法和聚类数目进行聚类过程,得到最终的聚类结果。
5. 聚类结果评价:通过评价指标(如轮廓系数、Davies-Bouldin指数等),对聚类结果进行评价,判断聚类效果的好坏。
四、实验结果:根据给定的数据集,我们选用K均值算法进行聚类分析。
首先,根据数据特点和需求,我们确定聚类数目为3、然后,进行数据预处理,包括去噪、异常值处理和缺失值处理。
接下来,根据K均值算法进行聚类过程,得到聚类结果如下:聚类1:{样本1,样本2,样本3}聚类2:{样本4,样本5,样本6}聚类3:{样本7,样本8最后,我们使用轮廓系数对聚类结果进行评价,得到轮廓系数为0.8,说明聚类效果较好。
五、实验分析和总结:通过本次实验,我们利用聚类分析方法对给定的数据进行了聚类,并进行了聚类结果的评价。
实验结果显示,选用K均值算法进行聚类分析,得到了较好的聚类效果。
实验中还发现,数据预处理对聚类分析结果具有重要影响,必要的数据清洗和处理工作是确保聚类结果准确性的关键。
此外,聚类数目的选择也是影响聚类结果的重要因素,过多或过少的聚类数目都会造成聚类效果的下降。
模糊聚类分析实验报告
实验报告(一)一、实验内容模糊聚类在土地利用分区中的应用二、实验目的本次上机实习主要以指导学生掌握“如何应用模糊聚类方法进行土地利用规划分区”为目标。
三、实验方法本次试验是在Excel中实现。
利用《土地利用规划学》P114页数据,使用“欧氏距离法”、建模糊相似矩阵,并进行模糊聚类分析实现土地利用分区。
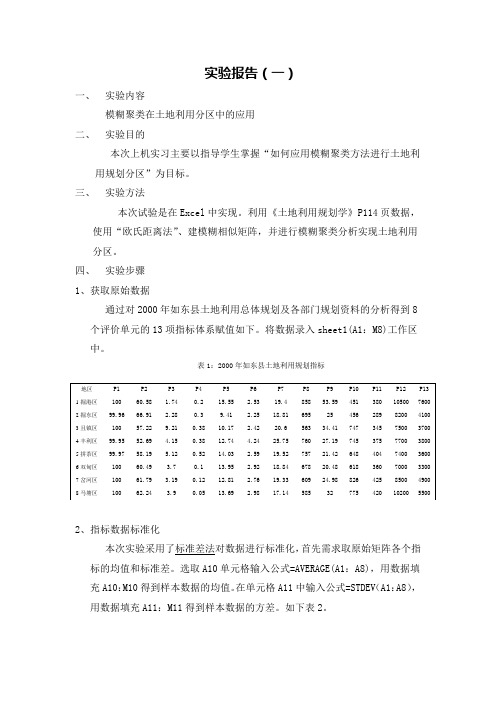
四、实验步骤1、获取原始数据通过对2000年如东县土地利用总体规划及各部门规划资料的分析得到8个评价单元的13项指标体系赋值如下。
将数据录入sheet1(A1:M8)工作区中。
表1:2000年如东县土地利用规划指标2、指标数据标准化本次实验采用了标准差法对数据进行标准化,首先需求取原始矩阵各个指标的均值和标准差。
选取A10单元格输入公式=AVERAGE(A1:A8),用数据填充A10:M10得到样本数据的均值。
在单元格A11中输入公式=STDEV(A1:A8),用数据填充A11:M11得到样本数据的方差。
如下表2。
表2:13个指标值得均值和标准差选取A13单元格输入公式=(A1-A$10)/A$11,并用数据填充A13:M20区域得到标准化矩阵如下表3。
表3:标准化数据矩阵3、求取模糊相似矩阵本次试验是通过欧氏距离法求取模糊相似矩阵。
其数学模型为:mr ij=1−c√∑(x ik−x jk)2k=1选取A23单元格输入公式=SQRT((A$13-A13)^2+(B$13-B13)^2+(C$13-C13)^2+(D$13-D13)^2+(E$13-E13)^2+(F$13-F13)^2+(G$13-G13)^2+(H$13-H13)^2+(I$13-I13)^2+(J$13-J13)^2+(K$13-K13)^2+(L$13-L13)^2+(M$13-M13)^2)求的d11,B23中输入公式=SQRT((A$14-A13)^2+(B$14-B13)^2+(C$14-C13)^2+(D$14-D13)^2+(E$14-E13)^2+(F$14-F13)^2+(G$14-G13)^2+(H$14-H13)^2+(I$14-I13)^2+(J$14-J13)^2+(K$14-K13)^2+(L$14-L13)^2+(M$14-M13)^2)q 求的d12。
聚类分析算法实验报告(3篇)

第1篇一、实验背景聚类分析是数据挖掘中的一种重要技术,它将数据集划分成若干个类或簇,使得同一簇内的数据点具有较高的相似度,而不同簇之间的数据点则具有较低相似度。
本实验旨在通过实际操作,了解并掌握聚类分析的基本原理,并对比分析不同聚类算法的性能。
二、实验环境1. 操作系统:Windows 102. 软件环境:Python3.8、NumPy 1.19、Matplotlib 3.3.4、Scikit-learn0.24.03. 数据集:Iris数据集三、实验内容本实验主要对比分析以下聚类算法:1. K-means算法2. 聚类层次算法(Agglomerative Clustering)3. DBSCAN算法四、实验步骤1. K-means算法(1)导入Iris数据集,提取特征数据。
(2)使用Scikit-learn库中的KMeans类进行聚类,设置聚类数为3。
(3)计算聚类中心,并计算每个样本到聚类中心的距离。
(4)绘制聚类结果图。
2. 聚类层次算法(1)导入Iris数据集,提取特征数据。
(2)使用Scikit-learn库中的AgglomerativeClustering类进行聚类,设置链接方法为'ward'。
(3)计算聚类结果,并绘制树状图。
3. DBSCAN算法(1)导入Iris数据集,提取特征数据。
(2)使用Scikit-learn库中的DBSCAN类进行聚类,设置邻域半径为0.5,最小样本数为5。
(3)计算聚类结果,并绘制聚类结果图。
五、实验结果与分析1. K-means算法实验结果显示,K-means算法将Iris数据集划分为3个簇,每个簇包含3个样本。
从聚类结果图可以看出,K-means算法能够较好地将Iris数据集划分为3个簇,但存在一些噪声点。
2. 聚类层次算法聚类层次算法将Iris数据集划分为3个簇,与K-means算法的结果相同。
从树状图可以看出,聚类层次算法在聚类过程中形成了多个分支,说明该算法能够较好地处理不同簇之间的相似度。
SPSS聚类分析实验报告

SPSS聚类分析实验报告一、实验目的本实验旨在通过SPSS软件对样本数据进行聚类分析,找出样本数据中的相似性,并将样本划分为不同的群体。
二、实验步骤1.数据准备:在SPSS软件中导入样本数据,并对数据进行处理,包括数据清洗、异常值处理等。
2.聚类分析设置:在SPSS软件中选择聚类分析方法,并设置分析参数,如距离度量方法、聚类方法、群体数量等。
3.聚类分析结果:根据分析结果,对样本数据进行聚类,并生成聚类结果。
4.结果解释:分析聚类结果,确定每个群体的特征,观察不同群体之间的差异性。
三、实验数据本实验使用了一个包含1000个样本的数据集,每个样本包含了5个变量,分别为年龄、性别、收入、教育水平和消费偏好。
下表展示了部分样本数据:样本编号,年龄,性别,收入,教育水平,消费偏好---------,------,------,------,---------,---------1,30,男,5000,大专,电子产品2,25,女,3000,本科,服装鞋包3,35,男,7000,硕士,食品饮料...,...,...,...,...,...四、实验结果1. 聚类分析设置:在SPSS软件中,我们选择了K-means聚类方法,并设置群体数量为3,距离度量方法为欧氏距离。
2.聚类结果:经过聚类分析后,我们将样本分为了3个群体,分别为群体1、群体2和群体3、每个群体的特征如下:-群体1:年龄偏年轻,女性居多,收入较低,教育水平集中在本科,消费偏好为服装鞋包。
-群体2:年龄跨度较大,男女比例均衡,收入中等,教育水平较高,消费偏好为电子产品。
-群体3:年龄偏高,男性居多,收入较高,教育水平较高,消费偏好为食品饮料。
3.结果解释:根据聚类结果,我们可以看到不同群体之间的差异性较大,每个群体都有明显的特征。
这些结果可以帮助企业更好地了解不同群体的消费习惯,为市场营销活动提供参考。
五、实验结论通过本次实验,我们成功地对样本数据进行了聚类分析,并得出了3个不同的群体。
聚类的实验报告

一、实验目的1. 理解聚类算法的基本原理和过程。
2. 掌握K-means算法的实现方法。
3. 学习如何使用聚类算法对数据集进行有效划分。
4. 分析不同聚类结果对实际应用的影响。
二、实验环境1. 操作系统:Windows 102. 编程语言:Python3. 库:NumPy、Matplotlib、Scikit-learn三、实验内容本次实验主要使用K-means算法对数据集进行聚类,并分析不同参数设置对聚类结果的影响。
1. 数据集介绍实验所使用的数据集为Iris数据集,该数据集包含150个样本,每个样本包含4个特征(花瓣长度、花瓣宽度、花萼长度、花萼宽度),以及对应的分类标签(Iris-setosa、Iris-versicolor、Iris-virginica)。
2. K-means算法原理K-means算法是一种基于距离的聚类算法,其基本思想是将数据集中的对象划分为K个簇,使得每个对象与其所属簇的质心(即该簇中所有对象的平均值)的距离最小。
3. 实验步骤(1)导入数据集首先,使用NumPy库导入Iris数据集,并提取特征值和标签。
(2)划分簇使用Scikit-learn库中的KMeans类进行聚类,设置聚类个数K为3。
(3)计算聚类结果计算每个样本与对应簇质心的距离,并将样本分配到最近的簇。
(4)可视化结果使用Matplotlib库将聚类结果可视化,展示每个样本所属的簇。
(5)分析不同参数设置对聚类结果的影响改变聚类个数K,观察聚类结果的变化,分析不同K值对聚类效果的影响。
四、实验结果与分析1. 初始聚类结果当K=3时,K-means算法将Iris数据集划分为3个簇,如图1所示。
图1 K=3时的聚类结果从图1可以看出,K-means算法成功地将Iris数据集划分为3个簇,每个簇对应一个Iris物种。
2. 不同K值对聚类结果的影响(1)当K=2时,K-means算法将Iris数据集划分为2个簇,如图2所示。
聚类分析实习报告
聚类分析实习报告(经典版)编制人:__________________审核人:__________________审批人:__________________编制单位:__________________编制时间:____年____月____日序言下载提示:该文档是本店铺精心编制而成的,希望大家下载后,能够帮助大家解决实际问题。
文档下载后可定制修改,请根据实际需要进行调整和使用,谢谢!并且,本店铺为大家提供各种类型的经典范文,如报告总结、演讲发言、活动方案、条据文书、合同协议、心得体会、社交礼仪、教学资料、作文大全、其他范文等等,想了解不同范文格式和写法,敬请关注!Download tips: This document is carefully compiled by this editor. I hope that after you download it, it can help you solve practical problems. The document can be customized and modified after downloading, please adjust and use it according to actual needs, thank you!Moreover, our store provides various types of classic sample essays, such as report summaries, speeches, activity plans, written documents, contract agreements, personal experiences, social etiquette, teaching materials, complete essays, and other sample essays. If you want to learn about different sample formats and writing methods, please stay tuned!聚类分析实习报告聚类分析是一种常用的数据分析技术,能够将一组相似的样本数据分为若干个不同的类别或簇。
实验报告 聚类分析
实验四聚类分析实验要求:选取一组有实际意义的数据,利用SAS的五种系统聚类方法将n个样本进行分类,要求:1)说明每一种方法的分类结果;2)利用主成分分析说明哪一种分类结果更合理。
实验目的:学会利用SAS语言编写程序以实现聚类分析过程。
实验过程与结果分析:我们仍对实验一的数据集chengshi(2006年各省市主要城市建设水平指标年度统计数据)进行聚类分析。
第一步:编写SAS程序。
proc cluster data=chengshi method=single outtree=tree1;id region;proc tree data=tree1 horizontal graphics;id region;run;proc cluster data=chengshi method=complete outtree=tree2;id region;proc tree data=tree2 horizontal graphics;id region;run;proc cluster data=chengshi method=centroid outtree=tree3;id region;proc tree data=tree3 horizontal graphics;id region;run;proc cluster data=chengshi method=average outtree=tree4;id region;proc tree data=tree4 horizontal graphics;id region;run;proc cluster data=chengshi method=ward outtree=tree5;id region;proc tree data=tree5 horizontal graphics;id region;run;第二步: 将数据集提交运行,运行结果见图1-图10;图1 利用最小距离法所得到的树状分类图图2 最小距离法的聚类过程图3 利用最大距离法所得到的树状分类图图4 最大距离法的聚类过程图5 利用重心法所得到的树状分类图图6 重心法的聚类过程图7 利用平均距离法所得到的树状分类图图8 平均距离法的聚类过程图9 利用离差平方和法所得到的树状分类图图10 离差平方和法的聚类过程第三步:对输出的结果进行分析。
聚类分析中实验报告
一、实验背景聚类分析是数据挖掘中的一种无监督学习方法,通过对数据集进行分组,将相似的数据对象归为同一类别。
本实验旨在通过实践,加深对聚类分析方法的理解,掌握常用的聚类算法及其应用。
二、实验目的1. 理解聚类分析的基本原理和方法。
2. 掌握常用的聚类算法,如K-means、层次聚类、密度聚类等。
3. 学习使用Python等工具进行聚类分析。
4. 分析实验结果,总结聚类分析方法在实际应用中的价值。
三、实验环境1. 操作系统:Windows 102. 编程语言:Python3.83. 数据库:SQLite 3.32.24. 聚类分析库:scikit-learn 0.24.2四、实验步骤1. 数据准备- 下载并导入实验数据集,本实验使用的是Iris数据集,包含150个样本和4个特征。
- 使用pandas库对数据进行预处理,包括缺失值处理、异常值处理等。
2. 聚类算法实现- 使用scikit-learn库实现K-means聚类算法。
- 使用scikit-learn库实现层次聚类算法。
- 使用scikit-learn库实现密度聚类算法(DBSCAN)。
3. 结果分析- 使用可视化工具(如matplotlib)展示聚类结果。
- 分析不同聚类算法的优缺点,对比聚类效果。
4. 实验总结- 总结实验过程中遇到的问题和解决方法。
- 分析聚类分析方法在实际应用中的价值。
五、实验结果与分析1. K-means聚类- 使用K-means聚类算法将数据集分为3个类别。
- 可视化结果显示,K-means聚类效果较好,将数据集分为3个明显的类别。
2. 层次聚类- 使用层次聚类算法将数据集分为3个类别。
- 可视化结果显示,层次聚类效果较好,将数据集分为3个类别,且与K-means聚类结果相似。
3. 密度聚类(DBSCAN)- 使用DBSCAN聚类算法将数据集分为3个类别。
- 可视化结果显示,DBSCAN聚类效果较好,将数据集分为3个类别,且与K-means聚类结果相似。
对数据进行聚类分析实验报告
对数据进行聚类分析实验报告数据聚类分析实验报告摘要:本实验旨在通过对数据进行聚类分析,探索数据点之间的关系。
首先介绍了聚类分析的基本概念和方法,然后详细解释了实验设计和实施过程。
最后,给出了实验结果和结论,并提供了改进方法的建议。
1. 引言数据聚类分析是一种将相似的数据点自动分组的方法。
它在数据挖掘、模式识别、市场分析等领域有广泛应用。
本实验旨在通过对实际数据进行聚类分析,揭示数据中的隐藏模式和规律。
2. 实验设计与方法2.1 数据收集首先,我们收集了一份包含5000条数据的样本。
这些数据涵盖了顾客的消费金额、购买频率、地理位置等信息。
样本数据经过清洗和预处理,确保了数据的准确性和一致性。
2.2 聚类分析方法本实验采用了K-Means聚类算法进行数据分析。
K-Means算法是一种迭代的数据分组算法,通过计算数据点到聚类中心的距离,将数据点划分到K个不同的簇中。
2.3 实验步骤(1)数据预处理:对数据进行归一化和标准化处理,确保每个特征的权重相等。
(2)确定聚类数K:通过执行不同的聚类数,比较聚类结果的稳定性,选择合适的K值。
(3)初始化聚类中心:随机选取K个数据点作为初始聚类中心。
(4)迭代计算:计算数据点与聚类中心之间的距离,将数据点划分到距离最近的聚类中心所在的簇中。
更新聚类中心的位置。
(5)重复步骤(4),直到聚类过程收敛或达到最大迭代次数。
3. 实验结果与分析3.1 聚类数选择我们分别执行了K-Means算法的聚类过程,将聚类数从2增加到10,比较了每个聚类数对应的聚类结果。
通过对比样本内离差平方和(Within-Cluster Sum of Squares, WCSS)和轮廓系数(Silhouette Coefficient),我们选择了最合适的聚类数。
结果表明,当聚类数为4时,WCSS值达到最小,轮廓系数达到最大。
3.2 聚类结果展示根据选择的聚类数4,我们将数据点划分为四个不同的簇。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
聚类分析实验报告姓名:学号:班级:
一:实验目的
1.了解聚类分析的基本原理及在spss中的实现过程。
2.
3.
由上面的分析我们知道评定一个上市公司业绩的指标有四类,但我们看EXCEL可知,每一类下面有4-5个指标,每类指标有较强相关性,存在多重共线性和维数过高而不易分析得影响。
所以首先采用系统聚类法对每类指标进行聚类,再采用比较复相关系数得出每类最具代表的指标,达到降维的目的。
(注:以下对指标分析均采用主间连接法,度量标准为person 相关性)
以下是实验截图:
(1):对盈利能力指标
从上表分析我们可将盈利能力的4个指标分为两类,即“毛利率”为一类,“销售净利率”、“成本费用利润率”和“资产净利润”为一类。
所以“毛利率”为一类,另外再对“销售净利润”、“成本费用利润率”和“资产净利润”分别作对另3个指标的复相关系数,结果
(2):对偿债能力指标的聚类
从上表分析我们可将偿债能力的5个指标分为两类,即“资产负债率”和“产权比率”为一类,“流动比率”、“速动比率”和“现金流动负债比”为一类。
然后同上法作复相关系数,结果如下:
①、以“资产负债率”为因变量,其余为自变量得:
,
流增长率”和“总资产增长率”代表成长能力的指标。
(4):对运营能力指标的聚类
从上表分析我们可将营运能力的5个指标分为两类,即“应收账款周转率”单独为一类,“总资产周转率”、“股东权益周转率”、“固定资产周转率”和“存货周转率”为一类。
然后同上法作复相关系数,结果如下:
①、以“总资产周转率”为因变量,其余为自变量得:
③、以“固定资产周转率”为因变量,其余为自变量得:
④、以“存货周转率”为因变量,其余为自变量得:
力三个方面的指标进行聚类时得到了很好的结果,而对经营能力进行聚类时相对较差,这是因为经营能力的指标相对于其他三方面的指标相关性较低,其实在一开始我对这四个方面共19个指标做了一次聚类,发现反应经营能力的指标的一部分和反应其他三方面的指标聚在了一起。
这其实可从经济上解释,因为经营能力越好,则其盈利能力、偿债能力和成长能力就越好。
但我们也可将其单独归为一类。
综上我们得出了反应一家上市公司业绩的8
个指标,接下来,我们将通过因子分析来对上市公司经营业绩做出综合评价。