润乾集算报表实现动态层次钻取报表(一)
如何实现报表分析动态取数

如何实现报表分析动态取数
今天学习一个EXCEL案例,非常方便大家在分析报表时动态取数。
原创作者是queyue (会计视野),写的很好,可以学习一下。
OFFSET(引用的基点,偏移的行数,偏移的列数,结果的高度,结果的宽度)
=OFFSET(A1,1,,3,2)——表示从A1单元格偏移1行0列,返回一个高度为3,宽度为2的单元格区域。
即,A2:B4区域。
其中,1后面2个逗号,实际上相当于:
=OFFSET(A1,1,0,3,2)——也就是有一个0简写了。
同理,你问的后面为什么有2个逗号也是如此,表示结果的高度和宽度都为1(稍有不同,不是0),其实都可以省略,比如:
OFFSET($F4,,MATCH(TODAY(),$G$2:$IV$2,)+1)——表示从F4单元格偏移0行,match列。
至于Match为啥加1,则可以通过计算弄明白,这只是一个修正的数值而已。
上年累计SUM(OFFSET('2011利润表'!$D$3,1,1,1,MATCH(分析表!$C$1,'2012利润表'!$E$3:$P$3,0))),
本年累计SUM(OFFSET('2012利润表'!$D$3,1,1,1,MATCH(分析表!$C$1,'2012利润表'!$E$3:$P$3,0)))
表格下载:
1、开通黄钻的,直接点击下面附件,直接下载。
2、未开通黄钻的,请到/zxView.asp?id=647下载。
润乾集算报表呈现输出之分栏显示
润乾集算报表呈现输出之分栏显示
报表应用中常常会遇到一些列数很少行数很多的报表,这种报表窄而长,显示和打印时,横向会留出大片空白,不但浪费张纸而且不美观,不方便用户查阅。
在集算报表中我们可以通过设置报表的分栏属性对报表进行纵向分栏,即在打印纸上横向布局多列报表,这样既美观又节约纸张,还方便浏览报表。
集算报表中设置报表分栏很简单,可以参考如下步骤:
新建报表
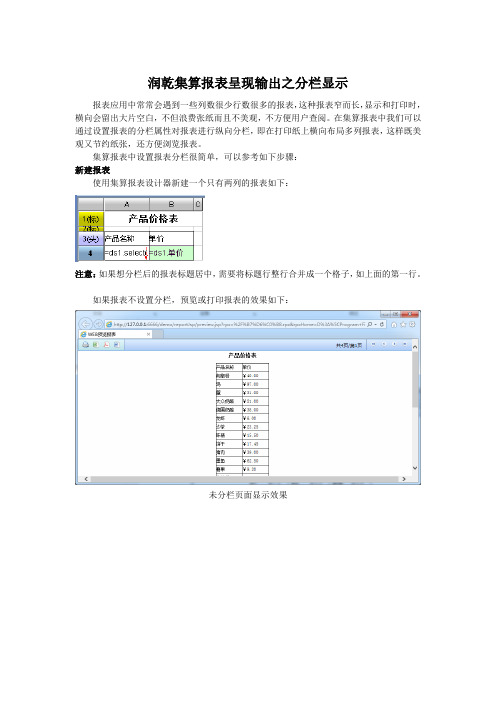
使用集算报表设计器新建一个只有两列的报表如下:
注意:如果想分栏后的报表标题居中,需要将标题行整行合并成一个格子,如上面的第一行。
如果报表不设置分栏,预览或打印报表的效果如下:
未分栏页面显示效果
未设置分栏打印预览效果
可以看到不设置分栏报表的显示效果非常不美观,下面设置分栏。
设置分栏
选择【属性】-【报表属性】菜单,在“分页”选项下,设置分栏数,如下:
预览并打印报表
报表在页面上预览可以看到设置分栏后的显示效果:
设置分栏后的打印效果:。
润乾集算报表开发多源分片报表
润乾集算报表开发多源分片报表使用润乾集算报表可以开发多源分片报表,在同一报表中的不同部分可以包含不同数据来源。
集算报表提供的扩展模型和主格模型让这类报表开发非常简单。
下面通过具体实例来来看一下多源分片报表的开发过程。
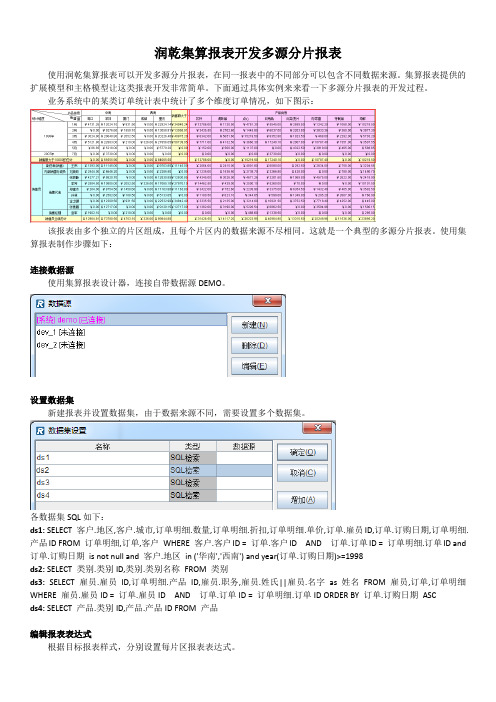
业务系统中的某类订单统计表中统计了多个维度订单情况,如下图示:该报表由多个独立的片区组成,且每个片区内的数据来源不尽相同。
这就是一个典型的多源分片报表。
使用集算报表制作步骤如下:连接数据源使用集算报表设计器,连接自带数据源DEMO。
设置数据集新建报表并设置数据集,由于数据来源不同,需要设置多个数据集。
各数据集SQL如下:ds1: SELECT 客户.地区,客户.城市,订单明细.数量,订单明细.折扣,订单明细.单价,订单.雇员ID,订单.订购日期,订单明细.产品ID FROM 订单明细,订单,客户WHERE 客户.客户ID = 订单.客户ID AND 订单.订单ID = 订单明细.订单ID and 订单.订购日期is not null and 客户.地区in ('华南','西南') and year(订单.订购日期)>=1998ds2: SELECT 类别.类别ID,类别.类别名称FROM 类别ds3:SELECT 雇员.雇员ID,订单明细.产品ID,雇员.职务,雇员.姓氏||雇员.名字as 姓名FROM 雇员,订单,订单明细WHERE 雇员.雇员ID = 订单.雇员ID AND 订单.订单ID = 订单明细.订单ID ORDER BY 订单.订购日期ASCds4: SELECT 产品.类别ID,产品.产品ID FROM 产品编辑报表表达式根据目标报表样式,分别设置每片区报表表达式。
其中:A1-E4按日期维度汇总了每个地区的销售额;A5-E6按销售人员维度汇总了每个地区的销售额;F1-G4按日期维度汇总了每类产品的销售额;F5-G6按销售人员维度汇总了每类产品的销售额。
润乾报表基本介绍[技巧]
![润乾报表基本介绍[技巧]](https://img.taocdn.com/s3/m/c4386b2530126edb6f1aff00bed5b9f3f90f7216.png)
润乾报表3.0介绍润乾报表3.0是用于统计报表制作及报表及数据填报的大型企业级工具软件。
产品首次成功解决了报表单元格与关系数据库之间的关联规律性,特别适合于中国式报表的填报和统计。
一、产品优势1.绘制方便润乾报表采用类EXCEL的绘制方式,真正做到所见即所得,把程序员从繁重且无聊的报表格式设置工作中解脱出来,极大的提高的表格绘制的方便度和效率,产品特有的EXCEL导入功能(包括格式)可充分利用业务人员原有积累。
2.数据模型先进润乾报表独创的数据模型首次成功地解决了中国报表中单元格与数据字段之间的弱关联性,彻底打破传统行式报表方案,报表行列完全对称,特有的层次扩展机制使多层分组及交叉报表制作非常简单,提供针对关联格的跨行跨组运算,很容易计算小计、同期比等数据。
同一报表中支持多个异构的数据源,允许报表各片之间无关,可用多个简单的数据集成组合出复杂报表,程序员无须再为每张报表编程(脚本或存储过程)或写复杂SQL准备数据。
3.输出能力丰富润乾报表每个单元格属性均提供条件控制,如颜色、行高、是否可见等均可与格内数据相关;支持代码显示值对应、多种数据格式、图片文件和图片字段的处理。
产品提供十几种各类统计图,支持PNG/GIF/JPG三种格式。
每张报表均可生成HTML、EXCEL、PDF三种输出格式(输出结果完全不失真,包括其内的统计图)。
单元格与统计图例均可加带参数的链接从而实现数据钻取功能,多层报表可在线收缩展开。
4.打印控制强大润乾报表提供强大的打印控制功能,按行数和纸张大小分页分栏或强制分页,表头自动重复(包括左表头),允许一张纸上打多个报表,提供末页补足空行。
可采用像素和毫米两种计量单位,独创的底图描绘功能以支持套打;5.集成性好润乾报表采用纯JAVA开发,利用服务器端提供丰富的API调用和标记可完全无缝地嵌入到基于J2EE的应用程序中(可看作应用程序员自己写的代码),程序员可更换报表的数据库连接和数据源、采用应用服务器的连接池管理;设计器也提供外置的数据源和数据字典定义,可由应用程序员提供这些信息。
润乾报表4.0高级设计(一)

第10页
1.2.1 运算模型基本概念
集合函数
运算结果为集合的函数,我们称为集合函数。
集合函数包括:group(),select(),list(), query(),call(),to()等。
集合表达式/单值表达式
计算结果为集合的表达式称为集合表达式; 计算结果为单值的表达式称为单值表达式。
第11页
集合表达式与单值表达式
集合表达式 单值表达式
第12页
集合函数
Select Group Call/Call2 query/query2 List …
第13页
Select()
语法:
datasetName.select( <select_exp>{, desc_exp{, filter_exp{, sort_exp{,rootGroupExp}}}} )
第14页
练习
网格式报表
第15页
group()
语法:
datasetName.group(selectExp{,descExp{,filterExp{,sortExp {,groupSortExp{,groupDescExp{,rootGroupExp}}}}}})
=ds1.sum(# 5,#4==A1)
一组数据的集合,数据类型由sql语句的第一个选出字段决定
第22页
query2()
函数说明:
执行sql语句,返回结果数据集合,只能返回单列数据,如果sql语 句中有多个字段,则返回第一个字段的结果值。和query()函数的差别 在于多了第一个参数,第一个参数用于制定数据源名称,通过他可以 实现不同单元格从不同数据源获取数据 语法: query2(dbname, sqlStatement{,arg1{,arg2{,arg3{,……}}}} 参数说明: dbname 数据库逻辑名,为null表示缺省数据库 sqlStatement 合法的sql语句 arg(n) sql语句的参数,可以是常数也可以是表达式 返回值: 一组数据的集合,数据类型由sql语句的第一个选出字段决定
润乾报表使用手册

润乾报表使用手册(总25页) -CAL-FENGHAI.-(YICAI)-Company One1-CAL-本页仅作为文档封面,使用请直接删除报表使用手册XX股份有限公司中国济南目录1 概述..................................................错误!未定义书签。
2 安装..................................................错误!未定义书签。
准备好安装程序................................错误!未定义书签。
安装中的选项..................................错误!未定义书签。
授权文件配置..................................错误!未定义书签。
3 报表制作..............................................错误!未定义书签。
报表制作要求..................................错误!未定义书签。
制作一张报表的步骤............................错误!未定义书签。
启动报表设计器................................错误!未定义书签。
连接数据源....................................错误!未定义书签。
数据源对话框...............................错误!未定义书签。
编辑数据源.................................错误!未定义书签。
注意事项...................................错误!未定义书签。
设计报表格式..................................错误!未定义书签。
格式设计...................................错误!未定义书签。
润乾报表实现组内排序报表及改进

润乾报表实现组内排序报表及改进报表开发中经常会遇到需要进行组内排序的报表,如按月份的分组汇总值排序显示,并显示每月销售额前十名的记录。
使用报表工具一般通过隐藏行列辅助可以实现,下面通过实例说明润乾报表的实现过程,以及改进方案。
报表需求根据销售管理系统数据统计客户所在地区的订单总额,地区并按订单总额降序排列,要求每个地区中显示销售额在前五名的销售人员及其订单数量和订单金额,其他人员归入“其他”项中。
报表样式如下:这里应该注意的是地区分组中如果销售人数少于5个则不显示“其他”项(如上图中的西北地区)。
润乾报表实现润乾报表实现主要依靠条件隐藏行实现,根据分组成员数量是否显示“其他”项,报表模板及表达式如下:在润乾报表中,使用ds.group()的多个参数,结合条件判断隐藏行,多种使用方法结合完成了报表开发,可见润乾报表的强大之处。
但是由于要按照分组后汇总的订单金额排序,所以在B3的分组表达式中应用ds1.sum(订单金额)表达式作为ds.group()的参数,对于原始数据量较大的情况下,该表达式效率较低;而且,由于只显示前5名销售,在C3(排名)和D3(其他)中设置了隐藏行表达式,对于分组较多的情况仍然会存在性能问题;另外需要在E3和F3中使用格集过滤表达式计算其他销售人员合计,计算时要带着单元格属性计算,效率仍然不高。
上述提到的问题在传统报表工具中皆是存在的,原因在于数据计算(报表数据源准备)与报表呈现混在一起导致,开发人员不得不再报表中编写较复杂的计算逻辑以完成报表开发,造成报表开发和运行效率都不高。
如果能将两部分分开,势必能提升开发和运行效率。
润乾公司在润乾报表的基础上,推出了可以完全满足复杂报表开发的集算报表,其内置了用于完成报表数据计算(数据源准备)的集算器,从而将数据计算和报表呈现剥离开,进一步梳理了报表开发流程,使得报表开发变得更加清晰。
上述报表需求使用集算报表可以这样完成:集算报表实现编写集算脚本使用集算脚本编辑工具完成计算脚本,并为报表输出计算后结果集:A1:执行sql得到初步汇总订单数据A2:按照地区分组后组内成员按订单金额排序A3-C7:循环A3,取前五名记录,并将超过第五的记录都归入“其他”项,结果写回A3A8:结果按地区总额降序排列后返回给报表报表调用使用集算报表设计器,新建报表,使用“集算器”数据集类型,选择上面编辑好的集算脚本(sort.dfx)报表模板及表达式报表模板中根据集算脚本返回的结果集,分别取得地区分组和销售列表等数据,无需复杂表达式即完成报表开发。
润乾报表调用参数

润乾报表调用参数润乾报表是一种常用的财务报表分析工具,可以帮助企业对财务状况进行全面的分析和评估。
在使用润乾报表时,我们需要了解如何正确调用参数,以获取准确的报表数据。
本文将介绍润乾报表的调用参数及其使用方法,帮助读者更好地使用润乾报表进行财务分析。
一、调用参数的作用和分类润乾报表的调用参数是指在生成报表时需要提供的信息,包括报表类型、时间范围、公司代码等。
不同的调用参数可以实现不同的报表功能。
根据调用参数的不同,润乾报表的调用参数可以分为以下几类:1. 报表类型参数:用于指定要生成的报表类型,比如资产负债表、利润表、现金流量表等。
通过设置不同的报表类型参数,可以获取不同类型的财务报表数据。
2. 时间范围参数:用于指定报表的时间范围,比如年度报表、季度报表、月度报表等。
根据业务需要,可以灵活调整时间范围参数,以获取特定时间段内的财务数据。
3. 公司代码参数:用于指定要查询的公司代码,适用于多公司集团财务分析的场景。
通过设置不同的公司代码参数,可以获取不同公司的财务报表数据。
4. 其他参数:润乾报表还提供了一些其他的调用参数,用于实现更复杂的报表功能。
比如币种参数、科目代码参数、部门代码参数等,可以根据具体需求进行设置。
二、调用参数的使用方法使用润乾报表进行财务分析时,正确设置调用参数是非常重要的。
下面以资产负债表为例,介绍润乾报表调用参数的使用方法。
1. 首先,打开润乾报表软件,在报表模块中选择要生成的报表类型,比如资产负债表。
2. 然后,在报表设置中找到调用参数选项,点击进入参数设置界面。
3. 在参数设置界面中,根据需要设置报表的时间范围参数。
比如如果要生成年度报表,可以选择起始日期和结束日期为一年的时间范围。
4. 接下来,设置公司代码参数。
如果润乾报表支持多公司查询,可以选择要查询的公司代码,以获取相应公司的财务报表数据。
5. 如果需要对报表数据进行进一步筛选,可以设置其他参数,比如币种参数、科目代码参数等。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
润乾集算报表实现动态层次钻取报表(一)
在报表项目中有时会有动态层次报表,而且还需要层次钻取的场景,开发难度较大。
这里记录了使润乾集算报表开发《各级部门KPI报表》的过程。
《各级部门KPI报表》初始状态如下图:
当前节点是根节点“河北省”,要求报表显示当前节点的下一级节点“地市”汇总的KPI 数值。
Kpi又分为普通指标和VIP指标两类,共四项。
如果点击“石家庄”来钻取的时候,要求能够将石家庄下一级的KPI汇总指标显示出来,如下图:
点击“中心区”钻取,要求能够将下一级的KPI汇总指标显示出来,以此类推,直到显示到最后一级。
如下图:
前四级固定是“省、地市、区县、营业部”,后边则是动态的“架构4、架构5、架构6. . . 架构13”(根节点“省”对应“架构0”)。
这个报表对应的oracle数据库表有两个,tree(树形结构维表)和kpi(指标事实表),如下图:
Tree表
Kpi表
Tree表的叶子节点,通过id字段与kpi表关联。
这个报表的难点在于1、动态的多层数据、标题;2、树形结构数据与事实表关联。
采用润乾集算报表实现的第一步:编写集算脚本tree.dfx,完成源数据计算。
集算脚本
A1:连接预先配置好的oracle数据库。
A2:新建一个序列,内容是“省、地市、区县、营业部、架构4、架构5、架构6. . . 架构13”。
A3:使用oracle数据库提供的connect by语句编写sql,从数据库中取出指定id(节点编号)
的所有父节点id、name。
id是预先定义的网格参数,如果传进来的值是104020,那么A3的计算结果是:
A4:为A3增加一个字段title,按照顺序,对应A2中的层级。
结果是:
A5:计算变量level,是A3序表的长度,也就是输入节点“104020”的层级号“4”(“省”为第一级)。
A6:计算输入节点“104020”的下一级对应的层级名称“架构4”,赋值给变量xtitle。
A7:编写sql,从tree表中取出输入节点“104020”的所有叶子节点,并拆分sys_connect_by_path字符串,得到这些叶子节点对应的输入节点“104020”的下一级节点。
形成临时表leaf与kpi表关联分组汇总。
为了能够得到输入节点“104020”的下一级节点的name,leaf还需要与tree关联一次。
需要注意的是,如果输入节点号本身就是叶子节点,结果中的name将为空。
完整的sql如下:
with leaf as(
SELECT tree.id id,REGEXP_SUBSTR(SYS_CONNECT_BY_PATH(id, ';'),'[^;]+',1,2) x FROM tree where connect_by_isleaf=1
START WITH ID = ?
CONNECT BY NOCYCLE PRIOR id = pid
)
select nvl(leaf.x,max(leaf.id)) id,'"+xtitle+"' title,max() name, sum(kpi.kpi1) kpi1,sum(kpi.kpi2) kpi2,sum(kpi.vipkpi1) vipkpi1,sum(kpi.vipkpi2) vipkpi2
from leaf left join kpi on leaf.id = kpi.id left join tree on leaf.x=tree.id
group by leaf.x order by leaf.x
计算的结果是:
A8:关闭数据库连接。
A9:向报表返回A4、A7两个结果集。
第二步:在报表设计器中定义报表参数和集算数据集,调用tree.dfx。
如下图:
定义报表参数“id”
定义集算数据集(其中的参数名“id”是集算脚本的输出参数名,参数值“id”是报表参数。
第三步,设计报表如下图:
A列是报表的左半部分,是输入节点(例如:“104020”)的所有父节点和它本身,横向扩展,A1的值是id,显示的是title。
A3显示的是name。
B列是报表的中间部分,是输入节点(例如:“104020”)的下一级子节点,纵向扩展。
在B3格中设置隐藏列的条件是value()==null,如果输入节点本省就是叶子节点,那么name==null,
B列就会隐藏不显示了。
C列到F列是报表的右半部分,显示的是对应的kpi统计值。
为了实现报表的格式需要,A3单元格需要将左主格设置为B3。
为了实现钻取功能,需要:
1、将A3单元格的超链接属性定义为表达式:
"/reportJsp/showReport.jsp?rpx=r4.rpx&id="+ds1.ID。
超链接指向本报表自身,报表参数是当前列对应的ds1.ID。
2、将B3单元格的超链接属性定义为表达式:
"/reportJsp/showReport.jsp?rpx=r4.rpx&id="+ds2.ID。
超链接指向本报表自身,报表参数是当前行对应的ds2.ID。
第四步:发布报表并运行。
实际的超链值如下图:
从上述实现步骤可以看到,难度最大的是tree.dfx中的A7单元格的复杂SQL。
应该说,oracle数据库的树形递归查询还是比较丰富的,用其他数据库(比如MySQL,PostgreSQL及Greenplum等)可能就很难实现A7中的SQL。
那么有什么其他方案,可以让这些数据库也能实现上述复杂的树形结构计算呢?
集算报表内置的集算引擎具备强大的计算能力,可以解决这个困难。
具体方案可参见《润乾集算报表实现动态层次钻取报表(二)》。