EVIEWS实验报告1
《计量经济学》eviews实验报告一元线性回归模型详解

计量经济学》实验报告一元线性回归模型-、实验内容(一)eviews基本操作(二)1、利用EViews软件进行如下操作:(1)EViews软件的启动(2)数据的输入、编辑(3)图形分析与描述统计分析(4)数据文件的存贮、调用2、查找2000-2014年涉及主要数据建立中国消费函数模型中国国民收入与居民消费水平:表1年份X(GDP)Y(社会消费品总量)200099776.339105.72001110270.443055.42002121002.048135.92003136564.652516.32004160714.459501.02005185895.868352.62006217656.679145.22007268019.493571.62008316751.7114830.12009345629.2132678.42010408903.0156998.42011484123.5183918.62012534123.0210307.02013588018.8242842.82014635910.0271896.1数据来源:二、实验目的1.掌握eviews的基本操作。
2.掌握一元线性回归模型的基本理论,一元线性回归模型的建立、估计、检验及预测的方法,以及相应的EViews软件操作方法。
三、实验步骤(简要写明实验步骤)1、数据的输入、编辑2、图形分析与描述统计分析3、数据文件的存贮、调用4、一元线性回归的过程点击view中的Graph-scatter-中的第三个获得在上方输入Isycx回车得到下图DependsntVariable:Y Method:LeastSquares□ate:03;27/16Time:20:18 Sample:20002014 Includedobservations:15VariableCoefficientStd.Errort-StatisticProb.C-3J73.7023i820.535-2.1917610.0472X0416716 0.0107S838.73S44 a.ooao R-squared0.991410 Meandependentwar119790.2 AdjustedR.-squared 0.990750 S.D.dependentrar 7692177 S.E.ofregression 7J98.292 Akaike infocriterion20.77945 Sumsquaredresid 7;12E^-08 Scliwarz 匚「爬伽20.37386 Loglikelihood -1&3.3459Hannan-Quinncriter. 20.77845 F-statistic 1I3&0-435 Durbin-Watsonstat0.477498Prob(F-statistic)a.oooooo在上图中view 处点击view-中的actual ,Fitted ,Residual 中的第一 个得到回归残差打开Resid 中的view-descriptivestatistics 得到残差直方图/icw Proc Qtjject PrintN^me FreezeEstimateForecastStatsResids凹Group:UNIIILtD Worktile:UN III LtLJ::Unti1DependentVariablesMethod;LeastSquares□ate:03?27/16Time:20:27Sample(adjusted):20002014Includedobservations:15afteradjustmentsVariable Coefficient Std.Errort-Statistic ProtJ.C-3373.7023^20.535-2.191761 0.0472X0.4167160.01075S38.735440.0000R-squared0.991410 Meandependeniwar1-19790.3 AdjustedR-squa.red0990750S.D.dependentvar 76921.77 SE.ofregre.ssion 7J98.292 Akaike infacriterion20.77945 Sumsquaredresid 7.12&-0S Schwarzcriterion 20.S73S6 Laglikelihood -153.84&9Hannan-Quinncrite匚20.77545 F-statistic1I3&0.435Durbin-Watsonstat 0.477498 ProbCF-statistic) a.ooaooo在回归方程中有Forecast,残差立为yfse,点击ok后自动得到下图roreestYFM J訓YForea空巾取且:20002015 AdjustedSErmpfe:2000231i mskJddd obaerratire:15Roof kter squa red Error理l%2Mean/^oLteError畐惯啟iJean Afe.PereersErro r5.451SSQThenhe鼻BI附GKWCE口.他腐4Prop&niwi□ooooooVactaree Propor^tori0.001^24G M『倚■底Props^lori09®475在上方空白处输入lsycs…之后点击proc中的forcase根据公式Y。
Eviews实验报告

Eviews实验报告
本次实验使用Eviews对数据进行了分析和建模,主要分为以下几个部分:
一、数据预处理
1. 数据清洗:对数据进行了初步的检查和清洗,处理了数据中的缺失值和异常值;
2. 数据变换:对原始数据进行了对数化处理,使其符合正态分布。
二、数据分析
1. 描述性统计:通过统计均值、标准差、相关系数等指标,对数据进行了分析和描述;
2. 单因素分析:使用单因素方差分析对不同自变量与因变量之间的关系进行了检验。
三、建模分析
1. 模型选择:根据变量相关性和变量显著性等因素,最终选择了一组自变量,建立了多元线性回归模型;
2. 模型检验:对建立的模型进行了残差分析,验证了模型的可靠性和稳定性;
3. 预测分析:利用建立的模型对新数据进行了预测,并进行了模型预测精度的评估。
四、实验结论
通过Eviews的分析和建模,得出了以下结论:
1. 数据清洗和变换可以提高数据分析的准确性和可靠性;
2. 描述性统计和单因素分析可以为建模提供有用的参考和决策依据;
3. 多元线性回归模型可以较好地解释自变量与因变量之间的关系,并可进行预测和决策分析。
综上所述,本次实验通过Eviews软件对数据进行了分析和建模,得出了有关数据的一些重要结论,为后续数据分析和决策提供了基础和支持。
eviews实验报告一元线形回归模型
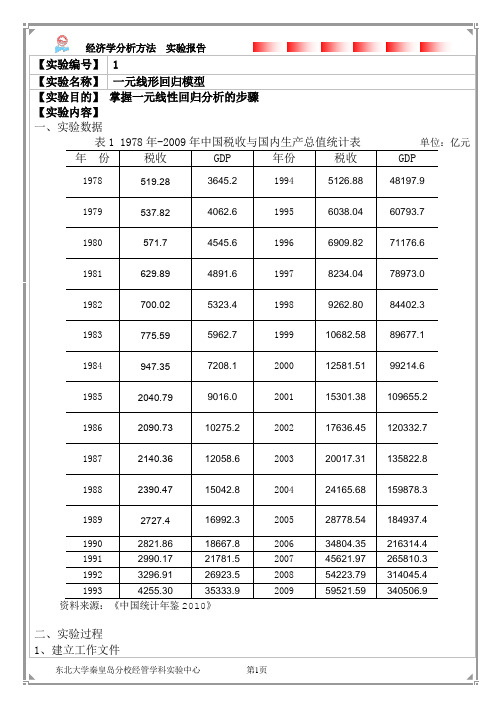
【实验编号】 1【实验名称】一元线形回归模型【实验目的】掌握一元线性回归分析的步骤【实验内容】一、实验数据表1 1978年-2009年中国税收与国内生产总值统计表单位:亿元年份税收GDP 年份税收GDP1978 519.28 3645.2 1994 5126.88 48197.91979 537.82 4062.6 1995 6038.04 60793.71980 571.7 4545.6 1996 6909.82 71176.61981 629.89 4891.6 1997 8234.04 78973.01982 700.02 5323.4 1998 9262.80 84402.31983 775.59 5962.7 1999 10682.58 89677.11984 947.35 7208.1 2000 12581.51 99214.61985 2040.79 9016.0 2001 15301.38 109655.21986 2090.73 10275.2 2002 17636.45 120332.71987 2140.36 12058.6 2003 20017.31 135822.81988 2390.47 15042.8 2004 24165.68 159878.31989 2727.4 16992.3 2005 28778.54 184937.41990 2821.86 18667.8 2006 34804.35 216314.41991 2990.17 21781.5 2007 45621.97 265810.31992 3296.91 26923.5 2008 54223.79 314045.41993 4255.30 35333.9 2009 59521.59 340506.9 资料来源:《中国统计年鉴2010》二、实验过程1、建立工作文件(1)点击桌面Eviews5.0图标,运行Eviews软件。
回归分析实验1 Eviews基本操作及一元线性回归

第一部分EViews基本操作第一章预备知识一、什么是EViewsEViews (Econometric Views)软件是QMS(Quantitative Micro Software)公司开发的、基于Windows平台下的应用软件,其前身是DOS操作系统下的TSP软件。
EViews具有现代Windows软件可视化操作的优良性。
可以使用鼠标对标准的Windows菜单和对话框进行操作。
操作结果出现在窗口中并能采用标准的Windows技术对操作结果进行处理。
EViews还拥有强大的命令功能和批处理语言功能。
在EViews的命令行中输入、编辑和执行命令。
在程序文件中建立和存储命令,以便在后续的研究项目中使用这些程序。
EViews是Econometrics Views的缩写,直译为计量经济学观察,通常称为计量经济学软件包,是专门从事数据分析、回归分析和预测的工具,在科学数据分析与评价、金融分析、经济预测、销售预测和成本分析等领域应用非常广泛。
应用领域■ 应用经济计量学■ 总体经济的研究和预测■ 销售预测■ 财务分析■ 成本分析和预测■ 蒙特卡罗模拟■ 经济模型的估计和仿真■ 利率与外汇预测EViews引入了流行的对象概念,操作灵活简便,可采用多种操作方式进行各种计量分析和统计分析,数据管理简单方便。
其主要功能有:(1)采用统一的方式管理数据,通过对象、视图和过程实现对数据的各种操作;(2)输入、扩展和修改时间序列数据或截面数据,依据已有序列按任意复杂的公式生成新的序列;(3)计算描述统计量:相关系数、协方差、自相关系数、互相关系数和直方图;(4)进行T 检验、方差分析、协整检验、Granger 因果检验;(5)执行普通最小二乘法、带有自回归校正的最小二乘法、两阶段最小二乘法和三阶段最小二乘法、非线性最小二乘法、广义矩估计法、ARCH 模型估计法等;(6)对选择模型进行Probit、Logit 和Gompit 估计;(7)对联立方程进行线性和非线性的估计;(8)估计和分析向量自回归系统;(9)多项式分布滞后模型的估计;(10)回归方程的预测;(11)模型的求解和模拟;(12)数据库管理;(13)与外部软件进行数据交换EViews可用于回归分析与预测(regression and forecasting)、时间序列(Time Series)以及横截面数据(cross-sectional data )分析。
EViews计量经济学实验报告

EViews 计量经济学实验报告实验一 EViews软件的基本操作小组成员: 【实验目的】了解EViews软件的基本操作对象,掌握软件的基本操作。
【实验内容】数据的输入、编辑与序列生成;实验内容以表1-1所列出的消费支出和可支配收入的统计资料为例进行操作。
表1-1 中国内地各地区城镇居民家庭人均全年可支配收入与人均全年消费性支出单位:元地区消费支出Y 可分配收入 X 地区消费支出 Y 可支配收入 X北京 19977.52 14825.41 湖北 9802.65 7397.32天津 14283.09 10548.05 湖南 10504.67 8169.30河北 10304.56 7343.49 广东 16015.58 12432.22山西 10027.70 7170.94 广西 9898.75 6791.95 内蒙古 10357.99 7666.61 海南 9395.13 7126.78辽宁 10369.61 7987.49 重庆 11569.74 9398.69吉林 9775.07 7352.64 四川 9350.11 7524.81 黑龙江 9182.31 6655.43 贵州 9116.61 6848.39上海 20667.91 14761.75 云南 10069.89 7379.81江苏 14084.26 9628.59 西藏 8941.08 6192.57浙江 18265.10 13348.51 陕西 9267.70 7553.28安徽 9771.05 7294.73 甘肃 8920.59 6974.21福建 13753.28 9807.71 青海 9000.35 6530.11江西 9551.12 6645.54 宁夏 9177.26 7205.57山东 12192.24 8468.40 新疆 8871.27 6730.01河南 9810.26 6685.18资料来源:《中国统计年鉴》(2007)【实验步骤】一、创建工作文件启动EViews软件之后,进入EViews主窗口(如图1-1所示)。
eviews实验报告总结(范本)

eviews实验报告总结eviews实验报告总结篇一:Evies实验报告实验报告一、实验数据:1994至201X年天津市城镇居民人均全年可支配收入数据 1994至201X年天津市城镇居民人均全年消费性支出数据 1994至201X年天津市居民消费价格总指数二、实验内容:对搜集的数据进行回归,研究天津市城镇居民人均消费和人均可支配收入的关系。
三、实验步骤:1、百度进入“中华人民共和国国家统计局”中的“统计数据”,找到相关数据并输入Exc el,统计结果如下表1:表11994年--201X年天津市城镇居民消费支出与人均可支配收入数据2、先定义不变价格(1994=1)的人均消费性支出(Yt)和人均可支配收入(Xt)令:Yt=cn sum/priceXt=ine/pri ce 得出Yt与Xt的散点图,如图1.很明显,Yt和X t服从线性相关。
图1 Yt和Xt散点图3、应用统计软件EVies完成线性回归解:根据经济理论和对实际情况的分析也都可以知道,城镇居民人均全年耐用消费品支出Yt依赖于人均全年可支配收入Xt的变化,因此设定回归模型为 Yt=β0+β?Xt﹢μt(1)打开E Vies软件,首先建立工作文件, Fil e rkfile ,然后通过bject建立 Y、X系列,并得到相应数据。
(2)在工作文件窗口输入命令:l s y c x,按E nter键,回归结果如表2 :表2 回归结果根据输出结果,得到如下回归方程:Y t=977.908+0.670Xt s=(172.3797) (0.0122) t=(5.673) (54.950) R2=0.995385 Adjust ed R2=0.995055 F-sta tistic=3019.551 残差平方和Sum sq uared resi d =1254108回归标准差S.E.f regressi n=299.2978(3)根据回归方程进行统计检验:拟合优度检验由上表2中的数分别为0.995385和0.995055,计算结果表明,估计的样本回归方程较好地拟合了样本观测值。
Eviews多重共线性实验报告-V1

Eviews多重共线性实验报告-V1本文主要将Eviews多重共线性实验报告进行整理,旨在帮助读者更好地理解和应用多重共线性实验结果。
1. 研究背景多重共线性是指在回归模型中,自变量之间存在高度相关的情况。
这种相关关系会导致模型的不稳定性,降低模型的解释能力和预测能力。
因此,在进行回归分析时,需要对多重共线性进行检测和处理。
2. 数据来源和处理本次实验所使用的数据来自某公司销售数据,共有18个自变量和1个因变量。
在进行回归分析之前,需要对数据进行预处理。
首先,我们通过观察变量间的相关系数矩阵来初步判断是否存在多重共线性。
如果存在高度相关的自变量,可以考虑通过主成分分析等方法来降维,减少变量间的冗余。
本实验中,我们发现变量间的相关性较小,因此没有进行降维操作。
3. 模型建立我们采用逐步回归的方法建立回归模型,并对模型的适配度和稳定性进行评估。
首先,我们使用全模型(包含所有自变量)进行回归分析,并得到如下统计结果:R-squared:0.7767Adj. R-squared:0.7152F-statistic:12.38(显著)通过观察模型的系数,我们发现存在一些变量的系数非常大,而一些变量的系数非常小甚至为0,这也是多重共线性的表现之一。
为了进一步检验模型的稳定性和解释能力,我们采用逐步回归的方法进行变量筛选。
在此过程中,我们设置的入模标准是F统计量显著,出模标准是T统计量显著或P值小于0.05。
最终,我们得到了一个包含4个自变量的最优模型,其统计结果如下:R-squared:0.7224Adj. R-squared:0.6812F-statistic:17.69(显著)通过观察模型的系数,我们发现所有自变量的系数都显著,且大小合理。
这说明通过逐步回归的方法,我们成功地排除了多重共线性的影响,建立了一个具有较好稳定性和解释能力的模型。
4. 结论和建议在本实验中,我们成功地应用了Eviews工具,通过逐步回归的方法检验和处理多重共线性,建立了一个较为稳定和解释能力强的回归模型。
计量经济学Eviews简单线性回归模型的建立与分析应用实验报告

实验一:简单线性回归模型的建立与分析应用【实验目的】1、熟悉计量经济学软件包EViews的界面和基本操作;2、掌握计量经济学分析实际经济问题的具体步骤;3、掌握简单线性回归模型的参数估计、统计检验、预测的基本操作方法;4、理解简单线性回归模型中参数估计值的经济意义。
【实验类型】综合型【实验软硬件要求】计量经济学软件包EViews、微型计算机【实验内容】为研究深圳市地方预算内财政收入(Y)与地区生产总值(X)的关系,建立简单线性回归模型,现根据深圳市统计局网站的相关信息,得到统计数据如下表:请按照下列步骤完成实验一,每个步骤要写出操作过程:(1)打开EViews,新建适当的工作文件夹;打开Eviews后,依次点击File-New-Workfile,新建一个时间序列数据(Dated-regular frequencied)类型的文件,频率选择年度(Annual),键入起止日期1990-2008(如图一),点击ok,新建工作文件夹完成(如图二)(图一)(图二)(2)在工作文件夹中新建变量X和Y,并输入数据;依次点击Objects-New Object,对象类型选择序列(Series),并输入序列名Y(如图三),点击OK,重复以上操作,新建系列对象X。
新建系列对象完成后如(图四)按住ctrl并同时选定X和Y,用鼠标右击选择open—as group,点击Edit +/-开始编辑,输入数据,数据输入完毕再点击Edit+/-一次。
数据输入后如(图五)。
(图三)(图四)(图五)(3)生成X和Y的自然对数序列,保存在工作文件夹中,命名为lnX和lnY;依次点击Objects-Generate Sereies,出现Generate Series by Equation 窗口,在Enter equation窗口中输入公式:lnY=log(Y)点击ok,重复以上操作,输入:lnX=log(X) 创建序列lnX。
(如图六)(图六)(4)求X和Y的描述统计量的值,写出操作过程并画出相应表格;依次点击Quick-Group Statistics—Descriptive Statistics-Common sample,打开Series List窗口,输入x y,点击ok,输出结果(如图七)(图七)(5)作出X和Y的散点图,写出操作过程并画出相应图像,并判断模型是否接近于线性形式;依次点击Quick-Graph,打开Graph Options窗口,在Specific 中选择Scatter(散点图) (如图八)点击OK,得到散点图(如图九)(图八)由散点图可以看出模型接近线性形式(图九)(6) 用OLS 法对模型i i i u X Y ++=21ββ做参数估计,将估计结果保存在工作文件夹中,命名为eq01,写出操作过程和回归分析报告,并解释斜率的经济含义;在窗口空白处输入:ls y c x ,回车,得到结果如图回归分析报告:根据输出结果可得Ŷi = 26.02096 + 0.088820Xi (14.80278) (0.004356) t= (1.757843) (20.38986) R 2 = 0.960716 F=415.7464 D.W=0.626334 n=19 斜率的经济含义:斜率为0.088820,表示地区生产总值每增加1亿元,地方预算内财政收入平均来说增加0.088820亿元(7) 用OLS 法对模型i i i u X Y ++=ln ln 21ββ做参数估计,将估计结果保存在工作文件夹中,命名为eq02,写出操作过程和回归分析报告,并解释斜率 的经济含义;在主窗口空白处输入:ls lny c lnx ,回车,结果如图回归分析报告:根据输出结果可得lny = -1.272730 + 0.873867lnx(0.238775) (0.032394) t= (-5.330249) (26.9761) R 2 = 0.977172 F=727.7097 D.W= 0.811127 n=19 斜率的经济含义:斜率为0.873867,表示地区生产总值每增加1亿元,地方预算内财政收入平均来说增加0.0873867亿元(8) 将保存工作文件夹保存在桌面,文件名为test1.wfl ;依次点击File-Save As 将文件保存在桌面,命名为test1.wfl (9) 对eq01的估计结果做经济意义检验和统计检验(05.0=α),估计的效果如何?经济意义检验:x 的系数β2的估计值为0.088820,说明地区生产总值每增加1亿元,地方预算内财政收入平均来说增加0.088820亿元,该值处于(0,1)符合预期。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
EVIEWS实验报告专业:金融学班级:10907学号:*******姓名:***一、选题自1949年新中国成立以后,我国国债发行基本分为两个阶段:20世纪50年代是第一阶段,为了支援人民解放战争,恢复和发展经济,我国先后发行过人民胜利折实公债和国家经济建设公债。
80年代以来是第二阶段,进入20世纪80年代以后,随着改革开放的不断深入,我国国民收入分配格局发生了变化,国债的发行量也逐年扩大。
本次实验出发点是根据1980-2005年的国债规模和可能的相关因素进行分析,同时达到掌握使用EVIEWS进行经济问题分析的目的。
二、建立模型影响国债规模的因素是多方面的、多层次的,我们暂且不去考虑微观上国债的管理水平与结构、筹资成本、期限安排、偿还方式等因素,因为这些因素的影响是个别的,并且难以计量。
所以从宏观经济角度出发,引入财政赤字、国内生产总值(GDP)、年还本付息支出等指标,并建立多元线性回归模型。
以国债发行量作为被解释变量Y,财政赤字、GDP、还本付息支出作为解释变量分别用X1、X2、X3表示。
建立模型如下:Y=b0+b1*X1+b2*X2+b3*X3三、数据来源下表列出了1980-2005年间历年国债发行规模及各相关因素的具体数据表1 单位:亿元(来源于中国统计年鉴2006,1980-2005年数据)四、实验结果通过普通最小二乘法对变量进行回归估计,得到结果如下:Dependent Variable: YMethod: Least SquaresDate: 10/02/11 Time: 13:09Sample: 1980 2005Included observations: 26Variable Coefficient Std. Error t-Statistic Prob.C -82.30505 63.20978 -1.302093 0.2064X1 0.816282 0.075733 10.77836 0.0000X2 0.671558 0.414988 1.618259 0.1199X3 0.980645 0.160403 6.113619 0.0000R-squared 0.994963 Mean dependent var 2015.208Adjusted R-squared 0.994276 S.D. dependent var 2355.453S.E. of regression 178.2087 Akaike info criterion 13.34443Sum squared resid 698683.5 Schwarz criterion 13.53798Log likelihood -169.4775 F-statistic 1448.494Durbin-Watson stat 1.141533 Prob(F-statistic) 0.000000Y=-82.3051+0.8163X1+0.6716X2+0.9806X3五、模型检验1、从回归估计的结果看,可决系数R2=0.9949,模型拟合较好。
方程的显著性检验中F的伴随概率等于0,小于0.05,说明所有的待估参数不全为零,方程总体上的线性关系是显著成立的。
在变量的显著性检验中,X1和X3的t检验伴随概率均小于0.05,说明变量显著。
而C和X2的t检验伴随概率大于0.05,变量不显著。
2、异方差性检验。
对模型进行不包含交叉乘积项的White检验,结果显示存在异方差性。
White Heteroskedasticity Test:Test Equation:Dependent Variable: RESID^2Method: Least SquaresDate: 10/02/11 Time: 21:14Sample: 1980 2005Included observations: 26Variable Coefficient Std. Error t-Statistic Prob.C -26554.99 23537.57 -1.128196 0.2733X1 35.21995 99.91746 0.352490 0.7284X1^2 -0.014355 0.025157 -0.570602 0.5750X2 422.3798 248.5467 1.699398 0.1056X2^2 -0.394623 0.134875 -2.925851 0.0087X3 -174.6289 102.0625 -1.710999 0.1034X3^2 0.089593 0.029247 3.063328 0.0064R-squared 0.625761 Mean dependent var 26872.44Adjusted R-squared 0.507580 S.D. dependent var 67942.62S.E. of regression 47677.14 Akaike info criterion 24.60710Sum squared resid 4.32E+10 Schwarz criterion 24.94581Log likelihood -312.8922 F-statistic 5.294942Durbin-Watson stat 2.476291 Prob(F-statistic) 0.0023323、随机误差项与解释变量的相关性检验。
以随机误差项U作为被解释变量,与三个解释变量一起进行回归估计,得到结果如下:Dependent Variable: UMethod: Least SquaresDate: 10/02/11 Time: 14:01Sample: 1980 2005Included observations: 26Variable Coefficient Std. Error t-Statistic Prob.C -17.40680 63.20978 -0.275381 0.7856X1 -0.004304 0.075733 -0.056831 0.9552X2 0.064139 0.414988 0.154556 0.8786X3 -0.027858 0.160403 -0.173677 0.8637R-squared 0.001765 Mean dependent var -14.33804Adjusted R-squared -0.134358 S.D. dependent var 167.3223S.E. of regression 178.2087 Akaike info criterion 13.34443Sum squared resid 698683.5 Schwarz criterion 13.53798Log likelihood -169.4775 F-statistic 0.012963Durbin-Watson stat 1.141533 Prob(F-statistic) 0.997919结果显示,估计变量的t检验的伴随概率均大于0.05,说明随机误差项与解释变量之间不相关。
4、正态性检验和序列相关性检。
在经典假设中,随机误差项服从零均值、同方差的正态分布,并且序列不相关,所以需要检验随机误差项是否满足正态性假设和序列不相关的假设。
检验结果如下:看图形右侧的指标,“Jarque-Bera”的伴随概率小于0.05,表明正态性假设不成立。
同时对模型进行自相关检验,结果如下:Breusch-Godfrey Serial Correlation LM Test:F-statistic 2.919863 Probability 0.077165Obs*R-squared 5.875948 Probability 0.052973Test Equation:Dependent Variable: RESIDMethod: Least SquaresDate: 10/02/11 Time: 21:12Presample missing value lagged residuals set to zero.Variable Coefficient Std. Error t-Statistic Prob.C 46.76660 64.97195 0.719797 0.4800X1 0.051967 0.073114 0.710763 0.4854X2 -0.423398 0.428181 -0.988829 0.3346X3 0.135687 0.158727 0.854842 0.4028 RESID(-1) 0.600517 0.289957 2.071057 0.0515RESID(-2) -0.215861 0.449609 -0.480108 0.6364R-squared 0.225998 Mean dependent var -5.17E-13Adjusted R-squared 0.032497 S.D. dependent var 167.1746S.E. of regression 164.4358 Akaike info criterion 13.24209Sum squared resid 540782.4 Schwarz criterion 13.53242Log likelihood -166.1472 F-statistic 1.167945Durbin-Watson stat 2.068695 Prob(F-statistic) 0.359125 “Obs*R-squared”的伴随概率大于0.05,表明不存在二阶自相关。
六、模型的修正我们考虑采用加权最小二乘法来修正模型,以w作为权数。
w=1/abs[Y-(b0+b1*X1+b2*X2+b3*X3)]再次对其进行回归估计,估计结果如下:Variable Coefficient Std. Error t-Statistic Prob.C -64.89825 9.577072 -6.776419 0.0000X1 0.820586 0.012323 66.58738 0.0000X2 0.607420 0.048240 12.59162 0.0000X3 1.008503 0.023160 43.54494 0.0000Weighted StatisticsR-squared 0.999868 Mean dependent var 1511.973Adjusted R-squared 0.999851 S.D. dependent var 2643.072S.E. of regression 32.31651 Akaike info criterion 9.929672Sum squared resid 22975.85 Schwarz criterion 10.12323Log likelihood -125.0857 F-statistic 47766.23Durbin-Watson stat 0.791044 Prob(F-statistic) 0.000000从回归估计的结果看,可决系数R2=0.9999,拟合效果非常好。