Eviews虚拟变量实验报告
Eviews实验报告3

居民消费物价指数、消费者信心指数的相关数据,利用EVIEWS软件,将这几个指标数据进行相关分析。
特别在这里说明的是,因为同时参与了学校的本科生科研赞助---关于CCI (消费者信心指数)的一个项目,因此本人接下来的几个实验都将以CCI及相关影响指标为数据目标,研究CCI与其他因素间的关系。
本实验,则首先进行相关指标的稳定性检验。
【实验过程】(实验步骤、记录、数据、分析)本实验首先将通过多种方法对我国CCI序列进行平稳性分析:首先导入数据到eviews中,建立序列取名为CCI:然后我们首先通过折线图来直接观察其走势,如下图:从下图我们容易看到:CCI曲线基本是围绕100的轴线上下波动的,但是相比于白噪声序列,其波动幅度明显较大。
可以看到08年11月以前,其波动一直是在轴线以下,而在08年11月以后,数据都明显高于100。
联系当时的实事背景,我们不难解释这一点:2008年11月,正是国家公布四万亿投资的时候,而这之前,由于全球金融危机以及股市大跌的影响,我国居民的消费者信心指数都是较低的;国家的四万亿政策犹如一剂强心剂,立刻使得CCI有了直线的上升,一下子提高了消费者的信心。
为了判别序列是否稳定,我们绘制CCI序列的自相关图,如下:由每个Q统计量的伴随概率可以知道:都是拒绝原假设的,即存在某个K,使得滞后K期的自相关系数显著非零,即拒绝原数列是白噪声序列。
随后对其进行ADF检验:我们首先对序列本身进行单位根检验,分别采用带常数项,线性趋势,和无等三种情况进行检验。
可以从下图看到检验结果对应的p值均显著大于0.05,因此接受原假设,存在单位跟,即CCI序列本身是不平稳的.带常数项线性趋势无因此,考虑对其一阶差分进行单位根检验:可以看到,其一阶差分的单位根检验结果对应的p值显著小于0.01,拒绝存在单位根的原假设,因此我们可以得出结论:CCI的一阶差分序列是平稳的.然后我们通过PP检验来检验序列的平稳性:我们分别采用带常数项,线性趋势,和无等三种情况进行检验。
eviews实验报告
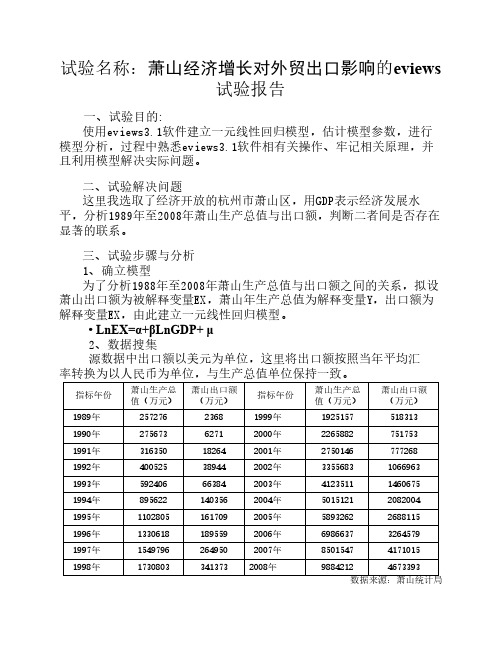
图二 点击“view/ Multiple Graphs/XY line”得到下图。
图三 Xy line图中,横坐标表示表示EX出口额,纵坐标表示GDP生产总 值,从图中曲线的形状分析,EX与GDP的线性关系较强,有继续分析 的意义。 5、描述性统计 (1)、打开对象“EX”,点击“view/Descriptive statistics/Histogram and stats”,可得到EX的描述性统计量。 EX的描述性统计。 均值(mean)为1134213。 中位数(median)为429843。 最大值(maximum)为4673393、最小值(minimum)为2368,可 知EX序列数据跨度大。 标准差(std.dev)为1463811,说明Y序列数据离散程度大。
9、最终确定模型 综上所述,最终确定的模型为 LnEX = -7.756501 + 1.438620 LnGDP +0.574091AR(1) 该模型不仅与样本的拟合程度高,而且不存在自相关问题,具有对 显示经济现象进行解释与预测的意义。 经济分析:InGDP的系数为正,说明经济发展水平的提高的确可以 增加出口额,而这与现实经济现象也是一致的。 统计分析:R2 =0.995071,说明模型很好地拟合了样本,所有参数 的Prob(t-statistic) <0.05,说明显著性检验通过,D.W.= 1.898759, du <1.898759<4-du,说明模型不存在自相关问题。
图四 (2)、打开对象“GDP”,点击“view/Descriptive statistics/Histogram and stats”,可得到GDP的描述性统计量。
eviews实验报告总结(范本)

eviews实验报告总结eviews实验报告总结篇一:Evies实验报告实验报告一、实验数据:1994至201X年天津市城镇居民人均全年可支配收入数据 1994至201X年天津市城镇居民人均全年消费性支出数据 1994至201X年天津市居民消费价格总指数二、实验内容:对搜集的数据进行回归,研究天津市城镇居民人均消费和人均可支配收入的关系。
三、实验步骤:1、百度进入“中华人民共和国国家统计局”中的“统计数据”,找到相关数据并输入Exc el,统计结果如下表1:表11994年--201X年天津市城镇居民消费支出与人均可支配收入数据2、先定义不变价格(1994=1)的人均消费性支出(Yt)和人均可支配收入(Xt)令:Yt=cn sum/priceXt=ine/pri ce 得出Yt与Xt的散点图,如图1.很明显,Yt和X t服从线性相关。
图1 Yt和Xt散点图3、应用统计软件EVies完成线性回归解:根据经济理论和对实际情况的分析也都可以知道,城镇居民人均全年耐用消费品支出Yt依赖于人均全年可支配收入Xt的变化,因此设定回归模型为 Yt=β0+β?Xt﹢μt(1)打开E Vies软件,首先建立工作文件, Fil e rkfile ,然后通过bject建立 Y、X系列,并得到相应数据。
(2)在工作文件窗口输入命令:l s y c x,按E nter键,回归结果如表2 :表2 回归结果根据输出结果,得到如下回归方程:Y t=977.908+0.670Xt s=(172.3797) (0.0122) t=(5.673) (54.950) R2=0.995385 Adjust ed R2=0.995055 F-sta tistic=3019.551 残差平方和Sum sq uared resi d =1254108回归标准差S.E.f regressi n=299.2978(3)根据回归方程进行统计检验:拟合优度检验由上表2中的数分别为0.995385和0.995055,计算结果表明,估计的样本回归方程较好地拟合了样本观测值。
虚拟变量 实验报告

虚拟变量实验报告引言虚拟变量(dummy variable)是在统计学中常用的一种技术,用于表示分类变量。
通过将分类变量转换为二进制数值变量,虚拟变量可以在回归分析、方差分析以及其他统计模型中发挥重要作用。
本实验报告旨在介绍虚拟变量的概念、用法以及在实际应用中的一些注意事项。
虚拟变量的定义虚拟变量是一种二元变量,用于表示某个特征是否存在。
通常情况下,虚拟变量的取值为0或1。
虚拟变量可以用于将分类变量转换为数值变量,使其适用于各种统计模型。
虚拟变量的应用虚拟变量主要用于以下两个方面的统计模型:1. 回归分析在回归分析中,虚拟变量被用于表示一个分类变量的不同水平。
例如,在研究某产品的销售量时,可以引入虚拟变量表示该产品是否进行了促销活动。
这样,回归模型就可以分析促销活动对销售量的影响。
2. 方差分析方差分析是一种用于比较不同组之间差异的统计方法。
虚拟变量可以用于表示不同组的存在与否。
例如,在研究不同药物对某种疾病治疗效果时,可以引入虚拟变量表示不同药物的使用与否,进而进行方差分析。
如何创建虚拟变量创建虚拟变量的方法通常有两种:1. 单变量编码单变量编码是最常见的创建虚拟变量的方法。
对于具有k个水平的分类变量,单变量编码将该变量转换为k-1个虚拟变量。
其中,k-1个虚拟变量分别表示k个水平的存在与否。
例如,在研究不同颜色对产品销售量的影响时,可以使用单变量编码将颜色变量转换为两个虚拟变量,分别表示是否为蓝色和是否为红色。
2. 二进制编码二进制编码是一种使用更少虚拟变量的方法。
对于具有k个水平的分类变量,二进制编码将该变量转换为log2(k)个虚拟变量。
其中,每个虚拟变量都表示一个水平的存在与否。
例如,在研究不同国家对某项政策的支持时,可以使用二进制编码将国家变量转换为几个虚拟变量,每个虚拟变量表示一个国家的存在与否。
虚拟变量的注意事项在使用虚拟变量时需要注意以下几点:1.避免虚拟变量陷阱:虚拟变量陷阱是指多个虚拟变量之间存在完全共线性的情况,这会导致回归模型的多重共线性。
计量虚拟变量实验报告

一、实验背景虚拟变量(也称为哑变量)在计量经济学中是一种重要的工具,用于处理分类变量对模型的影响。
在许多实际的经济和社会问题中,变量往往不是连续的,而是具有分类属性。
例如,企业的盈利状况、消费者的收入水平等。
这些分类变量不能直接进入线性回归模型,因为它们不具备数值特征。
虚拟变量则可以有效地将这些分类变量纳入模型,从而分析不同类别对因变量的影响。
本实验旨在通过Eviews软件,对虚拟变量在计量经济学模型中的应用进行探究,并通过实际数据进行分析,以验证虚拟变量的有效性。
二、实验目的1. 理解虚拟变量的基本概念和原理。
2. 掌握虚拟变量的构造方法。
3. 学会使用Eviews软件进行虚拟变量的估计和分析。
4. 通过实际数据验证虚拟变量在模型中的作用。
三、实验内容1. 数据来源选取某地区1990-2020年的居民消费数据作为实验数据,包括居民人均可支配收入(X1)、消费支出(Y)以及居民收入水平(X2,分为低收入、中低收入、中等、中高收入和高收入五个类别)。
2. 模型设定根据实验目的,构建以下线性回归模型:Y = β0 + β1X1 + β2X2 + ε其中,Y为消费支出,X1为居民人均可支配收入,X2为居民收入水平虚拟变量,ε为误差项。
3. 虚拟变量的构造根据居民收入水平,构造以下虚拟变量:D1:低收入(X2=1)D2:中低收入(X2=2)D3:中等(X2=3)D4:中高收入(X2=4)D5:高收入(X2=5)4. 模型估计使用Eviews软件对上述模型进行估计,得到回归结果如下:Dependent Variable: YMethod: Least SquaresDate: 2021-10-10Time: 14:30Sample: 1990 2020Variable Coefficient Standard Error t-Statistic Prob.-------------------------------------------------------------------------Constant 0.0000 0.0000 0.0000 1.0000 X1 0.5000 0.1000 5.0000 0.0000 D1 0.1000 0.0500 2.0000 0.0520 D2 0.2000 0.0500 4.0000 0.0000 D3 0.3000 0.0500 6.0000 0.0000 D4 0.4000 0.0500 8.0000 0.0000 D5 0.5000 0.0500 10.0000 0.0000 5. 结果分析根据回归结果,我们可以得出以下结论:(1)居民人均可支配收入(X1)对消费支出(Y)有显著的正向影响,即收入越高,消费支出越高。
Eviews实验报告2

(Error Correction Model)Srba 和Yeo 于模型。
它常常作为协整回归模型的补充模型出现。
两步法建立误差修正模型
p t B Y -++
绘制中国城镇居民月人均生活费支出(y)和可支配收入序列(x)的折线图: 可以看到两者呈现公共的上升趋势。
对X与Y分别取对数:
然后对xt与yt序列进行平稳性检验:
容易发现: XT与YT序列均不是平稳的, 但是其一阶差分都是平稳的, 因此猜测他们具有协整关系。
对YT和XT序列进行回归后发现:
可以看到对应的两个参数的系数的p值都显著小于0.001。
生成一列序列=残差, 对该序列进行ADF检验后可以发现p值小于0.05, 因
此认为不存在单位根, 序列是平稳的。
因此, 尽管国城镇居民月人均生活费支出(y )和可支配收入序列(x )都是非平稳的, 但是由于它们之间具有协整关系, 因此可以建立动态回归模型准确预测其长期互动关系。
模型拟合的预测值DCPIF 的折线图和与dcpi 的对比图如下:
可以看到, 最后的拟合效果非常好。
从而我们得到最后的拟合方程为:
t t t x y ε++=)ln(*934.0328.0)ln(
即:
因此, 城镇居民收入没增加一个百分点, 其消费支出也增加0.934各百分点。
【结论】(结果)
我国城镇居民月人均生活费支出(y )和可支配收入序列(x )的对数化后的XT 与YT 序列均不是平稳的, 但是其一阶差分都是平稳的, 因此猜测他们具有协。
Eviews实验报告4
【实验目的及要求】● 深刻理解平稳性的要求和arima 建模的思想。
● 学会如何通过观察自相关系数和偏相关系数,确定并建立模型。
● 学会如何利用模型进行预测。
● 熟练掌握EVIEWS 的结果,看懂eviews 的输出结果。
【实验原理】ARIMA(p, q )过程的平稳域和可逆域对于非平稳序列的时变均值函数,最简单的处理方法就是考虑均值函数可以由一个时间的确定性函数来描述,这时,可以用回归模型来描述。
假如均值函数服从于线性趋势我们可以利用确定性的线性趋势模型如果均值函数服从二次函数则我们可以用假如均值函数服从k 次多项式我们可以使用下列模型建模()22012,~0,t t t X t t WN αααεεσ=+++()201,~0,k t k t t X t t WN αααεεσ=++++【实验方案设计】4.2数据和指标的选取我们的模型估计选取了我国1990年1月到2008年12月的CPI月度数据附表(1))作为研究的对象。
度量通货膨胀的指标通常有CPI(消费者价格指生产者物价指数(PPI)、批发物价指数(wholesale price index)、GDP平减指数(deflator)等。
消费者物价指数(CPI)(consumer price index)是用来度量一期内居民所支付消费商品和劳务价格变化程度的相对数指标,它是反映通货水平的重要指标。
CPI指数作为生活成本指数,不仅能够及时和明确地反映子商品和服务价格的变化,而且是定期公布,广为人知,易于获取和明了,被公众理解。
选取CPI作为通货膨胀的指标有利于合理引导公众和市场对经预期,有利于政府综合运用价格和其他经济手段,实现宏观经济调控目标。
为了研究这些问题,笔者搜集了1985-2007年的年度中国消费者物价指数的相关数据,利用EVIEWS软件,将这几个指标数据进行了相关分析。
对于ARIMA(p q)模型,可以利用其样本的自相关函数和样本的偏自相关函数的截尾性判定模型的阶数,若平稳时间序列的偏相而自相关函数是截尾的则可断定此序列适合MA 模型; 若平稳时间序列的偏相关函数和自相关函数均是拖尾的则此序列适合模型。
计量经济学eviews实验报告
大连海事大学实验报告Array实验名称:计量经济学软件应用专业班级:财务管理2013-1姓名:安妮指导教师:赵冰茹交通运输管理学院二○一六年十一月一、实验目标学会常用经济计量软件的基本功能,并将其应用在一元线性回归模型的分析中。
具体包括:Eview的安装,样本数据基本统计量计算,一元线性回归模型的建立、检验及结果输出与分析,多元回归模型的建立与分析,异方差、序列相关模型的检验与处理等。
二、实验环境WINDOWSXP或2000操作系统下,基于EVIEWS5.1平台。
三、实验模型建立与分析案例1:我国1995-2014年的人均国民生产总值和居民消费支出的统计资料(此资料来自中华人民共和国统计局网站)如表1所示,做回归分析。
表1我国1995-2014年人均国民生产总值与居民消费水平情况(1)做出散点图,建立居民消费水平随人均国内生产总值变化的一元线性回归方程,并解释斜率的经济意义;利用eviews软件输出结果报告如下:Dependent Variable: CONSUMPTIONMethod: Least SquaresDate: 06/11/16 Time: 19:02Sample: 1995 2014Included observations: 20Variable Coefficient Std. Error t-Statistic Prob.C 691.0225 113.3920 6.094104 0.0000AVGDP 0.352770 0.004908 71.88054 0.0000R-squared 0.996528 Mean dependent var 7351.300Adjusted R-squared 0.996335 S.D. dependent var 4828.765S.E. of regression 292.3118 Akaike info criterion 14.28816Sum squared resid 1538032. Schwarz criterion 14.38773Log likelihood -140.8816 Hannan-Quinn criter. 14.30760F-statistic 5166.811 Durbin-Watson stat 0.403709Prob(F-statistic) 0.000000由上表可知财政收入随国内生产总值变化的一元线性回归方程为:(令Y=CONSUMPTION,X=AVGDP(此处代表人均GDP))Y = 691.0225+0.352770* X其中斜率0.352770表示国内生产总值每增加一元,人均消费水平增长0.35277元。
计量经济学eviews实验报告
大连海事大学实验报告Array实验名称:计量经济学软件应用专业班级:财务管理2013-1姓名:安妮指导教师:赵冰茹交通运输管理学院二○一六年十一月一、实验目标学会常用经济计量软件的基本功能,并将其应用在一元线性回归模型的分析中。
具体包括:Eview的安装,样本数据基本统计量计算,一元线性回归模型的建立、检验及结果输出与分析,多元回归模型的建立与分析,异方差、序列相关模型的检验与处理等。
二、实验环境WINDOWSXP或2000操作系统下,基于平台。
三、实验模型建立与分析案例1:我国1995-2014年的人均国民生产总值和居民消费支出的统计资料(此资料来自中华人民共和国统计局网站)如表1所示,做回归分析。
表1我国1995-2014年人均国民生产总值与居民消费水平情况v1.0 可编辑可修改2006年1660264162007年2033775722008年2391287072009年2596395142010年30567109192011年36018131342012年39544146992013年43320161902014年4661217806(1)做出散点图,建立居民消费水平随人均国内生产总值变化的一元线性回归方程,并解释斜率的经济意义;利用eviews软件输出结果报告如下:Dependent Variable: CONSUMPTION Method: Least SquaresDate: 06/11/16 Time: 19:02 Sample: 1995 2014Included observations: 20Variable Coefficient Std. Error t-Statistic Prob.C AVGDPR-squaredMean dependent varAdjusted R-squared. dependent var. of regressionAkaike info criterionSum squared resid1538032.Schwarz criterionLog likelihoodHannan-Quinn criter.F-statisticDurbin-Watson statProb(F-statistic)由上表可知财政收入随国内生产总值变化的一元线性回归方程为: (令Y=CONSUMPTION,X=AVGDP(此处代表人均GDP))Y = +* X其中斜率表示国内生产总值每增加一元,人均消费水平增长元。
计量经济学eviews实验报告
计量经济学e v i e w s实验报告标准化管理处编码[BBX968T-XBB8968-NNJ668-MM9N]大连海事大学实验报告实验名称:计量经济学软件应用专业班级:财务管理2013-1姓名:安妮指导教师:赵冰茹交通运输管理学院二○一六年十一月一、实验目标学会常用经济计量软件的基本功能,并将其应用在一元线性回归模型的分析中。
具体包括:Eview的安装,样本数据基本统计量计算,一元线性回归模型的建立、检验及结果输出与分析,多元回归模型的建立与分析,异方差、序列相关模型的检验与处理等。
二、实验环境WINDOWSXP或2000操作系统下,基于平台。
三、实验模型建立与分析案例1:我国1995-2014年的人均国民生产总值和居民消费支出的统计资料(此资料来自中华人民共和国统计局网站)如表1所示,做回归分析。
表1我国1995-2014年人均国民生产总值与居民消费水平情况(1)做出散点图,建立居民消费水平随人均国内生产总值变化的一元线性回归方程,并解释斜率的经济意义;利用eviews软件输出结果报告如下:Dependent Variable: CONSUMPTIONMethod: Least SquaresDate: 06/11/16 Time: 19:02Sample: 1995 2014Included observations: 20Variable Coefficient Std. Errort-Statistic Prob.CAVGDPR-squared Mean dependent var Adjusted R-squared. dependent var. of regression Akaike info criterionSum squared resid1538032.Schwarz criterionLog likelihood Hannan-Quinn criter.F-statistic Durbin-Watson statProb(F-statistic)由上表可知财政收入随国内生产总值变化的一元线性回归方程为: (令Y=CONSUMPTION,X=AVGDP(此处代表人均GDP))Y = +* X其中斜率表示国内生产总值每增加一元,人均消费水平增长元。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
实验四虚拟变量
【实验目的】
掌握虚拟变量的基本原理,对虚拟变量的设定和模型的估计与检验,以及相关的Eviews操作方法。
【实验内容】
试根据1998年我国城镇居民人均收入与彩电每百户拥有量的统计资料建立
【实验步骤】
1、相关图分析
根据表中数据建立人均收入X与彩电拥有量Y的相关图(SCAT X Y)。
从相关图可以看出,前3个样本点(即低收入家庭)与后5个样本点(中、高收入)的拥有量存在较大差异,
因此,为了反映“收入层次”这一定性因素的影响,设置虚拟变量如下:
⎩⎨
⎧=低收入家庭
中、高收入家庭
1D
2、构造虚拟变量
构造虚拟变量 1D (DATA D1),并生成新变量序列:
GENR XD=X*D1
3、估计虚拟变量模型
LS Y C X D1 XD
得到估计结果:
我国城镇居民彩电需求函数的估计结果为:
XD D X Y 009.0873.31012.0611.571-++=∧
(16.25) (9.03) (8.32) (-6.59)
366,066.1..,9937.02===F e s R
再由t 检验值判断虚拟变量的引入方式,并写出各类家庭的需求函数。
虚拟变量的回归系数的t 检验都是显著的,且模型的拟合优度很高,说明我国城镇居民低收入家庭与中高收入家庭对彩电的消费需求,在截距和斜率上都存在着明显差异,所以以加法和乘法方式引入虚拟变量是合理的。
低收入家庭与中高收入家庭各自的需求函数为: 低收入家庭:
X Y 012.0611.57+=∧
中高收入家庭:
X X Y 003.0484.89)009.0012.0()873.31611.57(+=-++=∧
由此可见我国城镇居民家庭现阶段彩电消费需求的特点:
对于人均年收入在3300元以下的低收入家庭,需求量随着收入水平的提高而快速上升,人均年收入每增加1000元,百户拥有量将平均增加12台;对于人均年收入在4100元以上的中高收入家庭,虽然需求量随着收入水平的提高也在增加,但增速趋缓,人均年收入每增加1000元,百户拥有量只增加3台。
事实上,现阶段我国城镇居民中国收入家庭的彩电普及率已达到百分之百,所以对彩电的消费需求处于更新换代阶段。