实验报告7-虚拟变量
虚拟变量实验报告感想

通过本次虚拟变量实验,我对虚拟变量有了更加深入的理解和认识,感受到了其在计量经济学中的重要作用。
以下是我对本次实验的一些感想。
一、虚拟变量的重要性虚拟变量在计量经济学中具有举足轻重的地位。
它可以将定性变量转化为定量变量,使模型更加全面地反映经济现象。
在现实生活中,许多因素都是定性因素,如性别、民族、地区等,这些因素无法直接用数值表示,但它们对经济现象的影响却是客观存在的。
虚拟变量恰好能够将这些定性因素纳入模型,使模型更加准确、全面地反映经济现象。
二、虚拟变量的设定在本次实验中,我们学习了如何设定虚拟变量。
首先,要明确虚拟变量的含义和作用,然后根据研究目的和实际数据情况,确定虚拟变量的个数。
需要注意的是,当定性变量含有m个类别时,应引入m-1个虚拟变量,以避免多重共线性问题。
此外,虚拟变量的取值应遵循互斥和完备的原则,即每个样本只能属于一个类别。
三、虚拟变量的估计与检验在本次实验中,我们运用Eviews软件对虚拟变量模型进行了估计和检验。
通过观察模型的回归结果,我们可以了解虚拟变量对因变量的影响程度。
此外,我们还可以通过t检验、F检验等方法对虚拟变量的显著性进行检验。
在检验过程中,要注意控制其他变量的影响,以确保检验结果的可靠性。
四、虚拟变量的应用虚拟变量在实际应用中非常广泛。
以下是一些常见的应用场景:1. 时间序列分析:在时间序列分析中,虚拟变量可以用来表示季节性、节假日等因素对经济现象的影响。
2. 州际差异分析:在分析不同地区经济现象时,可以引入地区虚拟变量,以反映地区间的差异。
3. 政策效应分析:在分析政策对经济现象的影响时,可以引入政策虚拟变量,以观察政策实施前后经济现象的变化。
4. 模型设定:在构建计量经济模型时,可以引入虚拟变量来表示定性因素,使模型更加全面。
五、实验收获通过本次虚拟变量实验,我收获颇丰。
首先,我掌握了虚拟变量的基本原理和操作方法,为今后的研究奠定了基础。
其次,我学会了如何设定虚拟变量、估计模型和检验结果,提高了自己的实践能力。
【精品】计量经济学实验报告(虚拟变量)

【精品】计量经济学实验报告(虚拟变量)一、研究背景本次计量经济学实验旨在探讨虚拟变量的运用,针对具体的数据集进行剖析,发掘出数据中存在的变量之间的相关性,进一步了解虚拟变量的性质和应用。
二、研究数据与模型本次实验所使用的数据主要来自于美国地区居民的生活经历与工作情况。
我们采用了线性回归模型来建立数据之间的相关性。
其中,自变量包括:年龄、性别、收入、婚姻状态、教育程度、是否有孩子和是否居住在城市;因变量为每周工作时间。
首先,我们运用SPSS对数据进行了初步的分析。
结果显示,数据存在了年龄、性别、收入、婚姻状态、教育程度、是否有孩子和是否居住在城市等多个变量。
其中,包括了虚拟变量。
我们选取了其中一个虚拟变量进行研究,即“是否有孩子”。
在该变量中,响应值为“是”、“否”,我们将其转换为虚拟变量,即0表示没有孩子,1表示有孩子。
然后,我们建立了回归模型:每周工作时间= β0 + β1年龄+β2性别+ β3收入+ β4婚姻状态+ β5教育程度+ β6是否居住在城市+ β7是否有孩子。
最后,我们选取了样本数据中的500个数据进行模型拟合,其中250条数据表示没有孩子,250条数据表示有孩子。
三、实验结果通过数据分析软件的运算,我们得出了模型拟合的结果。
模型拟合结果如下:从结果中我们可以看出,虚拟变量“是否有孩子”对于每周工作时间的影响显著,其系数为2.01,t值为4.8,显著性水平为0.01,说明儿童数量对于家长的工作时间有显著的影响。
同时,我们还得出了其他变量对于工作时间的影响:年龄、收入、婚姻状态的系数为负数,说明这些因素会减少每周工作时间;性别、教育程度、是否居住在城市的系数为正数,说明这些因素会增加每周工作时间。
四、结论通过本次实验,我们可以得出以下结论:1.虚拟变量是计量经济学中常见的方法之一,在处理定量变量与定性变量时能够有效的将其转换为数值变量。
2.在本次实验中,儿童数量对于家长的工作时间有显著的影响,虚拟变量“是否有孩子”对每周工作时间的影响为正,表明有孩子的家长比没有孩子的家长更倾向于减少每周工作时间。
计量经济学虚拟变量实验报告
第七章虚拟变量实验报告一、研究目的改革开放以来,我国经济保持了长期较快发展,与此同时,我国对外贸易规模也日益增长。
尤其是2002年中国加入世界贸易组织之后,我国对外贸易迅速扩张。
2012年,我国进出口总值38667.6亿美元,与上年同期相比增长6.2%。
至此,我国贸易总额首次超过美国,成为世界贸易规模最大的国家。
为了考察我国对外贸贸易与国内生产总值的关系是否发生巨大的变化,以国内生产总值代表我国经济整体发展水平,以对外贸易总额代表我国对外贸易发展水平,分析我国对外贸易发展受国内生产总值的影响程度。
二、模型设定为研究我国对外贸易发展规模受我国经济发展程度影响,引入国内生产总值为自变量。
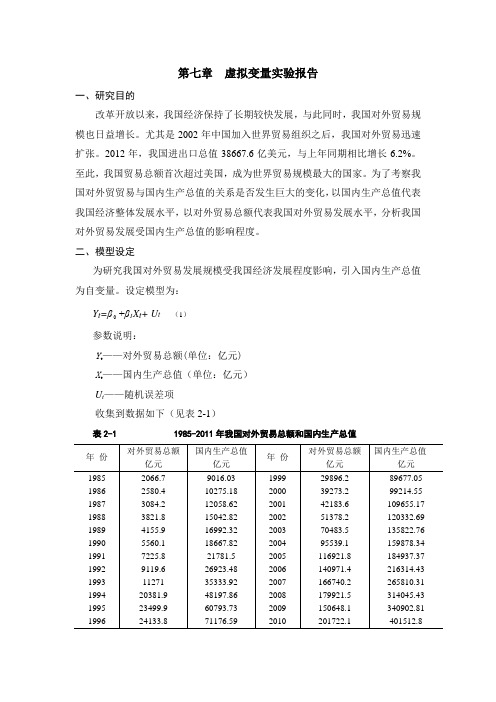
设定模型为:+β1X t+ U t (1)Y t=β参数说明:Y t——对外贸易总额(单位:亿元)X t——国内生产总值(单位:亿元)U t——随机误差项收集到数据如下(见表2-1)表2-1 1985-2011年我国对外贸易总额和国内生产总值注:资料来源于《中国统计年鉴》1986-2012。
为了研究1985-2011年期间我国对外贸易总额随国内生产总值的变化规律是否有显著不同,考证对外贸易与国内生产总值随时间变化情况,如下图所示。
图2.1 对外贸易总额(Y)与国内生产总值(X)随时间变化趋势图从图2.1中,可以看出对外贸易总额明显表现出了阶段特征:在2002年、2007年和2009年有明显的转折点。
为了分析对外贸易总额在2002年前后、2007年前后及2009年前后几个阶段的数量关系,引入虚拟变量D1、D2、D3。
这三个年度对应的GDP分别为120332.69亿元、265810.31亿元和340902.81亿元。
据此,设定以下以加法和乘法两种方式同时引入虚拟变量的模型:Y t=β0+β1Xt+β2(Xt-120332.69)D1+β3(Xt-265810.31)D2+β4(Xt-340902.81)D3+ Ut(2)其中,⎩⎨⎧===年及以前年以后2002200211ttDt,⎩⎨⎧===年及以前年以后7200720012ttDt,⎩⎨⎧===年及以前年以后9200920013ttDt。
虚拟变量实验报告心得

虚拟变量实验报告心得引言虚拟变量实验是社会科学研究中常用的一种方法,通过引入虚拟变量来衡量与原始变量相关的特定因素,从而更精确地分析因果关系。
在这次实验中,我们通过使用虚拟变量探究了性别对学生成绩的影响。
实验设计与方法我们选择了一所中学作为实验地点,选取了300名学生作为研究对象。
在实验开始前,我们在知情同意书中明确告知了学生和家长本次实验的目的和方法,以及他们可以随时退出实验的权利。
我们将参与者的性别作为自变量,学生成绩作为因变量。
通过收集学生在考试中的成绩和性别信息,并加入额外信息,如年龄、家庭背景等,用以控制其他可能影响学生成绩的因素。
结果分析通过对实验数据的统计分析,我们得到了一些有趣的结果。
在总体上,女生的平均成绩要高于男生,这与过去的研究结果一致。
然而,在进一步分析中,在不同年龄段中,这种差异并不明显。
在高年级中,男生的成绩甚至稍微高于女生。
这可能与个体差异、学习环境等因素有关。
在使用虚拟变量探究家庭背景对学生成绩的影响时,我们发现了一些有趣的现象。
在来自不同家庭背景的学生中,受教育程度较高的家庭孩子成绩明显优于受教育程度较低的家庭。
这表明家庭背景对学生成绩有重要的影响。
心得体会本次实验让我对虚拟变量有了更深入的理解。
虚拟变量作为一种常用的统计方法,可以在社会科学研究中提供更准确的分析结果。
通过引入虚拟变量,我们可以从不同的角度探究自变量与因变量之间的关系。
然而,在进行虚拟变量实验时,我们也遇到了一些困难和挑战。
首先,虚拟变量的选择需要基于理论和实际背景,需要合理的解释和解释能力。
其次,在实验设计中,需要仔细控制其他潜在因素,以确保对自变量的独立性检验有效。
另外,本次实验的样本数量有限,可能存在一定的局限性。
为了获得更加准确和可靠的结果,未来的研究可以考虑增加样本数量,扩大实验范围,以增强结果的可靠性。
总的来说,本次实验让我更加深入地了解和理解了虚拟变量,并掌握了其在社会科学研究中的应用。
虚拟变量 实验报告

虚拟变量实验报告引言虚拟变量(dummy variable)是在统计学中常用的一种技术,用于表示分类变量。
通过将分类变量转换为二进制数值变量,虚拟变量可以在回归分析、方差分析以及其他统计模型中发挥重要作用。
本实验报告旨在介绍虚拟变量的概念、用法以及在实际应用中的一些注意事项。
虚拟变量的定义虚拟变量是一种二元变量,用于表示某个特征是否存在。
通常情况下,虚拟变量的取值为0或1。
虚拟变量可以用于将分类变量转换为数值变量,使其适用于各种统计模型。
虚拟变量的应用虚拟变量主要用于以下两个方面的统计模型:1. 回归分析在回归分析中,虚拟变量被用于表示一个分类变量的不同水平。
例如,在研究某产品的销售量时,可以引入虚拟变量表示该产品是否进行了促销活动。
这样,回归模型就可以分析促销活动对销售量的影响。
2. 方差分析方差分析是一种用于比较不同组之间差异的统计方法。
虚拟变量可以用于表示不同组的存在与否。
例如,在研究不同药物对某种疾病治疗效果时,可以引入虚拟变量表示不同药物的使用与否,进而进行方差分析。
如何创建虚拟变量创建虚拟变量的方法通常有两种:1. 单变量编码单变量编码是最常见的创建虚拟变量的方法。
对于具有k个水平的分类变量,单变量编码将该变量转换为k-1个虚拟变量。
其中,k-1个虚拟变量分别表示k个水平的存在与否。
例如,在研究不同颜色对产品销售量的影响时,可以使用单变量编码将颜色变量转换为两个虚拟变量,分别表示是否为蓝色和是否为红色。
2. 二进制编码二进制编码是一种使用更少虚拟变量的方法。
对于具有k个水平的分类变量,二进制编码将该变量转换为log2(k)个虚拟变量。
其中,每个虚拟变量都表示一个水平的存在与否。
例如,在研究不同国家对某项政策的支持时,可以使用二进制编码将国家变量转换为几个虚拟变量,每个虚拟变量表示一个国家的存在与否。
虚拟变量的注意事项在使用虚拟变量时需要注意以下几点:1.避免虚拟变量陷阱:虚拟变量陷阱是指多个虚拟变量之间存在完全共线性的情况,这会导致回归模型的多重共线性。
第七章虚拟变量

第七章虚拟变量第七章虚拟变量第一节虚拟变量的引入一、什么是虚拟变量前面几章介绍的解释变量都是可以直接度量的,称为定量变量。
如收入、支出、价格、资金等等。
但在现实经济生活中,影响应变量变动的因素,除了这些可以直接获得实际观测数据的定量变量外,还包括一些无法定量的解释变量的影响,如性别、民族、国籍、职业、文化程度、政府经济政策变动等因素,他们只表示某种特征的存在与不存在,所以称为属性变量或定性变量。
属性变量:不能精确计量的说明某种属性或状态的定性变量。
在计量经济模型中,应当包含属性变量对应变量的影响作用。
那怎么才能把定性变量包括在模型中呢?属性变量通常是非数值变量,直接纳入回归方程中进行回归,显然是很困难的。
为此,人们采取了一种构造人工变量的方法,将这些定性变量进行量化,使其能与定量变量一样在回归模型中得以应用。
由于定性变量通常是表明某种特征或属性是否存在,如性别变量中以男性为分析基础的话,那就只有男性、非男性;政策变动变量中以政策不变为基准,则有政策不变,和政策变动;至于有两种以上的状态的话,比如学历分高中,本科,本科以上等等,我们又怎么办呢?把疑问留到后面去解决。
既然定性变量只有存在或不存在两种状态,所以量化的一般方法是取值为0或1。
称为虚拟变量。
虚拟变量:人工构造的取值为0或1的作为属性变量代表的变量。
一般常用D表示。
D=0,表示某种属性或状态不存在D=1,表示某种属性或状态存在比如前面说的性别变量,以男性为基准,则当样本为男性时,虚拟变量取0,当样本为女性时,则虚拟变量取1。
当虚拟变量作为解释变量引入计量经济模型时,对其回归系数的估计和统计检验方法都与定量解释变量相同。
二、虚拟变量的作用1、作为属性因素的代表,如,性别、种族等2、作为某些非精确计量的数量因素的代表,如:受教育程度、年龄段等;3、作为某些偶然因素或政策因素的代表,如战争、911等。
4、时间序列分析中作为季节(月份)的代表(比如对某些明显有淡季、旺季之分的产品)5、分段回归,研究斜率、截距的变动;6、比较两个回归模型;7、虚拟应变量概率模型,应变量本身是定性变量(比如你研究某产品的购买率,应变量本身就是买或不买)三、虚拟变量的设置规则1、虚拟变量D取值为0,还是取值为1,要根据研究的目的决定。
计量虚拟变量实验报告

一、实验背景虚拟变量(也称为哑变量)在计量经济学中是一种重要的工具,用于处理分类变量对模型的影响。
在许多实际的经济和社会问题中,变量往往不是连续的,而是具有分类属性。
例如,企业的盈利状况、消费者的收入水平等。
这些分类变量不能直接进入线性回归模型,因为它们不具备数值特征。
虚拟变量则可以有效地将这些分类变量纳入模型,从而分析不同类别对因变量的影响。
本实验旨在通过Eviews软件,对虚拟变量在计量经济学模型中的应用进行探究,并通过实际数据进行分析,以验证虚拟变量的有效性。
二、实验目的1. 理解虚拟变量的基本概念和原理。
2. 掌握虚拟变量的构造方法。
3. 学会使用Eviews软件进行虚拟变量的估计和分析。
4. 通过实际数据验证虚拟变量在模型中的作用。
三、实验内容1. 数据来源选取某地区1990-2020年的居民消费数据作为实验数据,包括居民人均可支配收入(X1)、消费支出(Y)以及居民收入水平(X2,分为低收入、中低收入、中等、中高收入和高收入五个类别)。
2. 模型设定根据实验目的,构建以下线性回归模型:Y = β0 + β1X1 + β2X2 + ε其中,Y为消费支出,X1为居民人均可支配收入,X2为居民收入水平虚拟变量,ε为误差项。
3. 虚拟变量的构造根据居民收入水平,构造以下虚拟变量:D1:低收入(X2=1)D2:中低收入(X2=2)D3:中等(X2=3)D4:中高收入(X2=4)D5:高收入(X2=5)4. 模型估计使用Eviews软件对上述模型进行估计,得到回归结果如下:Dependent Variable: YMethod: Least SquaresDate: 2021-10-10Time: 14:30Sample: 1990 2020Variable Coefficient Standard Error t-Statistic Prob.-------------------------------------------------------------------------Constant 0.0000 0.0000 0.0000 1.0000 X1 0.5000 0.1000 5.0000 0.0000 D1 0.1000 0.0500 2.0000 0.0520 D2 0.2000 0.0500 4.0000 0.0000 D3 0.3000 0.0500 6.0000 0.0000 D4 0.4000 0.0500 8.0000 0.0000 D5 0.5000 0.0500 10.0000 0.0000 5. 结果分析根据回归结果,我们可以得出以下结论:(1)居民人均可支配收入(X1)对消费支出(Y)有显著的正向影响,即收入越高,消费支出越高。
第七章虚拟变量

如何刻画我国居民在不同时段的消费行为?
基本思路:采用乘法方式引入虚拟变量的手段。显然, 1979年是一个转折点,可考虑在这个转折点作为虚拟 变量设定的依据。若设X* =1979,当 t<X* 时可引 入虚拟变量。(为什么选择1979作为转折点?)
实质:加法方式引入虚拟变量改变的是截距;乘法方式 引入虚拟变量改变的是斜率。
一、加法类型 (1)一个两种属性定性解释变量而无定量变量的情形
例:按性别划分的教授薪金
(2)包含一个定量变量,一个定性变量模型
, 设有模型,yt = 0 + 1 xt + 2D + ut
其中yt,xt为定量变量;D为定性变量。当D = 0 或1时,上述模型可表达为,
令Y代表年薪, X代表教龄,建立模型:
Yi B0 B1Xi B2D2i B3D3i B4D4i ui
可以看出基准类是本科女教师,B0为刚参加工作的本 科女教师的工资;B1为参加工作时间对工资的影响;B2 是性别差异系数;B3和B4为学历差异系数,B3是硕士学 历与本科学历的收入差异,B4是博士学历与本科学历的 收入差异;通过上述分析,我们可以确定Bi的符号。
问题:如何刻画同时发展油菜籽生产和养蜂生产的交互 作用?
基本思想:在模型中引入相关的两个变量的乘积。
区别之处在于,上页定义中的交互效应是针对数量变量, 而现在是定性变量,又应当如何处理?
(3)分段回归分析
作用: 提高模型的描述精度。
虚拟变量也可以用来代表数量因素的不同阶段。分段线性 回归就是类似情形中常见的一种。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
2013-2014学年第 一 学期
实 验 报 告
实验课程名称 虚拟变量模型
专 业 班 级 资产评估1101
学生 学号 31105073
学 生 姓 名 方申慧
实验指导教师 董美双
编号:
实验名称多重共线性检验与修正指导老师董美双成绩
专业资产评估班级 1101 姓名方申慧学号 31105073
一、实验目的
目的:通过实验,理解并掌握虚拟变量模型的意义、建模的方法、虚拟变量引入的原则和技巧等。
要求:熟练掌握虚拟变量引入的加法方式和乘法方式,并正确解读和分析回归结果。
首先做例题8-10,按步骤分析季节性因素的影响;然后利用上证指数的数据分析股市周效应(周1-周5任选),或者自己收集数据按上面的步骤做一遍,把结果输出到word文档中。
步骤:
例题8-10
Dependent Variable: Y
Method: Least Squares
Date: 11/28/13 Time: 09:12
Sample: 1982:1 1988:4
Included observations: 28
C 2431.198 93.35790 26.04170 0.0000
T 48.95067 4.528524 10.80941 0.0000
D1 1388.091 103.3655 13.42896 0.0000
D2 201.8415 102.8683 1.962136 0.0620
D3 85.00647 102.5688 0.828775 0.4157
R-squared 0.945831 Mean dependent var 3559.718
Adjusted R-squared 0.936411 S.D. dependent var 760.2102
S.E. of regression 191.7016 Akaike info criterion 13.51019
Sum squared resid 845238.2 Schwarz criterion 13.74808
Log likelihood -184.1426 F-statistic 100.4000 Durbin-Watson stat
1.215758 Prob(F-statistic)
0.000000
D2,D3不显著,D1显著 所以剔除D2,D3
Dependent Variable: Y Method: Least Squares Date: 11/28/13 Time: 09:17 Sample: 1982:1 1988:4 C 2515.862 78.55127 32.02828 0.0000 T 49.73300 4.677660 10.63203 0.0000 D1
1290.910
87.26062
14.79373
0.0000 R-squared
0.936688 Mean dependent var 3559.718 Adjusted R-squared 0.931623 S.D. dependent var 760.2102 S.E. of regression 198.7868 Akaike info criterion 13.52330 Sum squared resid 987904.7 Schwarz criterion 13.66604 Log likelihood -186.3262 F-statistic 184.9359 Durbin-Watson stat
1.403341 Prob(F-statistic)
0.000000
9
.184,7.198..,9316.0)79.14)(63.10)(03.32(91.129073.4986.25152
1===++=∧
F E S R
t D t y
模型效果显著
第一季度模型:y=2515.86+49.73t
第二,三,四季度模型:y=2515.86+1290.91+49.73t
利用上证指数的数据分析股市周效应(周1-周5任选)
时间
y t D1 D2 D3
D4
2013-09-23,一 2221.04 146 1 0 0 0 2013-09-24,二 2207.53 147 0 1 0 0 2013-09-25,三 2198.51 148 0 0 1 0 2013-09-26,四 2155.81 149 0 0 0 1 2013-09-27,五 2160.03 150 0 0 0 0 2013-09-30,一 2174.67 151 1 0 0 0 2013-10-08,二
2198.2
152
1
2013-10-09,三2211.77 153 0 0 1 0 2013-10-10,四2190.93 154 0 0 0 1 2013-10-11,五2228.15 155 0 0 0 0 2013-10-14,一2237.77 156 1 0 0 0 2013-10-15,二2233.41 157 0 1 0 0 2013-10-16,三2193.07 158 0 0 1 0 2013-10-17,四2188.54 159 0 0 0 1 2013-10-18,五2193.78 160 0 0 0 0 2013-10-21,一2229.24 161 1 0 0 0 2013-10-22,二2210.65 162 0 1 0 0 2013-10-23,三2183.11 163 0 0 1 0 2013-10-24,四2164.32 164 0 0 0 1 2013-10-25,五2132.96 165 0 0 0 0 2013-10-28,一2133.87 166 1 0 0 0 2013-10-29,二2128.86 167 0 1 0 0 2013-10-30,三2160.46 168 0 0 1 0 2013-10-31,四2141.61 169 0 0 0 1 2013-11-01,五2149.56 170 0 0 0 0 2013-11-04,一2149.63 171 1 0 0 0 2013-11-05,二2157.24 172 0 1 0 0 2013-11-06,三2139.61 173 0 0 1 0 2013-11-07,四2129.4 174 0 0 0 1 2013-11-08,五2106.13 175 0 0 0 0 2013-11-11,一2109.47 176 1 0 0 0 2013-11-12,二2126.77 177 0 1 0 0 2013-11-13,三2087.94 178 0 0 1 0 2013-11-14,四2100.51 179 0 0 0 1 2013-11-15,五2135.83 180 0 0 0 0 2013-11-18,一2197.22 181 1 0 0 0 2013-11-19,二2193.13 182 0 1 0 0 2013-11-20,三2206.61 183 0 0 1 0 2013-11-21,四2205.77 184 0 0 0 1 2013-11-22,五2196.38 185 0 0 0 0 2013-11-25,一2186.11 186 1 0 0 0 2013-11-26,二2183.07 187 0 1 0 0 2013-11-27,三2201.07 188 0 0 1 0 2013-11-28,四2219.37 189 0 0 0 1 2013-11-29,五2220.5 190 0 0 0 0 设周五为基础性变量
Dependent Variable: Y
Method: Least Squares
Date: 11/30/13 Time: 13:33
Sample(adjusted): 9/23/2013 11/29/2013
Variable Coefficient Std. Error t-Statistic Prob. C 2185.181 17.71836 123.3286 0.0000 T -0.636933 0.463976 -1.372773 0.1777 D1 10.30782 19.03243 0.541592 0.5912 D2 10.92698 18.99280 0.575322 0.5684 D3 5.262800 18.96445 0.277509 0.7829 R-squared
0.072773 Mean dependent var 2175.102 Adjusted R-squared -0.046102 S.D. dependent var 39.28610 S.E. of regression 40.18147 Akaike info criterion 10.34825 Sum squared resid 62967.48 Schwarz criterion 10.58914 Log likelihood -226.8357 F-statistic 0.612183 Durbin-Watson stat
0.288024 Prob(F-statistic)
0.691087
612183
.0,18147.40..,072.0)192301.0)(277509.0)(575322.0)(541592.0)(372773.1)(3286.123(643600.3262800.592692.1030782.10636933.0181.218524321===---+++-=∧
F E S R t D D D D t y
在0.05的显著性水平下,系数D 没有通过检验
周五模型:t y 636933.0181.2185
-=∧
周一周二周三周四模型:t y 636933.02215.322
-=∧。