统计学辛普森悖论
辛普森悖论名词解释(一)

辛普森悖论名词解释(一)辛普森悖论什么是辛普森悖论?辛普森悖论是一种统计学中的悖论,即在两个或多个子群体中观察到的某种趋势可能在将这些子群体合并后发生逆转的现象。
简单来说,辛普森悖论指的是对整体数据产生错误判断的情况。
辛普森悖论的背景辛普森悖论最早由英国数学家辛普森在1951年发现。
他发现,当两个或多个具有不同特征的子群体的数据被合并时,可能会导致观察结果与各个子群体的结果相反。
这一悖论在实际生活中也经常出现,引发了人们对数据分析和解读的思考。
相关名词解释•辛普森悖论:指将不同子群体的数据合并后,观察到的结果与各个子群体的结果相反的现象。
•子群体:指在辛普森悖论中参与比较的不同成员群体,可以是人群、物体或其他社会群体。
•观察结果:指根据数据进行分析后得出的结论。
•逆转:指子群体之间的关系在合并后发生变化,即原本较小子群体的结果超过了较大子群体的结果。
•数据合并:指将不同子群体的数据合并成一个整体进行比较和分析的过程。
举例说明为了更好地理解辛普森悖论,我们可以通过以下实例进行说明:•实例1:–子群体1:男性申请者与女性申请者获得升职的比例–子群体2:在每个部门内,男性申请者与女性申请者获得升职的比例–合并数据:将各个部门的升职比例合并–结果:在子群体1中,女性申请者获得升职的比例高于男性申请者;但在子群体2中,每个部门内男性申请者获得升职的比例都高于女性申请者。
–解释:辛普森悖论在这个例子中表现为,当不同部门的数据被合并时,女性申请者获得升职的比例反而低于男性申请者。
•实例2:–子群体1:一家公司不同地区销售额的增长率–子群体2:在每个地区内,不同产品线的销售额增长率–合并数据:将不同地区和产品线的销售额增长率合并–结果:在子群体1中,有些地区的增长率高于其他地区;但在子群体2中,每个地区内某些产品线的增长率高于其他产品线。
–解释:辛普森悖论在这个例子中表现为,当不同地区和产品线的数据被合并时,某些地区的增长率反而低于其他地区,某些产品线的增长率也反而低于其他产品线。
maup 辛普森悖论 区间谬误

标题:探究概率统计中的maup、辛普森悖论和区间谬误在概率统计领域中,maup(多元空间分布)是一个重要概念,它探讨了在不同空间尺度下数据分析的问题;辛普森悖论则是一个令人深思的悖论,揭示了当数据分别分析和整体分析之间出现的误导性结果;而区间谬误则是在统计推断中常见的错误,值得我们深入思考。
让我们来探讨maup这一概念。
maup是多元空间分布(modifiable areal unit problem)的缩写,指的是研究在不同空间尺度下数据进行空间单位划分所带来的影响。
在实际研究中,我们常常需要通过地理单位对数据进行划分和聚合,在不同空间尺度下得到的结果可能会有所不同。
这就引发了一个重要问题,即我们应该使用何种空间尺度来进行数据分析和研究。
maup的存在使得我们需要对空间单位的选择和空间尺度效应进行深入的思考和研究。
当我们在不同区域空间尺度下进行数据分析时,可能会出现由规模效应引起的误解,这就需要我们认真对待maup所带来的挑战,并在研究中加以考虑。
让我们转向辛普森悖论的讨论。
辛普森悖论是指在数据分别分析和整体分析之间出现的悖论现象。
简单来说,这个悖论揭示了当我们将数据进行分组或细分后,可能得出与整体数据完全相反的结论。
这给我们的数据分析带来了极大的挑战,因为我们往往需要建立精细的数据模型和进行细致的分析,但同时也需要警惕分析过于细致所带来的误导性结果。
辛普森悖论提醒我们,需要在数据分析中综合考虑整体和部分的关系,避免过于片面地进行分析和解读。
对于辛普森悖论的研究和理解对于我们正确分析和解释数据具有重要意义。
让我们探讨区间谬误。
区间谬误是指在统计推断中常见的错误,主要体现在对统计量的置信区间的解释和使用上。
在统计学中,我们经常会计算出统计量的置信区间,用以估计参数或评估模型的准确性。
然而,区间谬误指出了在对置信区间的解释和使用时可能存在的问题,例如过于自信地认为真值落在置信区间中,或者过于简单地对置信区间进行比较而忽视了其他因素。
统计学辛普森悖论的内容

统计学辛普森悖论的内容统计学辛普森悖论(Simpson's Paradox),又称辛普森效应,是指在统计数据分析中,一个总体的不同子集中出现的关系与整体数据的关系恰好相反。
简单来说,当我们将数据分组并进行分析时,得出的结论可能会与整体数据相矛盾。
辛普森悖论最早由英国统计学家E.H.辛普森于1951年提出,他在研究统计学考试成绩的数据时发现了这个现象。
为了更好地说明辛普森悖论,我们将针对一个具体的例子进行讨论。
假设某家医院正在研究针对某种疾病的两种不同疗法的疗效。
研究人员将患者分为两个子集:男性(子集A)和女性(子集B),然后比较两种疗法在不同子集中的成功率。
在子集A中,疗法A有80%的成功率,而疗法B只有40%的成功率;在子集B中,疗法A的成功率为60%,而疗法B的成功率为70%。
这个结果可能导致人们错误地认为疗法A比疗法B更有效。
然而,当我们将整体数据考虑进来时,情况就完全不同了。
整体上,疗法A的成功率为65%,而疗法B的成功率为67.5%。
这个结果与我们之前的结论相反,疗法B在整体上比疗法A更有效。
辛普森悖论的发生是由于子集A和子集B在整体数据中所占比例的差异导致的。
在这个例子中,虽然在子集A和子集B中,疗法A的成功率都不如疗法B,但是子集A在整体数据中所占比例远大于子集B。
所以,整体上疗法A的平均成功率反而比疗法B低。
为了更好地理解辛普森悖论,我们可以通过一个可视化的例子来说明。
假设我们有一个学校的招生数据,该学校有两个专业:科学(子集A)和文科(子集B)。
我们将招生成功率与考试成绩进行比较。
具体数据如下:子集A:科学专业-学生甲:考试成绩80分,成功录取-学生乙:考试成绩70分,未录取子集B:文科专业-学生丙:考试成绩80分,未录取-学生丁:考试成绩70分,成功录取看上去,科学专业的成功录取率为50%,而文科专业的成功录取率为50%。
这暗示我们两个专业的录取机会是相同的。
然而,当我们将整体数据考虑进来时,结果却完全不同。
辛普森悖论

(2) 性别并非是录取率高低的唯一因素,甚至可能是毫无影响的,至于在法商学院中出现的比率差可能是属于随机事件,又或者是其他因素作用,譬如学生入学成绩却刚好出现这种录取比例,使人牵强地误认为这是由性别差异而造成的。
回避方式
编辑
为了避免辛普森悖论出现,就需要斟酌个别分组的权重,以一定的系数去消除以分组资料基数差异所造成的影响,同时必需了解该情境是否存在其他潜在要因而综合考虑。
管理应用
编辑
辛普森悖论就像是欲比赛100场篮球以总胜率评价好坏,于是有人专找高手挑战20 场而胜1场,另外80场找平手挑战而胜40场,结果胜率41%,另一人则专挑高手挑战80场而胜8场,而剩下20场平手打个全胜,结果胜率为28%,比41%小很多,但仔细观察挑战对象,后者明显较有实力。
量与质是不等价的,无奈的是量比质来得容易量测,所以人们总是习惯用量来评定好坏,而此数据却不是重要的。
除了质与量的迷思之外,辛普森悖论的另外一个启示是:如果我们在人生的抉择上选择了一条比较难走的路,就得要有可能不被赏识的领悟,所以这算是怀才不遇这个成语在统计上的诠释。
二元logit辛普森悖论

二元logit辛普森悖论我们来介绍一下二元logit模型。
在二元logit模型中,我们关心的是一个二元分类变量,比如成功或失败、生存或死亡等。
我们希望利用一些自变量来解释这个二元分类变量的概率。
二元logit模型的核心思想是将这个概率转化为一个线性方程,然后通过一个logit函数将其映射到一个0到1之间的概率值。
这个线性方程可以用一些自变量的线性组合表示,每个自变量都有一个权重。
通过最大似然估计等方法,我们可以得到模型的参数估计值,从而进行预测和推断。
接下来,我们来介绍一下辛普森悖论。
辛普森悖论最早由英国统计学家辛普森在20世纪50年代提出,它揭示了一个有趣的现象:在整体观察上存在的关系方向可能在细分的条件下呈现相反的关系方向。
简单来说,辛普森悖论告诉我们不能仅仅根据整体观察的结果来做出判断,而需要考虑更加具体的条件。
这对于统计学家和数据分析师来说是一个很重要的教训,因为我们往往会陷入以偏概全的思维模式中。
那么,二元logit模型和辛普森悖论之间有什么关系呢?其实,辛普森悖论可以在二元logit模型中得到很好的体现。
考虑一个简单的例子,假设我们想研究一个药物对某种疾病的治疗效果。
我们收集了一批患者的数据,其中包括了他们的性别和是否接受治疗等信息。
我们使用二元logit模型来建立一个预测模型,用以预测患者是否能够成功治疗。
在整体观察上,我们可能发现女性患者的治疗成功率要高于男性患者。
然而,当我们将数据按照是否接受治疗进行细分时,却发现在接受治疗的群体中,男性患者的治疗成功率要高于女性患者。
这个结果与整体观察中的关系方向相反,正是辛普森悖论的一个典型案例。
那么,为什么会发生这种情况呢?这是因为在整体观察中,男性患者接受治疗的比例要低于女性患者,而在接受治疗的群体中,男性患者的成功率要高于女性患者。
因此,在整体观察中,女性的成功率要高于男性,但是当我们细分数据时,这种关系就发生了变化。
这个例子告诉我们,在进行数据分析时,一定要注意辛普森悖论的存在。
什么是辛普森悖论?辛普森悖论的重要性

什么是辛普森悖论?辛普森悖论的重要性什么是辛普森悖论?辛普森悖论的重要性对于数据科学家而言,了解统计现象和问“为什么”是非常重要的。
想象这样一个场景:一天,你和朋友约好了一起吃晚饭,你们俩都想找一家完美的餐厅。
由于选项太多,两人今天的口味也不一定一样,为了避免长达数小时的争论,你们保守地采用了现代人常用的一种方法:查看美食评论。
在用同一个APP看了所有餐厅后,最终你们锁定了其中的两家:Carlos餐厅和Sophia餐厅。
你更喜欢Carlos,因为从两性数据上看来,无论是男性用餐者还是女性用餐者,他们给出的好评率都更高(例:男性好评率=男性好评数/男性评论总数);而你的朋友更倾向于Sophia,因为他发现从整体上来看,Sophia的好评率更高,口味应该更大众。
那么这到底是怎么回事?是APP统计错误了吗?事实上,这两个统计结论都是正确的,只是你们在不知不觉中已经走进了辛普森悖论。
在这里,我们能用完全相同的一组数据证明两个全然相反的论点。
什么是辛普森悖论?辛普森悖论得名于英国统计学家E.H.辛普森(E.H.Simpson),这是他于1951年阐述的一种现象:当我们以分组和聚合两种方式统计同一数据集时,最后得出的两个趋势可能是完全逆转的。
在上面这个“吃饭”案例中,Carlos餐厅的两性推荐率更高,但它的总体推荐率却低了。
如果不想被绕晕,我们可以用一些直观的数据来说明:上表清楚地表明,当数据分组时,Carlos是首选,但是当数据合并时,Sophia是首选!导致这一悖论的原因是样本大小。
当我们分组统计数据时,Carlos餐厅的女性推荐率高达90%,但它的样本只有40个,只占总评论人数的10%;而Sophia餐厅的女性推荐率虽然只有80%,但女性评论者有250个,这显然会大幅拉高餐厅的总体好评率。
所以在挑选餐厅时,我们事先要确定数据的统计方法,是合并更合理,还是分组更合理——这取决于数据生成的过程,即数据的因果模型。
数据思维篇之七大悖论
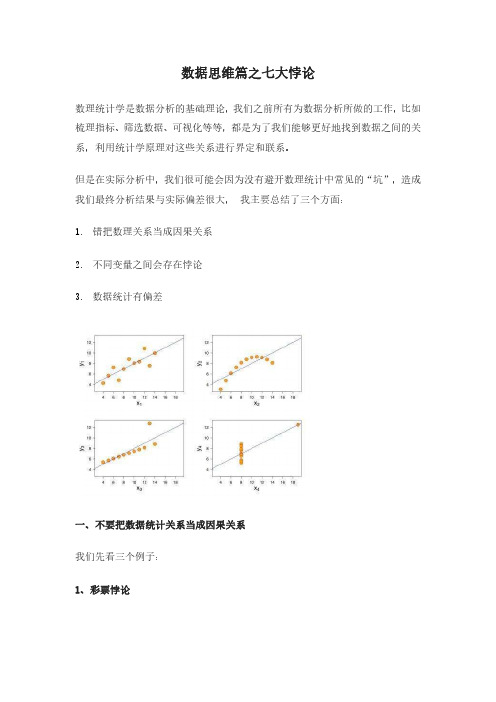
数据思维篇之七大悖论数理统计学是数据分析的基础理论,我们之前所有为数据分析所做的工作,比如梳理指标、筛选数据、可视化等等,都是为了我们能够更好地找到数据之间的关系,利用统计学原理对这些关系进行界定和联系。
但是在实际分析中,我们很可能会因为没有避开数理统计中常见的“坑”,造成我们最终分析结果与实际偏差很大,我主要总结了三个方面:1.错把数理关系当成因果关系2.不同变量之间会存在悖论3.数据统计有偏差一、不要把数据统计关系当成因果关系我们先看三个例子:1、彩票悖论首先根据假设检验,如果原假设概率非常小,就可以拒绝原假设。
假设0.0001就是一个非常小的概率,组织一次公正的10000张彩票抽奖活动,按照之前的假设,1号彩票中奖的概率是0.0001,是要拒绝的,依次类推,我们可以拒绝所有的彩票,那么就没有彩票可中奖,但现实情况是总会有中奖的彩票,这是统计和逻辑不相符的一个例子。
2、无票入场者悖论假设在一个有1000个座位的音乐厅举办一场音乐会,主办单位只售出了499张票,但当音乐会开始的时候,1000个坐席却都坐满了,这时主办单位有权向每个人收票钱,因为每个人无票入场的概率都是50.1%,这样音乐厅虽然只有1000个座位,却将会有1499张门票的收入,但实际情况并非如此。
3、生日悖论先来看一个问题:如果一个班里有23个同学,那么他们当中至少有两个人生日相同的概率是多少?按照常识我们会觉得这个概率应该挺小的,毕竟一年365天,23个人撞期,还是挺小的,然而结果却是50%,也就是说有50%的概率这23个人中有两个人生日相同。
这里的50%到底是什么意思呢,是说只要是一个班里有23个及以上的学生,就一定有一半的概率两个人同一天生日吗?来,请回看我们这一节的标题:统计关系并不等于因果关系,这句话很重要,理解它更重要。
上面3个例子说明了以概率为依据做决策是不合逻辑的,然而逻辑和统计本身却是大不相同,在逻辑上,一个命题只有对和错两种划分,而在统计上,却可以说成对的概率有50%,错的概率为20%,就是这一点不确定性造就了以逻辑推理和统计为基础所得决策上的不一致,或者说矛盾,这就是统计关系不等于因果关系。
辛普森悖论

辛普森悖论辛普森悖论是一种非常有趣同时也非常具有挑战性的统计现象,它所涉及到的问题与统计学有着紧密的联系。
在20世纪60年代,美国著名的统计学家Edward Simpson首次发现并提出了这一悖论,因而得名为辛普森悖论。
该悖论存在于统计分析的比较结果中,简单地说,就是有时候我们可能会得到两个互相矛盾的结果。
这是因为在统计学分析中,样本容量的大小、组别之间的差别以及变量之间的相关性等问题会对结果产生很大的影响。
辛普森悖论的一个经典案例是关于两所大学录取率的比较。
假设大学A和大学B都进行了招生工作,我们将其招生结果进行比较,发现大学A较大学B 录取率更高。
但当我们将两所大学的数据再次分类,将男女学生分别计算,结果发现男女学生的录取率得到完全相反的结果。
也就是说,大学A对男生录取的比率比大学B低,而对女生的录取率相同。
很多人都会认为这是一种错误的分析结果,因为总体数据表明大学A总的录取率高于大学B,但实际上这是一个典型的辛普森悖论。
在这个案例中,当我们将数据再次分类后,发现男性和女性学生在两所大学的比例比较不同。
因此,我们不能简单的使用总体数据来比较两所大学的录取率。
辛普森悖论最易产生的问题是当我们把数据按不同的分类方式分割后,有时会得到与总体数据完全相反的结果。
例如,在某次参赛的比赛中,A队总体表现最为出色,其他队伍的成绩都比不上A队。
但如果我们把数据按照时间分开来看,我们却发现,A队在比赛的前半段表现得很差,但在整个比赛中,以优异的表现夺得了冠军。
辛普森悖论实际上在日常生活中也很常见,例如一个公司招聘新员工时,我们可能会发现男性的录取率比女性高,并可能会将这一情况归咎于性别歧视。
但实际上,如果我们查看公司提供的岗位与男女申请人的比例,我们也许就能发现是因为男性申请了更多技术型岗位,而女性则更多地申请了管理层的岗位。
由此,导致男性录取的比例更高。
总之,辛普森悖论的存在告诉了我们,在统计分析过程中,一定要注意样本的分类方式,不能简单粗暴的使用总体数据来比较不同组别的结果。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
统计学辛普森悖论
引言:
统计学是一门研究数据收集、分析和解释的学科,它在科学研究、商业决策、政策制定等领域都发挥着重要作用。
然而,我们常常会遇到一个现象,即当我们将数据进行细分分析后,得出的结论与整体数据的结论相反。
这就是统计学中著名的辛普森悖论。
一、什么是辛普森悖论?
辛普森悖论,又称为辛普森效应,是指当我们对数据进行细分分析时,得出的结论与整体数据的结论相反的现象。
这种现象常常出现在数据集中存在不同的类别或组群时。
二、辛普森悖论的经典案例
为了更好地理解辛普森悖论,我们可以通过一个经典案例来说明。
假设某个学校在招生过程中有两个不同的专业:专业A和专业B。
我们对该学校的录取情况进行统计分析,得出以下数据:
专业A:200名男生中有120人被录取,300名女生中有100人被录取;
专业B:300名男生中有150人被录取,200名女生中有120人被录取。
整体数据显示,男生的录取率高于女生。
然而,当我们对不同的专业进行分别分析时,却发现女生的录取率在每个专业中都高于男生。
这就是典型的辛普森悖论。
三、辛普森悖论的成因
辛普森悖论产生的原因主要有两个方面:样本大小和类别之间的关系。
1. 样本大小:在上述案例中,男生和女生的样本大小存在差异,男生的样本数量要大于女生。
当我们只看整体数据时,男生的录取率较高,但当我们对不同的专业进行分别分析时,女生的录取率却在每个专业中都高于男生。
这是因为男生的样本量大,整体数据中占比较大,从而影响了整体数据的结论。
2. 类别之间的关系:在上述案例中,男生和女生在不同专业的录取情况存在差异。
男生在专业A中录取率高于专业B,而女生在专业A 中录取率低于专业B。
这种差异导致了整体数据和分组数据的结论相反。
四、如何避免辛普森悖论的影响
辛普森悖论的出现给我们的数据分析带来了挑战,但我们可以采取一些方法来避免其影响。
1. 充分了解数据:在进行数据分析之前,我们应该充分了解数据的来源、样本数量以及类别之间的关系。
只有在了解数据的基本情况后,我们才能更准确地进行分析。
2. 注意样本大小:样本大小对于数据分析至关重要。
当我们对数据进行细分分析时,应该尽量保证各个类别的样本数量相对均衡,以避免样本大小对结果的影响。
3. 综合考虑多个因素:在进行数据分析时,我们应该综合考虑多个因素,而不仅仅只看某一个特定的指标。
通过全面考虑各个因素,我们可以更准确地得出结论。
五、结语
统计学辛普森悖论是我们在数据分析过程中常常遇到的一个现象,它提醒我们在进行数据分析时要注意样本大小和类别之间的关系。
只有充分了解数据、注意样本大小以及综合考虑多个因素,我们才能做出准确且可靠的结论。
通过对辛普森悖论的认识和理解,我们可以更好地应用统计学知识,提高数据分析的准确性和可靠性。