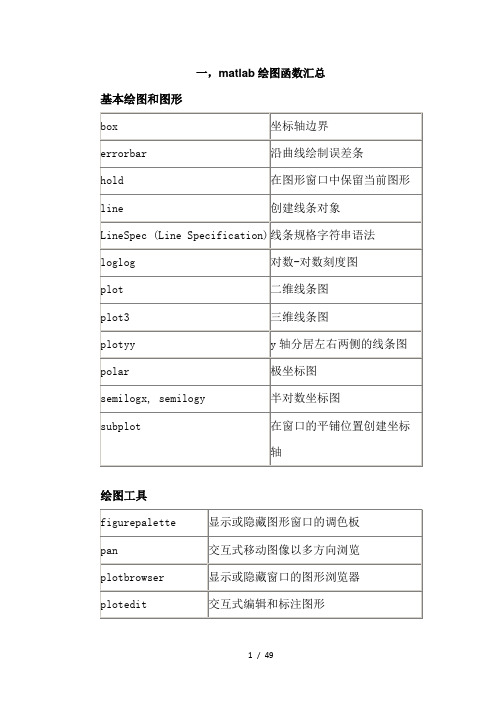
数学建模十大算法部分带有源代码
数学建模中常用的十种算法

数学建模中常用的十种算法在数学建模中,有许多种算法可以用来解决不同类型的问题。
下面列举了数学建模中常用的十种算法。
1.线性规划算法:线性规划是一种优化问题,目标是找到一组线性约束条件下使目标函数最大或最小的变量的值。
常用的线性规划算法包括单纯形法、内点法和对偶法等。
2.非线性规划算法:非线性规划是一种目标函数或约束条件中存在非线性项的优化问题。
常见的非线性规划算法有牛顿法、拟牛顿法和遗传算法等。
3.整数规划算法:整数规划是一种线性规划的扩展,约束条件中的变量必须为整数。
常用的整数规划算法包括分支定界法、割平面法和混合整数线性规划法等。
4.动态规划算法:动态规划是一种通过将问题分解为更小的子问题来解决的算法。
它适用于一类有重叠子问题和最优子结构性质的问题,例如背包问题和最短路径问题。
5.聚类算法:聚类是一种将数据集划分为不同群组的算法。
常见的聚类算法有K均值算法、层次聚类法和DBSCAN算法等。
6.回归分析算法:回归分析是一种通过拟合一个数学模型来预测变量之间关系的算法。
常见的回归分析算法有线性回归、多项式回归和岭回归等。
7.插值算法:插值是一种通过已知数据点推断未知数据点的数值的算法。
常用的插值算法包括线性插值、拉格朗日插值和样条插值等。
8.数值优化算法:数值优化是一种通过改变自变量的取值来最小化或最大化一个目标函数的算法。
常见的数值优化算法有梯度下降法、共轭梯度法和模拟退火算法等。
9.随机模拟算法:随机模拟是一种使用概率分布来模拟和模拟潜在结果的算法。
常见的随机模拟算法包括蒙特卡洛方法和离散事件仿真等。
10.图论算法:图论是一种研究图和网络结构的数学理论。
常见的图论算法有最短路径算法、最小生成树算法和最大流量算法等。
以上是数学建模中常用的十种算法。
这些算法的选择取决于问题的特性和求解的要求,使用合适的算法可以更有效地解决数学建模问题。
数学建模十大算法部分带有源代码综述

• • •ห้องสมุดไป่ตู้• • • • • • •
蒙特卡罗算法 数据处理算法 数学规划算法 图论算法 动态规划、回溯搜索、分治算法、分支定 界 三大非经典算法 网格算法和穷举法 连续离散化方法 数值分析算法 图象处理算法
1、蒙特卡罗算法
该算法又称随机性模拟算法,是通过计算机 仿真来解决问题的算法,同时可以通过模拟 可以来检验自己模型的正确性,是比赛时必 用的方法
现在假设需要识别出这一伪币。把两个或三个硬币的情况作 为不可再分的小问题。注意如果只有一个硬币,那么不能判 断出它是否就是伪币。在一个小问题中,通过将一个硬币分 别与其他两个硬币比较,最多比较两次就可以找到伪币。这 样,1 6硬币的问题就被分为两个8硬币(A组和B组)的问题。 通过比较这两组硬币的重量,可以判断伪币是否存在。如果 没有伪币,则算法终止。否则,继续划分这两组硬币来寻找 伪币。假设B是轻的那一组,因此再把它分成两组,每组有4 个硬币。称其中一组为B1,另一组为B2。比较这两组,肯定 有一组轻一些。如果B1轻,则伪币在B1中,再将B1又分成两 组,每组有两个硬币,称其中一组为B1a,另一组为B1b。比 较这两组,可以得到一个较轻的组。由于这个组只有两个硬 币,因此不必再细分。比较组中两个硬币的重量,可以立即 知道哪一个硬币轻一些。较轻的硬币就是所要找的伪币。
例2-1 [找出伪币] 给你一个装有1 6个硬币 的袋子。1 6个硬币中有一个是伪造的,并 且那个伪造的硬币比真的硬币要轻一些。你 的任务是找出这个伪造的硬币。为了帮助你 完成这一任务,将提供一台可用来比较两组 硬币重量的仪器,利用这台仪器,可以知道 两组硬币的重量是否相同。
比较硬币1与硬币2的重量。假如硬币1比硬币 2轻,则硬币1是伪造的;假如硬币2比硬币1 轻,则硬币2是伪造的。这样就完成了任务。 假如两硬币重量相等,则比较硬币3和硬币4。 同样,假如有一个硬币轻一些,则寻找伪币 的任务完成。假如两硬币重量相等,则继续 比较硬币5和硬币6。按照这种方式,可以最 多通过8次比较来判断伪币的存在并找出这一 伪币。
数学建模十大经典算法

法解及题试模建学数国全年历
。理处行进 baltaM 用使常通�题问的决解要需是就理处何如及以示展何如形
。 1 � y � x 是件条要充的内形扇在落 P。值似近的 k 为作 n/m 比的 n 数总的点投所与 m 数点的内形扇在落将。内形扇在落点个少多有中其看等相会机的置位 个一每中形方正在落点的投所使�点多很入投机随中形方正在是法办个一�呢 K 例比的占 中积面形方正在积面形扇出求样怎。值的 iP 到得而从�1S 到得能即立就 S/1S=K 例比的占 中 S 积面形方正在 1S 积面形扇出求能要只。分部一的形方正位单 1 为长边是它�形扇个一 是积面 4/1 的圆位单。iP 到得而从 4/iP 得求来积面的 4/1 的圆位单求用利�中法分积值数在 �等线行平括包�题例的似相多很有�例实法算、2 。解似近的题问得获以�样抽或拟模计统现实机算计用�系联 相型模率概的定一同题问的解求所将是它�法方的题问算计多很决解来�数机随伪的见常 更或�数机随用使指是�法方拟模计统称也。法方算计种一的础基为法方论理计统和率概以 解理的义含、1
�点特的展发题赛
论图
B01 A01 划规态动 排安理合的床病科眼 B90 析分法方制控的台验试器动制 A90 讨探准标费学育教等高 B80 位定机相码数 A80 理处据数 划规标目多 运奥看�交公乘 B70 测预长增口人国中 A70 测预的效疗及价评的法疗病滋艾 B60 置配源资版出 A60
393141.3 051931.3 002531.3 000580.3 000011.3
测预和价评的质水江长 A50 计设点网市超时临会运奥 A40 排安辆车的产生矿天露 B30 播传的 SRAS A30 题问票彩 B20 理管塞阻电输的场市力电 B40
赁租线在 DVD B50
数学建模应该掌握的十大算法(汇编)

数学建模竞赛中应当掌握的十类算法排名如下:1、蒙特卡罗算法(该算法又称随机性模拟算法,是通过计算机仿真来解决问题的算法,同时可以通过模拟可以来检验自己模型的正确性,是比赛时必用的方法)2、数据拟合、参数估计、插值等数据处理算法(比赛中通常会遇到大量的数据需要处理,而处理数据的关键就在于这些算法,通常使用Matlab作为工具)3、线性规划、整数规划、多元规划、二次规划等规划类问题(建模竞赛大多数问题属于最优化问题,很多时候这些问题可以用数学规划算法来描述,通常使用Lindo、Lingo软件实现)4、图论算法(这类算法可以分为很多种,包括最短路、网络流、二分图等算法,涉及到图论的问题可以用这些方法解决,需要认真准备)5、动态规划、回溯搜索、分治算法、分支定界等计算机算法(这些算法是算法设计中比较常用的方法,很多场合可以用到竞赛中)6、最优化理论的三大非经典算法:模拟退火法、神经网络、遗传算法(这些问题是用来解决一些较困难的最优化问题的算法,对于有些问题非常有帮助,但是算法的实现比较困难,需慎重使用)7、网格算法和穷举法(网格算法和穷举法都是暴力搜索最优点的算法,在很多竞赛题中有应用,当重点讨论模型本身而轻视算法的时候,可以使用这种暴力方案,最好使用一些高级语言作为编程工具)8、一些连续离散化方法(很多问题都是实际来的,数据可以是连续的,而计算机只认的是离散的数据,因此将其离散化后进行差分代替微分、求和代替积分等思想是非常重要的)9、数值分析算法(如果在比赛中采用高级语言进行编程的话,那一些数值分析中常用的算法比如方程组求解、矩阵运算、函数积分等算法就需要额外编写库函数进行调用)10、图象处理算法(赛题中有一类问题与图形有关,即使与图形无关,论文中也应该要不乏图片的,这些图形如何展示以及如何处理就是需要解决的问题,通常使用Matlab进行处理)8.1 遗传算法的概念是建立在自然选择和自然遗传学机理基础上的迭代自适应概率性搜索算法,在1975年由Holland教授提出。
10个重要的算法C语言实现源代码

/*///////////////////////////////////*/ 10个重要的算法C语言实现源代码: // 拉格朗日, // 牛顿插值, // 高斯, // 龙贝格, // 牛顿迭代, // 牛顿-科特斯, // 雅克比, // 秦九昭, // 幂法, // 高斯塞德尔 /*///1.拉格朗日插值多项式,用于离散数据的拟合//C/C++ code#include <stdio.h>#include <conio.h>#include <alloc.h>float lagrange(float *x,float *y,float xx,int n) /*拉格朗日插值算法*/{int i,j;float *a,yy=0.0; /*a作为临时变量,记录拉格朗日插值多项式*/a=(float *)malloc(n*sizeof(float));for(i=0;i<=n-1;i++){a[i]=y[i];for(j=0;j<=n-1;j++)if(j!=i) a[i]*=(xx-x[j])/(x[i]-x[j]);yy+=a[i];}free(a);return yy;}main(){int i,n;float x[20],y[20],xx,yy;printf("Input n:");scanf("%d",&n);if(n>=20){printf("Error!The value of n must in (0,20)."); getch();return 1;}if(n<=0){printf("Error! The value of n must in (0,20)."); getch();return 1;}for(i=0;i<=n-1;i++){printf("x[%d]:",i);scanf("%f",&x[i]);}printf("\n");for(i=0;i<=n-1;i++){printf("y[%d]:",i);scanf("%f",&y[i]);}printf("\n");printf("Input xx:");scanf("%f",&xx);yy=lagrange(x,y,xx,n);printf("x=%f,y=%f\n",xx,yy);getch();}//2.牛顿插值多项式,用于离散数据的拟合//C/C++ code#include <stdio.h>#include <conio.h>#include <alloc.h>void difference(float *x,float *y,int n){float *f;int k,i;f=(float *)malloc(n*sizeof(float));for(k=1;k<=n;k++){ f[0]=y[k];for(i=0;i<k;i++)f[i+1]=(f[i]-y[i])/(x[k]-x[i]);y[k]=f[k];}return;}main(){int i,n;float x[20],y[20],xx,yy;printf("Input n:");scanf("%d",&n);if(n>=20){printf("Error! The value of n must in (0,20)."); getch();return 1;}if(n<=0){printf("Error! The value of n must in (0,20)."); getch();return 1;}for(i=0;i<=n-1;i++){printf("x[%d]:",i);scanf("%f",&x[i]);}printf("\n");for(i=0;i<=n-1;i++){printf("y[%d]:",i);scanf("%f",&y[i]);}printf("\n");difference(x,(float *)y,n);printf("Input xx:");scanf("%f",&xx);yy=y[20];for(i=n-1;i>=0;i--) yy=yy*(xx-x[i])+y[i];printf("NewtonInter(%f)=%f",xx,yy);getch();}//3.高斯列主元消去法,求解其次线性方程组//C/C++ code#include<stdio.h>#include <math.h>#define N 20int main(){int n,i,j,k;int mi,tmp,mx;float a[N][N],b[N],x[N];printf("\nInput n:");scanf("%d",&n);if(n>N){ printf("The input n should in(0,N)!\n"); getch();return 1;}if(n<=0){ printf("The input n should in(0,N)!\n"); getch();return 1;}printf("Now input a(i,j),i,j=0...%d:\n",n-1); for(i=0;i<n;i++){for(j=0;j<n;j++)scanf("%f",&a[i][j]);}printf("Now input b(i),i,j=0...%d:\n",n-1); for(i=0;i<n;i++)scanf("%f",&b[i]);for(i=0;i<n-2;i++){for(j=i+1,mi=i,mx=fabs(a[i][j]);j<n-1;j++) if(fabs(a[j][i])>mx){mi=j;mx=fabs(a[j][i]);}if(i<mi){tmp=b[i];b[i]=b[mi];b[mi]=tmp;for(j=i;j<n;j++){tmp=a[i][j];a[i][j]=a[mi][j];a[mi][j]=tmp;}}for(j=i+1;j<n;j++){tmp=-a[j][i]/a[i][i];b[j]+=b[i]*tmp;for(k=i;k<n;k++)a[j][k]+=a[i][k]*tmp;}}x[n-1]=b[n-1]/a[n-1][n-1];for(i=n-2;i>=0;i--){x[i]=b[i];for(j=i+1;j<n;j++)x[i]-=a[i][j]*x[j];x[i]/=a[i][i];}for(i=0;i<n;i++)printf("Answer:\n x[%d]=%f\n",i,x[i]); getch();return 0;}#include<math.h>#include<stdio.h>#define NUMBER 20#define Esc 0x1b#define Enter 0x0dfloat A[NUMBER][NUMBER+1] ,ark;int flag,n;exchange(int r,int k);float max(int k);message();main()float x[NUMBER];int r,k,i,j;char celect;clrscr();printf("\n\nUse Gauss.");printf("\n\n1.Jie please press Enter.");printf("\n\n2.Exit press Esc.");celect=getch();if(celect==Esc)exit(0);printf("\n\n input n=");scanf("%d",&n);printf(" \n\nInput matrix A and B:");for(i=1;i<=n;i++){printf("\n\nInput a%d1--a%d%d and b%d:",i,i,n,i); for(j=1;j<=n+1;j++)scanf("%f",&A[i][j]);}for(k=1;k<=n-1;k++){ark=max(k);if(ark==0){printf("\n\nIt's wrong!");message();}else if(flag!=k)exchange(flag,k);for(i=k+1;i<=n;i++)for(j=k+1;j<=n+1;j++)A[i][j]=A[i][j]-A[k][j]*A[i][k]/A[k][k];}x[n]=A[n][n+1]/A[n][n];for( k=n-1;k>=1;k--){float me=0;for(j=k+1;j<=n;j++){me=me+A[k][j]*x[j];}x[k]=(A[k][n+1]-me)/A[k][k];}for(i=1;i<=n;i++)printf(" \n\nx%d=%f",i,x[i]);}message();}exchange(int r,int k){int i;for(i=1;i<=n+1;i++)A[0][i]=A[r][i];for(i=1;i<=n+1;i++)A[r][i]=A[k][i];for(i=1;i<=n+1;i++)A[k][i]=A[0][i];}float max(int k){int i;float temp=0;for(i=k;i<=n;i++)if(fabs(A[i][k])>temp){temp=fabs(A[i][k]);flag=i;}return temp;}message() {printf("\n\n Go on Enter ,Exit press Esc!"); switch(getch()){case Enter: main();case Esc: exit(0);default:{printf("\n\nInput error!");message();}}//4.龙贝格求积公式,求解定积分//C/C++ code#include<stdio.h>#include<math.h>#define f(x) (sin(x)/x)#define N 20#define MAX 20#define a 2#define b 4#define e 0.00001float LBG(float p,float q,int n){int i;float sum=0,h=(q-p)/n;for (i=1;i<n;i++)sum+=f(p+i*h);sum+=(f(p)+f(q))/2;return(h*sum);}void main(){int i;int n=N,m=0;float T[MAX+1][2];T[0][1]=LBG(a,b,n);n*=2;for(m=1;m<MAX;m++){for(i=0;i<m;i++)T[i][0]=T[i][1];T[0][1]=LBG(a,b,n);n*=2;for(i=1;i<=m;i++)T[i][1]=T[i-1][1]+(T[i-1][1]-T[i-1][0])/(pow(2,2*m)-1); if((T[m-1][1]<T[m][1]+e)&&(T[m-1][1]>T[m][1]-e)){printf("Answer=%f\n",T[m][1]); getch();return ;}}//5.牛顿迭代公式,求方程的近似解//C/C++ code#include<stdio.h>#include<math.h>#include<conio.h>#define N 100#define PS 1e-5#define TA 1e-5float Newton(float (*f)(float),float(*f1)(float),float x0 ) {float x1,d=0;int k=0;do{x1= x0-f(x0)/f1(x0);if((k++>N)||(fabs(f1(x1))<PS)){printf("\nFailed!");getch();exit();}d=(fabs(x1)<1?x1-x0:(x1-x0)/x1);x0=x1;printf("x(%d)=%f\n",k,x0);}while((fabs(d))>PS&&fabs(f(x1))>TA) ;return x1;}float f(float x){return x*x*x+x*x-3*x-3;}float f1(float x){return 3.0*x*x+2*x-3;}void main(){float f(float);float f1(float);float x0,y0;printf("Input x0: ");scanf("%f",&x0);printf("x(0)=%f\n",x0);y0=Newton(f,f1,x0);printf("\nThe root is x=%f\n",y0);getch();}//6. 牛顿-科特斯求积公式,求定积分//C/C++ code#include<stdio.h>#include<math.h>float (*a)[];float h;int n,f;float *r;int NC(a,h,n,r,f){int nn,i;float ds;if(n>1000||n<2){if (f)printf("\n Faild! Check if 1<n<1000!\n",n);return(-1);}if(n==2){*r=0.5*((*a)[0]+(*a)[1])*(h);return(0);}if (n-4==0){*r=0;*r=*r+0.375*(h)*((*a)[n-4]+3*(*a)[n-3]+3*(*a)[n-2]+(*a)[n-1]); return(0);}if(n/2-(n-1)/2<=0)nn=n;elsenn=n-3;ds=(*a)[0]-(*a)[nn-1];for(i=2;i<=nn;i=i+2)ds=ds+4*(*a)[i-1]+2*(*a)[i];*r=ds*(h)/3;if(n>nn)*r=*r+0.375*(h)*((*a)[n-4]+3*(*a)[n-3]+3*(*a)[n-2]+(*a)[n-1]); return(0);}main(){float h,r;int n,ntf,f;int i;float a[16];printf("Input the x[i](16):\n");for(i=0;i<=15;i++)scanf("%d",&a[i]);h=0.2;f=0;ntf=NC(a,h,n,&r,f);if(ntf==0)printf("\nR=%f\n",r);elseprintf("\n Wrong!Return code=%d\n",ntf);getch();}//7.雅克比迭代,求解方程近似解//C/C++ code#include <stdio.h>#include <math.h>#define N 20#define MAX 100#define e 0.00001int main(){int n;int i,j,k;float t;float a[N][N],b[N][N],c[N],g[N],x[N],h[N];printf("\nInput dim of n:"); scanf("%d",&n);if(n>N){printf("Faild! Check if 0<n<N!\n"); getch(); return 1; } if(n<=0){printf("Faild! Check if 0<n<N!\n");getch();return 1;}printf("Input a[i,j],i,j=0…%d:\n",n-1);for(i=0;i<n;i++)for(j=0;j<n;j++)scanf("%f",&a[i][j]);printf("Input c[i],i=0…%d:\n",n-1);for(i=0;i<n;i++)scanf("%f",&c[i]);for(i=0;i<n;i++)for(j=0;j<n;j++){b[i][j]=-a[i][j]/a[i][i]; g[i]=c[i]/a[i][i]; }for(i=0;i<MAX;i++){for(j=0;j<n;j++)h[j]=g[j];{for(k=0;k<n;k++){if(j==k)continue;h[j]+=b[j][k]*x[k];}}t=0;for(j=0;j<n;j++)if(t<fabs(h[j]-x[j])) t=fabs(h[j]-x[j]);for(j=0;j<n;j++)x[j]=h[j];if(t<e){printf("x_i=\n");for(i=0;i<n;i++)printf("x[%d]=%f\n",i,x[i]);getch();return 0;}printf("after %d repeat , return\n",MAX);getch();return 1;}getch();}//8.秦九昭算法//C/C++ code#include <math.h>float qin(float a[],int n,float x) {float r=0;int i;for(i=n;i>=0;i--)r=r*x+a[i];return r;}main(){float a[50],x,r=0;int n,i;do{printf("Input frequency:");scanf("%d",&n);}while(n<1);printf("Input value:");for(i=0;i<=n;i++)scanf("%f",&a[i]);printf("Input frequency:");scanf("%f",&x);r=qin(a,n,x);printf("Answer:%f",r);getch();}//9.幂法//C/C++ code#include<stdio.h>#include<math.h>#define e 0.00001#define n 3float x[n]={0,0,1};float a[n][n]={{2,3,2},{10,3,4},{3,6,1}}; float y[n];main(){int i,j,k;float xm,oxm;oxm=0;for(k=0;k<N;k++){for(j=0;j<n;j++){y[j]=0;for(i=0;i<n;i++)y[j]+=a[j][i]*x[i];}xm=0;for(j=0;j<n;j++)if(fabs(y[j])>xm) xm=fabs(y[j]);for(j=0;j<n;j++)y[j]/=xm;for(j=0;j<n;j++)x[j]=y[j];if(fabs(xm-oxm)<e){printf("max:%f\n\n",xm);printf("v[i]:\n");for(k=0;k<n;k++)printf("%f\n",y[k]);break;}oxm=xm;}getch();}//10.高斯塞德尔//C/C++ code#include<math.h>#include<stdio.h>#define M 99float a[N][N];float b[N];int main(){int i,j,k,n;float sum,no,d,s,x[N];printf("\nInput dim of n:");scanf("%d",&n);if(n>N){printf("Faild! Check if 0<n<N!\n "); getch();return 1;}if(n<=0){printf("Faild! Check if 0<n<N!\n "); getch();return 1;}printf("Input a[i,j],i,j=0…%d:\n",n-1); for(i=0;i<n;i++)for(j=0;j<n;j++)scanf("%f",&a[i][j]);printf("Input b[i],i=0…%d:\n",n-1); for(i=0;i<n;i++)scanf("%f",&b[i]);for(i=0;i<n;i++) x[i]=0;k=0;printf("\nk=%dx=",k);for(i=0;i<n;i++)printf("%12.8f",x[i]);do{k++;if(k>M){printf("\nError!\n");getch();}break;}no=0.0;for(i=0;i<n;i++){s=x[i];sum=0.0;for(j=0;j<n;j++)if (j!=i)sum=sum+a[i][j]*x[j];x[i]=(b[i]-sum)/a[i][i];d=fabs(x[i]-s);if (no<d)no=d;}printf("\nk=%2dx=",k);for(i=0;i<n;i++)printf("%f",x[i]);}while (no>=0.1e-6);if(no<0.1e-6){printf("\n\n answer=\n");printf("\nk=%d",k);for (i=0;i<n;i++)printf("\n x[%d]=%12.8f",i,x[i]); }getch();}。
数学建模常用的十大算法

数学建模常用的十大算法一、线性回归算法线性回归算法(linear regression)是数学建模中最常用的算法之一,用于研究变量之间的线性关系。
它可以将变量之间的关系建模为一个线性方程,从而找出其中的关键因素,并预测未来的变化趋势。
二、逻辑回归算法逻辑回归算法(logistic regression)是一种用于建立分类模型的线性回归算法。
它可用于分类任务,如肿瘤疾病的预测和信用评级的决定。
逻辑回归利用某个事件的概率来建立分类模型,这个概率是通过一个特定的函数来计算的。
三、决策树算法决策树算法(decision tree)是一种非参数化的分类算法,可用于解决复杂的分类和预测问题。
它使用树状结构来描述不同的决策路径,每个分支表示一个决策,而每个叶子节点表示一个分类结果。
决策树算法的可解释性好,易于理解和解释。
四、k-均值聚类算法k-均值聚类算法(k-means clustering)是无监督学习中最常用的算法之一,可用于将数据集分成若干个簇。
此算法通过迭代过程来不断优化簇的质心,从而找到最佳的簇分类。
k-均值聚类算法简单易用,但对于高维数据集和离群值敏感。
五、支持向量机算法支持向量机算法(support vector machine)是一种强大的分类和回归算法,可用于解决复杂的非线性问题。
该算法基于最大化数据集之间的间隔,找到一个最佳的超平面来将数据分类。
支持向量机算法对于大型数据集的处理效率较高。
六、朴素贝叶斯算法朴素贝叶斯算法(naive bayes)是一种基于贝叶斯定理的分类算法,用于确定不同变量之间的概率关系。
该算法通过使用先验概率来计算各个变量之间的概率,从而预测未来的变化趋势。
朴素贝叶斯算法的处理速度快且适用于高维数据集。
七、随机森林算法随机森林算法(random forest)是一种基于决策树的分类算法,它利用多个决策树来生成随机森林,从而提高预测的准确性。
该算法通过随机化特征选择和子决策树的训练,防止过度拟合,并产生更稳定的预测结果。
数学建模算法的matlab代码
二,hamiton回路算法提供一种求解最优哈密尔顿的算法---三边交换调整法,要求在运行jiaohuan3(三交换法)之前,给定邻接矩阵C和节点个数N,结果路径存放于R中。
bianquan.m文件给出了一个参数实例,可在命令窗口中输入bianquan,得到邻接矩阵C和节点个数N以及一个任意给出的路径R,,回车后再输入jiaohuan3,得到了最优解。
由于没有经过大量的实验,又是近似算法,对于网络比较复杂的情况,可以尝试多运行几次jiaohuan3,看是否能到进一步的优化结果。
%%%%%%bianquan.m%%%%%%%N=13;for i=1:Nfor j=1:NC(i,j)=inf;endendfor i=1:NC(i,i)=0;endC(1,2)=6.0;C(1,13)=12.9;C(2,3)=5.9;C(2,4)=10.3;C(3,4)=12.2;C(3,5)=17.6;C(4,13)=8.8;C(4,7)=7.4;C(4,5)=11.5;C(5,2)=17.6;C(5,6)=8.2;C(6,9)=14.9;C(6,7)=20.3;C(7,9)=19.0;C(7,8)=7.3;C(8,9)=8.1;C(8,13)=9.2;C(9,10)=10.3;C(10,11)=7.7;C(11,12)=7.2;C(12,13)=7.9;for i=1:Nfor j=1:Nif C(i,j) < infC(j,i)=C(i,j);endendendfor i=1:NC(i,i)=0;endR=[4 7 6 5 3 2 1 13 12 11 10 9 8];<pre name="code" class="plain">%%%%%%%%jiaohuan3.m%%%%%%%%%%n=0;for I=1:(N-2)for J=(I+1):(N-1)for K=(J+1):Nn=n+1;Z(n,:)=[I J K];endendendR=1:Nfor m=1:(N*(N-1)*(N-2)/6)I=Z(m,1);J=Z(m,2);K=Z(m,3); r=R;if J-I~=1&K-J~=1&K-I~=N-1 for q=1:(J-I)r(I+q)=R(J+1-q);endfor q=1:(K-J)r(J+q)=R(K+1-q);endendif J-I==1&K-J==1r(K)=R(J);r(J)=R(K);endif J-I==1&K-J~=1&K-I~=N-1 for q=1:(K-J)r(I+q)=R(I+1+q); endr(K)=R(J);endif K-J==1&J-I~=1&K~=Nfor q=1:(J-I)r(I+1+q)=R(I+q); endr(I+1)=R(K);endif I==1&J==2&K==Nfor q=1:(N-2)r(1+q)=R(2+q);endr(N)=R(2);endif I==1&J==(N-1)&K==Nfor q=1:(N-2)r(q)=R(1+q);endr(N-1)=R(1);endif J-I~=1&K-I==N-1for q=1:(J-1)r(q)=R(1+q);endr(J)=R(1);endif J==(N-1)&K==N&J-I~=1r(J+1)=R(N);for q=1:(N-J-1)r(J+1+q)=R(J+q);endendif cost_sum(r,C,N)<cost_sum(R,C,N)R=rendendfprintf('总长为%f\n',cost_sum(R,C,N))%%%%%%cost_sum.m%%%%%%%%functiony=cost_sum(x,C,N)y=0;for i=1:(N-1)y=y+C(x(i),x(i+1));endy=y+C(x(N),x(1));三,灰色预测代码<pre name="code" class="plain">clearclcX=[136 143 165 152 165 181 204 272 319 491 571 605 665 640 628];x1(1)=X(1);X1=[];for i=1:1:14x1(i+1)=x1(i)+X(i+1);X1=[X1,x1(i)];endX1=[X1,X1(14)+X(15)]for k=3:1:15p(k)=X(k)/X1(k-1);p1(k)=X1(k)/X1(k-1);endp,p1clear kZ=[];for k=2:1:15z(k)=0.5*X1(k)+0.5*X1(k-1);Z=[Z,z(k)];endZB=[-Z',ones(14,1)]Y=[];clear ifor i=2:1:15Y=[Y;X(i)];endYA=inv(B'*B)*B'*Yclear ky1=[];for k=1:1:15y(k)=(X(1)-A(2)/A(1))*exp(-A(1)*(k-1))+A(2)/A(1); y1=[y1;y(k)];endy1clear kX2=[];for k=2:1:15x2(k)=y1(k)-y1(k-1);X2=[X2;x2(k)];endX2=[y1(1);X2]e=X'-X2m=abs(e)./X's=e'*en=sum(m)/13clear ksyms ky=(X(1)-A(2)/A(1))*exp(-A(1)*(k-1))+A(2)/A(1)Y1=[];for j=16:1:21y11=subs(y,k,j)-subs(y,k,j-1);Y1=[Y1;y11];endY1%程序中的变量定义:alpha是包含α、μ值的矩阵;%ago是预测后累加值矩阵;var是预测值矩阵;%error是残差矩阵; c是后验差比值function basicgrey(x,m) %定义函数basicgray(x)if nargin==1 %m为想预测数据的个数,默认为1 m=1;endclc; %清屏,以使计算结果独立显示if length(x(:,1))==1 %对输入矩阵进行判断,如不是一维列矩阵,进行转置变换x=x';endn=length(x); %取输入数据的样本量x1(:,1)=cumsum(x); %计算累加值,并将值赋及矩阵be for i=2:n %对原始数列平行移位 Y(i-1,:)=x(i,:);endfor i=2:n %计算数据矩阵B的第一列数据z(i,1)=0.5*x1(i-1,:)+0.5*x1(i,:);endB=ones(n-1,2); %构造数据矩阵BB(:,1)=-z(2:n,1);alpha=inv(B'*B)*B'*Y; %计算参数α、μ矩阵for i=1:n+m %计算数据估计值的累加数列,如改n+1为n+m可预测后m个值ago(i,:)=(x1(1,:)-alpha(2,:)/alpha(1,:))*exp(-alpha(1, :)*(i-1))+alpha(2,:)/alpha(1,:);endvar(1,:)=ago(1,:);f or i=1:n+m-1 %可预测后m个值var(i+1,:)=ago(i+1,:)-ago(i,:); %估计值的累加数列的还原,并计算出下m个预测值end[P,c,error]=lcheck(x,var); %进行后验差检验[rela]=relations([x';var(1:n)']); %关联度检验ago %显示输出预测值的累加数列alpha %显示输出参数α、μ数列var %显示输出预测值error %显示输出误差P %显示计算小残差概率 c %显示后验差的比值crela %显示关联度judge(P,c,rela) %评价函数显示这个模型是否合格<pre name="code" class="plain">function judge(P,c,rela) %评价指标并显示比较结果if rela>0.6'根据经验关联度检验结果为满意(关联度只是参考主要看后验差的结果)'else'根据经验关联度检验结果为不满意(关联度只是参考主要看后验差的结果)'endif P>0.95&c<0.5'后验差结果显示这个模型评价为“优”'else if P>0.8&c<0.5'后验差结果显示这个模型评价为“合格”'else if P>0.7&c<0.65'后验差结果显示这个模型评价为“勉强合格”' else'后验差结果显示这个模型评价为“不合格”' endendendfunction [P,c,error]=lcheck(x,var)%进行后验差检验n=length(x);for i=1:nerror(i,:)=abs(var(i,:)-x(i,:)); %计算绝对残差c=std(abs(error))/std(x); %调用统计工具箱的标准差函数计算后验差的比值cs0=0.6745*std(x);ek=abs(error-mean(error));pk=0;for i=1:nif ek(i,:)<s0pk=pk+1;endendP=pk/n; %计算小残差概率%附带的质料里有一部分讲了关联度function [rela]=relations(x)%以x(1,:)的参考序列求关联度[m,n]=size(x);for i=1:mfor j=n:-1:2x(i,j)=x(i,j)/x(i,1);endfor i=2:mx(i,:)=abs(x(i,:)-x(1,:)); %求序列差endc=x(2:m,:);Max=max(max(c)); %求两极差Min=min(min(c));p=0.5; %p称为分辨率,0<p<1,一般取p=0.5for i=1:m-1for j=1:nr(i,j)=(Min+p*Max)/(c(i,j)+p*Max); %计算关联系数endendfor i=1:m-1rela(i)=sum(r(i,:))/n; %求关联度end四,非线性拟合function f=example1(c,tdata)f=c(1)*(exp(-c(2)*tdata)-exp(-c(3)*tdata));<pre name="code" class="plain">function f=zhengtai(c,x) f=(1./(sqrt(2.*3.14).*c(1))).*exp(-(x-c(1)).^2./(2.*c( 2)^2));x=1:1:12;y=[01310128212]';c0=[2 8];for i=1:1000c=lsqcurvefit(@zhengtai,c0,x,y);c0=c;endy1=(1./(sqrt(2.*3.14).*c(1))).*exp(-(x-c(1)).^2./(2.*c (2)^2));plot(x,y,'r-',x,y1);legend('实验数据','拟合曲线')x=[0.25 0.5 0.75 1 1.5 2 2.5 3 3.5 4 4.5 5 6 7 8 9 10 11 12 13 14 15 16]';y=[30 68 75 82 82 77 68 68 58 51 50 41 38 35 28 25 18 15 12 10 7 7 4]';f=@(c,x)c(1)*(exp(-c(2)*x)-exp(-c(3)*x));c0=[114 0.1 2]';for i=1:50opt=optimset('TolFun',1e-3);[c R]=nlinfit(x,y,f,c0,opt)c0=c;hold onplot(x,c(1)*(exp(-c(2)*x)-exp(-c(3)*x)),'g')endt=[0.25 0.5 0.75 1 1.5 2 2.5 3 3.5 4 4.5 5 6 7 8 9 10 11 12 13 14 15 16];y=[30 68 75 82 82 77 68 68 58 51 50 41 38 35 28 25 18 15 12 10 7 7 4];c0=[1 1 1];for i=1:50 c=lsqcurvefit(@example1,c0,t,y);c0=c;endy1=c(1)*(exp(-c(2)*t)-exp(-c(3)*t));plot(t,y,' +',t,y1);legend('实验数据','拟合曲线')五,插值拟合相关知识在生产和科学实验中,自变量及因变量间的函数关系有时不能写出解析表达式,而只能得到函数在若干点的函数值或导数值,或者表达式过于复杂而需要较大的计算量。
数模十大常用算法及说明&参考文献

数模十大常用算法及说明1. 蒙特卡罗算法该算法又称随机性模拟算法,是通过计算机仿真来解决问题的算法,同时可以通过模拟来检验自己模型的正确性,几乎是比赛时必用的方法。
2. 数据拟合、参数估计、插值等数据处理算法比赛中通常会遇到大量的数据需要处理,而处理数据的关键就在于这些算法,通常使用MATLAB 作为工具。
3. 线性规划、整数规划、多元规划、二次规划等规划类算法建模竞赛大多数问题属于最优化问题,很多时候这些问题可以用数学规划算法来描述,通常使用Lindo 、Lingo 软件求解。
4. 图论算法这类算法可以分为很多种,包括最短路、网络流、二分图等算法,涉及到图论的问题可以用这些方法解决,需要认真准备。
5. 动态规划、回溯搜索、分治算法、分支定界等计算机算法这些算法是算法设计中比较常用的方法,竞赛中很多场合会用到。
6. 最优化理论的三大非经典算法:模拟退火算法、神经网络算法、遗传算法这些问题是用来解决一些较困难的最优化问题的,对于有些问题非常有帮助,但是算法的实现比较困难,需慎重使用。
7. 网格算法和穷举法两者都是暴力搜索最优点的算法,在很多竞赛题中有应用,当重点讨论模型本身而轻视算法的时候,可以使用这种暴力方案,最好使用一些高级语言作为编程工具。
8. 一些连续数据离散化方法很多问题都是实际来的,数据可以是连续的,而计算机只能处理离散的数据,因此将其离散化后进行差分代替微分、求和代替积分等思想是非常重要的。
9. 数值分析算法如果在比赛中采用高级语言进行编程的话,那些数值分析中常用的算法比如方程组求解、矩阵运算、函数积分等算法就需要额外编写库函数进行调用。
10. 图象处理算法赛题中有一类问题与图形有关,即使问题与图形无关,论文中也会需要图片来说明问题,这些图形如何展示以及如何处理就是需要解决的问题,通常使用MATLAB 进行处理。
十类算法的详细说明1.蒙特卡罗算法大多数建模赛题中都离不开计算机仿真,随机性模拟是非常常见的算法之一。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
假如把1 6硬币的例子看成一个大的问题。第一步, 把这一问题分成两个小问题。随机选择8个硬币作 为第一组称为A组,剩下的8个硬币作为第二组称 为B组。这样,就把1 6个硬币的问题分成两个8硬 币的问题来解决。第二步,判断A和B组中是否有 伪币。可以利用仪器来比较A组硬币和B组硬币的 重量。假如两组硬币重量相等,则可以判断伪币不 存在。假如两组硬币重量不相等,则存在伪币,并 且可以判断它位于较轻的那一组硬币中。最后,在 第三步中,用第二步的结果得出原先1 6个硬币问 题的答案。若仅仅判断硬币是否存在,则第三步非 常简单。无论A组还是B组中有伪币,都可以推断 这1 6个硬币中存在伪币。因此,仅仅通过一次重 量的比较,就可以判断伪币是否存在。
分治算法
君主和殖民者们所成功运用的分而治之策略也 可以运用到高效率的计算机算法的设计过程中。 利用这一策略可以解决如下问题:最小最大问 题、矩阵乘法、残缺棋盘、排序、选择和计算 一个几何问题——找出二维空间中距离最近的 两个点。
算法思想
分而治之方法与软件设计的模块化方法非常相 似。为了解决一个大的问题,可以: 1) 把它 分成两个或多个更小的问题; 2) 分别解决每 个小问题; 3) 把各小问题的解答组合起来, 即可得到原问题的解答。小问题通常与原问题 相似,可以递归地使用分而治之策略来解决。
算法思想
分枝定界(branch and bound)是另一种系统地搜 索解空间的方法,它与回溯法的主要区别在于对E-节 点的扩充方式。每个活节点有且仅有一次机会变成E节点。当一个节点变为E-节点时,则生成从该节点移 动一步即可到达的所有新节点。在生成的节点中,抛 弃那些不可能导出(最优)可行解的节点,其余节点 加入活节点表,然后从表中选择一个节点作为下一个 E-节点。从活节点表中取出所选择的节点并进行扩充, 直到找到解或活动表为空,扩充过程才结束。
6、模拟退火法、神经网络、遗传算 法
模拟退火法(SLeabharlann mulated Annealing)是 Kirkpatrick等人在一九八三年提出并成功地 应用在组合最佳化問題中,它是蒙特卡罗演算 法的推广。 人工神经网络的基本结构: 递归网络和前馈网 络 人工神经网络的典型模型有:自适应谐振理论 (ART)、 Kohonen 网络 、 反向传播(BP)网 络 、 Hopfield网
数学建模竞赛中应当 掌握的十类算法
• 蒙特卡罗算法 • 数据处理算法 • 数学规划算法 • 图论算法 • 动态规划、回溯搜索、分治算法、分支定
界 • 三大非经典算法 • 网格算法和穷举法 • 连续离散化方法 • 数值分析算法 • 图象处理算法
1、蒙特卡罗算法
该算法又称随机性模拟算法,是通过计算机 仿真来解决问题的算法,同时可以通过模拟 可以来检验自己模型的正确性,是比赛时必 用的方法
5、动态规划、回溯搜索、分治算法、 分支定界
这些算法是算法设计中比较常用的方法, 很多场合可以用到竞赛中
动态规划
它建立在最优原则的基础上。采用动态规 划方法,可以优雅而高效地解决许多用贪 婪算法或分而治之算法无法解决的问题。 动态规划方法在解决背包问题、图象压缩、 矩阵乘法链、最短路径、无交叉子集和元 件折叠等方面的有很大作用。
7、网格算法和穷举法
网格算法和穷举法都是暴力搜索最优点的 算法,在很多竞赛题中有应用,当重点讨 论模型本身而轻视算法的时候,可以使用 这种暴力方案,最好使用一些高级语言作 为编程工具
2、数据拟合、参数估计、插值 等数据处理算法
数据拟和: 从给出的一大堆数据中找出规律, 即设法构造一条曲线(拟和曲线)反映数据点 总的趋势,以消除其局部波动。
参数估计:对给定的统计问题,在建立了统 计模型以后,我们的任务就是依据样本对未 知总体进行各种推断,参数估计是统计推断 的重要内容之一。包括点估计方法、频率替 换法、矩法、极大似然估计法
插值法是函数逼近的一种重要方法,包括 多项式插值、分段插值和三角插值
3、数学规划算法
线性规划、整数规划、多元规划、二次规 划等规划类问题(建模竞赛大多数问题属 于最优化问题,很多时候这些问题可以用 数学规划算法来描述,通常使用Lindo、 Lingo软件实现)
4、图论算法
这类算法可以分为很多种,包括最短路、 网络流、二分图等算法,涉及到图论的问 题可以用这些方法解决,需要认真准备
考虑平面上的一个边长为1的正方形及其内 部的一个形状不规则的“图形”,如何求 出这个“图形”的面积呢?Monte Carlo方 法是这样一种“随机化”的方法:向该正 方形“随机地”投掷N个点落于“图形”内, 则该“图形”的面积近似为M/N。
另一类形式与Monte Carlo方法相似,但理 论基础不同的方法—“拟蒙特卡罗方法” (Quasi-Monte Carlo方法)—近年来也获得 迅速发展。我国数学家华罗庚、王元提出 的“华—王”方法即是其中的一例。这种方 法的基本思想是“用确定性的超均匀分布 序列(数学上称为Low Discrepancy Sequences)代替Monte Carlo方法中的随 机数序列。对某些问题该方法的实际速度 一般可比Monte Carlo方法提出高数百倍, 并可计算精确度。
蒙特卡罗(Monte Carlo)方法,或称计算机 随机模拟方法,是一种基于“随机数”的 计算方法。这一方法源于美国在第一次世 界大战进研制原子弹的“曼哈顿计划”。 该计划的主持人之一、数学家冯·诺伊曼用 驰名世界的赌城—摩纳哥的Monte Carlo— 来命名这种方法,为它蒙上了一层神秘色 彩。
• 具体实现的matlab代码: • ------------------------------------------------------------------------------------------------
--• function val = ballvol(n, m) • % BALLVOL Compute volume of unit ball in R^n •% • % Computes the volume of the n-dimensional unit ball • % using monte-carlo method. • % usage: val = BallVol(n, m) • % where: n = dimension • % m = number of realisations • % If the second argument is omitted, 1e4 is taken as default for m. • % (c) 1998, Rolf Krause, krause@math.fu-berlin.de • M = 1e4; • error = 0; • if(nargin <1 | nargin > 2), error('wrong number of arguments'); end • if nargin == 2, M = m; end • R = rand(n, M); • in = 0; • for i=1:M • if(norm(R(:,i),2) <= 1.0), in = in+1; end • end
算法思想
和贪婪算法一样,在动态规划中,可将一个 问题的解决方案视为一系列决策的结果。不同 的是,在贪婪算法中,每采用一次贪婪准则便 做出一个不可撤回的决策,而在动态规划中, 还要考察每个最优决策序列中是否包含一个最 优子序列。
寻找问题的解的一种可靠的方法是首先列出所有候 选解,然后依次检查每一个,在检查完所有或部 分候选解后,即可找到所需要的解。理论上,当 候选解数量有限并且通过检查所有或部分候选解 能够得到所需解时,上述方法是可行的。不过, 在实际应用中,很少使用这种方法,因为候选解 的数量通常都非常大(比如指数级,甚至是大数 阶乘),即便采用最快的计算机也只能解决规模 很小的问题。对候选解进行系统检查的方法有多 种,其中回溯和分枝定界法是比较常用的两种方 法。按照这两种方法对候选解进行系统检查通常 会使问题的求解时间大大减少(无论对于最坏情 形还是对于一般情形)。事实上,这些方法可以 使我们避免对很大的候选解集合进行检查,同时 能够保证算法运行结束时可以找到所需要的解。 因此,这些方法通常能够用来求解规模很大的问 题。
现在假设需要识别出这一伪币。把两个或三个硬币的情况作 为不可再分的小问题。注意如果只有一个硬币,那么不能判 断出它是否就是伪币。在一个小问题中,通过将一个硬币分 别与其他两个硬币比较,最多比较两次就可以找到伪币。这 样,1 6硬币的问题就被分为两个8硬币(A组和B组)的问 题。通过比较这两组硬币的重量,可以判断伪币是否存在。 如果没有伪币,则算法终止。否则,继续划分这两组硬币来 寻找伪币。假设B是轻的那一组,因此再把它分成两组,每 组有4个硬币。称其中一组为B1,另一组为B2。比较这两组, 肯定有一组轻一些。如果B1轻,则伪币在B1中,再将B1又 分成两组,每组有两个硬币,称其中一组为B1a,另一组为 B1b。比较这两组,可以得到一个较轻的组。由于这个组只 有两个硬币,因此不必再细分。比较组中两个硬币的重量, 可以立即知道哪一个硬币轻一些。较轻的硬币就是所要找的 伪币。
例2-1 [找出伪币] 给你一个装有1 6个硬币 的袋子。1 6个硬币中有一个是伪造的,并 且那个伪造的硬币比真的硬币要轻一些。你 的任务是找出这个伪造的硬币。为了帮助你 完成这一任务,将提供一台可用来比较两组 硬币重量的仪器,利用这台仪器,可以知道 两组硬币的重量是否相同。
比较硬币1与硬币2的重量。假如硬币1比硬币 2轻,则硬币1是伪造的;假如硬币2比硬币1 轻,则硬币2是伪造的。这样就完成了任务。 假如两硬币重量相等,则比较硬币3和硬币4。 同样,假如有一个硬币轻一些,则寻找伪币 的任务完成。假如两硬币重量相等,则继续 比较硬币5和硬币6。按照这种方式,可以最 多通过8次比较来判断伪币的存在并找出这一 伪币。
分枝定界
类似于回溯法,分枝定界法在搜索解空间时,也经常 使用树形结构来组织解空间。然而与回溯法不同的 是,回溯算法使用深度优先方法搜索树结构,而分 枝定界一般用宽度优先或最小耗费方法来搜索这些 树。本章与第1 6章所考察的应用完全相同,因此, 可以很容易比较回溯法与分枝定界法的异同。相对 而言,分枝定界算法的解空间比回溯法大得多,因 此当内存容量有限时,回溯法成功的可能性更大