吴恩达深度学习课程:神经网络和深度学习
机器学习领域的知名人物和论文

机器学习领域的知名人物和论文机器学习作为人工智能领域的重要分支及研究方向,不断涌现出许多杰出的知名人物以及具有重要影响力的论文。
这些人物和论文在推动机器学习技术发展和应用方面起到了重要的作用。
本文将介绍几位机器学习领域的知名人物以及他们的重要论文,带领读者了解机器学习领域的发展脉络和重要思想。
1. Andrew Ng(吴恩达)在机器学习领域,Andrew Ng无疑是一个家喻户晓的人物。
他是斯坦福大学的教授,并且曾经是谷歌的首席科学家。
他的重要贡献之一是创建了Coursera上非常著名的机器学习课程,该课程使得机器学习技术的学习变得更加便捷和可普及。
他的学术研究涉及深度学习、神经网络以及数据挖掘等领域。
他的论文《Deep Learning》被广泛引用,对深度学习领域的发展起到了重要推动作用。
2. Geoffrey Hinton(杰弗里·辛顿)Geoffrey Hinton被誉为“深度学习之父”,他是深度学习领域的杰出研究者和学者。
他的重要贡献之一是开发了BP(Backpropagation)算法,该算法为神经网络的训练提供了有效的方法。
他还提出了“Dropout”技术,通过随机丢弃一些神经元的方式来防止神经网络的过拟合问题。
他的论文《Deep Neural Networks for Acoustic Modeling in Speech Recognition》对语音识别等领域产生了巨大的影响。
3. Yoshua BengioYoshua Bengio是加拿大蒙特利尔大学教授,也是深度学习领域的重要人物之一。
他在深度学习领域的贡献源远流长。
他的论文《Learning Deep Architectures for AI》介绍了深度学习的概念和技术,并提出了一种深度置信网络(Deep Belief Networks)的训练方法。
这篇论文的发表引发了深度学习的研究和应用的热潮。
4. Ian GoodfellowIan Goodfellow是深度学习领域的年轻研究者,其主要贡献是提出了生成对抗网络(GAN)的概念。
吴恩达深度学习第二课第一周编程作业_regularization(正则化)
吴恩达深度学习第⼆课第⼀周编程作业_regularization(正则化)Regularization 正则化声明本⽂作业是在jupyter notebook上⼀步⼀步做的,带有⼀些过程中查找的资料等(出处已标明)并翻译成了中⽂,如有错误,欢迎指正!参考Kulbear 的和和,以及的,以及,欢迎来到本周的第⼆次作业。
深度学习模型有很⼤的灵活性和容量,如果训练数据集不够⼤,过拟合可能会成为⼀个严重的问题。
当然,它在训练集上做得很好,但学习过的⽹络不能推⼴到它从未见过的新例⼦!(也就是训练可以,⼀到实战测试就拉胯。
) 第⼆个作业的⽬的: 2. 正则化模型: 2.1:使⽤⼆范数对⼆分类模型正则化,尝试避免过拟合。
2.2:使⽤随机删除节点的⽅法精简模型,同样是为了尝试避免过拟合。
您将学习:在您的深度学习模型中使⽤正则化。
让我们⾸先导⼊将要使⽤的包。
# import packagesimport numpy as npimport matplotlib.pyplot as pltfrom reg_utils import sigmoid, relu, plot_decision_boundary, initialize_parameters, load_2D_dataset, predict_decfrom reg_utils import compute_cost, predict, forward_propagation, backward_propagation, update_parametersimport sklearnimport sklearn.datasetsimport scipy.io #scipy是构建在numpy的基础之上的,它提供了许多的操作numpy的数组的函数。
scipy.io包提供了多种功能来解决不同格式的⽂件的输⼊和输出。
from testCases import * #from XXX import*是把XXX下的所有名字引⼊当前名称空间。
【吴恩达课后编程作业】第三周作业(附答案、代码)隐藏层神经网络神经网络、深度学习、机器学习
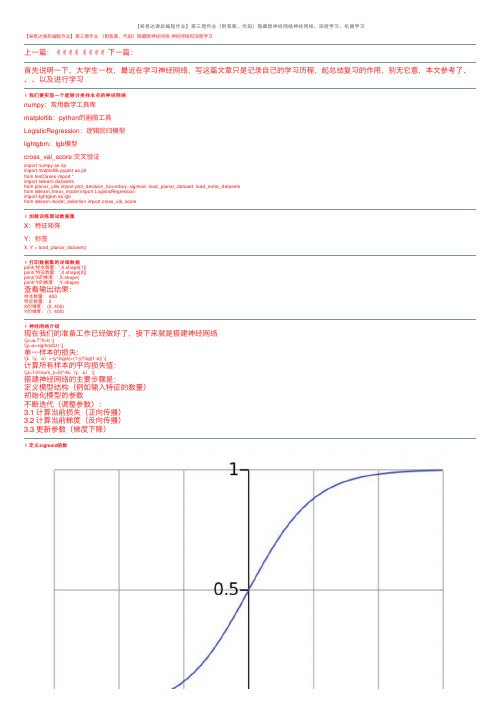
【吴恩达课后编程作业】第三周作业(附答案、代码)隐藏层神经⽹络神经⽹络、深度学习、机器学习【吴恩达课后编程作业】第三周作业(附答案、代码)隐藏层神经⽹络神经⽹络和深度学习上⼀篇:✌✌✌✌✌✌✌✌下⼀篇:⾸先说明⼀下,⼤学⽣⼀枚,最近在学习神经⽹络,写这篇⽂章只是记录⾃⼰的学习历程,起总结复习的作⽤,别⽆它意,本⽂参考了、、、以及进⾏学习✌我们要实现⼀个能够分类样本点的神经⽹络numpy:常⽤数学⼯具库matplotlib:python的画图⼯具LogisticRegression:逻辑回归模型lightgbm:lgb模型cross_val_score:交叉验证import numpy as npimport matplotlib.pyplot as pltfrom testCases import *import sklearn.datasetsfrom planar_utils import plot_decision_boundary, sigmoid, load_planar_dataset, load_extra_datasetsfrom sklearn.linear_model import LogisticRegressionimport lightgbm as lgbfrom sklearn.model_selection import cross_val_score✌加载训练测试数据集X:特征矩阵Y:标签X, Y = load_planar_dataset()✌打印数据集的详细数据print('样本数量:',X.shape[1])print('特征数量:',X.shape[0])print('X的维度:',X.shape)print('Y的维度:',Y.shape)查看输出结果:样本数量: 400特征数量: 2X的维度: (2, 400)Y的维度: (1, 400)✌神经⽹络介绍现在我们的准备⼯作已经做好了,接下来就是搭建神经⽹络\[z=w.T*X+b \]\[y=a=sigmoid(z) \]单⼀样本的损失:\[L(y,a)=-(y*log(a)+(1-y)*log(1-a)) \]计算所有样本的平均损失值:\[J=1/m\sum_{i=0}^mL(y,a) \]搭建神经⽹络的主要步骤是:定义模型结构(例如输⼊特征的数量)初始化模型的参数不断迭代(调整参数):3.1 计算当前损失(正向传播)3.2 计算当前梯度(反向传播)3.3 更新参数(梯度下降)✌定义sigmoid函数\[a=sigmoid(z) \]\[sigmoid=1/(1+e^-x) \]因为我们要做的是⼆分类问题,所以到最后要将其转化为概率,所以可以利⽤sigmoid函数的性质将其转化为0~1之间def sigmoid(z):"""功能:激活函数,计算sigmoid的值参数:z:任何维度的矩阵返回:s:sigmoid(z)"""s=1/(1+np.exp(-z))return s✌定义各⽹络层的节点数这⾥我们为什么要获取各个层的节点数呢?原因是在初始化w、b等参数时需要确定其维度,以便于后⾯的传播计算def layer_size(X,Y):"""功能:获得各个⽹络层的节点数参数:X:特征矩阵Y:标签返回:in_layer:输出层的节点数hidden_layer:隐藏层的节点数out_layer:输出层的节点数"""# 本数据集为两个特征in_layer=X.shape[0]# ⾃⼰定义隐藏层为4个节点hidden_layer=4# 输出层为1维out_layer=Y.shape[0]return in_layer,hidden_layer,out_layer✌定义初始化w、b的函数在进⾏梯度下降之前,要初始化w和b的值,但是这⾥会有个问题,为了⽅便我们会把w、b的值全部初始化为0,这样做是不正确的,原因是:如果都为0,会导致在传播计算时,模型对称,各个节点的参数不起作⽤,可以⾃⼰推到⼀下所以我们要给w、b进⾏随机取值本⽂参数维度:W1:(4,2)b1:(4,1)W2:(1,4)b2:(1,1)def init_w_b(in_layer,hidden_layer,out_layer):"""功能:初始化w,b的维度和值参数:in_layer:输出层的节点数hidden_layer:隐藏层的节点数out_layer:输出层的节点数返回:init_params:对应各层参数的字典"""# 定义随机种⼦,以便之后每次产⽣随机数唯⼀np.random.seed(2021)# 初始化参数,符合⾼斯分布W1=np.random.randn(hidden_layer,in_layer)*0.01b1=np.random.randn(hidden_layer,1)W2=np.random.randn(out_layer,hidden_layer)*0.01b2=np.random.randn(out_layer,1)init_params={'W1':W1,'b1':b1,'W2':W2,'b2':b2}return init_params✌定义向前传播函数神经⽹络分为正向传播和反向传播正向传播计算求出损失函数,然后反向计算各个梯度然后进⾏梯度下降,更新参数计算公式:\[Z1=W1*X+b1 \]\[A1=tanh(Z1) \]\[Z2=W2*A1+b2 \]\[A2=sigmoid(Z2) \]def forward(W1,b1,W2,b2,X,Y):"""功能:向前传播,计算出各个层的激活值和未激活值(A1,A2,Z1,Z2)参数:W1:隐藏层的权值参数b1:隐藏层的偏置参数W2:输出层的权值参数b2:输出层的偏置参数X:特征矩阵Y:标签返回:forward_params:对应各层数据的字典"""# 计算隐藏层Z1=np.dot(W1,X)+b1Z1=np.dot(W1,X)+b1# 激活A1=np.tanh(Z1)# 计算第⼆层Z2=np.dot(W2,A1)+b2# 激活A2=sigmoid(Z2)forward_params={'Z1':Z1,'A1':A1,'Z2':Z2,'A2':A2,'W1':W1,'b1':b1,'W2':W2,'b2':b2}return forward_params✌定义损失函数损失函数为交叉熵,数值越⼩,表明模型越优秀计算公式:\[J(W1,b1,W2,b2)=1/m\sum_{i=0}^m-(y*log(A2)+(1-y)*log(1-A2)) \]def loss_fn(W1,b1,W2,b2,X,Y):"""功能:构造损失函数,计算损失值参数:W1:隐藏层的权值参数b1:隐藏层的偏置参数W2:输出层的权值参数b2:输出层的偏置参数X:特征矩阵Y:标签返回:loss:模型损失值"""# 样本数m=X.shape[1]# 向前传播,获取激活值A2forward_params=forward(W1,b1,W2,b2,X,Y)A2=forward_params['A2']# 计算损失值loss=np.multiply(Y,np.log(A2))+np.multiply(1-Y,np.log(1-A2))loss=-1/m*np.sum(loss)# 降维,如果不写,可能会有错误loss=np.squeeze(loss)return loss✌定义向后传播函数反向计算各个梯度然后进⾏梯度下降,更新参数计算公式:\[dZ2=A2-Y \]\[dW2=1/m*dZ2*A1.T \]\[db2=1/m*\sum_{i=0}^mdZ2 \]第⼀层的参数同理,这⾥要记住计算各参数梯度,就是⾼数中的链式法则,这也就是为什么叫做向后传播,想要计算前⼀层的参数导数值就要先计算出后⼀层的梯度值\[y=2*x \]\[z=3*y \]\[∂z/∂x=(∂z/∂y )*(dy/dx) \]记住这个⼀切都OKdef backward(W1,b1,W2,b2,X,Y):"""功能:向后传播,计算各个层参数的梯度(偏导)参数:W1:隐藏层的权值参数b1:隐藏层的偏置参数W2:输出层的权值参数b2:输出层的偏置参数X:特征矩阵Y:标签返回:grads:各参数的梯度值"""# 样本数m=X.shape[1]# 进⾏前向传播,获取各参数值forward_params=forward(W1,b1,W2,b2,X,Y)A1=forward_params['A1']A2=forward_params['A2']W1=forward_params['W1']W2=forward_params['W2']# 计算梯度dZ2= A2 - YdW2 = (1 / m) * np.dot(dZ2, A1.T)db2 = (1 / m) * np.sum(dZ2, axis=1, keepdims=True)dZ1 = np.multiply(np.dot(W2.T, dZ2), 1 - np.power(A1, 2))dW1 = (1 / m) * np.dot(dZ1, X.T)db1 = (1 / m) * np.sum(dZ1, axis=1, keepdims=True)grads = {"dW1": dW1,"db1": db1,"dW2": dW2,"db2": db2 }return grads✌定义整个传播过程⼀个传播流程包括:向前传播计算损失函数向后传播3.1 计算梯度3.2 更新参数def propagate(W1,b1,W2,b2,X,Y):"""功能:传播运算,向前->损失->向后->参数:W1:隐藏层的权值参数b1:隐藏层的偏置参数W2:输出层的权值参数b2:输出层的偏置参数X:特征矩阵Y:标签Y:标签返回:grads,loss:各参数的梯度,损失值"""# 计算损失loss=loss_fn(W1,b1,W2,b2,X,Y)# 向后传播,计算梯度grads=backward(W1,b1,W2,b2,X,Y)return grads,loss✌定义优化器函数⽬标是通过最⼩化损失函数 J来学习 w 和 b 。
吴恩达提示词系列解读

吴恩达提示词系列解读摘要:1.吴恩达简介2.提示词系列的背景和意义3.深度学习提示词解读4.强化学习提示词解读5.计算机视觉提示词解读6.自然语言处理提示词解读7.总结正文:吴恩达,全球知名的AI专家,拥有丰富的学术和产业经验,他的一系列提示词为广大AI学习者提供了宝贵的指导。
本文将针对吴恩达提示词系列进行解读,以期帮助大家更好地理解和学习AI技术。
1.吴恩达简介吴恩达,Andrew Ng,曾是斯坦福大学的人工智能教授,后来创立了Google Brain项目,并成为了百度首席科学家。
他一直致力于推动AI技术的发展和应用,尤其是在深度学习和强化学习领域。
2.提示词系列的背景和意义吴恩达提示词系列是他对AI领域的重要观点和思考的总结,涵盖了深度学习、强化学习、计算机视觉、自然语言处理等多个领域。
这些提示词对于AI学习者来说,具有很高的参考价值,可以帮助我们更好地理解AI技术的发展趋势和应用方向。
3.深度学习提示词解读吴恩达的深度学习提示词主要包括“神经网络”、“反向传播”、“卷积神经网络”、“循环神经网络”等。
这些提示词概括了深度学习的核心概念和技术,对于理解深度学习的基本原理和应用至关重要。
4.强化学习提示词解读吴恩达的强化学习提示词主要包括“智能体”、“环境”、“状态”、“动作”、“奖励”等。
这些提示词揭示了强化学习的本质,即智能体如何在环境中通过选择动作来获得奖励,从而实现学习。
5.计算机视觉提示词解读吴恩达的计算机视觉提示词主要包括“图像分类”、“目标检测”、“语义分割”等。
这些提示词代表了计算机视觉的主要任务,对于我们理解和应用计算机视觉技术具有重要意义。
6.自然语言处理提示词解读吴恩达的自然语言处理提示词主要包括“词向量”、“序列到序列模型”、“注意力机制”等。
这些提示词概括了自然语言处理的核心技术,对于我们理解和应用自然语言处理技术具有重要价值。
人工智能 国外经典课程

人工智能国外经典课程人工智能是当今科技领域的热门话题,国外有许多经典课程涵盖了人工智能的各个领域和技术。
下面我将列举一些国外经典的人工智能课程,这些课程涵盖了人工智能的基础理论、算法和应用等方面。
1. Stanford University - CS229: Machine Learning这门课程由斯坦福大学的吴恩达教授主讲,是机器学习领域的经典之作。
课程内容包括监督学习、无监督学习、强化学习等各种机器学习算法和方法。
2. Massachusetts Institute of Technology - 6.034: Artificial Intelligence这门课程由麻省理工学院的Patrick Henry Winston教授主讲,涵盖了人工智能的基础知识、推理和规划、感知和学习等方面。
课程通过讲解经典的人工智能方法和案例,帮助学生理解人工智能的核心概念和技术。
3. University of California, Berkeley - CS188: Introduction to Artificial Intelligence这门课程是加州大学伯克利分校的经典人工智能课程,内容包括搜索、规划、机器学习、自然语言处理等方面。
课程通过理论讲解和实践项目,培养学生的人工智能编程能力和解决实际问题的能力。
4. Carnegie Mellon University - 10-701: Introduction to这门课程由卡内基梅隆大学的Tom Mitchell教授主讲,介绍了机器学习的基本理论和算法。
课程内容包括统计学习理论、监督学习和无监督学习方法等,旨在帮助学生理解机器学习的原理和应用。
5. University of Washington - CSE 446: Machine Learning这门课程由华盛顿大学的Pedro Domingos教授主讲,涵盖了机器学习的基本概念、算法和应用。
吴恩达推荐的深度学习书目

UFLDL Recommended ReadingsIf you're learning about UFLDL (Unsupervised Feature Learning and Deep Learning), here is a list of papers to consider reading. We're assuming you're already familiar with basic machine learning at the level of [CS229 (lecture notes available)].The basics:▪[CS294A] Neural Networks/Sparse Autoencoder Tutorial. (Most of this is now in the UFLDL Tutorial, but the exercise is still on the CS294A website.)▪[1] Natural Image Statistics book, Hyvarinen et al.▪This is long, so just skim or skip the chapters that you already know.▪Important chapters: 5 (PCA and whitening; you'll probably already know the PCA stuff),6 (sparse coding),7 (ICA), 10 (ISA), 11 (TICA), 16 (temporal models).▪[2] Olshausen and Field. Emergence of simple-cell receptive field properties by learning a sparse code for natural images Nature 1996. (Sparse Coding)▪[3] Rajat Raina, Alexis Battle, Honglak Lee, Benjamin Packer and Andrew Y. Ng.Self-taught learning: Transfer learning from unlabeled data. ICML 2007Autoencoders:▪[4] Hinton, G. E. and Salakhutdinov, R. R. Reducing the dimensionality of data with neural networks. Science 2006.▪If you want to play with the code, you can also find it at [5].▪[6] Bengio, Y., Lamblin, P., Popovici, P., Larochelle, H. Greedy Layer-Wise Training of Deep Networks. NIPS 2006▪[7] Pascal Vincent, Hugo Larochelle, Yoshua Bengio and Pierre-Antoine Manzagol.Extracting and Composing Robust Features with Denoising Autoencoders. ICML 2008.▪(They have a nice model, but then backwards rationalize it into a probabilistic model.Ignore the backwards rationalized probabilistic model [Section 4].)Analyzing deep learning/why does deep learning work:▪[8] H. Larochelle, D. Erhan, A. Courville, J. Bergstra, and Y. Bengio. An Empirical Evaluation of Deep Architectures on Problems with Many Factors of Variation. ICML 2007.▪(Someone read this and let us know if this is worth keeping,. [Most model related material already covered by other papers, it seems not many impactful conclusionscan be made from results, but can serve as reading for reinforcement for deepmodels])▪[9] Dumitru Erhan, Yoshua Bengio, Aaron Courville, Pierre-Antoine Manzagol, Pascal Vincent, and Samy Bengio. Why Does Unsupervised Pre-training Help Deep Learning?JMLR 2010▪[10] Ian J. Goodfellow, Quoc V. Le, Andrew M. Saxe, Honglak Lee and Andrew Y. Ng.Measuring invariances in deep networks. NIPS 2009.RBMs:▪[11] Tutorial on RBMs.▪But ignore the Theano code examples.▪(Someone tell us if this should be moved later. Useful for understanding some of DL literature, but not needed for many of the later papers? [Seems ok to leave in, usefulintroduction if reader had no idea about RBM's, and have to deal with Hinton's 06Science paper or 3-way RBM's right away])Convolution Networks:▪[12] Tutorial on Convolution Neural Networks.▪But ignore the Theano code examples.Applications:▪Computer Vision▪[13] Jianchao Yang, Kai Yu, Yihong Gong, Thomas Huang. Linear Spatial Pyramid Matching using Sparse Coding for Image Classification, CVPR 2009 ▪[14] A. Torralba, R. Fergus and Y. Weiss. Small codes and large image databases for recognition. CVPR 2008.▪Audio Recognition▪[15] Unsupervised feature learning for audio classification using convolutional deep belief networks, Honglak Lee, Yan Largman, Peter Pham and Andrew Y. Ng. In NIPS 2009.Natural Language Processing:▪[16] Yoshua Bengio, Réjean Ducharme, Pascal Vincent and Christian Jauvin, A Neural Probabilistic Language Model. JMLR 2003.▪[17] R. Collobert and J. Weston. A Unified Architecture for Natural Language Processing: Deep Neural Networks with Multitask Learning. ICML 2008.▪[18] Richard Socher, Jeffrey Pennington, Eric Huang, Andrew Y. Ng, and Christopher D.Manning. Semi-Supervised Recursive Autoencoders for Predicting Sentiment Distributions.EMNLP 2011▪[19] Richard Socher, Eric Huang, Jeffrey Pennington, Andrew Y. Ng, and Christopher D.Manning. Dynamic Pooling and Unfolding Recursive Autoencoders for ParaphraseDetection. NIPS 2011▪[20] Mnih, A. and Hinton, G. E. Three New Graphical Models for Statistical Language Modelling. ICML 2007Advanced stuff:▪Slow Feature Analysis:▪[21] Slow feature analysis yields a rich repertoire of complex cell properties. Journal of Vision, 2005.▪Predictive Sparse Decomposition▪[22] Koray Kavukcuoglu, Marc'Aurelio Ranzato, and Yann LeCun, "Fast Inference in Sparse Coding Algorithms with Applications to Object Recognition", Computationaland Biological Learning Lab, Courant Institute, NYU, 2008.▪[23] Kevin Jarrett, Koray Kavukcuoglu, Marc'Aurelio Ranzato, and Yann LeCun, "What is the Best Multi-Stage Architecture for Object Recognition?", In ICCV 2009Mean-Covariance models▪[24] M. Ranzato, A. Krizhevsky, G. Hinton. Factored 3-Way Restricted Boltzmann Machines for Modeling Natural Images. In AISTATS 2010.▪[25] M. Ranzato, G. Hinton, Modeling Pixel Means and Covariances Using Factorized Third-Order Boltzmann Machines. CVPR 2010▪(someone and tell us if you need to read the 3-way RBM paper before the mcRBM one[I didn't find it necessary, in fact the CVPR paper seemed easier to understand.])▪[26] Dahl, G., Ranzato, M., Mohamed, A. and Hinton, G. E. Phone Recognition with the Mean-Covariance Restricted Boltzmann Machine. NIPS 2010.▪[27] Y. Karklin and M. S. Lewicki, Emergence of complex cell properties by learning to generalize in natural scenes, Nature, 2008.▪(someone tell us if this should be here. Interesting algorithm + nice visualizations, though maybe slightly hard to understand. [seems a good reminder there are otherexisting models])Overview▪[28] Yoshua Bengio. Learning Deep Architectures for AI. FTML 2009.▪(Broad landscape description of the field, but technical details there are hard to follow so ignore that. This is also easier to read after you've gone over some of literature ofthe field.)Practical guides:▪[29] Geoff Hinton. A practical guide to training restricted Boltzmann machines. UTML TR 2010–003.▪ A practical guide (read if you're trying to implement and RBM; but otherwise skip since this is not really a tutorial).▪[30] Y. LeCun, L. Bottou, G. Orr and K. Muller. Efficient Backprop. Neural Networks: Tricks of the trade, Springer, 1998▪Read if you're trying to run backprop; but otherwise skip since very low-level engineering/hackery tricks and not that satisfying to read.Also, for other lists of papers:▪[31] Honglak Lee's Course▪[32] from Geoff's tutorial。
《深度学习PPT》第3章 人工神经网络与深度学习
9 of 57
3.1 探秘大脑的工作原理
第3章 人工神经网络与深度学习
3.1.2 人脑神经元的结构
神经元的基本结构包括细胞体和突起两部分。细胞体包括细胞核、细胞质、细胞 膜。细胞膜内外电位差称为膜电位。神经元的突起一般包括数条短而呈树状分支 的树突和一条长而分支少的轴突。长的突起外表大都套有一层鞘,组成神经纤维, 神经纤维末端的细小分支叫作神经末梢。神经纤维集结成束,外面包有膜,构成 一条神经。
6 of 57
3.1 探秘大脑的工作原理
(5)深度学习算法 数据输 出
外部环 境
第3章 人工神经网络与深度学习
数据输入
执行
深度学习(端到端网络,一组函数集)
知识库
学习
深度学 习
深度学习的基本模型
人的活动过程伴随信息传递、知识处理和智能的形成过程,其信息 传输模型如图所示
7 of 57
3.1 探秘大脑的工作原理
22 of 57
3.4 人脑神经网络的互连结构
第3章 人工神经网络与深度学习
3.4.1 前馈神经网络
前馈神经网络(feedforward neural network),简称前馈网络,是人 工神经网络的一种。在此种神经网络中,各神经元从输入层开始,接 收前一级输入,并输入到下一级,直至输出层。整个网络中无反馈, 可用一个有向无环图表示
输出
hw.b
3.2 人脑神经元模型
3.2.2 激活函数
常用激活函数主要有:线性函数、 非线性函数(sigmoid型函数)、 概率型函数。
y
x 0
(a)线性函数 y
x 0
(c) ReLU函数 y
1 x
0 (e) sigmoid函数
神经网络及深度学习(包含matlab代码).pdf
神经网络及深度学习(包含matlab代码).pdf
神经网络可以使用中间层构建出多层抽象,正如在布尔电路中所做的那样。
如果进行视觉模式识别,那么第1 层的神经元可能学会识别边;第2 层的神经元可以在此基础上学会识别更加复杂的形状,例如三角形或矩形;第3 层将能够识别更加复杂的形状,以此类推。
有了这些多层抽象,深度神经网络似乎可以学习解决复杂的模式识别问题。
正如电路示例所体现的那样,理论研究表明深度神经网络本质上比浅层神经网络更强大。
《深入浅出神经网络与深度学习》PDF+代码分析
《深入浅出神经网络与深度学习》PDF中文,249页;PDF英文,292页;配套代码。
提取码: 6sgh
以技术原理为导向,辅以MNIST 手写数字识别项目示例,介绍神经网络架构、反向传播算法、过拟合解决方案、卷积神经网络等内容,以及如何利用这些知识改进深度学习项目。
学完后,将能够通过编写Python 代码来解决复杂的模式识别问题。
神经网络优化算法:梯度下降法、Momentum、RMSprop和Adam
神经⽹络优化算法:梯度下降法、Momentum、RMSprop和Adam最近回顾神经⽹络的知识,简单做⼀些整理,归档⼀下神经⽹络优化算法的知识。
关于神经⽹络的优化,吴恩达的深度学习课程讲解得⾮常通俗易懂,有需要的可以去学习⼀下,本⼈只是对课程知识点做⼀个总结。
吴恩达的深度学习课程放在了⽹易云课堂上,链接如下(免费):神经⽹络最基本的优化算法是反向传播算法加上梯度下降法。
通过梯度下降法,使得⽹络参数不断收敛到全局(或者局部)最⼩值,但是由于神经⽹络层数太多,需要通过反向传播算法,把误差⼀层⼀层地从输出传播到输⼊,逐层地更新⽹络参数。
由于梯度⽅向是函数值变⼤的最快的⽅向,因此负梯度⽅向则是函数值变⼩的最快的⽅向。
沿着负梯度⽅向⼀步⼀步迭代,便能快速地收敛到函数最⼩值。
这就是梯度下降法的基本思想,从下图可以很直观地理解其含义。
梯度下降法的迭代公式如下:w=w-\alpha* dw其中w是待训练的⽹络参数,\alpha是学习率,是⼀个常数,dw是梯度。
以上是梯度下降法的最基本形式,在此基础上,研究⼈员提出了其他多种变种,使得梯度下降法收敛更加迅速和稳定,其中最优秀的代表便是Mommentum, RMSprop和Adam等。
Momentum算法Momentum算法⼜叫做冲量算法,其迭代更新公式如下:\begin{cases} v=\beta v+(1-\beta)dw \\ w=w-\alpha v \end{cases}光看上⾯的公式有些抽象,我们先介绍⼀下指数加权平均,再回过头来看这个公式,会容易理解得多。
指数加权平均假设我们有⼀年365天的⽓温数据\theta_1,\theta_2,...,\theta_{365},把他们化成散点图,如下图所⽰:这些数据有些杂乱,我们想画⼀条曲线,⽤来表征这⼀年⽓温的变化趋势,那么我们需要把数据做⼀次平滑处理。
最常见的⽅法是⽤⼀个华东窗⼝滑过各个数据点,计算窗⼝的平均值,从⽽得到数据的滑动平均值。
吴恩达深度学习第一课第四周课后编程作业assignment4_1
吴恩达深度学习第⼀课第四周课后编程作业assignment4_1Building your Deep Neural Network: Step by Step本⽂作业是在jupyter notebook上⼀步⼀步做的,带有⼀些过程中查找的资料等(出处已标明)并翻译成了中⽂,如有错误,欢迎指正!欢迎来到第四周作业(第⼆部分的第⼀部分)!您之前已经训练了⼀个两层的神经⽹络(只有⼀个隐藏层)。
这周,你将构建⼀个深度神经⽹络,你想要多少层就有多少层!•在本笔记本中,您将实现构建深度神经⽹络所需的所有功能(函数)。
•在下⼀个作业中,你将使⽤这些函数来建⽴⼀个⽤于图像分类的深度神经⽹络。
完成这项任务后,您将能够:•使⽤⾮线性单元,⽐如ReLU来改进你的模型•构建更深层次的神经⽹络(隐含层超过1层)•实现⼀个易于使⽤的神经⽹络类符号:就是上标的【l】代表第l层,上标的【i】代表第i个样本,下标的 i 代表第 i 个条⽬1 - Packages 包让我们⾸先导⼊在此任务中需要的所有包。
·numpy是使⽤Python进⾏科学计算的主要包。
·matplotlib是⼀个⽤Python绘制图形的库。
·dnn_utils为本笔记本提供了⼀些必要的函数。
·testCases提供了⼀些测试⽤例来评估函数的正确性·seed(1)⽤于保持所有随机函数调⽤的⼀致性。
它将帮助我们批改你的作业。
请不要换种⼦。
import numpy as npimport h5py #h5py是Python语⾔⽤来操作HDF5的模块。
import matplotlib.pyplot as pltfrom testCases_v2 import *from dnn_utils_v2 import sigmoid, sigmoid_backward, relu, relu_backward%matplotlib inlineplt.rcParams['figure.figsize'] = (5.0, 4.0) # set default size of plotsplt.rcParams['image.interpolation'] = 'nearest'plt.rcParams['image.cmap'] = 'gray'%load_ext autoreload%autoreload 2np.random.seed(1)python库——h5py⼊门讲解,来⾃,链接:%load_ext autoreload是什么意思:在执⾏⽤户代码前,重新装⼊软件的扩展和模块。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
吴恩达深度学习课程:神经网络和深度学习[中英文字幕+ppt课件]
内容简介
吴恩达(Andrew Ng)相信大家都不陌生了。
2017年8 月8 日,吴恩达在他自己创办的在线教育平台Coursera 上线了他的人工智能专项课程(Deep Learning Specialization)。
此课程广受好评,通过视频讲解、作业与测验等让更多的人对人工智能有了了解与启蒙,国外媒体报道称:吴恩达这次深度学习课程是迄今为止,最全面、系统和容易获取的深度学习课程,堪称普通人的人工智能第一课。
关注微信公众号datayx 然后回复“深度学习”即可获取。
第一周深度学习概论:
学习驱动神经网络兴起的主要技术趋势,了解现今深度学习在哪里应用、如何应用。
1.1 欢迎来到深度学习工程师微专业
1.2 什么是神经网络?
1.3 用神经网络进行监督学习
1.4 为什么深度学习会兴起?
1.5 关于这门课
1.6 课程资源
第二周神经网络基础:
学习如何用神经网络的思维模式提出机器学习问题、如何使用向量化加速你的模型。
2.1 二分分类
2.2 logistic 回归
2.3 logistic 回归损失函数
2.4 梯度下降法
2.5 导数
2.6 更多导数的例子
2.7 计算图
2.8 计算图的导数计算
2.9 logistic 回归中的梯度下降法
2.10 m 个样本的梯度下降
2.11 向量化
2.12 向量化的更多例子
2.13 向量化logistic 回归
2.14 向量化logistic 回归的梯度输出
2.15 Python 中的广播
2.16 关于python / numpy 向量的说明
2.17 Jupyter / Ipython 笔记本的快速指南
2.18 (选修)logistic 损失函数的解释
第三周浅层神经网络:
学习使用前向传播和反向传播搭建出有一个隐藏层的神经网络。
3.1 神经网络概览
3.2 神经网络表示
3.3 计算神经网络的输出
3.4 多样本向量化
3.5 向量化实现的解释
3.6 激活函数
3.7 为什么需要非线性激活函数?
3.8 激活函数的导数
3.9 神经网络的梯度下降法
3.10 (选修)直观理解反向传播
3.11 随机初始化
第四周深层神经网络:
理解深度学习中的关键计算,使用它们搭建并训练深层神经网络,并应用在计算机视觉中。
4.1 深层神经网络
4.2 深层网络中的前向传播
4.3 核对矩阵的维数
4.4 为什么使用深层表示
4.5 搭建深层神经网络块
4.6 前向和反向传播
4.7 参数VS 超参数
4.8 这和大脑有什么关系?
..................
课程介绍
If you want to break into AI, this Specialization will help you do so. Deep Learning is one of the most highly sought after skills in tech. We will help you become good at Deep Learning.
In five courses, you will learn the foundations of Deep Learning, understand how to build neural networks, and learn how to lead successful machine learning projects. You will learn about Convolutional networks, RNNs, LSTM, Adam, Dropout, BatchNorm, Xavier/He initialization, and more. You will work on case studies from healthcare, autonomous driving, sign language reading, music generation, and natural language processing. You will master not only the theory, but also see how it is applied in industry. You will practice all these ideas in Python and in TensorFlow, which we will teach.
You will also hear from many top leaders in Deep Learning, who will share with you their personal stories and give you career advice.
AI is transforming multiple industries. After finishing this specialization, you will likely find creative ways to apply it to your work.
We will help you master Deep Learning, understand how to apply it, and build a career in AI.。