stata回归分析完整步骤-吐血推荐12页
STATA软件操作相关与回归分析

STATA软件操作相关与回归分析一、相关分析相关分析用于研究两个变量之间的相关性。
在STATA中,可以使用命令"correlate"进行相关分析。
语法:correlate 变量列表例子:我们以一个示例数据集"auto"为例,研究汽车价格与里程数和马力之间的相关性。
```sysuse autocorrelate price mpg turn```上述命令将计算汽车价格(price)与里程数(mpg)和轮胎转向(turn)之间的相关系数。
输出结果将显示相关系数矩阵,其中包括Pearson相关系数、Spearman相关系数和Kendall相关系数。
二、简单线性回归简单线性回归分析用于研究一个因变量和一个自变量之间的关系。
在STATA中,可以使用命令“regress”进行简单线性回归分析。
语法:regress 因变量自变量例子:我们继续使用上述示例数据集"auto",研究汽车价格与里程数之间的关系。
```sysuse autoregress price mpg```上述命令将进行汽车价格(price)与里程数(mpg)之间的简单线性回归分析。
输出结果将包括回归系数估计值、拟合优度、标准误差、t值、P值等。
另外,使用命令“predict”可以进行预测。
例子:我们可以使用上述回归模型,对新数据进行价格的预测。
```predict new_price, x```上述命令将对新数据集中的里程数进行预测,并将结果保存在新的变量new_price中。
三、多元回归分析多元回归分析用于研究一个因变量和多个自变量之间的关系。
在STATA中,可以使用命令“regress”进行多元回归分析。
语法:regress 因变量自变量1 自变量2 ...例子:我们使用示例数据集"auto",研究汽车价格与里程数、马力和重量之间的关系。
```sysuse autoregress price mpg displacement weight```上述命令将进行汽车价格(price)与里程数(mpg)、马力(displacement)和重量(weight)之间的多元线性回归分析。
5分钟速学stata面板数据回归初学者超实用!

5分钟速学stata面板数据回归初学者超实用!5 分钟速学 Stata 面板数据回归初学者超实用!在当今的数据分析领域,Stata 软件因其强大的功能和易用性而备受青睐。
对于初学者来说,掌握 Stata 中的面板数据回归分析是一项非常有用的技能。
在接下来的 5 分钟里,让我们一起快速了解一下面板数据回归的基础知识和操作步骤。
首先,我们来了解一下什么是面板数据。
面板数据是一种同时包含时间和个体两个维度的数据结构。
比如说,我们研究多个公司在若干年的财务数据,这就是一个典型的面板数据。
与单纯的横截面数据或时间序列数据相比,面板数据能够提供更丰富的信息,有助于我们更好地理解和解释经济现象。
那么,为什么要使用面板数据回归呢?它有几个显著的优点。
一是可以控制个体的异质性,即不同个体之间可能存在的固有差异。
二是能够更好地捕捉动态效应,观察变量随时间的变化。
三是增加了样本量,提高了估计的效率和准确性。
在 Stata 中进行面板数据回归,我们首先需要将数据导入。
假设我们的数据文件是一个 Excel 表格,我们可以使用`import excel` 命令来导入数据。
当然,如果数据是其他格式,如 CSV 等,Stata 也提供了相应的导入命令。
导入数据后,我们需要告诉 Stata 这是一个面板数据,并指定个体标识变量和时间标识变量。
例如,如果我们的数据中,每个公司有一个唯一的代码作为个体标识,每年有一个年份作为时间标识,我们可以使用以下命令:```stataxtset company_id year```接下来,就是选择合适的面板数据回归模型。
常见的模型有固定效应模型和随机效应模型。
固定效应模型假设个体之间的差异是固定的,不随时间变化。
如果我们认为个体的未观测到的特征与解释变量相关,那么就应该选择固定效应模型。
在 Stata 中,可以使用`xtreg y x1 x2, fe` 命令来进行固定效应回归。
随机效应模型则假设个体之间的差异是随机的,与解释变量不相关。
5分钟速学stata面板数据回归(初学者超实用!)
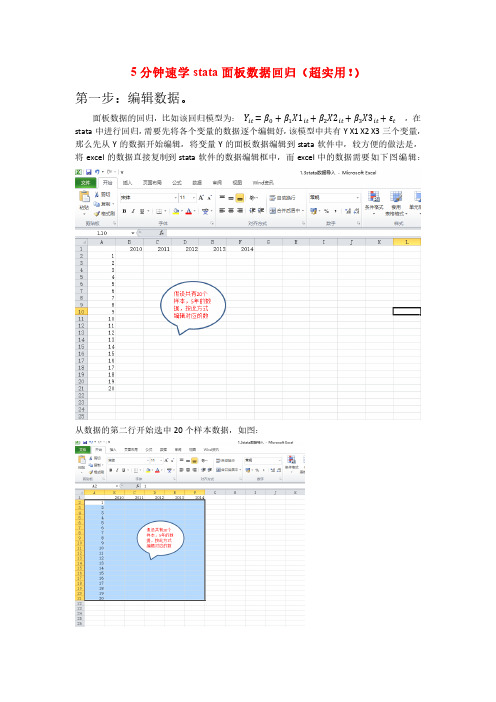
5分钟速学stata面板数据回归(超实用!)第一步:编辑数据。
面板数据的回归,比如该回归模型为:Y it=β0+β1X1it+β2X2it+β3X3it+εt,在stata中进行回归,需要先将各个变量的数据逐个编辑好,该模型中共有Y X1 X2 X3三个变量,那么先从Y的数据开始编辑,将变量Y的面板数据编辑到stata软件中,较方便的做法是,将excel的数据直接复制到stata软件的数据编辑框中,而excel中的数据需要如下图编辑:从数据的第二行开始选中20个样本数据,如图:直接复制粘贴至stata中的data editor中,如图:第二步:格式调整。
首先,请将代表样本的var1Y变量数据是选20个省份5年的数据为样本,那么口令为rename var1 province。
例如:本例中的Y变量数据编辑接下来需要输入口令为reshape long var,i(province)其中,var代表的是所有的年份(var2,var3,var4,var5,var6),转化后格式如图:转化成功后,继续重命名,其中_j这里代表原始表中的年份,var代表该变量的名称例如,我们编辑的是Y变量的数据,所以口令3和口令4的输入如下:口令3:rename _j year口令4:rename var taxi (注:taxi就是Y变量,我们用taxi表示Y)命名完,数据编辑框如下图所示。
第三步:排序。
例如,本例中的Y变量(taxi),是20个省份和5年的面板数据,那么口令4为sort province year(虽意思是将province按升序排列,然后再根据排好的province数列排year这一列升序排列。
然很多时候在执行sort之前,数据已经符合排序要求了,但为以防万一,请务必执行此操作)第三步:保存。
按下图中圈红的保存键,保存变量Y(即taxi)的数据。
第四步:重置。
至此,变量Y的数据导入完成。
接下来将stata此时,数据编辑框空白,接下来就可以输入X1的数据,方法与变量Y的数据输入完全一样。
stata回归分析完整步骤-吐血推荐

stata回归分析完整步骤——吐血推荐****下载连乘函数prod,方法为:findit dm71sort stkcd date //对公司和日期排序gen r1=1+r //r为实际公司的股票收益率gen r2=1+r_yq //r_yq为公司的预期股票收益率egen r3=prod(r1),by(stkcd date) //求每个公司事件日的累计复合收益率egen r4=prod(r2),by(stkcd date) //求每个公司事件日的累计预期的复合收益率gen r=r4-r3capture clear (清空内存中的数据)capture log close (关闭所有打开的日志文件)set mem 128m (设置用于stata使用的内存容量)set more off (关闭more选项。
如果打开该选项,那么结果分屏输出,即一次只输出一屏结果。
你按空格键后再输出下一屏,直到全部输完。
如果关闭则中间不停,一次全部输出。
)set matsize 4000 (设置矩阵的最大阶数。
我用的是不是太大了?)cd D: (进入数据所在的盘符和文件夹。
和dos的命令行很相似。
)log using (文件名).log,replace (打开日志文件,并更新。
日志文件将记录下所有文件运行后给出的结果,如果你修改了文件内容,replace选项可以将其更新为最近运行的结果。
)use (文件名),clear (打开数据文件。
)(文件内容)log close (关闭日志文件。
)exit,clear (退出并清空内存中的数据。
)假设你清楚地知道所需的变量,现在要做的是检查数据、生成必要的数据并形成数据库供将来使用。
检查数据的重要命令包括codebook,su,ta,des和list。
其中,codebook提供的信息最全面,缺点是不能使用if条件限制范围,所以,有时还要用别的帮帮忙。
su空格加变量名报告相应变量的非缺失的观察个数,均值,标准差,最小值和最大值。
stata时间序列回归步骤命令

stata时间序列回归步骤命令1.引言1.1 概述概述部分的内容:时间序列回归是一种经济学和统计学领域中常用的分析方法,用于研究随时间变化的因果关系。
它涉及使用时间上的观测数据来分析自变量和因变量之间的关系,并预测未来的值。
Stata是一种功能强大的统计软件,广泛用于数据分析和经济研究。
在Stata中,有一系列的命令可供使用,用于进行时间序列回归分析。
本文将介绍使用Stata进行时间序列回归分析的步骤和相应的命令。
通过学习这些命令,读者将能够熟练地使用Stata进行时间序列回归分析,并获得准确和可靠的结果。
本文主要包括以下章节内容:1. 引言部分介绍了时间序列回归的概述、文章结构和目的,旨在帮助读者全面了解本文内容。
2. 正文部分将详细介绍时间序列回归的概念和原理,并介绍Stata中的时间序列回归命令。
这些命令包括数据准备、建立模型、模型估计和统计推断等步骤。
3. 结论部分对本文进行总结,并展望时间序列回归在未来的应用前景。
同时,还会指出时间序列回归分析中可能存在的局限性,以及可能的改进方向。
通过本文的学习,读者将了解时间序列回归分析的基本概念和步骤,掌握对时间序列数据进行回归分析的方法和技巧,并能够运用Stata软件进行实际的分析工作。
1.2文章结构文章结构(Article Structure)本文将按照以下结构进行叙述。
第一部分为引言部分,目的是对时间序列回归步骤命令进行一个概述,并说明本文的目的。
接下来,第二部分将详细介绍时间序列回归的概念和一般步骤,并使用stata命令进行说明。
同时,本文还将重点介绍两个关键要点,这些要点对于正确进行时间序列回归分析非常重要。
最后,第三部分为结论,将总结本文的主要内容,并展望一下未来可能的研究方向。
在正文部分,我们将首先概述时间序列回归的基本概念,并提供了一个对该方法的整体认识。
然后,我们将详细介绍stata时间序列回归步骤命令的使用方法,包括数据导入、变量设定、模型拟合和结果解释等。
stata回归分析完整步骤-吐血推荐

stata回归分析完整步骤——吐血推荐****下载连乘函数prod,方法为:findit dm71sort stkcd date //对公司和日期排序gen r1=1+r //r为实际公司的股票收益率gen r2=1+r_yq //r_yq为公司的预期股票收益率egen r3=prod(r1),by(stkcd date) //求每个公司事件日的累计复合收益率egen r4=prod(r2),by(stkcd date) //求每个公司事件日的累计预期的复合收益率gen r=r4-r3capture clear (清空内存中的数据)capture log close (关闭所有打开的日志文件)set mem 128m (设置用于stata使用的内存容量)set more off (关闭more选项。
如果打开该选项,那么结果分屏输出,即一次只输出一屏结果。
你按空格键后再输出下一屏,直到全部输完。
如果关闭则中间不停,一次全部输出。
)set matsize 4000 (设置矩阵的最大阶数。
我用的是不是太大了?)cd D: (进入数据所在的盘符和文件夹。
和dos的命令行很相似。
)log using (文件名).log,replace (打开日志文件,并更新。
日志文件将记录下所有文件运行后给出的结果,如果你修改了文件内容,replace选项可以将其更新为最近运行的结果。
)use (文件名),clear (打开数据文件。
)(文件内容)log close (关闭日志文件。
)exit,clear (退出并清空内存中的数据。
)假设你清楚地知道所需的变量,现在要做的是检查数据、生成必要的数据并形成数据库供将来使用。
检查数据的重要命令包括codebook,su,ta,des和list。
其中,codebook提供的信息最全面,缺点是不能使用if条件限制范围,所以,有时还要用别的帮帮忙。
su空格加变量名报告相应变量的非缺失的观察个数,均值,标准差,最小值和最大值。
5分钟速学stata面板数据回归初学者超实用!
5分钟速学stata面板数据回归初学者超实用!5 分钟速学 Stata 面板数据回归初学者超实用!在当今的数据分析领域,Stata 软件因其强大的功能和易用性而备受青睐。
对于初学者来说,掌握 Stata 面板数据回归是一项具有挑战性但又十分有用的技能。
在接下来的 5 分钟里,让我们一起快速了解一下Stata 面板数据回归的基础知识和实用技巧。
一、什么是面板数据面板数据(Panel Data)是指在不同时间点上对多个个体进行观测所得到的数据集合。
与横截面数据(只在一个时间点上对多个个体进行观测)和时间序列数据(只对一个个体在不同时间点上进行观测)相比,面板数据结合了两者的特点,能够提供更丰富的信息和更有效的估计。
想象一下,我们要研究不同公司在多年间的销售额变化情况。
如果我们只有某一年各个公司的销售额数据,那就是横截面数据;如果我们只有一家公司多年的销售额数据,那就是时间序列数据;而如果我们有多家公司多年的销售额数据,那这就是面板数据。
二、为什么要使用面板数据回归面板数据回归有许多优点。
首先,它可以控制个体之间未观测到的异质性。
例如,不同公司可能具有不同的管理水平、企业文化等,这些因素很难直接测量,但在面板数据中可以通过个体固定效应或随机效应来控制。
其次,面板数据通常包含更多的信息和变化,有助于提高估计的准确性和效率。
此外,面板数据还可以用于分析动态关系,例如研究过去的投资如何影响当前的产出。
三、Stata 中面板数据的基本命令在 Stata 中,处理面板数据首先要告诉软件数据的结构。
我们使用`xtset` 命令来完成这个任务。
假设我们的数据中,个体变量是`company` ,时间变量是`year` ,那么命令就是:```stataxtset company year```接下来,我们可以进行面板数据回归。
常见的模型有固定效应模型(Fixed Effects Model)和随机效应模型(Random Effects Model)。
stata截面数据回归步骤
stata截面数据回归步骤Stata截面数据回归步骤引言:截面数据回归是经济学和社会科学研究中常用的分析方法之一。
Stata是一种流行的统计软件,广泛应用于截面数据回归分析。
本文将介绍使用Stata进行截面数据回归的步骤和注意事项。
一、导入数据在使用Stata进行截面数据回归之前,首先需要将数据导入到Stata 中。
可以使用Stata的import命令将数据从外部文件导入到Stata 中,常见的外部文件格式包括Excel、CSV等。
导入数据后,可以使用describe命令查看数据的基本信息,包括变量的名称、类型、标签等。
二、数据清洗在进行截面数据回归之前,需要对数据进行清洗。
数据清洗的目的是发现并处理数据中的异常值、缺失值等问题,以及进行变量的转换和衍生变量的构建。
Stata提供了一系列数据清洗的命令,如drop、replace、gen等。
在使用这些命令时,需要注意保留原始数据的备份,以防误操作。
三、描述性统计分析在进行截面数据回归之前,可以先对数据进行描述性统计分析,以了解数据的基本特征。
Stata提供了一系列描述性统计命令,如summarize、tabulate等。
这些命令可以计算变量的均值、标准差、最小值、最大值等统计量,以及绘制直方图、柱状图等图表。
四、回归模型设定在进行截面数据回归之前,需要设定回归模型。
回归模型包括因变量和自变量。
在Stata中,可以使用regress命令进行回归分析。
regress命令的基本语法是:regress 因变量自变量1 自变量2 ...。
在设定回归模型时,需要考虑自变量的选择和变量之间的关系。
五、回归结果解读在进行截面数据回归之后,需要解读回归结果。
Stata提供了一系列回归结果解读的命令,如estat命令。
estat命令可以计算回归结果的置信区间、显著性水平等统计量。
此外,还可以通过绘制残差图、拟合曲线等图表来评估回归模型的拟合效果。
六、回归诊断在进行截面数据回归之后,需要对回归模型进行诊断。
Stata软件之回归分析
0
10
20
30
5
10 years of education Fitted values
15
20
hourly wage
三、简单回归分析的Stata软件操作实例
7、wage对edu的OLS回归,只使用年龄小于或等于30岁的样 本。命令如下: reg wage edu if age<=30 得到以下运行结果,保存该运行结果;
Variable age edu exp expsq wage lnwage Obs 1225 1225 1225 1225 1225 1225 Mean 36.79755 8.992653 21.8049 613.9776 7.1255 1.808352 Std. Dev. 10.67631 2.719068 11.77443 548.3072 4.766828 .5307399 Min 16 0 0 0 1.25 .2231435 Max 60 19 50 2500 37.5 3.624341
计量经济软件应用
——Stata软件实验之一元、 多元回归分析
内容概要
一、实验目的 二、简单回归分析的Stata基本命令 三、简单回归分析的Stata软件操作实例 四、多元回归分析的Stata基本命令 五、多元回归分析的Stata软件操作实例
一、实验目的:
掌握运用Stata软件进行简单回归分析以及 多元回归分析的操作方法和步骤,并能看懂 Stata软件运行结果。
三、简单回归分析的Stata软件操作实例
1、打开数据文件。直接双击“工资方程1.dta”文件;或者点 击Stata窗口工具栏最左侧的Open键,然后选择“工资方程 1.dta”即可;或者先复制Excel表S-2中的数据,再点击Stata 窗口工具栏右起第4个Data Editor键,将数据粘贴到打开的 数据编辑窗口中,然后关闭该数据编辑窗口,点击工具栏左 起第二个Save键保存数据,保存时需要给数据文件命名。 2、给出数据的简要描述。使用describe命令,简写为: des 得到以下运行结果;
stata回归分析完整步骤-吐血推荐-推荐下载
stata回归分析完整步骤——吐血推荐****下载连乘函数prod,方法为:findit dm71sort stkcd date //对公司和日期排序gen r1=1+r //r为实际公司的股票收益率gen r2=1+r_yq //r_yq为公司的预期股票收益率egen r3=prod(r1),by(stkcd date) //求每个公司事件日的累计复合收益率egen r4=prod(r2),by(stkcd date) //求每个公司事件日的累计预期的复合收益率gen r=r4-r3capture clear (清空内存中的数据)capture log close (关闭所有打开的日志文件)set mem 128m (设置用于stata使用的内存容量)set more off (关闭more选项。
如果打开该选项,那么结果分屏输出,即一次只输出一屏结果。
你按空格键后再输出下一屏,直到全部输完。
如果关闭则中间不停,一次全部输出。
)set matsize 4000 (设置矩阵的最大阶数。
我用的是不是太大了?)cd D: (进入数据所在的盘符和文件夹。
和dos的命令行很相似。
)log using (文件名).log,replace (打开日志文件,并更新。
日志文件将记录下所有文件运行后给出的结果,如果你修改了文件内容,replace选项可以将其更新为最近运行的结果。
)use (文件名),clear (打开数据文件。
)(文件内容)log close (关闭日志文件。
)exit,clear (退出并清空内存中的数据。
)假设你清楚地知道所需的变量,现在要做的是检查数据、生成必要的数据并形成数据库供将来使用。
检查数据的重要命令包括codebook,su,ta,des和list。
其中,codebook提供的信息最全面,缺点是不能使用if条件限制范围,所以,有时还要用别的帮帮忙。
su 空格加变量名报告相应变量的非缺失的观察个数,均值,标准差,最小值和最大值。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
stata回归分析完整步骤——吐血推荐****下载连乘函数prod,方法为:findit dm71sort stkcd date //对公司和日期排序gen r1=1+r //r为实际公司的股票收益率gen r2=1+r_yq //r_yq为公司的预期股票收益率egen r3=prod(r1),by(stkcd date) //求每个公司事件日的累计复合收益率egen r4=prod(r2),by(stkcd date) //求每个公司事件日的累计预期的复合收益率gen r=r4-r3capture clear (清空内存中的数据)capture log close (关闭所有打开的日志文件)set mem 128m (设置用于stata使用的内存容量)set more off (关闭more选项。
如果打开该选项,那么结果分屏输出,即一次只输出一屏结果。
你按空格键后再输出下一屏,直到全部输完。
如果关闭则中间不停,一次全部输出。
)set matsize 4000 (设置矩阵的最大阶数。
我用的是不是太大了?)cd D: (进入数据所在的盘符和文件夹。
和dos的命令行很相似。
)log using (文件名).log,replace (打开日志文件,并更新。
日志文件将记录下所有文件运行后给出的结果,如果你修改了文件内容,replace选项可以将其更新为最近运行的结果。
)use (文件名),clear (打开数据文件。
)(文件内容)log close (关闭日志文件。
)exit,clear (退出并清空内存中的数据。
)假设你清楚地知道所需的变量,现在要做的是检查数据、生成必要的数据并形成数据库供将来使用。
检查数据的重要命令包括codebook,su,ta,des和list。
其中,codebook提供的信息最全面,缺点是不能使用if条件限制范围,所以,有时还要用别的帮帮忙。
su空格加变量名报告相应变量的非缺失的观察个数,均值,标准差,最小值和最大值。
ta空格后面加一个(或两个)变量名是报告某个变量(或两个变量二维)的取值(不含缺失值)的频数,比率和按大小排列的累积比率。
des后面可以加任意个变量名,只要数据中有。
它报告变量的存储的类型,显示的格式和标签。
标签中一般记录这个变量的定义和单位。
list报告变量的观察值,可以用if或in来限制范围。
所有这些命令都可以后面不加任何变量名,报告的结果是正在使用的数据库中的所有变量的相应信息。
说起来苍白无力,打开stata 亲自实验一下吧。
顺带说点儿题外话。
除了codebook之外,上述统计类的命令都属于r族命令(又称一般命令)。
执行后都可以使用return list报告储存在r()中的统计结果。
最典型的r族命令当属summarize。
它会把样本量、均值、标准差、方差、最小值、最大值、总和等统计信息储存起来。
你在执行su之后,只需敲入return list就可以得到所有这些信息。
其实,和一般命令的return命令类似,估计命令(又称e族命令)也有ereturn命令,具有报告,储存信息的功能。
在更复杂的编程中,比如对回归分解,计算一些程序中无法直接计算的统计量,这些功能更是必不可少。
检查数据时,先用codebook看一下它的值域和单位。
如果有-9,-99这样的取值,查一下问卷中对缺失值的记录方法。
确定它们是缺失值后,改为用点记录。
命令是replace (变量名)=. if (变量名)==-9。
再看一下用点记录的缺失值有多少,作为选用变量的一个依据。
得到可用的数据后,我会给没有标签的变量加上注解。
或者统一标签;或者统一变量的命名规则。
更改变量名的命令是ren (原变量名)空格(新变量名)。
定义标签的命令是labe l var (变量名)空格”(标签内容)”。
整齐划一的变量名有助于记忆,简明的标签有助于明确变量的单位等信息。
如果你需要使用通过原始变量派生出的新变量,那么就需要了解gen,egen和replace这三个命令。
gen和replace常常在一起使用。
它们的基本语法是gen (或replace)空格(变量名)=(表达式)。
二者的不同之处在于gen是生成新变量,replace是重新定义旧变量。
虚拟变量是我们常常需要用到的一类派生变量。
如果你需要生成的虚拟变量个数不多,可以有两种方法生成。
一种是简明方法:gen空格(变量名)=((限制条件))[这外面的小括弧是命令需要的,里面的小括弧不是命令需要的,只是说明“限制条件”并非命令]。
如果某个观察满足限制条件,那么它的这个虚拟变量取值为1,否则为0。
另一种要麻烦一点。
就是gen (变量名)=1 if (取值为一限制条件)replace(相同的变量名)=0 if (取值为零的限制条件)两个方法貌似一样,但有一个小小的区别。
如果限制条件中使用的变量都没有任何缺失值,那么两种方法的结果一样。
如果有缺失值,第一种方法会把是缺失值的观察的虚拟变量都定义为0。
而第二种方法可以将虚拟变量的取值分为三种,一是等于1,二是等于0,三是等于缺失值。
这样就避免了把本来信息不明的观察错误地纳入到回归中去。
下次再讲如何方便地生成成百上千个虚拟变量。
大量的虚拟变量往往是根据某个已知变量的取值生成的。
比如,在某个回归中希望控制每个观察所在的社区,即希望控制标记社区的虚拟变量。
社区数目可能有成百上千个,如果用上次的所说的方法生成就需要重复成百上千次,这也太笨了。
大量生成虚拟变量的命令如下;ta (变量名), gen((变量名))第一个括号里的变量名是已知的变量,在上面的例子中是社区编码。
后一个括号里的变量名是新生成的虚拟变量的共同前缀,后面跟数字表示不同的虚拟变量。
如果我在这里填入d,那么,上述命令就会新生成d1,d2,等等,直到所有社区都有一个虚拟变量。
在回归中控制社区变量,只需简单地放入这些变量即可。
一个麻烦是虚拟变量太多,怎么简单地加入呢?一个办法是用省略符号,d*表示所有d字母开头的变量,另一法是用破折号,d1-d150表示第一个到第150个社区虚拟变量(假设共有150个社区)。
还有一种方法可以在回归中直接控制虚拟变量,而无需真的去生成这些虚拟变量。
使用命令areg可以做到,它的语法是areg (被解释变量)(解释变量), absorb(变量名)absorb选项后面的变量名和前面讲的命令中第一个变量名相同。
在上面的例子中即为社区编码。
回归的结果和在reg中直接加入相应的虚拟变量相同。
生成变量的最后一招是egen。
egen和gen都用于生成新变量,但egen的特点是它更强大的函数功能。
gen可以支持一些函数,egen支持额外的函数。
如果用gen搞不定,就得用ege n想办法了。
不过我比较懒,到现在为止只用用取平均、加和这些简单的函数。
有的时候数据情况复杂一些,往往生成所需变量不是非常直接,就需要多几个过程。
曾经碰到原始数据中记录日期有些怪异的格式。
比如,1991年10月23日被记录为19911023。
我想使用它年份和月份,并生成虚拟变量。
下面是我的做法:gen yr=int(date)gen mo=int((data-yr*10000)/100)ta yr, gen( yd)ta mo, gen( md)假设你已经生成了所有需要的变量,现在最重要的就是保存好你的工作。
使用的命令是sav e空格(文件名),replace。
和前面介绍的一样,replace选项将更新你对数据库的修改,所以一定要小心使用。
最好另存一个新的数据库,如果把原始库改了又变不回去,就叫天不应叫地不灵了。
前面说的都是对单个数据库的简单操作,但有时我们需要改变数据的结构,或者抽取来自不同数据库的信息,因此需要更方便的命令。
这一类命令中我用过的有:改变数据的纵横结构的命令reshape,生成退化的数据库collapse,合并数据库的命令append和merge。
纵列(longitudinal)数据通常包括同一个行为者(agent)在不同时期的观察,所以处理这类数据常常需要把数据库从宽表变成长表,或者相反。
所谓宽表是以每个行为者为一个观察,不同时期的变量都记录在这个观察下,例如,行为者是厂商,时期有2000、2019年,变量是雇佣人数和所在城市,假设雇佣人数在不同时期不同,所在城市则不变。
宽表记录的格式是每个厂商是一个观察,没有时期变量,雇佣人数有两个变量,分别记录2000年和20 19年的人数,所在城市只有一个变量。
所谓长表是行为者和时期共同定义观察,在上面的例子中,每个厂商有两个观察,有时期变量,雇佣人数和所在城市都只有一个,它们和时期变量共同定义相应时期的变量取值。
在上面的例子下,把宽表变成长表的命令格式如下:reshape long (雇佣人数的变量名), i((标记厂商的变量名)) j((标记时期的变量名))因为所在城市不随时期变化,所以在转换格式时不用放在reshapelong后面,转换前后也不改变什么。
相反地,如果把长表变成宽表则使用如下命令reshape wide (雇佣人数的变量名), i((标记厂商的变量名)) j((标记时期的变量名)) 唯一的区别是long换成了wide。
collapse的用处是计算某个数据库的一些统计量,再把它存为只含有这些统计量的数据库。
用到这个命令的机会不多,我使用它是因为它可以计算中位数和从1到99的百分位数,这些统计量在常规的数据描述命令中没有。
如果要计算中位数,其命令的语法如下collapse (median) ((变量名)), by((变量名))生成的新数据库中记录了第一个括号中的变量(可以是多个变量)的中位数。
右面的by选项是根据某个变量分组计算中位数,没有这个选项则计算全部样本的中位数。
合并数据库有两种方式,一种是增加观察,另一种是增加变量。
第一种用append,用在两个数据库的格式一样,但观察不一样,只需用append空格using空格(文件名)就可以狗尾续貂了。
简单明了,不会有什么错。
另一种就不同了,需要格外小心。
如果两个数据库中包含共同的观察,但是变量不同,希望从一个数据库中提取一些变量到另一个数据库中用m erge。
完整的命令如下:use(文件名)[打开辅助数据库]sort (变量名)[根据变量排序,这个变量是两个数据库共有的识别信息]save (文件名),replace[保存辅助数据库]use(文件名)[打开主数据库]sort (变量名)[对相同的变量排序]merge (变量名) using (文件名), keep((变量名))[第一个变量名即为前面sort后面的变量名,文件名是辅助数据库的名字,后面的变量名是希望提取的变量名]ta[显示_merge的取值情况。
_merge等于1的观察是仅主库有的,等于2的是仅辅助库有的,等于3是两个库都有的。