spss中分类汇总教程
Spss软件常用菜单含义与功能介绍
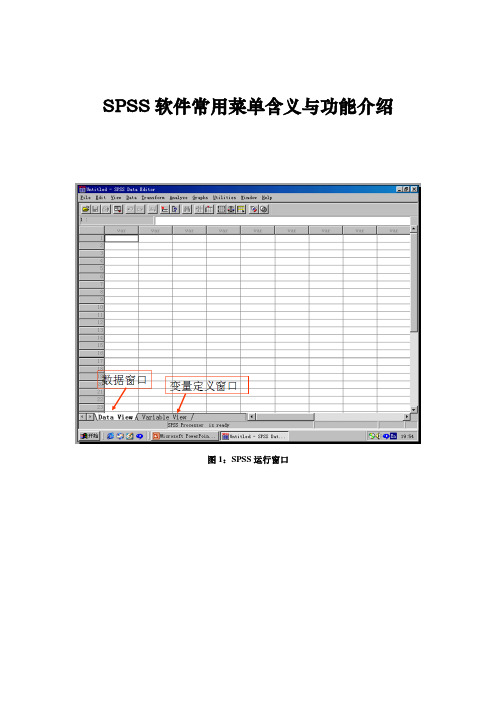
SPSS软件常用菜单含义与功能介绍图1:SPSS运行窗口1、计算产生变量根据已经存在的变量,经过函数计算后,建立新变量或替换员原量的值。
图2:计算产生变量图3:分类汇总1、描述性统计(1)频数分布分析:通过频数分布表、直方图,以及集中趋势和离散趋势的各种统计量,描述数据的分布特征。
(2)描述性统计分析:计算描述数据的集中趋势和离散趋势的各种统计量,还可以做标准化变换(变成均值为0,方差为1的数据)。
(3)探索性分析:判断数据有无离群点(outliers),极端值(extreme values);进行正态分布检验和方差齐性检验;了解数据指标之间差异的特征。
(1)双变量相关分析:分析两个变量之间是否存在相关关系。
(2)偏相关分析:剔除其他变量的影响的情况下,计算两变量之间的相关系数。
3、聚类分析与判别分析(1)系统聚类:最常用的聚类方法。
(2)判别分析:判别所研究的对象属于哪一类的统计方法。
(1)线性回归:一个因变量(dependent )与多个自变量(independents )之间存在线性数量关系。
(2)曲线拟合:可以完成11种曲线的自动拟合(根据需要进行选择),并进行参数估计与检验,绘制拟合图形等。
自变量(independent )只能选一个或者使用时间作为自变量(time: 即使用1,2,3,…,),即只能做一元函数的曲线拟合。
因变量(dependent )可以选多个,将分别做多个一元函数的拟合。
模型Models 模型名称 模型表达式Linear 线性模型 01*y b b x =+ Logarithmic对数模型01*ln y b b x =+Inverse 逆模型 01/y b b x =+ Quadratic 二次模型 2012**y b b x b x =++ Cubic 三次模型 230123***y b b x b x b x =+++Compound 复合模型 01*x y b b =Power 幂模型 10*b y b x = S S 型模型 01/b b x y e +=Growth 生长模型 01*b b x y e += Exponential 指数模型 1*0*b x y b e =LogisticLogistic 模型011/(1)b b x y e --=+一般可以先选择所有的11种模型,再根据结果选择最佳模型。
使用SPSSSPSS中文版统计软件的统计分析操作方法

使用SPSSSPSS中文版统计软件的统计分析操作方法SPSS(Statistical Package for the Social Sciences)是一种用于统计分析的软件工具,它可以帮助研究人员对数据进行处理、分析和解释。
下面将介绍SPSS中文版统计软件的常见统计分析操作方法。
一、数据导入和预处理1. 启动SPSS软件后,在主界面选择"文件"->"打开"->"数据",然后选择要导入的数据文件,如Excel或CSV格式文件。
2.在数据导入对话框中,选择正确的数据类型和分隔符,并指定变量名和数据属性。
3.完成数据导入后,可以对数据进行预处理操作,如数据清洗、变量选择、数据转换等。
二、描述统计分析1.在数据导入后,在主界面选择"统计"->"描述性统计"->"频数",然后选择要进行频数分析的变量。
2.设置所需的统计量和显示选项,如均值、标准差、最小值、最大值等,并生成描述统计表。
三、数据可视化1.在主界面选择"图表"->"柱形图",然后选择要进行柱形图分析的变量。
2.设置柱形图的样式、颜色和标题等,并生成柱形图。
3.可以根据需要选择其他类型的统计图表,如折线图、散点图、饼图等,以进行数据可视化展示。
四、假设检验1.在主界面选择"分析"->"描述统计"->"交叉表",然后选择要进行交叉表分析的变量。
2.设置所需的交叉表分析选项,如分组变量、交叉分类表等,并生成交叉表。
3.可以根据需要进行卡方检验、t检验、方差分析等假设检验方法来比较两个或多个变量之间的差异。
五、回归分析1.在主界面选择"回归"->"线性",然后选择要进行回归分析的因变量和自变量。
spss第四章数据文件的操作与变换

2.选择对观测量作加权处理的方式。
.请勿对个案加权:对数据文件不作加权处理。这是系统默认状 态。
.加权个案:选择此项表示要求作加权处理。
3.当在上一步中选择了“加权个案〞选项后。从左边源变量列表框 中选择一个作为权变量的变量名,单击向右箭头按钮,送入“频率 变量〞下面的矩形框中。在此我们选择变量名“频数〞作为加权变 量。
9、平滑
4.14 替换缺失值
在分析带有缺失值的观测数据时,通常将带有缺失值的 观测量排除在分析数据范围之外,但在进展时间系列的统 计分析时,不能将带有缺失值的观测量排除在外.此时可用 替换缺失值的方法进展处理.其操作步骤如下:
替换缺失值的方法:
1、序列平均值: 用整列变量值的均值替代缺失值。如果变量值中 含有多个缺失值,那么它们都将由同一个值替换。(e414-1)
其操作步骤如下:
1. 在主菜单中单击T“转换〞,展开下拉菜单,从下拉菜单中选择“对个案 内的值计数〞 。
2. 执行“对个案内的值计数〞操作后,观测量中特定变量值出现的次数,将通 过创立一个新的变量〔称为目标变量)来保存及显示。
3.在主对话框左边的源变量列表框中选择要进展计数的变量名〔中国青 年〕,单击向一右箭头按钮,将它送入 “变量〞下方的矩形框中。
第四章 数据文件操作与变换
4·1 定义时间系列日期型变量
数据→定义日期
说明:
1、执行后,在数据窗口中为每个时间单位对应 一个新的数值变量,变量名后带 “_〞,如 YEAR_ , DAY_ , MONTH_ 等。最后还附加了一个 具有描述意义的字符变量DATE_。
2、如果在这之前已经定义了一组时间系列变量, 那么新建立的变量将全部替代原有的时间系列。
SPSS操作实验手册

SPSS试验操作指导手册(2023版)2.SPSS数据整顿2.1 SPSS数据文献旳建立SPSS数据文献旳建立可以运用【File(文献)】菜单中旳命令来实现。
详细来说, SPSS提供了四种创立数据文献旳措施:●新建数据文献【File(文献)】→【New(新建)】→【Data(数据)】命令;●直接打开已经有数据文献【File(文献)】→【Open (打开)】→【Data(数据)】命令;●使用数据库查询;【File(文献)】→【Open Database(打开数据库)】→【New Query(新建查询)】命令, 弹出【Database Wizard(数据库向导)】对话框●从文本向导导入数据文献。
【File(文献)】→【Read Text Data(打开文本数据)】命令, 弹出【Open Data(打开数据)】对话框实例分析: 股票指数旳导入文献2-1.xls是上证指数从2023年1月4日至2023年10月16 日旳数据资料, 包括了开盘价、当日最高价、当日最低价和收盘价等选项, 请将该数据导入至SPSS中。
2.2 SPSS数据文献旳属性一种完整旳SPSS文献构造包括变量名称、变量类型、变量名标签、变量值标签等内容。
注意: SPSS数据文献中旳一列数据称为一种变量, 每个变量都应有一种变量名。
SPSS数据文献中旳一行数据称为一条个案或观测量(Case)2.2.1 实例分析: 员工满意度调查表旳数据属性设计1.实例内容为了提高员工旳工作积极性, 完善企业各方面管理制度, 并到达有旳放矢旳目旳, 某企业决定对我司员工进行不记名调查, 但愿理解员工对企业旳满意状况。
请根据该企业设计旳员工满意度调查题目(行政人事管理部分)旳特点, 设计该调查表数据在SPSS旳数据属性。
2.实例操作详细环节如下文献(2-2.sav.)Step01: 打开SPSS中旳Data View窗口, 录入或导入原始调查数据。
Step02:选择菜单栏中旳【File(文献)】→【Save (保留)】命令, 保留数据文献, 以免丢失。
SPSS数据分析7

SPSS数据分析7SPSS数据分析7SPSS是一款功能强大的统计软件,可以用于数据的清洗、整理、分析和可视化。
在进行SPSS数据分析时,一般需要经过以下步骤:数据导入、数据清洗、数据整理、数据分析和结果解读。
下面将逐步介绍这些步骤。
首先,将数据导入SPSS软件中。
SPSS支持多种数据格式,如Excel、CSV等。
打开SPSS软件后,点击菜单栏的“File”选项,选择“Open”,导入数据文件。
接下来,进行数据整理。
数据整理主要包括数据排序、合并和拆分等操作。
在菜单栏上选择“Data”选项,然后选择“Sort Cases”可以对数据进行排序。
在“Sort Cases”对话框中,我们可以选择按照一些或多个变量进行排序。
此外,我们还可以使用“Data”选项下的“Merge Files”进行数据的合并,使用“Split File”进行数据的拆分,具体操作根据实际需求进行选择。
然后,进行数据分析。
SPSS提供了丰富的统计方法和分析工具,可以根据不同的研究目的和数据类型进行选择。
常见的数据分析方法包括描述统计分析、相关分析、方差分析、回归分析、因子分析等。
点击菜单栏上的“Analyze”选项,可以选择相应的分析方法和工具,并设置相应的参数。
在设置参数时,需要注意选择适当的检验方法和统计指标。
最后,进行结果解读。
通过SPSS进行数据分析后,会得到相应的结果报告和图表。
在结果解读时,需要结合具体的研究问题和数据分析方法来进行解读。
要注意关注显著性水平、效应大小和置信区间等指标,判断结果的可靠性和实际意义。
此外,还可以使用SPSS提供的图表和可视化工具来展示数据分析的结果,更直观地呈现研究的结论。
综上所述,SPSS数据分析主要包括数据导入、数据清洗、数据整理、数据分析和结果解读等步骤。
通过SPSS软件的功能和工具,可以实现对数据的全面分析和解读,为研究者提供科学的数据支持,帮助做出准确的决策和结论。
分类汇总使用方法

分类汇总使用方法一、数据清洗在进行分类汇总之前,需要对数据进行清洗和预处理,以保证数据的准确性和一致性。
数据清洗主要包括以下几个方面:1.缺失值处理:检查数据中的缺失值,并选择合适的处理方法,如填充缺失值或删除含有缺失值的记录。
2.异常值处理:识别数据中的异常值,并采取相应的处理方法,如将异常值替换为合理值或删除含有异常值的记录。
3.特征工程:通过特征选择、特征构造等方法,对数据进行变换和增强,以提高分类汇总的效果。
二、特征选择在进行分类汇总时,需要选择与目标变量相关的特征,以提取分类所需的特征信息。
特征选择的方法包括:1.基于统计的特征选择:根据特征与目标变量之间的相关性、方差等统计指标,选择最重要的特征。
2.基于模型的特征选择:通过训练分类模型,并根据模型的特征权重或特征贡献度来选择最重要的特征。
3.集成方法特征选择:将多个特征选择方法结合使用,以提高特征选择的准确性和稳定性。
三、分类方法选择根据数据的特点和分类任务的要求,选择合适的分类方法。
常见的分类方法包括:1.决策树分类:通过构建决策树来对数据进行分类。
2.朴素贝叶斯分类:基于贝叶斯定理和特征之间独立假设的分类方法。
3.支持向量机分类:在数据空间中找到一个超平面,将不同类别的数据分隔开。
4.神经网络分类:通过训练神经网络来对数据进行分类。
5.集成方法分类:将多个分类方法结合使用,以提高分类的准确性和稳定性。
四、训练模型根据选择的分类方法,使用训练数据集对模型进行训练。
在训练过程中,需要对模型进行参数调整和优化,以提高模型的准确性和稳定性。
同时,需要注意防止过拟合和欠拟合问题。
五、评估模型使用测试数据集对训练好的模型进行评估,以检验模型的分类性能。
评估指标包括准确率、精度、召回率、F1值等。
通过对模型的评估结果进行分析,可以发现模型存在的问题和改进的方向。
六、部署应用将训练好的模型部署到实际应用中,用于对新的数据进行分类预测。
在部署过程中,需要考虑模型的实时性、可扩展性和安全性等方面的问题。
SPSS数据录入(一)

精选课件
14
录入数据的第一步是定义变量属性,随后才能进行 数据录入。
(一)单选题的录入 单选题的录入可以采用字符直接录入、字符代码+值 标签、数值代码+值标签三种方式。
精选课件
15
(二)多选题的录入
1.多重二分法(Multiple Dichotomy Method) 所谓多重二分法,是在编码的时候,对应每一个选项都要定义
一、常用基本概念 (1)spss算术表达式 spss算术表达式是由常量、spss变
量名、spss的算术运算符、圆括号等组成的式子。 (2)spss函数 spss提供了多达70多种函数,分为八大类:
算术函数、统计函数、分布函数、逻辑函数、字符串函数、 日期时间函数、缺失值函数和其它函数。 (3)spss条件表达式 通过spss的算术表达式和函数可以对 所有记录计算一个结果,如果仅希望对部分记录进行计算, 则应当利用spss的条件表达式指定对那些记录进行计算。
精选课件
5
1.1 数据格式概述
1.1.1 统计软件中数据的录入格式 (1)不同观测对象的数据不能在同一记录中出现,即同一
观测数据应当独占一行。 (2)每一个观测量指标或影响因素只能占据一列的位置,
即同一指标的数量观测值都应当录入到同一个变量中去。
即:一个观测占一行,一个变量占一列
精选课件
6
1.1.2 变量属性介绍
一个变量,有几个选项就有几个变量,这些变量均为二分类, 他们各自代表对一个选项的选择结果。P16 H3b 2.多重分类法(Multiple Category Method) 多重分类法,也是利用多个变量对一个多选题的答案进行定义, 应该用多少个变量,由被访者实际可能给出的最多答案数而 定。P16 H4
《用SPSS作聚类分析》课件

《用SPSS作聚类分析》 PPT课件
欢迎来到《用SPSS作聚类、SPSS的应用以及结果分析。让我们一起开始这个有趣而有深度的数据 挖掘之旅吧!
什么是聚类分析?
聚类分析是一种数据分析方法,将相似的事物归类到同一组,帮助我们找到 数据中的规律和模式。
SPSS聚类分析的基本步骤
1
数据准备
选取要分析的数据并进行预处理,
聚类方法选择
2
如缺失值填充。
根据需求选择合适的聚类方法,如
层次聚类、K-Means聚类或模糊聚 类。
3
变量选择
选择对聚类分析有影响的变量并进
行预处理。
聚类分析运行
4
对选取的变量运行聚类分析,并选
择最优的聚类数。
5
结果分析
分析聚类结果,命名聚类结果,并 可视化展示。
为什么要进行聚类分析?
聚类分析能够帮助我们发现数据中隐藏的规律和模式,为决策提供科学依据,优化业务流程,提 高效率。
参考文献
贺志鹏. 数据挖掘与SPSS实战[M].
清华大学出版社, 2009.
Mirkin B. Clustering: A Data Recovery Approach[M].
CRC Press, 1996.
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
spss教程:分类汇总
按照某种分类变量进行分类计算,对原始数据分类,做出表格形式,便于直观地观察数据大致分布情况。
方法/步骤
1.调出相关窗口,分类变量是“户口状况”,汇总变量为“人均面积”、“计划
面积”。
分类变量可以多个,称为“多重分类汇总”,第一个分类变量称为“主分类变量”,依次称为“第二、第三分类变量”。
2.按钮“函数”表示计算哪些汇总变量,系统默认均值,用户可自己定义。
3.“变量名与标签”:重新命名汇总结果中的变量名和标签,系统有默认的命名,
见图片。
“保存”:将最后的汇总结果保存在何处。
我此处选择的是第二种,即“将汇总结果保存在一个数据编辑窗口中”。
“个案数”:保存各分类组的个案数,系统默认变量名“N_BREAK”。
4.选择第二种保存方式,结果展示见图片。
“个案数”分别是2825、168。
对
于系统缺失值,spss自动剔除含缺失值的样本,所以平均值的计算不受缺失样本量的影响。
END
经验内容仅供参考,如果您需解决具体问题(尤其法律、医学等领域),建议您详细咨询相关领域专业人士。