13_尚硅谷大数据之HDFS 2.X新特性
大数据Hadoop入门第七讲 Hadoop2.x HDFS新特性

第七讲 Hadoop2.x HDFS新特性
Hadoop1.x HDFS缺点
HDFS架构在整个集群中允许且仅允许一个单独的命名空间。命名空间被一 个单独的namenode节点所管理。这种架构决策实现简单。但也会产生单点 问题,内存瓶颈,性能瓶颈等限制。虽然Hadoop1中的secondary namenode是作为namenode的备份出现的,但是由于设计问题,无法作为 namenode的热备,解决namenode的问题。
Hadoop2.x Federation(联邦)
目的:水平扩展NameNode服务 使用多个独立的namenode(namespaces)。每个namenode是独立的,
不需要和其它namenode协调合作。datanode作为统一的块存储设备被所 有namenode节点使用。 每一个datanode节点都在所有的namenode进行 注册。 datanode发送心跳信息、块报告到所有namenode,同时执行所有 namenode发来的命令。
减弱NameNode的能力,Hadoop1中NameNode除了管理元数据外,还 需要管理edit log数据;hadoop2中通过引入JournalNode来专门的进行 edit log数据管理操作。Active NameNode负责push日志到JournalNode, Standby NameNode负责pull日志进行内容同步。
缺点:namenode的实效会导致部分数据无法访问,负载均衡很难自动完 成。
Hadoop2.x Block Pool(块池)
目的:解决federation机制中多个namenode带来的块管理问题。 块池是属于单个命名空间的一组块。 每一个datanode为所有的block
hdfs原理、架构与特性介绍

HDFS 原理、架构与特性介绍本文主要讲述HDFS原理-架构、副本机制、HDFS负载均衡、机架感知、健壮性、文件删除恢复机制1:当前HDFS架构详尽分析HDFS架构·NameNode·DataNode·Sencondary NameNode数据存储细节NameNode 目录结构Namenode 的目录结构:${ .dir}/current /VERSION/edits/fsimage/fstime.dir 是hdfs-site.xml 里配置的若干个目录组成的列表。
NameNodeNamenode 上保存着HDFS 的名字空间。
对于任何对文件系统元数据产生修改的操作,Namenode 都会使用一种称为EditLog 的事务日志记录下来。
例如,在HDFS 中创建一个文件,Namenode 就会在Editlog 中插入一条记录来表示;同样地,修改文件的副本系数也将往Editlog 插入一条记录。
Namenode 在本地操作系统的文件系统中存储这个Editlog 。
整个文件系统的名字空间,包括数据块到文件的映射、文件的属性等,都存储在一个称为FsImage 的文件中,这个文件也是放在Namenode 所在的本地文件系统上。
Namenode 在内存中保存着整个文件系统的名字空间和文件数据块映射(Blockmap) 的映像。
这个关键的元数据结构设计得很紧凑,因而一个有4G 内存的Namenode 足够支撑大量的文件和目录。
当Namenode 启动时,它从硬盘中读取Editlog 和FsImage ,将所有Editlog 中的事务作用在内存中的FsImage 上,并将这个新版本的FsImage 从内存中保存到本地磁盘上,然后删除旧的Editlog ,因为这个旧的Editlog 的事务都已经作用在FsImage 上了。
这个过程称为一个检查点(checkpoint) 。
在当前实现中,检查点只发生在Namenode 启动时,在不久的将来将实现支持周期性的检查点。
Hadoop1.x与Hadoop2.x的区别
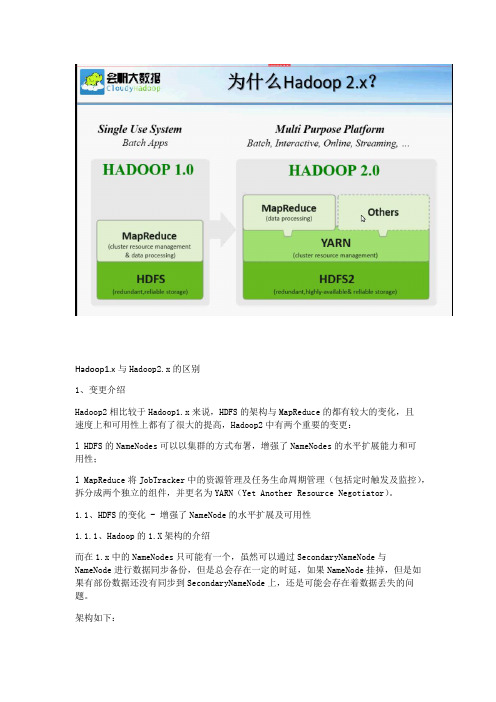
Hadoop1.x与Hadoop2.x的区别1、变更介绍Hadoop2相比较于Hadoop1.x来说,HDFS的架构与MapReduce的都有较大的变化,且速度上和可用性上都有了很大的提高,Hadoop2中有两个重要的变更:l HDFS的NameNodes可以以集群的方式布署,增强了NameNodes的水平扩展能力和可用性;l MapReduce将JobTracker中的资源管理及任务生命周期管理(包括定时触发及监控),拆分成两个独立的组件,并更名为YARN(Yet Another Resource Negotiator)。
1.1、HDFS的变化 - 增强了NameNode的水平扩展及可用性1.1.1、Hadoop的1.X架构的介绍而在1.x中的NameNodes只可能有一个,虽然可以通过SecondaryNameNode与NameNode进行数据同步备份,但是总会存在一定的时延,如果NameNode挂掉,但是如果有部份数据还没有同步到SecondaryNameNode上,还是可能会存在着数据丢失的问题。
架构如下:包含两层:Namespacel 包含目录、文件以及块的信息l 支持对Namespace相关文件系统的操作,如增加、删除、修改以及文件和目录的展示Block Storage Service包含两部份l 块管理(在Namenode中实现的)提供数据节点群集成员的登记,并定期通过心跳进行检查。
提供块报告以及块的存储位置的维护提供对块的操作,如对块进行增删改的操作及获取块的存储地址对块的复本的的复制以及存储位置的管理l 存储 - 提供Datanode进行数据的本地存储,并提供读写的操作1.1.1、Hadoop的2.X架构的介绍在2.X中,HDFS的变化,主要体现在增强了NameNode的水平扩展及可用性,可以同时部署多个NameNode,这些NameNodes之间是相互独立,也就是说他们不需要相互协调,DataNode同时在所有NameNodes注册,做为他们共有的存储节点,并向定时向所有的这些NameNodes发送心跳块使用情况的报告,并处理所有NameNodes向其发送的指令。
尚硅谷大数据技术之 Hadoop(生产调优手册)说明书

尚硅谷大数据技术之Hadoop(生产调优手册)(作者:尚硅谷大数据研发部)版本:V3.3第1章HDFS—核心参数1.1 NameNode内存生产配置1)NameNode内存计算每个文件块大概占用150byte,一台服务器128G内存为例,能存储多少文件块呢?128 * 1024 * 1024 * 1024 / 150Byte ≈9.1亿G MB KB Byte2)Hadoop2.x系列,配置NameNode内存NameNode内存默认2000m,如果服务器内存4G,NameNode内存可以配置3g。
在hadoop-env.sh文件中配置如下。
HADOOP_NAMENODE_OPTS=-Xmx3072m3)Hadoop3.x系列,配置NameNode内存(1)hadoop-env.sh中描述Hadoop的内存是动态分配的# The maximum amount of heap to use (Java -Xmx). If no unit # is provided, it will be converted to MB. Daemons will# prefer any Xmx setting in their respective _OPT variable.# There is no default; the JVM will autoscale based upon machine # memory size.# export HADOOP_HEAPSIZE_MAX=# The minimum amount of heap to use (Java -Xms). If no unit # is provided, it will be converted to MB. Daemons will# prefer any Xms setting in their respective _OPT variable.# There is no default; the JVM will autoscale based upon machine # memory size.# export HADOOP_HEAPSIZE_MIN=HADOOP_NAMENODE_OPTS=-Xmx102400m(2)查看NameNode占用内存[atguigu@hadoop102 ~]$ jps3088 NodeManager2611 NameNode3271 JobHistoryServer2744 DataNode3579 Jps[atguigu@hadoop102 ~]$ jmap -heap 2611Heap Configuration:MaxHeapSize = 1031798784 (984.0MB)(3)查看DataNode占用内存[atguigu@hadoop102 ~]$ jmap -heap 2744Heap Configuration:MaxHeapSize = 1031798784 (984.0MB)查看发现hadoop102上的NameNode和DataNode占用内存都是自动分配的,且相等。
hdfs基本知识的总结

hdfs基本知识的总结
HDFS是一种分布式文件系统,它可以在大规模的集群中存储和管理大文件。
以下是HDFS基本知识的总结:
1. HDFS的工作原理:HDFS将大文件分成多个块,并存储在不同的节点上,这些节点组成了一个集群。
HDFS使用主节点和工作节点协同工作,主节点负责管理文件系统的命名空间和块的复制,而工作节点负责存储和管理数据块。
2. HDFS的文件访问方式:HDFS支持顺序读写和随机读写。
顺序读写是指一次读或写整个文件,而随机读写是指读或写文件的特定区域。
3. HDFS的块大小:HDFS的块大小通常为128MB,这是因为HDFS 旨在处理大文件,而较大的块大小可以提高文件的处理效率。
4. HDFS的数据复制:HDFS将数据块复制到不同的节点上,以实现数据的冗余备份和高可用性。
默认情况下,HDFS会将每个数据块复制到3个节点上。
5. HDFS的目录结构:HDFS的目录结构类似于传统文件系统的目录结构,但是在HDFS中,每个目录都可以包含子目录和文件,并且可以通过命名空间进行管理。
6. HDFS的命令行工具:HDFS提供了一些命令行工具,例如hdfs dfs和hadoop fs,可以用于查看和管理HDFS中的文件和目录。
总之,HDFS是一种很有用的分布式文件系统,可以用于存储和管理大规模的数据。
熟悉HDFS的基本知识将有助于更好地使用它。
13_尚硅谷大数据之常见错误及解决方案

第13章常见错误及解决方案1)SecureCRT 7.3出现乱码或者删除不掉数据,免安装版的SecureCRT 卸载或者用虚拟机直接操作或者换安装版的SecureCRT2)连接不上mysql数据库(1)导错驱动包,应该把mysql-connector-java-5.1.27-bin.jar导入/opt/module/hive/lib的不是这个包。
错把mysql-connector-java-5.1.27.tar.gz导入hive/lib包下。
(2)修改user表中的主机名称没有都修改为%,而是修改为localhost3)hive默认的输入格式处理是CombineHiveInputFormat,会对小文件进行合并。
hive (default)> set hive.input.format;hive.input.format=bineHiveInputFormat可以采用HiveInputFormat就会根据分区数输出相应的文件。
hive (default)> set hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;4)不能执行mapreduce程序可能是hadoop的yarn没开启。
5)启动mysql服务时,报MySQL server PID file could not be found! 异常。
在/var/lock/subsys/mysql路径下创建hadoop102.pid,并在文件中添加内容:43966)报service mysql status MySQL is not running, but lock file (/var/lock/subsys/mysql[失败])异常。
解决方案:在/var/lib/mysql 目录下创建:-rw-rw----. 1 mysql mysql 5 12月22 16:41 hadoop102.pid 文件,并修改权限为777。
7_尚硅谷大数据之HDFS概述
一HDFS概述1.1 HDFS产生背景随着数据量越来越大,在一个操作系统管辖的范围内存不下了,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,迫切需要一种系统来管理多台机器上的文件,这就是分布式文件管理系统。
HDFS只是分布式文件管理系统中的一种。
1.2 HDFS概念HDFS,它是一个文件系统,用于存储文件,通过目录树来定位文件;其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色。
HDFS的设计适合一次写入,多次读出的场景,且不支持文件的修改。
适合用来做数据分析,并不适合用来做网盘应用。
1.3 HDFS优缺点1.3.1 优点1)高容错性(1)数据自动保存多个副本。
它通过增加副本的形式,提高容错性;(2)某一个副本丢失以后,它可以自动恢复。
2)适合大数据处理(1)数据规模:能够处理数据规模达到GB、TB、甚至PB级别的数据;(2)文件规模:能够处理百万规模以上的文件数量,数量相当之大。
3)流式数据访问,它能保证数据的一致性。
4)可构建在廉价机器上,通过多副本机制,提高可靠性。
1.3.2 缺点1)不适合低延时数据访问,比如毫秒级的存储数据,是做不到的。
2)无法高效的对大量小文件进行存储。
(1)存储大量小文件的话,它会占用NameNode大量的内存来存储文件、目录和块信息。
这样是不可取的,因为NameNode的内存总是有限的;(2)小文件存储的寻址时间会超过读取时间,它违反了HDFS的设计目标。
3)并发写入、文件随机修改。
(1)一个文件只能有一个写,不允许多个线程同时写;(2)仅支持数据append(追加),不支持文件的随机修改。
1.4 HDFS组成架构HDFS的架构图这种架构主要由四个部分组成,分别为HDFS Client、NameNode、DataNode和Secondary NameNode。
下面我们分别介绍这四个组成部分。
1)Client:就是客户端。
Hadoop2.0x新特性介绍
下一代数据处理框架介绍
主要内容
• Hadoop 1.0 的局限性 • Hadoop 2.0 新特性介绍 • Hadoop现状及最新进展
Hadoop1.0的局限- HDFS
※资源隔离 ※元数据扩展性 ※访问效率
※数据丢失
※单点的问题
Hadoop1.0的局限-MapReduce
Hadoop2.0 新特性: HDFS Snapshots
快照是整个文件系统或文件系统的一个子树在一个时间 点的实时映像,创建速度快、开销小,在一些场景快照具 有非常重要的用途:
– 防止用户错误操作:以滚动的方式建立只读定期快照,如果
用户不小心删除文件,该文件可以从最新的RO快照中恢复
– 数据备份:在某一时间点创建只读快照作为备份,并且可以 以此时间点实现增量数据处理
数,用户程序也可指定每个任务需要的虚拟CPU个数
• 可为每个节点单独配置可用内存,采用线程监控的方案控 制内存使用,发现任务超过约定的资源量会将其杀死 • Mesos等资源管理软件
Hadoop2.0 新特性: YARN上运行的软件
Applications Run Natively In Hadoop
-共享存储fencing,确保只有一个NN可以写入edits -客户端fencing,确保只有一个NN可以响应客户端的请求 - DN fencing,确保只有一个NN可以向DN下发删除等命令
Hadoop2.0 新特性: NameNode Federation
Hadoop 1.0版本容量及性能缺陷:
• NodeManager
– 单个节点上的资源管理 – 处理来自ResourceManager的命令 – 处理来自ApplicationMaster的命令
hdfs特点描述
hdfs特点描述
HDFS,即Hadoop分布式文件系统,是Hadoop核心子项目,为Hadoop提供了一个综合性的文件系统抽象。
它的主要特点和优势包括:
1.高可靠性:HDFS采用了数据冗余和自动故障恢复技术,确保了数据的可靠性。
当节点发生故障时,HDFS可以自动检测并将数据从故障节点重新复制到其他节点。
2.支持海量数据的存储:HDFS设计用于存储超大文件,通常支持TB和PB级别的数据。
3.高扩展性:HDFS支持线性扩展,可以根据需要向集群中添加更多的节点。
4.流式数据访问:HDFS适合处理大规模数据集上的应用,提供高吞吐量的数据访问。
5.放宽POSIX约束:为了实现流式读取文件系统数据的目的,HDFS在某些方面放宽了POSIX约束。
6.低延迟数据访问:HDFS为大数据集提供了低延迟的数据访问。
7.检测和快速应对硬件故障:在集群环境中,硬件故障是常见性问题。
HDFS能够快速检测并应对这些故障。
8.适合廉价机器的部署:HDFS是一个高度容错性的系统,适合在价格相对较低的机器上部署。
总的来说,HDFS是为大数据应用而设计的,具有高可靠性、高扩展性和高性能的特点。
云计算之HDFS
云计算之HDFSHDFS(Hadoop Distributed File System)是Apache Hadoop项目中的一个关键组件,是一种分布式文件系统。
它的设计目标是能够处理超大规模数据集(大到可以容纳数百个节点的文件系统),提供高吞吐量的数据访问,以及容错性。
HDFS是基于Google的GFS(Google File System)论文设计实现的,用于在由大量计算机组成的集群上存储和处理数据。
HDFS的核心概念是将数据划分为多个数据块(block)并分布在集群中的不同节点上。
每个数据块通常大小为64MB或者128MB,并且会有多个副本分别存储在不同的节点上,以提高数据可用性和容错性。
HDFS通过将数据块跨多个节点进行分布式存储,可以实现快速且可靠的数据访问。
HDFS的架构包括一个NameNode和多个DataNode。
NameNode负责存储文件系统的元数据,包括文件的名称、目录结构、数据块的位置等。
DataNode负责存储实际的数据块。
当客户端需要读取或写入文件时,会先与NameNode进行通信,获取需要访问的数据块的位置,然后直接与DataNode进行数据交互。
HDFS具有以下特点:1.高吞吐量:HDFS采用了批处理的方式来处理数据,可以支持大规模的顺序读写操作,而不适用于随机读写。
这使得HDFS在处理大数据集时具有极高的吞吐量。
2.容错性:HDFS通过将数据块复制到多个节点上,提供了高可用性和容错性。
当一些节点发生故障时,可以从其他副本中恢复数据,保证系统的可用性。
3.可扩展性:HDFS的设计可以轻松地扩展到上千个节点,可以处理PB级别的数据集。
新增节点时,数据可以自动均衡地分配到不同的节点上,无需手动迁移数据。
4.数据局部性:HDFS采用了数据局部性原则,即将计算任务分配到离数据最近的节点上执行,减少了数据传输延迟。
5.冗余存储:HDFS会将数据块存储在多个节点上,提供了冗余存储的机制。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
七HDFS 2.X新特性
7.1 集群间数据拷贝
1)scp实现两个远程主机之间的文件复制
scp -r hello.txt root@hadoop103:/user/atguigu/hello.txt// 推push
scp -r root@hadoop103:/user/atguigu/hello.txt hello.txt// 拉pull
scp -r root@hadoop103:/user/atguigu/hello.txt root@hadoop104:/user/atguigu //是通过本
地主机中转实现两个远程主机的文件复制;如果在两个远程主机之间ssh没有配置的情况下
可以使用该方式。
2)采用discp命令实现两个hadoop集群之间的递归数据复制
[atguigu@hadoop102 hadoop-2.7.2]$ bin/hadoop distcp hdfs://haoop102:9000/user/atguigu/hello.txt hdfs://hadoop103:9000/user/atguigu/hello.txt
7.2 Hadoop存档
1)hdfs存储小文件弊端
每个文件均按块存储,每个块的元数据存储在NameNode的内存中,因此hadoop存储
小文件会非常低效。
因为大量的小文件会耗尽NameNode中的大部分内存。
但注意,存储
小文件所需要的磁盘容量和存储这些文件原始内容所需要的磁盘空间相比也不会增多。
例如,
一个1MB的文件以大小为128MB的块存储,使用的是1MB的磁盘空间,而不是128MB。
2)解决存储小文件办法之一
Hadoop存档文件或HAR文件,是一个更高效的文件存档工具,它将文件存入HDFS
块,在减少NameNode内存使用的同时,允许对文件进行透明的访问。
具体说来,Hadoop
存档文件对内还是一个一个独立文件,对NameNode而言却是一个整体,减少了NameNode
的内存。
3)案例实操
(1)需要启动yarn进程
[atguigu@hadoop102 hadoop-2.7.2]$ start-yarn.sh
(2)归档文件
把/user/atguigu目录里面的所有文件归档成一个叫myhar.har的归档文件,并把归档后文件存储到/user/my路径下。
[atguigu@hadoop102 hadoop-2.7.2]$ bin/hadoop archive -archiveName myhar.har -p /user/atguigu /user/my
(3)查看归档
[atguigu@hadoop102 hadoop-2.7.2]$ hadoop fs -lsr /user/my/myhar.har
[atguigu@hadoop102 hadoop-2.7.2]$ hadoop fs -lsr har:///myhar.har
(4)解归档文件
[atguigu@hadoop102 hadoop-2.7.2]$ hadoop fs -cp har:/// user/my/myhar.har /* /user/atguigu
7.3 快照管理
快照相当于对目录做一个备份。
并不会立即复制所有文件,而是指向同一个文件。
当写入发生时,才会产生新文件。
1)基本语法
(1)hdfs dfsadmin -allowSnapshot 路径(功能描述:开启指定目录的快照功能)(2)hdfs dfsadmin -disallowSnapshot 路径(功能描述:禁用指定目录的快照功能,默认是禁用)
(3)hdfs dfs -createSnapshot 路径(功能描述:对目录创建快照)
(4)hdfs dfs -createSnapshot 路径名称(功能描述:指定名称创建快照)
(5)hdfs dfs -renameSnapshot 路径旧名称新名称(功能描述:重命名快照)
(6)hdfs lsSnapshottableDir (功能描述:列出当前用户所有可快照目录)(7)hdfs snapshotDiff 路径1 路径2 (功能描述:比较两个快照目录的不同之处)(8)hdfs dfs -deleteSnapshot <path> <snapshotName> (功能描述:删除快照)
2)案例实操
(1)开启/禁用指定目录的快照功能
[atguigu@hadoop102 hadoop-2.7.2]$ hdfs dfsadmin -allowSnapshot /user/atguigu/data
[atguigu@hadoop102 hadoop-2.7.2]$ hdfs dfsadmin -disallowSnapshot
/user/atguigu/data
(2)对目录创建快照
[atguigu@hadoop102 hadoop-2.7.2]$ hdfs dfs -createSnapshot /user/atguigu/data
通过web访问hdfs://hadoop102:50070/user/atguigu/data/.snapshot/s…..// 快照和源文
件使用相同数据块
[atguigu@hadoop102 hadoop-2.7.2]$ hdfs dfs -lsr /user/atguigu/data/.snapshot/ (3)指定名称创建快照
[atguigu@hadoop102 hadoop-2.7.2]$ hdfs dfs -createSnapshot /user/atguigu/data miao170508
(4)重命名快照
[atguigu@hadoop102 hadoop-2.7.2]$ hdfs dfs -renameSnapshot /user/atguigu/data/
miao170508 atguigu170508
(5)列出当前用户所有可快照目录
[atguigu@hadoop102 hadoop-2.7.2]$ hdfs lsSnapshottableDir
(6)比较两个快照目录的不同之处
[atguigu@hadoop102 hadoop-2.7.2]$ hdfs snapshotDiff /user/atguigu/data/ . .snapshot/atguigu170508
(7)恢复快照
[atguigu@hadoop102 hadoop-2.7.2]$ hdfs dfs -cp /user/atguigu/input/.snapshot/s2*******-134303.027 /user
7.4 回收站
1)默认回收站
默认值fs.trash.interval=0,0表示禁用回收站,可以设置删除文件的存活时间。
默认值fs.trash.checkpoint.interval=0,检查回收站的间隔时间。
如果该值为0,则该值设
置和fs.trash.interval的参数值相等。
要求fs.trash.checkpoint.interval<=fs.trash.interval。
2)启用回收站
修改core-site.xml,配置垃圾回收时间为1分钟。
<property>
<name>fs.trash.interval</name>
<value>1</value>
</property>
3)查看回收站
回收站在集群中的;路径:/user/atguigu/.Trash/….
4)修改访问垃圾回收站用户名称
进入垃圾回收站用户名称,默认是dr.who,修改为atguigu用户
[core-site.xml]
<property>
<name>er</name>
<value>atguigu</value>
</property>
5)通过程序删除的文件不会经过回收站,需要调用moveToTrash()才进入回收站Trash trash = New Trash(conf);
trash.moveToTrash(path);
6)恢复回收站数据
[atguigu@hadoop102 hadoop-2.7.2]$ hadoop fs -mv /user/atguigu/.Trash/Current/user/atguigu/input /user/atguigu/input
7)清空回收站
[atguigu@hadoop102 hadoop-2.7.2]$ hadoop fs -expunge。