《数理统计》第7章(0-1)分布参数的
概率论与数理统计 第7章.ppt

即 S 2是 2 的无偏估计,故通常取S 2作 2的估计量.
例3 设总体 X 服从参数为 的指数分布, 概率密度
x 1 e , f ( x; ) 0,
x 0, 其他.
其中参数 0, 又设 X 1 , X 2 ,, X n 是来自总体 X 的 样本, 试证 X 和 nZ n[min( X 1 , X 2 ,, X n )] 都是 的无偏估计.
行到其中有15只失效时结束试验, 测得失效时 间(小时)为115, 119, 131, 138, 142, 147, 148, 155,
158, 159, 163, 166, 167, 170, 172.
试求电池的平均寿命 的最大似然估计值 .
解
n 50, m 15,
s( t15 ) 115 119 170 172 (50 15) 172
总体 X 的 k 阶矩 k E ( X k )的相合估计量, 进而若待估参数 g( 1 , 2 ,, n ), 其中g 为连续 ˆ g( 函数, 则 的矩估计量 ˆ1 , ˆ 2 , , ˆ n ) g( A1 , A2 ,
, An ) 是 的相合估计量.
第三节
估计量的评选标准
一、问题的提出
二、无偏性 三、有效性 四、相合性 五、小结
一、问题的提出
从前一节可以看到, 对于同一个参数, 用不 同的估计方法求出的估计量可能不相同. 而且, 很明显, 原则上任何统计量都可以作为未知参数 的估计量. 问题 (1)对于同一个参数究竟采用哪一个估计量好? (2)评价估计量的标准是什么? 下面介绍几个常用标准.
如果不能得到完全样本, 就考虑截尾寿命试验.
3. 两种常见的截尾寿命试验
概率论与数理统计复习7章

( n − 1) S 2 ( n − 1) S 2 = 1 − α 即P 2 <σ2 < 2 χα 2 ( n − 1) χ1−α 2 ( n − 1) ( n − 1) S 2 ( n − 1) S 2 置信区间为: 2 , χα 2 ( n − 1) χ12−α 2 ( n − 1)
则有:E ( X v ) = µv (θ1 , θ 2 ,⋯ , θ k ) 其v阶样本矩是:Av = 1 ∑ X iv n i =1
n
估计的未知参数,假定总体X 的k阶原点矩E ( X k ) 存在,
µ θ , θ ,⋯ , θ = A k 1 1 1 2 µ2 θ1, θ 2 ,⋯ , θ k = A2 用样本矩作为总体矩的估计,即令: ⋮ µ θ , θ ,⋯ , θ = A k k k 1 2 ɵ ɵ ˆ 解此方程即得 (θ1 , θ 2 ,⋯ , θ k )的一个矩估计量 θ 1 , θ 2 ,⋯ , θ k
+∞
−∞
xf ( x ) dx = ∫ θ x θ dx =
1 0
令E ( X ) = X ⇒
θ +1
θ
ˆ = X ⇒θ =
( )
X 1− X
θ +1
2
θ
7.2极大似然估计法
极大似然估计法: 设总体X 的概率密度为f ( x,θ ) (或分布率p( x,θ )),θ = (θ1 ,θ 2 ,⋯ ,θ k ) 为 未知参数,θ ∈ Θ, Θ为参数空间,即θ的取值范围。设 ( x1 , x2 ,⋯ , xn ) 是 样本 ( X 1 , X 2 ,⋯ , X n )的一个观察值:
i =1 n
概率论与数理统计第7章参数估计PPT课件

a1(1, ,k )=v1
1 f1(v1, ,vk )
假定方程组a2(1, ,k ) v2 ,则可求出2 f2(v1, ,vk )
ak (1, ,k ) vk
k fk (v1, ,vk )
则x1 xn为X的样本值时,可用样本值的j阶原点矩Aj估计vj,其中
Aj
1 n
n i1
xij ( j
L(x1, ,xn;ˆ)maxL(x1, ,xn;),则称ˆ(x1, ,xn)为
的一种参数估计方法 .
它首先是由德国数学家
高斯在1821年提出的 ,然而, 这个方法常归功于英国统
Gauss
计学家费歇(Fisher) . 费歇在1922年重新发现了
这一方法,并首先研究了这
种方法的一些性质 .
Fisher
10
极大似然估计是在已知总体分布形式的情形下的 点估计。
极大似然估计的基本思路:根据样本的具体情况
注:估计量为样本的函数,样本不同,估计量不 同。
常用估计量构造法:矩估计法、极大似然估计法。
4
7.1.1 矩估计法
矩估计法是通过参数与总体矩的关系,解出参数, 并用样本矩替代总体矩而得到的参数估计方法。 (由大数定理可知样本矩依概率收敛于总体矩, 且许多分布所含参数都是矩的函数)
下面我们考虑总体为连续型随机变量的情况:
n
它是的函数,记为L(x1, , xn; ) f (xi , ), i 1
并称其为似然函数,记为L( )。
注:似然函数的概念并不仅限于连续随机变量 ,
对于离散型随机变量,用 P {Xx}p(x,)
替代f ( x, )
即可。
14
设总体X的分布形式已知,且只含一个未知参数,
概率论与数理统计习题及答案第七章

习题7-11.选择题(1)设总体X 的均值口与方差 /都存在但未知,而X 1,X 2,L ,X n 为来自X 的样本,则均值 口与方差 (T 2的矩估计量分别是 ().(A) X 和(B)1 nX 和—(Xn i 1i )2.(C)口和 2(T・1 (D) X 和一 nn(X ii 1 x)2.解 选(D).(2) 设X : U[0,],其中 e >0为未知参数,又X ,,X 2,L ,X n 为来自总体X 的样本 ,则e 的矩估计量是().(A) X . (B)2X . (C)max{X i }.(D)mi^X i}.解选(B).2.设总体X 其中0v B v 为未知参数,X1, X 2,…,X.为来自总体X 的样本,试求e 的矩 估计量.解 因为 E (X )=(- 2)x3 e +1x (1 -4 e )+5x e =1-5 e ,令 1 5 X 得到的矩估计量为3.设总体X 的概率密度为f(x ;)(1)x ,0 x 1,0,其它•其中 0> -1是未知参数,X ,冷… ,X n 是来自 X 的容量为n 的简单随机样本求:(1) 的矩估计量;⑵ 0的极大似然估计量•解 总体X 的数学期望为-19 2X 1令E(X) X ,即一1 X,得参数B 的矩估计量为?•21 X设X 1, X 2,…,x n 是相应于样本X 1, X 2,…,X n 的一组观测值,则似然函 数为n(1)n X i , 0x i 1,i 10,其它.In xi 1In X ii 14.设总体X 服从参数为的指数分布,即X 的概率密度为E(X)1xf(x)dx o (1)x dx当 0<X i <1(i =1,2,3,…,n )时,L >0 且 In L nln(1)In X i ,i 1dln LnIn x =0,得0的极大似然估计值为而0的极大似然估计量为f(X,xe , x 0,其中0为未知参数,X, X2,)0, x< 0,…,X n为来自总体X的样本,试求未知参数的矩估计量与极大似然估计量解因为E(X)= 1= X , 所以的矩估计量为设X1, X2,…,x n是相应于样本X i, X2,…,X 的一组观测值,则似然函数取对数Xii 1然估计量为In L 0,得5.设总体X的概率密度为f (x,) 其中(0< <1)是未知参数.X, N为样本值x1, X2,L ,x n中小于极大似然估计量•解⑴ X E(X) xnInnXn e 11X).的极大似然估计值为1,的极大似X0,X2,0x1,, 1< x< 2,其它,…,X n为来自总体的简单随机样本,记1的个数.dx 2x(1求:(1)e的矩估计量;(2)e的3 3 —)dx ,所以矩一X .2 21⑵ 设样本X ,X 2 ,L X n 按照从小到大为序(即顺序统计量的观测值)有如下关系:X (1) w X (2)X ( Ni <1 W X ( N +1) W X (N+2)X (n ).似然函数为N n NL()(1 ),X (1) w X (2) w L w X ( N ) 1W X (N1) W X (N2) w L w X n ,0,其它.考虑似然函数非零部分,得到In L ( 0 ) = N ln 0 + ( n -N ) ln(1 - 0 ),令d |nL ( )」o ,解得0的极大似然估计值为? N .d1n习题7-2的无偏估计量•1.选择题:设总体X 的均值与方差 2都存在但未知,X i ,X 2,L ,X n 为X 的样本,则无论总体 X 服从什么分布,()1X i和丄 (XiX)2.(B)n i 1 n i1 n(C)X i 和n 1 i 1解 选(D).2.若X 1 ,X 2lx1 1X 2kX 334解 要求E( 7X 1-X j 和丄 1 i 1 n 1n(X ii 1X)2.(X i1)2 • (D)X i 和丄(X i)2.X 3为来 自总体X : N(,2)的样本,且的无偏估计量,问k 等于多少1 11 「2 kX 3)3 4k解之,k=g(A)13.设总体X的均值为0,方差2存在但未知,又X「X2为来自总体X1 2 2的样本,试证:—(X i X2)为的无偏估计21 2 1 2 2证因为E[—(X i X2) ] —E[(X i 2X^2 X2 )]2 2-[E(X i2) 2E(X i X2)E(X22)]-2 2所以-(X i X2)2为2的无偏估计•2习题7-31.选择题(1)总体未知参数的置信水平为的置信区间的意义是指()(A)区间平均含总体95%的值.(B)区间平均含样本95%的值.(C) 未知参数有95%的可靠程度落入此区间.(D) 区间有95%的可靠程度含参数的真值•解选(D).(2)对于置信水平1- a (0< a <1),关于置信区间的可靠程度与精确程度F列说法不正确的是().(A)若可靠程度越咼,则置信区间包含未知参数真值的可能性越大(B)如果a越小,则可靠程度越高,精确程度越低•(C)如杲1 - a越小,则可靠程度越高,精确程度越低•(D)若精确程度越高,则可靠程度越低,而1- a越小.解选(C)习题7-41. 某灯泡厂从当天生产的灯泡中随机抽取9只进行寿命测试,取得数据如下(单位:小时): 1050, 1100, 1080 , 1120, 1250, 1040, 1130, 1300, 1200设灯泡寿命服从正态分布 N 口 , 902),取置信度为,试求当天生产的全部灯泡的平均寿命的置信区间所求置信区间为(x - z /2 , X - z /2 ) \l n J n 90 90 (1141.11 = 1.96,1141.11 r 1.96)V 9V 9(1082.31,1199.91).2.为调查某地旅游者的平均消费水平,随机访问了40名旅游者,算得平均消费额为 X 105元,样本标准差s 28元•设消费额服从正态分布 取置信水平为,求该地旅游者的平均消费额的置信区间解计算可得X 105, s 2 =282.对于a =,查表可得t_(n 1) t o.025(39)2.0227.2所求口的置信区间为3. 假设某种香烟的尼古丁含量服从正态分布 .现随机抽取此种香烟 8支解计算得到X1141.11, CT 2 =902.对于a =,查表可得Z /2Z).Q25匸96*(Xt (n 1), x ■■- n 2s —t (n ■■- n 21)) (1052.0227, 1052.0227)2828为一组样本,测得其尼古丁平均含量为毫克,样本标准差s=毫克.试求此种香烟尼古丁含量的总体方差的置信水平为的置信区间.a =,查表可得 2(n 1) 爲5(7) 20.278,并说明该置信区间的实际意义1 2的置信水平为的置信区间是,”的实际意义是:在两总体第一个正态总体的均值1比第二个正态总体均值 2大〜,此结 论的可靠性达到95%.5.某商场为了了解居民对某种商品的需求 ,调查了 100户,得出每户月2解已知n =8, s2 2 (n 1)0.995(7) 1 - 20.989,所以方差d 2的置信区间为((n 1)S 2(2_ (n 1)22 22(8 1) 2.4 (8 1) 2.4 _2 —)(, )=,.2(n 廿丿 20.2780.9891 -(n 1)S 4.某厂利用两条自动化流水线灌装番茄酱 ,分别从两条流水线上抽取样本:X ,X 2,…,X 12 及 Y ,Y 2,…,丫17,算出 x 10.6g, y2 29.5g, s 1 2.4, s 2 4.7 .假设这两条流水线上装的番茄酱的重量都服从正态分布 ,且相互独立,其均值分别为2又设两总体方差1:.求2置信水平为的置信区间解由题设2 2x 10.6,y 9.5,s 12.4, s 2 4.7,n12,n 2 17,m 1)s 2 仏 1)s :(12 1) 2.4(171) 471.94212 17 2t_gn 22q n 2 22) t °.°25(27)2.05181,所求置信区间为((X y)11) ((10.6 9.5) 2.05181 1.94结论“方差相等时, [(a n 22)s w2)平均需求量为10公斤,方差为9 .如果这种商品供应10000户,取置信水平为•(1) 取置信度为,试对居民对此种商品的平均月需求量进行区间估计(2) 问最少要准备多少这种商品才能以99%的概率满足需要解(1) 每户居民的需求量的置信区间为_ s(xt(n* n_ s1), xt (nV n1)) (xs卅,%s川)(10,9J492.575,10 2.575)(9.2275,10.7725). 100J10010000户居民对此种商品月需求量的置信度为的置信区间为(92275,107725);(2)最少要准备92275公斤商品才能以99%的概率满足需要。
《概率论与数理统计》7

未知参数 , ,, 的函数.分别令
12
k
L(1,,k ) 0,(i 1,2,...,k)
或令
i
ln L(1,,k ) 0,(i 1,2,...,k)
i
由此方程组可解得参数 i 的极大似然估计值 ˆi.
例5 设X~b(1,p), X1, X2 , …,Xn是来自X的一个样本,
求参数 p 的最大似然估计量.
解 E( X ) ,E( X 2 ) D( X ) [E( X )]2 2 2
由矩估计法,
【注】
X
1
n
n i 1
X
2 i
2
2
ˆ X ,
ˆ
2
1 n
n i 1
(Xi
X )2
对任何总体,总体均值与方差的矩估计量都不变.
➢常见分布的参数矩估计量
(1)若总体X~b(1, p), 则未知参数 p 的矩估计量为
7-1
第七章
参数估计
统计 推断
的 基本 问题
7-2
参数估 计问题
(第七章)
点估计 区间估 计
假设检 验问题 (第八章)
什么是参数估计?
参数是刻画总体某方面概率特性的数量.
当此数量未知时,从总体抽出一个样本, 用某种方法对这个未知参数进行估计就 是参数估计.
例如,X ~N ( , 2),
若, 2未知, 通过构造样本的函数, 给出
k = k(A1, A2 , …, A k)
用i 作为i的估计量------矩估计量.
例1 设总体X服从[a,b]上的均匀分布,a,b未知,
X1, X2 , …,Xn为来自总体X的样本,试求a,b的 矩估计量.
解 E(X ) a b , D(X ) (b a)2
《概率论与数理统计》第七章

n
n
ln xi
(4)的极大似然估计量为:ˆ
n
n2 i1
lnX
i
2
i1
第七章 参数估计 ‹#›
例 9 设X~b(1,p), X1,X2,…,Xn是来自X的一个样本, 试求参数p的最大似然估计量
解: 设x1, x2,, xn,是相应于样本X1,X2,…,Xn 的一个样本值,X
的分布律为:
(3)以样本各阶矩A1, ,Ak代替总体各阶矩1,
得各参数的矩估计
ˆi gi(A1, ,Ak ), i 1, , k
, k,
第七章 参数估计 ‹#›
注意:
在实际应用时,为求解方便,也可以用
中心矩 i 代替原点矩i,相应地以样本中心矩Bi 估计 i.
(二)最大似然估计法
最(极)大似然估计的原理介绍
第七章
参数估计
目录/Contents
第1章 随机事件与 2 概率
§ 1 点估计
§3
估计量的评选标准
第七章 参数估计 ‹#›
问题的提出:
在实际进行统计时,有不少总体的(我们关心的某 确定指标)概率分布是已知的。比如
例 1 产品寿命服从的分布
X~
f
(
x)
1
x
e
x0
0
其他
但其中有参数是未知的: θ
n
似然函数 L f xi , 。 i 1
, xn ,
极大似然原理:L(ˆ( x1 ,
,
xn
))
max
L(
).
计算简化方法:
在求L 的最大值时,通常转换为求:lnL 的最大值,
lnL 称为对数似然函数.
利用
(完整版)(0-1)分布参数的区间估计
对给定的置信水平1 ,确定分位数t (n 1)
使
P{ X S
n
t (n 1)}
1
即
P{ X t (n 1)
S }1
n
于是得到 的置信水平为 1 的单侧置
信区间为
[ X t (n 1)
S , ] n
即 的置信水平为 1 的单侧置信下限为
第六节 (0-1)分布参数的区间估计
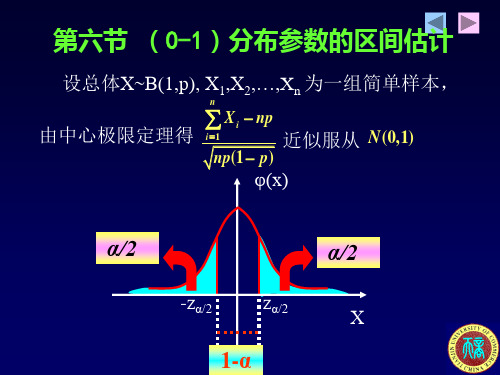
设总体X~B(1,p), X1,X2,…,Xn 为一组简单样本,
n
由中心极限定理得
Xi np
i 1
近似服从
N (0, 1)
np(1 p)
φ(x)
α/2
α/2
-zα/2
zα/2
X
1-α
n
Xi np
故
P{ Z / 2
i 1
np(1
p)
P{ ˆ1} 1
则称区间 [ˆ1, )是 的置信水平为 1 的 单侧置信区间. ˆ1 称为单侧置信下限.
又若统计量 ˆ2 ˆ2( X1, X2, , Xn) 满足
P{ ˆ2 } 1
则称区间(,ˆ2 ]是 的置信水平为 1 的 单侧置信区间. ˆ2 称为单侧置信上限.
解 一级品率p是(0-1)分布的参数.
n 100, x 0.6, z /2 1.96
p的1-α置信区间: (0.5, 0.69)
第七节 单侧置信区间
设 是 一个待估参数,给定 0,
若由样本X1,X2,…Xn确定的统计量
ˆ1 ˆ1( X1, X2, , Xn) 满足
X t (n 1)
S n
将样本值代入得
浙大四版概率论与数理统计 《0-1分布参数的区间估计》

n 100,
1 0.95,
2 则 a n z / 2 103.84,
2 2 b ( 2nX z ) ( 2 n x z /2 / 2 ) 123.84,
c nX nx 36,
2 2
b b 2 4ac 0.50, 于是 p1 2a b b 2 4ac p2 0.69, 2a
b b 2 4ac b b 2 4ac , , 2 a 2 a
2 2 2 其中 a n z , b ( 2 n X z ), c n X . /2 /2
推导过程如下: 因为(0–1)分布的均值和),
p 的置信水平为0.95的置信区间为 (0.50, 0.69).
例2 设从一大批产品的120个样品中, 得次品9个, 求这批产品的次品率 p 的置信水平为0.90的置信 区间. 9 0.09, 1 0.90, 解 n 120, x 100
2 则 a n z 2 122.71, 2 2 b ( 2n X z ) ( 2 n x z 2 2 ) 24.31,
设 X 1 , X 2 ,, X n 是一个样本, 因为容量n较大,
由中心极限定理知
X i np
i 1
n
nX np np(1 p ) np(1 p )
近似地服从 N (0,1) 分布,
nX np P z / 2 z / 2 1 , np(1 p)
c n X nx 2 0.972,
2
b b 4ac 0.056, 于是 p1 2a
2
b b 4ac 0.143, p2 2a
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
的X样~本N,(, 2 )
,均2未知. 试求 的置2 信水平为 的1单侧置信上限.
, 2 的无偏估计分别为 X , S 2,且
(n 1)S 2
2
~
2 (n
1)
故的2 置信度为 1的单侧置信上限为
2
(n
2 1
1)S 2 (n 1)
形式运算
2
~
(n 1)S 2
2 (n1)
, 1 ?
(注意 较小)
2 1
X
近似
~
N(0 ,间1) 估计问题
S/ n
从而求得 的置信水平为 1的近似置信区间为
X
S n
z / 2 ,
X
S n
z
/
2
第七章 参数估计
§6 (0-1)分布参数的区间估计 2/2
工厂生产的某产品次品率不超过 5%才能出厂.
今抽检 10件0 产品,发现次品 件4,问这批产品能否出厂?要求
检验结果具有 的9可5%信度.
15、16、19、20、22 END
第七章 参数估计
令
X
0 , 检验合格 1 , 检验不合格
则总体 X ~ b(1, p). Q E(X ) p , p 的 1的 置信区间为
X
S n
z / 2 ,
X
S n
z
/
2
现 n 100 , X 0.04, z /2 z 0.025 1.96 ,又因 X 2 X , 故
S2
1
n
n
i 1
X
2 i
X
2
关心上限P{ 来自对这类“好”指 标} 1关心下限
则称 ( , 为) 的置信水平为 的1 单侧置信区间, 称 为 单侧置信下限.
若存在统计量 (X1, X2,, Xn ) 满足 有Θ
P{ } 1
则称 (,为 ) 的置信水平为 称 为 单侧置信上限.
的1
单侧置信区间,
第七章 参数估计
§6 (0-1)分布参数的区间估计 1/2
设 X1, X2,为,来Xn自总体 的样X本,且
E(X) ,
D(X ) 2 均存在.求 的置信水平为 1的置信区间.
利用中心极限定理可知,当 n充分大时有
若未2 知,则有
X / n
近似
~
因总体 X的分
N (0 , 1布) 未知,故这是非
正态总体参数的区
故
的单侧X 置 信P~下SX限Sn/为tn(nt1)(n
1)
1~ X
S n
t(n 1)
等故价的地单有侧置的P信置{ X下信限上S为n限t是X(Xn什X么S1n)SntSn(tn}(t1n)(1n1)第1七)章
t(n 1)
参数估计
§6 (0-1)分布参数的区间估计 6/2
设 X1, X为2,来自, X总n 体
§6 (0-1)分布参数的区间估计 5/2
设 X1, X2,, Xn 为来自总体 X ~ N(, 2 ) 的样本,
, 2均未知.试求 的置信水平为 1的单侧置信下限.
, 2 的无偏估计分别是 X , S 2,且
X ~ t(n 1)
S/ n
对于给定怎的样置直信接水写平出1置,可信查下表限求得 t使(n 得1)
(n
1)
2 (n 1)
第七章 参数估计
§6 (0-1)分布参数的区间估计 7/2
参数估计主要内容
矩估计量
最大似然 估计量
似 然 函
选估 计 量
数的
评
无偏性 有效性 相合性
正态总 体均值 方差的 置信区 间与上
下限
最大似然估计的性质
求置信区间 的步骤
置信区间和上下限
第七章 参数估计
§6 (0-1)分布参数的区间估计 8/2
X
X
2
X
(1
X
)
0.0384
求得 p的 95置%信区间为
( 0.0014 , 0.0786 ) 由于置信上限 0.0786 >故5%这,批产品不能出第厂七.章 参数估计
§6 (0-1)分布参数的区间估计 3/2
第七章 参数估计
§6 (0-1)分布参数的区间估计 4/2
对这类“坏”指
满足 有Θ 标