【原创】R语言线性回归案例数据分析可视化报告(附代码数据)
用R语言做回归分析

⽤R语⾔做回归分析使⽤R做回归分析整体上是⽐较常规的⼀类数据分析内容,下⾯我们具体的了解⽤R语⾔做回归分析的过程。
⾸先,我们先构造⼀个分析的数据集x<-data.frame(y=c(102,115,124,135,148,156,162,176,183,195),var1=runif(10,min=1,max=50),var2=runif(10,min=100,max=200),var3=c(235,321,412,511,654,745,821,932,1020,1123))接下来,我们进⾏简单的⼀元回归分析,选择y作为因变量,var1作为⾃变量。
⼀元线性回归的简单原理:假设有关系y=c+bx+e,其中c+bx 是y随x变化的部分,e是随机误差。
可以很容易的⽤函数lm()求出回归参数b,c并作相应的假设检验。
model<-lm(y~var1,data=x)summary(model)Call:lm(formula = x$y ~ x$var1 + 1)Residuals:Min 1Q Median 3Q Max-47.630 -18.654 -3.089 21.889 52.326Coefficients:Estimate Std. Error t value Pr(>|t|)(Intercept) 168.4453 15.2812 11.023 1.96e-09 ***x$var1 -0.4947 0.4747 -1.042 0.311Signif. codes: 0 ‘’ 0.001 ‘’ 0.01 ‘’ 0.05 ‘.’ 0.1 ‘ ’ 1Residual standard error: 30.98 on 18 degrees of freedomMultiple R-squared: 0.05692, Adjusted R-squared: 0.004525F-statistic: 1.086 on 1 and 18 DF, p-value: 0.3111从回归的结果来看,p值为0.311,变量var1不不显著,正常情况下p值⼩于0.05则认为有⾼的显著性⽔平。
r语言回归分析案例

r语言回归分析案例R语言回归分析案例。
回归分析是统计学中常用的一种方法,它用于探究变量之间的关系,并对未来的变量进行预测。
R语言作为一种强大的统计分析工具,被广泛应用于回归分析中。
本文将通过一个实际案例,介绍如何使用R语言进行回归分析。
首先,我们需要准备一些数据。
假设我们有一个数据集,包括了房屋的面积、房龄和售价。
我们想要分析房屋的售价与其面积、房龄之间的关系。
接下来,我们将使用R语言进行回归分析。
在R语言中,我们可以使用lm()函数来进行线性回归分析。
首先,我们需要加载我们的数据集,并创建一个线性模型。
代码如下:```R。
# 加载数据集。
data <read.csv("house_data.csv")。
# 创建线性模型。
model <lm(price ~ area + age, data = data)。
```。
在上面的代码中,我们使用lm()函数创建了一个线性模型,其中price是我们要预测的变量,而area和age是我们用来预测的自变量。
接下来,我们可以使用summary()函数来查看我们的线性回归模型的结果。
```R。
# 查看回归分析结果。
summary(model)。
```。
summary()函数将输出我们线性回归模型的各项统计指标,包括回归系数、残差标准差、R平方等。
通过这些指标,我们可以评估我们的回归模型的拟合程度和预测能力。
除了线性回归分析,R语言还支持其他类型的回归分析,如多元回归、逻辑回归等。
对于不同类型的回归分析,我们可以使用不同的函数来创建模型,并使用不同的方法来评估模型的拟合程度。
总之,R语言是一种强大的统计分析工具,它提供了丰富的函数和包,支持各种类型的回归分析。
通过本文介绍的案例,我们可以看到R语言在回归分析中的应用,希望对大家有所帮助。
【原创】R语言数据可视化分析报告(附代码数据)
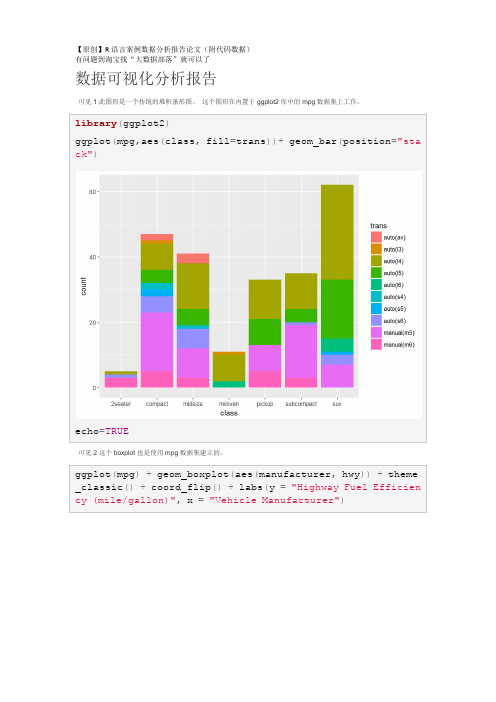
Vis 3这个图形是用另一个数据集菱形建立的,也是内置在ggplot2包中的数据集。
library(ggthemes)
ggplot(diamonds)+geom_density(aes(price,fill=cut,color=cut),alpha=0.4,size=0.5)+labs(title='Diamond Price Density',x='Diamond Price (USD)',y='Density')+theme_economist()
library(ggplot2)
ggplot(mpg,aes(class,fill=trans))+geom_bar(position="stack")
echo=TRUE
可见2这个boxplot也是使用mpg数据集建立的。
ggplot(mpg)+geom_boxplot(aes(manufacturer,hwy))+theme_classic()+coord_flip()+labs(y="Highway Fuel Efficiency (mile/gallon)",x="Vehicle Manufacturer")
echo=TRUE
另外,我正在使用ggplot2软件包来将线性模型拟合到框架内的所有数据上。
ggplot(iris,aes(Sepal.Length,Petal.Length))+geom_point()+geom_smooth(method=lm)+theme_minimal()+theme(panel.grid.major=element_line(size=1),panel.grid.minor=element_line(size=0.7))+labs(title='relationship between Petal and Sepal Length',x='Iris Sepal Length',y='Iris Petal Length')
r语言回归分析案例

r语言回归分析案例R语言回归分析案例。
在统计学中,回归分析是一种用于研究变量之间关系的重要方法。
而R语言作为一种强大的统计分析工具,被广泛应用于回归分析中。
本文将通过一个实际案例,介绍如何使用R语言进行回归分析,并展示分析结果。
案例背景。
假设我们是一家电子商务公司的数据分析师,公司希望了解广告投入对销售额的影响。
我们收集了过去一年的数据,包括每月的广告花费和销售额。
现在,我们需要利用回归分析来探究两者之间的关系,并预测未来的销售额。
数据准备。
首先,我们需要导入数据并进行初步的处理。
我们使用R语言中的数据框架来存储数据,并利用相关的包来进行数据处理和分析。
在这一步,我们会检查数据的完整性,处理缺失值和异常值,确保数据的质量。
回归分析建模。
接下来,我们将利用R语言中的线性回归模型来建立广告花费和销售额之间的关系模型。
我们会使用lm()函数来拟合模型,并利用summary()函数来查看模型的统计指标和显著性检验结果。
通过分析模型的系数和拟合优度,我们可以得出广告投入对销售额的影响程度以及模型的预测能力。
模型诊断。
在建立回归模型后,我们需要进行模型诊断,以验证模型的合理性和假设的成立性。
我们将利用R语言中的各种图表和检验方法,如残差分析、QQ图、方差膨胀因子等,来检验模型的残差是否符合正态分布、是否存在异方差性等问题。
预测与解释。
最后,我们将利用建立的回归模型来进行预测和解释。
我们可以利用predict()函数来预测未来销售额,并利用coef()函数来解释模型中各个变量的影响程度。
通过这些分析,我们可以为公司提供关于广告投入对销售额的预测和解释结果,为决策提供参考依据。
总结。
通过本文的案例分析,我们展示了如何利用R语言进行回归分析。
从数据准备、模型建立、模型诊断到预测与解释,我们全面展示了回归分析的全过程。
希望本文可以帮助读者更好地理解回归分析方法,并在实际工作中运用R语言进行数据分析。
结语。
回归分析作为统计学中的重要方法,对于研究变量之间的关系具有重要意义。
【原创】R语言进行分位数回归数据分析报告论文(附代码数据)

欢迎登陆官网:/datablog用R语言进行分位数回归作者的主要贡献有:(1)整理了分位数回归的一些基本原理和方法;(2)归纳了用R语言处理分位数回归的程序,其中写了两个函数整合估计结果;(3)写了一个分位数分解函数来处理MM2005的分解过程;(4)使用一个数据集进行案例分析,完整地展现了分析过程。
第一节分位数回归介绍(一)为什么需要分位数回归?传统的线性回归模型描述了因变量的条件均值分布受自变量X的影响过程。
其中,最小二乘法是估计回归系数的最基本方法。
如果模型的随机误差项来自均值为零、方差相同的分布,那么回归系数的最小二乘估计为最佳线性无偏估计(BLUE);如果随机误差项是正态分布,那么回归系数的最小二乘估计与极大似然估计一致,均为最小方差无偏估计(MVUL)。
此时它具有无偏性、有效性等优良性质。
但是在实际的经济生活中,这种假设通常不能够满足。
例如当数据中存在严重的异方差,或后尾、尖峰情况时,最小二乘法的估计将不再具有上述优良性质。
为了弥补普通最小二乘法(OLS)在回归分析中的缺陷,1818年Laplace[2]提出了中位数回归(最小绝对偏差估计)。
在此基础上,1978年Koenker 和Bassett[3]把中位数回归推广到了一般的分位数回归(Quantile Regression)上。
分位数回归相对于最小二乘回归,应用条件更加宽松,挖掘的信息更加丰富。
它依据因变量的条件分位数对自变量X进行回归,这样得到了所有分位数下的回归模型。
因此分位数回归相比普通的最小二乘回归,能够更加精确第描述自变量X对因变量Y的变化范围,以及条件分布形状的影响。
(二)一个简单的分位数回归模型[4]假设随机变量的分布函数为(1)Y的分位数的定义为满足的最小值,即(2)回归分析的基本思想就是使样本值与拟合值之间的距离最短,对于Y的一组随机样本,样本均值回归是使误差平方和最小,即(3)样本中位数回归是使误差绝对值之和最小,即(4)样本分位数回归是使加权误差绝对值之和最小,即(5)上式可等价表示为:其中,为检查函数(check function),定义为:欢迎登陆官网:/datablog其中,为指示函数(indicator function),z是条件关系式,当z为真时,;当z为假时,。
R语言可视化案例分析报告 附代码数据

R语言可视化案例分析报告
路线
在ANLY 512期间,我们将研究数据可视化的理论和实践。
我们将使用R和R中的软件包来汇编数据并构建许多不同类型的可视化。
问题
在R中查找mtcars数据。
这是您将用来创建图形的数据集。
使用这些数据来手动绘制下一个问题的图形。
1.绘制一个饼图,显示来自mtcars数据集的具有不同碳水化合物值的汽车的比例。
2.
3. 结果显示,大部分汽车使用了化油器的数量1,2,4。
小汽车使用的数量是6或8。
2.绘制一个条形图,显示mtcars中每个齿轮类型的数量。
5.
结果表明wt和mpg具有负相关关系。
随着汽车重量的增加,每加仑的里程会减少。
5.使用数据设计您的选择的可视化。
The result shows the mpg mean of cars with manual transmission is greater than cars with automatic transmission.。
R语言与多元线性回归分析计算案例
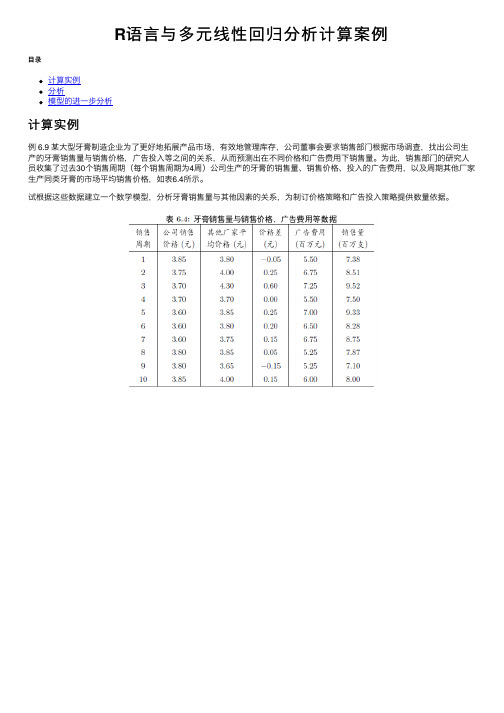
R语⾔与多元线性回归分析计算案例⽬录计算实例分析模型的进⼀步分析计算实例例 6.9 某⼤型⽛膏制造企业为了更好地拓展产品市场,有效地管理库存,公司董事会要求销售部门根据市场调查,找出公司⽣产的⽛膏销售量与销售价格,⼴告投⼊等之间的关系,从⽽预测出在不同价格和⼴告费⽤下销售量。
为此,销售部门的研究⼈员收集了过去30个销售周期(每个销售周期为4周)公司⽣产的⽛膏的销售量、销售价格、投⼊的⼴告费⽤,以及周期其他⼚家⽣产同类⽛膏的市场平均销售价格,如表6.4所⽰。
试根据这些数据建⽴⼀个数学模型,分析⽛膏销售量与其他因素的关系,为制订价格策略和⼴告投⼊策略提供数量依据。
分析由于⽛膏是⽣活的必需品,对于⼤多数顾客来说,在购买同类⽛膏时,更多的会关⼼不同品牌之间的价格差,⽽不是它们的价格本⾝。
因此,在研究各个因素对销售量的影响时,⽤价格差代替公司销售价格和其他⼚家平均价格更为合适。
模型的建⽴与求解记⽛膏销售量为Y,价格差为X1,公司的⼴告费为X2,假设基本模型为线性模型:输⼊数据,调⽤R软件中的lm()函数求解,并⽤summary()显⽰计算结果(程序名:exam0609.R)计算结果通过线性回归系数检验和回归⽅程检验,由此得到销售量与价格差与⼴告费之间的关系为:模型的进⼀步分析为进⼀步分析回归模型,我们画出y与x1和y与x2散点图。
从散点图上可以看出,对于y与x1,⽤直线拟合较好。
⽽对于y与x2,则⽤⼆次曲线拟合较好,如下图:绘制x1与y的散点图和回归直线绘制x2与y的散点图和回归曲线其中 I(X2^2),表⽰模型中X2的平⽅项,及X22,从上图中,将销售量模型改为:似乎更合理,我们做相应的回归分析:此时,我们发现,模型残差的标准差Residual standard error有所下降,相关系数的平⽅Multiple R-squared有所上升,这说明模型修正的是合理的。
但同时也出现了⼀个问题,就是对于β2的P-值>0.05。
r语言回归分析案例

r语言回归分析案例R语言回归分析案例。
回归分析是统计学中一种重要的数据分析方法,用于研究自变量与因变量之间的关系。
在R语言中,我们可以利用各种回归模型来进行数据分析和预测。
本文将通过一个实际案例来介绍如何使用R语言进行回归分析。
案例背景。
假设我们是一家电商公司的数据分析师,现在我们手上有一份销售数据,包括了产品的售价、广告费用、促销活动等信息。
我们希望利用这些数据来建立一个回归模型,预测产品销售额与各项因素之间的关系。
数据准备。
首先,我们需要导入数据并进行初步的数据清洗。
在R语言中,我们可以使用read.csv()函数来读取csv格式的数据文件,然后使用summary()函数来查看数据的基本情况,包括均值、标准差、最大最小值等。
模型建立。
接下来,我们可以利用lm()函数来建立线性回归模型。
假设我们将销售额作为因变量Y,售价、广告费用、促销活动等作为自变量X1、X2、X3等,那么模型的建立代码可以如下所示:model <lm(Y ~ X1 + X2 + X3, data = sales_data)。
然后,我们可以使用summary()函数来查看模型的回归系数、拟合优度等统计信息。
通过这些统计信息,我们可以初步判断模型的拟合程度和各个自变量对因变量的影响程度。
模型诊断。
在建立回归模型之后,我们需要对模型进行诊断,以确保模型的可靠性。
在R语言中,我们可以使用plot()函数来绘制残差图、QQ图等,以检验模型的残差是否符合正态分布、是否存在异方差等问题。
模型预测。
最后,我们可以利用建立好的回归模型来进行销售额的预测。
在R语言中,我们可以使用predict()函数来对新的数据进行预测,从而帮助企业做出更准确的销售预测。
总结。
通过本文的案例,我们简要介绍了如何利用R语言进行回归分析。
从数据准备、模型建立、模型诊断到模型预测,我们逐步展示了整个回归分析的流程。
希望本文能够帮助读者更好地理解回归分析方法,并在实际工作中应用R语言进行数据分析。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
R语言线性回归案例数据分析可视化报告
在本实验中,我们将查看来自所有30个职业棒球大联盟球队的数据,并检查一个赛季的得分与其他球员统计数据之间的线性关系。
我们的目标是通过图表和数字总结这些关系,以便找出哪个变量(如果有的话)可以帮助我们最好地预测一个赛季中球队的得分情况。
数据
用变量at_bats绘制这种关系作为预测。
关系看起来是线性的吗?如果你知道一个团队的
at_bats,你会习惯使用线性模型来预测运行次数吗?
散点图
.如果关系看起来是线性的,我们可以用相关系数来量化关系的强度。
.残差平方和
回想一下我们描述单个变量分布的方式。
回想一下,我们讨论了中心,传播和形状等特征。
能够描述两个数值变量(例如上面的runand at_bats)的关系也是有用的。
从前面的练习中查看你的情节,描述这两个变量之间的关系。
确保讨论关系的形式,方向和强度以及任何不寻常的观察。
正如我们用均值和标准差来总结单个变量一样,我们可以通过找出最符合其关联的线来总结这两个变量之间的关系。
使用下面的交互功能来选择您认为通过点云的最佳工作的线路。
# Click two points to make a line.。