《统计分析与SPSS的应用(第五版)》课后练习答案(第8章)
统计分析与SPSS的应用第五版课后练习答案
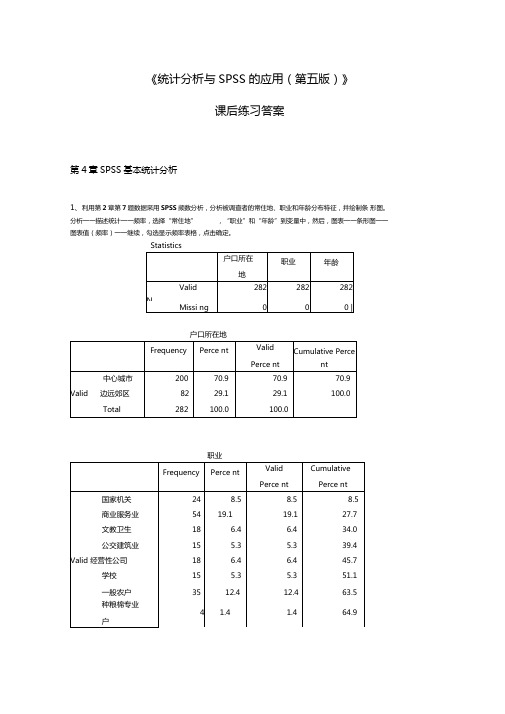
《统计分析与SPSS的应用(第五版)》课后练习答案第4章SPSS基本统计分析1、利用第2章第7题数据采用SPSS频数分析,分析被调查者的常住地、职业和年龄分布特征,并绘制条形图。
分析一一描述统计一一频率,选择“常住地”,“职业”和“年龄”到变量中,然后,图表一一条形图一一图表值(频率)一一继续,勾选显示频率表格,点击确定。
Statistics户口所在地职业种果菜专业户10 3.5 3.568.4工商运专业户3412.112.180.5退役人员17 6.0 6.086.5金融机构3512.412.498.9现役军人3 1.1 1.1100.0 Total282100.0100.0年龄Freque ncy Perce nt ValidPerce nt Cumulative Percent20岁以下4 1.4 1.4 1.420~35 岁14651.851.853.2 Valid 35~50 岁9132.332.385.5 50岁以上4114.514.5100.0Total282100.0100.0.I賊M■■-■I T r'i Itl分析:本次调查的有效样本为 282份。
常住地的分布状况是:在中心城市的人最多,有200人,而在边远郊区只有 82人;职业的分布状况是:在商业服务业的人最多,其次是一般农户和金融机构;年龄方面:在35-50岁的人最多。
由于变量中无缺失数据,因此频数分布表中的百分比相同。
2、利用第2章第7题数据,从数据的集中趋势、离散程度以及分布形状等角度,分析被调查者本次存款金额的基本特征,并与标准正态分布曲线进行对比。
进一步,对不同常住地储户存款金额的基本特征进行对比分析。
分析一一描述统计一一描述,选择存款金额到变量中。
点击选项,勾选均值、标准差、方差、最小值、最大值、范围、偏度、峰度、按变量列表,点击继续一一确定。
N Mean Std. oration Skegness Ku 电$1$Statistic Statistic Sladi^tir Std F IT rr Statistic Rtri Frror存AT)裁金舉Valic N 2022::473S.00 10C45.569 6.234 .14533.B5G .289分析:由表中可以看出,有效样本为282份,存(取)款金额的均值是4738.09,标准差为10945.09,峰度系数为33.656,偏度系数为5.234。
《统计分析与SPSS的应用(第五版)》课后练习答案-(1)

《统计分析与S P S S的应用(第五版)》课后练习答案第一章练习题答案1、SPSS的中文全名是:社会科学统计软件包(后改名为:统计产品与服务解决方案)英文全名是:Statistical Package for the Social Science.(Statistical Product and Service Solutions)2、SPSS的两个主要窗口是数据编辑器窗口和结果查看器窗口。
●数据编辑器窗口的主要功能是定义SPSS数据的结构、录入编辑和管理待分析的数据;●结果查看器窗口的主要功能是现实管理SPSS统计分析结果、报表及图形。
3、SPSS的数据集:●SPSS运行时可同时打开多个数据编辑器窗口。
每个数据编辑器窗口分别显示不同的数据集合(简称数据集)。
●活动数据集:其中只有一个数据集为当前数据集。
SPSS只对某时刻的当前数据集中的数据进行分析。
4、SPSS的三种基本运行方式:●完全窗口菜单方式、程序运行方式、混合运行方式。
●完全窗口菜单方式:是指在使用SPSS的过程中,所有的分析操作都通过菜单、按钮、输入对话框等方式来完成,是一种最常见和最普遍的使用方式,最大优点是简洁和直观。
●程序运行方式:是指在使用SPSS的过程中,统计分析人员根据自己的需要,手工编写SPSS命令程序,然后将编写好的程序一次性提交给计算机执行。
该方式适用于大规模的统计分析工作。
●混合运行方式:是前两者的综合。
5、.sav是数据编辑器窗口中的SPSS数据文件的扩展名.spv是结果查看器窗口中的SPSS分析结果文件的扩展名.sps是语法窗口中的SPSS程序6、SPSS的数据加工和管理功能主要集中在编辑、数据等菜单中;统计分析和绘图功能主要集中在分析、图形等菜单中。
7、概率抽样(probability sampling):也称随机抽样,是指按一定的概率以随机原则抽取样本,抽取样本时每个单位都有一定的机会被抽中,每个单位被抽中的概率是已知的,或是可以计算出来的。
《统计分析与SPSS的应用》课后练习答案
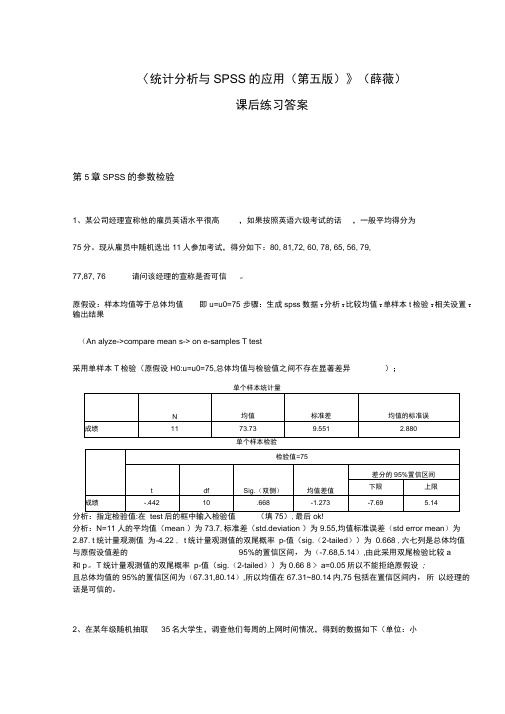
〈统计分析与SPSS的应用(第五版)》(薛薇)课后练习答案第5章SPSS的参数检验1、某公司经理宣称他的雇员英语水平很高,如果按照英语六级考试的话,一般平均得分为75分。
现从雇员中随机选出11人参加考试,得分如下:80, 81,72, 60, 78, 65, 56, 79,77,87, 76 请问该经理的宣称是否可信。
原假设:样本均值等于总体均值即u=u0=75 步骤:生成spss数据T分析T比较均值T单样本t检验T相关设置T 输出结果(An alyze->compare mean s-> on e-samples T test采用单样本T检验(原假设H0:u=u0=75,总体均值与检验值之间不存在显著差异);分析:N=11人的平均值(mean )为73.7,标准差(std.deviation )为9.55,均值标准误差(std error mean)为2.87. t统计量观测值为-4.22 , t统计量观测值的双尾概率p-值(sig.(2-tailed))为0.668 ,六七列是总体均值与原假设值差的95%的置信区间,为(-7.68,5.14),由此采用双尾检验比较a和p。
T统计量观测值的双尾概率p-值(sig.(2-tailed))为0.66 8 > a=0.05所以不能拒绝原假设;且总体均值的95%的置信区间为(67.31,80.14),所以均值在67.31~80.14内,75包括在置信区间内,所以经理的话是可信的。
2、在某年级随机抽取35名大学生,调查他们每周的上网时间情况,得到的数据如下(单位:小(1) 请利用SPSS 对上表数据进行描述统计,并绘制相关的图形。
(2)基于上表数据,请利用SPSS 给出大学生每周上网时间平均值的 9 5%的置信区间。
(1)分析描述统计描述、频率 (2)分析 比较均值 单样本T 检验每周上网时间的样本平均值为 27.5 ,标准差为10.7,总体均值95%的置信区间为23.8-31.2.3、经济学家认为决策者是对事实做出反应 ,不是对提出事实的方式做出反应 。
《统计分析与SPSS的应用(第五版)》课后练习答案

《统计分析与SPSS的应用(第五版)》课后练习答案第一章练习题答案1、SPSS的中文全名是:社会科学统计软件包(后改名为:统计产品与服务解决方案)英文全名是:Statistical Package for the Social Science.(Statistical Product and Service Solutions)2、SPSS的两个主要窗口是数据编辑器窗口和结果查看器窗口。
●数据编辑器窗口的主要功能是定义SPSS数据的结构、录入编辑和管理待分析的数据;●结果查看器窗口的主要功能是现实管理SPSS统计分析结果、报表及图形。
3、SPSS的数据集:●SPSS运行时可同时打开多个数据编辑器窗口。
每个数据编辑器窗口分别显示不同的数据集合(简称数据集)。
●活动数据集:其中只有一个数据集为当前数据集。
SPSS只对某时刻的当前数据集中的数据进行分析。
4、SPSS的三种基本运行方式:●完全窗口菜单方式、程序运行方式、混合运行方式。
●完全窗口菜单方式:是指在使用SPSS的过程中,所有的分析操作都通过菜单、按钮、输入对话框等方式来完成,是一种最常见和最普遍的使用方式,最大优点是简洁和直观。
●程序运行方式:是指在使用SPSS的过程中,统计分析人员根据自己的需要,手工编写SPSS命令程序,然后将编写好的程序一次性提交给计算机执行。
该方式适用于大规模的统计分析工作。
●混合运行方式:是前两者的综合。
5、.sav是数据编辑器窗口中的SPSS数据文件的扩展名.spv是结果查看器窗口中的SPSS分析结果文件的扩展名.sps是语法窗口中的SPSS程序6、SPSS的数据加工和管理功能主要集中在编辑、数据等菜单中;统计分析和绘图功能主要集中在分析、图形等菜单中。
7、概率抽样(probability sampling):也称随机抽样,是指按一定的概率以随机原则抽取样本,抽取样本时每个单位都有一定的机会被抽中,每个单位被抽中的概率是已知的,或是可以计算出来的。
统计分析与SPSS的应用第五版课后练习答案精编版

统计分析与S P S S的应用第五版课后练习答案公司内部编号:(GOOD-TMMT-MMUT-UUPTY-UUYY-DTTI-《统计分析与SPSS的应用(第五版)》(薛薇)课后练习答案第3章SPSS数据的预处理1、利用第2章第7题数据,采用SPSS数据筛选功能将数据分成两份文件。
其中,第一份数据文件存储常住地是“沿海或中心繁华城市”且本次存款金额在1000至5000之间的调查数据;第二份数据文件是按照简单随机抽样所选取的70%的样本数据。
第一份文件:选取数据数据——选择个案——如果条件满足——存款>=1000&存款<5000&常住地=沿海或中心繁华城市。
第二份文件:选取数据数据——选择个案——随机个案样本——输入70。
2、利用第2章第7题数据,将其按常住地(升序)、收入水平(升序)、存款金额(降序)进行多重排序。
排序数据——排序个案——把常住地、收入水平、存款金额作为排序依据分别设置排列顺序。
3、利用第2章第9题的完整数据,对每个学生计算得优课程数和得良课程数,并按得优课程数的降序排序。
计算转换——对个案内的值计数输入目标变量及目标标签,把所有课程选取到数字变量,定义值——设分数的区间,之后再排序。
4、利用第2章第9题的完整数据,计算每个学生课程的平均分以及标准差。
同时,计算男生和女生各科成绩的平均分。
方法一:利用描述性统计,数据——转置学号放在名称变量,全部课程放在变量框中,确定后,完成转置。
分析——描述统计——描述,将所有学生变量全选到变量框中,点击选项——勾选均值、标准差。
先拆分数据——拆分文件按性别拆分,分析——描述统计——描述,全部课程放在变量框中,选项——均值。
方法二:利用变量计算,转换——计算变量分别输入目标变量名称及标签——均值用函数mean完成平均分的计算,标准差用函数SD完成标准差的计算。
数据——分类汇总——性别作为分组变量、全部课程作为变量摘要、(创建只包含汇总变量的新数据集并命名)——确定5、利用第2章第7题数据,大致浏览存款金额的数据分布状况,并选择恰当的组限和组距进行组距分组。
《统计分析与SPSS的应用(第五版)》课后练习答案.doc(1)

《统计分析与SPSS的应⽤(第五版)》课后练习答案.doc(1)《统计分析与SPSS的应⽤(第五版)》课后练习答案第⼀章练习题答案1、SPSS的中⽂全名是:社会科学统计软件包(后改名为:统计产品与服务解决⽅案)英⽂全名是:Statistical Package for the Social Science.(Statistical Product and Service Solutions)2、SPSS的两个主要窗⼝是数据编辑器窗⼝和结果查看器窗⼝。
数据编辑器窗⼝的主要功能是定义SPSS数据的结构、录⼊编辑和管理待分析的数据;结果查看器窗⼝的主要功能是现实管理SPSS统计分析结果、报表及图形。
3、SPSS的数据集:SPSS运⾏时可同时打开多个数据编辑器窗⼝。
每个数据编辑器窗⼝分别显⽰不同的数据集合(简称数据集)。
活动数据集:其中只有⼀个数据集为当前数据集。
SPSS只对某时刻的当前数据集中的数据进⾏分析。
4、SPSS的三种基本运⾏⽅式:完全窗⼝菜单⽅式、程序运⾏⽅式、混合运⾏⽅式。
完全窗⼝菜单⽅式:是指在使⽤SPSS的过程中,所有的分析操作都通过菜单、按钮、输⼊对话框等⽅式来完成,是⼀种最常见和最普遍的使⽤⽅式,最⼤优点是简洁和直观。
程序运⾏⽅式:是指在使⽤SPSS的过程中,统计分析⼈员根据⾃⼰的需要,⼿⼯编写SPSS命令程序,然后将编写好的程序⼀次性提交给计算机执⾏。
该⽅式适⽤于⼤规模的统计分析⼯作。
混合运⾏⽅式:是前两者的综合。
5、.sav是数据编辑器窗⼝中的SPSS数据⽂件的扩展名.spv是结果查看器窗⼝中的SPSS分析结果⽂件的扩展名.sps是语法窗⼝中的SPSS程序6、SPSS的数据加⼯和管理功能主要集中在编辑、数据等菜单中;统计分析和绘图功能主要集中在分析、图形等菜单中。
7、概率抽样(probability sampling):也称随机抽样,是指按⼀定的概率以随机原则抽取样本,抽取样本时每个单位都有⼀定的机会被抽中,每个单位被抽中的概率是已知的,或是可以计算出来的。
《统计分析和SPSS的应用(第五版)》课后练习答案与解析(第9章)

《统计分析与SPSS的应用〔第五版〕》〔薛薇〕课后练习答案第9章SPSS的线性回归分析1、利用第2章第9题的数据,任意选择两门课程成绩作为解释变量和被解释变量,利用SPSS 提供的绘制散点图功能进行一元线性回归分析。
请绘制全部样本以与不同性别下两门课程成绩的散点图,并在图上绘制三条回归直线,其中,第一条针对全体样本,第二和第三条分别针对男生样本和女生样本,并对各回归直线的拟和效果进行评价。
选择fore和phy两门成绩体系散点图步骤:图形→旧对话框→散点图→简单散点图→定义→将fore导入Y轴,将phy导入X轴,将sex 导入设置标记→确定。
接下来在SPSS输出查看器中,双击上图,打开图表编辑在图表编辑器中,选择"元素"菜单→选择总计拟合线→选择线性→应用→再选择元素菜单→点击子组拟合线→选择线性→应用。
分析:如上图所示,通过散点图,被解释变量y<即:fore>与解释变量phy有一定的线性关系。
但回归直线的拟合效果都不是很好。
2、请说明线性回归分析与相关分析的关系是怎样的?相关分析是回归分析的基础和前提,回归分析则是相关分析的深入和继续。
相关分析需要依靠回归分析来表现变量之间数量相关的具体形式,而回归分析则需要依靠相关分析来表现变量之间数量变化的相关程度。
只有当变量之间存在高度相关时,进行回归分析寻求其相关的具体形式才有意义。
如果在没有对变量之间是否相关以与相关方向和程度做出正确判断之前,就进行回归分析,很容易造成"虚假回归"。
与此同时,相关分析只研究变量之间相关的方向和程度,不能推断变量之间相互关系的具体形式,也无法从一个变量的变化来推测另一个变量的变化情况,因此,在具体应用过程中,只有把相关分析和回归分析结合起来,才能达到研究和分析的目的。
线性回归分析是相关性回归分析的一种,研究的是一个变量的增加或减少会不会引起另一个变量的增加或减少。
3、请说明为什么需要对线性回归方程进行统计检验?一般需要对哪些方面进行检验?检验其可信程度并找出哪些变量的影响显著、哪些不显著。
最新《统计分析与SPSS的应用(第五版)》课后练习答案(第8章)

《统计分析与SPSS的应用(第五版)》(薛薇)课后练习答案第8章SPSS的相关分析1、对15家商业企业进行客户满意度调查,同时聘请相关专家对这15家企业的综合竞争力进行评分,结果如下表。
编号客户满意度得分综合竞争力得分编号客户满意度得分综合竞争力得分1 90 70 9 10 602 100 80 10 20303 150 150 11 801004 130 14012701105 120 90 13 30106 110 120 14 50 407 40 20 15 60 508 140 130请问,这些数据能否说明企业的客户满意度与其综合竞争力存在较强的正相关,为什么?能。
步骤:(1)图形→旧对话框→散点/点状→简单分布→进行相应设置→确定;(2)再双击图形→元素→总计拟合线→拟合线→线性→确定(3)分析→相关→双变量→进行相关项设置→确定相关性客户满意度得分综合竞争力得分客户满意度得分Pearson 相关性 1 .864**显著性(双尾).000N 16 15综合竞争力得分Pearson 相关性.864** 1显著性(双尾).000N 15 15**. 在置信度(双测)为 0.01 时,相关性是显著的。
两者的简单相关系数为0.864,说明存在正的强相关性。
2、为研究香烟消耗量与肺癌死亡率的关系,收集下表数据。
(说明:1930年左右几乎极少的妇女吸烟;采用1950年的肺癌死亡率是考虑到吸烟的效果需要一段时间才可显现)。
国家1930年人均香烟消耗量1950年每百万男子中死于肺癌的人数澳大利亚480 180加拿大500 150丹麦380 170芬兰1100 350英国1100 460荷兰490 240冰岛230 60挪威250 90瑞典300 110瑞士510 250美国1300 200绘制上述数据的散点图,并计算相关系数,说明香烟消耗量与肺癌死亡率之间是否存在显著的相关关系。
香烟消耗量与肺癌死亡率的散点图(操作方法与第1题相同)相关性人均香烟消耗死于肺癌人数人均香烟消耗Pearson 相关性 1 .737**显著性(双尾).010N 11 11死于肺癌人数Pearson 相关性.737** 1显著性(双尾).010N 11 11**. 在置信度(双测)为 0.01 时,相关性是显著的。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
《统计分析与SPSS的应用(第五版)》(薛薇)
课后练习答案
第8章SPSS的相关分析
1、对15家商业企业进行客户满意度调查,同时聘请相关专家对这15家企业的综合竞争力进行评分,结果如下表。
编号客户满意度得分综合竞争力得分编号客户满意度得分综合竞争力得分
1 90 70 9 10 60
2 100 80 10 20 30
3 150 150 11 80 100
4 130 140 12 70 110
5 120 90 13 30 10
6 110 120 14 50 40
7 40 20 15 60 50
8 140 130
请问,这些数据能否说明企业的客户满意度与其综合竞争力存在较强的正相关,为什么?
能。
步骤:(1)图形旧对话框散点/点状简单分布进行相应设置确定;(2)再双击图形元素总计拟合线拟合线线性确定
(3)分析相关双变量进行相关项设置确定
相关性
客户满意度得分综合竞争力得分
** 客户满意度得分Pearson 相关性 1 .864
显著性(双尾).000
N 16 15 综合竞争力得分Pearson 相关性.864 ** 1
显著性(双尾).000
N 15 15 **. 在置信度(双测)为0.01 时,相关性是显著的。
两者的简单相关系数为0.864,说明存在正的强相关性。
2、为研究香烟消耗量与肺癌死亡率的关系,收集下表数据。
(说明:1930年左右几乎极少的妇女吸烟;采用1950年的肺癌死亡率是考虑到吸烟的效果需要一段时间才可显现)。
国家1930 年人均香烟消耗量1950 年每百万男子中死于肺癌的人数
澳大利亚480 180
加拿大500 150
丹麦380 170
芬兰1100 350
英国1100 460
荷兰490 240
冰岛230 60
挪威250 90
瑞典300 110
瑞士510 250
美国1300 200
绘制上述数据的散点图,并计算相关系数,说明香烟消耗量与肺癌死亡率之间是否存在显
著的相关关系。
香烟消耗量与肺癌死亡率的散点图(操作方法与第 1 题相同)
相关性
人均香烟消耗死于肺癌人数
**
人均香烟消耗Pearson 相关性 1 .737
显著性(双尾).010
N 11 11
死于肺癌人数Pearson 相关性.737 ** 1
显著性(双尾).010
N 11 11
**. 在置信度(双测)为0.01 时,相关性是显著的。
相关系数为0.737。
因概率P 值小于显著性水平(0.05),拒绝原假设,认为两者存在显著关系。
3. 收集到某商品在不同地区的销售额、销售价格以及该地区平均家庭收入的数据,如下表:
销售额(万元)销售价格(元)收入
100.0 50.00 10000.00
75.0 70.00 6000.00
80.0 60.00 12000.00
70.0 60.00 5000.00
50.0 80.00 3000.00
65.0 70.00 4000.00
90.0 50.00 13000.00
100.0 40.00 11000.00
110.0 30.00 13000.00
60.0 90.00 3000.00
1)绘制销售额、销售价格以及家庭收入两两变量间的散点图。
如果所绘制的图形不能较清
晰地展示变量之间的关系,应对数据如何处理后再绘图。
2)选择恰当的统计方法分析销售额与销售价格之间的相关关系。
(1)
如果所绘制的图形不能较清晰地展示变量之间的关系,应对散点图进行调整。
在SPSS 查看器窗口中选中相应的散点图双击鼠标,进入SPSS图形编辑器窗口。
选中【选项】菜单
下的【分箱元素】子菜单进行数据合并。
(2)
分析相关偏相关进行相关项设置确定
相关性
控制变量销售额(万元)销售价格(元)家庭收入(元)a
- 无- 销售额(万元)相关性 1.000 -.933 .880
显著性(双侧). .000 .001
df 0 8 8 销售价格(元)相关性-.933 1.000 -.857
显著性(双侧).000 . .002
df 8 0 8 家庭收入(元)相关性.880 -.857 1.000
显著性(双侧).001 .002 .
df 8 8 0 家庭收入(元)销售额(万元)相关性 1.000 -.728
显著性(双侧). .026
df 0 7
销售价格(元)相关性-.728 1.000
显著性(双侧).026 .
df 7 0
a. 单元格包含零阶(Pearson) 相关。
如表所示,在家庭收入作为控制变量的条件下,销售额和价格的偏相关系数为-0.728,
呈一定的负相关关系,且统计关系显著。