贪心算法实验(最小生成树)
最小生成树 实验报告

最小生成树实验报告最小生成树实验报告一、引言最小生成树是图论中的一个重要概念,它在实际问题中有着广泛的应用。
本次实验旨在通过编程实现最小生成树算法,并通过实验数据对算法进行分析和评估。
二、算法介绍最小生成树算法的目标是在给定的带权无向图中找到一棵生成树,使得树上所有边的权重之和最小。
本次实验我们选择了两种经典的最小生成树算法:Prim 算法和Kruskal算法。
1. Prim算法Prim算法是一种贪心算法,它从一个顶点开始,逐步扩展生成树的规模,直到包含所有顶点为止。
算法的具体步骤如下:(1)选择一个起始顶点,将其加入生成树中。
(2)从与生成树相邻的顶点中选择一个权重最小的边,将其加入生成树中。
(3)重复上述步骤,直到生成树包含所有顶点。
2. Kruskal算法Kruskal算法是一种基于并查集的贪心算法,它首先将图中的边按权重从小到大进行排序,然后逐个加入生成树中,直到生成树包含所有顶点为止。
算法的具体步骤如下:(1)将图中的边按权重从小到大进行排序。
(2)逐个加入边,如果该边的两个顶点不在同一个连通分量中,则将其加入生成树中。
(3)重复上述步骤,直到生成树包含所有顶点。
三、实验过程本次实验我们使用C++语言实现了Prim算法和Kruskal算法,并通过随机生成的图数据进行了测试。
1. Prim算法的实现我们首先使用邻接矩阵表示图的结构,然后利用优先队列来选择权重最小的边。
具体实现过程如下:(1)创建一个优先队列,用于存储生成树的候选边。
(2)选择一个起始顶点,将其加入生成树中。
(3)将与生成树相邻的顶点及其边加入优先队列。
(4)从优先队列中选择权重最小的边,将其加入生成树中,并更新优先队列。
(5)重复上述步骤,直到生成树包含所有顶点。
2. Kruskal算法的实现我们使用并查集来维护顶点之间的连通关系,通过排序后的边序列来逐个加入生成树中。
具体实现过程如下:(1)将图中的边按权重从小到大进行排序。
用破圈法求最小生成树的算法

用破圈法求最小生成树的算法
求最小生成树是搜索树上每条边将权值加起来最小的那棵树,也就是要
求在给定顶点的一组边的条件下求出最小的生成树,一般采用贪心算法来求解。
其中最常用的算法就是破圈法。
破圈法实质上是 Prim 算法的改进,是一种贪心算法。
它的基本思想是:试着将边依次加入最小生成树中,当已生成的最小生成树中的边形成了一个
环的时候,其中的边中权值最大的一条被舍弃,存在于两个不同的顶点间。
破圈法求最小生成树算法基本步骤如下:
1.初始化最小生成树,构造一个空集合;
2.从贴源点开始,找出所有连接源点的边中权值最小的增加一条边到空集合中;
3.重复上述步骤,在剩余边权中选出最小值,增加一条边,并保证了加入当
前边后不产生环;
4.当把所有边都添加到集合中,即得到最小生成树;
破圈法的复杂度是O(n^2),由于它具有简单的求解过程和易于实现的特性,因而得到广泛的应用。
破圈法非常适合在网络中采用,它可以容易的获
得一条路径的最小权值生成树从而实现网络的最佳路径匹配。
破圈法可以证明:当每一条边都属于给定顶点集合时,最小生成树一定
存在。
因此它在可以用来求解最小生成树的问题中是非常有效的。
的最小生成树算法Prim与Kruskal算法的比较

的最小生成树算法Prim与Kruskal算法的比较Prim算法和Kruskal算法都是常用的最小生成树算法,它们可以在给定的加权连通图中找到连接所有节点的最小权重边集合。
然而,这两种算法在实现细节和时间复杂度上有所不同。
本文将对Prim算法和Kruskal算法进行比较,并讨论它们的优缺点以及适用场景。
一、Prim算法Prim算法是一种贪心算法,它从一个起始节点开始,逐步扩展最小生成树的边集合,直到包含所有节点为止。
具体步骤如下:1. 选取一个起始节点作为最小生成树的根节点。
2. 在最小生成树的边集合中寻找与当前树集合相连的最小权重边,并将这条边添加到最小生成树中。
3. 将新添加的节点加入到树集合中。
4. 重复步骤2和3,直到最小生成树包含所有节点为止。
Prim算法的时间复杂度为O(V^2),其中V是节点的个数。
这是因为在每轮迭代中,需要从树集合以外的节点中找到与树集合相连的最小权重边,而在最坏情况下,可能需要检查所有的边。
二、Kruskal算法Kruskal算法是一种基于边的贪心算法,它按照边的权重从小到大的顺序依次选择边,并判断是否加入最小生成树中。
具体步骤如下:1. 初始化一个空的最小生成树。
2. 将所有边按照权重从小到大进行排序。
3. 依次检查每条边,如果这条边连接了两个不同的树(即不会形成环),则将这条边加入到最小生成树中。
4. 重复步骤3,直到最小生成树包含所有节点为止。
Kruskal算法使用并查集数据结构来快速判断连通性,时间复杂度为O(ElogE),其中E是边的个数。
排序边的时间复杂度为O(ElogE),而对每条边进行判断和合并操作的时间复杂度为O(E)。
三、比较与总结1. 时间复杂度:Prim算法的时间复杂度为O(V^2),而Kruskal算法的时间复杂度为O(ElogE)。
因此,在边的数量较大的情况下,Kruskal 算法的效率优于Prim算法。
2. 空间复杂度:Prim算法需要维护一个大小为V的优先队列和一个大小为V的布尔数组,而Kruskal算法需要维护一个大小为V的并查集。
Boruvka算法求最小生成树
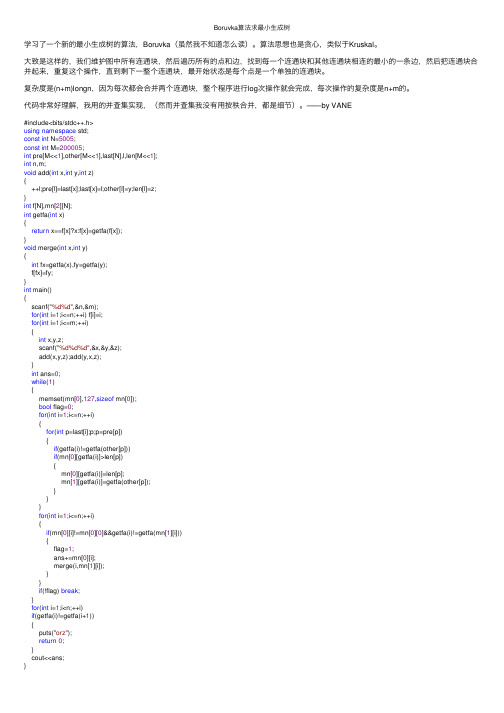
Boruvka算法求最⼩⽣成树学习了⼀个新的最⼩⽣成树的算法,Boruvka(虽然我不知道怎么读)。
算法思想也是贪⼼,类似于Kruskal。
⼤致是这样的,我们维护图中所有连通块,然后遍历所有的点和边,找到每⼀个连通块和其他连通块相连的最⼩的⼀条边,然后把连通块合并起来,重复这个操作,直到剩下⼀整个连通块,最开始状态是每个点是⼀个单独的连通块。
复杂度是(n+m)longn,因为每次都会合并两个连通块,整个程序进⾏log次操作就会完成,每次操作的复杂度是n+m的。
代码⾮常好理解,我⽤的并查集实现,(然⽽并查集我没有⽤按秩合并,都是细节)。
——by VANE#include<bits/stdc++.h>using namespace std;const int N=5005;const int M=200005;int pre[M<<1],other[M<<1],last[N],l,len[M<<1];int n,m;void add(int x,int y,int z){++l;pre[l]=last[x];last[x]=l;other[l]=y;len[l]=z;}int f[N],mn[2][N];int getfa(int x){return x==f[x]?x:f[x]=getfa(f[x]);}void merge(int x,int y){int fx=getfa(x),fy=getfa(y);f[fx]=fy;}int main(){scanf("%d%d",&n,&m);for(int i=1;i<=n;++i) f[i]=i;for(int i=1;i<=m;++i){int x,y,z;scanf("%d%d%d",&x,&y,&z);add(x,y,z);add(y,x,z);}int ans=0;while(1){memset(mn[0],127,sizeof mn[0]);bool flag=0;for(int i=1;i<=n;++i){for(int p=last[i];p;p=pre[p]){if(getfa(i)!=getfa(other[p]))if(mn[0][getfa(i)]>len[p]){mn[0][getfa(i)]=len[p];mn[1][getfa(i)]=getfa(other[p]);}}}for(int i=1;i<=n;++i){if(mn[0][i]!=mn[0][0]&&getfa(i)!=getfa(mn[1][i])){flag=1;ans+=mn[0][i];merge(i,mn[1][i]);}}if(!flag) break;}for(int i=1;i<n;++i)if(getfa(i)!=getfa(i+1)){puts("orz");return0;}cout<<ans;}。
最小生成树及克鲁斯卡尔算法

最小生成树及克鲁斯卡尔算法
最小生成树是指在一个连通的无向图中,找到一棵生成树,使得所有
边的权值之和最小。
克鲁斯卡尔算法是一种用来求解最小生成树的贪
心算法。
克鲁斯卡尔算法的基本思想是将所有边按照权值从小到大排序,然后
依次加入生成树中,如果加入某条边会形成环,则不加入该边。
直到
生成树中有n-1条边为止,其中n为图中节点的个数。
克鲁斯卡尔算法的时间复杂度为O(ElogE),其中E为边的数量。
因为需要对所有边进行排序,所以时间复杂度与边的数量有关。
最小生成树的应用非常广泛,例如在网络设计、电力传输、交通规划
等领域都有重要的应用。
在网络设计中,最小生成树可以用来构建网
络拓扑结构,使得网络的总成本最小。
在电力传输中,最小生成树可
以用来确定输电线路的布局,使得电力传输的成本最小。
在交通规划中,最小生成树可以用来确定道路的布局,使得交通运输的成本最小。
除了克鲁斯卡尔算法,还有其他求解最小生成树的算法,例如Prim算法、Boruvka算法等。
这些算法的基本思想都是贪心算法,但具体实
现方式有所不同。
总之,最小生成树是图论中的一个重要问题,克鲁斯卡尔算法是一种常用的求解最小生成树的算法。
在实际应用中,需要根据具体情况选择合适的算法,并结合实际需求进行优化。
贪心算法Kruskal 算法

Kruskal 算法假设给定一个加权连通图G,G的边集合为E,顶点个数为n,要求其一棵最小生成树T。
Kruskal 算法的粗略描述:假设T中的边和顶点均涂成红色,其余边为白色。
开始时G中的边均为白色。
1)将所有顶点涂成红色;2)在白色边中,挑选一条权最小的边,使其与红色边不形成圈,将该白色边涂红;3)重复2)直到有n-1条红色边,这n-1条红色边便构成最小生成树T的边集合。
注意到在算法执行过程中,红色顶点和红色边会形成一个或多个连通分支,它们都是G的子树。
一条边与红色边形成圈当且仅当这条边的两个端点属于同一个子树。
因此判定一条边是否与红色边形成圈,只需判断这条边的两端点是否属于同一个子树。
上述判断可以如此实现:给每个子树一个不同的编号,对每一个顶点引入一个标记t,表示这个顶点所在的子树编号。
当加入一条红色边,就会使该边两端点所在的两个子树连接起来,成为一个子树,从而两个子树中的顶点标记要改变成一样。
综上,可将Kruskal算法细化使其更容易计算机实现。
代码://Kruskal#include "stdio.h"#define maxver 10#define maxright 100int G[maxver][maxver],record=0,touched[maxver][maxver];int circle=0;int FindCircle(int,int,int,int);void main(){int path[maxver][2],used[maxver][maxver];int i,j,k,t,min=maxright,exsit=0;int v1,v2,num,temp,status=0;restart:printf("Please enter the number of vertex(s) in the graph:\n");scanf("%d",&num);if(num>maxver||num<0){printf("Error!Please reinput!\n");goto restart;}for(j=0;j<num;j++)for(k=0;k<num;k++){if(j==k){G[j][k]=maxright;used[j][k]=1;}elseif(j<k){re:printf("Please input the right between vertex %d and vertex %d,if no edge exists please input -1:\n",j+1,k+1);scanf("%d",&temp);if(temp>=maxright||temp<-1){printf("Invalid input!\n");goto re;}if(temp==-1)temp=maxright;G[j][k]=G[k][j]=temp;used[j][k]=used[k][j]=0;touched[j][k]=touched[k][j]=0;}}for(j=0;j<num;j++){path[j][0]=0;path[j][1]=0;}for(j=0;j<num;j++){status=0;for(k=0;k<num;k++)if(G[j][k]<maxright){status=1;break;}if(status==0)break;}for(i=0;i<num-1&&status;i++){for(j=0;j<num;j++)for(k=0;k<num;k++)if(G[j][k]<min&&!used[j][k]){v1=j;v2=k;min=G[j][k];}if(!used[v1][v2])used[v2][v1]=1;touched[v1][v2]=1;touched[v2][v1]=1;path[i][0]=v1;path[i][1]=v2;for(t=0;t<record;t++)FindCircle(path[t][0],path[t][0],num,path[t][0]);if(circle){/*if a circle exsits,roll back*/circle=0;i--;exsit=0;touched[v1][v2]=0;touched[v2][v1]=0;min=maxright;}else{record++;min=maxright;}}}if(!status)printf("We cannot deal with it because the graph is not connected!\n"); else{for(i=0;i<num-1;i++)printf("Path %d:vertex %d to vertex %d\n",i+1,path[i][0]+1,path[i][1]+1); }}int FindCircle(int start,int begin,int times,int pre){ /* to judge whether a circle is produced*/int i;for(i=0;i<times;i++)if(touched[begin][i]==1){if(i==start&&pre!=start){circle=1;return 1;break;}elseif(pre!=i)FindCircle(start,i,times,begin);else continue; }return 1; }。
因为贪心而失败的例子
因为贪心而失败的例子贪心算法是一种常用的解决问题的算法思想,它通常在每一步选择中都采取当前状态下最好或最优的选择,从而希望最终能够达到全局最优的结果。
然而,贪心算法的贪心选择可能会导致最终结果并非全局最优,而是局部最优或者根本无法得到可行解。
因此,贪心算法在某些问题上会因为贪心而失败。
下面将列举10个因为贪心而失败的例子。
1. 颜色分配问题:假设有n个节点需要着色,并且相邻的节点不能具有相同的颜色。
贪心算法选择每次都选择可用颜色最少的节点进行着色。
然而,这种贪心选择可能会导致最终无法着色所有节点,因为后续节点的颜色选择受到前面节点的限制。
2. 找零问题:假设需要找零的金额为m,而只有面额为1元、5元、10元的硬币。
贪心算法选择每次都选择面额最大的硬币进行找零。
然而,在某些情况下,贪心选择可能会导致找零的硬币数量不是最小的。
3. 最小生成树问题:在一个连通图中,选择一些边构成一个树,使得这些边的权值之和最小,同时保证图中的所有节点都能够通过这些边连通。
贪心算法选择每次都选择权值最小的边加入到树中。
然而,这种贪心选择可能会导致最终得到的树不是最小生成树。
4. 背包问题:给定一组物品,每个物品有自己的重量和价值,在给定的背包容量下,选择一些物品放入背包中,使得背包中物品的总价值最大。
贪心算法选择每次都选择单位重量价值最大的物品放入背包中。
然而,在某些情况下,贪心选择可能会导致最终得到的背包价值不是最大的。
5. 最短路径问题:在一个有向图中,找到两个节点之间的最短路径。
贪心算法选择每次都选择距离最近的节点进行扩展。
然而,这种贪心选择可能会导致最终得到的路径不是最短的。
6. 任务调度问题:给定一组任务,每个任务有自己的开始时间和结束时间,在给定的时间段内,选择一些任务进行调度,使得能够完成尽可能多的任务。
贪心算法选择每次都选择结束时间最早的任务进行调度。
然而,在某些情况下,贪心选择可能会导致最终完成的任务数量不是最多的。
采用普里姆算法和克鲁斯卡尔算法,求最小生成树
采用普里姆算法和克鲁斯卡尔算法,求最小生成树普利姆算法(Prim's Algorithm)和克鲁斯卡尔算法(Kruskal's Algorithm)是求解最小生成树的两种常用方法。
最小生成树是指连接图中所有节点,且边的权重和最小的树。
这两种算法各有特点,在不同的场景中使用。
1.普利姆算法:适用于边稠密的图普利姆算法是一种贪心算法,从一个节点开始,不断选择与当前树相连的、权重最小的边,并将该边连接的节点加入树中,直到所有节点都被遍历完。
这样就得到了最小生成树。
以下是普利姆算法的伪代码:1.创建一个空的树,用于保存最小生成树2.选择一个起始节点,将其加入树中3.从树中已有的节点出发,找到与树相连的边中权重最小的边4.将找到的边连接的节点加入树中5.重复步骤3和4,直到所有节点都加入树中普利姆算法的时间复杂度为O(ElogV),其中E为边的数量,V为节点的数量。
2.克鲁斯卡尔算法:适用于边稀疏的图克鲁斯卡尔算法是一种基于排序和并查集的贪心算法,按照边的权重从小到大的顺序选择,并判断是否会构成环。
如果不会构成环,则选择该边,并将其加入最小生成树中,直到所有节点都被连接。
以下是克鲁斯卡尔算法的伪代码:1.创建一个空的树,用于保存最小生成树2.将所有边按权重从小到大排序3.创建一个并查集,用于判断边是否会构成环4.遍历排序后的边,对于每条边,判断其连接的两个节点是否属于同一个集合(即是否会构成环)5.如果不会构成环,则选择该边,并将其加入树中,同时将该边连接的两个节点合并到同一个集合中6.重复步骤4和5,直到所有节点都连接在一起克鲁斯卡尔算法的时间复杂度为O(ElogE),其中E为边的数量。
这两种算法的应用场景有所不同。
如果要求解的图是边稠密的(即边的数量接近节点数量的平方),则使用普利姆算法更为高效。
因为普利姆算法的时间复杂度与边的数量有关,所以处理边稠密的图会更快一些。
而对于边稀疏的图(即边的数量接近节点数量的线性),克鲁斯卡尔算法更加适用,因为它的时间复杂度与边的数量有关。
算法实验报告贪心
一、实验背景贪心算法是一种在每一步选择中都采取当前状态下最好或最优的选择,从而希望导致结果是全局最好或最优的算法策略。
贪心算法并不保证能获得最优解,但往往能获得较好的近似解。
在许多实际应用中,贪心算法因其简单、高效的特点而被广泛应用。
本实验旨在通过编写贪心算法程序,解决经典的最小生成树问题,并分析贪心算法的优缺点。
二、实验目的1. 理解贪心算法的基本原理和应用场景;2. 掌握贪心算法的编程实现方法;3. 分析贪心算法的优缺点,并尝试改进;4. 比较贪心算法与其他算法在解决最小生成树问题上的性能。
三、实验内容1. 最小生成树问题最小生成树问题是指:给定一个加权无向图,找到一棵树,使得这棵树包含所有顶点,且树的总权值最小。
2. 贪心算法求解最小生成树贪心算法求解最小生成树的方法是:从任意一个顶点开始,每次选择与当前已选顶点距离最近的顶点,将其加入生成树中,直到所有顶点都被包含在生成树中。
3. 算法实现(1)数据结构- 图的表示:邻接矩阵- 顶点集合:V- 边集合:E- 已选顶点集合:selected- 最小生成树集合:mst(2)贪心算法实现```def greedy_mst(graph):V = set(graph.keys()) # 顶点集合selected = set() # 已选顶点集合mst = set() # 最小生成树集合for i in V:selected.add(i)mst.add((i, graph[i]))while len(selected) < len(V):min_edge = Nonefor edge in mst:u, v = edgeif v not in selected and (min_edge is None or graph[u][v] < graph[min_edge[0]][min_edge[1]]):min_edge = edgeselected.add(min_edge[1])mst.add(min_edge)return mst```4. 性能分析为了比较贪心算法与其他算法在解决最小生成树问题上的性能,我们可以采用以下两种算法:(1)Prim算法:从任意一个顶点开始,逐步添加边,直到所有顶点都被包含在生成树中。
克里斯卡尔算法最小生成树
克里斯卡尔算法最小生成树什么是克里斯卡尔算法?克里斯卡尔算法是一种求解最小生成树(Minimum Spanning Tree, MST)的算法,它采用贪心算法的思想,在给定一个连通图的情况下,通过逐步选择边来生成树,最终得到权值和最小的生成树。
为了更好地理解克里斯卡尔算法,我们首先要明确最小生成树的概念。
在一个连通图中,最小生成树是指连接图中所有顶点的树,并且树上所有边的权值之和最小。
生成树是一个无环的连通图,具有n个顶点的连通图的生成树必然含有n-1条边。
克里斯卡尔算法的步骤如下:1. 初始化:将图中的每个顶点看作是一个单独的树,每个树只包含一个节点。
同时,创建一个空的边集合用于存储最小生成树的边。
2. 对所有边按照权值进行升序排列。
3. 依次选择权值最小的边,并判断该边连接的两个节点是否属于不同的树(不属于同一个连通分量)。
4. 如果两个节点不属于同一个树,则将这条边添加到边集合中,并将两个节点合并为同一个连通分量。
5. 重复步骤3和步骤4,直到最小生成树的边数达到n-1条为止。
6. 返回边集合,即为最小生成树。
通过这个步骤的执行,克里斯卡尔算法能够保证运行过程中生成的树权值和是最小的。
这是因为在选择边时,我们总是选择权值最小且不会形成环路的边,这样生成的树就不会包含多余的边。
需要注意的是,克里斯卡尔算法适用于带权无向连通图,如果是带权有向图,需要先进行转化为无向图的操作。
另外,克里斯卡尔算法在实际应用中有着广泛的应用,比如网络设计、电路设计以及地图路线规划等领域。
总结一下,克里斯卡尔算法是一种通过贪心思想解决最小生成树问题的算法。
它通过逐步选择权值最小的边,并将不同的树合并为一个连通分量的方式,生成一个权值和最小的生成树。
在实际应用中,克里斯卡尔算法具有重要的意义,能够为我们提供高效、经济的解决方案。
通过了解和学习克里斯卡尔算法,我们能够更好地理解图论中的最小生成树问题,并运用其解决实际问题。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
算法分析与设计实验报告第一次附加实验
附录:
完整代码(贪心法)
//贪心算法最小生成树prim算法
#include<iostream>
#include<fstream>
#include<string>
#include<time.h>
#include<iomanip>
using namespace std;
#define inf 9999; //定义无限大的值const int N=6;
template<class Type> //模板定义
void Prim(int n,Type c[][N+1]);
int main()
{
int c[N+1][N+1];
cout<<"连通带权图的矩阵为:"<<endl;
for(int i=1;i<=N;i++) //输入邻接矩阵{
for(int j=1;j<=N;j++)
{
cin>>c[i][j];
}
}
cout<<"Prim算法最小生成树选边次序如下:"<<endl;
clock_t start,end,over; //计算程序运行时间的算法
start=clock();
end=clock();
over=end-start;
start=clock();
Prim(N,c); //调用Prim算法函数
end=clock();
printf("The time is %6.3f",(double)(end-start-over)/CLK_TCK); //显示运行时间cout<<endl;
system("pause");
return 0;
}
template<class Type>
//参数为结点个数n,和无向带权图中各结点之间的距离c[][N+1]
void Prim(int n,Type c[][N+1])
{
Type lowcost[N+1]; //记录c[j][closest]的最小权值
int closest[N+1]; //V-S中点j在s中的最临接顶点
bool s[N+1]; //标记各结点是否已经放入S集合¦
s[1]=true;
//初始化s[i],lowcost[i],closest[i]
for(int i=2;i<=n;i++)
{
lowcost[i]=c[1][i];
closest[i]=1;
s[i]=false;
}
for(int i=1;i<n;i++)
{
Type min=inf;
int j=1;
for(int k=2;k<=n;k++)//找出V-S中是lowcost最小的顶点j
{
if((lowcost[k]<min)&&(!s[k]))//如果k的lowcost比min小并且k结点没有被访问
{
min=lowcost[k]; //更新min的值
j=k;
}
}
cout<<j<<' '<<closest[j]<<endl; //输出j和最邻近j的点
s[j]=true; //将j添加到s中
for(int k=2;k<=n;k++)
{
if((c[j][k]<lowcost[k])&&(!s[k]))//s集合放进j后更新各结点的lowcost 的值
{
lowcost[k]=c[j][k];
closest[k]=j;
}
}
}
}。