新《计量经济学》第6章 计量练习题
计量经济学各章作业习题(后附答案)

《计量经济学》习题集第一章绪论一、单项选择题1、变量之间的关系可以分为两大类,它们是【】A 函数关系和相关关系B 线性相关关系和非线性相关关系C 正相关关系和负相关关系D 简单相关关系和复杂相关关系2、相关关系是指【】A 变量间的依存关系B 变量间的因果关系C 变量间的函数关系D 变量间表现出来的随机数学关系3、进行相关分析时,假定相关的两个变量【】A 都是随机变量B 都不是随机变量C 一个是随机变量,一个不是随机变量D 随机或非随机都可以4、计量经济研究中的数据主要有两类:一类是时间序列数据,另一类是【】A 总量数据B 横截面数据C平均数据 D 相对数据5、下面属于截面数据的是【】A 1991-2003年各年某地区20个乡镇的平均工业产值B 1991-2003年各年某地区20个乡镇的各镇工业产值C 某年某地区20个乡镇工业产值的合计数D 某年某地区20个乡镇各镇工业产值6、同一统计指标按时间顺序记录的数据列称为【】A 横截面数据B 时间序列数据C 修匀数据D原始数据7、经济计量分析的基本步骤是【】A 设定理论模型→收集样本资料→估计模型参数→检验模型B 设定模型→估计参数→检验模型→应用模型C 个体设计→总体设计→估计模型→应用模型D 确定模型导向→确定变量及方程式→估计模型→应用模型8、计量经济模型的基本应用领域有【】A 结构分析、经济预测、政策评价B 弹性分析、乘数分析、政策模拟C 消费需求分析、生产技术分析、市场均衡分析D 季度分析、年度分析、中长期分析9、计量经济模型是指【】A 投入产出模型B 数学规划模型C 包含随机方程的经济数学模型D 模糊数学模型10、回归分析中定义【】A 解释变量和被解释变量都是随机变量B 解释变量为非随机变量,被解释变量为随机变量C 解释变量和被解释变量都是非随机变量D 解释变量为随机变量,被解释变量为非随机变量11、下列选项中,哪一项是统计检验基础上的再检验(亦称二级检验)准则【】A. 计量经济学准则 B 经济理论准则C 统计准则D 统计准则和经济理论准则12、理论设计的工作,不包括下面哪个方面【】A 选择变量B 确定变量之间的数学关系C 收集数据D 拟定模型中待估参数的期望值13、计量经济学模型成功的三要素不包括【】A 理论B 应用C 数据D 方法14、在经济学的结构分析中,不包括下面那一项【】A 弹性分析B 乘数分析C 比较静力分析D 方差分析二、多项选择题1、一个模型用于预测前必须经过的检验有【】A 经济准则检验B 统计准则检验C 计量经济学准则检验D 模型预测检验E 实践检验2、经济计量分析工作的四个步骤是【】A 理论研究B 设计模型C 估计参数D 检验模型E 应用模型3、对计量经济模型的计量经济学准则检验包括【】A 误差程度检验B 异方差检验C 序列相关检验D 超一致性检验E 多重共线性检验4、对经济计量模型的参数估计结果进行评价时,采用的准则有【】A 经济理论准则B 统计准则C 经济计量准则D 模型识别准则E 模型简单准则三、名词解释1、计量经济学2、计量经济学模型3、时间序列数据4、截面数据5、弹性6、乘数四、简述1、简述经济计量分析工作的程序。
计量经济学课后习题答案

计量经济学练习题第一章导论一、单项选择题⒈计量经济研究中常用的数据主要有两类:一类是时间序列数据,另一类是【 B 】A 总量数据B 横截面数据C平均数据 D 相对数据⒉横截面数据是指【 A 】A 同一时点上不同统计单位相同统计指标组成的数据B 同一时点上相同统计单位相同统计指标组成的数据C 同一时点上相同统计单位不同统计指标组成的数据D 同一时点上不同统计单位不同统计指标组成的数据⒊下面属于截面数据的是【 D 】A 1991-2003年各年某地区20个乡镇的平均工业产值B 1991-2003年各年某地区20个乡镇的各镇工业产值C 某年某地区20个乡镇工业产值的合计数D 某年某地区20个乡镇各镇工业产值⒋同一统计指标按时间顺序记录的数据列称为【 B 】A 横截面数据B 时间序列数据C 修匀数据 D原始数据⒌回归分析中定义【 B 】A 解释变量和被解释变量都是随机变量B 解释变量为非随机变量,被解释变量为随机变量C 解释变量和被解释变量都是非随机变量D 解释变量为随机变量,被解释变量为非随机变量二、填空题⒈计量经济学是经济学的一个分支学科,是对经济问题进行定量实证研究的技术、方法和相关理论,可以理解为数学、统计学和_经济学_三者的结合。
⒉现代计量经济学已经形成了包括单方程回归分析,联立方程组模型,时间序列分析三大支柱。
⒊经典计量经济学的最基本方法是回归分析。
计量经济分析的基本步骤是:理论(或假说)陈述、建立计量经济模型、收集数据、计量经济模型参数的估计、检验和模型修正、预测和政策分析。
⒋常用的三类样本数据是截面数据、时间序列数据和面板数据。
⒌经济变量间的关系有不相关关系、相关关系、因果关系、相互影响关系和恒等关系。
三、简答题⒈什么是计量经济学它与统计学的关系是怎样的计量经济学就是对经济规律进行数量实证研究,包括预测、检验等多方面的工作。
计量经济学是一种定量分析,是以解释经济活动中客观存在的数量关系为内容的一门经济学学科。
新《计量经济学》第6章 计量练习题

《计量经济学》第6章习题一、单项选择题1.当模型存在严重的多重共线性时,OLS 估计量将不具备( ) A .线性 B .无偏性 C .有效性 D .一致性2.如果每两个解释变量的简单相关系数比较高,大于( )时则可认为存在着较严重的多重共线性。
A .0.5B .0.6C .0.7D .0.83.方差扩大因子VIF j 可用来度量多重共线性的严重程度,经验表明,VIF j ( )时,说明解释变量与其余解释变量间有严重的多重共线性。
A .小于5B .大于1C .小于1D .大于104.对于模型01122i i i i Y X X u βββ=+++,与r 23等于0相比,当r 23等于0.5时,3ˆβ的方差将是原来的( )A .2倍B .1.5倍C .1.33倍D .1.25倍 5.无多重共线性假定是假定各解释变量之间不存在( )A .线性关系B .非线性关系C .自相关D .异方差 二、多项选择题1.多重共线性包括( )A .完全的多重共线性B .不完全的多重共线性C .解释变量间精确的线性关系D .解释变量间近似的线性关系E .非线性关系2.多重共线性产生的经济背景主要由( )A .经济变量之间具有共同变化趋势B .模型中包含滞后变量C .采用截面数据D .样本数据自身的原因E .模型设定误差 3.多重共线性检验的方法包括( )A .简单相关系数检验法B .方差扩大因子法C .直观判断法D .逐步回归法E .DW 检验法 4.修正多重共线性的经验方法包括( ) A .剔除变量法 B .增大样本容量C .变换模型形式D .截面数据与时间序列数据并用E .变量变换 5.严重的多重共线性常常会出现下列情形( ) A .适用OLS 得到的回归参数估计值不稳定 B .回归系数的方差增大C .回归方程高度显著的情况下,有些回归系数通不过显著性检验D .回归系数的正负号得不到合理的经济解释E .预测精度降低一、单项选择题1.C2.D3.D4.C5.A 二、多项选择题1.AB2.ABCD3.ABCD4.ABCDE5.ABCDE三、简答题1.什么是多重共线性?产生多重共线性的经济背景是什么?所谓多重共线性(Multicollinearity )是指线性回归模型中的解释变量之间由于存在精确相关关系或高度相关关系而使模型估计失真或难以估计准确。
第六章计量经济学

第六章 虚拟变量的回归模型第一部分 学习目标和要求本章主要介绍虚拟变量的基本概念及其应用。
需要掌握并理解以下内容:(1) 虚拟变量的基本概念、虚拟变量分别作为解释变量和被解释变量的情形、虚拟变量回归模型的类型和解释变量个数选取规则; (2) 定量变量与不同数量定性变量(一对一、一对多和多对多)虚拟变量模型; (3) 应用虚拟变量改变回归直线的截距或斜率; (4) 分段线性回归;(5) 应用虚拟变量检验回归模型的结构稳定性、传统判别结构稳定性的方法及存在的缺陷、虚拟变量法比较两个回归方程的结构方法。
第二部分 练习题一、解释下列概念:1.虚拟变量2.方差分析模型(ANOV A ) 3.协方差模型(ANOCV A ) 4.基底5.级差截距系数 6.虚拟变量陷阱二、简要回答下列问题:1.虚拟变量在线性回归模型中的作用是什么?举例说明。
2.回归模型中虚拟变量个数的选取原则是什么?为什么?3.如果现在有月度数据,在对下面的假设进行检验时,你将引入几个虚拟变量? A) 一年中的每月均呈现季节性波动趋势;B) 只有双数月份呈现季节性波动趋势。
4.如果现在让你着手检验上海和深圳两个股票市场在过去5年内的收益率是否有显著差异,如何使用虚拟变量进行?三、考虑如下模型:12i i i Y D u ββ=++其中,i D 对前20个观察值取0,对后30个观察值取1。
已知2()300i Var u =。
(1) 如何解释1β和2β? (2) 这两组的均值分别是多少?(3) 已知12()15Cov ββ∧∧+=-。
如何计算12()ββ∧∧+的方差?四、考虑如下模型:12i i i i Y D X u ααβ=+++ 其中Y 代表一位大学教授的年薪; X 为从教年限; D 为性别虚拟变量。
考虑定义虚拟变量的三种方式:(1)D 对男性取值1,对女性取值0; (2)D 对女性取值1,对男性取值2; (3)D 对女性取值1,对男性取值-1;对每种虚拟变量定义解释上述回归模型。
伍德里奇---计量经济学第6章部分计算机习题详解(STATA)
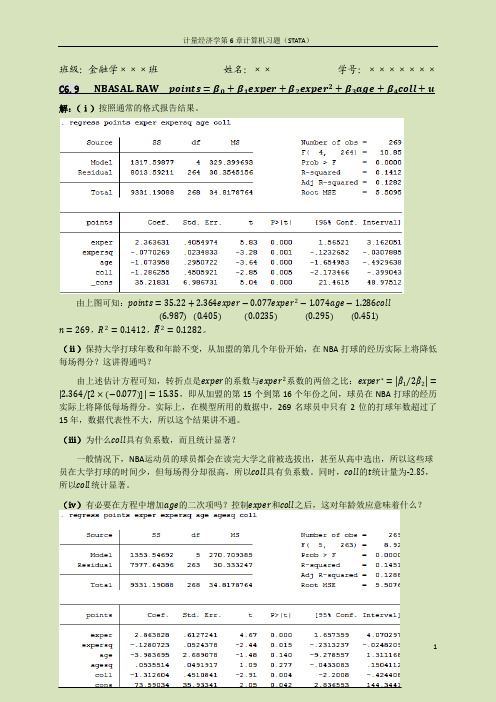
班级:金融学×××班姓名:××学号:×××××××C6.9 NBASAL.RAW points=β0+β1exper+β2exper2+β3age+β4coll+u 解:(ⅰ)按照通常的格式报告结果。
由上图可知:points=35.22+2.364exper−0.077exper2−1.074age−1.286coll6.9870.4050.02350.295 (0.451)n=269,R2=0.1412,R2=0.1282。
(ⅱ)保持大学打球年数和年龄不变,从加盟的第几个年份开始,在NBA打球的经历实际上将降低每场得分?这讲得通吗?由上述估计方程可知,转折点是exper的系数与exper2系数的两倍之比:exper∗= β12β2= 2.364[2×−0.077]=15.35,即从加盟的第15个到第16个年份之间,球员在NBA打球的经历实际上将降低每场得分。
实际上,在模型所用的数据中,269名球员中只有2位的打球年数超过了15年,数据代表性不大,所以这个结果讲不通。
(ⅲ)为什么coll具有负系数,而且统计显著?一般情况下,NBA运动员的球员都会在读完大学之前被选拔出,甚至从高中选出,所以这些球员在大学打球的时间少,但每场得分却很高,所以coll具有负系数。
同时,coll的t统计量为-2.85,所以coll统计显著。
(ⅳ)有必要在方程中增加age的二次项吗?控制exper和coll之后,这对年龄效应意味着什么?增加age的二次项后,原估计模型变成:points=73.59+2.864exper−0.128exper2−3.984age+0.054age2−1.313coll35.930.610.05 2.690.05 (0.45)n=269,R2=0.1451,R2=0.1288。
《计量经济学》第六章精选题及答案

第六章自相关二、问答题1、那些原因可以造成自相关;2、存在自相关时,参数的OLS估计具有哪些性质;3、如何检验是否存在自相关;4、当存在自相关时,如何利用广义差分法进行参数估计;5、当存在自相关时,如何利用广义最小平方估计法进行参数估计;6、异方差与自相关有什么异同;三、计算题1、证明:当样本个数较大时,)d。
≈-1(2ρα2、通过D-W检验,判断下列模型中是否存在自相关,显著性水平%5=(1)样本大小:20;解释变量个数(包括常数项):2;d=0.73;(2)样本大小:35;解释变量个数(包括常数项):3;d=3.56;(3)样本大小:50;解释变量个数(包括常数项):3;d=1.87;(4)样本大小:80;解释变量个数(包括常数项):6;d=1.62;(5)样本大小:100;解释变量个数(包括常数项):5;d=2.41;3、假定存在下表所示的时间序列数据:请回答下列问题:(1)利用表中数据估计模型:t t t x y εββ++=10;(2)利用D-W 检验是否存在自相关?如果存在请用d 值计算估计自相关系数ρ;(3)利用广义差分法重新估计模型:'''1011(1)()t t tt t y y x x ρβρβρε---=-+-+。
第三部分 参考答案二、问答题1、那些原因可以造成自相关?答:造成自相关的原因大致包括以下六个方面:(1)经济变量的变化具有一定的倾向性。
在实际的经济现象中,许多经济变量的现值依赖于他的前期值。
也就是说,许多经济时间序列都有一个明显的相依性特点,这种现象称作经济变量所具有的惯性。
(2)缺乏应有变量的设定偏差。
(3)不正确的函数形式的设定错误。
(4)蛛网现象和滞后效应。
(5)随机误差项的特征。
(6)数据拟合方法造成的影响。
2、存在自相关时,参数的OLS 估计具有哪些性质?答:当存在自相关,即I D ≠ΩΩ=,)(2σε时,OLS 估计的性质有:(1)βˆ是观察值Y 和X 的线性函数;(2)βˆ是β的无偏估计;(3)βˆ的协方差矩阵为112)()()ˆ(--'Ω''=X X X X X X D σβ;(4)βˆ不是β的最小方差线性无偏估计;(5)如果nX X n Ω'∞→lim存在,那么βˆ是β的一致估计;(6)2σ 不是2σ的无偏估计;(7)2σ不是2σ的一致估计。
庞皓《计量经济学》(第4版)章节题库-第6章 自相关【圣才出品】

形式,D 项解释变量是随机的。
3.给定的显著性水平,若 DW 统计量的下和上临界值分别为 dL 和 dU,则当 4-dL<DW<4 时,可认为随机误差项( )。
A.存在一阶正自相关 B.存在一阶负自相关 C.不存在序列相关 D.存在序列相关与否不能断定 【答案】B 【解析】DW 检验是一种检验序列自相关的方法,它按照下列准则考察计算得到的 DW 值,以判断模型的一阶自相关状态:①若 0<DW<dL,则存在正自相关;②若 dL<DW<dU,则不能确定;若 dU<DW<4-dU,则无自相关:③若 4-dU<DW<4-dL,则不能确定;④若 4-dL<DW<4,则存在负自相关。
台
估计的一种方法,但它却损失了部分样本观测值。
5.DW 值在 0 和 4 之间,数值越大说明正相关程度越大,数值越小说明负相关程度
越大。( )
【答案】×
【解析】由
n
e%t e%t 1
DW
21
t2 n
t 1
e%t 2
21
可知,DW 值是关于相关系数的递减函数,即当相关系数越大时,DW
2
1 2
B.
2
2
1 2
C.
1 2
D.
【答案】A
【解析】由于 Var(μt)=E(μt)2=E(ρμt-1+εt)
2=E(ρ2μt-12+εt2+2ρμt-1εt)=ρ2Var(μt-1)+σε2,所以 Var(μt)=σε2/(1-ρ2)。
3 / 23
圣才电子书
5 / 23
圣才电子书
十万种考研考证电子书、题库视频学习平 台
2.序列相关违背了哪项基本假定?其来源有哪些?检验方法有哪些,都适用于何种 形式的序列相关检验?
(完整word版)计量经济学习题及答案..

期中练习题1、回归分析中使用的距离是点到直线的垂直坐标距离。
最小二乘准则是指( )A .使∑=-n t tt Y Y 1)ˆ(达到最小值 B.使∑=-nt t t Y Y 1达到最小值 C. 使∑=-nt t tY Y12)(达到最小值 D.使∑=-nt tt Y Y 12)ˆ(达到最小值 2、根据样本资料估计得出人均消费支出 Y 对人均收入 X 的回归模型为ˆln 2.00.75ln i iY X =+,这表明人均收入每增加 1%,人均消费支出将增加 ( )A. 0.75B. 0.75%C. 2D. 7.5% 3、设k 为回归模型中的参数个数,n 为样本容量。
则对总体回归模型进行显著性检验的F 统计量与可决系数2R 之间的关系为( )A.)1/()1()/(R 22---=k R k n F B. )/(1)-(k )R 1/(R 22k n F --= C. )/()1(22k n R R F --= D. )1()1/(22R k R F --=6、二元线性回归分析中 TSS=RSS+ESS 。
则 RSS 的自由度为( )A.1B.n-2C.2D.n-39、已知五个解释变量线形回归模型估计的残差平方和为8002=∑te,样本容量为46,则随机误差项μ的方差估计量2ˆσ为( ) A.33.33 B.40 C.38.09 D. 201、经典线性回归模型运用普通最小二乘法估计参数时,下列哪些假定是正确的( ) A.0)E(u i = B. 2i )V ar(u i σ= C. 0)u E(u j i ≠D.随机解释变量X 与随机误差i u 不相关E. i u ~),0(2i N σ2、对于二元样本回归模型ii i i e X X Y +++=2211ˆˆˆββα,下列各式成立的有( ) A.0=∑ieB. 01=∑ii Xe C. 02=∑iiXeD.=∑ii Ye E.21=∑i iX X4、能够检验多重共线性的方法有( )A.简单相关系数矩阵法B. t 检验与F 检验综合判断法C. DW 检验法D.ARCH 检验法E.辅助回归法计算题1、为了研究我国经济发展状况,建立投资(1X ,亿元)与净出口(2X ,亿元)与国民生产总值(Y ,亿元)的线性回归方程并用13年的数据进行估计,结果如下:ii i X X Y 21051980.4177916.2805.3871ˆ++= S.E=(2235.26) (0.12) (1.28) 2R =0.99 F=582 n=13问题如下:①从经济意义上考察模型估计的合理性;(3分) ②估计修正可决系数2R ,并对2R 作解释;(3分)③在5%的显著性水平上,分别检验参数的显著性;在5%显著性水平上,检验模型的整体显著性。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
《计量经济学》第6章习题一、单项选择题1.当模型存在严重的多重共线性时,OLS 估计量将不具备( ) A .线性 B .无偏性 C .有效性 D .一致性2.如果每两个解释变量的简单相关系数比较高,大于( )时则可认为存在着较严重的多重共线性。
A .0.5B .0.6C .0.7D .0.83.方差扩大因子VIF j 可用来度量多重共线性的严重程度,经验表明,VIF j ( )时,说明解释变量与其余解释变量间有严重的多重共线性。
A .小于5B .大于1C .小于1D .大于104.对于模型01122i i i i Y X X u βββ=+++,与r 23等于0相比,当r 23等于0.5时,3ˆβ的方差将是原来的( )A .2倍B .1.5倍C .1.33倍D .1.25倍 5.无多重共线性假定是假定各解释变量之间不存在( )A .线性关系B .非线性关系C .自相关D .异方差 二、多项选择题1.多重共线性包括( )A .完全的多重共线性B .不完全的多重共线性C .解释变量间精确的线性关系D .解释变量间近似的线性关系E .非线性关系2.多重共线性产生的经济背景主要由( )A .经济变量之间具有共同变化趋势B .模型中包含滞后变量C .采用截面数据D .样本数据自身的原因E .模型设定误差 3.多重共线性检验的方法包括( )A .简单相关系数检验法B .方差扩大因子法C .直观判断法D .逐步回归法E .DW 检验法 4.修正多重共线性的经验方法包括( ) A .剔除变量法 B .增大样本容量C .变换模型形式D .截面数据与时间序列数据并用E .变量变换 5.严重的多重共线性常常会出现下列情形( ) A .适用OLS 得到的回归参数估计值不稳定 B .回归系数的方差增大C .回归方程高度显著的情况下,有些回归系数通不过显著性检验D .回归系数的正负号得不到合理的经济解释E .预测精度降低一、单项选择题1.C2.D3.D4.C5.A 二、多项选择题1.AB2.ABCD3.ABCD4.ABCDE5.ABCDE三、简答题1.什么是多重共线性?产生多重共线性的经济背景是什么?所谓多重共线性(Multicollinearity )是指线性回归模型中的解释变量之间由于存在精确相关关系或高度相关关系而使模型估计失真或难以估计准确。
一般来说,由于经济数据的限制使得模型设计不当,导致设计矩阵中解释变量间存在普遍的相关关系。
产生多重共线性的经济背景有经济变量之间存在共同变化趋势;利用截面数据研究经济现象;模型中大量引入滞后经济变量;样本数据自身的原因2.完全多重共线性与不完全多重共线性的区别是什么? 对于一般多元线性回归模型而言01122i k k i Y X X X u ββββ=+++++ (1)我们说回归模型(1)存在多重共线性,根据多重共线性的定义可知,它的某个解释变量可以写成其他一些解释变量的线性组合。
不妨设X 1可以写成其他某些解释变量的线性组合,则有:12233k k X X X X ααα=+++ (2)至少有一个0i α≠(2,3,,i k =),我们称这种情况为完全多重共线性。
这时X 1与右侧线性组合的相关系数是1。
在实际中很少遇到完全多重共线性的情况,常常是接近完全多重共线性或者高度多重共线性,我们以后提到的多重共线性都是指高度多重共线性。
不妨设X 1与其他解释变量高度共线性,即可以近似写成其他解释变量的线性组合,这时,有:12233k k i X X X X v ααα=++++ (3)至少有一个0i α≠(2,3,,i k =), i v 是随机误差项。
这时X 1与右侧线性组合的相关系数不是1,但接近于1 。
3.多重共线性的危害是什么?为何会造成这些危害?参数估计的后果:完全多重共线性下的参数估计为一“不定式”;不完全多重共线性下的参数估计为—渐近“不定式”;多重共线性下参数估计值的方差统计检验的后果:参数的显著性检验失败;完全多重共线性下的预测无意义;参数估计值的符号与经济意义相悖4.判断是否存在多重共线性的方法有哪些?(1)相关系数法。
作出各解释变量的相关系数矩阵,利用相关系数矩阵可以很容易看出自变量之间的共线性。
(2)辅助回归方法,即把多个解释变量中的一个作为因变量其余的作为自变量做回归分析看显著性。
还可以更具OLS 估计量的性质,得到估计参数的“方差膨胀因子”进行判断。
5.有哪些克服多重共线性的方法有哪些。
(1)模型的变量变换(差分模型;增长率模型);(2)先验信息的利用;参数的约束;数据的结合;截面数据的利用(3)其他方法:增加样本容量;剔除变量;改变模型的函数形; (4)逐步回归法 四、计算题1.在研究生产函数时,得到以下两种结果:1n Yˆt =-5.04 + 0.8871n K t + 0.8931n L t (A ) S.E.= (1.40) (0.087) (0.137) R 2=0.878 n =211n Yˆt =-8.57 + 0.0272T + 0.4601n K t + 1.2851n L t (B ) S.E.= (2.99) (0.020) (0.333) (0.324) R 2=0.889 n =21其中,Y =产量,K =资本,L =劳动,T =时间,n =样本容量。
请回答:(1)验证模型(A )中所有的系数在统计上都是显著的(5%); (2)验证模型(B )中T 和ln K 的系数在统计上不显著(5%); (3)可能什么原因造成了(B )中ln K 的系数不显著;(4)如果T 与ln K 的相关系数为0.98,你将如何判断并能得出什么结论? 解(1)给定显著性水平α=0.05,查自由度为(1)n k --=21-2-1=18的t 分布表,得临界值0.025(18)t =2.101。
对1n K t 而言,t=0.887/0.087=10.19,由于10.19 2.101t =>,故变量1n K t 的系数是显著的;对1n L t 而言,t=0.893/0.137=6.52,由于 6.52 2.101t =>,故变量1n L t 的系数也是显著的。
(2)给定显著性水平α=0.05,查自由度为(1)n k --=21-3-1=17的t 分布表,得临界值0.025(17)t =2.11。
对T 而言,t =0.0272/0.02=1.36,由于 1.36 2.11t =<,故变量T 的系数是不显著的;对1n K t 而言,t =0.46/0.333=1.38,由于 1.38 2.11t =<,故变量1n K t 的系数也是不显著的;(3)T 与1n K t 存在较强的相关性,模型存在多重共线性。
(4)T 与ln K 的相关系数为0.98,高度相关,模型存在多重共线性。
2.某地区供水部门利用最近15年的用水年度数据得出如下估计模型:Wˆ=-326.9 + 0.305HO + 0.363POP – 0.005RE – 17.87PR – 1.123RA (-1.7) (0.9) (1.4) (-0.6) (-1.2) (-0.8)2R =0.939 F =38.9其中,W (Water )—用水总量(百万立方米),HO (House )—住户总数(千户),POP (Population )—总人口(千人),RE (Revenue )—人均收人(元),PR (price )—价格(元/100立方米),RA (rain )—降雨量(毫米)。
(1)根据经济理论和直觉,预计回归系数的符号是什么(不包括常量)? 为什么? 观察符号与你的直觉相符吗?(2)在10%的显著性水平下,请进行变量的t 检验与方程的F 检验。
t 检验与F 检验结果有相矛盾的现象吗?(3)你认为估计值是①有偏的;②无效的或③不一致的吗? 详细阐述理由。
解(1)在其他变量不变的情况下,一城市的人口越多或房屋数量越多,则对用水的需求越高。
所以可期望HO 和POP 的符号为正;收入较高的个人可能用水较多,因此RE 的预期符号为正,但它可能是不显著的。
如果水价上涨,则用户会节约用水,所以可预期PR 的系数为负。
显然如果降雨量较大,则草地和其他花园或耕地的用水需求就会下降,所以可以期望RA 的系数符号为负。
从估计的模型看,除了RE 之外,所有符号都与预期相符。
(2)t -统计量检验单个变量的显著性,F -统计值检验变量是否是联合显著的。
这里t -检验的自由度为15-5-1=9,在10%的显著性水平下的临界值为1.833。
可见,所有参数估计值的t 值的绝对值都小于该值,所以即使在10%的水平下这些变量也不是显著的。
这里,F -统计值的分子自由度为5,分母自由度为9。
10%显著性水平下F 分布的临界值为2.61。
可见计算的F 值大于该临界值,表明回归系数是联合显著的。
T 检验与F 检验结果的矛盾可能是由于多重共线性造成的。
HO 、POP 、RE 都是高度相关的,这将使它们的t -值降低且表现为不显著。
PR 和RA 不显著另有原因。
根据经验,如果一个变量的值在样本期间没有很大的变化,则它对被解释变量的影响就不能够很好地被度量。
可以预期水价与年降雨量在各年中一般没有太大的变化,所以它们的影响很难度量。
(3)多重共线性往往表现的是解释变量间的样本观察现象,在不存在完全共线性的情况下,近似共线并不意味着基本假定的任何改变,所以OLS 估计量的无偏性、一致性和有效性仍然成立,即仍是BLUE 估计量。
但共线性往往导致参数估计值的方差大于不存在多重共线性的情况。
3.家庭消费支出不仅取决于可支配收入,还决定与家庭的的财富。
设此问题的理论模型为:01122i i i i Y X X u βββ=+++其中,Y i 为消费支出,X 1i 为家庭可支配收入,X 2i 为家庭财富。
根据表6-8中的数据建立回归模型并回答下列问题:(1)对所得的R 2、2R 、F 、t 等值作出评价; (2)所估计模型是否可靠,为什么? 表6-8 家庭消费支出与收入数据 编号1 2 3 4 5 6 7 8 9 10 Y 7065 90 95 110 115 120 140 155 150 X 1 80 100 120 140 160 180 200 220 240 260 X 2810100912731425169318762052220124352686解 (1)Dependent Variable: Y Method: Least SquaresDate: 08/23/13 Time: 22:07 Sample: 1 10Included observations: 10Coefficient Std. Error t-Statistic Prob. C 24.55158 6.952348 3.531408 0.0096 X1 0.568425 0.716098 0.793781 0.4534 X2 -0.005833 0.070294 -0.082975 0.9362R-squared 0.962099 Mean dependentvar 111.0000Adjusted R-squared 0.951270 S.D. dependentvar 31.42893S.E. of regression 6.937901 Akaike infocriterion 6.955201Sum squared resid 336.9413 Schwarzcriterion 7.045976Log likelihood -31.77600 Hannan-Quinncriter. 6.855620F-statistic 88.84545 Durbin-Watsonstat 2.708154 Prob(F-statistic) 0.000011(2)该模型并不可靠,原因是所选两个变量间存在严重多重共线性,X 1与X 2相关系数为4.表6-9提供了我国粮食总产量以及受主要因素影响的数据。